【决策树-鸢尾花分类】
决策树算法简介
决策树是一种基于树状结构的分类与回归算法。它通过对数据集进行递归分割,将样本划分为多个类别或者回归值。决策树算法的核心思想是通过构建树来对数据进行划分,从而实现对未知样本的预测。
决策树的构建过程
决策树的构建过程包括以下步骤:
-
选择特征:从数据集中选择一个最优特征,使得根据该特征的取值能够将数据划分为最具有区分性的子集。
-
划分数据集:根据选定的特征将数据集分割成不同的子集,每个子集对应树中的一个分支。
-
递归构建:对每个子集递归地应用上述步骤,直到满足终止条件,如子集中的样本属于同一类别或达到预定深度。
-
决策节点:将特征选择和数据集划分过程映射到决策树中的节点。
-
叶节点:表示分类结果的节点,叶节点对应于某个类别或者回归值。
决策树的优点
决策树算法具有以下优点:
-
易于理解和解释:决策树的构建过程可以直观地表示,易于理解和解释,适用于数据探索和推断分析。
-
处理多类型数据:决策树可以处理离散型和连续型特征,适用于多类型数据。
-
能处理缺失值:在构建决策树时,可以处理含有缺失值的数据。
-
高效处理大数据:决策树算法的时间复杂度较低,对于大规模数据集也能得到较高的效率。
决策树的缺点
决策树算法也有一些缺点:
-
容易过拟合:决策树容易生成复杂的模型,导致过拟合问题,需要进行剪枝等处理。
-
不稳定性:数据的细微变化可能导致生成不同的决策树,算法不稳定。
决策树的应用场景
决策树算法在许多领域都有广泛的应用,包括但不限于:
-
分类问题:决策树用于解决分类问题,如垃圾邮件识别、疾病诊断等。
-
回归问题:对于回归问题,决策树可以预测连续性输出,如房价预测、销售量预测等。
-
特征选择:决策树可用于选择重要特征,帮助简化模型。
示例代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X, y = data.data, data.target# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y)# 创建决策树分类器
clf = DecisionTreeClassifier()# 训练模型
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)# 直接对比预测值和真实值
print(y_pred == y_test)# 可视化决策树
from sklearn.tree import export_graphviz
import graphvizdot_data = export_graphviz(clf, out_file=None,feature_names=data.feature_names,class_names=data.target_names,filled=True, rounded=True,special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("iris")
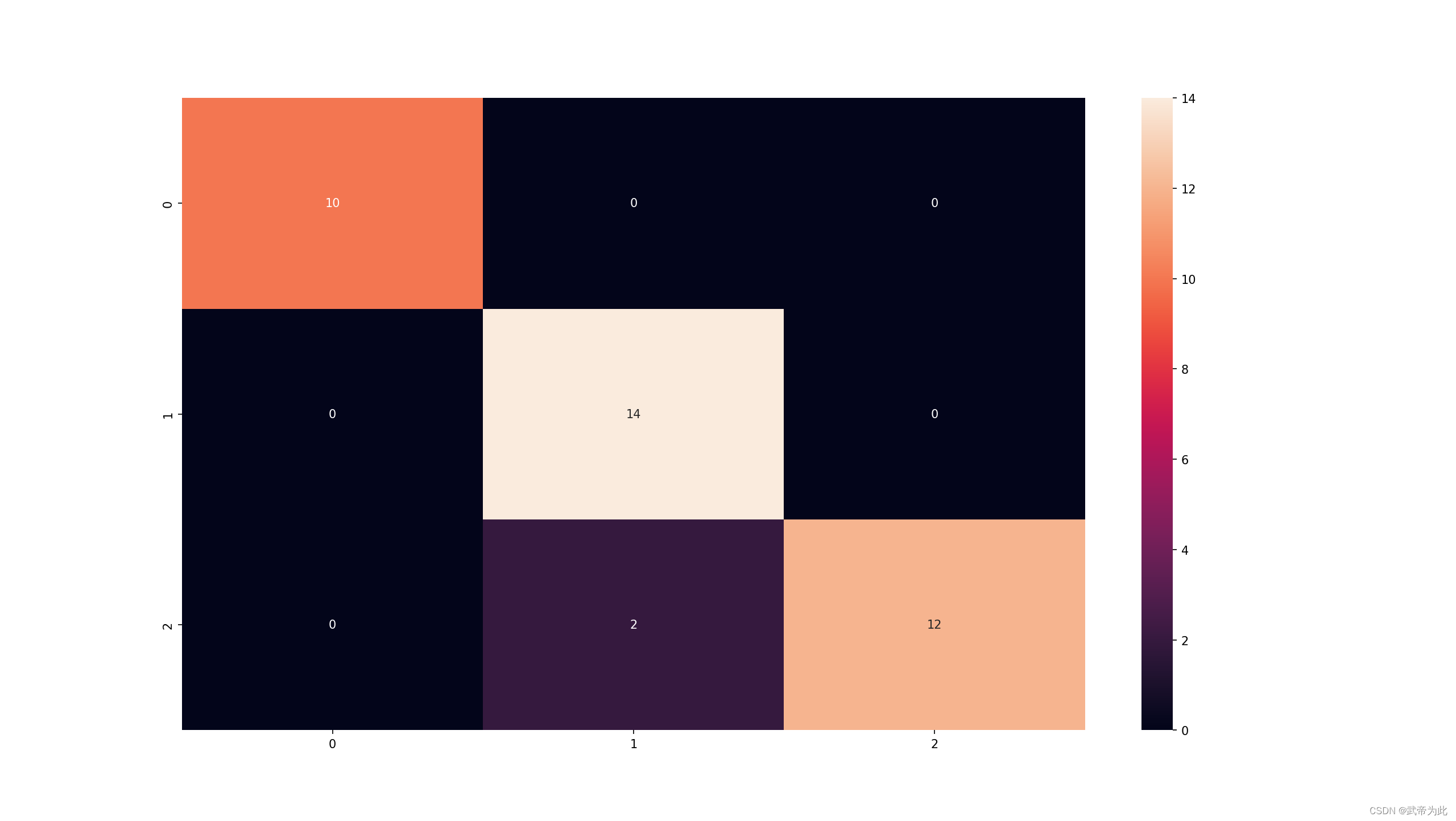
graph.view()# 可视化混淆矩阵
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)# 可视化混淆矩阵
sns.heatmap(cm, annot=True)
plt.show()# 可视化分类报告
from sklearn.metrics import classification_report# 计算分类报告
report = classification_report(y_test, y_pred)# 打印分类报告
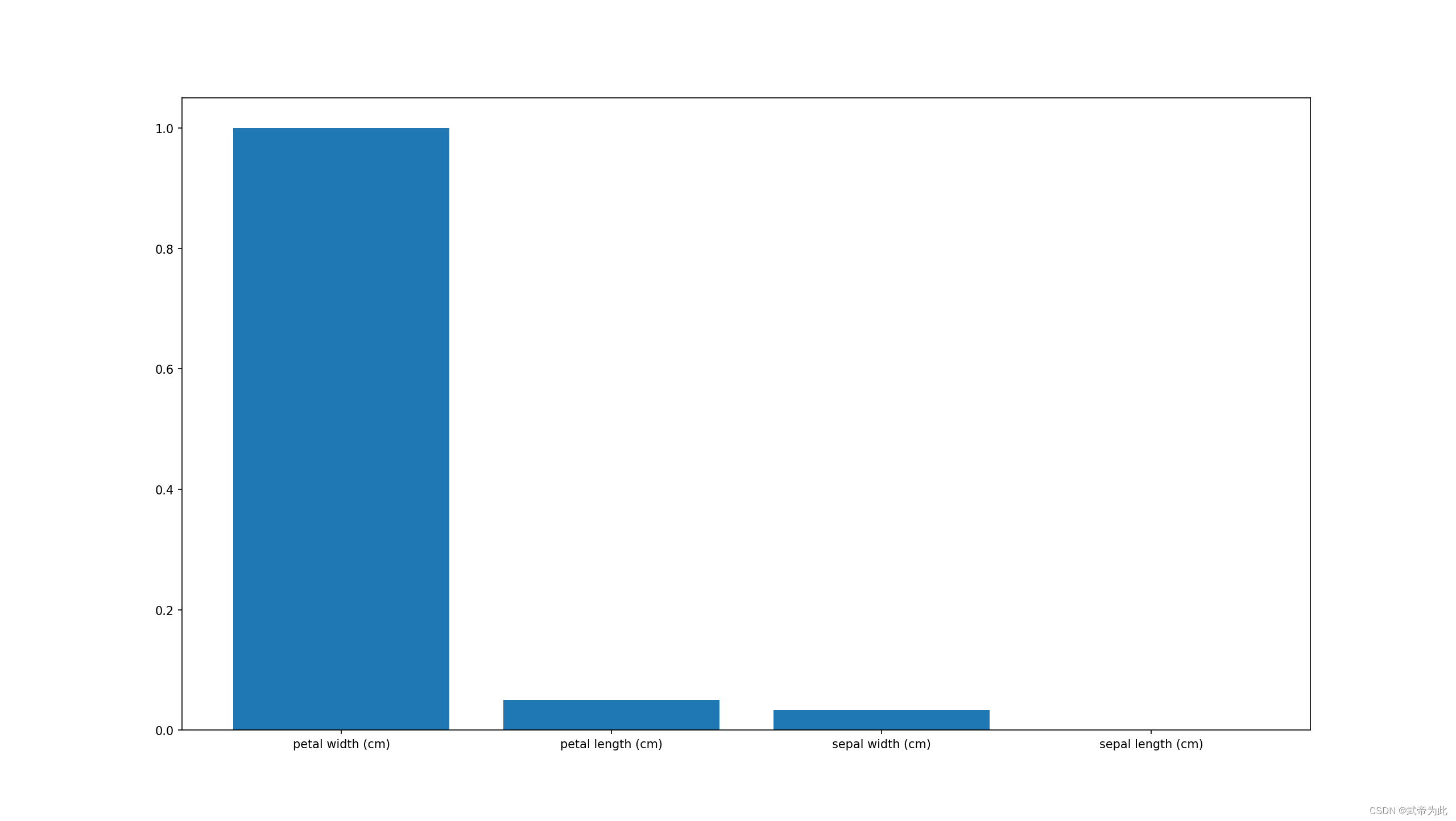
print(report)# 可视化特征重要性
import matplotlib.pyplot as plt
import numpy as np# 获取特征重要性
importances = clf.feature_importances_# 获取特征名称
feature_names = data.feature_names# 将特征重要性标准化
importances = importances / np.max(importances)# 将特征名称和特征重要性组合在一起
feature_names = np.array(feature_names)
feature_importances = np.array(importances)
feature_names_importances = np.vstack((feature_names, feature_importances))# 将特征重要性排序
feature_names_importances = feature_names_importances[:, feature_names_importances[1, :].argsort()[::-1]]# 绘制条形图
plt.bar(feature_names_importances[0, :], feature_names_importances[1, :].astype(float))
plt.show()
总结
决策树算法是一种强大且灵活的机器学习算法,适用于分类和回归任务。它具有易于理解、处理多类型数据以及高效处理大数据等优点。然而,需要注意过拟合和不稳定性等缺点。
相关文章:
【决策树-鸢尾花分类】
决策树算法简介 决策树是一种基于树状结构的分类与回归算法。它通过对数据集进行递归分割,将样本划分为多个类别或者回归值。决策树算法的核心思想是通过构建树来对数据进行划分,从而实现对未知样本的预测。 决策树的构建过程 决策树的构建过程包括以…...
)
类与对象(中--构造函数)
类与对象(中--构造函数) 1、构造函数的特性2、默认构造函数3、编译器自动生成的默认构造函数(无参的)(当我们不写构造函数时)3.1 编译器自动生成的默认构造函数只对 自定义类型的成员变量 起作用࿰…...

Makefile学习1
文章目录 Makefile学习1Makefile简介Makefile重要性Makefile内容1) 显式规则2) 隐晦规则3) 变量的定义4) 文件指示5) 注释 Makefile规则规则默认目标多目标多规则目标伪目标 Makefile目标依赖头文件依赖自动生成头文件依赖关系 Makefile命令Makefile变量变量定义和使用赋值立即…...
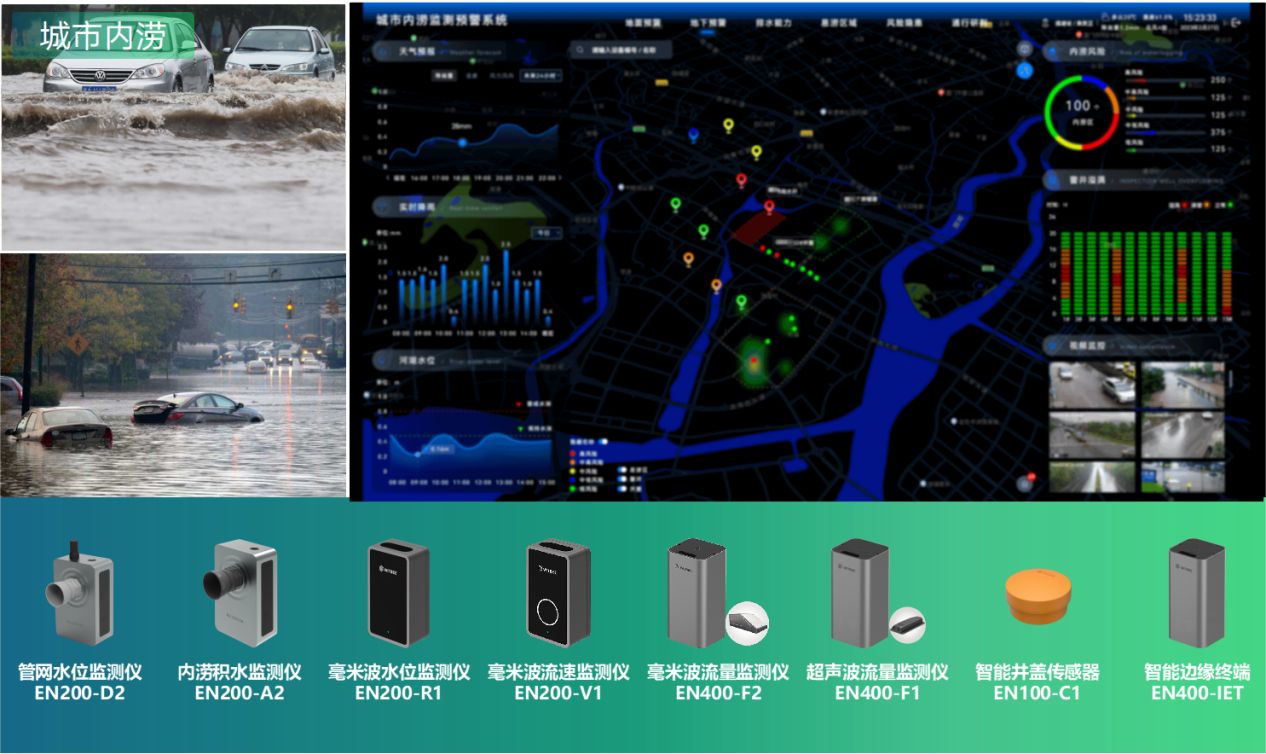
城市内涝监测预警系统,科学“智治”应对灾害
近日,台风“杜苏芮”以摧枯拉朽之势给我国东南沿海地区带来狂风骤雨,福建的三个国家气象观测站日降水量突破历史极值。之后,“杜苏芮”一路北上。中央气象台预报称,7月29日至8月1日,北京、天津、河北、山东西部、河南北…...

切片[::-1]解析列表list表示的“非负整数加1”
列表数位表示非负整数,熟练操作“满十进位”。 (本笔记适合熟练操作Python列表list的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅…...
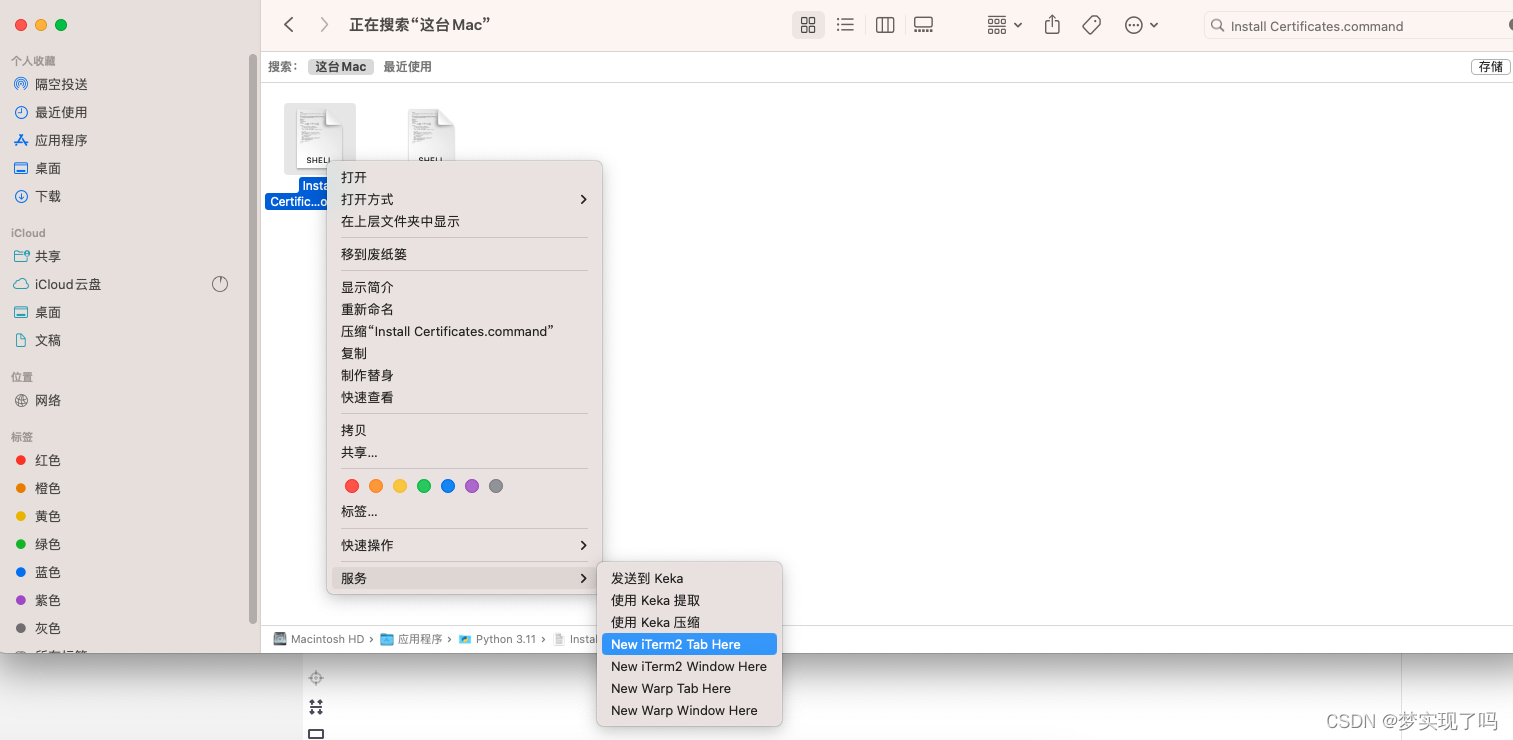
Mac下certificate verify failed: unable to get local issuer certificate
出现这个问题,可以安装证书 在finder中查找 Install Certificates.command找到后双击,或者使用其他终端打开 安装完即可...

Django项目启动错误
uwsgi项目启动错误信息如下Did you install mysqlclient?Command pkg-config --exists mysqlclient returned non-zero exit status 1Command pkg-config --exists mariadb returned non-zero exit status 1.Traceback (most recent call last):File "/home/dream21th/co…...

Vue2 第十二节 Vue组件化编程 (二)
1. VueComponent 2. 单文件组件 一. VueComponent 组件本质上是一个名为VueComponent的构造函数,不是程序员定义的,是Vue.extend生成的只需要写<school/>或者<school><school/>,Vue解析时,会帮我们创建schoo…...
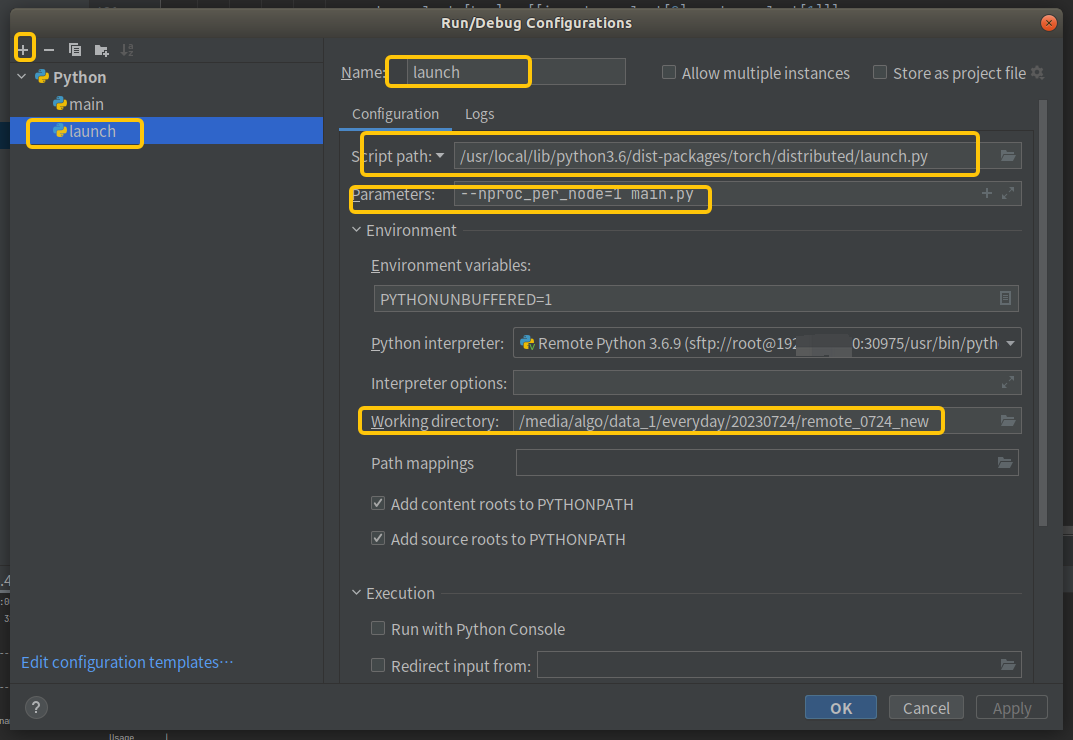
pycharm 远程连接服务器并且debug, 支持torch.distributed.launch debug
未经允许,本文不得转载,vx:837007389 文章目录 step1:下载专业版本的pycharmstep2 配置自动同步文件夹,即远程的工程文件和本地同步2.1 Tools -> Deployment -> configuration2.2 设置同步文件夹2.3 同步服务器…...

SAP ABAP 基础语法超详细
1.表声明 Tables: 表名[,表名]. 声明多个表时可用逗号分隔当你声明了一个数据表的同时,系统也同时自动生成了一个和数据表同名的结构,结构的变量集等于数据表里面的字段。 2.定义变量 Data: v1[(l)] [type t] [decimals d] [v…...

html学习3(表格table、列表list)
1、html表格由<table>标签来定义。 <thead>用来定义表格的标题部分,其内部用 <th > 元素定义列的标题,可以使其在表格中以粗体显示,与普通单元格区分开来。<tbody>用来定义表格的主体部分,其内部用<t…...

【SpringBoot】85、SpringBoot中Boolean类型数据转0/1返回序列化配置
在 SpringBoot 中,前端传参数 0,1,后端可自动解析为 boolean 类型,但后端返回前端 boolean 类型时,却无法自动转换为 0,1,所以我们需要自定义序列化配置,将 boolean 类型转化为 0,1 1、类型对应 boolean 类型有false,true对应的 int 类型0,12、序列化配置 import com.f…...

hbase优化:客户端、服务端、hdfs
hbase优化 一.读优化 1.客户端: scan。cache 设置是否合理:大scan场景下将scan缓存从100增大到500或者1000,用以减少RPC次数使用批量get进行读取请求离线批量读取请求设置禁用缓存,scan.setBlockCache(false)以指定列族或者列进行…...

docker安装memcached
查找容器是否有该镜像存在 docker search memcached拉取镜像 docker pull memcached创建容器 docker create --name memcache1 memcached或者映射一下端口 docker create -p 11211:11211 --name memcache1 memcached启动 docker start memcache1指定容器的 IP docker net…...
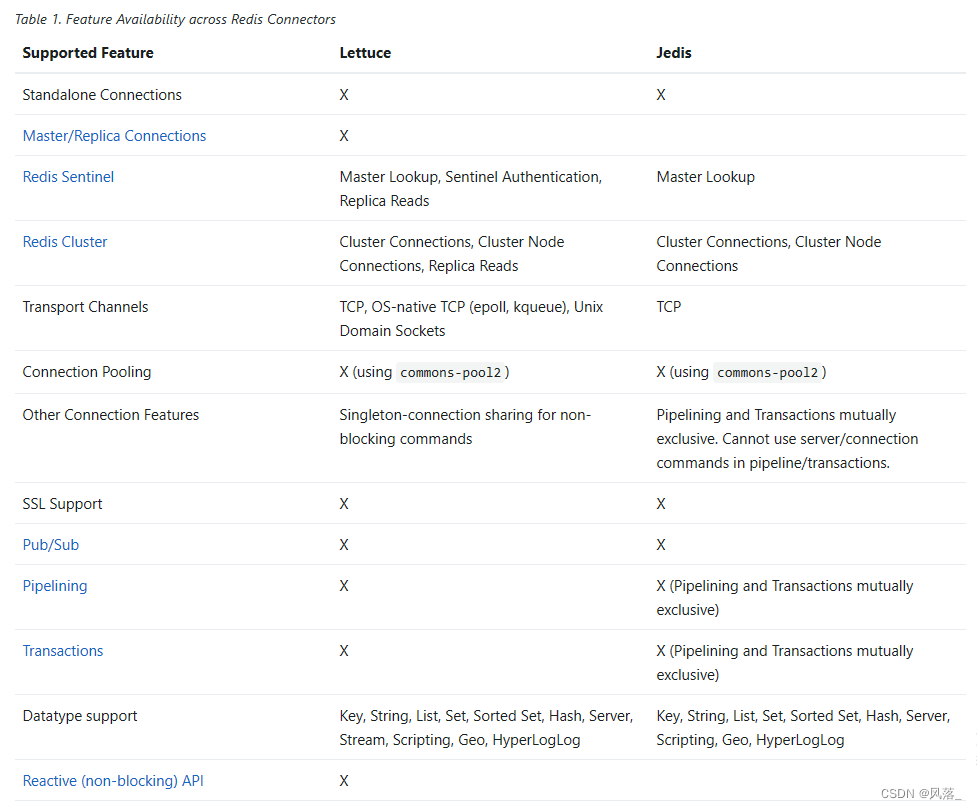
Redis 客户端有哪些?
文章目录 JedisLettuceRedisson最佳实践 - 到底用哪个? Redis 最常见的 Java 客户端有两个,Jedis 和 Lettuce,高级客户端有 Redisson,见下图(图源 Clients | Redis) Jedis Github地址:redis/j…...

smbms 超市订单管理系统设计与实现计划表
smbms 超市订单管理系统 项目描述 smbms-JDBC:不使用 SSM 框架进行开发bookStore:学完ssm框架后的整合项目smbms-SSM:使用 SSM 框架开发 项目记录 smbms-JDBC 2023-10-28:第一天,搭建环境,写好基本的工…...

如何解决制造业数字化改造的障碍?
制造业的数字化转型可能是一个复杂且具有挑战性的过程,但解决以下障碍有助于为成功实施铺平道路: 抵制变革:数字化转型中最常见的挑战之一是员工的抵制,尤其是那些习惯传统方法的员工。为了克服这一问题,组织需要培养一…...

代码随想录算法训练营day49
文章目录 Day49买卖股票的最佳时机题目思路代码贪心算法动态规划法(推荐) 买卖股票的最佳时机II题目思路代码 Day49 买卖股票的最佳时机 121. 买卖股票的最佳时机 - 力扣(LeetCode) 题目 给定一个数组 prices ,它的第 i 个元素 prices[i]…...

云计算与大数据——部署Kubernetes集群+完成nginx部署(超级详细!)
云计算与大数据——部署Kubernetes集群完成nginx部署(超级详细!) 部署 Kubernetes 集群的基本思路如下: 准备环境: 选择适合的操作系统:根据需求选择适合的 Linux 发行版作为操作系统,并确保在所有节点上进行相同的选…...
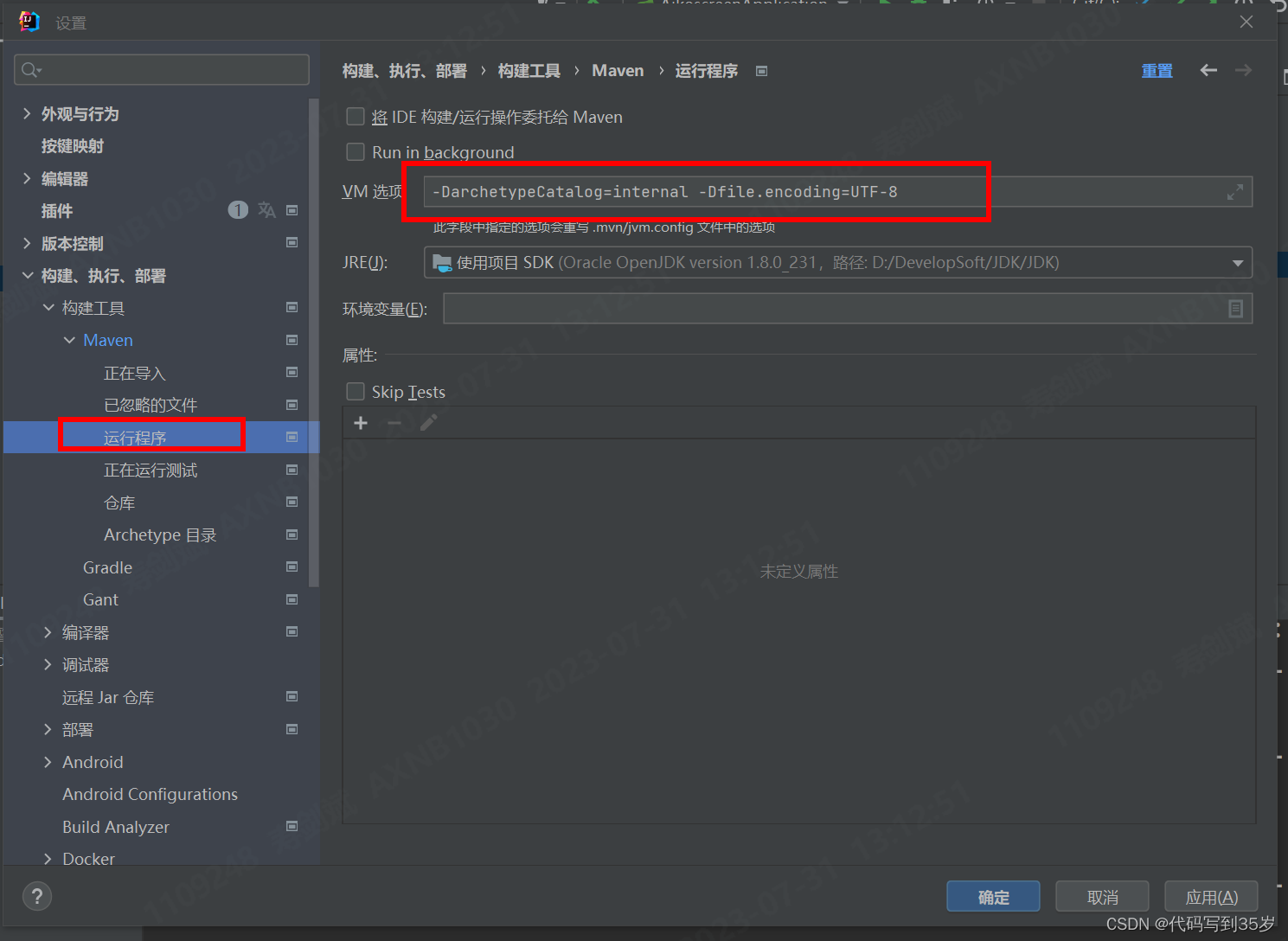
Maven 打包项目后,接口识别中文乱码
背景 项目在Idea里面运行,调用接口发送中文消息正常,用Maven打包项目后,运行jar包,调用接口发送中文出现乱码。 解决方法 1.Idea编译配置 2.如果更改了上述配置之后还是没有效果,则在运行jar包的前面加上 -Dfile.en…...

书成紫微动,律定凤凰驯:海棠山铁哥的道,从来不是嘴上说的,是写在作品里的
文坛从不缺大道理,也不缺高谈阔论的传道者,历来最缺的,是知行合一、落地成真的真大道。一、乱象:言道者多,行道者少口头标榜实际行径文脉传承随波逐流初心坚守妥协功利拒绝流量收割热度敬畏真诚唯数据论 语言可以伪装人…...

树莓派BlueZ源码编译安装与蓝牙协议栈深度配置指南
1. 项目概述与背景 如果你手头有一块树莓派,并且想用它来玩点物联网或者智能硬件项目,蓝牙功能几乎是绕不开的一环。无论是连接一个BLE温湿度传感器读取数据,还是控制一个蓝牙音箱,底层都需要一个稳定、功能完整的蓝牙协议栈来支…...

为Claude Code配置Taotoken密钥以解决访问限制与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken密钥以解决访问限制与token不足问题 对于经常使用Claude Code作为编程助手的开发者而言,直接…...

基于Hi3516DV300的智能相机全流程设计方案:从硬件选型到算法集成
1. 项目概述:从一块开发板到一台智能相机手头拿到一块Hi3516开发板,很多嵌入式开发者的第一反应可能是:这能做个啥?如果告诉你,基于这块海思的经典芯片,我们可以设计出一台功能完整、具备智能分析能力的网络…...

Adobe-GenP终极指南:5分钟免费解锁Adobe全家桶的完整方案
Adobe-GenP终极指南:5分钟免费解锁Adobe全家桶的完整方案 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 还在为Adobe Creative Cloud昂贵的订阅费用而苦…...

深入TMS320C6678中断控制器:从CIC、INTC到Event Combiner的底层机制图解
深入解析TMS320C6678中断控制器架构与实现机制 在嵌入式系统开发领域,中断处理机制的设计与实现往往是决定系统实时性和可靠性的关键因素。TMS320C6678作为一款高性能多核DSP处理器,其中断控制系统采用了分层式设计理念,通过片级中断控制器(C…...

观察Taotoken用量看板如何帮助团队控制API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何帮助团队控制API成本 作为团队的技术负责人,引入大模型API后,成本的可观测性与可…...

typescript笔记、ts笔记、npx命令
文章目录npx命令npx tsc编译前后的对比编译前编译后ts和js的区别?报错 error TS5112: tsconfig.json is present but will not be loaded if files are specified on commandline. Use --ignoreConfig to skip this error.typescript并不是一个新概念,只不过随着20…...

如何彻底解决Windows系统DLL缺失问题:Visual C++运行库一键修复终极指南
如何彻底解决Windows系统DLL缺失问题:Visual C运行库一键修复终极指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突…...

告别电脑“飞机起飞“噪音:FanControl风扇控制终极指南
告别电脑"飞机起飞"噪音:FanControl风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tr…...