滴滴数据服务体系建设实践
什么是数据服务化
大数据开发的主要流程分为数据集成、数据开发、数据生产和数据回流四个阶段。数据集成打通了业务系统数据进入大数据环境的通道,通常包含周期性导入离线表、实时采集并清洗导入离线表和实时写入对应数据源三种方式,当前滴滴内部同步中心平台已经提供了MySQL、Oracle、MongoDB、Publiclog等多种数据源的数据采集能力;数据开发/生产,用户可以构建实时、离线两种数据仓库,并基于SQL、Native、Shell等多种任务方式下的数据建模;数据回流通过将离线数据导入OLAP、RDBMS等,以提升访问性能,下游服务直接访问该数据源进行数据分析、数据可视化。
滴滴内部的数据梦工厂,就是提供一站式数据开发、生产的解决方案,核心关注的是数据开发、生产环节中的效率、安全和稳定性。
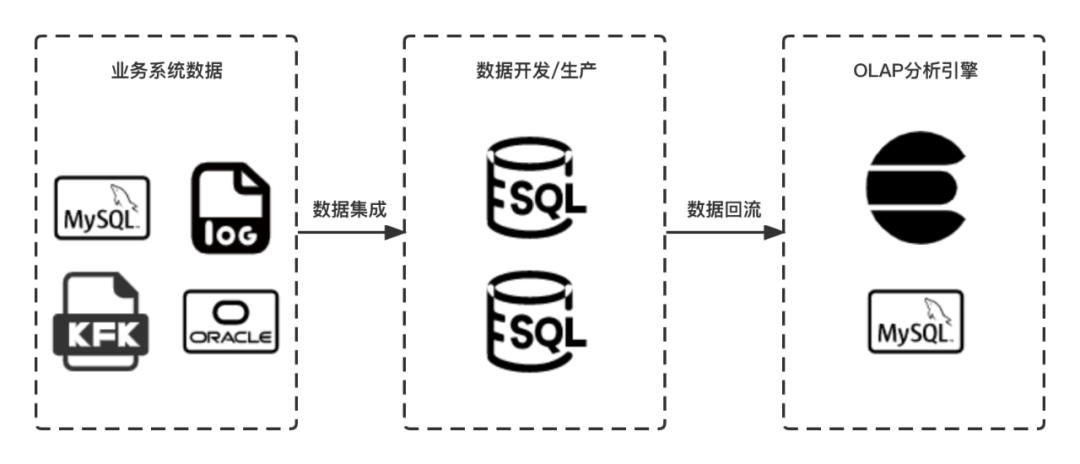
数据开发流程
为了体系地将数据交付用户,我们构建的是一站式的数据消费平台,包含了数易、数据智能问答机器人、异动分析等通用数据消费产品,和横向沉淀的内容产品北极星、集团展厅。一站式消费平台需要通过查询结构化、标准化的数据来提供可视化、分析能力。从数据消费产品的技术架构中,对查询性能有一定要求,会根据查询的方式回流到合适的多维分析存储引擎,最为常见的是MySQL、ClickHouse、Druid和StarRocks。因此,对多维分析存储引擎的查询收口、扩展计算能力扩展、性能优化实施和查询稳定性保障等,对于消费类数据产品来说都是公共、通用能力。
此外,对于其他个性化数据产品、运营平台、B端/C端产品来说,都是亟需的数据访问能力。这也是数据中台建设,对于数据访问能力统一化的核心问题:数据服务化能力。
对于该项能力建设,我们也不是一蹴而就的,主要分为三个阶段。
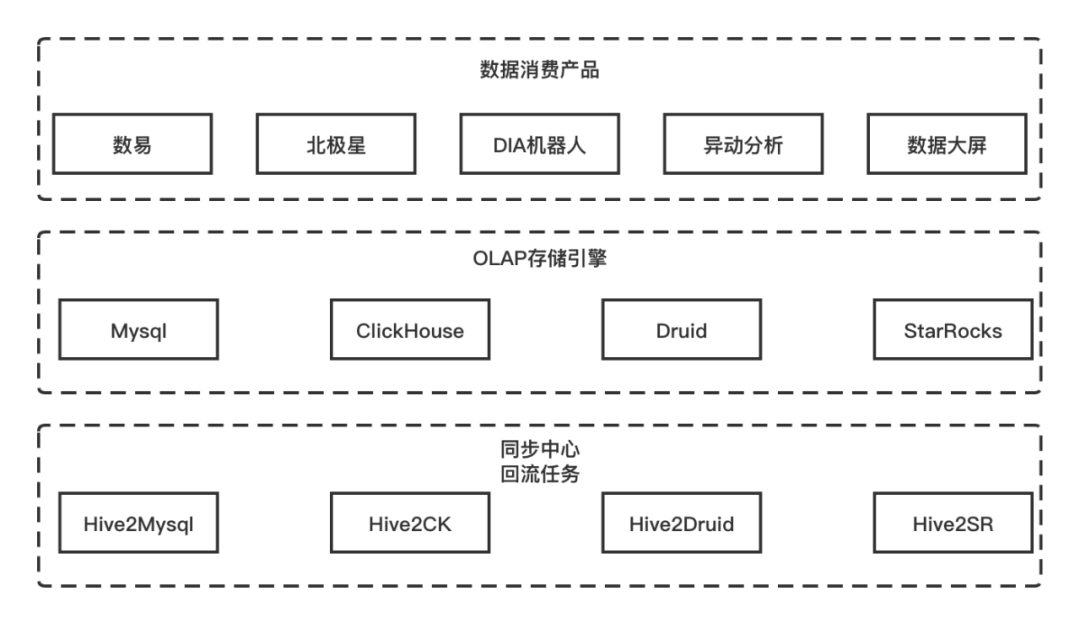
数据消费产品技术架构示意
阶段一:
建设同步中心数据回流能力
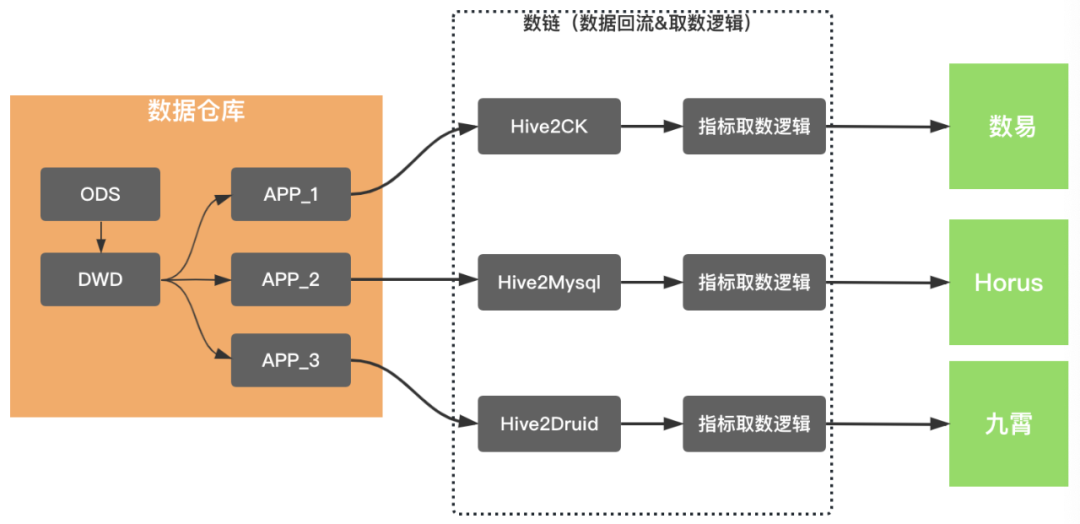
2019年滴滴发起了数据体系2.0建设,作为核心产出的数据梦工厂,其第一阶段目标是建设一站式的数据开发、生产平台,关键节点以同步中心的一站式建设完毕为里程碑。同步中心通过自动化流程的建设,结束了通过提工单的方式,来人工构建数据源间同步任务的历史,其核心产出是数据进入Hive链路的自主管理能力建设。另外,我们新建了Hive回流到MySQL、ClickHouse、Druid、Hbase和ES链路,使得数据回流完成平台化建设。
基于数据回流实现的数据服务化能力,使得服务分、北极星和数易等相关场景得以系统化覆盖。核心解决了业务直接访问大数据环境的性能问题,以数易为例,通过数据回流到ClickHouse,使数据查询性能P90从5s下降到2s以内,这样的性能提升使数易的用户体验有质的提升。这个阶段的数据产品的基本架构,尤其是查询侧,类似于下图所示,都抽象出来了数据回流和取数逻辑两个模块。
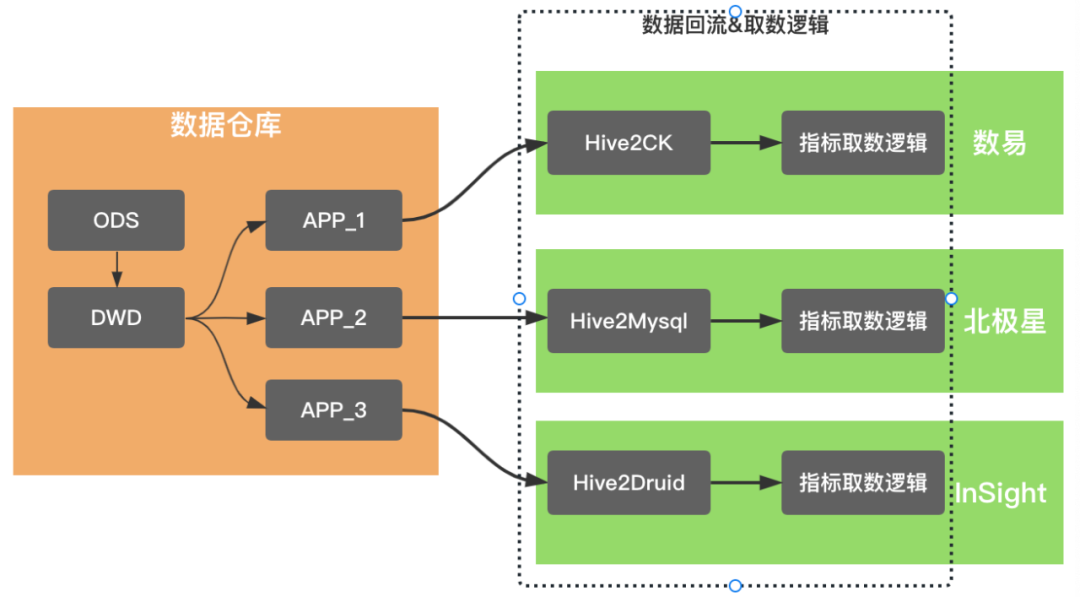
数据回流实现数据导出到多维分析存储引擎,并沉淀有任务的管理和运维能力,这些数据产品均深度打通了数据梦工厂,基于数据梦工厂强大的离线任务运维能力保障数据的产出。取数逻辑维护着具体的查询逻辑,除了北极星,其他两款产品均衍生出了基于查询抽象的中间件,例如InSight的QE(QueryEngine)、数易的查询中心。数据回流和取数逻辑,是数据产品的核心能力,也是建设成本极高的模块。所以,这个阶段,类似于数据智能问答机器人、数据门户、复杂表格等产品,采用了基于数易数据集的查询、加速能力,以快速验证产品。
阶段二:
建设数链平台,统一数据服务化
阶段一提供了数据回流在线存储能力,提升了相关系统调用性能,为数据产品发展做出了阶段性贡献。随着业务发展,数据表数量提升,取数逻辑隔离沉淀在不同系统问题凸显出来,管理成本不断提升。为了提升取数性能,除了加速到多维分析存储引擎之外,还需要对数据进行高度聚合,构建数据量较少的APP层。APP层表和业务需求有着强相关性,因此,需求的变化常常导致需要变更APP表支持业务。阶段一中,取数逻辑场景散落在不同的系统内部,APP表变更将是比较大的工作量,包含了不同看板的数据源切换,看板质量的再次验收,过程十分繁杂。
数据回流和取数逻辑在不同的数据产品内进行重复建设,也增加了数据产品构建的效率。为了提升效率,内部产品基本都依赖数易数据集进行建设,例如数据智能问答机器人、复杂表格。
但这不是最优的解决方案,问题主要体现在:
基于数易数据集,加速、限流、隔离等措施建设都非常复杂、庞杂。尤其,数易数据集加速方式分成一级的SQL任务加速、二级ClickHouse加速,形式固化。
数易的查询都是基于MPP建设,对于相对高的并发查询、点查很难支撑。
运维保障能力较弱,加速任务都由平台代持,用户感知较弱,且无法运维。
数易数据集是数易的强依赖,剥离建设服务化能力难度较大,当时对于数易来说也不是第一优先级考虑的事情。
综上所述,构建一个统一的数据服务化平台,有着较强的业务收益。从2021年初开始,数链平台应运而生,其基本思路在于对加速链路、查询逻辑进行统一管理,并提供统一、完备的查询网关。
数链的基本能力在于:
多样化的数据源:支持ES、MySQL、ClickHouse、Hbase、Druid等数据源的访问;
多场景的数据访问:支持key/value键值对的高并发查询、支持复杂的多维分析和支持数据下载能力;
统一的接入标准:统一的访问网关、统一数据访问协议、统一的数据运维和统一的API管理能力;
数据安全管控:支持对敏感数据访问的审计,数据下载外发管控能力。
数链平台构建之后,数据API构建时间从天级别下降到分钟级别,实现了白屏化API建设能力。当前,数链的API数量已经超过4000,周活API数量也超过了1600,服务了200多个应用,覆盖了所有的业务线,达成既定建设目标。
阶段三:
建设数链标准指标服务化
通过阶段二的平台建设,收益的数据产品主要是监控、看板、门户、运营系统和安全相关系统。这些系统主要看中数链构建API的效率,API业务逻辑的管理能力和API的运维能力。但是,数易、北极星等早期建设,有相关能力闭环的产品,很难找到接入数链的突破口,或者说收益很难看到。
当前,大数据中指标交付,长期通过Hive表和沉淀在指标管理工具的指标描述来交付,也就是说,数仓会提供给业务方一张Hive表,和描述性的取值逻辑。业务方通过Hive表构建看板、临时取数时,需要反复校验取数逻辑,效率比较低下。同时,同一个指标常常在北极星、数易等产品展示,最为尴尬的是常常出现数值的不一致,也就是指标消费的一致性问题凸显。
指标管理工具是根据指标管理方法论,构建的指标、维度元数据管理系统。为了录入指标、维度,数据团队花费非常大的成本。指标管理工具仅仅提供指标录入和检索能力,指标规范性建设只能依赖于自上而下的管理,无法有效自运转。对于指标一致性,只能是确保指标来自一个来源,并且交付方式不能是Hive表,而是指标本身,指标需要提供直接消费能力。
第二阶段服务化建设的困境,北极星、数易指标消费的二义性问题,以及指标管理工具的本身困局,标准指标服务化建设应运而生。基本思路如图所示,一个是指标管理工具提供模型管理,把指标和物理表进行关联,另外,就是数链提供统一的消费网关,让数易、北极星等数据产品打通这个消费渠道。
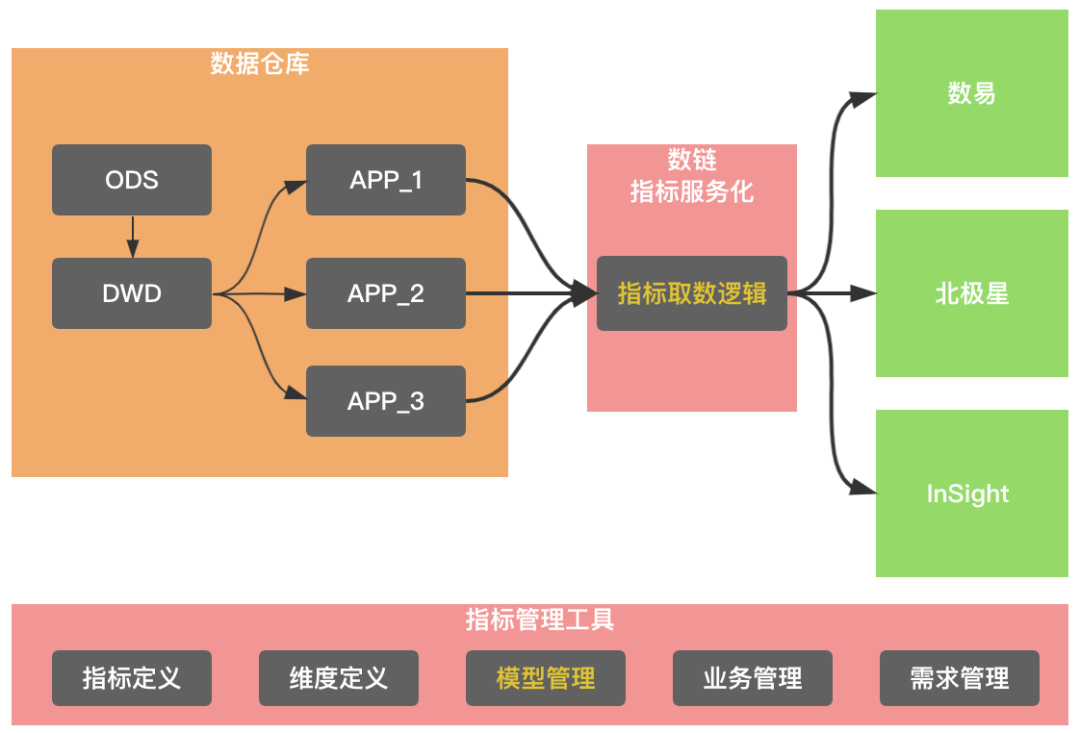
标准指标服务化建设,元数据管理需要扩展指标、维度的表达能力,并通过逻辑模型去关联指标、维度和具体物理表的具体字段。为了简化下游消费逻辑,标准指标服务化需要提供一定的自动化取数逻辑能力。通常一个指标会在不同的物理表中实现,通过不同物理表间指标实现的一致性校验,有效避免指标的二义性。
“
元数据管理
标准指标服务化最为关键的元数据:指标、维度和逻辑模型。下面依次进行介绍。
指标
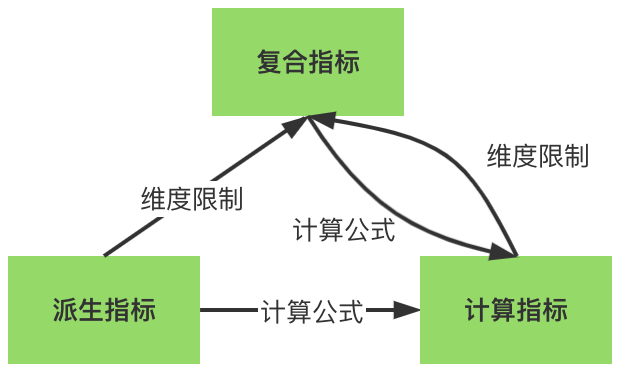
指标管理方法论主要介绍为了提升指标表达语义能力,引入的计算指标和复合指标。派生指标是指物理表(Hive/Starrocks/ClickHouse)开发后可以直接对外服务的指标,也就是一定物化在物理表上对应字段的指标。计算指标是根据已注册派生指标计算生成的指标,可以不物化到物理表上对应字段的指标,当前计算方式只支持加减乘除四则运算。例如,应答后取消率=应答后取消订单量/当日应答订单量。复合指标是指已注册派生复合维度生成的指标,可以不物化到物理表上对应字段的指标,例如,“网花出GMV”是根据指标“含openapi含扫码付GMV”,复合维度“订单聚合业务线”,维值为“网+出+花”生成的。如下图所示,复合指标和计算指标可以相互嵌套,当前复合指标在嵌套链中最多只能出现一次。
纬度
纬度类型,当前构建了四种:
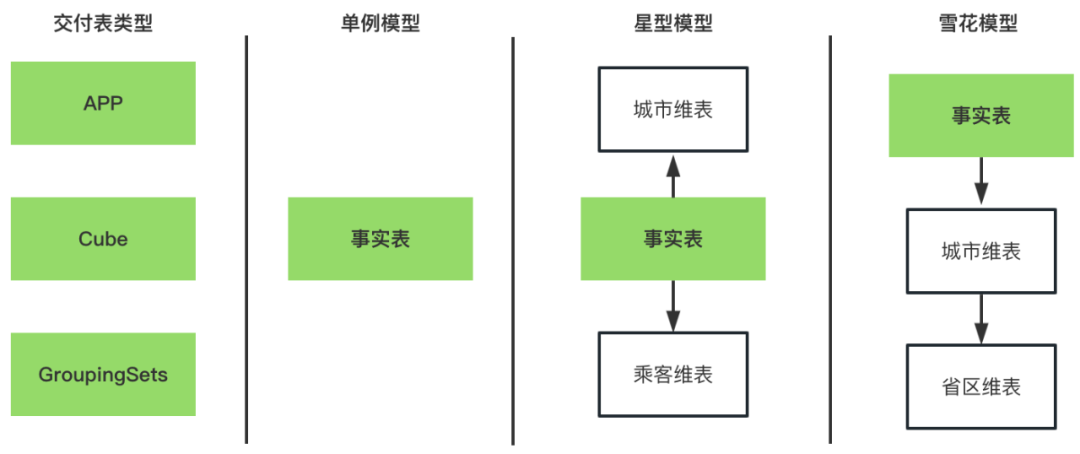
维表维度:独立的维表,维表会有唯一主键,以及其他属性信息。维表维度可以构建数仓的星形模型。如果还有存在外键,则可以构建多层维表依赖的雪花模型。例如,城市维表维度 whole_dw.dim_city。
枚举维度:key/value 键值对,键值对集中管理。例如:性别维度,对应的键值对男(M)/女(F)。
退化维度:维度逻辑无法集中管理,在不同物理表有着不同的实现,但表示的是同一个维度。例如,北极星的业务线维度,不同板块下的业务线id转换到北极星的业务线id有着不一样的转换逻辑,需要在具体实现中确定。
衍生维度:与退化维度不一样的情况,维度逻辑可以集中化管理,该逻辑是一段处理代码。
逻辑模型
逻辑模型在不同地方有不同的解读,指标管理工具中的逻辑模型是指标、维度和物理表绑定的载体。逻辑模型可以绑定派生指标、计算指标、复合指标三种指标,也可以绑定维表维度、枚举维度、衍生维度和退化维度四种维度。绑定到逻辑模型的指标、维度,可以直接绑定到物理表的字段,也可以绑定到根据物理表字段构建的计算字段。计算指标、复合指标还能根据计算逻辑或者复合逻辑,非物化的绑定。逻辑模型可以绑定多个指标、多个维度,反过来,一个指标、维度可以绑定到多个逻辑模型中。更通俗的说,一个指标的多种实现方式,是通过逻辑模型指定的。
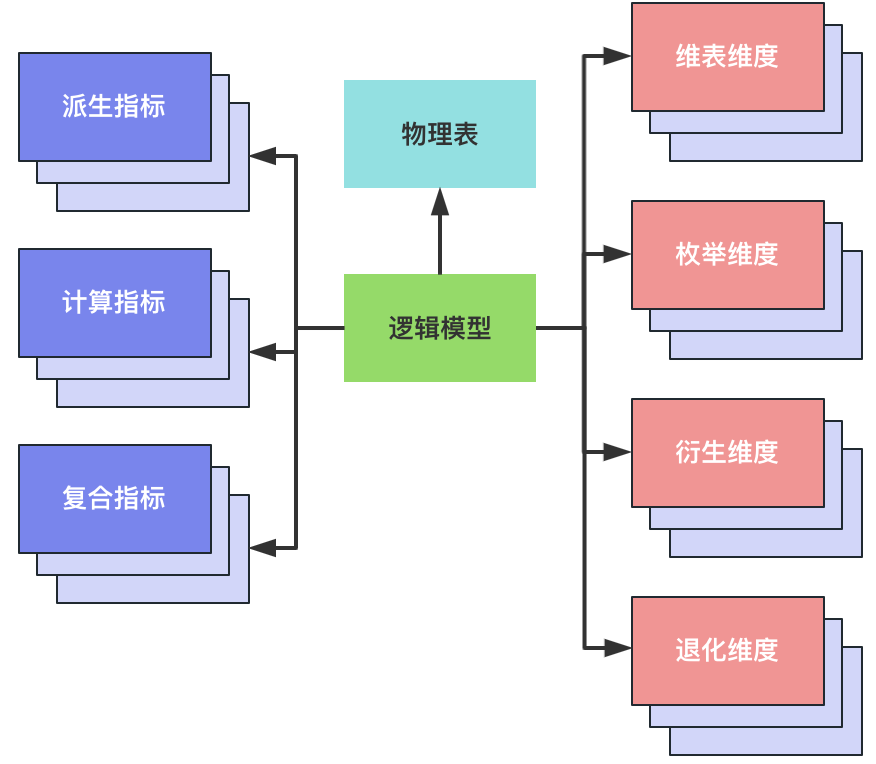
逻辑模型在指定物理表的时候,还对物理表的存储引擎、物理表的数据布局、数仓层级进行了指定。当前数链支持Hive、SR、ClickHouse三种存储引擎;数据布局支持一般APP表、Cube表和GroupingSets表;数仓层级支持APP、DM、DWS和DWD。
“
取数逻辑自动化
数链建设标准指标服务化中,取数逻辑自动化,一方面能实现集中管理(Single Source of Truth),另一方面也是提效过程。取数逻辑自动化,在标准指标服务化中主要体现在:
支持通过指标、维度取数,用户只需要提供所需要的指标和维度,通过取数接口获取数据。上面逻辑模型中提到,指标与逻辑模型是一对多关系。自动化的取数逻辑,会根据所需的指标、维度、分区范围,以及性能最佳的取数方式去选择合适的逻辑模型。需要重点指出的是,当计算指标依赖的派生指标只能通过不同的模型获取时,该取数过程支持通过联邦查询完成。
支持多种数据布局的表,当前已经支持一般APP表、Cube表和GroupingSets表。在取数中,已经屏蔽了不同数据布局的取数逻辑,用户无需关心原先表的数据布局方式。
支持多样的数仓建模模型,数仓建模规范产出中,可以是单例、星形和雪花模型。雪花和星形模型,自动化取数逻辑已经可以通过自动关联所需的维表,实现维表维度中的不同维度属性上卷等复杂的取数逻辑。
支持日、周、月、季粒度的上卷,在之前不同时间粒度的数据,只能通过开发不同的表实现。在查询性能有保障的情况下,现在可以实现时间粒度的上卷能力。
“
一致性校验
除了通过取数逻辑自动化实现取数提效之外,指标一致性也是数链建设标准指标服务化的核心出发点。指标一致性,一方面是通过统一的消费接口,另一方面,则是根据指标的实际现状,进行被动和自动的校验。
被动指标校验,由用户在平台配置所需要的进行校验的指标,如下图所示,像“最近一天全集团GMV”一样,可能在多个逻辑模型中实现。因此,校验逻辑是在几个逻辑模型产出后,进行一次周期性的校验。还有一种情况则是,“最近一天全集团GMV”,可以通过“最近一天网约车GMV”+“最近一天两轮车GMV”+“最近一天货运GMV”实现。因此,如下图所示,检验逻辑可以是左侧的逻辑模型_1和右侧的逻辑模型_1‘、逻辑模型_2’、逻辑模型_3‘产出后,进行一次周期性的校验。
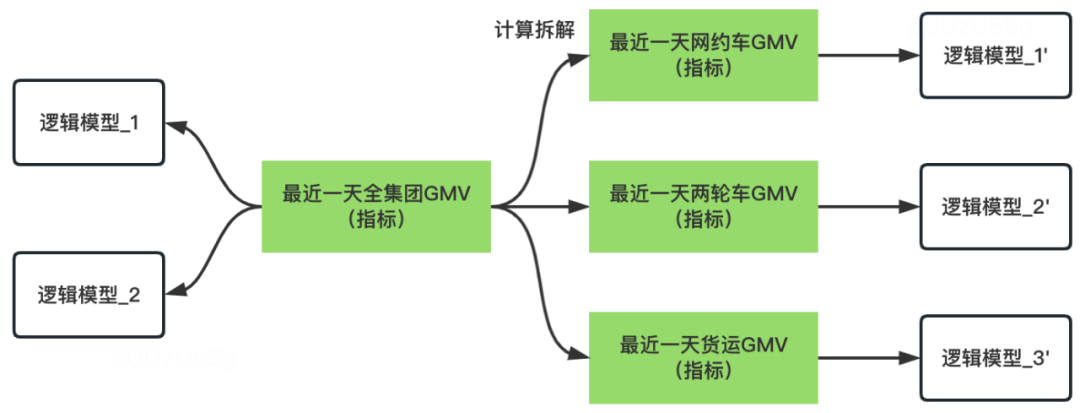
自动指标检验,检验的逻辑跟被动指标校验的区别在于,模型拆解方式由系统自动生成,另外,可以进行校验的指标也由系统筛选出来。
“
接入&查询流程
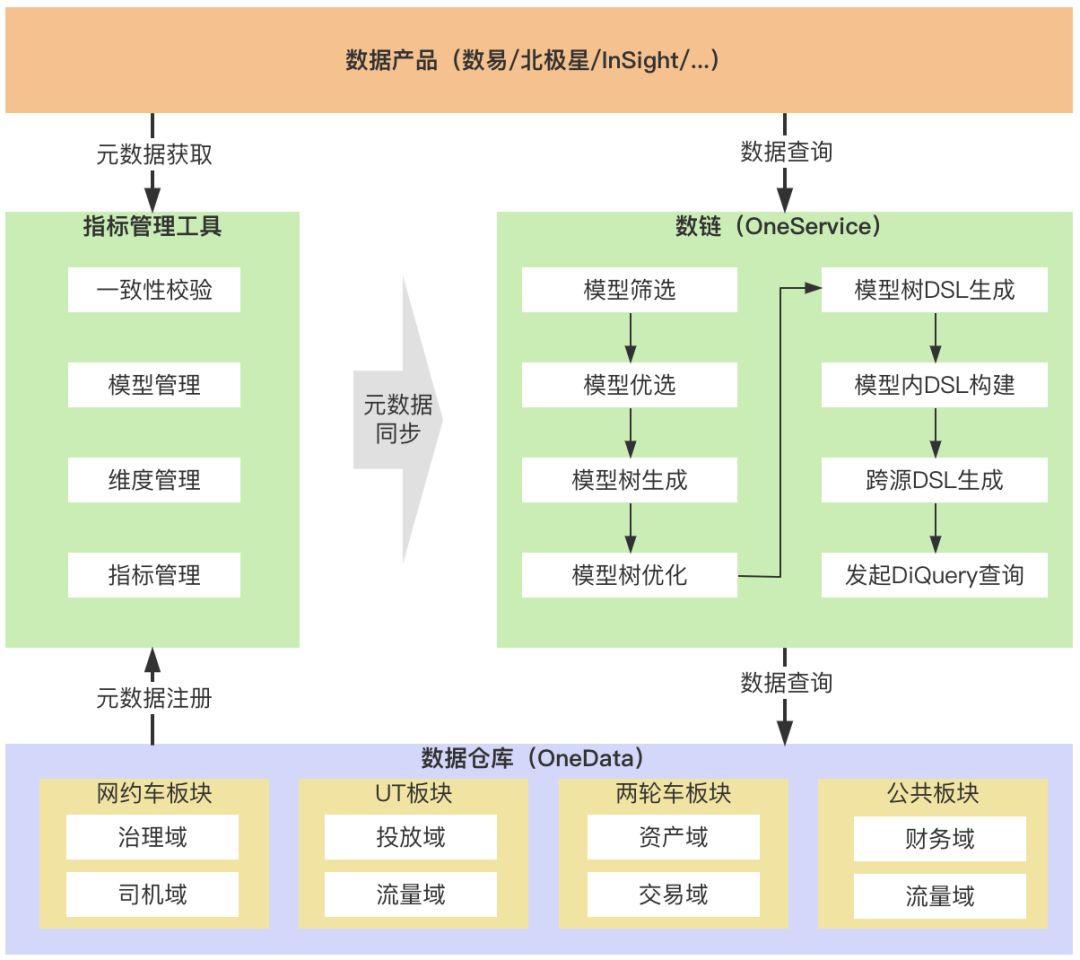
当下接入数链标准指标服务化的服务有北极星、数易和InSight,这三个产品也是滴滴最核心的数据产品。标准指标服务化在打通这三个产品的时候,都具备不同的挑战,具体会在其他同学分享的文章进行详述。这里只简单介绍下数据产品接入、查询的基本流程。
通常流程中,数据BP将会根据指标管理工具依次录入指标、维度,数据开发同学依据不同的数据架构方式构建数仓,并创建逻辑模型,和指标、维度进行关联绑定。管理好的元数据,会被实时同步到数链。
数易、北极星、InSight通过元数据接口,对报表、看板进行构建。发起数据查询时,请求将发送到数链,并经过模型筛选、优化,生成最终的执行SQL,查询的数据再返回数据产品侧。
数据服务体系整体架构
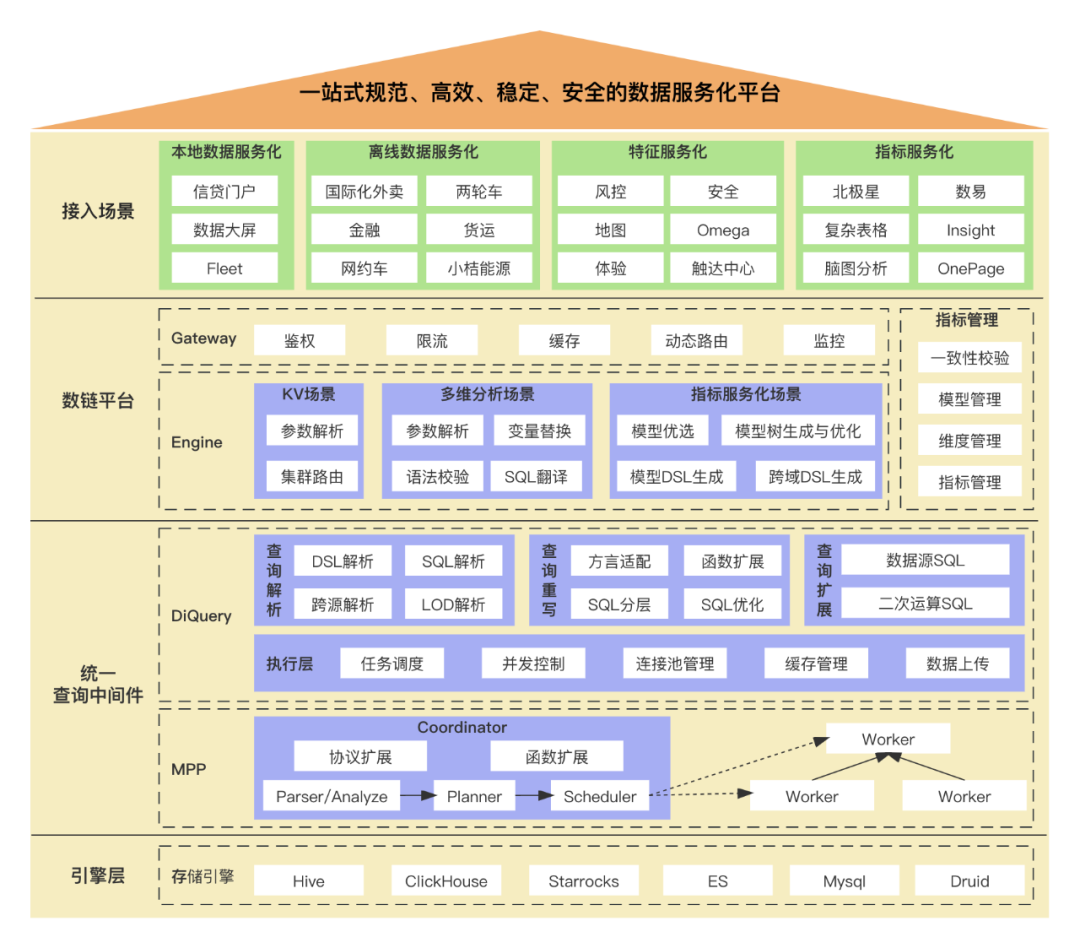
数链平台旨在打造一站式规范、高效、稳定和安全的数据服务化平台。当前服务的业务场景主要分为本地数据服务化、离线数据服务化、特征服务化和标准指标服务化。数链平台分为网关层和引擎层。网关实现的是统一的入口,并提供了鉴权、限流、缓存、路由、监控等能力。引擎层将实现场景分成了key/value键值对场景、多维分析场景和标准指标服务化场景。key/value键值对场景主要服务特征服务化,即牛盾、地图特征等业务场景。多维分析场景,主要服务于本地数据服务化和离线数据服务化,即Horus、九霄等业务场景。key/value键值对场景、多维分析场景是阶段二的核心能力,标准指标服务化场景则是阶段三的核心能力。
为了支撑多样、复杂的数据查询诉求,我们还建设了统一的查询中间件:DiQuery。DiQuery依托于MPP的强大查询能力,构建了统一的查询能力,服务于数链、数易等数据产品。DiQuery除了支持单表查询能力之外,还支持了联邦查询、LOD复杂函数查询能力。DiQuery支持同环比、四周均值等扩展函数,并支持在此基础上的上卷能力。
总结与展望
滴滴数据服务体系的发展,经历了原始的数据回流任务方式、统一数据服务化平台建设、标准指标服务化建设,一步步在建设更好的数据服务体系。标准指标服务化建设,是今年的重头戏,在数仓研发、产品和平台研发的鼎力协作中高速发展。
现在的数据服务体系,解耦了数据生产和数据消费的关系。接下来,需要推进数据生产的标准化,进一步解决指标一致性问题,提升数仓建设效率,并通过指标视角提升数据质量等等。标准指标服务化,将是一场一步步推进的数据平台重要演化,并在业界已经慢慢拉开帷幕。
相关文章:
滴滴数据服务体系建设实践
什么是数据服务化 大数据开发的主要流程分为数据集成、数据开发、数据生产和数据回流四个阶段。数据集成打通了业务系统数据进入大数据环境的通道,通常包含周期性导入离线表、实时采集并清洗导入离线表和实时写入对应数据源三种方式,当前滴滴内部同步中心…...

VBA技术资料MF36:VBA_在Excel中排序
【分享成果,随喜正能量】一个人的气质,并不在容颜和身材,而是所经历过的往事,是内在留下的印迹,令人深沉而安谧。所以,优雅是一种阅历的凝聚;淡然是一段人生的沉淀。时间会让一颗灵魂࿰…...

Shell脚本学习3
文章目录 Shell脚本学习3函数函数定义及使用函数参数获取函数返回值 重定向输入输出重定向 其他Here Document/dev/null 文件Shell文件包含获取当前正在执行脚本的绝对路径按特定字符串截取字符串 Shell脚本学习3 函数 函数定义及使用 函数可以让我们将一个复杂功能划分成若…...

代理模式--静态代理和动态代理
1.代理模式 定义:代理模式就是代替对象具备真实对象的功能,并代替真实对象完成相应的操作并且在不改变真实对象源代码的情况下扩展其功能,在某些情况下,⼀个对象不适合或者不能直接引⽤另⼀个对象,⽽代理对象可以在客户…...
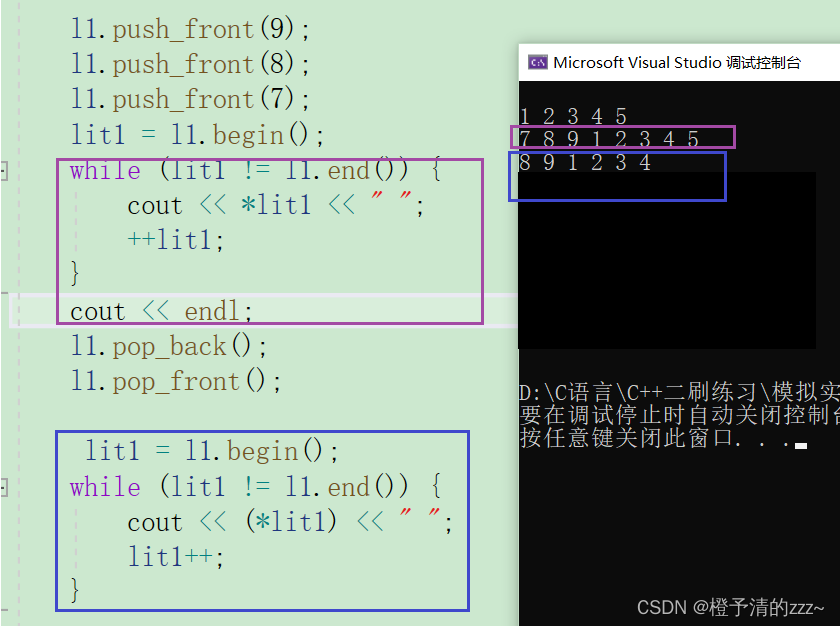
C++容器——list的模拟实现
目录 一.list的基本结构 二. 接下来就是对list类构造函数的设计了: 三.链表数据的增加: 四.接下来就是迭代器的创建了: 四.简单函数的实现: 五.构造与析构 六.拷贝构造和赋值重载 传统写法: 现代写法: 七.迭…...

VUE3 祖孙组件传值调用方法
1.在 Vue 3 中,你可以使用 provide/inject 来实现祖孙组件之间的传值和调用方法。 首先,在祖组件中使用 provide 来提供数据或方法,例如: // 祖组件 import { provide } from vue;export default {setup() {const data Hello;c…...

我的网安之路
机缘 我目前从事网安工作,一转眼我从发布的第一篇文章到现在已经过去了4年了,感慨时间过得很快 曾经我是一名Java开发工程师所以我的第一篇文章是跟开发相关的那个时候还是实习生被安排 一个很难的工作是完成地图实时定位以及根据GPS信息模拟海上追捕,这对刚入职的我来说很难 …...

langchain-ChatGLM源码阅读:webui.py
样式定制 使用gradio设置页面的视觉组件和交互逻辑 import gradio as gr import shutilfrom chains.local_doc_qa import LocalDocQA from configs.model_config import * import nltk import models.shared as shared from models.loader.args import parser from models.load…...

<C++>二、 类和对象
1.面向对象和面向过程 C语言是面向过程的,关注的是过程,分析出求解问题的步骤, 通过函数调用逐步解决问题。 C是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成。 2. C类 C…...

【HttpRunnerManager】搭建接口自动化测试平台实战
目录 一、需要准备的知识点 二、我搭建的环境 三、搭建过程 四、访问链接 五、两个问题点 【整整200集】超超超详细的Python接口自动化测试进阶教程,真实模拟企业项目实战!! 一、需要准备的知识点 1. linux: 安装 python3、nginx 安装和…...

【adb】adb常用命令
Android Debug Bridge (adb) Android 调试桥 (adb) 是一种功能多样的命令行工具,可让您与设备进行通信。adb 命令可用于执行各种设备操作,例如安装和调试应用。adb 提供对 Unix shell(可用来在设备上运行各种命令)的访问权限。它…...

SAP 委外副产品业务
SAP 委外副产品业务 1.订单bom设置数量为负 2.采购收货时,副产品O库存增加,545 O 借:原材料 贷:委外加工-发出材料 3.从O库存调拨回本地库存,542...
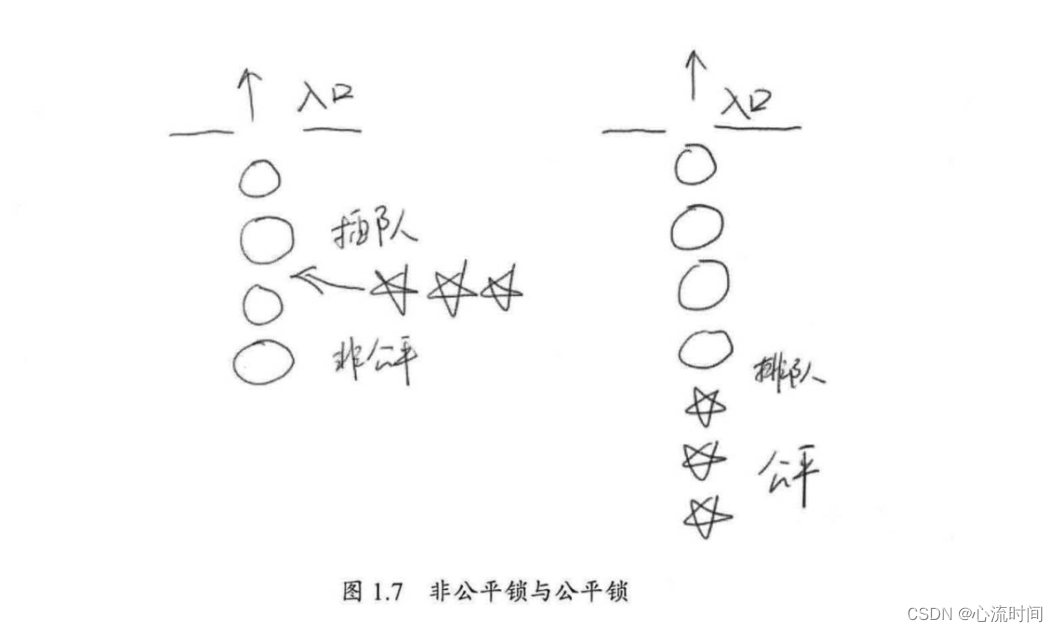
高并发编程-2. 并发级别
此文章为笔记,为阅读其他文章的感受、补充、记录、练习、汇总,非原创,感谢每个知识分享者。 原文 文章目录 阻塞无饥饿(Starvation-Free)无障碍(Obstruction-Free)无锁(Lock-Free)无等待 由于临界区的存在,多线程之间的并发必须受…...

牛客网Verilog刷题——VL47
牛客网Verilog刷题——VL47 题目答案 题目 实现4bit位宽的格雷码计数器。 电路的接口如下图所示: 输入输出描述: 信号类型输入/输出位宽描述clkwireIntput1时钟信号rst_nwireIntput1异步复位信号,低电平有效gray_outregOutput4输出格雷码计数…...
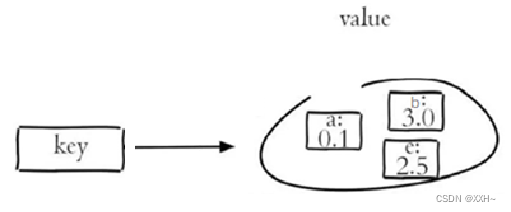
Redis以及Java使用Redis
一、Redis的安装 Redis是一个基于内存的 key-value 结构数据库。 基于内存存储,读写性能高 适合存储热点数据(热点商品、资讯、新闻) 企业应用广泛 官网:https://redis.io 中文网:https://www.redis.net.cn/ Redis…...

Apipost教程?一篇文章玩转Apipost
你是否经常遇到接口开发过程中的各种问题?或许你曾为接口测试与调试的繁琐流程而烦恼。不要担心!今天我将向大家介绍一款功能强大、易于上手的接口测试工具——Apipost,并带你深入了解如何玩转它,轻松实现接口测试与调试。 什么是…...
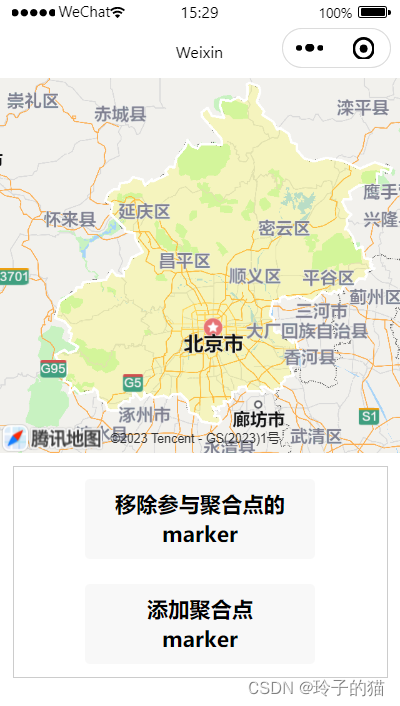
微信小程序开发学习之--地图绘制行政区域图
不知道大家有没有感觉就是在做微信小程序地图功能时刚刚接触时候真的感觉好迷茫呀,文档看不懂,资料找不到,就很难受呀,比如我现在的功能就想想绘制出一个区域的轮廓图,主要是为了显眼,效果图如下࿱…...
在windows下安装ruby使用gem
在windows下安装ruby使用gem 1.下载安装ruby环境2.使用gem3.gem换源 1.下载安装ruby环境 ruby下载地址 选择合适的版本进行下载和安装: 在安装的时候,请勾选Add Ruby executables to your PATH这个选项,添加环境变量: 安装Ruby成…...

【Ajax】笔记-设置CORS响应头实现跨域
CORS CORS CORS是什么? CORS(Cross-Origin Resource Sharing),跨域资源共享。CORS是官方的跨域解决方案,它的特点是不需要在客户端做任何特殊的操作,完全在服务器中进行处理,支持get和post请求。跨域资源共享标准新增了一组HTTP首…...
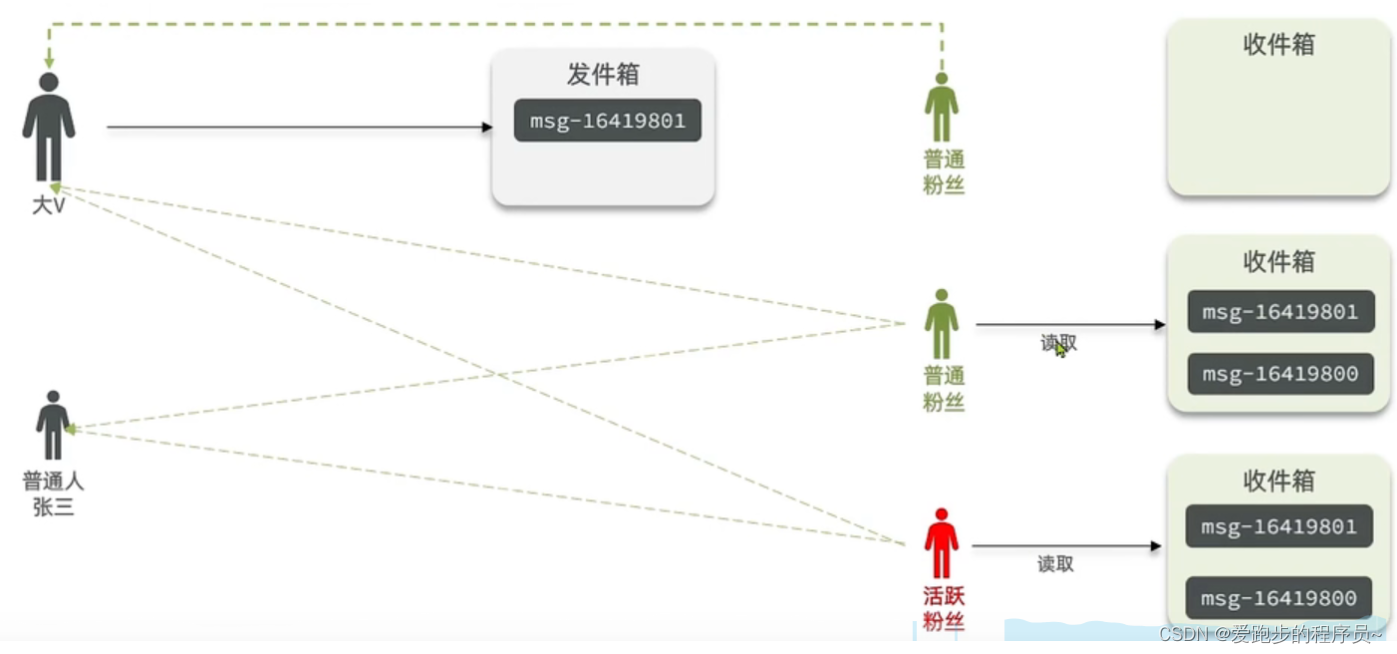
实现Feed流的三种模式:拉模式、推模式和推拉结合模式
在互联网产品中,Feed流是一种常见的功能,它可以帮助我们实时获取我们关注的用户的最新动态。Feed流的实现有多种模式,包括拉模式、推模式和推拉结合模式。在本文中,我们将详细介绍这三种模式,并通过Java代码示例来实现…...

基于RP2040与I2C总线打造可编程合成器吉他:从硬件到固件的完整实践
1. 项目概述:打造你的第一把可编程合成器吉他 如果你对电子音乐制作和嵌入式硬件开发都感兴趣,那么将两者结合的DIY项目无疑是最迷人的领域。今天要分享的,就是基于Adafruit RP2040 PropMaker Feather微控制器,从零开始打造一把功…...

Arduino与手机蓝牙通信:nRF8001 BLE模块硬件连接与软件配置全解析
1. 项目概述与核心价值如果你手头有一个Arduino项目,想让它和你的手机“说说话”,比如把传感器数据无线传到手机App上显示,或者用手机App远程控制几个LED灯,那么nRF8001这个蓝牙低功耗(BLE)模块绝对是你绕不…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...

无代码物联网实战:基于ESP32与WipperSnapper的泳池水温监测方案
1. 项目概述:告别繁琐编程,用无代码方案守护泳池水温又到了打理泳池的季节,除了常规的清洁和化学平衡,水温其实是个挺关键的指标。水温不仅影响游泳的舒适度,也关系到泳池加热设备的能耗和泳池化学品的反应速率。以前想…...

HS2-HF Patch:3步安装HoneySelect2终极增强补丁完整指南
HS2-HF Patch:3步安装HoneySelect2终极增强补丁完整指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch是HoneySelect2玩家的游戏增强…...
)
【实用小程序】超轻量级文件上传下载中心 (File Download Server)
站内源码及jar包下载 一、项目概述 文件下载中心一个基于 Java 内置 HTTP 服务器(com.sun.net.httpserver)构建的轻量级文件管理服务。它零第三方依赖,单 JAR 包即可运行,适合在内网环境或临时场景中快速搭建文件共享站点。 你的团队需要临时共享一批日志文件或交付物,…...


从巨头并购看FPGA技术演进与国产破局之路
1. 从两起世纪并购看FPGA的宿命与价值2015年,英特尔以167亿美元吞下Altera;2022年情人节,AMD用全股票交易正式将赛灵思(Xilinx)收入囊中。这两起震动半导体行业的并购案,表面看是巨头在“买公司”ÿ…...

解锁专业阅读体验:Chrome本地Markdown文件智能渲染解决方案
解锁专业阅读体验:Chrome本地Markdown文件智能渲染解决方案 【免费下载链接】markdownReader markdownReader is a extention for chrome, used for reading markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownReader 你是否曾经在Chrome…...

软电路入门:用导电缝纫线与LED制作可穿戴发光作品
1. 项目概述:当缝纫遇见电路 几年前,我第一次把一颗会发光的LED缝到帆布包上时,那种感觉非常奇妙。它不再是冰冷的电路板,而是布料纹理的一部分,随着针脚的走向亮起柔和的光。这就是软电路,或者说电子纺织品…...