Hadoop_HDFS_常见的文件组织格式与压缩格式
参考资料
1. HDFS中的常用压缩算法及区别_大数据_王知无_InfoQ写作社区
2. orc格式和parquet格式对比-阿里云开发者社区
3.Hadoop 压缩格式 gzip/snappy/lzo/bzip2 比较与总结 | 海牛部落 高品质的 大数据技术社区
4. Hive中的文件存储格式TEXTFILE、SEQUENCEFILE、RCFILE、ORCFILE、Parquet 和 AVRO使用与区别详解_text orc pquest sequentfile_皮哥四月红的博客-CSDN博客
5.Hadoop 压缩格式 gzip/snappy/lzo/bzip2 比较与总结 | 海牛部落 高品质的 大数据技术社区
本文主要介绍下HDFS上的常见文件格式和压缩格式
总结 :
HDFS 中常见的文件存储格式
- textfile :行式存储格式
- sequencefile :行式存储格式
- orc :列式存储格式, 支持ACID,常用的文件组织方式, 查询效率比parquet高
- parquet : 列式存储格式 不支持ACID
HDFS中常见的文件压缩方式
- gzip : 不支持split
- lzo : 支持split
- snappy : 不支持split, 数仓中最常用的压缩方式
- bzip2 : 支持split
行式存储和列式存储
TEXTFILE 、SEQUENCEFILE、RCFILE、ORC、PARQUET,AVRO。其中TEXTFILE 、SEQUENCEFILE、AVRO都是基于行式存储,其它三种是基于列式存储;所谓的存储格式就是在Hive建表的时候指定的将表中的数据按照什么样子的存储方式,如果指定了A方式,那么在向表中插入数据的时候,将会使用该方式向HDFS中添加相应的数据类型。
逻辑图
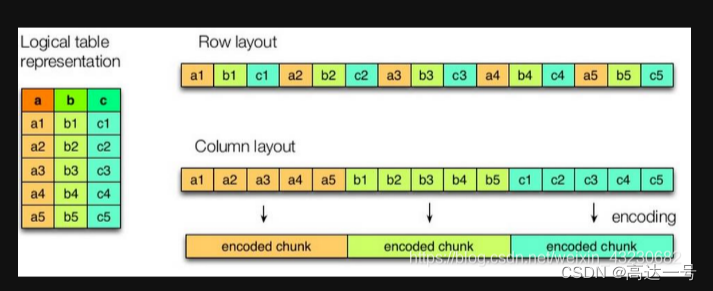
如上图所示,左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
1.行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
2.列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
=====================================================
文件格式
下面对常见的文件存储格式做一个详细的介绍,主要以最常用的sequenceFile 和 parquet 为主。
TextFile
文件存储就是正常的文本格式,将表中的数据在hdfs上 以文本的格式存储
,下载后可以直接查看,也可以使用cat命令查看
如何指定
1.无需指定,默认就是
2.显示指定stored as textfile
3.显示指定
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'优缺点
1.行存储使用textfile存储文件默认每一行就是一条记录,
2.可以使用任意的分隔符进行分割。
3.但无压缩,所以造成存储空间大。可结合Gzip、Bzip2、Snappy等使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
-------------------------------------------------------------------------------
SequenceFile
SequenceFile 文件是 Hadoop 用来存储二进制形式的[Key,Value]对而设计的一种平面文件(Flat File)。可以把 SequenceFile 当做是一个容器,把所有的文件打包到 SequenceFile 类中可以高效的对小文件进行存储和处理。SequenceFile 文件并不按照其存储的 Key 进行排序存储,SequenceFile 的内部类 Writer 提供了 append 功能。SequenceFile 中的 Key 和 Value 可以是任意类型 Writable 或者是自定义 Writable。
在存储结构上,SequenceFile 主要由一个 Header 后跟多条 Record 组成,Header 主要包含了 Key classname,value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。每条 Record 以键值对的方式进行存储,用来表示它的字符数组可以一次解析成:记录的长度、Key 的长度、Key 值和 value 值,并且 Value 值的结构取决于该记录是否被压缩。
SequenceFile 支持三种记录存储方式:
-
无压缩, io 效率较差. 相比压缩, 不压缩的情况下没有什么优势.
-
记录级压缩, 对每条记录都压缩. 这种压缩效率比较一般.
-
块级压缩, 这里的块不同于 hdfs 中的块的概念. 这种方式会将达到指定块大小的二进制数据压缩为一个块. 相对记录级压缩, 块级压缩拥有更高的压缩效率. 一般来说使用 SequenceFile 都会使用块级压缩.
如何指定
1.stored as sequecefile
2.或者显示指定:
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat'优缺点
1.sequencefile存储格有压缩,存储空间小,有利于优化磁盘和I/O性能
2.同时支持文件切割分片,提供了三种压缩方式:none,record,block(块级别压缩效率跟高).默认是record(记录)
3.基于行存储
-------------------------------------------------------------------------------
RCFile 不推荐,推荐进化的ORCFile
在hdfs上将表中的数据以二进制格式编码,并且支持压缩。下载后的数据不可以直接可视化。
如何指定
1.stored as rcfile
2.或者显示指定:
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileOutputFormat'
优缺点
1.行列混合的存储格式,基于列存储。
2.因为基于列存储,列值重复多,所以压缩效率高。
3.磁盘存储空间小,io小。
-------------------------------------------------------------------------------
ORCFile
ORC File,全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。
ORC(optimizedRC File) 存储源自RC(RecordCloimnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,主要是在压缩编码,查询性能方面做了优化.RC/ORC最初是在Hive中得到使用,最后发展势头不错,独立成一个单独的项目.Hive1.xbanbendu版本对事物和update操作的支持,便是给予ORC实现的(其他存储格式暂不支持).
如何指定
1.CREATE TABLE ... STORED AS ORC2.ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC3.SET hive.default.fileformat=Orc优缺点
1.面向列的存储格式
2.由Hadoop中RC files 发展而来,比RC file更大的压缩比,和更快的查询速度
3.Schema 存储在footer中
4.不支持schema evolution
5.支持事务(ACID)
6.为hive而生,在许多non-hive MapReduce的大数据组件中不支持使用
7.高度压缩比并包含索引
其他
ORC 文件格式可以使用 HIVE 自带的命令 concatenate 快速合并小文件
-------------------------------------------------------------------------------
Parquet
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
Apache Parquet 最初的设计动机是存储嵌套式数据,比如Protocolbuffer thrift json 等 将这类数据存储成列式格式以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,
如何指定
Hive 0.13 and later:STORED AS PARQUET;Hive 0.10 - 0.12:
ROW FORMAT SERDE 'parquet.hive.serde.ParquetHiveSerDe'
STORED AS
INPUTFORMAT 'parquet.hive.DeprecatedParquetInputFormat'
OUTPUTFORMAT 'parquet.hive.DeprecatedParquetOutputFormat'; 优缺点
1.与ORC类似,基于Google dremel
2.Schema 存储在footer
3.列式存储
4.高度压缩比并包含索引
5.相比ORC的局限性,parquet支持的大数据组件范围更广
Avro
Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
如何指定
1.STORED AS AVRO2.STORED ASINPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'优缺点
1.Avro以基于行的格式存储数据
2.设计的主要目标是为了满足schema evolution
3.schema和数据保存在一起
Parquet和ORC文件对比

不同文件格式的性能测试
测试demo1
新建六张不同文件格式的测试用表:
--textfile文件格式
CREATE TABLE `test_textfile`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile;--sequence文件格式
CREATE TABLE `test_sequence`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS sequence;--rc文件格式
CREATE TABLE `test_rc`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS rc;--orc文件格式
CREATE TABLE `test_orc`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS orc;--parquet文件格式
CREATE TABLE `test_parquet`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS parquet;--avro文件格式
CREATE TABLE `test_avro`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS avro;然后,从同一个源表新增数据到这六张测试表,为了体现存储数据的差异性,我们选取了一张数据量比较大的源表(源表数据量为30000000条),根据测试结果从存储空间和SQL查询两个方面进行比较:
文件存储格式 HDFS存储空间 不含group by 含group by
TextFile 7.3 G 105s 370s
Sequence 7.8 G 135s 385s
RC 6.9 G 92s 330s
ORC 246.0 M 34s 310s
Parquet 769.0 M 28s 195s
AVRO 8.0G 240s 530s
根据性能测试总结
- 从存储文件的压缩比来看,ORC和Parquet文件格式占用的空间相对而言要小得多。
- 从存储文件的查询速度看,当表数据量较大时Parquet文件格式查询耗时相对而言要小得多。
测试demo2
https://netflixtechblog.com/using-presto-in-our-big-data-platform-on-aws-938035909fd4
这篇文章主要讲解了persto对 orc和parquet 的对比,见文章中部。
=====================================================================
压缩方式
Hadoop对于压缩格式的是透明识别,hadoop能够自动为我们将压缩的文件解压。 目前在Hadoop中常用的几种压缩格式:lzo,gzip,snappy,bzip2,我们简单做一下对比,方便我们在实际场景中选择不同的压缩格式。
| 压缩格式 | codec类 | 算法 | 扩展名 | 多文件 | splitable | native | 工具 | hadoop自带 |
|---|---|---|---|---|---|---|---|---|
| gzip | GzipCodec | deflate | .gz | 否 | 否 | 是 | gzip | 是 |
| bzip2 | Bzip2Codec | bzip2 | .bz2 | 是 | 是 | 否 | bzip2 | 是 |
| lzo | LzopCodec | lzo | .lzo | 否 | 是 | 是 | lzop | 否 |
| snappy | SnappyCodec | snappy | .snappy | 否 | 否 | 是 | 无 | 否 |
- 压缩相关codec实现在org.apache.hadoop.io.compress包下面
deflate压缩
标准压缩算法,其算法实现是zlib,而gzip文件格式只是在deflate格式上增加了文件头和一个文件尾
gzip压缩
压缩率比较高,而且压缩/解压速度也比较快;
hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;
有hadoop native库;
大部分linux系统都自带gzip命令,使用方便;
缺点 : 不支持split;
①适用于压缩后的文件大小在120M以内(haoop2的标准block大小是120M)的处理,可以有效提高读的并发,对hive,streaming,Java 等mr程序透明,无需修改原程序
②由于gzip拥有较高的压缩比,因此相比于其他压缩算法,更适用于冷数据的存储
bzip2压缩
支持split,支持多文件;
具有很高的压缩率,比gzip压缩率都高;
hadoop本身支持,但不支持native;
在linux系统下自带bzip2命令,使用方便;
压缩/解压速度很慢;
不支持native;
①适合对速度要求不高,但需要较高的压缩率的时候,可以作为mapreduce作业的输出格式
②输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况
③对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用程序(即应用程序不需要修改)的情况
lzo压缩
压缩/解压速度也比较快,合理的压缩率;
支持split,是hadoop中最流行的压缩格式(需要建索引,文件修改后需要重新建索引);
支持hadoop native库;
可以在linux系统下安装lzop命令,使用方便;
压缩率比gzip要低一些;
hadoop本身不支持,需要安装;
在应用中对lzo格式的文件需要做一些特殊处理(为了支持split需要建索引,还需要指定inputformat为lzo格式);
①适用于较大文本的处理
snappy压缩
高速压缩速度和合理的压缩率;
支持hadoop native库;
不支持split;
压缩率比gzip要低;
hadoop本身不支持,需要安装;
linux系统下没有对应的命令
Tips :
① 当mapreduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式;
②或者作为一个mapreduce作业的输出和另外一个mapreduce作业的输入
是否压缩数据以及使用何种压缩格式对性能具有重要的影响,一般原则:
- 需要平衡压缩和解压缩数据所需的能力、读写数据所需的磁盘 IO,以及在网络中发送数据所需的网络带宽。正确平衡这些因素有赖于集群和数据的特征,以及您的使用模式。
- 如果数据已压缩(例如 JPEG 格式的图像),则不建议进行压缩。事实上,结果文件实际上可能大于原文件。
- GZIP 压缩使用的 CPU 资源比 Snappy 或 LZO 更多,但可提供更高的压缩比。GZIP 通常是不常访问的冷数据的不错选择。而 Snappy 或 LZO 则更加适合经常访问的热数据。
- BZip2 还可以为某些文件类型生成比 GZip 更多的压缩,但是压缩和解压缩时会在一定程度上影响速度。HBase 不支持 BZip2 压缩。
- Snappy 的表现通常比 LZO 好。应该运行测试以查看您是否检测到明显区别。
- 对于 MapReduce,如果您需要已压缩数据可拆分,BZip2、LZO 和 Snappy 格式都可拆分,但是 GZip 不可以。可拆分性与 HBase 数据无关。
- 对于 MapReduce,可以压缩中间数据、输出或二者。相应地调整您为 MapReduce 作业提供的参数。
=======================================================================
延申问题
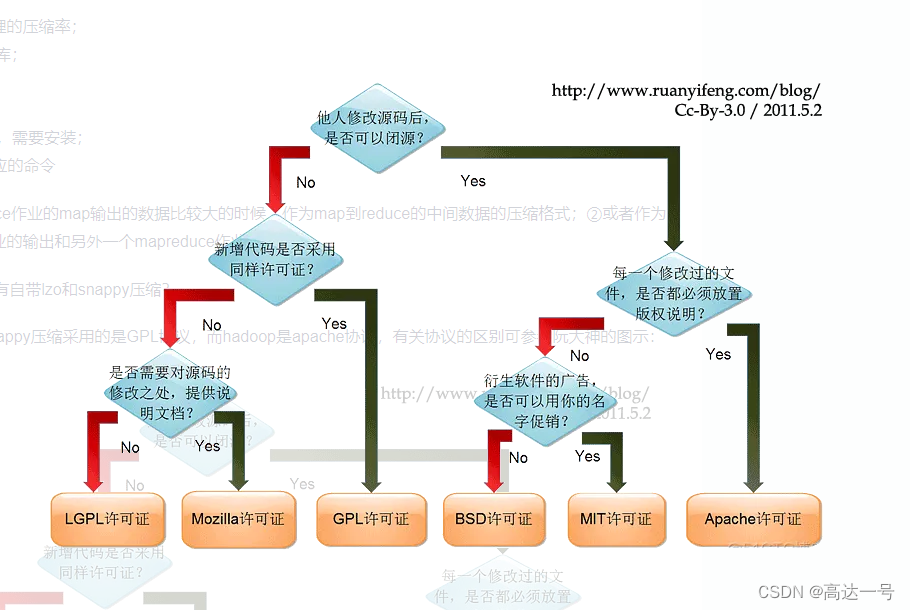
为什么hadoop没有自带lzo和snappy压缩?
主要是由于lzo和snappy压缩采用的是GPL协议,而hadoop是apache协议,有关协议的区别可参考阮大神的图示:
相关文章:
Hadoop_HDFS_常见的文件组织格式与压缩格式
参考资料 1. HDFS中的常用压缩算法及区别_大数据_王知无_InfoQ写作社区 2. orc格式和parquet格式对比-阿里云开发者社区 3.Hadoop 压缩格式 gzip/snappy/lzo/bzip2 比较与总结 | 海牛部落 高品质的 大数据技术社区 4. Hive中的文件存储格式TEXTFILE、SEQUENCEFILE、RCFILE…...
算法与数据结构(四)--排序算法
一.冒泡排序 原理图: 实现代码: /* 冒泡排序或者是沉底排序 *//* int arr[]: 排序目标数组,这里元素类型以整型为例; int len: 元素个数 */ void bubbleSort (elemType arr[], int len) {//为什么外循环小于len-1次?//考虑临界情况…...

【C/C++】C++11 在各编译器版本支持详情
C11 是在 2011 年发布的 C 标准,各编译器对 C11 的支持情况如下: GCC:GCC 4.8 及以上版本支持 C11。Clang:Clang 3.3 及以上版本支持 C11。Visual Studio:Visual Studio 2010 及以上版本支持部分 C11 特性,…...

flutter开发实战-图片保存到相册
flutter开发实战-图片保存到相册。保存相册使用的是image_gallery_saver插件 一、引入image_gallery_saver插件 在pubspec.yaml中引入插件 # 保存图片到相册image_gallery_saver: ^1.7.1# 权限permission_handler: ^10.0.0二、保存到相册的代码 使用image_gallery_saver将图…...

数据结构---栈
(一)栈之基础补充 C语言内存分配 对于一个C语言程序而言,内存空间主要由五个部分组成 代码段(text)、数据段(data)、未初始化数据段(bss),堆(heap) 和 栈(stack) 组成,其中代码段,数据段和BSS段是编译的时候由编译器分配的,而堆和栈是程序运行的时候由系统分配的。布局如…...

【RabbitMQ】golang客户端教程1——HelloWorld
一、介绍 本教程假设RabbitMQ已安装并运行在本机上的标准端口(5672)。如果你使用不同的主机、端口或凭据,则需要调整连接设置。如果你未安装RabbitMQ,可以浏览我上一篇文章Linux系统服务器安装RabbitMQ RabbitMQ是一个消息代理&…...

计算机图形学笔记2-Viewing 观测
观测主要解决的问题是如何把物体的三维“模型”变成我们在屏幕所看到的二维“图片”,我们在计算机看到实体模型可以分成这样几步: 相机变换(camera transformation)或眼变换(eye transformation):想象把相机放在任意一个位置来观测物体&#…...
Redis - 三大缓存问题(穿透、击穿、雪崩)
缓存穿透 概念: 查询一个数据库中也不存在的数据,数据库查询不到数据也就不会写入缓存,就会导致一直查询数据库 解决方法: 1. 缓存空数据 如果数据库也查询不到,就把空结果进行缓存 缺点是 - 消耗内存 2. 使用布…...
web自动化测试-PageObject 设计模式
为 UI 页面写测试用例时(比如 web 页面,移动端页面),测试用例会存在大量元素和操作细节。当 UI 变化时,测试用例也要跟着变化, PageObject 很好的解决了这个问题。 使用 UI 自动化测试工具时(包…...
 结构体、map 携带 符号 转成 “\u0026“)
golang json.Marshal() 结构体、map 携带 符号 转成 “\u0026“
问题:数据结构中的值 带有 & > < 等符号,当我们要将 struct map 转成json时,使用 json.Marshal() 函数,此函数会将 值中的 & < > 符号转义 为 类似 "\u0026" 像我们某个结构体中…...
)
【设计模式|行为型】备忘录模式(Memento Pattern)
说明 备忘录模式是一种行为型设计模式,通过捕获一个对象的内部状态,并在该对象之外保存这个状态,以便在需要时恢复对象到原先的状态。备忘录模式包含三个核心角色:。 发起人(Originator):负责…...
的区别是什么?)
Redis与其他缓存解决方案(如Memcached)的区别是什么?
Redis和其他缓存解决方案(如Memcached)在设计理念、功能和特点上有一些区别,以下是它们的主要区别: 数据类型支持:Redis支持多种数据类型(如字符串、哈希表、列表、集合、有序集合等)࿰…...

《面试1v1》Kafka的ack机制
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...
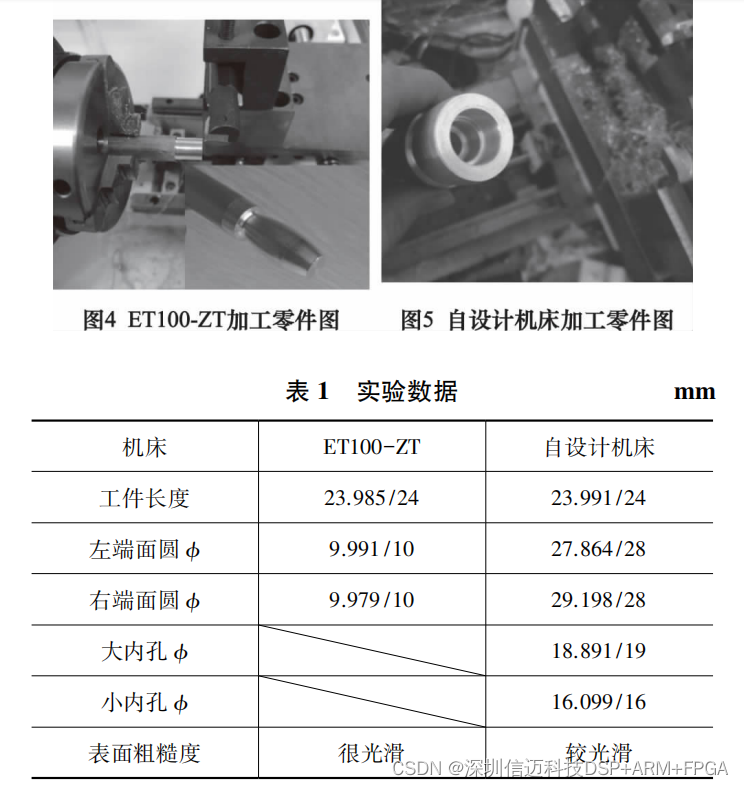
基于双 STM32+FPGA 的桌面数控车床控制系统设计
桌 面数控 设 备 对 小 尺寸零件加工在成 本 、 功 耗 和 占 地 面 积等方 面有 着 巨 大 优 势 。 桌 面数控 设 备 大致 有 3 种 实 现 方 案 : 第 一种 为 微 型 机 床搭 配 传统 数控系 统 , 但 是 桌 面数控 设 备 对 成 本 敏感 ; 第二 种 为 基 于 PC…...
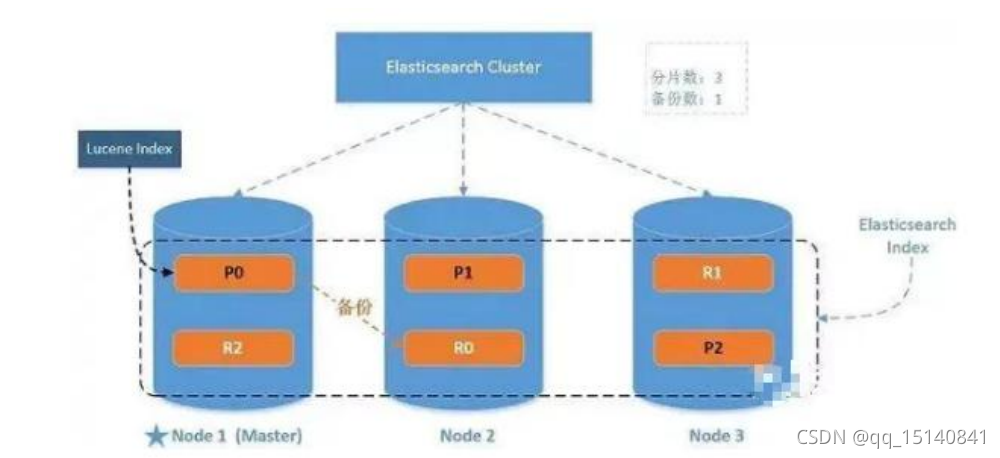
ES-5-进阶
单机 & 集群 单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器 性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中 配置服务器集群时,集…...

Java面试准备篇:全面了解面试流程与常见问题
文章目录 1.1 Java面试概述1.2 面试流程和注意事项1.3 自我介绍及项目介绍1.4 常见面试问题 在现代职场中,面试是求职过程中至关重要的一环,特别是对于Java开发者而言。为了帮助广大Java开发者更好地应对面试,本文将提供一份全面的Java面试准…...
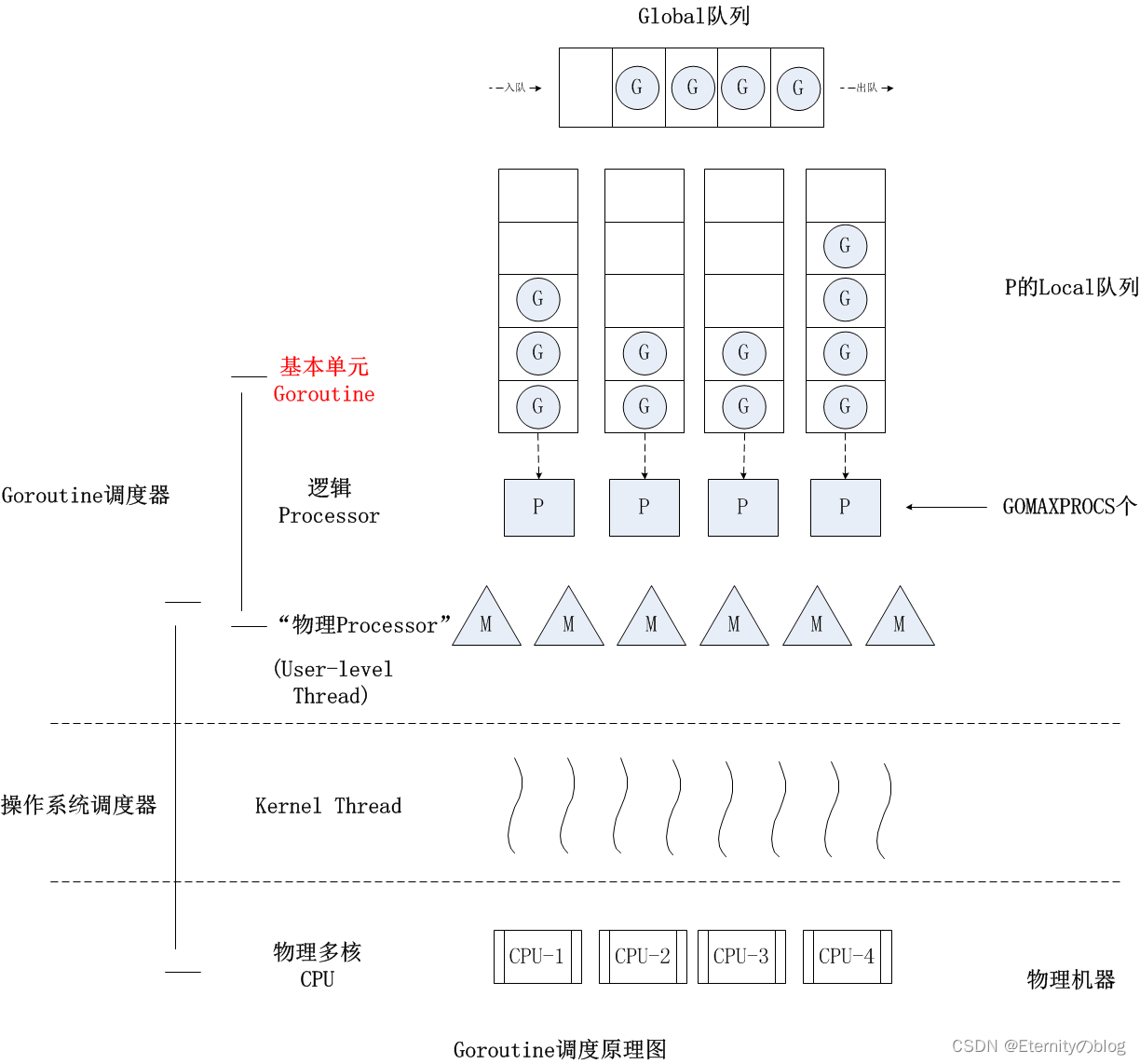
Go语言进阶语法八万字详解,通俗易懂
文章目录 File文件操作FileInfo接口权限打开模式File操作文件读取 I/O操作io包 文件复制io包下的Read()和Write()io包下的Copy()ioutil包总结 断点续传Seeker接口断点续传 bufio包bufio包原理Reader对象Writer对象 bufio包bufio.Readerbufio.Writer ioutil包ioutil包的方法示例…...

Apache RocketMQ 远程代码执行漏洞(CVE-2023-37582)
漏洞简介 Apache RocketMQ是一款低延迟、高并发、高可用、高可靠的分布式消息中间件。CVE-2023-37582 中,由于对 CVE-2023-33246 修复不完善,导致在Apache RocketMQ NameServer 存在未授权访问的情况下,攻击者可构造恶意请求以RocketMQ运…...

Kotlin Multiplatform 使用 CocoaPods 创建多平台分发库
Kotlin Multiplatform 支持直接创建Framework 方式和使用CocoaPods 方式创建Framework。 1、不同之处在于创建的时候需要选择不同的方式。 2、使用CocoaPods 方式还需要在 build.gradle(.kts) 文件中添加内容 在build.gradle(.kts) 文件中添加完成后,执行一下文件。…...

前端食堂技术周刊第 92 期:VueConf 2023、TypeChat、向量数据库、Nuxt 服务器组件指南
美味值:🌟🌟🌟🌟🌟 口味:整颗牛油果酸奶 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

全球无障碍宣传日:iOS 26 辅助功能大升级,这些实用小功能你用过吗?
辅助功能发展与升级很多人对辅助功能的印象还停留在 "小白点",但随着 iPhone 进入全面屏时代,它逐渐变得陌生。实际上,Apple 每年都会为其增添功能,方便身体有障人士使用 iPhone。而且,这些功能不仅惠及有障…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...