大数据_Hadoop_Parquet数据格式详解
之前有面试官问到了parquet的数据格式,下面对这种格式做一个详细的解读。
参考链接 :
列存储格式Parquet浅析 - 简书
Parquet 文件结构与优势_parquet文件_KK架构的博客-CSDN博客
Parquet文件格式解析_parquet.block.size_david'fantasy的博客-CSDN博客
Parquet文件组织格式
行组(Row Group)
按照行将数据物理上划分为多个单元,每一个行组包含一定的行数。一个行组包含这个行组对应的区间内的所有列的列块。
官方建议:
更大的行组意味着更大的列块,使得能够做更大的序列IO。我们建议设置更大的行组(512MB-1GB)。因为一次可能需要读取整个行组,所以我们想让一个行组刚好在一个HDFS块中。因此,HDFS块的大小也需要被设得更大。一个最优的读设置是:1GB的行组,1GB的HDFS块,1个HDFS块放一个HDFS文件。
列块(Column Chunk)
在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。一个列块由多个页组成。
页(Page)
每一个列块划分为多个页,页是压缩和编码的单元,对数据模型来说页是透明的。在同一个列块的不同页可能使用不同的编码方式。官方建议一个页为8KB。
==========================================================
Parquet 文件组织格式图示详解
图片1
图片2
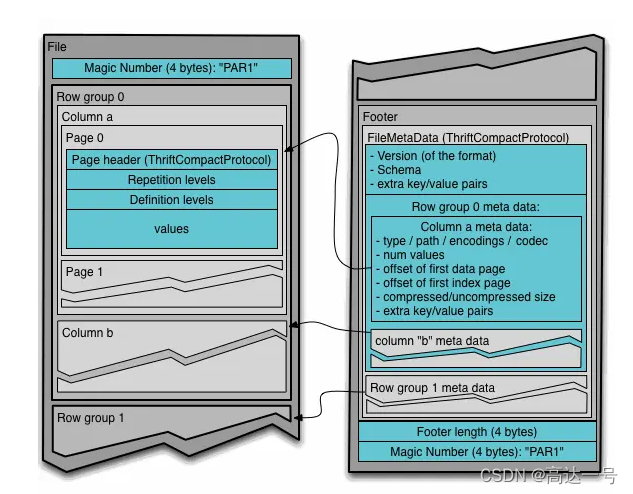
通过上面的图片1,我们知道parquet 主要由Header, Data Block, Footer 三个部分构成
Header
每个 Parquet 的首尾各有一个大小为 4 bytes ,内容为 PAR1 的 Magic Number,用来标识这个文件是 Parquet 文件。
Data Block
中间的 Data Block 是具体存放数据的区域,由多个行组(Row Group)组成。
行组 (Row Group),是按照行将数据在物理上分成多个单元,每一个行组包含一定的行数。
比如一个文件有10000条数据,被划分成两个 Row Group,那么每个 Row Group 有 5000 行数据。
在每个行组(Row Group)中,数据按列连续的存储在这个行组文件中,每列的所有数据组合成一个 Column Chunk(列块),一个列块拥有相同的数据类型,不同的列块可以有不同的压缩格式。
在每个列块(Column Chunk)中,数据按 Page 为最小单元来存储,Page 按内容分为 Data page 和 Index Page。(目前Parquet中还不支持索引页,但是在后面的版本中增加。)
这样逐层设计的目的在于:
多个 Row Group 可以实现数据的并行;
不同的 Column Chunk 用来实现列存储;
进一步分割成 Page,可以实现更细粒度的访问;
Footer
Footer部分由 File Metadata、**Footer Length **和 **Magic Number **三部分组成。
Footer Length 是一个 4 字节的数据,用于标识 Footer 部分的大小,帮助找到 Footer 的起始指针位置。
Magic Number同样是PAR1。
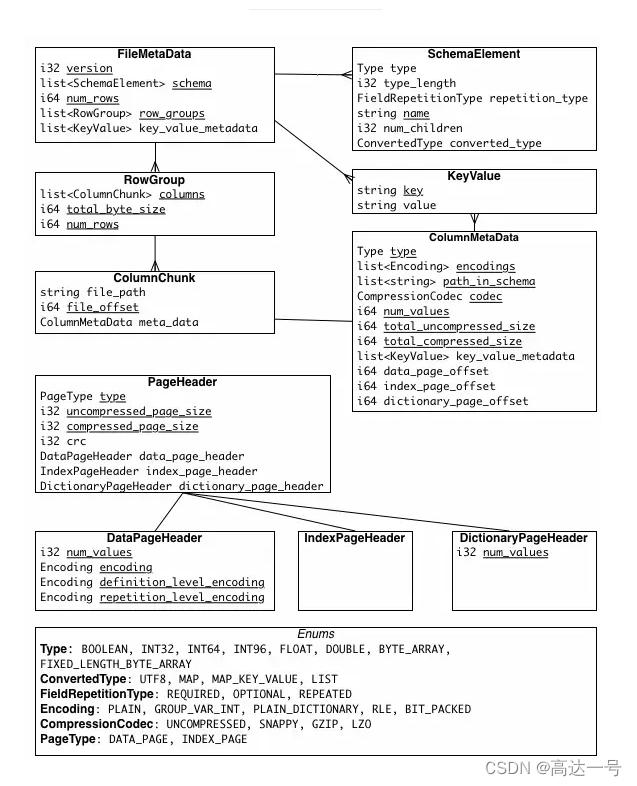
File Metada包含了非常重要的信息,包括Schema和每个 Row Group 的 Metadata。
每个 Row Group 的 Metadata 又由各个 Column 的 Metadata 组成,每个 Column Metadata 包含了其Encoding、Offset、Statistic 信息等等。
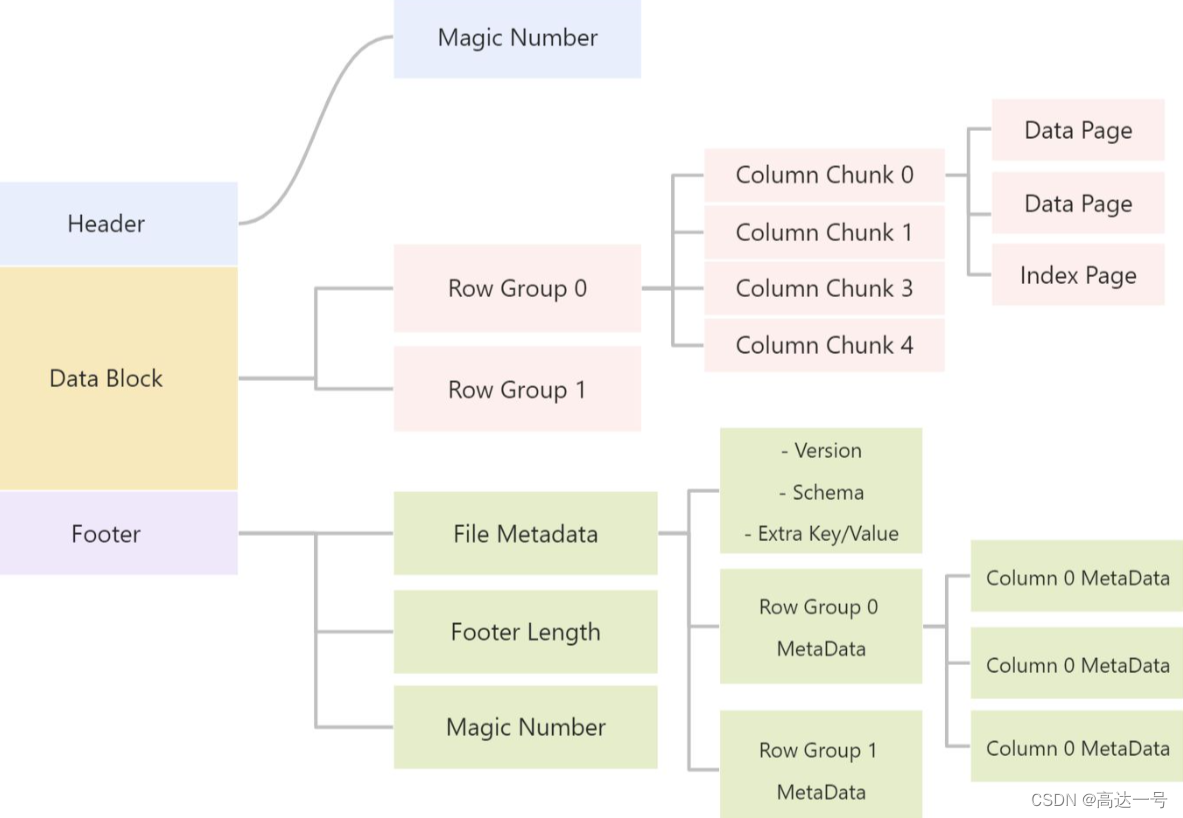
Parquet 文件的优势
(1) 映射下推(Project PushDown)/ 列裁剪(offset of first data page -> 列的起始结束位置)
说到列式存储的优势,映射下推是最突出的,它意味着在获取表中原始数据时只需要扫描查询中需要的列,由于每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容。
在Parquet中原生就支持映射下推,执行查询的时候可以通过Configuration传递需要读取的列的信息,这些列必须是Schema的子集,映射每次会扫描一个Row Group的数据,然后一次性得将该Row Group里所有需要的列的Cloumn Chunk都读取到内存中,每次读取一个Row Group的数据能够大大降低随机读的次数,除此之外,Parquet在读取的时候会考虑列是否连续,如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存。
Parquet 列式存储方式可以方便地在读取数据到内存之间找到真正需要的列,具体是:
并行的 task 对应一个Parquet的行组(row group),每一个task内部有多个列块,列快连续存储,同一列的数据存储在一起,任务中先去访问 footer 的 File metadata,其中包括每个行组的 metadata,里面的 Column Metadata 记录 offset of first data page 和 offset of first index page,这个记录了每个不同列的起始位置,这样就找到了需要的列的开始和结束位置。
其中 data 和 index 是对数值和字符串数据的处理方式,对于字符变量会存储为key/value对的字典转化为数值
(2)谓词下推(Column Statistic -> 列的range和枚举值信息)
谓词下推的基本思想:
尽可能用过滤表达式提前过滤数据,以使真正执行时能直接跳过无关的数据。
比如这个 SQL:
select item.name, order.* from order , item where order.item_id = item.id and item.category = 'book';
使用谓词下推,会将表达式 item.category = ‘book’ 下推到 join 条件 order.item_id = item.id 之前。
再往高大上的方面说,就是将过滤表达式下推到存储层直接过滤数据,减少传输到计算层的数据量。
Parquet 中 File metadata 记录了每一个 Row group 的 Column statistic,包括数值列的 max/min,字符串列的枚举值信息,比如如果 SQL 语句中对一个数字列过滤 >21 以上的,因此 File 0 的行组 1 和 File 1 的行组 0 不需要读取
另外Parquet未来还会增加诸如Bloom Filter和Index等优化数据,更加有效的完成谓词下推。
(3)压缩效率高,占用空间少,存储成本低
Parquet 这类列式存储有着更高的压缩比,相同类型的数据为一列存储在一起方便压缩,不同列可以采用不同的压缩方式,结合Parquet 的嵌套数据类型,可以通过高效的编码和压缩方式降低存储空间提高 IO 效率
===============
HDFS 上的Parquet 性能调优
如果采用HDFS文件系统,影响Parquet文件读写性能的参数主要有两个,dfs.blocksize和parquet.block.size
- dfs.blocksize
控制HDFS file中每个block的大小,该参数主要影响计算任务的并行度,例如在spark中,一个map操作的默认分区数=(输入文件的大小/dfs.block.size)*输入的文件数(分区数等于该操作产生的任务数),如果dfs.block.size设置过大或过小,都会导致
生成的Task数量不合理,因此应根据实际计算所涉及的输入文件大小以及executor数量决定何时的值。
- parquet.block.size
控制parquet的Row Group大小,一般情况下较大的值可以组织更大的连续存储的Column Chunk,有利于提升I/O性能,但上面也提到Row group是数据读写时候的缓存单元,每个需要读写的parquet文件都需要在内存中占据Row Group size设置的内存空间(读取的情况,由于可能跳过部分列,占据的内存会小于Row Group size),这样更大的Row Group size意味着更多的内存开销。同时设置该值时还需要考虑dfs.blocksize的值,尽量让Row Group size等同于HDFS一个block的大小,因为单个Row Group必须在一个计算任务中被处理,如果一个Row Group跨越了多个hdfs block可能会导致额外的远程数据读取。一般推荐的参数一个Row group大小1G,一个HDFS块大小1G,一个HDFS文件只含有一个块。
在Spark中可以使用如下方式修改默认配置参数:
val ONE_GB = 1024 * 1024 * 1024sc.hadoopConfiguration.setInt("dfs.blocksize", ONE_GB)sc.hadoopConfiguration.setInt("parquet.block.size", ONE_GB)Parquet 性能测试
压缩

上图是展示了使用不同格式存储TPC-H和TPC-DS数据集中两个表数据的文件大小对比,可以看出Parquet较之于其他的二进制文件存储格式能够更有效的利用存储空间,而新版本的Parquet(2.0版本)使用了更加高效的页存储方式,进一步的提升存储空间。
查询

上图展示了Twitter在Impala中使用不同格式文件执行TPC-DS基准测试的结果,测试结果可以看出Parquet较之于其他的行式存储格式有较明显的性能提升。
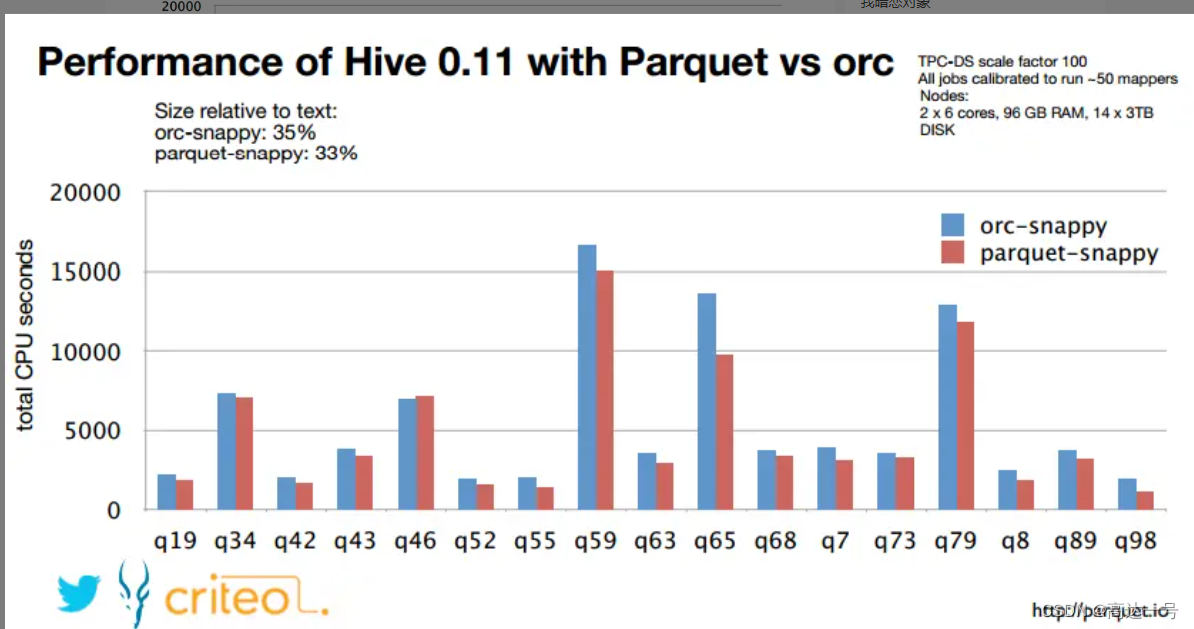
上图展示了criteo公司在Hive中使用ORC和Parquet两种列式存储格式执行TPC-DS基准测试的结果,测试结果可以看出在数据存储方面,两种存储格式在都是用snappy压缩的情况下量中存储格式占用的空间相差并不大,查询的结果显示Parquet格式稍好于ORC格式,两者在功能上也都有优缺点,Parquet原生支持嵌套式数据结构,而ORC对此支持的较差,这种复杂的Schema查询也相对较差;而Parquet不支持数据的修改和ACID,但是ORC对此提供支持,但是在OLAP环境下很少会对单条数据修改,更多的则是批量导入。
相关文章:
大数据_Hadoop_Parquet数据格式详解
之前有面试官问到了parquet的数据格式,下面对这种格式做一个详细的解读。 参考链接 : 列存储格式Parquet浅析 - 简书 Parquet 文件结构与优势_parquet文件_KK架构的博客-CSDN博客 Parquet文件格式解析_parquet.block.size_davidfantasy的博客-CSDN博…...

Docker的安装和部署
目录 一、Docker的安装部署 (1)关闭防火墙 (2)关闭selinux (3)安装docker引擎 (4)启动docker (5)设置docker自启动 (6)测试doc…...

FPGA项目实现:秒表设计
文章目录 项目要求项目设计 项目要求 设计一个时钟秒表,共六个数码管,前两位显示分钟,中间两位显示时间秒,后两位显示毫秒的高两位,可以通过按键来开始、暂停以及重新开始秒表的计数。 项目设计 为完成此项目共设计…...
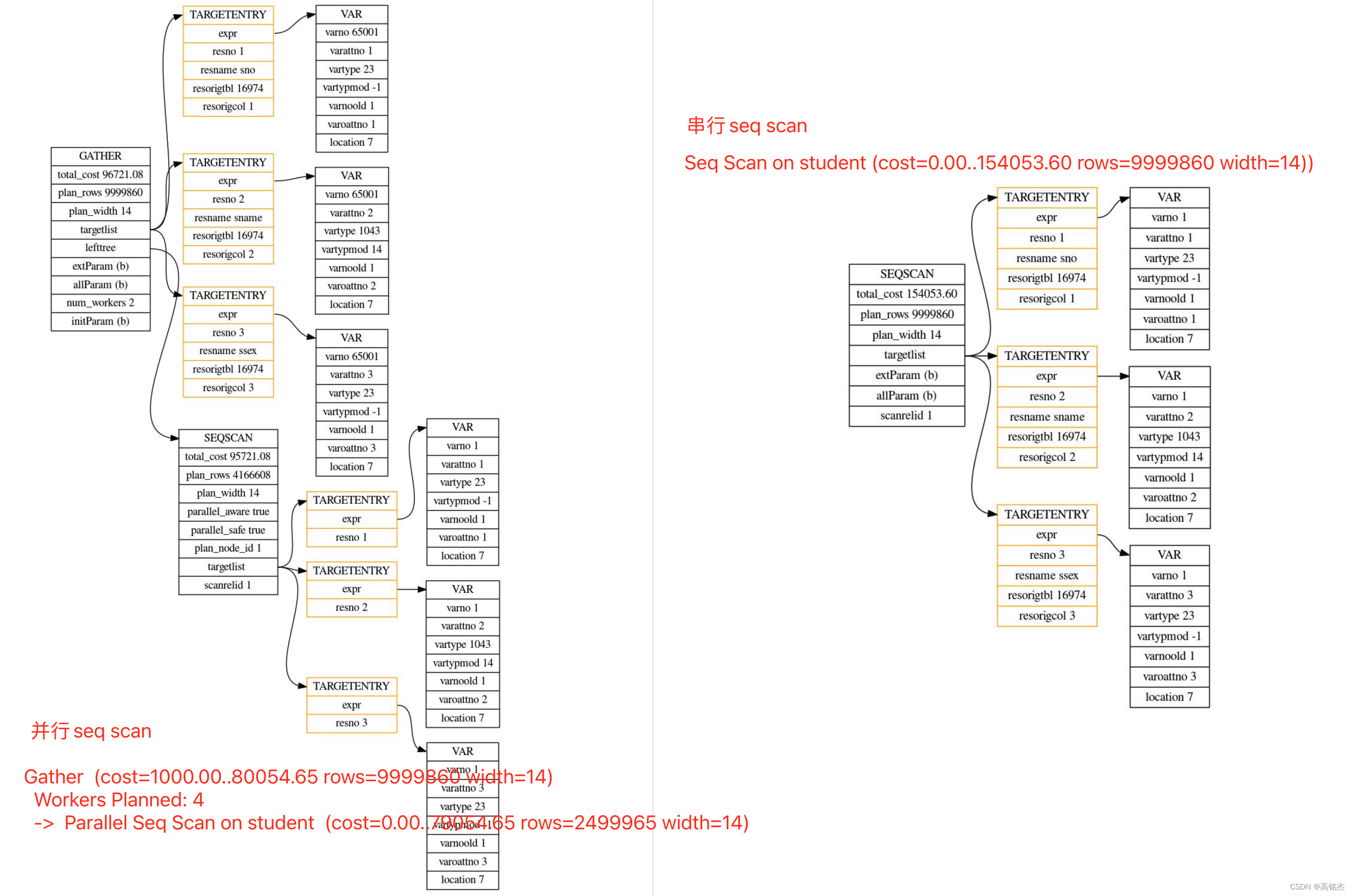
Postgresql源码(109)并行框架实例与分析
1 PostgreSQL并行参数 系统参数 系统总worker限制:max_worker_processes 默认8 系统总并发限制:max_parallel_workers 默认8 单Query限制:max_parallel_workers_per_gather 默认2 表参数限制:parallel_workers alter table tbl …...

ES派生类的prototype方法中,不能访问super的解决方案
1 下面的B.prototype.compile方法中,无法访问super class A {compile() {console.log(A)} }class B extends A {compile() {super.compile()console.log(B)} }B.prototype.compile function() {super.compile() // 报错,不可以在此处使用superconsole.…...

使用adb通过电脑给安卓设备安装apk文件
最近碰到要在开发板上安装软件的问题,由于是开发板上的安卓系统没有解析apk文件的工具,所以无法通过直接打开apk文件来安装软件。因此查询各种资料后发现可以使用adb工具,这样一来可以在电脑上给安卓设备安装软件。 ADB 就是连接 Android 手…...
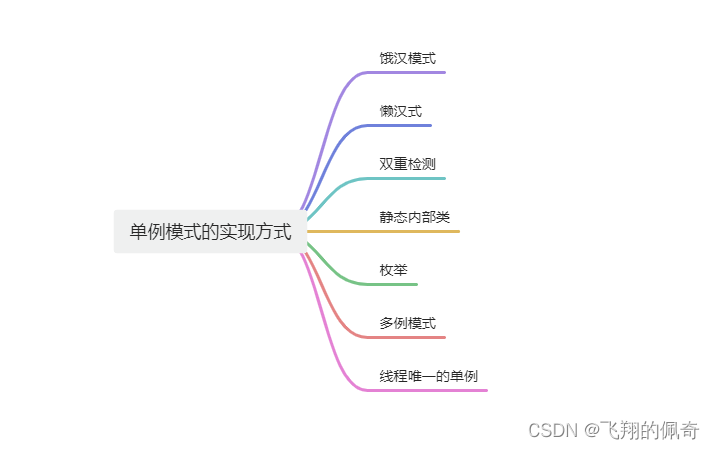
113、单例Bean是单例模式吗?
单例Bean是单例模式吗? 通常来说,单例模式是指在一个JVM中,一个类只能构造出来一个对象,有很多方法来实现单例模式,比如懒汉模式,但是我们通常讲的单例模式有一个前提条件就是规定在一个JVM中,那如果要在两个JVM中保证单例呢?那可能就要用分布式锁这些技术,这里的重点…...
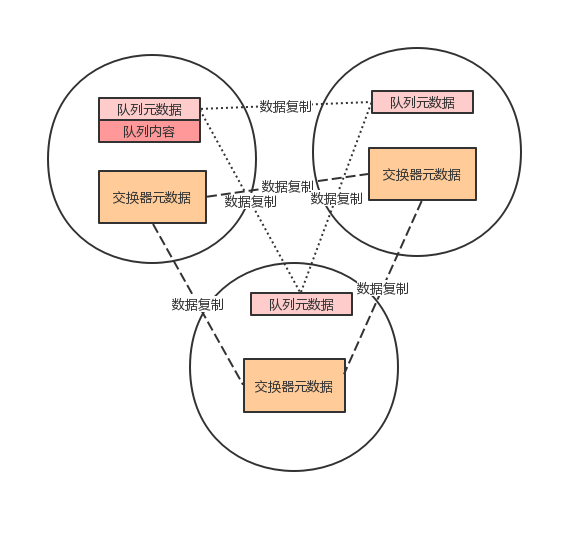
RabbitMQ 集群部署
RabbiMQ 是用 Erlang 开发的,集群非常方便,因为 Erlang 天生就是一门分布式语言,但其本身并不支持负载均衡。 RabbitMQ 的集群节点包括内存节点、磁盘节点。RabbitMQ 支持消息的持久化,也就是数据写在磁盘上,最合适的方案就是既有内存节点,又有磁盘节点。 RabbitMQ 模式大…...

2023年【零声教育】13代C/C++Linux服务器开发高级架构师课程体系分析
对于零声教育的C/CLinux服务器高级架构师的课程到2022目前已经迭代到13代了,像之前小编也总结过,但是课程每期都有做一定的更新,也是为了更好的完善课程跟上目前互联网大厂的岗位技术需求,之前课程里面也包含了一些小的分支&#…...

iOS开发-实现热门话题标签tag显示控件
iOS开发-实现热门话题标签tag显示控件 话题标签tag显示非常常见,如选择你的兴趣,选择关注的群,超话,话题等等。 一、效果图 二、实现代码 由于显示的是在列表中,这里整体控件是放在UITableViewCell中的。 2.1 标签…...

linux系统磁盘性能监视工具iostat
目录 一、iostat介绍 二、命令格式 三、命令参数 四、参考命令:iostat -c -x -k -d 1 (一)输出CPU 属性值 (二)CPU参数分析 (三)磁盘每一列的含义 (四)磁盘参数分…...

BT#蓝牙 - Link Policy Settings
对于Classic Bluetooth的Connection,有一个Link_Policy_Settings,是HCI configuration parameters中的一个。 Link_Policy_Settings 参数决定了本地链路管理器(Link Manager)在收到来自远程链路管理器的请求时的行为,还用来决定改变角色(rol…...

c++ | 动态链接库 | 小结
//环境 linux c //生成动态链接库 //然后调用动态链接库中的函数//出现的问题以及解决//注意在win和在linux中调用动态链接库的函数是不一样的//在要生成链接库的cpp文件中比如以后要调用本文件中的某个函数,需要extern "c" 把你定的函数“再封装”避免重…...

如何使用Flask-SQLAlchemy来管理数据库连接和操作数据?
首先,我们需要安装Flask-SQLAlchemy。你可以使用pip来安装它,就像这样: pip install Flask-SQLAlchemy好了,现在我们已经有了一个可以操作数据库的工具,接下来让我们来看看如何使用它吧! 首先,…...
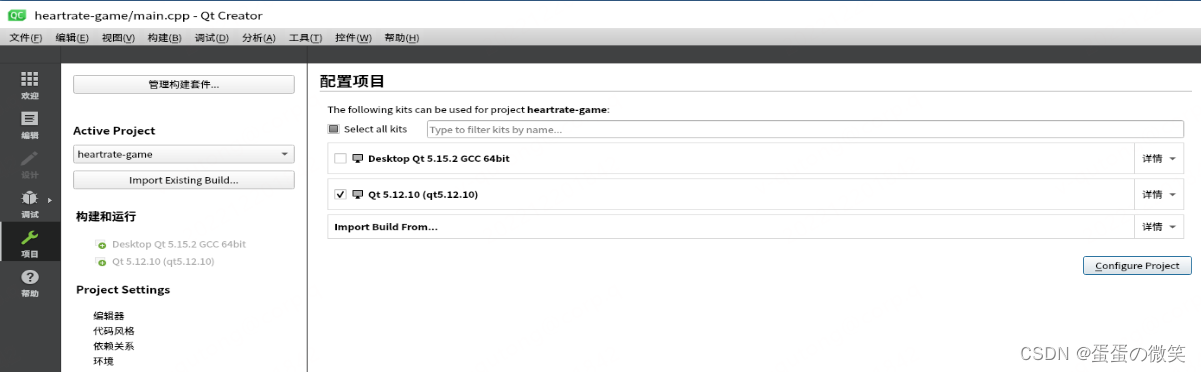
麒麟-飞腾Kylin-V4桌面arm64系统静态编译QT
1.系统具体版本: 2. 因为此版本的源很老了,需要修改版本的源,才能正常更新各种软件,否则,你连麒麟商店都打不开。 sudo vi /etc/apt/sources.list 选择你系统对应版本的源地址: #4.0.2桌面版本: deb ht…...

CentOS 项目发出一篇奇怪的博文
导读最近,在红帽限制其 RHEL 源代码的访问之后,整个社区围绕这件事发生了很多事情。 CentOS 项目发出一篇奇怪的博文 周五,CentOS 项目董事会发出了一篇模糊不清的简短博文,文中称,“发展社区并让人们更容易做出贡献…...

【Mybatis-Plus】or拼接
Mybatis-Plus的or拼接是个坑: 这是需要的结果: queryWrapper.and(c->c.or(a->a.eq("qcs3.status", "SIGNING").eq("qcs.status", "SIGNING")).or(b->b.eq("qcs.status","INVALIDING&q…...
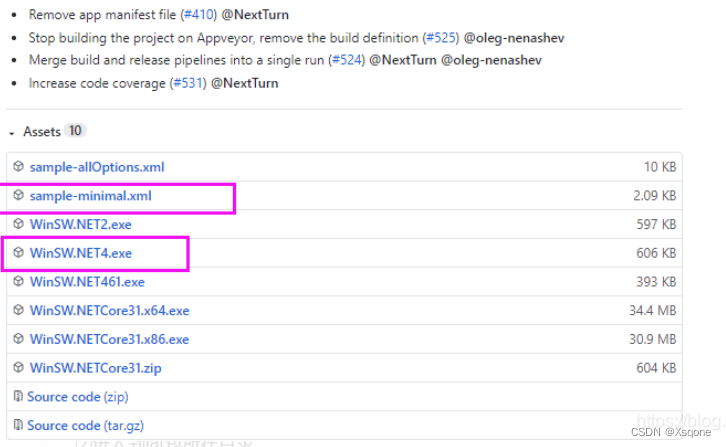
SpringBoot项目部署在Windows与Centos上
文章目录 Windows部署一、github上下载文件winsw二、文件目录三、编辑xml文件四、安装服务五、启动服务六、把jar包放到项目外面七、添加限制内存 Linux部署一、准备二、服务三、操作 Windows部署 windows部署服务借鉴于此篇博文 一、github上下载文件winsw 点击链接下载下图…...

网站服务器出错的原因分析和解决方法
网站在日常运行的过程中,难免会遇见一些问题,这次我们就来分析关于网站服务器出错、服务器异常的原因以及如何解决网站服务器错误的方法。 如何知道是网站服务器的问题呢? 只要网站不能正常访问运行,那么一定会反馈相关的错误代码和原…...

电影推荐系统】系统初步搭建及离线个性化推荐
上篇博文我们已经写完统计推荐部分,现在我们将使用VueElement-uiSpringBoot来快速搭建系统,展示出电影,并介绍个性化推荐部分。 1 系统页面设计 初步是想设计一个类似豆瓣电影推荐系统 用户登陆后,可以查看高分电影可以查看推荐…...

STM32L4实战:用RTC唤醒定时器实现33秒超长待机,实测功耗从52mA降到2.2mA
STM32L4超低功耗实战:从52mA到2.2mA的RTC唤醒优化全解析 当一块STM32L4开发板的功耗从52mA骤降到2.2mA,这不仅仅是数字的变化——它意味着智能穿戴设备的续航从1天延长到3周,工业传感器节点可以摆脱电源线的束缚,便携医疗设备的安…...

在 Taotoken 上观测多模型 API 调用用量与成本明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 上观测多模型 API 调用用量与成本明细 对于使用多个大模型 API 的开发者而言,清晰、透明地掌握调用情况和…...

从C代码到汇编:图解函数调用栈中rsp和rbp的“职责分工”
从C代码到汇编:图解函数调用栈中rsp和rbp的"职责分工" 在计算机程序的执行过程中,函数调用是最基础也最核心的概念之一。当我们从高级语言如C/C深入到汇编层面时,会发现函数调用的背后隐藏着一套精密的栈帧管理机制。本文将带您走进…...

跨越语言障碍的智能方案:DeepL Chrome扩展助力无缝多语言浏览
跨越语言障碍的智能方案:DeepL Chrome扩展助力无缝多语言浏览 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 想象一下,当你浏览外文网页时…...
)
【信息科学与工程学】【产品体系】第十二篇 制造业生产加工07 精度与误差库 ——智能制造(4)
表7.100.301—表7.100.329:精度控制高级技术与应用 一、误差补偿与校正(301-305) 表7.100.301:实时误差补偿 编号 概念/技术 在精度控制中的核心价值 7.100.301.1 实时误差补偿 在系统运行过程中,动态检测误差并实时施加修正的技术。相比离线补偿,能更好地跟踪…...

用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法
用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法 当数学建模问题遇上Python编程,会产生怎样的化学反应?本文将以2020年高教杯数学建模国赛B题"穿越沙漠"为例,带你从零开始构建一个完整的路径规划…...

性价比高的AI应用厂家
核心结论: 当前市面上AI应用厂商众多,但真正能做到“高性价比”的,必须同时满足三个条件:功能覆盖企业核心痛点(管理、销售、运营)、落地效果可量化(降本增效有数据支撑)、成本可控&…...

大功率充电桩生产厂家:高效能产品的选择与评估标准
一、行业背景与权威数据据中国电动汽车充电基础设施促进联盟(EVCIPA)数据显示,截至2026年2月底,我国电动汽车充电基础设施(枪)总数达到2101.0万个,同比增长47.8%。其中,公共充电设施…...

3大核心能力解析:Vin象棋如何用深度学习重塑中国象棋AI辅助体验
3大核心能力解析:Vin象棋如何用深度学习重塑中国象棋AI辅助体验 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi Vin象棋是一款基于YOLOv5深度学…...

4. 大型场馆大空间挡烟垂壁选型与布设
大型场馆、商业综合体、中庭展厅这类大空间建筑,空间跨度大、层高较高,传统隔断无法满足排烟分区要求,合理选用与布设挡烟垂壁,是解决大空间防排烟难题的核心途径。大空间场景在挡烟垂壁选型上,需优先适配大跨度、高空…...