spark-sql : “java.lang.NoSuchFieldError: out“ 异常解决
异常现象
at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:847)at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:922)at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:931)at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.NoSuchFieldError: outat org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:221)at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:127)at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:314)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:433)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:326)at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66)at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:219)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:219)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:219)at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)... 59 more
【ERROR】spark.sql hql error
Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.NoSuchFieldError: out;at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:218)at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:138)at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:126)at org.apache.spark.sql.hive.HiveSessionStateBuilder.org$apache$spark$sql$hive$HiveSessionStateBuilder$$externalCatalog(HiveSessionStateBuilder.scala:39)at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$1.apply(HiveSessionStateBuilder.scala:54)at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$1.apply(HiveSessionStateBuilder.scala:54)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.externalCatalog$lzycompute(SessionCatalog.scala:90)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.externalCatalog(SessionCatalog.scala:90)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.databaseExists(SessionCatalog.scala:243)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.org$apache$spark$sql$catalyst$catalog$SessionCatalog$$requireDbExists(SessionCatalog.scala:177)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.getTableMetadata(SessionCatalog.scala:432)at org.apache.spark.sql.catalyst.catalog.CatalogUtils$.getMetaData(ExternalCatalogUtils.scala:265
spark 应用程序
package org.example.spark;import java.util.Base64;
import org.apache.spark.sql.SparkSession;public class JavaSparkHiveExample {public static void main(String[] args) {long start = System.currentTimeMillis();byte[] decodedBytes = Base64.getDecoder().decode(args[0]);String sql = new String(decodedBytes);System.out.println("sql:" + sql);SparkSession spark = SparkSession.builder().config("spark.sql.hive.loadStagingDirectory.enabled", args[1]).appName("Java Spark Hive Example").enableHiveSupport().getOrCreate();spark.sql(sql);long end = System.currentTimeMillis();System.out.println("cost time:" + (end - start));}
}
异常原因
版本不兼容,cdp 集群中 spark 版本是 2.4.7。Java 工程中使用的是 2.4.0
解决办法
修改 Java工程依赖,如下:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.4.7.7.1.7.2000-305</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.7.7.1.7.2000-305</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.7.7.1.7.2000-305</version></dependency>
相关文章:

spark-sql : “java.lang.NoSuchFieldError: out“ 异常解决
异常现象 at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:847)at org.apac…...
以及详细解析)
Node.js入门笔记(包含源代码)以及详细解析
Node.js 入门笔记源码 01、如何在终端中执行js 文件 目标:将下面的代码语句在中断中执行 代码演示: console.log(Hello World)for (let i 0;i < 3;i) {console.log(6)}方法:在文件上右击打开在终端中执行,然后输入node空格 输…...

windows自动化点击大麦app抢购、捡漏,仅支持windows11操作系统
文章目录 必要条件程序运行必要条件 确保windows11版本操作系统,如果不是可以通过镜像升级为windows11如果已经是windows11操作系统,确保更新到最新版本 修改系统所在时区,将国家或地区改为美国 开启虚拟化 勾选Hyper-V,如果没有则不需要勾选 勾选虚拟机平台 勾选完毕,点…...

vue 拦截 v-html 中 a 标签 href 跳转
记录 template 中 给需要 拦截的 代码片段加上click 方法 click“targetNodeNameClick” <p class"message-content message-content-text" v-html"replaceURLWithHTMLLinks(getText(message))" click"targetNodeNameClick"></p>然…...

分布式id、系统id、业务id以及主键之间的关系
推荐 连分布式ID都理解不了,你是刚培训出来冒充面试官的吧 1 分布式id、系统id、业务id以及主键之间的关系 分布式ID、系统ID、业务ID和主键的关系: 分布式ID:在分布式系统中,由于存在多个独立的节点,为了保证每个节…...
)
设计模式七:适配器模式(Adapter Pattern)
适配器模式(Adapter Pattern)是一种结构型设计模式,用于将一个类的接口转换成客户端所期望的另一个接口。它允许不兼容的接口能够协同工作。 适配器模式涉及角色: 目标接口(Target Interface):…...

数据结构---队列
(一)队列之基础补充 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。 —— 百科 「队列 Queue」是一种…...

chatGPT在软件测试中应用方式有哪些?
ChatGPT可以在软件测试中以以下方式应用: 1. 自动化对话测试:ChatGPT可以用于自动化对话测试,模拟用户与软件系统进行实时对话。它可以扮演用户的角色,向系统发送各种类型的指令和请求,并验证系统的响应是否符合预期。…...

chatgpt 接口使用(一)
使用api实现功能 参考链接:https://platform.openai.com/examples 安装库: pip3 install openai 例如: import os import openaiopenai.api_key os.getenv("OPENAI_API_KEY") response openai.ChatCompletion.create(model&q…...

【个人笔记】Linux 服务管理两种方式service和systemctl
service命令与systemctl 命令 service 命令与传统的 SysVinit 和 Upstart 初始化系统相关。较早期的 Linux 发行版(如早期的 Ubuntu、Red Hat 等)使用了这些初始化系统。service 命令用于启动、停止、重启和查询系统服务的状态。虽然许多现代 Linux 发行…...
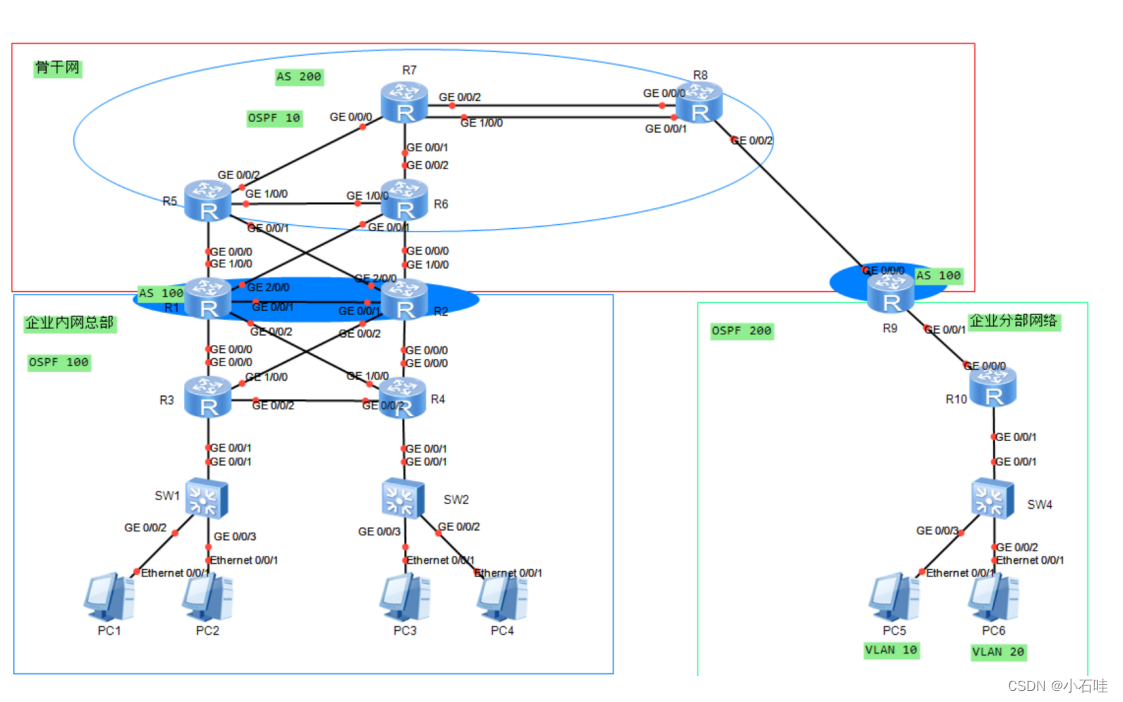
HCIP中期考试实验
考试需求 1、该拓扑为公司网络,其中包括公司总部、公司分部以及公司骨干网,不包含运营商公网部分。 2、设备名称均使用拓扑上名称改名,并且区分大小写。 3、整张拓扑均使用私网地址进行配置。 4、整张网络中,运行OSPF协议或者BGP…...
WebRTC的混音处理)
【WebRTC---源码篇】(二十二)WebRTC的混音处理
音频混音主力 音频混音主体主要通过(重采样) + (混音)为主 音频重采样 内容实现是在webrtc::voe中实现的,下面来对重采样全流程逐一分析 。 void RemixAndResample(const AudioFrame& src_frame,//源音频数据帧PushResampler<int16_t>* resampler,//重采样对…...

MTK system_server 卡死导致手机重启案例分析
和你一起终身学习,这里是程序员Android 经典好文推荐,通过阅读本文,您将收获以下知识点: 一、MTK AEE Log分析工具二、AEE Log分析流程三、system_server 卡死案例分析及解决 本文主要针对 Exception Type: system_server_watchdog , system_…...

加强 Kubernetes 能力:利用 CRD 定义多版本资源的实现方式
姚灿武,Rancher 中国研发工程师,拥有 7 年云计算领域经验,热衷开源技术,在云原生相关技术领域拥有丰富的开发和实践经验。 CRD,即自定义资源定义(Custom Resource Definition),是 Ku…...

区块链应用 DApp 开发需要掌握的技能
文章目录 前言为什么要开发 DAppDApp 的优势DApp 应用范围DApp 开发者技能 前言 前面区块链系列的文章中介绍了区块链技术、智能合约、web3js,Solidity 编程语言,在开发者的角度就是要基于这些知识在Web3时代去开发一个 DApp(去中心化应用程…...

关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题
由于一段时间没有使用Selenium,当再次使用时发现之前写的Selenium元素定位的代码运行之后会报错,发现是Selenium更新到新版本(4.x版本)后,以前的一些常用的代码的语法发生了改变,当然如果没有更新过或是下载…...

c++通过自然语言处理技术分析语音信号音高
对于语音信号的音高分析,可以使用基频提取技术。基频是指一个声音周期的重复率,也就是一个声音波形中最长的周期。 通常情况下,人的声音基频范围是85Hz到255Hz。根据语音信号的基频可以推断出其音高。 C中可以使用数字信号处理库或语音处理库…...
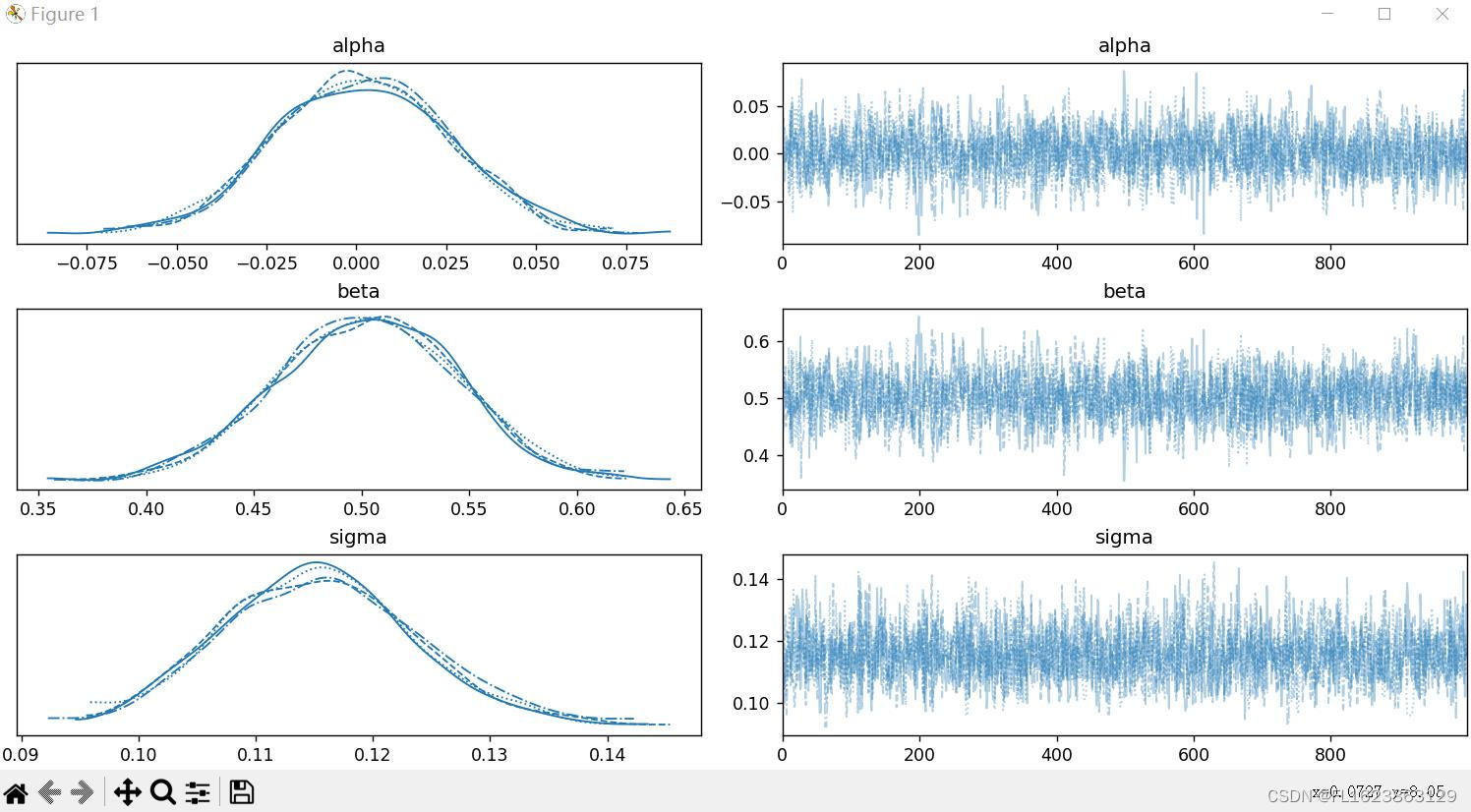
[pymc3][python]pymc3安装后测试代码2
测试环境: pymc33.11.2 代码: import numpy as np import pymc3 as pm import matplotlib.pyplot as pltif __name__ __main__:# 生成随机数据np.random.seed(123)x np.linspace(0, 1, 100)y 0.5 * x np.random.normal(0, 0.1, size100)# 定义概率…...

Go语言time库,时间和日期相关的操作方法
time库 用于处理时间、日期和时区的核心库。在实际开发中,常常需要与时间打交道,例如记录日志、处理时间差、计算时间间隔等等。因此,掌握time库的使用方法对于Go开发者来说非常重要。 在Go语言中,时间表示为time.Time类型&…...
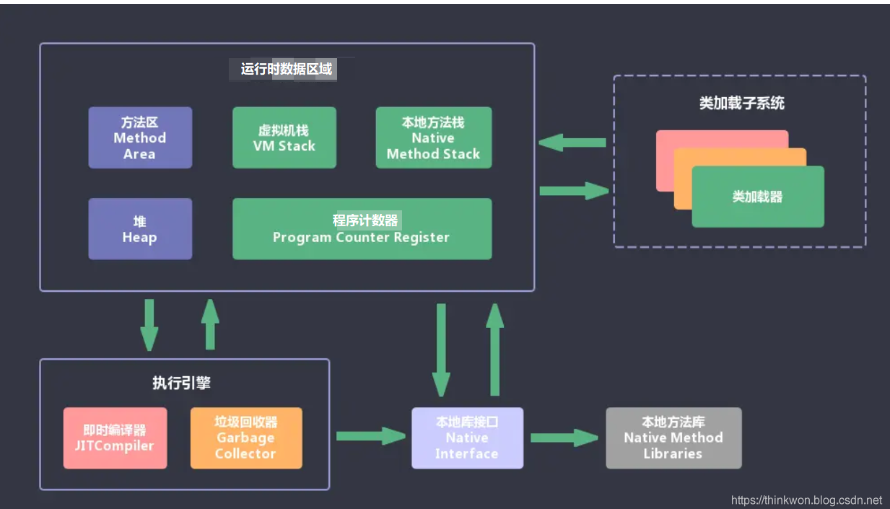
JVM总结笔记
JVM JVM是什么?JVM 的主要组成部分JVM工作流程JVM内存模型直接内存与堆内存的区别:堆栈的区别Java会存在内存泄漏吗?简述Java垃圾回收机制垃圾收集算法轻GC(Minor GC)和重GC(Full GC)新生代gc流程JVM优化与JVM调优 JVM是什么? JVM是Java Virtual Mach…...

跨境电商团队如何用Taotoken调用AI模型批量生成多语言商品描述
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 跨境电商团队如何用Taotoken调用AI模型批量生成多语言商品描述 对于跨境电商运营团队而言,为海量商品生成不同语言版本…...

从FOC电机库偷师:手把手教你用C语言写一个自己的“数学加速库”
从FOC电机库偷师:手把手教你用C语言写一个自己的"数学加速库" 在嵌入式开发领域,性能优化永远是个绕不开的话题。当你在STM32上跑电机控制算法时,突然发现三角函数计算成了瓶颈;当你处理传感器数据时,浮点运…...

AGIAgent框架实践:从LLM到可编程智能体的工程化之路
1. 项目概述:从AGI到AGIAgent的实践跨越最近在GitHub上看到一个挺有意思的项目,叫agi-hub/AGIAgent。光看名字,可能很多朋友会立刻联想到“通用人工智能”或者“AI智能体”,觉得这又是一个宏大叙事下的概念性项目。但实际深入探究…...

CMMLU中文理解瓶颈再定位:从词义消歧到跨文档推理,5个未公开bad case驱动的模型优化路径
更多请点击: https://intelliparadigm.com 第一章:CMMLU中文理解瓶颈再定位的总体发现 评测基准与数据分布偏移现象 近期对 CMMLU(Chinese Massive Multitask Language Understanding)基准的系统性重测揭示:模型在人…...
)
CloudCompare点云滤波保姆级教程:从低通到CSF,7种方法一次搞定(附避坑指南)
CloudCompare点云滤波实战指南:7大核心方法与避坑策略 点云数据处理是三维重建、地形测绘和工业检测等领域的关键环节。面对海量且带有噪声的原始点云,如何高效筛选有效信息成为每个从业者的必修课。CloudCompare作为开源点云处理利器,其丰富…...

复杂园区管控难?无感跨镜追踪打造全流程动态溯源方案
复杂园区管控难?无感跨镜追踪打造全流程动态溯源方案产业园区、科创园区、物流园区、化工园区等复杂场景,普遍存在点位分散、人员车流密集、动线繁杂、盲区死角多、安防设备数据割裂等管控难题。传统园区管理模式依赖人工巡检、单点监控查看、被动事后追…...

android C++版本opencv数值拼接图片+水平拼接图片效果
这是vconcat() 也就是vertical concat效果-----------------------这是hconcat() 也就是horizontal concat()...

android C++降低图片亮度 opencv 效果
需要注意的:如果是4通道,那么需要转换成3通道,处理完以后转换回去RGBA格式...
)
Midjourney葡萄酒视觉叙事术(从葡萄藤到酒标的一站式AI印相工作流)
更多请点击: https://intelliparadigm.com 第一章:Midjourney葡萄酒视觉叙事术(从葡萄藤到酒标的一站式AI印相工作流) 在数字酒庄时代,视觉叙事已成为品牌差异化的核心引擎。Midjourney 不再仅是图像生成工具…...

[IdeaLoop · 灵感回路] 独立开发者创业/副业灵感日报 · 2026-05-14
灵感日报 2026年05月14日 从今日全网热点提炼,精选 5 个值得关注的商业方向。— 灵感回路 IdeaLoop 完整报告(含竞品分析、MVP 规划、冷启动策略):idealoop.top 🏆 #1 胶片一键调色助手 综合评分:65 / 10…...