根据Pytorch源码实现的 ResNet18
一,类模块定义:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensorclass ResBlock(nn.Module):def __init__(self, inchannel, outchannel, stride=1) -> None:super(ResBlock, self).__init__()# 这里定义了残差块内连续的2个卷积层self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(outchannel)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(outchannel)self.downsample = nn.Sequential()if stride != 1 or inchannel != outchannel:# shortcut,这里为了跟2个卷积层的结果结构一致,要做处理self.downsample = nn.Sequential(nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(outchannel))def forward(self, x):out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = out + self.downsample(x)out = self.relu(out)return outclass ResNet18(nn.Module):def __init__(self, ResBlock, num_classes=1000) -> None:super(ResNet18, self).__init__()self.inchannel = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)self.layer1 = self.make_layer(ResBlock, 64, 2, stride=1)self.layer2 = self.make_layer(ResBlock, 128, 2, stride=2)self.layer3 = self.make_layer(ResBlock, 256, 2, stride=2)self.layer4 = self.make_layer(ResBlock, 512, 2, stride=2)self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))self.fc = nn.Linear(512, num_classes)def forward(self, x: Tensor) -> Tensor:out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.maxpool(out)out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = self.avgpool(out)out = out.view(out.size(0), -1)out = self.fc(out)return outdef make_layer(self, block, channels, num_blocks, stride):strides = [stride] + [1] * (num_blocks - 1)layers = []for stride in strides:layers.append(block(self.inchannel, channels, stride))self.inchannel = channelsreturn nn.Sequential(*layers)if __name__ == '__main__':model = ResNet18(ResBlock)print(model)二,对比Pytorch官方提供的预训练模型 加载xxx.pht文件
# 方案一: 使用官方自带的resnet18加载预训练模型
from torchvision import models# 当 xxx.pth预训练模型不存在时,可以联网直接下载
# model = models.resnet18(weights=ResNet18_Weights.DEFAULT) # 载入预训练模型
model = models.resnet18()# 加载与训练模型
weights_dict = torch.load('C:\\Users\\torch\\hub\\checkpoints\\resnet18-f37072fd.pth')model.load_state_dict(weights_dict, strict=True)
print(model)# 方案二: 使用自定义的ResNet18加载预训练模型
model = ResNet18(ResBlock)
weights_dict = torch.load('C:\\Users\\torch\\hub\\checkpoints\\resnet18-f37072fd.pth')model.load_state_dict(weights_dict, strict=True)
print(model)
三,用自定义的ResNet18记载Pytorch官网提供的预训练模型,训练自己的图像分类数据,完整代码
import matplotlib.pyplot as plt
from torchvision.models import ResNet18_Weightsimport warnings
warnings.filterwarnings("ignore") # 忽略烦人的红色提示import time
import os
from tqdm import tqdm
import pandas as pd
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F# 导入训练需使用的工具包
from torchvision import models
import torch.optim as optim
from torch.optim import lr_schedulerfrom sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score''' 运行一个 batch 的训练,返回当前 batch 的训练日志 '''
log_train = {}
def train_one_batch(images, labels, epoch, batch_idx):# 获得一个 batch 的数据和标注images = images.to(device)labels = labels.to(device)# images = [32, 3, 224, 224]outputs = model(images) # 输入模型,执行前向预测(mat1 and mat2 shapes cannot be multiplied (32x25088 and 512x30))loss = criterion(outputs, labels) # 计算当前 batch 中,每个样本的平均交叉熵损失函数值# 优化更新权重optimizer.zero_grad()loss.backward()optimizer.step()# 获取当前 batch 的标签类别和预测类别_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别preds = preds.cpu().numpy()loss = loss.detach().cpu().numpy()outputs = outputs.detach().cpu().numpy()labels = labels.detach().cpu().numpy()log_train['epoch'] = epochlog_train['batch'] = batch_idx# 计算分类评估指标log_train['train_loss'] = losslog_train['train_accuracy'] = accuracy_score(labels, preds)log_train['train_precision'] = precision_score(labels, preds, average='macro')log_train['train_recall'] = recall_score(labels, preds, average='macro')log_train['train_f1-score'] = f1_score(labels, preds, average='macro')return log_train''' 在整个测试集上评估,返回分类评估指标日志 '''
def evaluate_testset(epoch):loss_list = []labels_list = []preds_list = []with torch.no_grad():for images, labels in test_loader: # 生成一个 batch 的数据和标注images = images.to(device)labels = labels.to(device)outputs = model(images) # 输入模型,执行前向预测loss = criterion(outputs, labels) # 由 logit,计算当前 batch 中,每个样本的平均交叉熵损失函数值# 获取整个测试集的标签类别和预测类别_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别preds = preds.cpu().numpy()loss = loss.detach().cpu().numpy()outputs = outputs.detach().cpu().numpy()labels = labels.detach().cpu().numpy()loss_list.append(loss)labels_list.extend(labels)preds_list.extend(preds)log_test = {}log_test['epoch'] = epoch# 计算分类评估指标log_test['test_loss'] = np.mean(loss_list)log_test['test_accuracy'] = accuracy_score(labels_list, preds_list)log_test['test_precision'] = precision_score(labels_list, preds_list, average='macro')log_test['test_recall'] = recall_score(labels_list, preds_list, average='macro')log_test['test_f1-score'] = f1_score(labels_list, preds_list, average='macro')return log_testdef saveLog():# 训练日志-训练集df_train_log = pd.DataFrame()log_train = {}log_train['epoch'] = 0log_train['batch'] = 0images, labels = next(iter(train_loader))log_train.update(train_one_batch(images, labels, 0, 0))df_train_log = df_train_log.append(log_train, ignore_index=True)# 训练日志-测试集df_test_log = pd.DataFrame()log_test = {}log_test['epoch'] = 0log_test.update(evaluate_testset(0))df_test_log = df_test_log.append(log_test, ignore_index=True)return df_train_log, df_test_logif __name__ == '__main__':ntime = time.strftime('%Y%m%d_%H%M%S', time.localtime(time.time()))ntime = str(ntime)device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')print('device', device)from torchvision import transforms# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化train_transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化test_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])# 数据集文件夹路径dataset_dir = 'D:\\dl_workspace\\datasets\\fruit30_split'train_path = os.path.join(dataset_dir, 'train')test_path = os.path.join(dataset_dir, 'val')print('训练集路径', train_path)print('测试集路径', test_path)from torchvision import datasetstrain_dataset = datasets.ImageFolder(train_path, train_transform) # 载入训练集test_dataset = datasets.ImageFolder(test_path, test_transform) # 载入测试集# 各类别名称class_names = train_dataset.classesn_class = len(class_names)train_dataset.class_to_idx # 映射关系:类别 到 索引号idx_to_labels = {y: x for x, y in train_dataset.class_to_idx.items()} # 映射关系:索引号 到 类别# 保存为本地的 npy 文件# np.save('idx_to_labels.npy', idx_to_labels)# np.save('labels_to_idx.npy', train_dataset.class_to_idx)from torch.utils.data import DataLoaderBATCH_SIZE = 256# 训练集的数据加载器train_loader = DataLoader(train_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=4)# 测试集的数据加载器test_loader = DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=False,num_workers=4)from Utils import pyutils# 只微调训练模型最后一层(全连接分类层)# model = models.resnet18(weights=ResNet18_Weights.DEFAULT) # 载入预训练模型# model = models.resnet18()# print(model)# print('pymodel:', pyutils.getOrderedDictKeys(model.state_dict()))from ResNet18_Model import ResNet18, ResBlock, ResNetmodel = ResNet18(ResBlock)# 给自定义模型,加载预训练模型权重,(strict=False 可以看到具有相同网络层名称的网络被初始化,不具有的网络层的参数不会被初始化)weights_dict = torch.load('C:\\Users\\Administrator/.cache\\torch\\hub\\checkpoints\\resnet18-f37072fd.pth')model.load_state_dict(weights_dict, strict=True)# 修改全连接层,使得全连接层的输出与当前数据集类别数对应(新建的层默认 requires_grad=True)# 只微调训练最后一层全连接层的参数,其它层冻结(1000分类改成30分类)model.fc = nn.Linear(model.fc.in_features, n_class)optimizer = optim.Adam(model.fc.parameters())print(model)# 训练配置model = model.to(device)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数EPOCHS = 30 # 训练轮次 Epoch(训练集当中所有的训练数据扫一遍算作一个epoch)'''学习率的降低优化策略,每经过5个epoch,学习率降低为原来的一半(lr = lr*gamma)'''lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 学习率降低策略# df_train_log, df_test_log = saveLog()df_train_log = pd.DataFrame()df_test_log = pd.DataFrame()epoch = 0batch_idx = 0best_test_accuracy = 0# 运行训练for epoch in range(1, EPOCHS + 1):print(f'Epoch {epoch}/{EPOCHS}')## 训练阶段model.train()for images, labels in tqdm(train_loader): # 获得一个 batch 的数据和标注batch_idx += 1log_train = train_one_batch(images, labels, epoch, batch_idx)df_train_log = df_train_log.append(log_train, ignore_index=True)# wandb.log(log_train)lr_scheduler.step() # 学习率优化策略,跟新学习率## 测试阶段model.eval() # 将模型的模式从训练模式改成评估模式log_test = evaluate_testset(epoch) # 在整个测试集上评估,并且返回测试结果df_test_log = df_test_log.append(log_test, ignore_index=True)# wandb.log(log_test)# 保存最新的最佳模型文件if log_test['test_accuracy'] > best_test_accuracy:# 删除旧的最佳模型文件(如有)old_best_checkpoint_path = 'checkpoint/best-{:.3f}.pth'.format(best_test_accuracy)if os.path.exists(old_best_checkpoint_path):os.remove(old_best_checkpoint_path)# 保存新的最佳模型文件best_test_accuracy = log_test['test_accuracy']new_best_checkpoint_path = './checkpoint/{0}_best-{1:.3f}.pth'.format(ntime, log_test['test_accuracy'])torch.save(model, new_best_checkpoint_path)print('保存新的最佳模型', './checkpoint/{0}_best-{1:.3f}.pth'.format(ntime, best_test_accuracy))best_test_accuracy = log_test['test_accuracy']print(f'测试准确率: {best_test_accuracy} / {epoch}')df_train_log.to_csv('训练日志-训练集-{0}.csv'.format(ntime), index=False)df_test_log.to_csv('训练日志-测试集-{0}.csv'.format(ntime), index=False)# 测试集上的准确率为 87.662 %相关文章:

根据Pytorch源码实现的 ResNet18
一,类模块定义: import torch import torch.nn as nn import torch.nn.functional as F from torch import Tensorclass ResBlock(nn.Module):def __init__(self, inchannel, outchannel, stride1) -> None:super(ResBlock, self).__init__()# 这里定义了残差块…...
药品管理系统servlet+jsp+sql医院药店仓库进销存java源代码mysql
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 药品管理系统servletjspsql 系统有1权限:…...

这9个UI设计工具一定码住!非常好用
对于设计师来说,好用的UI设计工具无疑会对设计工作起到事半功倍的作用,今天本文与大家分享9个好用的UI设计工具,一起来看看吧! 1、即时设计 即时设计是一个能在网页中直接使用,且支持团队协作的国产UI设计工具&#…...

gin通过反射来执行动态的方法
在gin中,可以通过反射来执行对应的方法。下面是一个示例: package mainimport ("fmt""github.com/gin-gonic/gin""reflect" )type UserController struct{}func (uc *UserController) GetUser(c *gin.Context) {userId :…...
java高并发系列 - 第23天:JUC中原子类,一篇就够了
java高并发系列 - 第23天:JUC中原子类 这是java高并发系列第23篇文章,环境:jdk1.8。 本文主要内容 JUC中的原子类介绍介绍基本类型原子类介绍数组类型原子类介绍引用类型原子类介绍对象属性修改相关原子类预备知识 JUC中的原子类都是都是依靠volatile、CAS、Unsafe类配合…...
《HeadFirst设计模式(第二版)》第一章源码
代码文件目录结构: FlyBehavior.java package Chapter1_StrategyPattern.ch1_3_behavior.behaviors.fly;public interface FlyBehavior {void fly(); } FlyNoWay.java package Chapter1_StrategyPattern.ch1_3_behavior.behaviors.fly;public class FlyNoWay imp…...
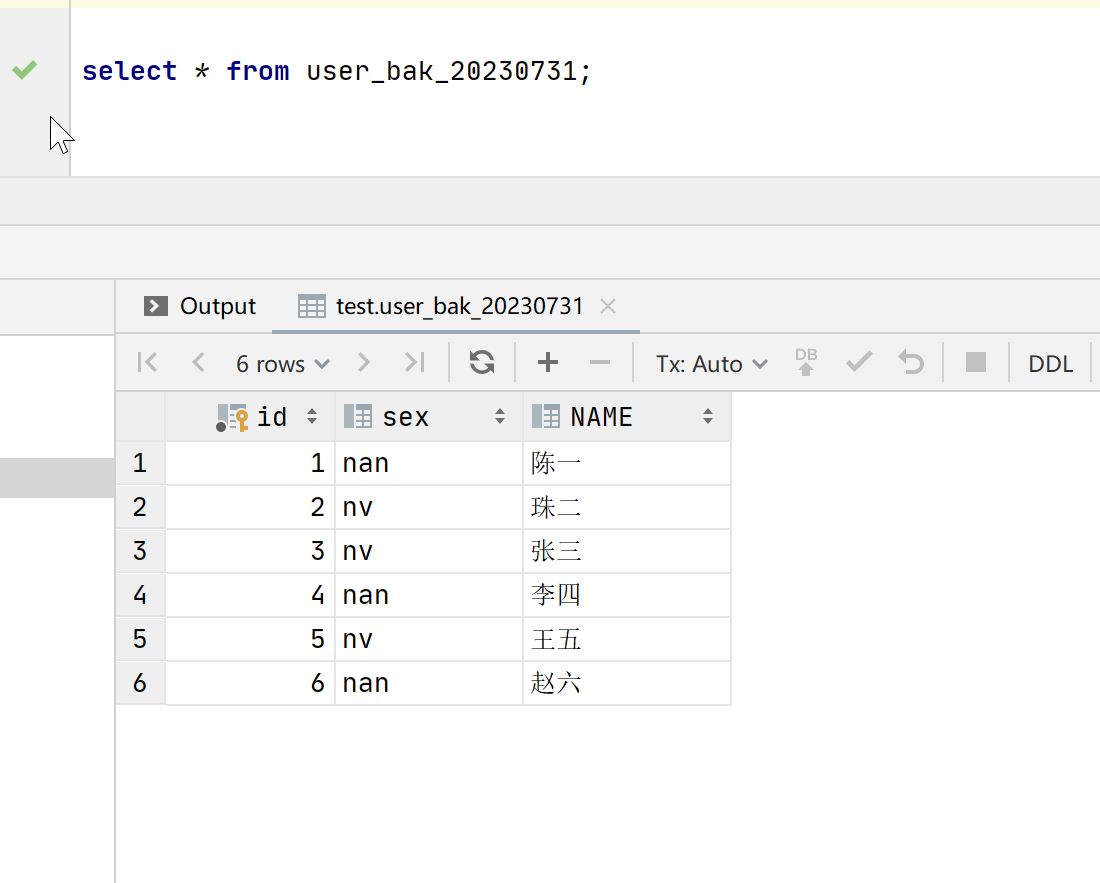
insert into select用法
文章目录 一、insert into select二、insert into select插入失败 本篇文章主要讲解insert into select 的用法,以及insert into select的坑或者注意事项。本篇文章中的sql基于mysql8.0进行讲解 一、insert into select 该语法常用于从另一张表查询数据插入到某表中…...

图像识别技术:计算机视觉的进化与应用展望
导言: 图像识别技术是计算机视觉领域的重要研究方向,它使计算机能够理解和解释图像内容,从而实现自动化和智能化的图像处理。随着深度学习等技术的快速发展,图像识别在诸多领域取得了重大突破,如自动驾驶、医疗影像分析…...

【免费送书】重新定义Python学习!
欢迎关注博主 Mindtechnist 或加入【智能科技社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。关…...

Qt 4. 发布exe
把ex2.exe放在H盘Ex2文件夹下,执行 H:\Ex2>windeployqt ex2.exe H:\Ex2>windeployqt ex2.exe H:\Ex2\ex2.exe 64 bit, release executable Adding Qt5Svg for qsvgicon.dll Skipping plugin qtvirtualkeyboardplugin.dll due to disabled dependencies (Qt5…...

消息队列的使用场景以及优缺点
消息队列是一种在应用系统之间传递消息的通信模式。它允许发送者将消息发布到一个队列中,而接收者则从队列中获取消息进行处理。 消息队列的主要特点包括: 异步通信:消息的发送和接收是异步进行的,发送者无需等待接收者的即时响应…...
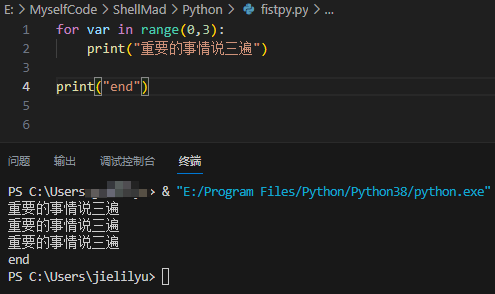
掌握Python的X篇_17_循环语句(while;for var in ;range)
文章目录 1. 为什么需要循环2. while循环3. for...in循环4. range函数 1. 为什么需要循环 循环语句方便我们做重复的事情,比如: for i in range (0,3):print("重要的事情说三遍")运行效果如下: Python中有while循环和for循环两…...

IDEA maven 报错 malformed \uxxx encoding
IDEA maven 报错 malformed \uxxx encoding 最近搞几个JAVA项目总是出现上面错误,在网上搜的大部分都是删maven库,删jar包等等,每次都搞了好久才解决,今天无意中发现并不是包的问题, 解决办法 1.点击 idea 右侧的ma…...
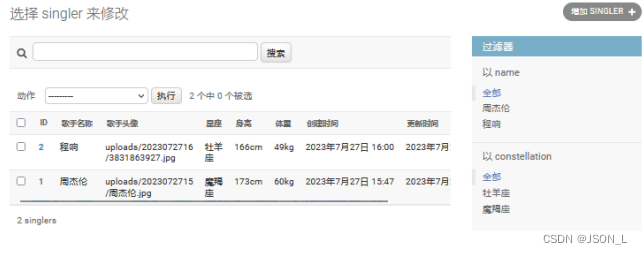
Django实现音乐网站 ⑵
使用Python Django框架制作一个音乐网站,在系列文章1的基础上继续开发,本篇主要是后台歌手表模块开发。 目录 表结构设计 歌手表(singer)结构 创建表模型 设置图片上传路径 创建上传文件目录 生成表迁移 执行创建表 后台管…...
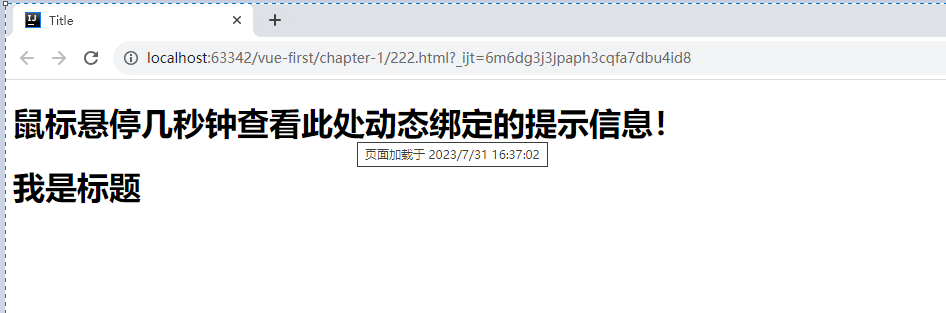
Vue 基础语法(二)
一、背景: 我们对于基础语法,说白了就是实现元素赋值,循环,判断,以及事件响应即可! 二、v-bind 我们已经成功创建了第一个 Vue 应用!看起来这跟渲染一个字符串模板非常类似,但是 V…...

kafka raft协议
1、首先要了解kafka是什么(Scala) Kafka是一个分布式的消息订阅系统,消息被持久化到一个topic中,topic是按照“主题名-分区”存储的,一个topic可以分为多个partition,在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),记录消息的消息位置…...
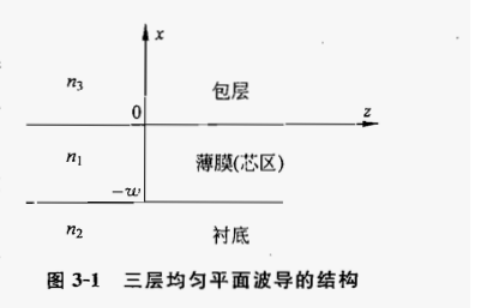
平板光波导中导模的(注意不是泄露模)传播常数β的matlab计算(验证了是对的)
参照的是导波光学_王建(清华大学)的公式(3-1-2、3-1-3),算的参数是这本书的图3-3的。 function []PropagationConstantsMain() clear;clc;close all lambda01.55;%真空或空气中的入射波长,单位um k02*pi/lambda0; m3;%导模阶数(需要人为指定) n11.62;%芯…...

JVM面试题--JVM组成
JVM是什么 Java Virtual Machine Java程序的运行环境(java二进制字节码的运行环境) 运行流程 什么是程序计数器? 程序计数器:线程私有的,内部保存的字节码的行号。用于记录正在执行的字节码指令的地址。 我们知道ja…...

【Golang 接口自动化05】使用yml管理自动化用例
目录 YAML 基本语法 对象:键值对的集合(key:value) 数组:一组按顺序排列的值 字面量:单个的、不可再分的值(数字、字符串、布尔值) yml 格式的测试用例 定义yml文件 创建结构体 读取yml文件中的用例数据 调试…...
【【STM32学习-3】】
STM32学习-3 下面是对c语言的稍微复习 这个是我们设置好的文件 以后拖出去用就可以了 这里加入关于指针的感想 关于指针数组和数组指针的想法 常规的东西是int a10; int * p&a; (p指向了a元素,意思是p等于a的地址 类型是int*)就是 整型指…...

Notemd Pro:基于Web技术栈的开源个人知识管理应用深度解析
1. 项目概述:一个面向未来的笔记应用如果你和我一样,常年混迹在程序员、产品经理和知识工作者的圈子里,那你一定对“笔记软件”这个赛道又爱又恨。爱的是,它确实是我们整理思路、记录灵感、构建知识体系的刚需;恨的是&…...

Wonder3D终极指南:如何用单张图片快速生成高质量3D模型
Wonder3D终极指南:如何用单张图片快速生成高质量3D模型 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 你是否曾梦想过将一张普通的2D图片瞬间变成生…...

AI LED调光控制器智能功率 MOSFET 完整选型方案
2026年随着 AI 技术在智能照明与调光控制中的深度渗透(如自适应色温、场景联动、人因节律照明),调光控制器对功率 MOSFET 提出更高要求:高精度PWM响应、超低导通损耗、高散热密度。微碧半导体(VBsemi)基于S…...

工业 DC-DC 性能深度对比解析|钡特电源 DF1-05D15LS 与 E0515S-1WR3 封装互通
在工业控制、仪器仪表、低功耗传感设备等场景中,1W 级隔离工业 DC-DC 模块因体积小、功率密度高、适配性强,成为硬件研发工程师常用的直流电源模块核心器件。随着国产化进程加速,国产工业 DC-DC 模块在性能、稳定性、性价比上逐步实现突破&am…...

JSON Lint for PHP:如何构建企业级JSON数据验证解决方案?
JSON Lint for PHP:如何构建企业级JSON数据验证解决方案? 【免费下载链接】jsonlint JSON Lint for PHP 项目地址: https://gitcode.com/gh_mirrors/jso/jsonlint 在现代Web开发和API设计中,JSON数据验证是确保系统稳定性的关键环节。…...

实战解析:XiaoMusic技术架构深度剖析与智能音箱语音控制实现方案
实战解析:XiaoMusic技术架构深度剖析与智能音箱语音控制实现方案 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 在智能音箱生态中,小爱音箱…...

ARM GICv3中断控制器架构与ICC_CTLR_EL3寄存器解析
1. ARM GICv3中断控制器架构概述在现代处理器架构中,中断控制器是连接外设与CPU核心的关键枢纽。ARM的通用中断控制器(Generic Interrupt Controller, GIC)经过多代演进,GICv3架构在虚拟化支持、多安全域管理和扩展性方面实现了显著提升。作为GICv3的核心…...

provision-cli:构建组织级基础设施即代码标准化工作流
1. 项目概述:一个为组织级基础设施管理而生的命令行工具如果你在管理一个稍具规模的技术团队,或者负责一个拥有多个项目、环境(开发、测试、生产)的软件产品,那么你一定对“基础设施即代码”这个概念不陌生。但当你真正…...

不止是多旋翼:用CopterSim玩转固定翼仿真,从模型替换到3D场景飞行全记录
从多旋翼到固定翼:解锁CopterSim的跨机型仿真潜能 当大多数人提起CopterSim时,第一反应往往是多旋翼无人机的仿真利器。但鲜为人知的是,这款工具蕴藏着更广阔的仿真可能性——通过巧妙的模型替换与参数调整,它能够完美模拟固定翼飞…...

收藏!AI覆盖率94%?程序员别慌,读懂这份报告保住你的饭碗!
Anthropic报告显示AI在程序员领域的理论覆盖率高达94%,但现实替代率仅为33%。AI尚无法大规模取代白领,主要因输出结果需人类承担后果、效率问题及无法替代岗位。高学历者中,机械执行者面临最大威胁,而拥有决策力、策略思考及复杂流…...