算法与数据结构(四)--排序算法
一.冒泡排序
原理图:

实现代码:
/* 冒泡排序或者是沉底排序 *//* int arr[]: 排序目标数组,这里元素类型以整型为例; int len: 元素个数 */
void bubbleSort (elemType arr[], int len) {//为什么外循环小于len-1次?//考虑临界情况,就是要循环到len-1个沉底/冒泡,则排序完毕for (int i=0; i<len-1; i++) {//为什么内循环小于等于len-2-i次?//考虑临界情况,第一次循环最后是索引为len-2与len-1进行比较,所以第一次循环到len-2,//每循环一次多沉底/冒泡一个,所以每循环完一次要多减去1,也就是多减去i,所以为len-2-ifor (int j=0; j<=len-2-i; j++) { //相邻元素比较,符合条件进行交换,数值大的元素沉底,数值小的元素冒泡if (arr[j] > arr[j+1]) { int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}
}二.插入排序
原理图:
实现代码:
// 插入排序函数(n是数组的长度)
void insertionSort(int arr[], int n) {//先对第二个元素进行插入(索引比实际位置少一),直到对n个元素进行插入for (int i = 1; i < n; i++) {int key = arr[i]; // 当前要插入的元素j = i-1;// 将当前元素与前面的比较,将比当前元素大的元素往后移动,自己往前移动// 直到找到合适的位置或者遍历到数组的开头while (int j >= 0 && arr[j] > key) {arr[j+1] = arr[j]; // 当前元素比key大,向后移动一位j = j-1; // 继续向前比较}arr[j+1] = key; // 将当前元素插入到正确的位置}
}
三.选择排序
原理图:
实现代码:
void selectionSort(int arr[], int n) {// 遍历数组,从第一个元素到倒数第二个元素,要排序n-1次,n-1个排好才算全部排好for (int i = 0; i < n - 1; i++) {int minIndex = i;//假设当前循环开始时,第一个元素为最小值// 在未排序部分寻找最小值for (int j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}// 如果最小值不是当前循环的第一个元素,则进行交换if (minIndex != i) {// 交换两个元素的位置int temp = arr[i];arr[i] = arr[minIndex];arr[minIndex] = temp;}}
}
上面三种简单排序算法在最坏情况及平均情况下都需要O()计算时间。
下面讨论的排序算法,它在平均情况下需要O(nlogn)时间。下面这些是目前最快的排序。
四.快速排序--分治法+挖坑填数
原理:
去B站看其中快速排序的哪一节!!!
分治法:大问题分解成各个小问题,对小问题求解,使得大问题得以解决。
实现代码:
#include<iostream>
using namespace std;
void PrintArray(int arr[],int len) {for(int i=0; i<len; i++) {cout<<arr[i]<<" ";}cout<<endl;
}
//快速排序,从小到大
void QuickSort(int arr[],int start,int end) {//i和j是索引的值,也可以看做是指针,//先让它们指向要排序数据的首尾int i=start;int j=end;//基准数,这里取数据的start位置,同时也是此时i的位置//挖坑填数时挖出来的第一个数(也就是第一个的坑)为基准数的位置/也是此时start和i的位置int temp=arr[start];//保证参数输入正确,即,start<end,否则不执行if(i<j) {//只要i和j不重合,就不断地移动j,挖坑填数,移动i,挖坑填数...//最后做到基准数小的数都在基准数的左边,比基准数大的数都在基准数的右边while(i<j) //移动指针j,从右向左找比基准数小的元素,比基准数大继续左移,//直到遇到比基准数小的元素才跳出循环,用该元素填坑while(i<j&&arr[j]>=temp) {j--;}//用j位置的数据给i的坑填数(将j的数据赋值给i),j变成坑if(i<j) {arr[i]=arr[j];}//移动指针i,从左向右找比基准数大的数,比基准数小i继续右移,//直到遇到比基准数小的元素才跳出循环,用该元素填坑while(i<j&&arr[i]<temp) {i++;}//用i位置的数据给j的坑填数(将i的数据赋值给j),j变成坑if(i<j) {arr[j]=arr[i];}}//最后i和j重叠的位置就是基准数的位置,把基准数放到i的位置填上最后一个坑arr[i]=temp;//递归//1.对左半部分进行快速排序QuickSort(arr,start,i-1);//2.对右半部分进行快速排序QuickSort(arr,i+1,end); }
}
int main() {int myArr[]= {4,2,8,0,5,7,1,3,9};int len=sizeof(myArr)/sizeof(int);PrintArray(myArr,len);QuickSort(myArr,0,len-1);PrintArray(myArr,len);return 0;
}五.归并排序/合并排序--分治法+合并两个有序序列
基本思想:分治法+将两个有序序列合并成一个有序序列
怎么合并呢?
就是开辟一块临时的存储空间。就比如有两个身高从低到高的队伍,要合并成一个也是身高从小到高的队伍,就先将每个队伍的第一个人比较身高,然后低的进去,然后第二个人再与另一个队的第一个人比较身高,低的进去。。。以此类推,差不多就是这样。
去B站看其中合并排序的哪一节!!!
#include<iostream>
#include<time.h>
#include<sys/timeb.h>
using namespace std;
#define MAX 10
//创建数组
int* CreatArray() {srand((unsigned int)time(NULL));int* arr=(int*)malloc(sizeof(int)*MAX);for(int i=0; i<MAX; i++) {arr[i]=rand()%MAX;}return arr;
}
//打印
void PrintArray(int arr[],int len) {for(int i=0; i<len; i++) {cout<<arr[i]<<" ";}cout<<endl;
}
//合并算法,从小到大
//int *temp--临时的存储空间
void Merge(int arr[],int start,int end,int mid,int *temp) {//一.将序列拆分为i,j两个序列 int i_start=start;//i序列的头指针 int i_end=mid;//i序列的尾指针 int j_start=mid+1;//j序列的头指针 int j_end=end;//j序列的尾指针 int length=0;//表示辅助空间有多少个元素//二.合并两个有序序列,并且使得合并后仍然有序//遍历到其中一个序列空为止while(i_start<=i_end&&j_start<=j_end) {//如果i指针指向的元素比j小,则先推出到辅助空间中if(arr[i_start]<arr[j_start]) {//将数据存到辅助空间中temp[length]=arr[i_start];//辅助空间长度加一length++;//i序列指针往后移判断下一个推入辅助空间的元素i_start++;} else {//如果j指针指向的元素比i小,则先推出到辅助空间中//将数据存到辅助空间中temp[length]=arr[j_start];//辅助空间长度加一length++;//j序列指针往后移判断下一个要推入辅助空间的元素j_start++;}}//三.只有一个序列为空,说明有一个序列里面还有剩下的元素,要将剩下的元素也存到辅助空间 //如果i这个序列的头指针仍然在尾指针之前,说明里面还有元素while (i_start<=i_end) {//将数据存到辅助空间中temp[length]=arr[i_start];//辅助空间长度加一length++;//i序列指针往后移判断下一个推入辅助空间的元素i_start++;}//如果j这个序列的头指针仍然在尾指针之前,说明里面还有元素while(j_start<=j_end) {//将数据存到辅助空间中temp[length]=arr[j_start];//辅助空间长度加一length++;//j序列指针往后移判断下一个要推入辅助空间的元素j_start++;}//四.把辅助空间中的数据覆盖到原空间for(int i=0;i<length;i++){arr[start+i]=temp[i];}
}
//归并排序
void MergeSort(int arr[],int start,int end,int* temp) {if(start>=end) {return;}int mid=(start+end)/2;//分组//左半边MergeSort(arr,start,mid,temp);//右半边MergeSort(arr,mid+1,end,temp);//合并Merge(arr,start,end,mid,temp);}
int main() {int* myArr=CreatArray();PrintArray(myArr,MAX);//辅助空间,来存储合并后的有序序列。int * temp=(int*)malloc(sizeof(int)* MAX) ;MergeSort(myArr,0,MAX-1,temp);PrintArray(myArr,MAX);//释放空间free(temp);free(myArr);
}六.希尔排序--分治法+插入排序(插入排序的提升版)
[算法]六分钟彻底弄懂希尔排序,简单易懂
20希尔排序
#include <stdio.h>
void shellSort(int arr[],int length) {int increasement=length;//确定分组的增量,你可以用你喜欢的增量,我这里取长度除以2 increasement=increasement/2;//增量小于1停止,也就是最后对一整组进行插入排序后停止 while(increasement>1) {//遍历每一组for(int i=0; i<increasement; i++) {// 对每一组进行快速排序//遍历当前这组的元素 for(int j=i+increasement; j<length; j+=increasement) {// 如果当前元素小于前一个元素,则进行插入操作if(arr[j]<arr[j-increasement]) {int temp=arr[j];int k;// 将大于temp的元素向后移动for(k=j-increasement; k>=0&&temp<arr[k]; k-=increasement) {arr[k+increasement]=arr[k];}// 插入temp到正确的位置arr[k+increasement]=temp;}}}//缩小增量 increasement=increasement/2;}
}
void printArray(int arr[], int n) {for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");
}int main() {int arr[] = {12, 34, 54, 2, 3};int n = sizeof(arr) / sizeof(arr[0]);printf("原始数组: ");printArray(arr, n);shellSort(arr, n);printf("排序后的数组: ");printArray(arr, n);return 0;
}为什么分组后的插入排序会快呢?
因为插入排序在元素序列基本有序和元素个数比较小的时候速度较快,而分组就创造了这种条件。
总结
可以发现,下面三种快的排序(平均情况下的时间复杂度都为O(nlogn))都使用了分治法,将一个大问题分为几个相同的小问题,分而治之。
相关文章:
算法与数据结构(四)--排序算法
一.冒泡排序 原理图: 实现代码: /* 冒泡排序或者是沉底排序 *//* int arr[]: 排序目标数组,这里元素类型以整型为例; int len: 元素个数 */ void bubbleSort (elemType arr[], int len) {//为什么外循环小于len-1次?//考虑临界情况…...

【C/C++】C++11 在各编译器版本支持详情
C11 是在 2011 年发布的 C 标准,各编译器对 C11 的支持情况如下: GCC:GCC 4.8 及以上版本支持 C11。Clang:Clang 3.3 及以上版本支持 C11。Visual Studio:Visual Studio 2010 及以上版本支持部分 C11 特性,…...

flutter开发实战-图片保存到相册
flutter开发实战-图片保存到相册。保存相册使用的是image_gallery_saver插件 一、引入image_gallery_saver插件 在pubspec.yaml中引入插件 # 保存图片到相册image_gallery_saver: ^1.7.1# 权限permission_handler: ^10.0.0二、保存到相册的代码 使用image_gallery_saver将图…...

数据结构---栈
(一)栈之基础补充 C语言内存分配 对于一个C语言程序而言,内存空间主要由五个部分组成 代码段(text)、数据段(data)、未初始化数据段(bss),堆(heap) 和 栈(stack) 组成,其中代码段,数据段和BSS段是编译的时候由编译器分配的,而堆和栈是程序运行的时候由系统分配的。布局如…...

【RabbitMQ】golang客户端教程1——HelloWorld
一、介绍 本教程假设RabbitMQ已安装并运行在本机上的标准端口(5672)。如果你使用不同的主机、端口或凭据,则需要调整连接设置。如果你未安装RabbitMQ,可以浏览我上一篇文章Linux系统服务器安装RabbitMQ RabbitMQ是一个消息代理&…...

计算机图形学笔记2-Viewing 观测
观测主要解决的问题是如何把物体的三维“模型”变成我们在屏幕所看到的二维“图片”,我们在计算机看到实体模型可以分成这样几步: 相机变换(camera transformation)或眼变换(eye transformation):想象把相机放在任意一个位置来观测物体&#…...
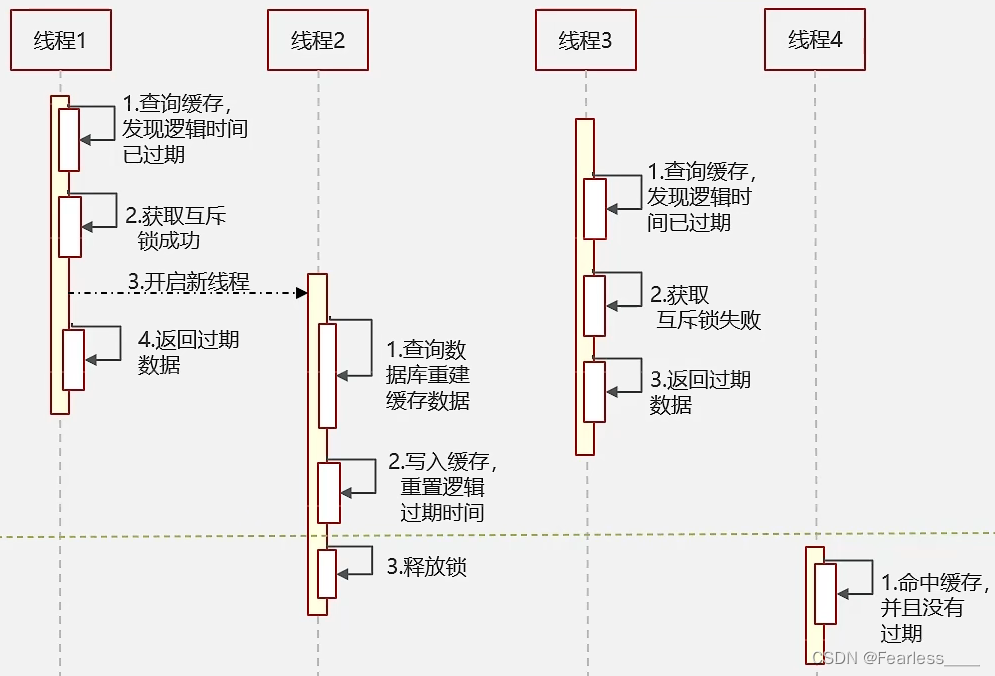
Redis - 三大缓存问题(穿透、击穿、雪崩)
缓存穿透 概念: 查询一个数据库中也不存在的数据,数据库查询不到数据也就不会写入缓存,就会导致一直查询数据库 解决方法: 1. 缓存空数据 如果数据库也查询不到,就把空结果进行缓存 缺点是 - 消耗内存 2. 使用布…...
web自动化测试-PageObject 设计模式
为 UI 页面写测试用例时(比如 web 页面,移动端页面),测试用例会存在大量元素和操作细节。当 UI 变化时,测试用例也要跟着变化, PageObject 很好的解决了这个问题。 使用 UI 自动化测试工具时(包…...
 结构体、map 携带 符号 转成 “\u0026“)
golang json.Marshal() 结构体、map 携带 符号 转成 “\u0026“
问题:数据结构中的值 带有 & > < 等符号,当我们要将 struct map 转成json时,使用 json.Marshal() 函数,此函数会将 值中的 & < > 符号转义 为 类似 "\u0026" 像我们某个结构体中…...
)
【设计模式|行为型】备忘录模式(Memento Pattern)
说明 备忘录模式是一种行为型设计模式,通过捕获一个对象的内部状态,并在该对象之外保存这个状态,以便在需要时恢复对象到原先的状态。备忘录模式包含三个核心角色:。 发起人(Originator):负责…...
的区别是什么?)
Redis与其他缓存解决方案(如Memcached)的区别是什么?
Redis和其他缓存解决方案(如Memcached)在设计理念、功能和特点上有一些区别,以下是它们的主要区别: 数据类型支持:Redis支持多种数据类型(如字符串、哈希表、列表、集合、有序集合等)࿰…...

《面试1v1》Kafka的ack机制
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...
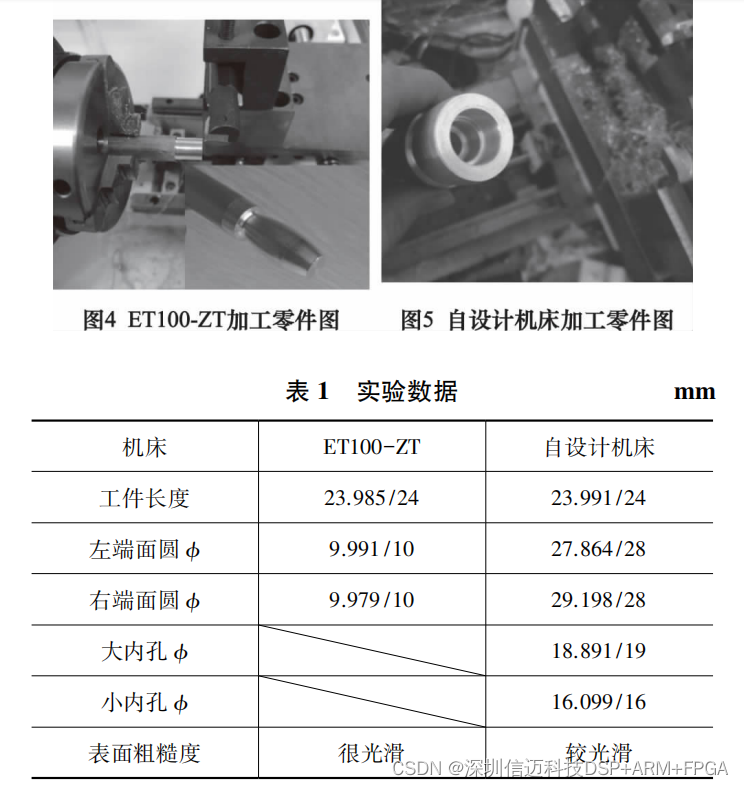
基于双 STM32+FPGA 的桌面数控车床控制系统设计
桌 面数控 设 备 对 小 尺寸零件加工在成 本 、 功 耗 和 占 地 面 积等方 面有 着 巨 大 优 势 。 桌 面数控 设 备 大致 有 3 种 实 现 方 案 : 第 一种 为 微 型 机 床搭 配 传统 数控系 统 , 但 是 桌 面数控 设 备 对 成 本 敏感 ; 第二 种 为 基 于 PC…...
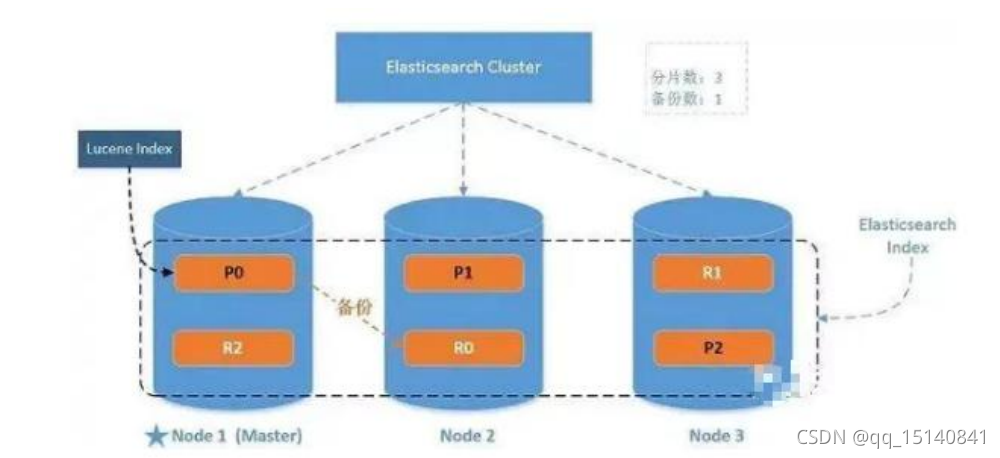
ES-5-进阶
单机 & 集群 单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器 性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中 配置服务器集群时,集…...

Java面试准备篇:全面了解面试流程与常见问题
文章目录 1.1 Java面试概述1.2 面试流程和注意事项1.3 自我介绍及项目介绍1.4 常见面试问题 在现代职场中,面试是求职过程中至关重要的一环,特别是对于Java开发者而言。为了帮助广大Java开发者更好地应对面试,本文将提供一份全面的Java面试准…...
Go语言进阶语法八万字详解,通俗易懂
文章目录 File文件操作FileInfo接口权限打开模式File操作文件读取 I/O操作io包 文件复制io包下的Read()和Write()io包下的Copy()ioutil包总结 断点续传Seeker接口断点续传 bufio包bufio包原理Reader对象Writer对象 bufio包bufio.Readerbufio.Writer ioutil包ioutil包的方法示例…...

Apache RocketMQ 远程代码执行漏洞(CVE-2023-37582)
漏洞简介 Apache RocketMQ是一款低延迟、高并发、高可用、高可靠的分布式消息中间件。CVE-2023-37582 中,由于对 CVE-2023-33246 修复不完善,导致在Apache RocketMQ NameServer 存在未授权访问的情况下,攻击者可构造恶意请求以RocketMQ运…...

Kotlin Multiplatform 使用 CocoaPods 创建多平台分发库
Kotlin Multiplatform 支持直接创建Framework 方式和使用CocoaPods 方式创建Framework。 1、不同之处在于创建的时候需要选择不同的方式。 2、使用CocoaPods 方式还需要在 build.gradle(.kts) 文件中添加内容 在build.gradle(.kts) 文件中添加完成后,执行一下文件。…...

前端食堂技术周刊第 92 期:VueConf 2023、TypeChat、向量数据库、Nuxt 服务器组件指南
美味值:🌟🌟🌟🌟🌟 口味:整颗牛油果酸奶 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先…...

用C语言构建一个手写数字识别神经网络
(原理和程序基本框架请参见前一篇 "用C语言构建了一个简单的神经网路") 1.准备训练和测试数据集 从http://yann.lecun.com/exdb/mnist/下载手写数字训练数据集, 包括图像数据train-images-idx3-ubyte.gz 和标签数据 train-labels-idx1-ubyte.…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

潮州东方轻奢风全屋高定找哪家
开篇引言根据《2026年中国全屋定制行业发展报告》,潮州市全屋定制市场规模同比增长38%,其中全屋高端定制细分市场同比增长52%。目前,潮州市家庭全屋定制需求占比72%,高端定制需求占比45%。为了帮助潮州市消费者选择合规、靠谱、差…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...