CMake简介
文章目录
- 为什么需要头文件
- 为什么 C++ 需要声明
- 头文件 - 批量插入几行代码的硬核方式
- 头文件进阶 - 递归地使用头文件
- CMake
- 什么是编译器
- 多文件编译与链接
- CMake 的命令行调用
- 为什么需要库(library)
- CMake 中的静态库与动态库
- CMake 中的子模块
- 子模块的头文件如何处理
- 目标的一些其他选项
- 第三方库 - 作为纯头文件引入
- 第三方库 - 作为子模块引入
为什么需要头文件
为什么 C++ 需要声明
在多文件编译章中,说到了需要在 main.cpp 声明 hello() 才能引用。为什么?
因为需要知道函数的参数和返回值类型:这样才能支持重载,隐式类型转换等特性。例如 show(3),如果声明了 void show(float x),那么编译器知道把 3 转换成 3.0f 才能调用。
让编译器知道 hello 这个名字是一个函数,不是一个变量或者类的名字:这样当我写下 hello() 的时候,他知道我是想调用 hello 这个函数,而不是创建一个叫 hello 的类的对象。
其实,C++ 是一种强烈依赖上下文信息的编程语言,举个例子:
vector < MyClass > a; // 声明一个由 MyClass 组成的数组
如果编译器不知道 vector 是个模板类,那他完全可以把 vector 看做一个变量名,把 < 解释为小于号,从而理解成判断‘vector’这个变量的值是否小于‘MyClass’这个变量的值。
正因如此,我们常常可以在 C++ 代码中看见这样的写法:typename decay::type
因为 T 是不确定的,导致编译器无法确定 decay 的 type 是一个类型,还是一个值。因此用 typename 修饰来让编译器确信这是一个类型名……
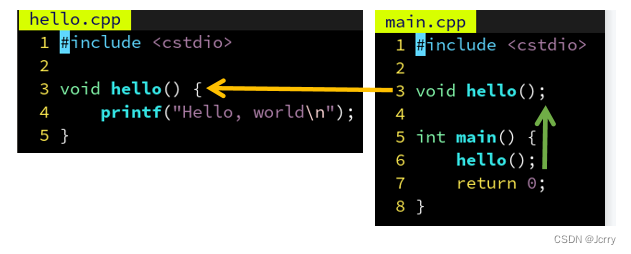
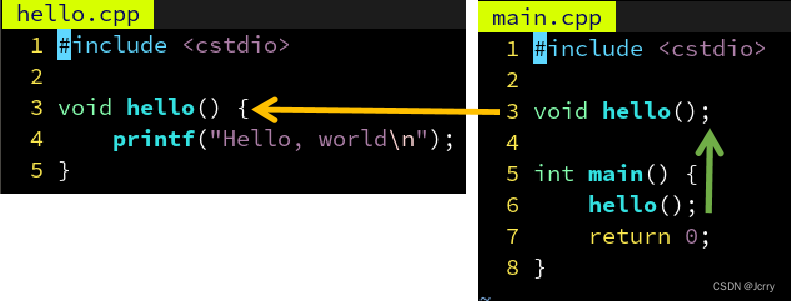
为了使用 hello 这个函数,我们刚才在 main.cpp 里声明了 void hello() 。
但是如果另一个文件 other.cpp 也需要用 hello 这个函数呢?也在里面声明一遍?
如果能够只写一遍,然后自动插入到需要用 hello 的那些 .cpp 里就好了……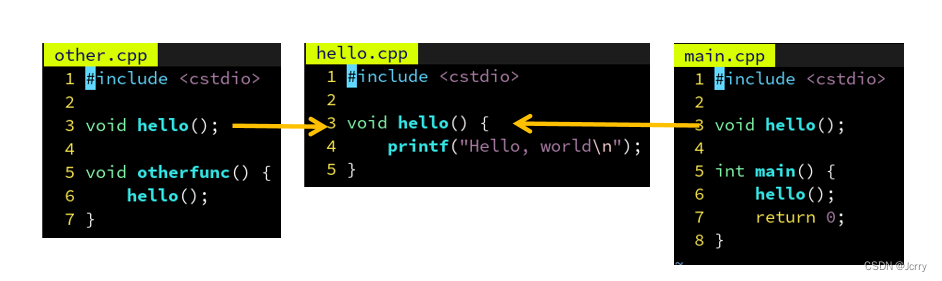
头文件 - 批量插入几行代码的硬核方式
没错,C 语言的前辈们也想到了,他们说,既然每个 .cpp 文件的这个部分是一模一样的,不如我把 hello() 的声明放到单独一个文件 hello.h 里,然后在需要用到 hello() 这个声明的地方,打上一个记号,#include “hello.h” 。然后用一个小程序,自动在编译前把引号内的文件名 hello.h 的内容插入到记号所在的位置,这样不就只用编辑 hello.h 一次了嘛~
后来,这个编译前替换的步骤逐渐变成编译器的了一部分,称为预处理阶段,#define 定义的宏也是这个阶段处理的。
此外,在实现的文件 hello.cpp 中导入声明的文件 hello.h 是个好习惯,可以保证当 hello.cpp 被修改时,比如改成 hello(int),编译器能够发现 hello.h 声明的 hello() 和定义的 hello(int) 不一样,避免“沉默的错误”。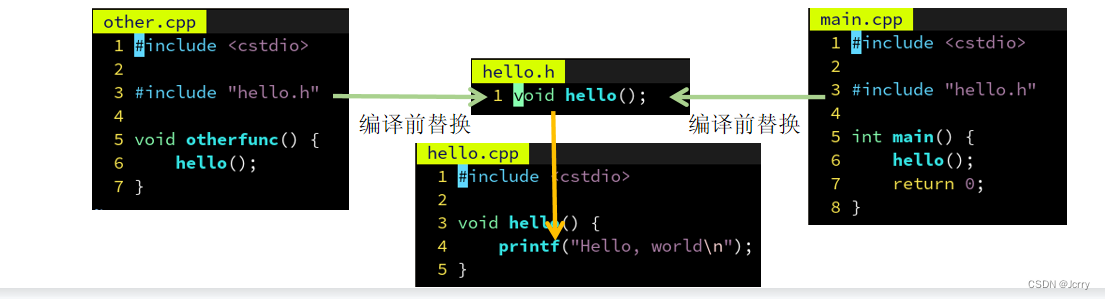
实际上 cstdio 也无非是提供了 printf 等一系列函数声明的头文件而已,实际的实现是在 libc.so 这个动态库里。其中 这种形式表示不要在当前目录下搜索,只在系统目录里搜索,”hello.h” 这种形式则优先搜索当前目录下有没有这个文件,找不到再搜索系统目录。
此外,在实现的文件 hello.cpp 中也导入声明的文件 hello.h 是个好习惯:
可以保证当 hello.cpp 被修改时,比如改成 hello(int),编译器能够发现 hello.h 声明的 hello() 和定义的 hello(int) 不一样,避免“沉默的错误”(虽然对支持重载的 C++ 不奏效)
可以让 hello.cpp 中的函数需要相互引用时,不需要关心定义的顺序。
头文件进阶 - 递归地使用头文件
在 C++ 中常常用到很多的类,和函数一样,类的声明也会被放到头文件中。
有时候我们的函数声明需要使用到某些类,就需要用到声明了该类的头文件,像这样递归地 #include 即可: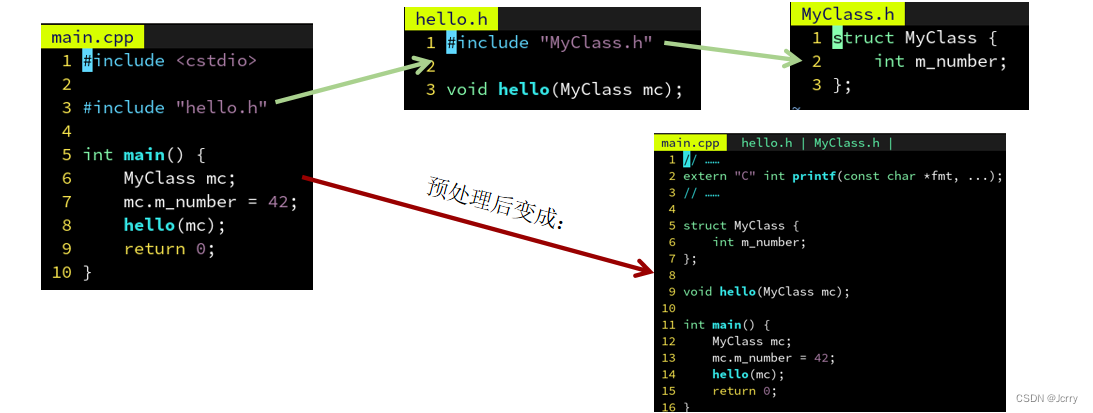
但是这样造成一个问题,就是如果多个头文件都引用了 MyClass.h,那么 MyClass 会被重复定义两遍: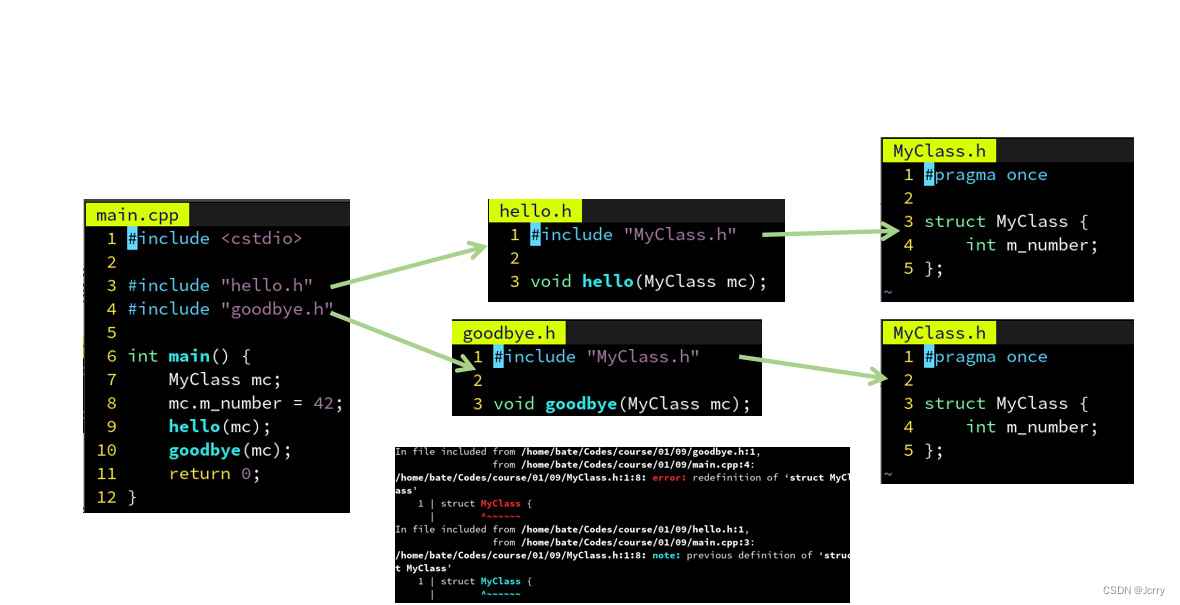
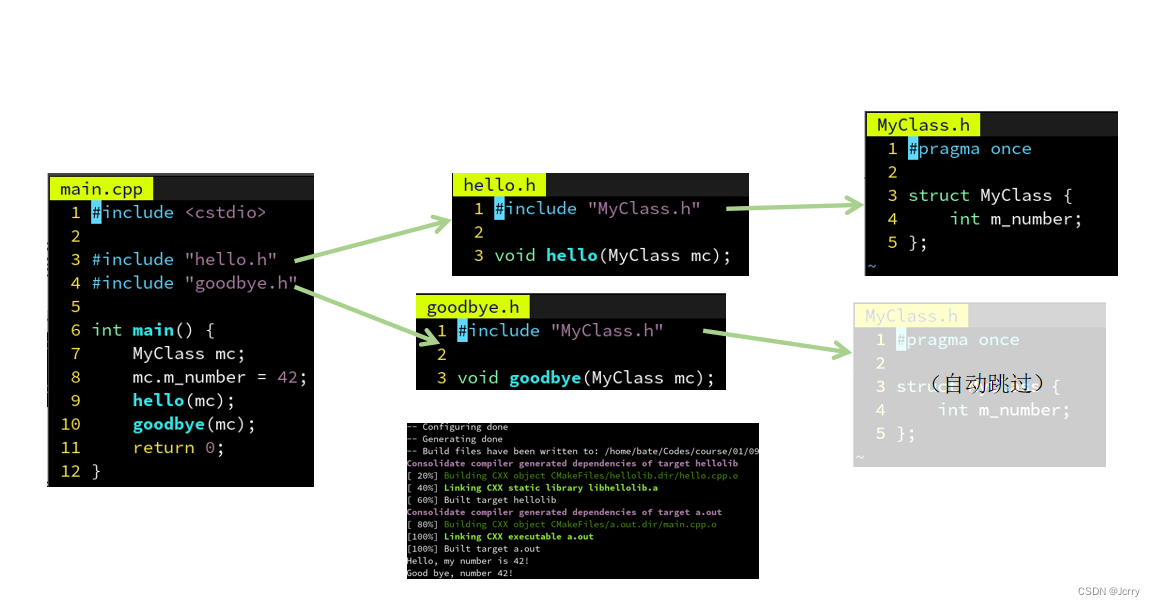
解决方案:在头文件前面加上一行:#pragma once
这样当预处理器第二次读到同一个文件时,就会自动跳过
通常头文件都不想被重复导入,因此建议在每个头文件前加上这句话
CMake
什么是编译器
编译器,是一个根据源代码生成机器码的程序。
>g++ main.cpp -o a.out
该命令会调用编译器程序g++,让他读取main.cpp中的字符串(称为源码),并根据C++标准生成相应的机器指令码,输出到a.out这个文件中,(称为可执行文件)。
> ./a.out
之后执行该命令,操作系统会读取刚刚生成的可执行文件,从而执行其中编译成机器码,调用系统提供的printf函数,并在终端显示出Hello, world。

多文件编译与链接
单文件编译虽然方便,但也有如下缺点:
所有的代码都堆在一起,不利于模块化和理解。
工程变大时,编译时间变得很长,改动一个地方就得全部重新编译。
因此,我们提出多文件编译的概念,文件之间通过符号声明相互引用。
> g++ -c hello.cpp -o hello.o
> g++ -c main.cpp -o main.o
其中使用 -c 选项指定生成临时的对象文件 main.o,之后再根据一系列对象文件进行链接,得到最终的a.out:
> g++ hello.o main.o -o a.out
CMake 的命令行调用
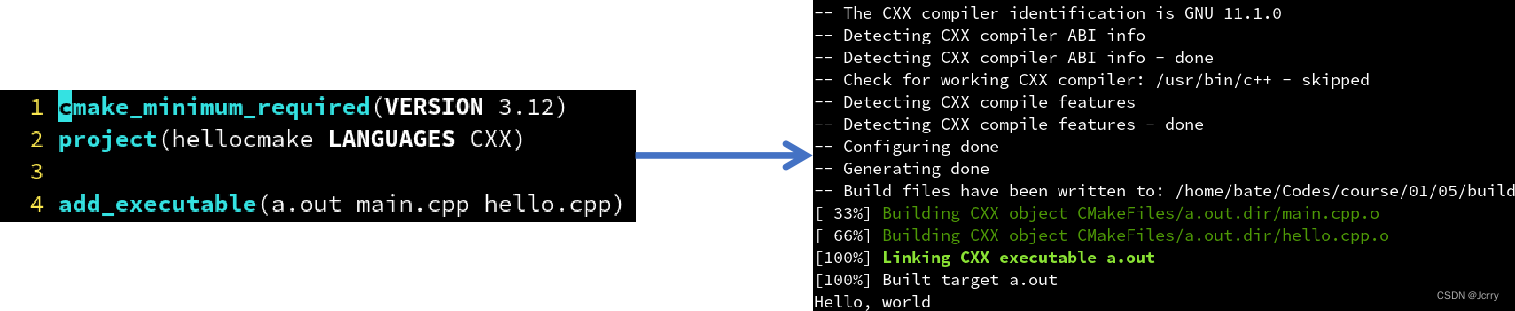
读取当前目录的 CMakeLists.txt,并在 build 文件夹下生成 build/Makefile:
> cmake -B build
让 make 读取 build/Makefile,并开始构建 a.out:
> make -C build
以下命令和上一个等价,但更跨平台:
> cmake --build build
执行生成的 a.out:
> build/a.out
为什么需要库(library)

有时候我们会有多个可执行文件,他们之间用到的某些功能是相同的,我们想把这些共用的功能做成一个库,方便大家一起共享。
库中的函数可以被可执行文件调用,也可以被其他库文件调用。
库文件又分为静态库文件和动态库文件。
其中静态库相当于直接把代码插入到生成的可执行文件中,会导致体积变大,但是只需要一个文件即可运行。
而动态库则只在生成的可执行文件中生成“插桩”函数,当可执行文件被加载时会读取指定目录中的.dll文件,加载到内存中空闲的位置,并且替换相应的“插桩”指向的地址为加载后的地址,这个过程称为重定向。这样以后函数被调用就会跳转到动态加载的地址去。
Windows:可执行文件同目录,其次是环境变量%PATH%
Linux:ELF格式可执行文件的RPATH,其次是/usr/lib等
CMake 中的静态库与动态库
CMake 除了 add_executable 可以生成可执行文件外,还可以通过 add_library 生成库文件。
add_library 的语法与 add_executable 大致相同,除了他需要指定是动态库还是静态库:
add_library(test STATIC source1.cpp source2.cpp) # 生成静态库 libtest.a
add_library(test SHARED source1.cpp source2.cpp) # 生成动态库 libtest.so
动态库有很多坑,特别是 Windows 环境下,初学者自己创建库时,建议使用静态库。
但是他人提供的库,大多是作为动态库的, 之后会讨论如何使用他人的库。
创建库以后,要在某个可执行文件中使用该库,只需要:
target_link_libraries(myexec PUBLIC test) # 为 myexec 链接刚刚制作的库 libtest.a
其中 PUBLIC 的含义稍后会说明(CMake 中有很多这样的大写修饰符)
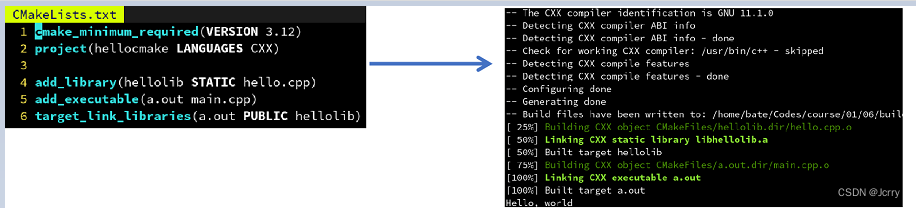
CMake 中的子模块
复杂的工程中,我们需要划分子模块,通常一个库一个目录,比如:
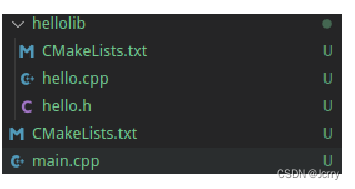
这里我们把 hellolib 库的东西移到 hellolib 文件夹下了,里面的 CMakeLists.txt 定义了 hellolib 的生成规则。
要在根目录使用他,可以用 CMake 的 add_subdirectory 添加子目录,子目录也包含一个 CMakeLists.txt,其中定义的库在 add_subdirectory 之后就可以在外面使用。
子目录的 CMakeLists.txt 里路径名(比如 hello.cpp)都是相对路径,这也是很方便的一点。

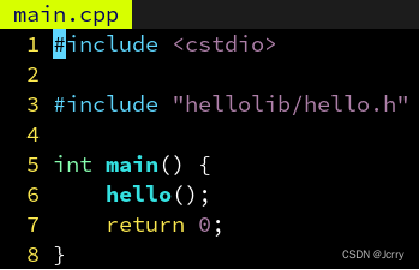
子模块的头文件如何处理
因为 hello.h 被移到了 hellolib 子文件夹里,因此 main.cpp 里也要改成:
如果要避免修改代码,我们可以通过 target_include_directories 指定
a.out 的头文件搜索目录:(其中第一个 hellolib 是库名,第二个是目录)

这样甚至可以用 <hello.h> 来引用这个头文件了,因为通过 target_include_directories 指定的路径会被视为与系统路径等价:
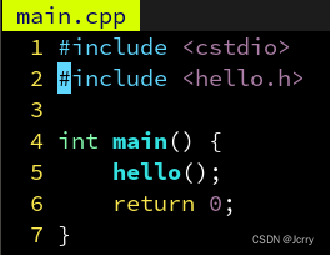
但是这样如果另一个 b.out 也需要用 hellolib 这个库,难道也得再指定一遍搜索路径吗?
不需要,其实我们只需要定义 hellolib 的头文件搜索路径,引用他的可执行文件 CMake 会自动添加这个路径:

这里用了 . 表示当前路径,因为子目录里的路径是相对路径,类似还有 … 表示上一层目录。
此外,如果不希望让引用 hellolib 的可执行文件自动添加这个路径,把 PUBLIC 改成 PRIVATE 即可。这就是他们的用途:决定一个属性要不要在被 link 的时候传播。
目标的一些其他选项
除了头文件搜索目录以外,还有这些选项,PUBLIC 和 PRIVATE 对他们同理:
target_include_directories(myapp PUBLIC /usr/include/eigen3) # 添加头文件搜索目录
target_link_libraries(myapp PUBLIC hellolib) # 添加要链接的库
target_add_definitions(myapp PUBLIC MY_MACRO=1) # 添加一个宏定义
target_add_definitions(myapp PUBLIC -DMY_MACRO=1) # 与 MY_MACRO=1 等价
target_compile_options(myapp PUBLIC -fopenmp) # 添加编译器命令行选项
target_sources(myapp PUBLIC hello.cpp other.cpp) # 添加要编译的源文件
以及可以通过下列指令(不推荐使用),把选项加到所有接下来的目标去:
include_directories(/opt/cuda/include) # 添加头文件搜索目录
link_directories(/opt/cuda) # 添加库文件的搜索路径
add_definitions(MY_MACRO=1) # 添加一个宏定义
add_compile_options(-fopenmp) # 添加编译器命令行选项
第三方库 - 作为纯头文件引入
有时候我们不满足于 C++ 标准库的功能,难免会用到一些第三方库。
最友好的一类库莫过于纯头文件库了,这里是一些好用的 header-only 库:
nothings/stb - 大名鼎鼎的 stb_image 系列,涵盖图像,声音,字体等,只需单头文件!
Neargye/magic_enum - 枚举类型的反射,如枚举转字符串等(实现方式很巧妙)
g-truc/glm - 模仿 GLSL 语法的数学矢量/矩阵库(附带一些常用函数,随机数生成等)
Tencent/rapidjson - 单纯的 JSON 库,甚至没依赖 STL(可定制性高,工程美学经典)
ericniebler/range-v3 - C++20 ranges 库就是受到他启发(完全是头文件组成)
fmtlib/fmt - 格式化库,提供 std::format 的替代品(需要 -DFMT_HEADER_ONLY)
gabime/spdlog - 能适配控制台,安卓等多后端的日志库(和 fmt 冲突!)
只需要把他们的 include 目录或头文件下载下来,然后 include_directories(spdlog/include) 即可。
缺点:函数直接实现在头文件里,没有提前编译,从而需要重复编译同样内容,编译时间长。
第三方库 - 作为子模块引入
第二友好的方式则是作为 CMake 子模块引入,也就是通过 add_subdirectory。
方法就是把那个项目(以fmt为例)的源码放到你工程的根目录:
这些库能够很好地支持作为子模块引入:
fmtlib/fmt - 格式化库,提供 std::format 的替代品
gabime/spdlog - 能适配控制台,安卓等多后端的日志库
ericniebler/range-v3 - C++20 ranges 库就是受到他启发
g-truc/glm - 模仿 GLSL 语法的数学矢量/矩阵库
abseil/abseil-cpp - 旨在补充标准库没有的常用功能
bombela/backward-cpp - 实现了 C++ 的堆栈回溯便于调试
google/googletest - 谷歌单元测试框架
google/benchmark - 谷歌性能评估框架
glfw/glfw - OpenGL 窗口和上下文管理
libigl/libigl - 各种图形学算法大合集
相关文章:
CMake简介
文章目录 为什么需要头文件为什么 C 需要声明头文件 - 批量插入几行代码的硬核方式头文件进阶 - 递归地使用头文件 CMake什么是编译器多文件编译与链接CMake 的命令行调用为什么需要库(library)CMake 中的静态库与动态库CMake 中的子模块子模块的头文件如…...
[threejs]相机与坐标
搞清相机和坐标的关系在threejs初期很重要,否则有可能会出现写了代码,运行时一片漆黑的现象,这种情况就有可能是因为你相机没弄对。 先来看一下threejs中的坐标(世界坐标) 坐标轴好理解,大家只需要知道在three中不同颜色代表的轴…...

Qt信号与槽机制的基石-MOC详解
引入 上篇讲到了信号与槽就是实现的观察者模式,那具体如何生成映射表就是moc做的事情。 一、moc简介 1. moc的定义 moc 全称是 Meta-Object Compiler,也就是“元对象编译器”,它主要用于处理C源文件中的非标准C代码。Qt 程序在交由标准编…...

关于单体架构缓存刷新实现方案
背景 如果各位看官是分布式项目应该都采用分布式缓存了,例如redis等,分布式缓存不在本次讨论范围哈;我个人建议是,如果是用户量比较大,建议采用分布式缓存机制,后期可以很容易前后到分布式服务或微服务。 …...

洞悉安全现状,建设网络安全防护新体系
一、“网络攻防演练行动“介绍 国家在2016年发布《网络安全法》,出台网络安全攻防演练相关规定:关键信息基础设施的运营者应“制定网络安全事件应急预案,并定期进行演练”。同年“实战化网络攻防演练行动”成为惯例。由公安部牵头࿰…...
spring中怎么通过静态工厂和动态工厂获取对象以及怎么通过 FactoryBean 获取对象
😀前言 本章是spring基于XML 配置bean系类中第4篇讲解spring中怎么通过静态工厂和动态工厂获取对象以及怎么通过 FactoryBean 获取对象 🏠个人主页:尘觉主页 🧑个人简介:大家好,我是尘觉,希望…...
)
三元组表实现矩阵相加(数据结构)
代码: 含注释,供参考 #include <stdio.h> #include <stdlib.h>typedef struct {int row,col,value;//分别为行数,列数,数值 } Triple; typedef struct {int len;//非零数值的个数Triple data[200]; } TSMatrix;void…...

ChinaJoy 2023微星雷鸟17游戏本震撼发布:搭载AMD锐龙9 7945HX首发8499元
ChinaJoy 2023展会中微星笔记本再次给大家带来惊喜,发布了搭载AMD移动端16大核的旗舰游戏本:雷鸟17,更重要的这样一款旗舰性能的游戏本,首发价8499元堪称当今游戏本市场中的“性价比爆款”! 本着和玩家一同制霸游戏战场…...

各种运算符
算术运算符 1.双目运算符 */%:从左到右优先级依次降低 一些注意事项: 1若a/b都为整型那么结果也为整型,如果ab其中有一个为实型,结果则为实型 求余运算符注意事项: 1运算对象必须为整数 2运算结果的整数跟左边数字的…...
yolov3-tiny原理解析及代码分析
前言 从去年十一月份开始学习yolo神经网络用于目标识别的硬件实现,到现在已经六个月了。一个硬件工程师,C/C基础都差劲的很,对照着darknet作者的源码和网上东拼西凑的原理讲解,一点一点地摸索。刚开始进度很慢,每天都…...

深入了解Redis-实战篇-短信登录
深入了解Redis-实战篇-短信登录 一、故事背景二、知识点主要构成2.1、短信登录2.1.1、生成随机短信验证码引入maven依赖生成验证码 2.1.2、实现登录校验拦截器2.1.3、基于Redis实现短信登录2.1.3.1、发送验证码时存入Redis2.1.3.2、登录时校验验证码 2.1.4、解决状态登录刷新的…...
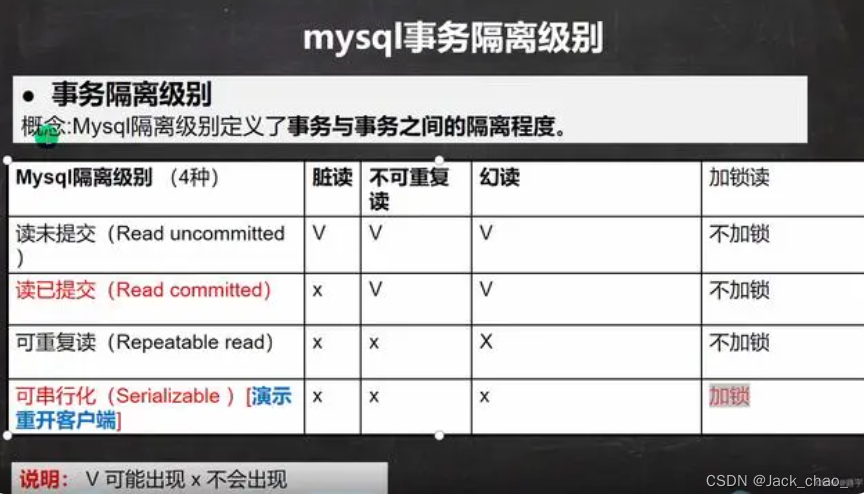
Mysql的锁
加锁的目的 对数据加锁是为了解决事务的隔离性问题,让事务之前相互不影响,每个事务进行操作的时候都必须先加上一把锁,防止其他事务同时操作数据。 事务的属性 (ACID) 原子性 一致性 隔离性 持久性 事务的隔离级别 锁…...

【EI/SCOPUS征稿】2023年算法、图像处理与机器视觉国际学术会议(AIPMV2023)
2023年算法、图像处理与机器视觉国际学术会议(AIPMV2023) 2023 International Conference on Algorithm, Image Processing and Machine Vision(AIPMV2023) 2023年算法、图像处理与机器视觉国际学术会议(AIPMV2023&am…...
Go语言性能优化建议与pprof性能调优详解——结合博客项目实战
文章目录 性能优化建议Benchmark的使用slice优化预分配内存大内存未释放 map优化字符串处理优化结构体优化atomic包小结 pprof性能调优采集性能数据服务型应用go tool pprof命令项目调优分析修改main.go安装go-wrk命令行交互界面图形化火焰图 性能优化建议 简介: …...
)
K阶斐波那契数列(数据结构)
代码: 注意k阶斐波那契序列定义:第k和k1项为1,前k - 1项为0,从k项之后每一项都是前k项的和 例如:k2时,斐波那契序列为:0,1,1,2,3,5,8,13... k3时,斐波那契序列为:0,0,…...

【JavaEE】博客系统前后端交互
目录 一、准备工作 二、数据库的表设计 三、封装JDBC数据库操作 1、创建数据表对应的实体类 2、封装增删改查操作 四、前后端交互逻辑的实现 1、博客列表页 1.1、展示博客列表 1.2、博客详情页 1.3、登录页面 1.4、强制要求用户登录,检查用户的登录状态 …...
Redis 简介
文章目录 Redis 简介 Redis 简介 Redis(Remote Dictionary Server),远程词典服务器,基于 C/S 架构,是一个基于内存的键值型 NoSQL 数据库,开源,遵守 BSD 协议,Redis 由 C语言 实现。…...

CS162 13-17 虚拟内存
起源 为啥我们需要虚拟内存-----------需求是啥? 可以给程序提供一个统一的视图,比如多个程序运行同一个代码段的话,同一个kernel,就可以直接共享 cpu眼里的虚拟内存 无限内存的假象 设计迭代过程 为啥这样设计? 一…...
接口自动化测试-Jmeter+ant+jenkins实战持续集成(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、下载安装配置J…...

最长连续序列——力扣128
文章目录 题目描述法一 哈希表 题目描述 法一 哈希表 用一个哈希表存储数组中的数,这样查看一个数是否存在即能优化至 O(1) 的时间复杂度 每次在哈希表中检查是否存在 x−1 即能判断是否需要跳过 int longestConsecutive(vector<int>& nums){unordered_s…...
)
老板惊呆了!Laravel 接入 OnlyOffice 后,团队协作效率翻 3 倍(附安全加固方案)
文章目录老板惊呆了!Laravel 接入 OnlyOffice 后,团队协作效率翻 3 倍(附安全加固方案)一、整体架构二、准备工作:OnlyOffice 服务(Docker 版)三、Laravel 后端集成1. 安装必要依赖2. 配置 Only…...

B站缓存合并工具:Android设备上的离线视频处理神器
B站缓存合并工具:Android设备上的离线视频处理神器 【免费下载链接】BilibiliCacheVideoMerge 🔥🔥Android上将bilibili缓存视频合并导出为mp4,支持安卓5.0 ~ 13,视频挂载弹幕播放(Android consolidates and exports t…...

LSTM比特币价格预测:特征工程驱动的交易信号生成器
1. 项目概述:为什么用RNN/LSTM做比特币价格预测,而不是随便套个模型?我从2018年开始接触加密资产量化分析,最早用的是ARIMA和随机森林——前者对趋势拐点完全失灵,后者在训练集上准确率92%,一到实盘就跌破6…...

Burp Suite安装避坑指南:Java环境、代理配置与HTTPS解密全解析
1. 为什么Burp Suite的安装,比你想象中更值得花20分钟认真对待 很多人点开“Burp Suite安装教程”,心里想的是:“不就是下载个JAR包,双击运行吗?5分钟搞定。”我试过——在三台不同配置的Windows机器上,用…...

异常检测实战:从面试陷阱到产线落地的20个关键问题
1. 项目概述:这不是刷题手册,而是一张通往机器学习工程现场的“通关地图”“Crack ML Interviews with Confidence: Anomaly Detection (20 Q&A)”——这个标题里藏着三个被绝大多数求职者严重低估的关键信号:Crack不是“背答案”&#x…...

视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单
视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含…...

工业物联网实战:Wind River Helix与边缘网关的云边协同部署指南
1. 项目概述:当工业软件平台遇上边缘网关最近在做一个工业物联网项目,客户现场有几十台不同年代、不同协议的设备需要接入云端,同时边缘侧还要跑一些实时性要求很高的控制逻辑。这让我想起了几年前折腾过的Wind River Helix平台和它的App Clo…...

FanControl终极指南:3个核心模块助你打造完美风扇控制方案
FanControl终极指南:3个核心模块助你打造完美风扇控制方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

CANN-Ascend-C存储体系-昇腾NPU的四级缓存怎么用才算对
写 Ascend C 算子,最常犯的错误不是计算写错,是数据搬运写错。昇腾NPU有四级存储,每一级的容量、带宽、延迟都不同。数据该放在哪一级、什么时候搬、搬多少,直接决定算子性能。 四级存储级别名称容量带宽延迟用途L0HBM(…...

Spotify推AI应用Studio,结合多信息源生成简报、播客和歌单!能“代你行动”
Spotify Studio:AI驱动的内容生成新利器Spotify Labs推出的全新独立AI应用程序Studio,可根据聊天机器人提示,在用户电脑上生成每日简报、播客和歌单。其生成内容会参考用户在Spotify上的收听历史,以及连接到该应用的其他应用信息&…...