神经概率语言模型
本文主要参考《A Neural Probabilistic Language Model》这是一篇很重要的语言模型论文,发表于2003年。主要贡献如下:
- 提出了一种基于神经网络的语言模型,是较早将神经网络应用于语言模型领域的工作之一,具有里程碑意义。
- 采用神经网络模型预测下一个单词的概率分布,已经成为神经网络语言模型训练的标准方法之一。
- 在论文中,作者训练了一个前馈神经网络,同时学习词的特征表示和词序列的概率函数,并取得了比 trigram 语言模型更好的单词预测效果,这证明了神经网络语言模型的有效性。
- 论文提出的思想与模型为后续的许多神经网络语言模型研究奠定了基础。
模型结构
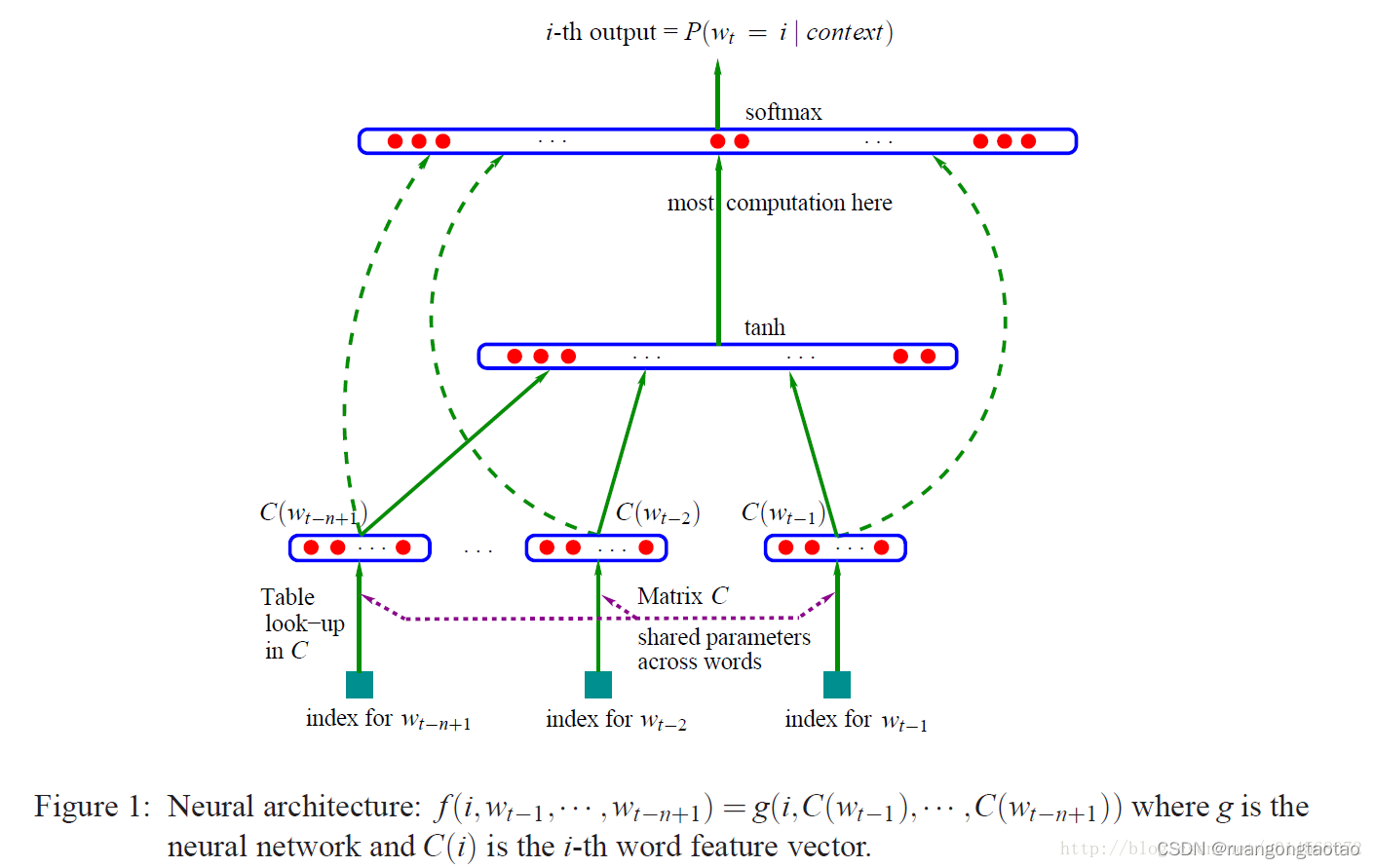
模型的目标是学到一个概率函数,根据上下文预测下一个词的概率分布:

import os
import time
import pandas as pd
from dataclasses import dataclassimport torch
import torch.nn as nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from torch.utils.data.dataloader import DataLoader
from torch.utils.tensorboard import SummaryWriter加载数据
数据集来10+中文外卖评价数据集:
data = pd.read_csv('./dataset/waimai_10k.csv')
data.dropna(subset='review',inplace=True)
data['review_length'] = data.review.apply(lambda x:len(x))
data.sample(5)| label | review | review_length | |
|---|---|---|---|
| 4545 | 0 | 从说马上送餐,到收到餐,时间特别久,给的送餐电话打不通! | 28 |
| 9855 | 0 | 韩餐做得像川菜,牛肉汤油得不能喝,量也比实体少很多,送餐时间久得太久了,1个半小时,唉。 | 44 |
| 5664 | 0 | 太糟了。等了两个小时,牛肉我吃的快吐了,再也不可能第二次 | 28 |
| 2323 | 1 | 很好吃,就是粥撒了点,等了一个多小时 | 18 |
| 8117 | 0 | 送餐员给我打电话比较粗鲁 | 12 |
统计信息:
data = data[data.review_length <= 50]
words = data.review.tolist()
chars = sorted(list(set(''.join(words))))
max_word_length = max(len(w) for w in words)print(f"number of examples: {len(words)}")
print(f"max word length: {max_word_length}")
print(f"size of vocabulary: {len(chars)}")number of examples: 10796
max word length: 50
size of vocabulary: 2272划分训练/测试集
test_set_size = min(1000, int(len(words) * 0.1))
rp = torch.randperm(len(words)).tolist()
train_words = [words[i] for i in rp[:-test_set_size]]
test_words = [words[i] for i in rp[-test_set_size:]]
print(f"split up the dataset into {len(train_words)} training examples and {len(test_words)} test examples")split up the dataset into 9796 training examples and 1000 test examples构造字符数据集[tensor]
- < BLANK> : 0
- token seqs : [1, 2, 3, 4, 5, 6]
- block_size : 3,上下文长度
- x : [[0, 0, 0],[0, 0, 1],[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5], [4, 5, 6]
- y : [1, 2, 3, 4, 5, 6, 0]
`class CharDataset(Dataset):def __init__(self, words, chars, max_word_length, block_size=1):self.words = wordsself.chars = charsself.max_word_length = max_word_lengthself.block_size = block_sizeself.char2i = {ch:i+1 for i,ch in enumerate(chars)}self.i2char = {i:s for s,i in self.char2i.items()} def __len__(self):return len(self.words)def contains(self, word):return word in self.wordsdef get_vocab_size(self):return len(self.chars) + 1 def get_output_length(self):return self.max_word_length + 1def encode(self, word):ix = torch.tensor([self.char2i[w] for w in word], dtype=torch.long)return ixdef decode(self, ix):word = ''.join(self.i2char[i] for i in ix)return worddef __getitem__(self, idx):word = self.words[idx]ix = self.encode(word)x = torch.zeros(self.max_word_length + self.block_size, dtype=torch.long)y = torch.zeros(self.max_word_length, dtype=torch.long)x[self.block_size:len(ix)+self.block_size] = ixy[:len(ix)] = ixy[len(ix)+1:] = -1 if self.block_size > 1:xs = []for i in range(x.shape[0]-self.block_size):xs.append(x[i:i+self.block_size].unsqueeze(0))return torch.cat(xs), yelse:return x, y` 数据加载器[DataLoader]
class InfiniteDataLoader:def __init__(self, dataset, **kwargs):train_sampler = torch.utils.data.RandomSampler(dataset, replacement=True, num_samples=int(1e10))self.train_loader = DataLoader(dataset, sampler=train_sampler, **kwargs)self.data_iter = iter(self.train_loader)def next(self):try:batch = next(self.data_iter)except StopIteration: self.data_iter = iter(self.train_loader)batch = next(self.data_iter)return batch构建模型
context_tokens → \to → embedding → \to → concate feature vector → \to → hidden layer → \to → output layer
@dataclass
class ModelConfig:block_size: int = None vocab_size: int = None n_embed : int = Nonen_hidden: int = None`class MLP(nn.Module):"""takes the previous block_size tokens, encodes them with a lookup table,concatenates the vectors and predicts the next token with an MLP.Reference:Bengio et al. 2003 https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf"""def __init__(self, config):super().__init__()self.block_size = config.block_sizeself.vocab_size = config.vocab_sizeself.wte = nn.Embedding(config.vocab_size + 1, config.n_embed) self.mlp = nn.Sequential(nn.Linear(self.block_size * config.n_embed, config.n_hidden),nn.Tanh(),nn.Linear(config.n_hidden, self.vocab_size))def get_block_size(self):return self.block_sizedef forward(self, idx, targets=None):embs = []for k in range(self.block_size):tok_emb = self.wte(idx[:,:,k]) embs.append(tok_emb)x = torch.cat(embs, -1) logits = self.mlp(x)loss = Noneif targets is not None:loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)return logits, loss` * 1
* 2
* 3
* 4
* 5
* 6
* 7
* 8
* 9
* 10
* 11
* 12
* 13
* 14
* 15
* 16
* 17
* 18
* 19
* 20
* 21
* 22
* 23
* 24
* 25
* 26
* 27
* 28
* 29
* 30
* 31
* 32
* 33
* 34
* 35
* 36
* 37
* 38
* 39
* 40
* 41
* 42
* 43
* 44@torch.inference_mode()
def evaluate(model, dataset, batch_size=10, max_batches=None):model.eval()loader = DataLoader(dataset, shuffle=True, batch_size=batch_size, num_workers=0)losses = []for i, batch in enumerate(loader):batch = [t.to('cuda') for t in batch]X, Y = batchlogits, loss = model(X, Y)losses.append(loss.item())if max_batches is not None and i >= max_batches:breakmean_loss = torch.tensor(losses).mean().item()model.train() return mean_loss训练模型
环境初始化
torch.manual_seed(seed=12345)
torch.cuda.manual_seed_all(seed=12345)work_dir = "./Mlp_log"
os.makedirs(work_dir, exist_ok=True)
writer = SummaryWriter(log_dir=work_dir)config = ModelConfig(vocab_size=train_dataset.get_vocab_size(),block_size=7,n_embed=64,n_hidden=128)格式化数据
train_dataset = CharDataset(train_words, chars, max_word_length, block_size=config.block_size)
test_dataset = CharDataset(test_words, chars, max_word_length, block_size=config.block_size)train_dataset[0][0].shape, train_dataset[0][1].shape(torch.Size([50, 7]), torch.Size([50]))初始化模型
model = MLP(config)model.to('cuda')MLP((wte): Embedding(2274, 64)(mlp): Sequential((0): Linear(in_features=448, out_features=128, bias=True)(1): Tanh()(2): Linear(in_features=128, out_features=2273, bias=True))
) `optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4, weight_decay=0.01, betas=(0.9, 0.99), eps=1e-8)batch_loader = InfiniteDataLoader(train_dataset, batch_size=64, pin_memory=True, num_workers=4)best_loss = None
step = 0
train_losses, test_losses = [],[]
while True:t0 = time.time()batch = batch_loader.next()batch = [t.to('cuda') for t in batch]X, Y = batchlogits, loss = model(X, Y)model.zero_grad(set_to_none=True)loss.backward()optimizer.step()torch.cuda.synchronize()t1 = time.time()if step % 1000 == 0:print(f"step {step} | loss {loss.item():.4f} | step time {(t1-t0)*1000:.2f}ms")if step > 0 and step % 100 == 0:train_loss = evaluate(model, train_dataset, batch_size=100, max_batches=10)test_loss = evaluate(model, test_dataset, batch_size=100, max_batches=10)train_losses.append(train_loss)test_losses.append(test_loss)if best_loss is None or test_loss < best_loss:out_path = os.path.join(work_dir, "model.pt")print(f"test loss {test_loss} is the best so far, saving model to {out_path}")torch.save(model.state_dict(), out_path)best_loss = test_lossstep += 1if step > 15100:break` * 1
* 2
* 3
* 4
* 5
* 6
* 7
* 8
* 9
* 10
* 11
* 12
* 13
* 14
* 15
* 16
* 17
* 18
* 19
* 20
* 21
* 22
* 23
* 24
* 25
* 26
* 27
* 28
* 29
* 30
* 31
* 32
* 33
* 34
* 35
* 36
* 37
* 38
* 39
* 40
* 41
* 42
* 43
* 44
* 45
* 46
* 47
* 48
* 49`step 0 | loss 7.7551 | step time 13.09ms
test loss 5.533482551574707 is the best so far, saving model to ./Mlp_log/model.pt
test loss 5.163593292236328 is the best so far, saving model to ./Mlp_log/model.pt
test loss 4.864410877227783 is the best so far, saving model to ./Mlp_log/model.pt
test loss 4.6439409255981445 is the best so far, saving model to ./Mlp_log/model.pt
test loss 4.482759475708008 is the best so far, saving model to ./Mlp_log/model.pt
test loss 4.350367069244385 is the best so far, saving model to ./Mlp_log/model.pt
test loss 4.250306129455566 is the best so far, saving model to ./Mlp_log/model.pt
test loss 4.16674280166626 is the best so far, saving model to ./Mlp_log/model.pt
test loss 4.0940842628479 is the best so far, saving model to ./Mlp_log/model.pt
.......................
step 6000 | loss 2.8038 | step time 6.44ms
step 7000 | loss 2.7815 | step time 11.88ms
step 8000 | loss 2.6511 | step time 5.93ms
step 9000 | loss 2.5898 | step time 5.00ms
step 10000 | loss 2.6600 | step time 6.12ms
step 11000 | loss 2.4634 | step time 5.94ms
step 12000 | loss 2.5373 | step time 7.75ms
step 13000 | loss 2.4050 | step time 6.29ms
step 14000 | loss 2.5434 | step time 7.77ms
step 15000 | loss 2.4084 | step time 7.10ms` * 1
* 2
* 3
* 4
* 5
* 6
* 7
* 8
* 9
* 10
* 11
* 12
* 13
* 14
* 15
* 16
* 17
* 18
* 19
* 20
* 21测试:评论生成器
`@torch.no_grad()
def generate(model, idx, max_new_tokens, temperature=1.0, do_sample=False, top_k=None):block_size = model.get_block_size()for _ in range(max_new_tokens):idx_cond = idx if idx.size(2) <= block_size else idx[:, :,-block_size:]logits, _ = model(idx_cond)logits = logits[:,-1,:] / temperatureif top_k is not None:v, _ = torch.topk(logits, top_k)logits[logits < v[:, [-1]]] = -float('Inf')probs = F.softmax(logits, dim=-1)if do_sample:idx_next = torch.multinomial(probs, num_samples=1)else:_, idx_next = torch.topk(probs, k=1, dim=-1)idx = torch.cat((idx, idx_next.unsqueeze(1)), dim=-1)return idx` * 1
* 2
* 3
* 4
* 5
* 6
* 7
* 8
* 9
* 10
* 11
* 12
* 13
* 14
* 15
* 16
* 17
* 18
* 19
* 20
* 21
* 22
* 23
* 24
* 25def print_samples(num=13, block_size=3, top_k = None):X_init = torch.zeros((num, 1, block_size), dtype=torch.long).to('cuda')steps = train_dataset.get_output_length() - 1 X_samp = generate(model, X_init, steps, top_k=top_k, do_sample=True).to('cuda')new_samples = []for i in range(X_samp.size(0)):row = X_samp[i, :, block_size:].tolist()[0] crop_index = row.index(0) if 0 in row else len(row)row = row[:crop_index]word_samp = train_dataset.decode(row)new_samples.append(word_samp)return new_samples不同上下文长度的生成效果
block_size=3
'送餐大叔叔风怎么第一次点的1迷就没有需减改进','送餐很快!菜品一般,送到都等到了都很在店里吃不出肥肉,第我地佩也不好意思了。第一次最爱付了凉面味道不','很不好进吧。。。。。这点一次都是卫生骑题!调菜油腻,真不太满意!','11点送到指定地形,不知道他由、奶茶类应盒子,幸好咸。。。','味道一般小份速度太难吃了。','快递小哥很贴心也吃不习惯。','非常慢。','为什么,4个盒子,反正订的有点干,送餐速度把面洒了不超值!很快!!!!!少菜分量不够吃了!味道很少餐','骑士剁疼倒还没给糖的','怎么吃,正好吃,便宜'block_size=5
['味道不错,送餐大哥工,餐大哥应不错。','配送很不满意','土豆炒几次,一小时才没吃,幸太多','粥不好吃,没有病311小菜送到,吃完太差了','太咸了,很感谢到,对这次送餐员辛苦,服务很不好','真的很香菇沙,卷哪丝口气,无语了!','菜不怎么夹生若梦粥,小伙n丁也没有收到餐。。。','一点不脆1个多小时才送到。等了那个小时。','就是送的太慢。。。。一京酱肉丝卷太不点了了,大份小太爱,真心不难吃,最后我的平时面没有听说什么呢,就','慢能再提前的好,牛肉好吃而且感觉适合更能事,味道倒卷,送的也很快!']block_size = 7
['味道还不错,但是酱也没给,一点餐不差','都是肥肉,有差劲儿大的,也太给了,那么好给这么多~后超难吃~','少了一个半小时才吃到了','商务还菜很好的','慢慢了~以后!点他家极支付30元分钟,送过用了呢。','就是没送到就给送王一袋儿食吃起来掉了,有点辣,这油还这抄套!','很好吃,就是送餐师傅不错','包装好的牛肉卷糊弄错酱,重面太少了,肉不新鲜就吃了','味道不错,送得太慢...','非常好非常快递小哥,态度极差,一点也好,菜和粥洒了一袋软,以先订过哈哈哈哈']相关文章:
神经概率语言模型
本文主要参考《A Neural Probabilistic Language Model》这是一篇很重要的语言模型论文,发表于2003年。主要贡献如下: 提出了一种基于神经网络的语言模型,是较早将神经网络应用于语言模型领域的工作之一,具有里程碑意义。采用神经网络模型预测下一个单词…...

什么是shadow DOM?
Shadow DOM(影子DOM)是一种用于在Web组件中封装HTML、CSS和JavaScript的技术。它是Web组件的一个重要特性,旨在将组件的结构、样式和行为封装在一个独立的、隔离的DOM树中,从而与主文档的DOM树相互隔离。 传统的Web开发中&#x…...

我的 365 天创作纪念日
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

spark-sql : “java.lang.NoSuchFieldError: out“ 异常解决
异常现象 at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:847)at org.apac…...
以及详细解析)
Node.js入门笔记(包含源代码)以及详细解析
Node.js 入门笔记源码 01、如何在终端中执行js 文件 目标:将下面的代码语句在中断中执行 代码演示: console.log(Hello World)for (let i 0;i < 3;i) {console.log(6)}方法:在文件上右击打开在终端中执行,然后输入node空格 输…...

windows自动化点击大麦app抢购、捡漏,仅支持windows11操作系统
文章目录 必要条件程序运行必要条件 确保windows11版本操作系统,如果不是可以通过镜像升级为windows11如果已经是windows11操作系统,确保更新到最新版本 修改系统所在时区,将国家或地区改为美国 开启虚拟化 勾选Hyper-V,如果没有则不需要勾选 勾选虚拟机平台 勾选完毕,点…...

vue 拦截 v-html 中 a 标签 href 跳转
记录 template 中 给需要 拦截的 代码片段加上click 方法 click“targetNodeNameClick” <p class"message-content message-content-text" v-html"replaceURLWithHTMLLinks(getText(message))" click"targetNodeNameClick"></p>然…...

分布式id、系统id、业务id以及主键之间的关系
推荐 连分布式ID都理解不了,你是刚培训出来冒充面试官的吧 1 分布式id、系统id、业务id以及主键之间的关系 分布式ID、系统ID、业务ID和主键的关系: 分布式ID:在分布式系统中,由于存在多个独立的节点,为了保证每个节…...
)
设计模式七:适配器模式(Adapter Pattern)
适配器模式(Adapter Pattern)是一种结构型设计模式,用于将一个类的接口转换成客户端所期望的另一个接口。它允许不兼容的接口能够协同工作。 适配器模式涉及角色: 目标接口(Target Interface):…...

数据结构---队列
(一)队列之基础补充 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。 —— 百科 「队列 Queue」是一种…...

chatGPT在软件测试中应用方式有哪些?
ChatGPT可以在软件测试中以以下方式应用: 1. 自动化对话测试:ChatGPT可以用于自动化对话测试,模拟用户与软件系统进行实时对话。它可以扮演用户的角色,向系统发送各种类型的指令和请求,并验证系统的响应是否符合预期。…...

chatgpt 接口使用(一)
使用api实现功能 参考链接:https://platform.openai.com/examples 安装库: pip3 install openai 例如: import os import openaiopenai.api_key os.getenv("OPENAI_API_KEY") response openai.ChatCompletion.create(model&q…...

【个人笔记】Linux 服务管理两种方式service和systemctl
service命令与systemctl 命令 service 命令与传统的 SysVinit 和 Upstart 初始化系统相关。较早期的 Linux 发行版(如早期的 Ubuntu、Red Hat 等)使用了这些初始化系统。service 命令用于启动、停止、重启和查询系统服务的状态。虽然许多现代 Linux 发行…...
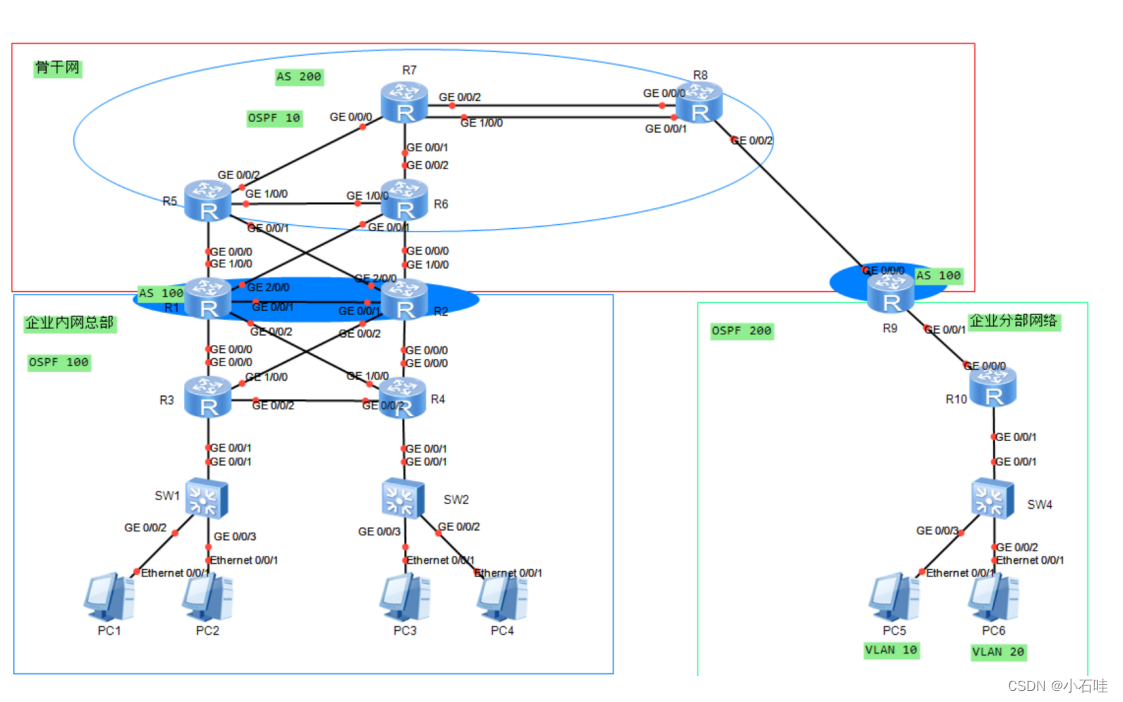
HCIP中期考试实验
考试需求 1、该拓扑为公司网络,其中包括公司总部、公司分部以及公司骨干网,不包含运营商公网部分。 2、设备名称均使用拓扑上名称改名,并且区分大小写。 3、整张拓扑均使用私网地址进行配置。 4、整张网络中,运行OSPF协议或者BGP…...
WebRTC的混音处理)
【WebRTC---源码篇】(二十二)WebRTC的混音处理
音频混音主力 音频混音主体主要通过(重采样) + (混音)为主 音频重采样 内容实现是在webrtc::voe中实现的,下面来对重采样全流程逐一分析 。 void RemixAndResample(const AudioFrame& src_frame,//源音频数据帧PushResampler<int16_t>* resampler,//重采样对…...

MTK system_server 卡死导致手机重启案例分析
和你一起终身学习,这里是程序员Android 经典好文推荐,通过阅读本文,您将收获以下知识点: 一、MTK AEE Log分析工具二、AEE Log分析流程三、system_server 卡死案例分析及解决 本文主要针对 Exception Type: system_server_watchdog , system_…...

加强 Kubernetes 能力:利用 CRD 定义多版本资源的实现方式
姚灿武,Rancher 中国研发工程师,拥有 7 年云计算领域经验,热衷开源技术,在云原生相关技术领域拥有丰富的开发和实践经验。 CRD,即自定义资源定义(Custom Resource Definition),是 Ku…...

区块链应用 DApp 开发需要掌握的技能
文章目录 前言为什么要开发 DAppDApp 的优势DApp 应用范围DApp 开发者技能 前言 前面区块链系列的文章中介绍了区块链技术、智能合约、web3js,Solidity 编程语言,在开发者的角度就是要基于这些知识在Web3时代去开发一个 DApp(去中心化应用程…...

关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题
由于一段时间没有使用Selenium,当再次使用时发现之前写的Selenium元素定位的代码运行之后会报错,发现是Selenium更新到新版本(4.x版本)后,以前的一些常用的代码的语法发生了改变,当然如果没有更新过或是下载…...

c++通过自然语言处理技术分析语音信号音高
对于语音信号的音高分析,可以使用基频提取技术。基频是指一个声音周期的重复率,也就是一个声音波形中最长的周期。 通常情况下,人的声音基频范围是85Hz到255Hz。根据语音信号的基频可以推断出其音高。 C中可以使用数字信号处理库或语音处理库…...
)
STM32 HAL库实战:手把手教你用匿名上位机V7显示自定义波形(附完整驱动代码)
STM32 HAL库与匿名上位机V7深度整合:自定义波形显示实战指南 在嵌入式系统开发中,数据可视化是调试和性能分析的关键环节。匿名上位机V7作为一款功能强大的国产调试工具,以其灵活的协议支持和直观的波形显示功能,成为众多工程师的…...

Visual C++运行库修复终极指南:AIO打包方案解决Windows系统兼容性难题
Visual C运行库修复终极指南:AIO打包方案解决Windows系统兼容性难题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾遇到过打开游戏或软件时…...

小红书内容采集全攻略:XHS-Downloader开源工具完整指南
小红书内容采集全攻略:XHS-Downloader开源工具完整指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&am…...

TypeScript函数式编程实战:fp-ts生产级应用技巧与模式解析
1. 项目概述:从类型体操到生产级函数式编程如果你在TypeScript社区里混迹过一段时间,大概率听说过或者用过fp-ts这个库。它把Haskell风格的函数式编程范式带到了TypeScript世界,提供了Option、Either、Task、Reader等一系列强大的代数数据类型…...

维普AI率82%熬夜改一周只降4个点!这款软件几分钟救我一命!
维普AI率82%熬夜改一周只降4个点!这款软件几分钟救我一命! 周一早上送维普看到 82% 那一刻 3 月 17 号周一早上 9 点。导师群:「答辩前再送一次维普看 AIGC 检测,下周一早上群里发达标截图」。我赶紧上传维普「智能检测 4.0」—…...

C++内存管理:从malloc到new的进化之路
在学习相关内容之前,我们先来做一道题目: 分析: globalvar是一个全局变量,所以globalvar在静态区;static GlobalVar被static修饰,说明它是一个静态变量,那就在静态区;static Var在静…...

从“抢人”到“识人”,回归匹配本质
金融校招如何穿透简历迷雾锁定真才? 在校园招聘的春季战场上,HR们往往陷入一种矛盾:一方面是后台爆满的简历收件箱,另一方面却是面试环节频频出现的“货不对板”。对于金融、咨询等对软素质要求极高的行业而言,校招实…...

全链路监控与可观测性:Spring AI 应用的日志、追踪与告警体系
系列导读 你现在看到的是《Spring AI 企业级集成与场景实践:从零搭建智能应用》的第 10/10 篇,当前这篇会重点解决:教会读者如何像监控数据库一样监控 AI 调用,快速定位性能瓶颈和异常。 上一篇回顾:第 9 篇《安全防线:Spring AI 应用的输入过滤、输出审核与数据隐私保…...

2026届学术党必备的AI论文网站实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 有着依托人工智能技术生成的免费AI论文工具,它为众多高校师生、科研从业者给予了…...
:mbuf、mempool、ethdev 的数据路径)
DPDK 教程(二):mbuf、mempool、ethdev 的数据路径
1 DPDK 教程(二):mbuf、mempool、ethdev 的数据路径 本文对应学习路径第二步:把“包从网卡进来到被应用消费”的主链路读成一张图。读完你应能口述:描述符环 → PMD RX → mbuf 与 mempool → 用户处理 → TX burst →…...