PyTorch 中的多 GPU 训练和梯度累积作为替代方案
动动发财的小手,点个赞吧!
在本文[1]中,我们将首先了解数据并行(DP)和分布式数据并行(DDP)算法之间的差异,然后我们将解释什么是梯度累积(GA),最后展示 DDP 和 GA 在 PyTorch 中的实现方式以及它们如何导致相同的结果。
简介
训练深度神经网络 (DNN) 时,一个重要的超参数是批量大小。通常,batch size 不宜太大,因为网络容易过拟合,但也不宜太小,因为这会导致收敛速度慢。
当处理高分辨率图像或占用大量内存的其他类型的数据时,假设目前大多数大型 DNN 模型的训练都是在 GPU 上完成的,根据可用 GPU 的内存,拟合小批量大小可能会出现问题。正如我们所说,因为小批量会导致收敛速度慢,所以我们可以使用三种主要方法来增加有效批量大小:
-
使用多个小型 GPU 在小批量上并行运行模型 — DP 或 DDP 算法 -
使用更大的 GPU(昂贵) -
通过多个步骤累积梯度
现在让我们更详细地了解 1. 和 3. — 如果您幸运地拥有一个大型 GPU,可以在其上容纳所需的所有数据,您可以阅读 DDP 部分,并在完整代码部分中查看它是如何在 PyTorch 中实现的,从而跳过其余部分。
假设我们希望有效批量大小为 30,但每个 GPU 上只能容纳 10 个数据点(小批量大小)。我们有两种选择:数据并行或分布式数据并行:
数据并行性 (DP)
首先,我们定义主 GPU。然后,我们执行以下步骤:
-
将 10 个数据点(小批量)和模型的副本从主 GPU 移动到其他 2 个 GPU -
在每个 GPU 上进行前向传递并将输出传递给主 GPU -
在主 GPU 上计算总损失,然后将损失发送回每个 GPU 以计算参数的梯度 -
将梯度发送回Master GPU(这些是所有训练示例的梯度平均值),将它们相加得到整批30个的平均梯度 -
更新主 GPU 上的参数并将这些更新发送到其他 2 个 GPU 以进行下一次迭代
这个过程存在一些问题和低效率:
-
数据-从主 GPU 传递,然后在其他 GPU 之间分配。此外,主 GPU 的利用率高于其他 GPU,因为总损失的计算和参数更新发生在主 GPU 上 -
我们需要在每次迭代时同步其他 GPU 上的模型,这会减慢训练速度
分布式数据并行 (DDP)
引入分布式数据并行是为了改善数据并行算法的低效率。我们仍然采用与之前相同的设置 — 每批 30 个数据点,使用 3 个 GPU。差异如下:
-
它没有主 GPU -
因为我们不再拥有主 GPU,所以我们直接从磁盘/RAM 以非重叠方式并行加载每个 GPU 上的数据 — DistributedSampler 为我们完成这项工作。在底层,它使用本地等级 (GPU id) 在 GPU 之间分配数据 - 给定 30 个数据点,第一个 GPU 将使用点 [0, 3, 6, ... , 27],第二个 GPU [1, 4, 7, .., 28] 和第三个 GPU [2, 5, 8, .. , 29]
n_gpu = 3
for i in range(n_gpu):
print(np.arange(30)[i:30:n_gpu])
-
前向传递、损失计算和后向传递在每个 GPU 上独立执行,异步减少梯度计算平均值,然后在所有 GPU 上进行更新
由于DDP相对于DP的优点,目前优先使用DDP,因此我们只展示DDP的实现。
梯度累积
如果我们只有一个 GPU 但仍想使用更大的批量大小,另一种选择是累积一定数量的步骤的梯度,有效地累积一定数量的小批量的梯度,从而增加有效的批量大小。从上面的例子中,我们可以通过 3 次迭代累积 10 个数据点的梯度,以达到与我们在有效批量大小为 30 的 DDP 训练中描述的结果相同的结果。
DDP流程代码
下面我将仅介绍与 1 GPU 代码相比实现 DDP 时的差异。完整的代码可以在下面的一些部分找到。首先我们初始化进程组,允许不同进程之间进行通信。使用 int(os.environ[“LOCAL_RANK”]) 我们检索给定进程中使用的 GPU。
init_process_group(backend="nccl")
device = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(device)
然后,我们需要将模型包装在 DistributedDataParallel 中,以支持多 GPU 训练。
model = NeuralNetwork(args.data_size)
model = model.to(device)
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[device])
最后一部分是定义我在 DDP 部分中提到的 DistributedSampler。
sampler = torch.utils.data.DistributedSampler(dataset)
培训的其余部分保持不变 - 我将在本文末尾包含完整的代码。
梯度累积代码
当反向传播发生时,在我们调用 loss.backward() 后,梯度将存储在各自的张量中。实际的更新发生在调用 optimizationr.step() 时,然后使用 optimizationr.zero_grad() 将张量中存储的梯度设置为零,以运行反向传播和参数更新的下一次迭代。
因此,为了累积梯度,我们调用 loss.backward() 来获取我们需要的梯度累积数量,而不将梯度设置为零,以便它们在多次迭代中累积,然后我们对它们进行平均以获得累积梯度迭代中的平均梯度(loss = loss/ACC_STEPS)。之后我们调用optimizer.step()并将梯度归零以开始下一次梯度累积。在代码中:
ACC_STEPS = dist.get_world_size() # == number of GPUs
# iterate through the data
for i, (idxs, row) in enumerate(loader):
loss = model(row)
# scale loss according to accumulation steps
loss = loss/ACC_STEPS
loss.backward()
# keep accumualting gradients for ACC_STEPS
if ((i + 1) % ACC_STEPS == 0):
optimizer.step()
optimizer.zero_grad()
代码
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
print(os.environ["CUDA_VISIBLE_DEVICES"])
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset, Sampler
import argparse
import torch.optim as optim
import numpy as np
import random
import torch.backends.cudnn as cudnn
import torch.nn.functional as F
from torch.distributed import init_process_group
import torch.distributed as dist
class data_set(Dataset):
def __init__(self, df):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, index):
sample = self.df[index]
return index, sample
class NeuralNetwork(nn.Module):
def __init__(self, dsize):
super().__init__()
self.linear = nn.Linear(dsize, 1, bias=False)
self.linear.weight.data[:] = 1.
def forward(self, x):
x = self.linear(x)
loss = x.sum()
return loss
class DummySampler(Sampler):
def __init__(self, data, batch_size, n_gpus=2):
self.num_samples = len(data)
self.b_size = batch_size
self.n_gpus = n_gpus
def __iter__(self):
ids = []
for i in range(0, self.num_samples, self.b_size * self.n_gpus):
ids.append(np.arange(self.num_samples)[i: i + self.b_size*self.n_gpus :self.n_gpus])
ids.append(np.arange(self.num_samples)[i+1: (i+1) + self.b_size*self.n_gpus :self.n_gpus])
return iter(np.concatenate(ids))
def __len__(self):
# print ('\tcalling Sampler:__len__')
return self.num_samples
def main(args=None):
d_size = args.data_size
if args.distributed:
init_process_group(backend="nccl")
device = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(device)
else:
device = "cuda:0"
# fix the seed for reproducibility
seed = args.seed
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
cudnn.benchmark = True
# generate data
data = torch.rand(d_size, d_size)
model = NeuralNetwork(args.data_size)
model = model.to(device)
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[device])
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
dataset = data_set(data)
if args.distributed:
sampler = torch.utils.data.DistributedSampler(dataset, shuffle=False)
else:
# we define `DummySampler` for exact reproducibility with `DistributedSampler`
# which splits the data as described in the article.
sampler = DummySampler(dataset, args.batch_size)
loader = DataLoader(
dataset,
batch_size=args.batch_size,
num_workers=0,
pin_memory=True,
sampler=sampler,
shuffle=False,
collate_fn=None,
)
if not args.distributed:
grads = []
# ACC_STEPS same as GPU as we need to divide the loss by this number
# to obtain the same gradient as from multiple GPUs that are
# averaged together
ACC_STEPS = args.acc_steps
optimizer.zero_grad()
for epoch in range(args.epochs):
if args.distributed:
loader.sampler.set_epoch(epoch)
for i, (idxs, row) in enumerate(loader):
if args.distributed:
optimizer.zero_grad()
row = row.to(device, non_blocking=True)
if args.distributed:
rank = dist.get_rank() == 0
else:
rank = True
loss = model(row)
if args.distributed:
# does average gradients automatically thanks to model wrapper into
# `DistributedDataParallel`
loss.backward()
else:
# scale loss according to accumulation steps
loss = loss/ACC_STEPS
loss.backward()
if i == 0 and rank:
print(f"Epoch {epoch} {100 * '='}")
if not args.distributed:
if (i + 1) % ACC_STEPS == 0: # only step when we have done ACC_STEPS
# acumulate grads for entire epoch
optimizer.step()
optimizer.zero_grad()
else:
optimizer.step()
if not args.distributed and args.verbose:
print(100 * "=")
print("Model weights : ", model.linear.weight)
print(100 * "=")
elif args.distributed and args.verbose and rank:
print(100 * "=")
print("Model weights : ", model.module.linear.weight)
print(100 * "=")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--distributed', action='store_true',)
parser.add_argument('--seed', default=0, type=int)
parser.add_argument('--epochs', default=2, type=int)
parser.add_argument('--batch_size', default=4, type=int)
parser.add_argument('--data_size', default=16, type=int)
parser.add_argument('--acc_steps', default=3, type=int)
parser.add_argument('--verbose', action='store_true',)
args = parser.parse_args()
print(args)
main(args)
总结
在本文中,我们简要介绍并直观地介绍了 DP、DDP 算法和梯度累积,并展示了如何在没有多个 GPU 的情况下增加有效批量大小。需要注意的一件重要事情是,即使我们获得相同的最终结果,使用多个 GPU 进行训练也比使用梯度累积要快得多,因此如果训练速度很重要,那么使用多个 GPU 是加速训练的唯一方法。
Reference
Source: https://towardsdatascience.com/multiple-gpu-training-in-pytorch-and-gradient-accumulation-as-an-alternative-to-it-e578b3fc5b91
本文由 mdnice 多平台发布
相关文章:

PyTorch 中的多 GPU 训练和梯度累积作为替代方案
动动发财的小手,点个赞吧! 在本文[1]中,我们将首先了解数据并行(DP)和分布式数据并行(DDP)算法之间的差异,然后我们将解释什么是梯度累积(GA),最后…...

Appium+python自动化(三十五)- 命令启动appium之 appium服务命令行参数(超详解)
简介 前边介绍的都是通过按钮点击启动按钮来启动appium服务,有的小伙伴或者童鞋们乍一听可能不信,或者会问如何通过命令行启动appium服务呢?且听一一道来。 一睹为快 其实相当的简单,不看不知道,一看吓一跳…...
vmware的window中安装GNS3
1.向vmware中的windows虚拟机传送文件 点击虚拟机-安装VMwaretools 安装在虚拟机上面 此图标代表已经成功,将文件复制到虚拟机上里面 2.安装 安装gns3,需要先安装winpcap(检查网卡)和wireshark(对winpcap上数据进行抓…...

FPGA XDMA 中断模式实现 PCIE3.0 AD7606采集 提供2套工程源码和QT上位机源码
目录 1、前言2、我已有的PCIE方案3、PCIE理论4、总体设计思路和方案AD7606数据采集和缓存XDMA简介XDMA中断模式QT上位机及其源码 5、vivado工程1--BRAM缓存6、vivado工程2--DDR4缓存7、上板调试验证8、福利:工程代码的获取 1、前言 PCIE(PCI Express&am…...
某某大学某学院后台Phar反序列化GetShell
觉得这个洞还算有点意思,可以记录一下 首先在另一个二级学院进行目录扫描时发现源码www.rar,并且通过一些页面测试推测这两个二级学院应该是使用了同一套CMS 分析源码,发现使用的是ThinkPHP 5.1.34 LTS框架 通过APP、Public得到后台访问路径…...

【ChatGPT辅助学Rust | 基础系列 | 基础语法】变量,数据类型,运算符,控制流
文章目录 简介:一,变量1,变量的定义2,变量的可变性3,变量的隐藏 二、数据类型1,标量类型2,复合类型 三,运算符1,算术运算符2,比较运算符3,逻辑运算…...
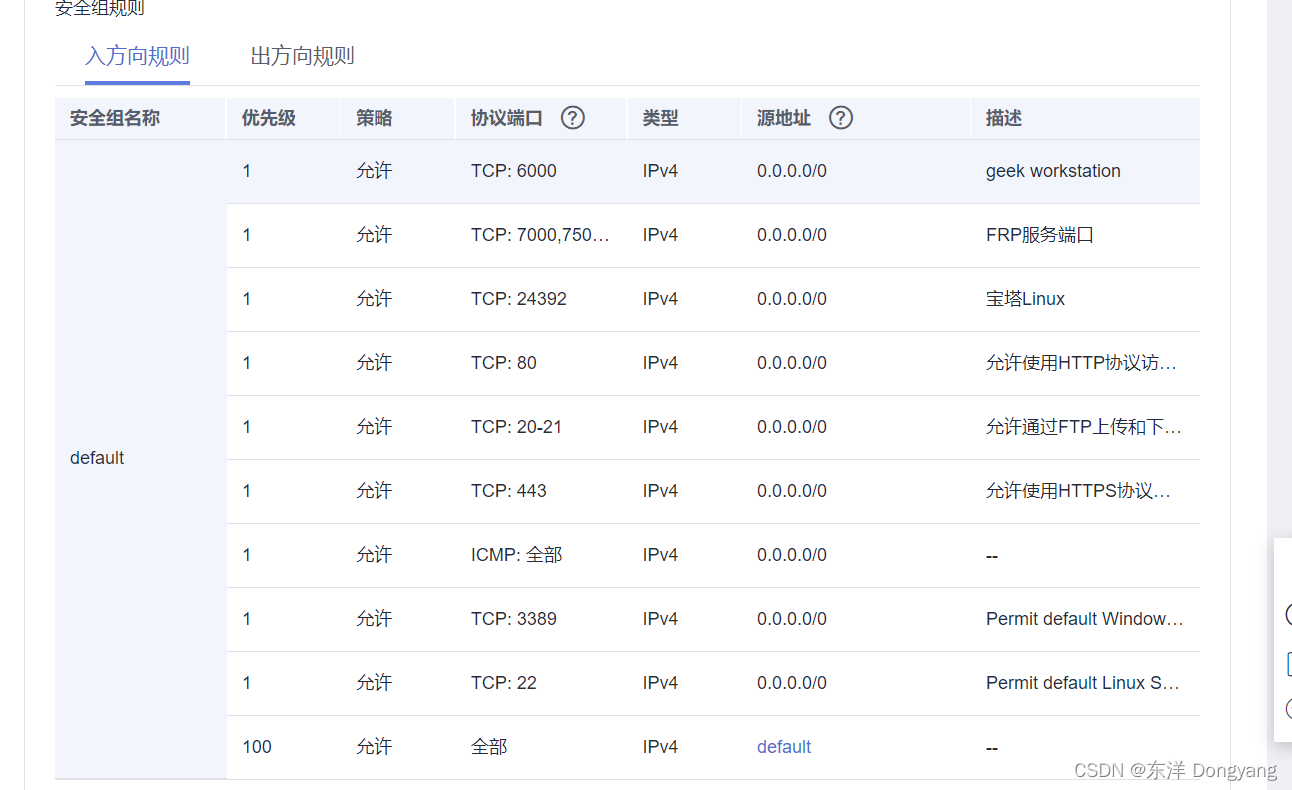
使用云服务器和Frp(快速反向代理)框架快速部署实现内网穿透
目录 一. 背景1.1 内网穿透1.2 Frp介绍1.3 Frp配置流程 二. 云服务器配置2.1 配置安全组2.2 编写frps.ini 三. 内网主机配置3.1 编辑frpc.ini文件3.2 启动服务并配置开机自启动 四. 参考文献 一. 背景 现在有一台ubuntu云服务器,我想通过内网穿透将一台内网的主机当…...

Mac 上使用 Tesseract OCR 识别图片文本
Tesseract OCR 引擎:Tesseract是一个开源的OCR引擎,你需要先安装它。可以从Tesseract官方网站(https://github.com/tesseract-ocr/tesseract)下载适用于你的操作系统的安装程序或源代码,并按照官方文档进行安装。 Tes…...

《MapboxGL 基础知识点》- 放大/缩小/定位/级别
中心点 getCenter:获取中心点 const {lng, lat} map.getCenter(); setCenter:设置中心点 // lng, lat map.setCenter([134, 28]); 缩放级别 getZoom:获取当前缩放级别 map.getZoom(); setZoom:设置缩放级别 map.setZoom(5…...

VScode的简单使用
一、VScode的安装 Visual Studio Code简称VS Code,是一款跨平台的、免费且开源的现代轻量级代码编辑器,支持几乎主流开发语言的语法高亮、智能代码补全、自定义快捷键、括号匹配和颜色区分、代码片段提示、代码对比等特性,也拥有对git的开箱…...

# Unity 如何获取Texture 的内存大小
Unity 如何获取Texture 的内存大小 在Unity中,要获取Texture的内存文件大小,可以使用UnityEditor.TextureUtil类中的一些函数。这些函数提供了获取存储内存大小和运行时内存大小的方法。由于UnityEditor.TextureUtil是一个内部类,我们需要使…...
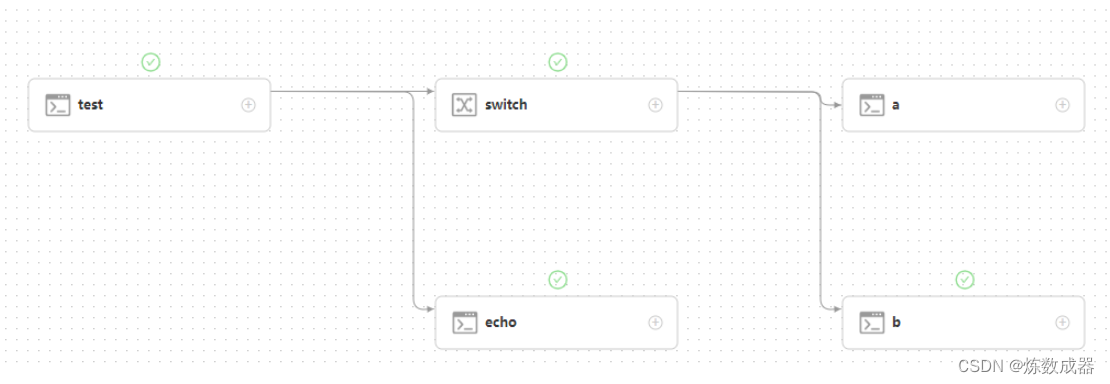
dolphinscheduler switch+传参无坑版
dolphinscheduler 的前后传参有较多的坑,即便是3.0.5版本仍然有一些bug 下面是目前能无坑在3.0.5版本上使用的操作 前置任务 在界面上设置变量和参数名称 跟官方网站不一样,注意最后一行一定使用echo ${setValue(key$query)}的方式,注意引…...

VINS-fusion安装
VINS-fusion中用的opencv3,如果安装的opencv4要做一系列替换 VINS-Mono在opencv4环境下的安装问题和解决方法 https://zhuanlan.zhihu.com/p/548140724 Vins-Fusion安装记录 https://zhuanlan.zhihu.com/p/432167383 CV_FONT_HERSHEY_SIMPLEX -> cv::FONT_HER…...
智慧消防:如何基于视频与智能分析技术搭建可视化风险预警平台?
一、背景分析 消防安全是一个重要的话题,涉及到每个人的生活和安全。每年都会发生大量的火灾,给人们带来极大的危害,摧毁了大量的财产,甚至造成了可怕的人员伤亡。而消防安全监督管理部门人员有限,消防安全监管缺乏有…...

selenium定位元素的方法
Selenium可以驱动浏览器完成各种操作,比如模拟点击等。要想操作一个元素,首先应该识别这个元素。人有各种的特征(属性),我们可以通过其特征找到人,如通过身份证号、姓名、家庭住址。同理,一个元…...

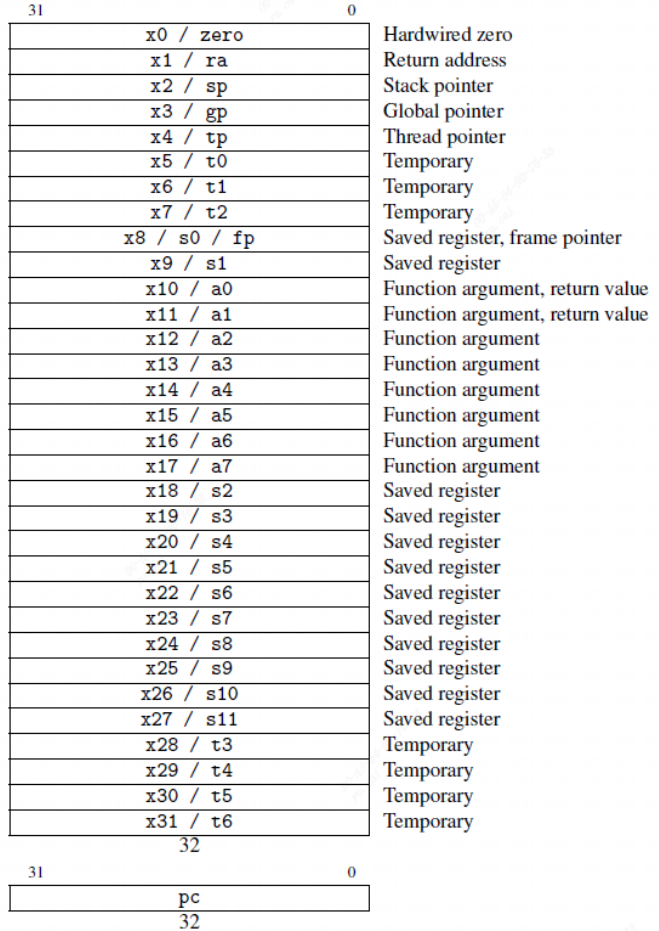
RISC-V特权级别
特权级别 RISC-V共有6个特权级别: 机器模式(M模式) M模式全称为Machine mode(机器模式)运行在这个模式下的程序为最高权限,它属于RISC-V里的最高权限模式,它具有访问所有资源的权限ÿ…...
RISC-V 指令集介绍
1. 背景介绍 指令集从本质上可以分为复杂指令集(Complex Instruction Set Computer,CISC)和精简指令集(Reduced Instruction Set Computer,RISC)两种。复杂指令集的特点是能够在一条指令内完成很多事情。 指…...

操作系统5
设备管理 I/O设备 什么是?--- 将数据Input/Output(输入/输出)计算机的外部设备。 分类: 按使用特性:人机交互类外设、存储设备、网络通信设备; 按传输速度:低速、中速、高速设备࿱…...

K8S系列文章之 Docker常用命令
一、镜像基础命令: $ docker info # 查看docker信息 $ docker system df # 查看镜像/容器/数据卷所占的空间。 $ ip addr #查看容器内部网络地址。 $ docker images # 查看镜像 $ docker search 镜像名称 # 搜索镜像 --limit :只列出N个镜像,默认为25个…...

谷歌: 安卓补丁漏洞让 N-days 与 0-days 同样危险
近日,谷歌发布了年度零日漏洞报告,展示了 2022 年的野外漏洞统计数据,并强调了 Android 平台中长期存在的问题,该问题在很长一段时间内提高了已披露漏洞的价值和使用。 更具体地说,谷歌的报告强调了安卓系统中的 &quo…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

观察 Taotoken 在多地域请求下的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在多地域请求下的延迟与稳定性表现 对于依赖大模型 API 进行开发的团队而言,服务的延迟与稳定性是影响开…...
)
别再依赖SDK了!手把手教你用OpenCV和Eigen从零实现RGB-D相机对齐(附完整C++代码)
从零实现RGB-D相机对齐:OpenCV与Eigen实战指南 在计算机视觉领域,RGB-D相机的深度与彩色图像对齐(D2C)是一个基础但至关重要的技术环节。虽然市面上大多数商用RGB-D相机都提供了现成的SDK和API来实现这一功能,但对于真…...

终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题
终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为学术论文翻译后排版全乱而烦恼吗?😫 技术文档翻…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...

Claw框架数据库迁移工具claw-migrate:原理、实践与团队协作指南
1. 项目概述:一个专为Claw设计的迁移工具最近在折腾一个叫Claw的开源项目,它本身是一个轻量级的Web框架,用起来挺顺手。但项目迭代过程中,难免会遇到数据库结构变更、数据迁移这类“脏活累活”。手动写SQL脚本?太原始&…...

【仿真学习框架】HoloMotion 从入门到精通:全身人形控制 Foundation Model 完全指南
HoloMotion 从入门到精通:全身人形控制 Foundation Model 完全指南 目标读者:具身智能研究者、人形机器人开发者、RL/机器人学习工程师 目录 第1章 HoloMotion 全景概览 1.1 什么是 HoloMotion 1.2 技术定位:"小脑"基座模型 1.3 4-Any 愿景与路线图 1.4 核心能力矩…...

AXI Crossbar设计解析:从总线互联原理到SoC集成实战
1. 项目概述:AXI Crossbar,不仅仅是“总线交叉开关”在复杂的数字系统设计,尤其是SoC(片上系统)和FPGA应用中,我们常常面临一个核心问题:多个主设备(Master,如CPU、DMA控…...

氛围驱动开发:数据化提升开发者效率与团队协作的实践指南
1. 项目概述:当开发节奏遇上“氛围感”最近在GitHub上看到一个挺有意思的项目,叫“vibe-driven-dev”。光看名字,你可能会有点摸不着头脑——“氛围驱动开发”?这听起来不像是一个传统的技术框架或工具库。没错,它确实…...

基于声明式Web自动化框架Hydra的电商数据监控实战
1. 项目概述:一个被低估的自动化利器 如果你经常需要处理一些重复性的、基于Web界面的操作,比如批量下载某个网站的资源、定时填写表单、或者监控网页内容的变化,那么你很可能已经厌倦了手动点击和等待。传统的脚本编写,尤其是涉及…...