(3)Gymnasium--CartPole的测试基于DQN
1、使用Pytorch基于DQN的实现
1.1 主要参考
(1)推荐pytorch官方的教程
Reinforcement Learning (DQN) Tutorial — PyTorch Tutorials 2.0.1+cu117 documentation
(2)
Pytorch 深度强化学习 – CartPole问题|极客笔记
2.2 pytorch官方的教程原理
待续,这两天时期多,过两天整理一下。
2.3代码实现
import gymnasium as gym
import math
import random
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from itertools import countimport torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as Fenv = gym.make("CartPole-v1")# set up matplotlib
# is_ipython = 'inline' in matplotlib.get_backend()
# if is_ipython:
# from IPython import displayplt.ion()# if GPU is to be used
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")Transition = namedtuple('Transition',('state', 'action', 'next_state', 'reward'))class ReplayMemory(object):def __init__(self, capacity):self.memory = deque([], maxlen=capacity)def push(self, *args):"""Save a transition"""self.memory.append(Transition(*args))def sample(self, batch_size):return random.sample(self.memory, batch_size)def __len__(self):return len(self.memory)class DQN(nn.Module):def __init__(self, n_observations, n_actions):super(DQN, self).__init__()self.layer1 = nn.Linear(n_observations, 128)self.layer2 = nn.Linear(128, 128)self.layer3 = nn.Linear(128, n_actions)# Called with either one element to determine next action, or a batch# during optimization. Returns tensor([[left0exp,right0exp]...]).def forward(self, x):x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))return self.layer3(x)# BATCH_SIZE is the number of transitions sampled from the replay buffer
# GAMMA is the discount factor as mentioned in the previous section
# EPS_START is the starting value of epsilon
# EPS_END is the final value of epsilon
# EPS_DECAY controls the rate of exponential decay of epsilon, higher means a slower decay
# TAU is the update rate of the target network
# LR is the learning rate of the ``AdamW`` optimizer
BATCH_SIZE = 128
GAMMA = 0.99
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 1000
TAU = 0.005
LR = 1e-4# Get number of actions from gym action space
n_actions = env.action_space.n
# Get the number of state observations
state, info = env.reset()
n_observations = len(state)policy_net = DQN(n_observations, n_actions).to(device)
target_net = DQN(n_observations, n_actions).to(device)
target_net.load_state_dict(policy_net.state_dict())optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)
memory = ReplayMemory(10000)steps_done = 0def select_action(state):global steps_donesample = random.random()eps_threshold = EPS_END + (EPS_START - EPS_END) * \math.exp(-1. * steps_done / EPS_DECAY)steps_done += 1if sample > eps_threshold:with torch.no_grad():# t.max(1) will return the largest column value of each row.# second column on max result is index of where max element was# found, so we pick action with the larger expected reward.return policy_net(state).max(1)[1].view(1, 1)else:return torch.tensor([[env.action_space.sample()]], device=device, dtype=torch.long)episode_durations = []def plot_durations(show_result=False):plt.figure(1)durations_t = torch.tensor(episode_durations, dtype=torch.float)if show_result:plt.title('Result')else:plt.clf()plt.title('Training...')plt.xlabel('Episode')plt.ylabel('Duration')plt.plot(durations_t.numpy())# Take 100 episode averages and plot them tooif len(durations_t) >= 100:means = durations_t.unfold(0, 100, 1).mean(1).view(-1)means = torch.cat((torch.zeros(99), means))plt.plot(means.numpy())plt.pause(0.001) # pause a bit so that plots are updated# if is_ipython:# if not show_result:# display.display(plt.gcf())# display.clear_output(wait=True)# else:# display.display(plt.gcf())def optimize_model():if len(memory) < BATCH_SIZE:returntransitions = memory.sample(BATCH_SIZE)# Transpose the batch (see https://stackoverflow.com/a/19343/3343043 for# detailed explanation). This converts batch-array of Transitions# to Transition of batch-arrays.batch = Transition(*zip(*transitions))# Compute a mask of non-final states and concatenate the batch elements# (a final state would've been the one after which simulation ended)non_final_mask = torch.tensor(tuple(map(lambda s: s is not None,batch.next_state)), device=device, dtype=torch.bool)non_final_next_states = torch.cat([s for s in batch.next_stateif s is not None])state_batch = torch.cat(batch.state)action_batch = torch.cat(batch.action)reward_batch = torch.cat(batch.reward)# Compute Q(s_t, a) - the model computes Q(s_t), then we select the# columns of actions taken. These are the actions which would've been taken# for each batch state according to policy_netstate_action_values = policy_net(state_batch).gather(1, action_batch)# Compute V(s_{t+1}) for all next states.# Expected values of actions for non_final_next_states are computed based# on the "older" target_net; selecting their best reward with max(1)[0].# This is merged based on the mask, such that we'll have either the expected# state value or 0 in case the state was final.next_state_values = torch.zeros(BATCH_SIZE, device=device)with torch.no_grad():next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0]# Compute the expected Q valuesexpected_state_action_values = (next_state_values * GAMMA) + reward_batch# Compute Huber losscriterion = nn.SmoothL1Loss()loss = criterion(state_action_values, expected_state_action_values.unsqueeze(1))# Optimize the modeloptimizer.zero_grad()loss.backward()# In-place gradient clippingtorch.nn.utils.clip_grad_value_(policy_net.parameters(), 100)optimizer.step()if torch.cuda.is_available():num_episodes = 600
else:# num_episodes = 50num_episodes = 600for i_episode in range(num_episodes):# Initialize the environment and get it's statestate, info = env.reset()state = torch.tensor(state, dtype=torch.float32, device=device).unsqueeze(0)for t in count():action = select_action(state)observation, reward, terminated, truncated, _ = env.step(action.item())reward = torch.tensor([reward], device=device)done = terminated or truncatedif terminated:next_state = Noneelse:next_state = torch.tensor(observation, dtype=torch.float32, device=device).unsqueeze(0)# Store the transition in memorymemory.push(state, action, next_state, reward)# Move to the next statestate = next_state# Perform one step of the optimization (on the policy network)optimize_model()# Soft update of the target network's weights# θ′ ← τ θ + (1 −τ )θ′target_net_state_dict = target_net.state_dict()policy_net_state_dict = policy_net.state_dict()for key in policy_net_state_dict:target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU)target_net.load_state_dict(target_net_state_dict)if done:episode_durations.append(t + 1)plot_durations()breakprint('Complete')
plot_durations(show_result=True)
plt.ioff()
plt.show()相关文章:
Gymnasium--CartPole的测试基于DQN)
(3)Gymnasium--CartPole的测试基于DQN
1、使用Pytorch基于DQN的实现 1.1 主要参考 (1)推荐pytorch官方的教程 Reinforcement Learning (DQN) Tutorial — PyTorch Tutorials 2.0.1cu117 documentation (2) Pytorch 深度强化学习 – CartPole问题|极客笔记 2.2 pytorch官方的教程原理 待续,这两天时…...
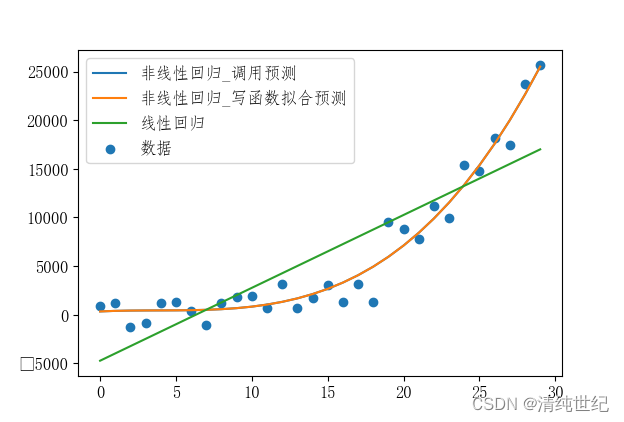
利用sklearn 实现线性回归、非线性回归
代码: import pandas as pd import numpy as np import matplotlib import random from matplotlib import pyplot as plt from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression# 创建虚拟数据 x np.array(r…...
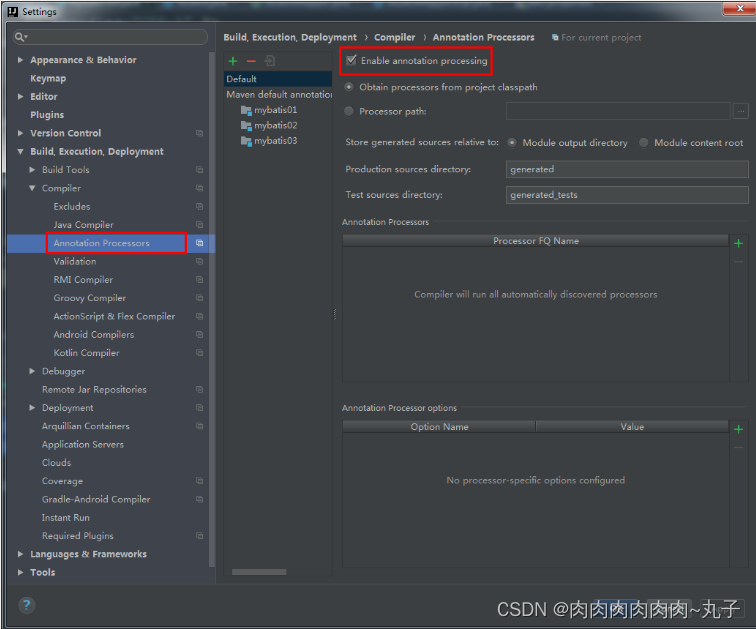
Java课题笔记~ MyBatis入门
一、ORM框架 当今企业级应用的开发环境中,对象和关系数据是业务实体的两种表现形式。业务实体在内存中表现为对象,在数据库中变现为关系数据。当采用面向对象的方法编写程序时,一旦需要访问数据库,就需要回到关系数据的访问方式&…...
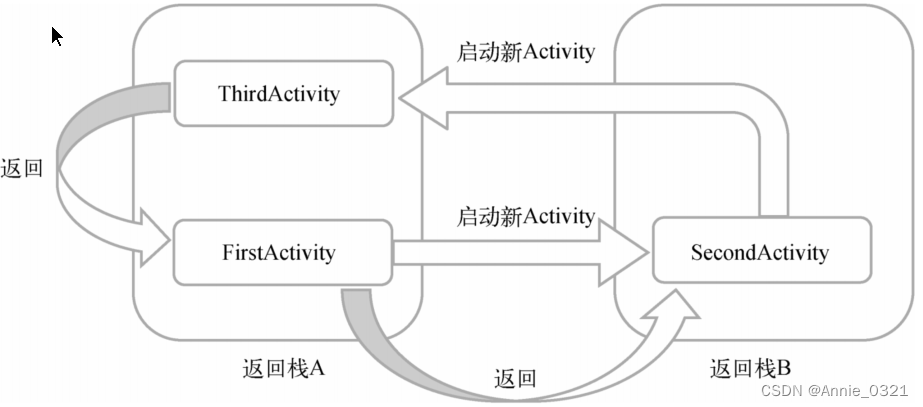
Activity的自启动模式
以下内容摘自郭霖《第一行代码》第三版 文章目录 Activity的自启动模式1.standard(默认)2.singleTop3.singleTask4.singleInstance Activity的自启动模式 启动模式一共有4种,分别是standard、singleTop、singleTask和singleInstance&#x…...

53数组的扩展
数组的扩展 扩展运算符Array.from()Array.of()实例方法:copyWithin()实例方法:find(),findIndex(),findLast(),findLastIndex()实例方法:fill()[实例方法:entries(),keys() 和 valu…...

Rust调试【三】
Local Debug: vscode CodeLLDB extension memory leak analysis: Rust and Valgrind FFI Memory wrapping: Foreign Function Interface FFI panic handling: Panic handling...

uniApp 对接安卓平板刷卡器, 读取串口数据
背景: 设备: 鸿合 电子班牌 刷卡对接 WS-B22CS, 安卓11; 需求: 将刷卡器的数据传递到自己的App中, 作为上下岗信息使用, 以完成业务; 对接方式: 1. 厂家技术首先推荐使用 接收自定义广播的方式来获取, 参考代码如下 对应到uniApp 中的实现如下 <template><view c…...

Go new 与 make
Go new 与 make 在Go语言中,"new"和"make"都是用于动态分配内存的关键字,但它们有不同的用途和区别。 "new": 在Go语言中,"new"是一个内建函数,用于值类型(基本类型和用户定…...
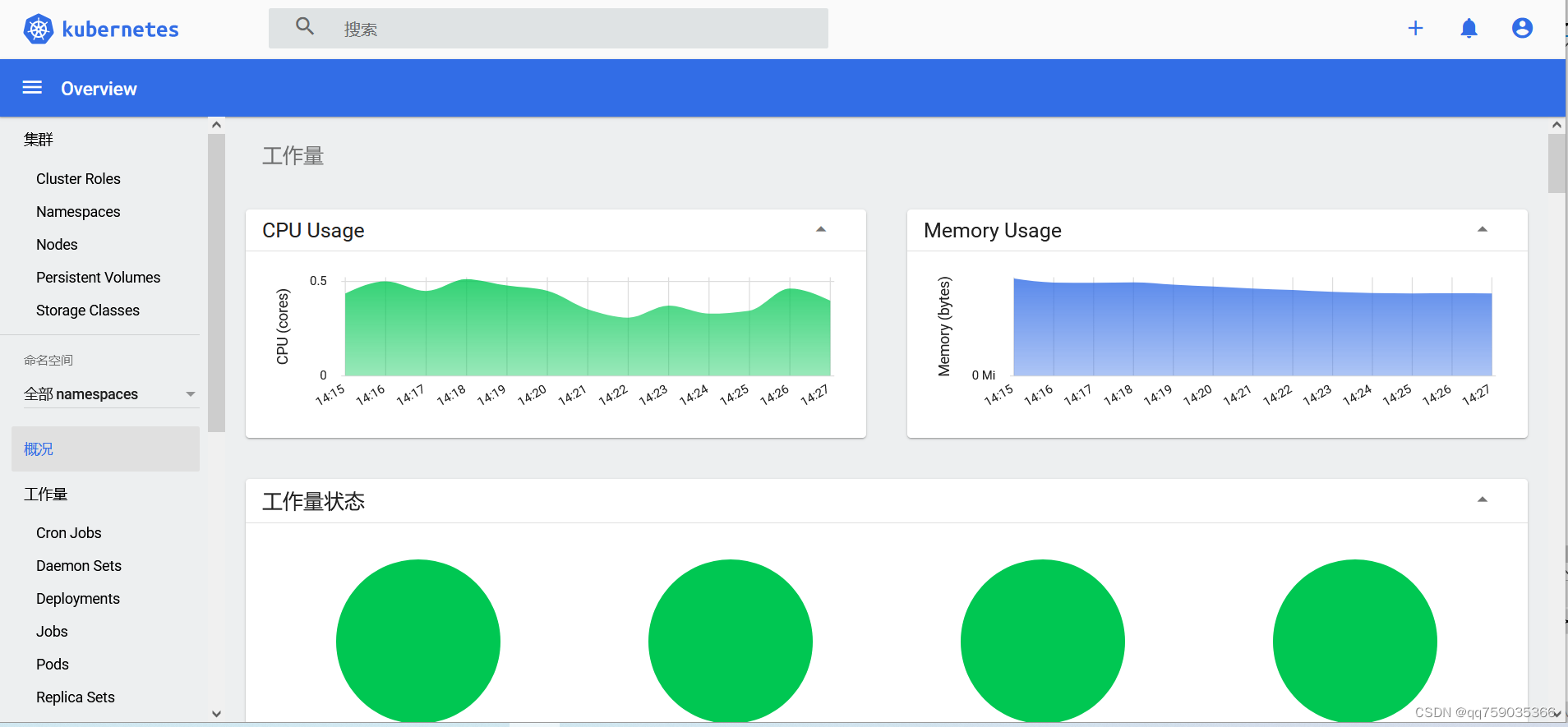
centos系统离线安装k8s v1.23.9最后一个版本并部署服务,docker支持的最后一个版本
注意:我这里的离线安装包是V1.23.9. K8S v1.23.9离线安装包下载: 链接:https://download.csdn.net/download/qq_14910065/88139255 这里包括离线安装所有的镜像,kubeadm,kubelet 和kubectl,calico.yaml&am…...

(学习笔记-内存管理)如何避免预读失效和缓存污染的问题?
传统的LRU算法存在这两个问题: 预读失效 导致的缓存命中率下降缓存污染 导致的缓存命中率下降 Redis的缓存淘汰算法是通过实现LFU算法来避免 [缓存污染] 而导致缓存命中率下降的问题(redis 没有预读机制) Mysql 和 Linux操作系统是通过改进…...
)
【arthas】入门与实战(一)
arthas 一、安装1. 安装与启动二、具体应用1.查看 dashboard1.1 各区域详解2.查看jvmweb访问查询垃圾回收器具体内容和大概的操作官网上都有,下面记录的是自己的一些操作、思考和查找的资料,帮助理解。 官网文档:https://arthas.aliyun.com/doc/ 一、安装 1. 安装与启动 …...

vim、awk、tail、grep的使用
vim命令 $定位到光标所在行的行末^定位到光标所在行的行首gg定位到文件的首行G定位到文件的末行dd删除光标所在行ndd删除n行(从光标所在行开始)D删除光标所在行,使之变为空白行x删除光标所在位置字符nx删除n个字符,从光标开始向后…...
vue拖拽改变宽度
1.封装组件ResizeBox.vue <template><div ref"resize" class"resize"><div ref"resizeHandle" class"handle-resize" /><slot /></div> </template> <script> export default {name: Resi…...
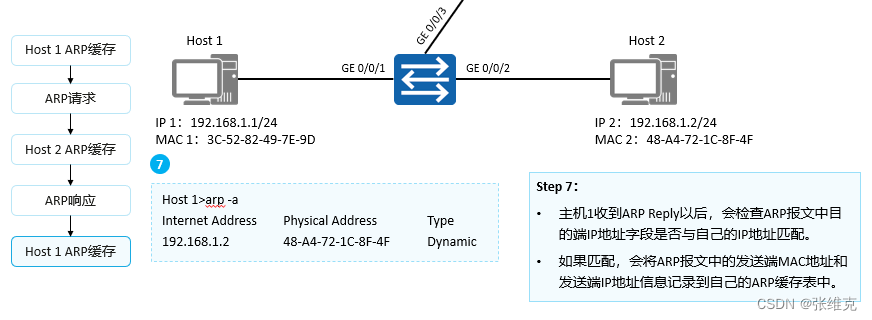
华为数通HCIA-ARP(地址解析协议)详细解析
地址解析协议 (ARP) ARP (Address Resolution Protocol)地址解析协议: 根据已知的IP地址解析获得其对应的MAC地址。 ARP(Address Resolution Protocol,地址解析协议)是根据IP地址获取数据链路层地址的一个…...
【Python机器学习】实验04(1) 多分类(基于逻辑回归)实践
文章目录 多分类以及机器学习实践如何对多个类别进行分类1.1 数据的预处理1.2 训练数据的准备1.3 定义假设函数,代价函数,梯度下降算法(从实验3复制过来)1.4 调用梯度下降算法来学习三个分类模型的参数1.5 利用模型进行预测1.6 评…...
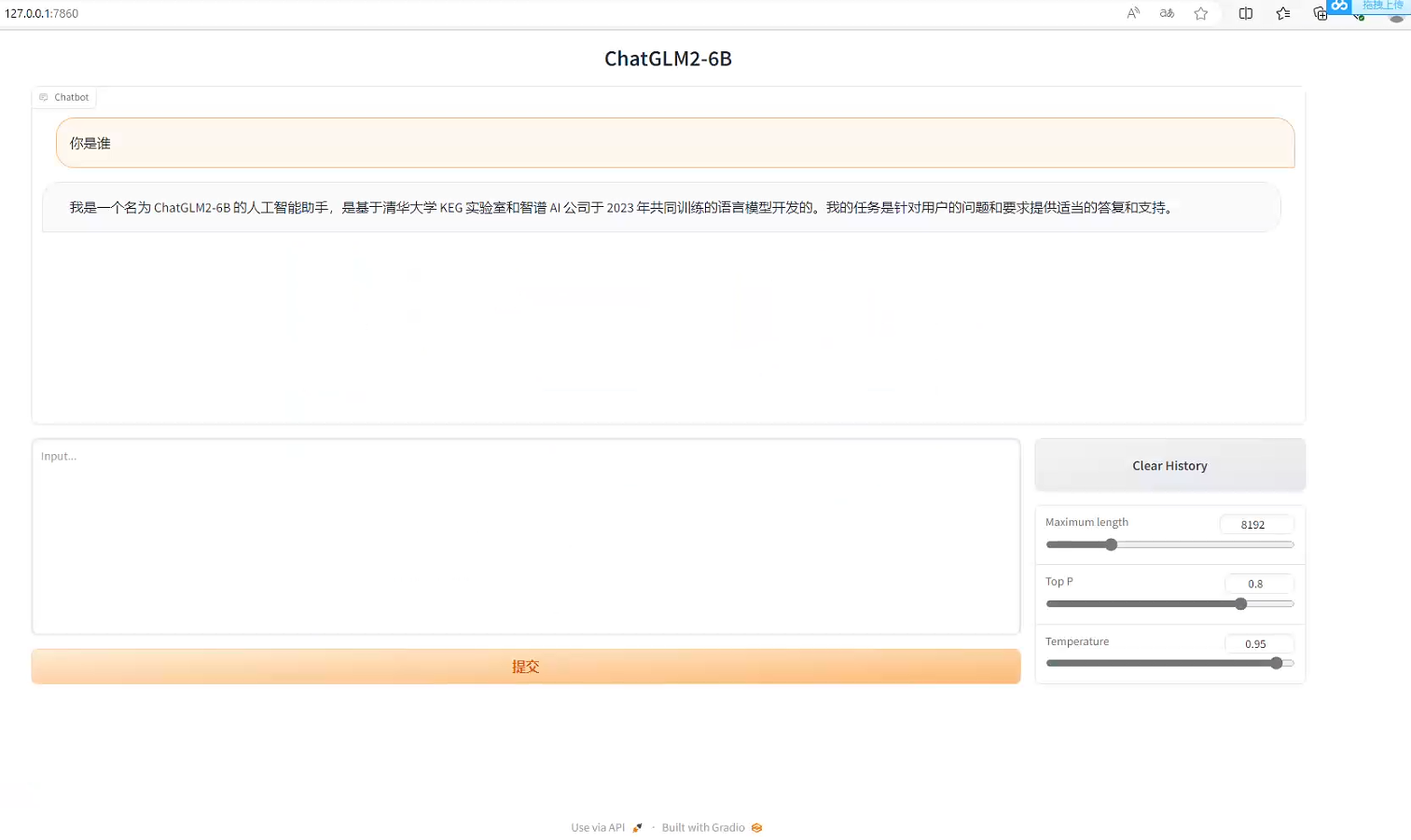
【ChatGLM_01】ChatGLM2-6B本地安装与部署(大语言模型)
基于本地知识库的问答 1、简介(1)ChatGLM2-6B(2)LangChain(3)基于单一文档问答的实现原理(4)大规模语言模型系列技术:以GLM-130B为例(5)新建知识库…...
扫描器搭建扩展使用教程)
谷歌Tsunami(海啸)扫描器搭建扩展使用教程
目录 介绍 下载地址 功能总结 原理 服务探测 漏洞检测 安装...

诚迈科技承办大同首届信息技术产业峰会,共话数字经济崭新未来
7月28日,“聚势而强共领信创”2023大同首届信息技术产业峰会圆满举行。本次峰会由中共大同市委、大同市人民政府主办,中国高科技产业化研究会国际交流合作中心、山西省信创协会协办,中共大同市云冈区委、大同市云冈区人民政府、诚迈科技&…...
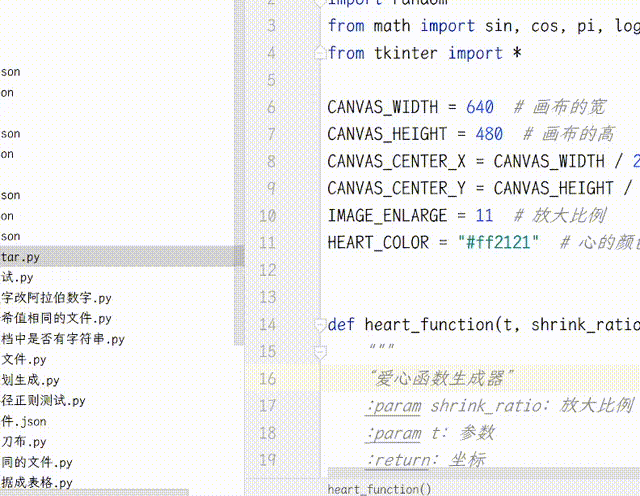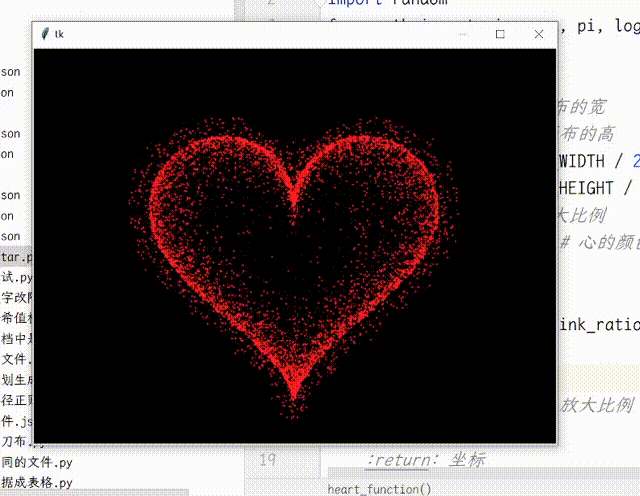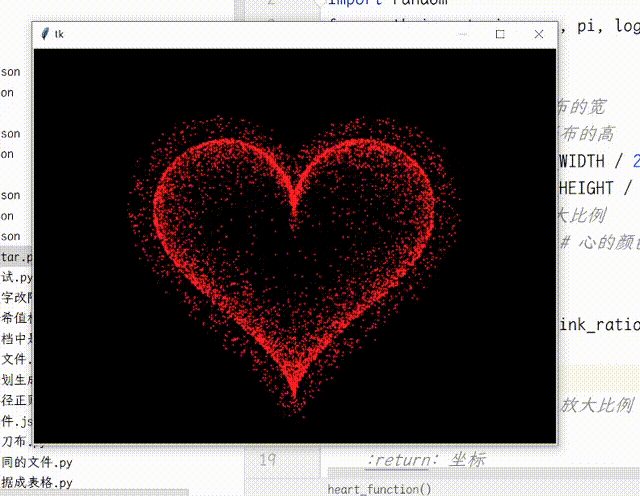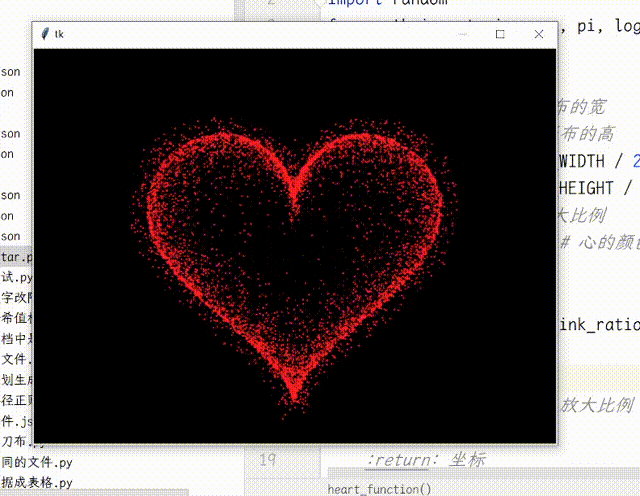
【Python】Python使用TK实现动态爱心效果
【Python】Python使用Tk实现动态爱心效果 画布使用了缓存机制,启动时绘制足够多的帧数,运行时一帧帧地取出来展示,明显更流畅,加快了程序执行速度。将控制跳动动画的函数从正弦函数换成了贝塞尔函数,贝塞尔函数更灵活…...
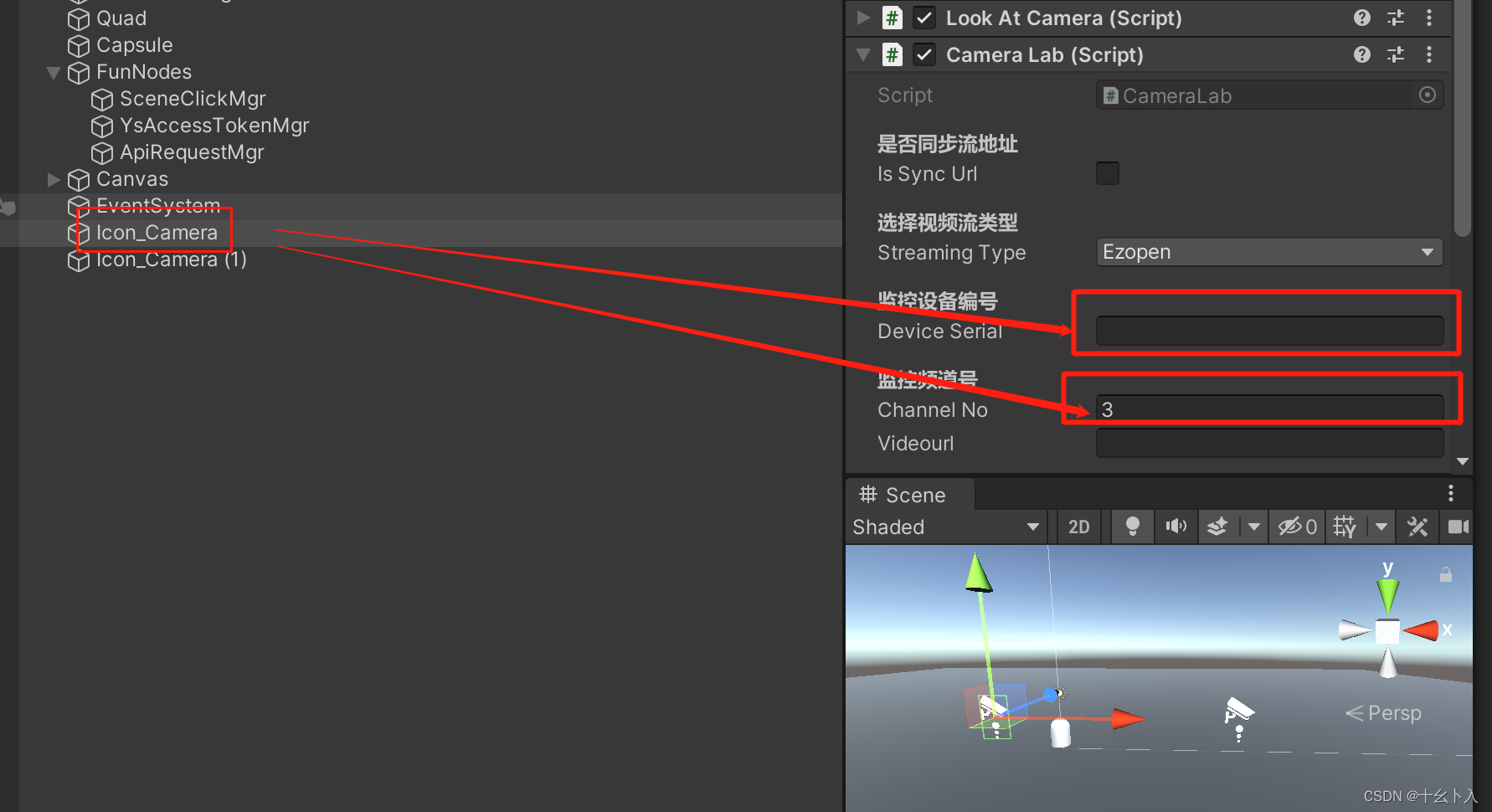
Unity3d C#快速打开萤石云监控视频流(ezopen)支持WebGL平台,替代UMP播放视频流的方案(含源码)
前言 Universal Media Player算是视频流播放功能常用的插件了,用到现在已经不知道躺了多少坑了,这个插件虽然是白嫖的,不过被甲方和领导吐槽的就是播放视频流的速度特别慢,可能需要几十秒来打开监控画面,等待的时间较…...

我想了解一下天津水阀机械有限公司规模怎么样
在阀门行业中,天津水阀机械有限公司(以下简称“天津水阀”)犹如一颗璀璨的明星,其规模和实力备受关注。接下来,让我们从多个维度深入了解这家企业的规模情况。一、占地面积与员工规模企业总部位于渤海经济核心圈的天津…...

长上下文语言模型的可复用推理模板设计与优化
1. 项目背景与核心价值在自然语言处理领域,长上下文语言模型(如GPT-4、Claude等)的崛起正在改变人机交互的范式。这类模型能够处理长达数万token的上下文窗口,为复杂推理任务提供了前所未有的可能性。然而在实际应用中,…...

安全施工日志软件适合哪些工程企业?先看安全是不是要放到一条业务线上
一、三个最常见的误区:以为日志是终点,其实它只是起点安全施工日志在很多项目上被当成“安全员的个人工作记录”。早上去现场转一圈,在本子上记几条问题,有空了誊到电子版里,月底归档交上去。看起来该做的事都做了&…...

别再死记硬背了!用三相霍尔传感器给BLDC电机测速和定位,这篇讲透了
三相霍尔传感器在BLDC电机控制中的实战解析:从测速到定位的完整框架 理解霍尔传感器的本质:超越数据手册的认知 第一次拿到三相双极性开关型霍尔传感器时,我盯着数据手册上的参数发呆——灵敏度、响应时间、工作电压...这些冰冷的数字对实际应…...

前端焦虑?收藏这份AI转型指南,助你从程序员变身AI产品经理!
文章分析了AI对前端编程领域的冲击,指出前端业务逻辑简单且GitHub语料丰富,适合转型AI工程师或产品经理。文章还探讨了AI在前端开发中的实际应用,如Cursor工具在需求分析、UI还原、业务逻辑实现等环节的效率提升,并指出AI完全替代…...

告别Steam客户端!WorkshopDL让你轻松下载创意工坊资源的终极指南
告别Steam客户端!WorkshopDL让你轻松下载创意工坊资源的终极指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否曾经因为Steam客户端占用太多系统资源而感到…...

3步解锁iOS设备:applera1n激活锁绕过工具深度解析
3步解锁iOS设备:applera1n激活锁绕过工具深度解析 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾面对一台因激活锁而无法使用的iOS设备感到束手无策?无论是二手购买的…...

DeepClaude技术解析:用Claude Code的Agent Loop驱动DeepSeek V4 Pro
上一篇:2026年5月AI模型排行榜:GPT-5.5、Claude Opus 4.7、DeepSeek V4三大阵营深度对比 下一篇:未完待续 核心结论:DeepClaude通过环境变量重定向和可选的Node.js代理架构,实现了Claude Code自主Agent循环与DeepSeek …...
)
别再让程序偷偷多开了!QtSingleApplication保姆级配置教程(附跨平台窗口置顶方案)
QtSingleApplication实战:彻底解决多开与窗口激活难题 你是否遇到过用户反复双击程序图标,导致同一应用弹出五六个窗口的尴尬场景?上周团队新发布的Markdown编辑器就因此收到一堆投诉——用户误操作多开导致配置文件互相覆盖。这种看似简单的…...

如何为Unity游戏实现零基础自动翻译:XUnity.AutoTranslator完整指南
如何为Unity游戏实现零基础自动翻译:XUnity.AutoTranslator完整指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 想要畅玩日文、韩文或其他外语Unity游戏却受困于语言障碍?XUni…...