Python爬虫(1)一次性搞定Selenium(新版)8种find_element元素定位方式

selenium中有8种不错的元素定位方式,每个方式和应用场景都不一样,需要根据自己的使用情况来进行修改
8种find_element元素定位方式
- 1.id定位
- 2.CSS定位
- 3.XPATH定位
- 4.name定位
- 5.class_name定位
- 6.Link_Text定位
- 7.PARTIAL_LINK_TEXT定位
- 8.TAG_NAME定位
- 总结
目前selenium已经出现了新的版本的定位方式,虽然说定位语法不一样,但是万变不离其宗。

用旧版的定位语法就会出现这个删除线,你用他来进行爬虫的时候运行时就会提示你虽然问题不大但是还是得考虑使用新版本的定位方式
DeprecationWarning: find_element_by_css_selector is deprecated. Please use find_element(by=By.CSS_SELECTOR, value=css_selector) insteadline = li.find_element_by_css_selector("p.title a ").get_attribute('href')
- selenium中find_element定位方式
- find_element(By.XPATH)
- find_element(By.CSS_SELECTOR)
- find_element(By.ID)
- find_element(By.TAG_NAME)
- find_element(By.class_name,)
- find_element(By.PARTIAL_LINK_TEXT)
- find_element(By.LINK_TEXT)
- find_element(By.name)
上面定位元素方法主要是单个,多个元素定位就在element后面加个s
1.id定位
在网站中有很多的id,我们可以通过找到这些id来帮助我们定位网页中的元素,但是id定位有缺点就是id元素往往是单一个存在,如果我们需要定位多个id的话id定位就不好帮助我们进行定位。

from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()
driver.get("网址")
a1 = driver.find_element(By.ID,'livenews-id-1-202301272620080422').text
print(a1)

2.CSS定位
css定位是最佳推荐的定位元素,不仅仅效率高,而且针对复杂场景的多个元素定位需求会比xpath和其他元素定位更好
在网页中快速定位我一般都是在开发者工具中找到selector然后针对这个标签进行选择
#livenews-id-1-202301272620081211 > div.media-content > h2 > a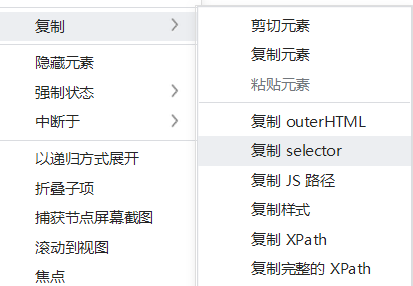
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()
driver.get("网站")
a1 = driver.find_element(By.CSS_SELECTOR,'#livenews-id-1-202301272620081211 > div.media-content > h2 > a').text
print(a1)

当然我们真正实际上使用的时候就不用那么复杂,如果我们找到了父元素,再去找子元素时就可以直接对里面的标签进行选择比如我们已经知道是在要的内容在div下的a标签中
div标签我们已经获取那么a标签的内容就可以直接选择a标签,也可以用h2 a 这样就表示选中h2标签中的所有a标签
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()# Chrome浏览器
driver.get("网站")
f1=driver.find_elements(By.XPATH,'//*[@id="livenews-id-1-202301282620082087"]')
for i,f2 in enumerate(f1):if i < 2:a1 = f2.find_element(By.CSS_SELECTOR, 'a').textprint(a1)
复杂标签应用可以参考这篇文章Python使用selenium中的CSS_SELECTOR进行搞定复杂多标签定位
css里面还有许多丰富的选择器可以参考这篇文章css选择器
3.XPATH定位
classname 选取所有的子节点
/ 从根节点选
// 匹配任意节点不考虑位置
. 选取当前节点。
用…选中当前节点的父节点
@ 选取属性
还可以用xpath的通配符选取节点
用*匹配任何元素的节点
用@*来匹配任何属性的节点
用node来匹配任意类型的节点
用//*来选中所有的元素
//div[@*]选中所有div属性的元素
在实际中的应用场景
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()# Chrome浏览器
driver.get("网站")
f1=driver.find_element(By.XPATH,'//*[@id="livenews-id-1-202301282620139465"]/div[1]/h2/a').get_attribute('text')
print(f1)
更多xpath定位可以参考这篇文章如何使用Xpath定位元素
4.name定位
name可以指定页面中的标签名,如果页面中没有重复name就可以使用,如果页面中有多个重复的name就不推荐使用
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()# Chrome浏览器
driver.get("网址")
f1=driver.find_element(By.NAME,'description')
print(f1)

5.class_name定位
class标签也是selenium指定的标签定位方式,但是这种方式实际中还是不推荐使用因为你会遇到一个div标签中出现非常多重复的class名
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()# Chrome浏览器
driver.get("网址")
f1=driver.find_element(By.CLASS_NAME,'time').text
print(f1)

6.Link_Text定位
专门定位文本的标签,需要指定标签内全部的文本内容才能够进行定位,否则是无法定位成功
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()# Chrome浏览器
driver.get("网址")
f1=driver.find_element(By.LINK_TEXT,'焦点').text
print(f1)
7.PARTIAL_LINK_TEXT定位
指定某部分文本即可定位成功,不用将文本内容全部输入即可定位成功
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()# Chrome浏览器
driver.get("网址")
f1=driver.find_element(By.PARTIAL_LINK_TEXT,'三亚').text

8.TAG_NAME定位
tag表示定位的一类功能,也就是用来定位div、h2这一类标签往往没什么用处,识别率特别低,页面中有非常多个div标签,而且你获取到的数据会非常混乱,数据清洗起来异常复杂
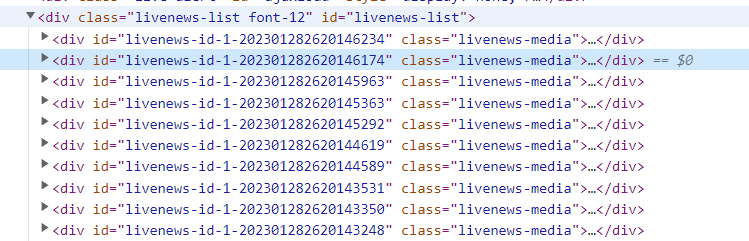
使用tag定位一下子就把整个页面所有的div信息给你获取下来
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.by import By
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
driver = webdriver.Chrome()# Chrome浏览器
driver.get("网址")
f1=driver.find_element(By.TAG_NAME,'div').text
print(f1)

总结
如果要从想要更加快速搞定爬虫的内容,建议只搞xpath、css这两种定位方式,吃透就能够应对绝大多数的爬虫情况,当然如果有反爬虫网站效果就不理想要自行处理。
相关文章:
Python爬虫(1)一次性搞定Selenium(新版)8种find_element元素定位方式
selenium中有8种不错的元素定位方式,每个方式和应用场景都不一样,需要根据自己的使用情况来进行修改 8种find_element元素定位方式 1.id定位2.CSS定位3.XPATH定位4.name定位5.class_name定位6.Link_Text定位7.PARTIAL_LINK_TEXT定位8.TAG_NAME定位总结 …...

前端(十一)——Vue vs. React:两大前端框架的深度对比与分析
😊博主:小猫娃来啦 😊文章核心:Vue vs. React:两大前端框架的深度对比与分析 文章目录 前言概述原理与设计思想算法生态系统与社区支持API与语法性能与优化开发体验与工程化对比总结结语 前言 在当今快速发展的前端领…...
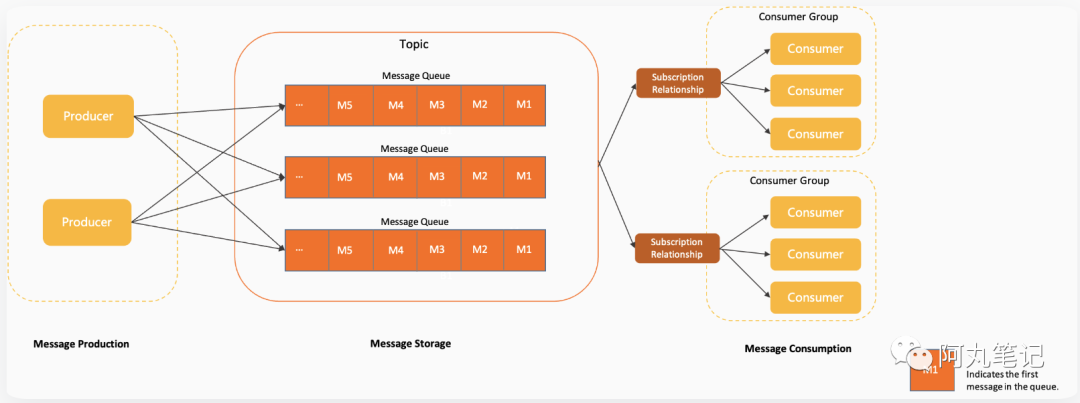
三分钟白话RocketMQ系列—— 核心概念
目录 关键字摘要 Q1:RocketMQ是什么? Q2: 作为消息中间件,RocketMQ和kafka有什么区别? Q3: RocketMQ的基本架构是怎样的? Q4:RocketMQ有哪些核心概念? 总结 RocketMQ是一个开源的分布式消…...

递归竖栏菜单简单思路
自己的项目要写一个竖栏菜单,所以记录一下思路吧,先粗糙的实现一把,有机会再把细节修饰一下 功能上就是无论这个菜单有多少层级,都能显示出来,另外,需要带图标,基于element-plus写成࿰…...

组件化、跨平台…未来前端框架将如何演进?
前端框架在过去几年间取得了显著的进步和演进。前端框架也将继续不断地演化,以满足日益复杂的业务需求和用户体验要求。从全球web发展角度看,框架竞争已经从第一阶段的前端框架之争(比如Vue、React、Angular等),过渡到…...
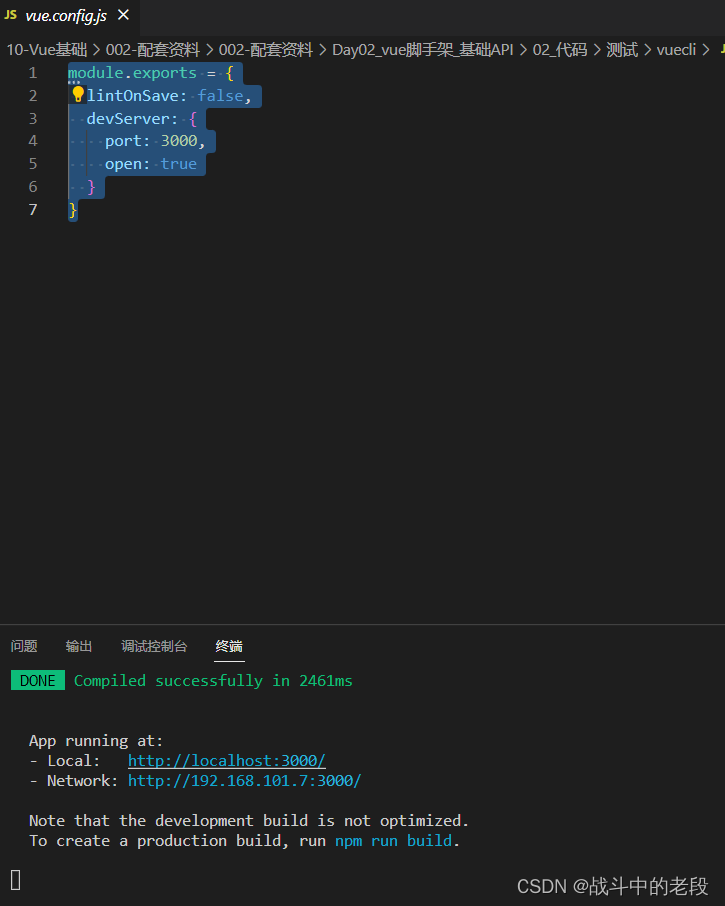
vue 修改端口号
在根目录创建一个vue.config.js文件夹 module.exports {lintOnSave: false,devServer: {port: 3000,open: true} }运行后...

hive的metastore问题汇总
1. metastore内存飙升 1 问题 metastore内存飙升降不下来; spark集群提交的任务无法运行, 只申请到了dirver的资源; 2 原因 当Spark任务无法获取足够资源时,因为任务无法继续进行,不能将元数据从Metastore返回给任务 后,这些元数据暂存在…...
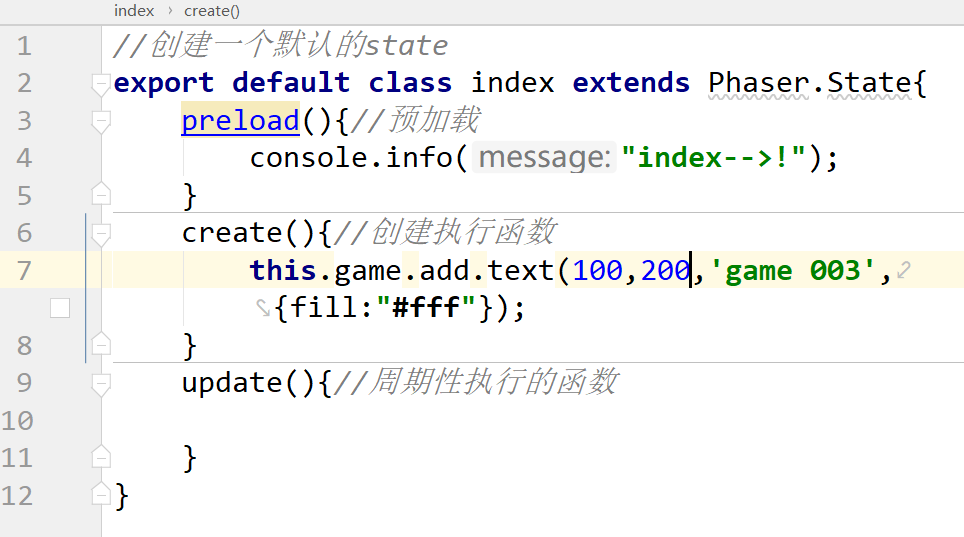
【phaser微信抖音小游戏开发003】游戏状态state场景规划
经过目录优化后的执行结果: 经历过上001,002的规划,我们虽然实现了helloworld .但略显有些繁杂,我们将做以下的修改。修改后的目录和文件结构如图。 game.js//小游戏的重要文件,从这个开始。 main.js 游戏的初始化&a…...

字符串性能优化
String 对象作为 Java 语言中重要的数据类型,是内存中占据空间最大的一个对象。高效地 使用字符串,可以提升系统的整体性能。 来一到题来引出这个话题 通过三种不同的方式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否…...
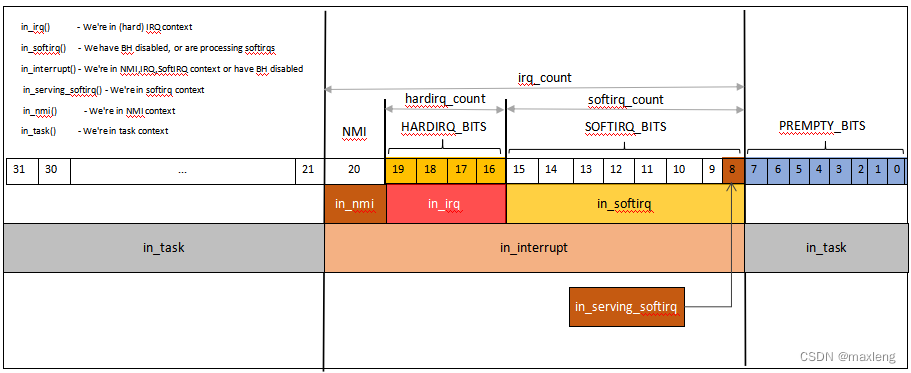
从零开始理解Linux中断架构(23)中断运行临界区和占先调度
Linux在内核中定义了6种运行临界区。 in_interrupt in_interrupt在驱动中使用频率最高的函数了,in_interrupt()就是指示Core是否正在中断处理中,包含了硬中断,软中断运行临界区。如果在中断处理中,则不能调用__do_softirq执行软中断处理。硬中断中不可调度不可中断,所有…...
Gymnasium--CartPole的测试基于DQN)
(3)Gymnasium--CartPole的测试基于DQN
1、使用Pytorch基于DQN的实现 1.1 主要参考 (1)推荐pytorch官方的教程 Reinforcement Learning (DQN) Tutorial — PyTorch Tutorials 2.0.1cu117 documentation (2) Pytorch 深度强化学习 – CartPole问题|极客笔记 2.2 pytorch官方的教程原理 待续,这两天时…...
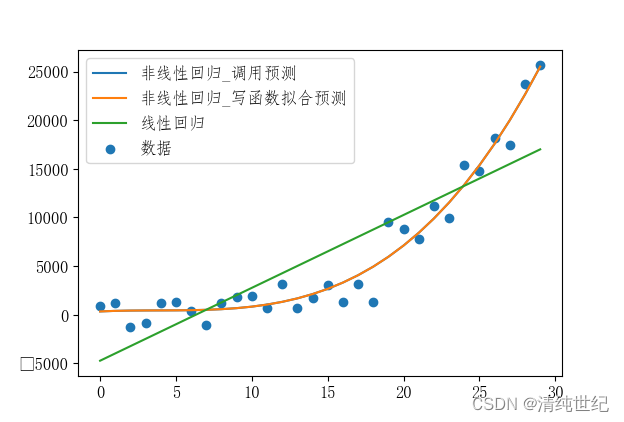
利用sklearn 实现线性回归、非线性回归
代码: import pandas as pd import numpy as np import matplotlib import random from matplotlib import pyplot as plt from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression# 创建虚拟数据 x np.array(r…...
Java课题笔记~ MyBatis入门
一、ORM框架 当今企业级应用的开发环境中,对象和关系数据是业务实体的两种表现形式。业务实体在内存中表现为对象,在数据库中变现为关系数据。当采用面向对象的方法编写程序时,一旦需要访问数据库,就需要回到关系数据的访问方式&…...
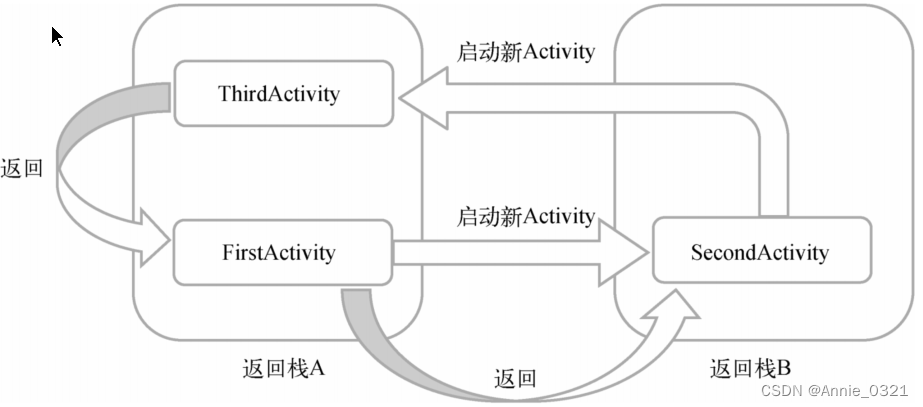
Activity的自启动模式
以下内容摘自郭霖《第一行代码》第三版 文章目录 Activity的自启动模式1.standard(默认)2.singleTop3.singleTask4.singleInstance Activity的自启动模式 启动模式一共有4种,分别是standard、singleTop、singleTask和singleInstance&#x…...

53数组的扩展
数组的扩展 扩展运算符Array.from()Array.of()实例方法:copyWithin()实例方法:find(),findIndex(),findLast(),findLastIndex()实例方法:fill()[实例方法:entries(),keys() 和 valu…...

Rust调试【三】
Local Debug: vscode CodeLLDB extension memory leak analysis: Rust and Valgrind FFI Memory wrapping: Foreign Function Interface FFI panic handling: Panic handling...

uniApp 对接安卓平板刷卡器, 读取串口数据
背景: 设备: 鸿合 电子班牌 刷卡对接 WS-B22CS, 安卓11; 需求: 将刷卡器的数据传递到自己的App中, 作为上下岗信息使用, 以完成业务; 对接方式: 1. 厂家技术首先推荐使用 接收自定义广播的方式来获取, 参考代码如下 对应到uniApp 中的实现如下 <template><view c…...

Go new 与 make
Go new 与 make 在Go语言中,"new"和"make"都是用于动态分配内存的关键字,但它们有不同的用途和区别。 "new": 在Go语言中,"new"是一个内建函数,用于值类型(基本类型和用户定…...
centos系统离线安装k8s v1.23.9最后一个版本并部署服务,docker支持的最后一个版本
注意:我这里的离线安装包是V1.23.9. K8S v1.23.9离线安装包下载: 链接:https://download.csdn.net/download/qq_14910065/88139255 这里包括离线安装所有的镜像,kubeadm,kubelet 和kubectl,calico.yaml&am…...

(学习笔记-内存管理)如何避免预读失效和缓存污染的问题?
传统的LRU算法存在这两个问题: 预读失效 导致的缓存命中率下降缓存污染 导致的缓存命中率下降 Redis的缓存淘汰算法是通过实现LFU算法来避免 [缓存污染] 而导致缓存命中率下降的问题(redis 没有预读机制) Mysql 和 Linux操作系统是通过改进…...

OpenVINO AI音频插件:5个本地AI功能让你的Audacity变身专业音频工作室
OpenVINO AI音频插件:5个本地AI功能让你的Audacity变身专业音频工作室 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openvino-plugins-ai…...
详情页开发避坑指南:路由配置与参数传递详解)
告别弹窗!若依框架(Ruoyi)详情页开发避坑指南:路由配置与参数传递详解
若依框架详情页开发实战:从路由配置到参数传递的深度解析 在若依框架的实际开发中,详情页的实现往往成为开发者遇到的"拦路虎"。明明按照文档操作,却频繁遭遇页面空白、参数丢失或控制台报错等问题。本文将深入剖析若依框架中前端路…...

如何构建工业级智能预测性维护系统:基于LSTM的5大实战策略
如何构建工业级智能预测性维护系统:基于LSTM的5大实战策略 【免费下载链接】Predictive-Maintenance-using-LSTM Example of Multiple Multivariate Time Series Prediction with LSTM Recurrent Neural Networks in Python with Keras. 项目地址: https://gitcod…...

实战指南:如何高效部署VoiceFixer语音修复系统,从噪声消除到低分辨率增强全解析
实战指南:如何高效部署VoiceFixer语音修复系统,从噪声消除到低分辨率增强全解析 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer VoiceFixer是一款基于深度学习的通用语音修复工…...

开发者必备:从聊天记录到结构化知识库的自动化工具实践
1. 项目概述:一个面向开发者的轻量级对话记录工具最近在整理几个开源项目的技术讨论记录时,我又一次陷入了混乱。Slack、Discord、Telegram、微信……不同平台的聊天记录散落各处,格式五花八门,想回溯一个关键的技术决策或一个报错…...

MacType终极指南:彻底解决Windows字体模糊问题的免费神器
MacType终极指南:彻底解决Windows字体模糊问题的免费神器 【免费下载链接】mactype Better font rendering for Windows. 项目地址: https://gitcode.com/gh_mirrors/ma/mactype 你是否厌倦了Windows系统上模糊不清的字体显示?长期面对锯齿边缘的…...

Taotoken用量看板如何帮助开发者洞察API消费明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助开发者洞察API消费明细 对于依赖大模型API进行开发的团队或个人而言,清晰、透明地掌握资源消…...

OpenHarmony Rust开发实战:GN构建配置与FFI互操作指南
1. 项目概述:为什么要在OpenHarmony里搞Rust?最近在折腾OpenHarmony开发板,想把一些对性能和安全性要求比较高的模块用Rust重写,结果发现官方文档里关于Rust构建的部分讲得比较零散。踩了一圈坑之后,我决定把OpenHarmo…...

电商网站滑块验证码破解:OpenCV图像识别+轨迹模拟方案
一、前言当前主流电商、会员登录、抢购下单、接口风控场景中,滑块拼图验证码已是最常见的人机校验方式。传统简单爬虫直接请求接口极易被拦截,而滑块验证码核心防护逻辑分为两点:一是缺口位置图像匹配校验,二是人为滑动轨迹行为风…...

WinUtil:Windows系统优化与批量软件管理的终极解决方案
WinUtil:Windows系统优化与批量软件管理的终极解决方案 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 还在为Windows系统优化和软…...