python解析帆软cpt及frm文件(xml)获取源数据表及下游依赖表
#!/user/bin/evn python
import os,re,openpyxl
'''输入:帆软脚本文件路径输出:帆软文件检查结果Excel
'''
#获取来源表
def table_scan(sql_str):# remove the /* */ commentsq = re.sub(r"/\*[^*]*\*+(?:[^*/][^*]*\*+)*/", "", sql_str)# remove whole line -- and # commentslines = [line for line in q.splitlines() if not re.match("^\s*(--|#)", line)]# print(q)# remove trailing -- and # commentsq = " ".join([re.split("--|#", line)[0] for line in lines])# split on blanks, parens and semicolonstokens = re.split(r"[\s)(;]+", q)# scan the tokens. if we see a FROM or JOIN, we set the get_next# flag, and grab the next one (unless it's SELECT).result = []get_next = Falsefor token in tokens:if get_next:if token.lower() not in ["", "select"]:result.append(token)get_next = Falseget_next = token.lower() in ["from", "join"]return result#【文件扫描,使用正则解析第一版,准确性不太高!】
def file_scan(path):f_content=open(path,'r',encoding='utf-8').read()#1、数据集查询sqlgpat=re.compile('<TableDataMap>(.*?)</TableDataMap>',re.S)if_has_sqlg=re.findall(sqlgpat,f_content)rs_sql_list=[]if if_has_sqlg:#获取数据集名称以及数据集查询语句sqlspat=re.compile('<TableData name="(.*?)".*?<DatabaseName>\n<!\[CDATA\[(.*?)]]></DatabaseName>.*?<Query>\n<!\[CDATA\[(.*?)]]></Query>.*?</TableData>',re.S)rs1=re.findall(sqlspat,if_has_sqlg[0])for rsv in rs1:from_tables=[]if '"*/"' in rsv[1]:sql=rsv[1].split('*/')for ss in sql:from_tables.extend(table_scan(ss))else:from_tables.extend(table_scan(rsv[2]))rs_sql_list.append([rsv[0],rsv[1],rsv[2],set(from_tables)])# print(rsv[1])#2、js获取if_has_jsgpat=re.compile('<NameJavaScript name="(.*?)</NameJavaScript>',re.S)if_has_jsg=re.findall(if_has_jsgpat, f_content)rep_list = [] # 报表列表,去重if if_has_jsg:for jscon in if_has_jsg:# conturlpat=re.compile('<Content>.*?var\surl\s=.*?viewlet=(.*?.[cptfrm]{3})&.*?</Content>',re.S)conturlpat = re.compile('<Content>.*?viewlet=(.*?[cptfrm]{3})[&?].*?</Content>', re.S)if '<JavaScript class="com.fr.js.ReportletHyperlink">' in jscon:# rlpat=re.compile('<ReportletName extendParameters="true" showPI="true">\s<!\[CDATA\[(.*?)]]></ReportletName>',re.S)rlpat = re.compile( '<ReportletName .*?\[CDATA\[(.*?)]]></ReportletName>', re.S)rl=re.findall(rlpat,jscon)[0]# print(re.findall(rlpat,jscon))if rl not in rep_list:rep_list.append(rl)elif '<JavaScript class="com.fr.js.WebHyperlink">' in jscon:wlpat=re.compile('<URL>\s<!\[CDATA\[(.*?)]]></URL>',re.S)wl=re.findall(wlpat,jscon)[0]if wl not in rep_list:rep_list.append(wl)elif re.search(conturlpat,jscon):frl=re.findall(conturlpat,jscon)[0]print(frl)if not frl.startswith('/'):frl='/'+frlif frl not in rep_list:rep_list.append(frl)# elif '<JavaScript class="com.fr.js.JavaScriptImpl">'in jscon and('.cpt' in jscon or '.frm' in jscon) :# print(jscon)if_has_cljpat=re.compile(r'<RHIframeSource.*?<Attr path="(.*?[cptfrm]{3}).*?</RHIframeSource>',re.S)f_has_clj=re.findall(if_has_cljpat,f_content)if f_has_clj:for v in f_has_clj:if v not in rep_list:rep_list.append(v)# print(rep_list)return rep_list,rs_sql_list#使用xml解析精准获取,解析升级版
def xml_scan(path):import xml.etree.ElementTree as ETtree = ET.parse(path) # 打开xml文件dataset_iters = [] # 数据集名称,数据集数据库链接名,数据集查询语句,数据集来源sql表if list(tree.getroot().iter("TableDataMap")):# 数据集TableDataMap父节点table_map_content = list(tree.getroot().iter("TableDataMap"))[0]# 获取数据集查询名称dataset_iters_map = table_map_content.iter('TableData')for val in dataset_iters_map:# print('查询名称--',val.attrib.get("name"))dataset_name = val.attrib.get("name").strip()if len(list(val.iter("DatabaseName"))):# 帆软目前一个数据集查询框只能链接单个数据库,所以获取数据库链接名只有1个# print('查询数据库链接名--', list(val.iter("DatabaseName"))[0].text.strip())dataset_connect_name = list(val.iter("DatabaseName"))[0].text.strip()else:# print('查询数据库链接名--',None)dataset_connect_name = Noneif len(list(val.iter("Query"))):# 帆软目前一个数据集查询框只能链接单个数据库,所以获取数据库链接名只有1个,且只有一个sql查询窗口内容# print('查询数据查询语句--', list(val.iter("Query"))[0].text.strip())dataset_query = list(val.iter("Query"))[0].text.strip()from_tables = []if '"*/"' in dataset_query:sql = dataset_query.split('*/')for ss in sql:from_tables.extend(table_scan(ss))else:from_tables.extend(table_scan(dataset_query))else:# print('查询数据查询语句--', None)dataset_query = Nonefrom_tables=[]dataset_iters.append([dataset_name, dataset_connect_name, dataset_query,from_tables])urls = set() # 报表全体下游调用URL集合js_contents = [] # js内容,内容清洗出来的URL,用于核对数据清洗是否准确# print(len(list(tree.iter("ReportletName"))))#js链接报表-网格报表-本地服务器local_url = [v.text.strip() for v in tree.iter("ReportletName")]if local_url:urls.update(local_url)# print(len(list(tree.iter("URL")))) # js链接报表-网格报表-远程web链接web_url = [v.text.strip() for v in tree.iter("URL")]if web_url:urls.update(web_url)# print(len(list(val.iter("RHIframeSource"))))# js链接报表-tab框架挂载报表for v in tree.iter("RHIframeSource"):webframe_url = list(v.iter("Attr"))[0].attrib.get("path")# 去除URL尾巴参数if webframe_url and not webframe_url.endswith("frm") and not webframe_url.endswith("cpt"):rpat = re.compile(r'.*?[cptfrm]{3}', re.I)webframe_url = re.findall(rpat, webframe_url)[0]urls.update([webframe_url])elif webframe_url:urls.update([webframe_url])# print(len(list(val.iter("Content"))))for cv in list(tree.iter("Content")):contents = cv.texttemp_url = []# print(contents)http_ul_pat = re.compile(r'"(http.*?)"') #js内容里面挂载web超链接local_ul_pat = re.compile(r'viewlet=(.*?[cptfrm]{3})')#js内容里面挂载服务器本地绝对路径报表链接# print(re.findall(http_ul_pat,contents))# print(re.findall(local_ul_pat, contents))if re.findall(http_ul_pat, contents):urls.update(re.findall(http_ul_pat, contents))temp_url.extend(re.findall(http_ul_pat, contents))if re.findall(local_ul_pat, contents):# print(re.findall(local_ul_pat, contents))#处理挂载服务器本地链接路径,有些挂载绝对目录不规范a/b/c.cpt处理后输出/a/b/c.cptfor vl in re.findall(local_ul_pat, contents):if vl.startswith('/'):urls.update([vl])temp_url.append(vl)else:urls.update(['/'+vl])temp_url.append('/'+vl)js_contents.append([contents, temp_url])# print(js_contents)return dataset_iters,urls,js_contentsdef write_excel(list_tar,file_path):wb = openpyxl.Workbook() # 新建工作簿sheet0=wb[wb.sheetnames[0]]sheet0.title=('引用报表列表')sheet1 = wb.create_sheet('来源mysql表')sheet2 = wb.create_sheet('帆软数据集查询及依赖明细')sheet3 = wb.create_sheet('帆软JS内容明细')sheet0['A1'] = '文件名'sheet0['B1'] = '依赖报表'sheet1['A1'] = '文件名'sheet1['B1'] = '依赖mysql表'sheet2['A1'] = '文件名'sheet2['B1'] = '数据集查询名称'sheet2['C1'] = '数据库链接名称'sheet2['D1'] = '数据集查询语句'sheet2['E1'] = '数据来源mysql表'sheet3['A1'] = '文件名'sheet3['B1'] = 'JS内容'sheet3['C1'] = 'JS解析URL'r=1k=1d=1x=1for index,item in enumerate(list_tar):print(('开始处理第 '+str(index+1)+' 个文件结果,共 '+str(len(list_tar))+' 个').center(50,'-'))# filename,dataset_iters, urls, js_contents# dataset_iters = [] # 数据集名称,数据集数据库链接名,数据集查询语句,数据集来源sql表target_file_name=item[0]cpt=item[2]sql=item[1]jsc=item[3]for id1,value in enumerate(sorted(cpt)):r=r+1sheet0.cell(row=r, column=1, value=target_file_name)sheet0.cell(row=r, column=2, value=value)sql_set=set()for id1,val in enumerate(sql):k = k + 1sql_set.update(val[3])sheet2.cell(row=k, column=1, value=target_file_name)sheet2.cell(row=k, column=2, value=val[0])sheet2.cell(row=k, column=3, value=val[1])sheet2.cell(row=k, column=4, value=val[2])sheet2.cell(row=k, column=5, value='\n'.join(val[3]))for id1,value in enumerate(sorted(sql_set)):d = d + 1sheet1.cell(row=d, column=1, value=target_file_name)sheet1.cell(row=d, column=2, value=value)for id1, value in enumerate(sorted(jsc)):if value[0] or value[1]:x = x +1sheet3.cell(row=x, column=1, value=target_file_name)sheet3.cell(row=x, column=2, value=value[0])sheet3.cell(row=x, column=3, value='\n'.join(value[1]))wb.save(file_path)wb.close() # excel使用完成需要关闭,否则会报错def main_scan(fr_path,result_path):rs_list=[]for index,file_name in enumerate(os.listdir(fr_path)):print(('正在扫描第 '+str(index+1)+' 个文件,共 '+str(len(os.listdir(fr_path)))+' 个文件').center(50,'-'))try:dataset_iters,urls,js_contents = xml_scan(os.path.join(fr_path,file_name))rs_list.append([file_name,dataset_iters,urls,js_contents])except:print('【文件扫描失败】:',file_name)print('文件扫描完毕,正在写入Excel'.ljust(50,'-'))write_excel(rs_list, result_path)if __name__ == '__main__':#帆软扫描文件夹绝对路径fr_path=r'C:\FineReport_10.0\webapps\webroot\WEB-INF\reportlets\mytest\'#帆软扫描结果文件绝对路径result_path=r'C:\FineReport_10.0\webapps\webroot\WEB-INF\reportlets\scaning_result.xlsx'main_scan(fr_path, result_path)
运行结果
![]()


![]()
![]()
相关文章:

python解析帆软cpt及frm文件(xml)获取源数据表及下游依赖表
#!/user/bin/evn python import os,re,openpyxl 输入:帆软脚本文件路径输出:帆软文件检查结果Excel#获取来源表 def table_scan(sql_str):# remove the /* */ commentsq re.sub(r"/\*[^*]*\*(?:[^*/][^*]*\*)*/", "", sql_str)# r…...

TypeScript
TypeScript 简称: TS ,是 JavaScript 的超集 ,简单来说就是: JS 有的 TS 都有 TypeScript Type JavaScript (在 JS 基础之上, 为 JS 添加了类型支持 ) TypeScript 是 微软 开发…...

解决启动vue前端报错:npm ERR! Missing script: “serve“
目录 一、遇到问题 二、出现报错的两个原因 三、解决办法 一、遇到问题 npm ERR! Missing script: "serve" npm ERR! npm ERR! To see a list of scripts, run: npm ERR! npm run npm ERR! A complet...

数据结构 | 线性数据结构——列表
目录 一、无序列表抽象数据类型 二、实现无序列表:链表 2.1 Node类 2.2 UnorderedList类 三、有序列表抽象数据类型 四、实现有序列表 列表是元素的集合,其中每一个元素都有一个相对于其他元素的位置。更具体地说,这种列表成为无序列表…...
, orr(位或), eor(异或)】)
【ARM 常见汇编指令学习 6 - bic(位清除), orr(位或), eor(异或)】
文章目录 BIC 指令ORR 位或指令EOR 异或指令 上篇文章:ARM 常见汇编指令学习 5 – arm64汇编指令 wzr 和 xzr 下篇文章:ARM 常见汇编指令学习 7 - LDR 指令与LDR伪指令及 mov指令 BIC 指令 指令格式 bic{条件}{S} Rd,Rn,operan…...
)
在CSDN学Golang场景化解决方案(EFK分布式日志系统方案)
一,ElasticSearch 分布式集群部署 在 Golang EFK 分布式日志系统方案中,ElasticSearch 是一个分布式搜索引擎和数据存储库,它可以用于存储和搜索大量的日志数据。以下是 ElasticSearch 分布式集群部署的步骤: 下载 ElasticSearc…...
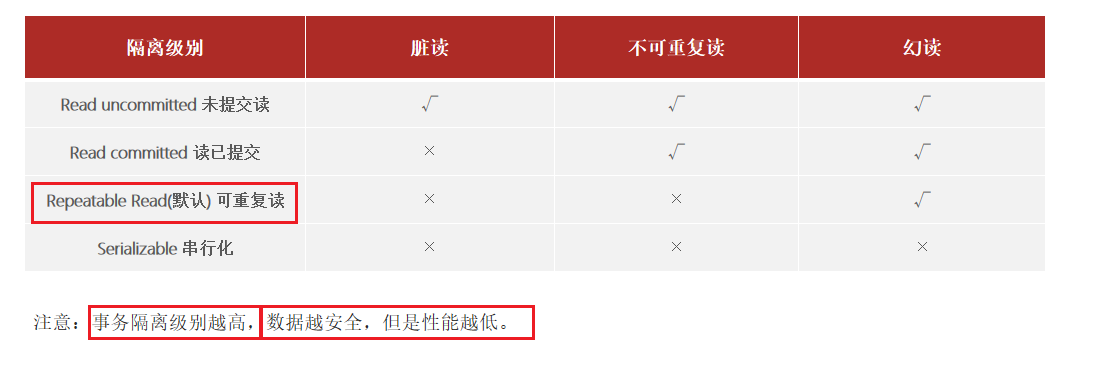
MySQL篇
文章目录 一、MySQL-优化1、在MySQL中,如何定位慢查询?2、SQL语句执行很慢, 如何分析呢?3、了解过索引吗?(什么是索引)4、索引的底层数据结构了解过嘛 ?5、什么是聚簇索引什么是非聚簇索引 ?6、知道什么是回表查询嘛…...

图数据库Neo4j学习四——Spring Data NEO
1配置 1.1Maven依赖 <!--neo4j --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-neo4j</artifactId> </dependency>1.2yml配置 spring:data:neo4j:uri: bolt://localhost:76…...
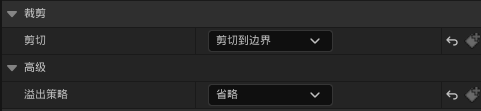
UE虚幻引擎 UTextBlock UMG文本控件超过边界区域以后显示省略号
版本 5.2.1 裁剪 - 剪切 - 剪切到边界 裁剪 - 高级 - 溢出策略 - 省略...

Spring Boot实践五 --异步任务线程池
一、使用Async实现异步调用 在Spring Boot中,我们只需要通过使用Async注解就能简单的将原来的同步函数变为异步函数,Task类实现如下: package com.example.demospringboot;import lombok.extern.slf4j.Slf4j; import org.springframework.s…...
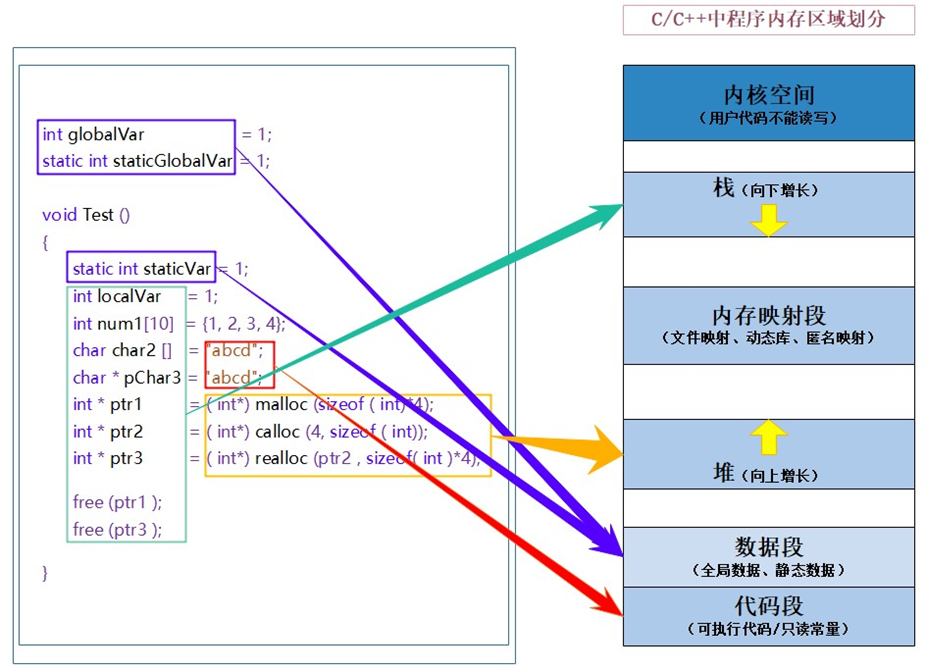
<C语言> 动态内存管理
1.动态内存函数 为什么存在动态内存分配? int main(){int num 10; //向栈空间申请4个字节int arr[10]; //向栈空间申请了40个字节return 0; }上述的开辟空间的方式有两个特点: 空间开辟大小是固定的。数组在声明的时候,必须指定数组的…...

【ASPICE】:学习记录
学习记录 ASPICE中文资料什么是ASPICE过程参考模型 ASPICE全称“Automotive Software Process Improvement and Capability dEtermination”,即“汽车软件过程改进及能力评定”模型框架 ASPICE中文资料 主要资料来源 什么是ASPICE 过程参考模型...

图论--最短路问题
图论–最短路问题 邻接表 /* e[idx]:存储点的编号 w[idx]:存储边的距离(权重) */ void add(int a, int b, int c) {e[idx] b;ne[idx] h[a];w[idx] ch[a] idx ; }1.拓扑排序 给定一个 n 个点 m 条边的有向图,点的编号是 11 到 n…...
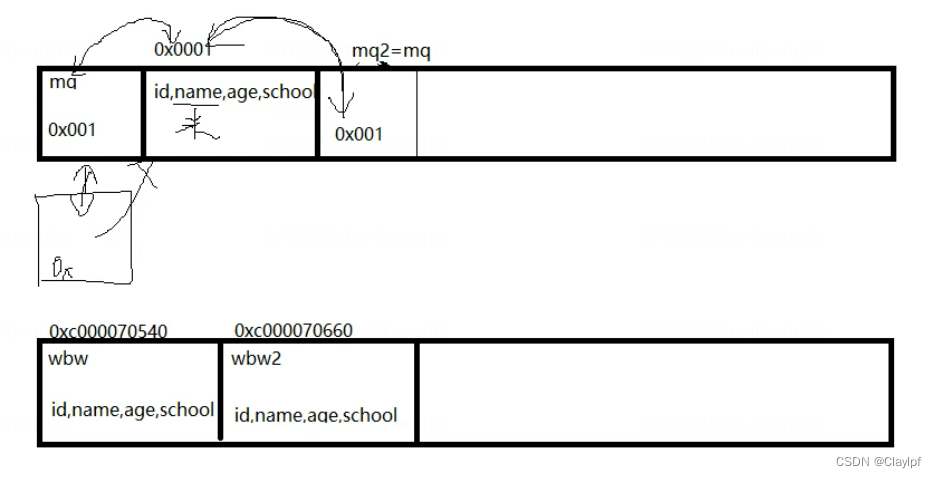
go 结构体 - 值类型、引用类型 - 结构体转json类型 - 指针类型的种类 - 结构体方法 - 继承 - 多态(interface接口) - 练习
目录 一、结构体 1、python 与 go面向对象的实现: 2、初用GO中的结构体:(实例化一个值类型的数据(结构体)) 输出结果不同的三种方式 3、实例化一个引用类型的数据(结构体) 4、…...

盘点16个.Net开源项目
今天一起盘点下,16个.Net开源项目,有博客、商城、WPF和WinForm控件、企业框架等。(点击标题,查看详情) 一、一套包含16个开源WPF组件的套件 项目简介 这是基于WPF开发的,为开发人员提供了一组方便使用自…...
记录对 require.js 的理解
目录 一、使用 require.js 主要是为了解决这两个问题二、require.js 的加载三、main.js 一、使用 require.js 主要是为了解决这两个问题 实现 js 文件的异步加载,避免网页失去响应;管理模块之间的依赖性,便于代码的编写和维护。 二、require.…...
minio-分布式文件存储系统
minio-分布式文件存储系统 minio的简介 MinIO基于Apache License v2.0开源协议的对象存储服务,可以做为云存储的解决方案用来保存海量的图片,视频,文档。由于采用Golang实现,服务端可以工作在Windows,Linux, OS X和FreeBSD上。配置…...
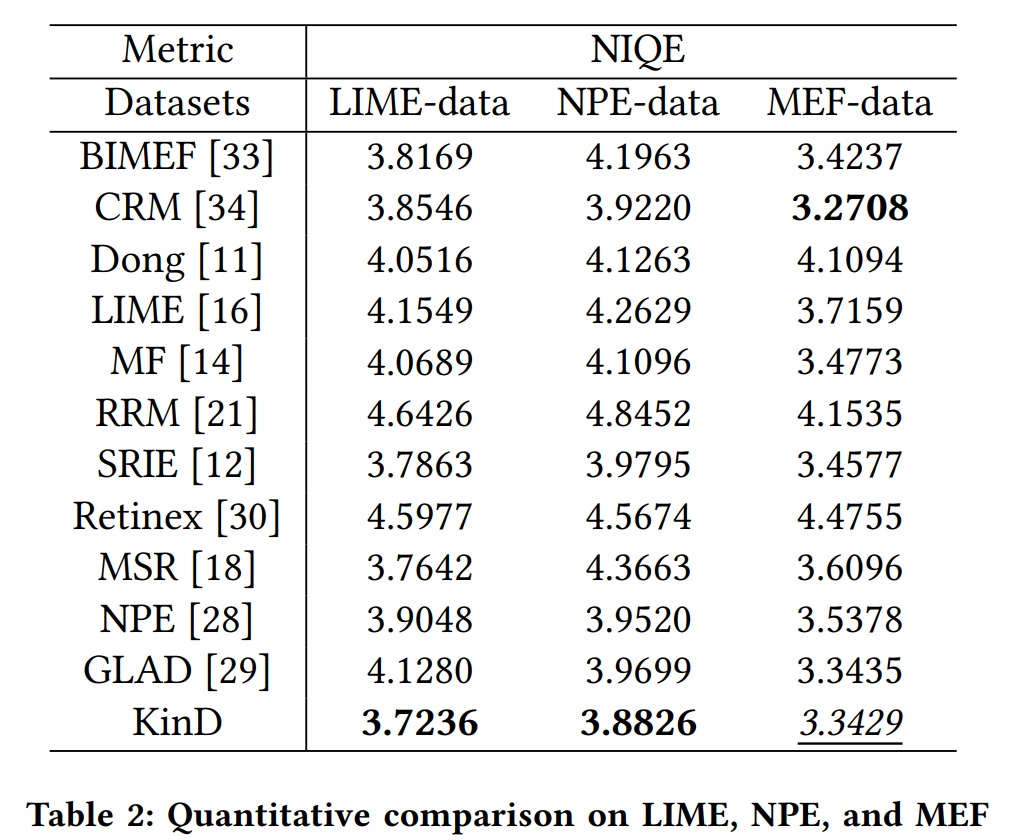
Kindling the Darkness: A Practical Low-light Image Enhancer论文阅读笔记
这是ACMMM2019的一篇有监督暗图增强的论文,KinD其网络结构如下图所示: 首先是一个分解网络分解出R和L分量,然后有Restoration-Net和Adjustment-Net分别去对R分量和L分量进一步处理,最终将处理好的R分量和L分量融合回去。这倒是很常…...

AcWing 4575. Bi数和Phi数
文章目录 题意:思路:代码 题意: 就是给你n个数,对于每一个数y你都需要找到一个最小x使得 ϕ ( x ) ≥ y \phi(x) \ge y ϕ(x)≥y,然后再求一个最小平和。 思路: 其实最开始以来的思路就是二分,我先进行线性筛求出每个数的欧拉函数…...
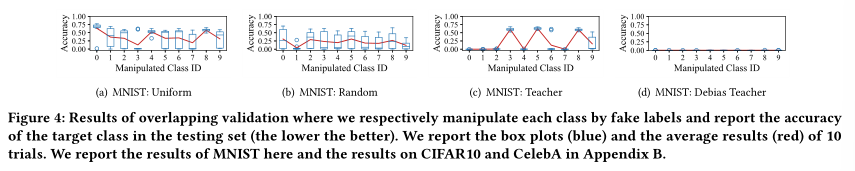
《Federated Unlearning via Active Forgetting》论文精读
文章目录 1、概述2、方法实验主要贡献框架概述 3、实验结果比较方法实验结果忘却完整性忘却效率模型实用性 4、总结 原文链接: Federated Unlearning via Active Forgetting 1、概述 对机器学习模型隐私的⽇益关注催化了对机器学习的探索,即消除训练数…...

河北邯郸职称评审的方式有哪几种?
1、以考代评以考代评就是指有些专业技术岗位可以通过参加考试而不是递交繁琐的材料来获得专业技术职务资格。只要顺利通过国家指定的科目考试,你就可以获得专业技术资格,省去了各种审核流程的烦恼。2、只评不考只评不考是目前zui常见、适用范围zui广的一…...

taotoken如何为github actions工作流提供稳定的大模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken如何为github actions工作流提供稳定的大模型服务 应用场景类,探讨在github actions自动化流水线中集成taotok…...

Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序
Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detecti…...

千问 LeetCode 2569. 更新数组后处理求和查询 Java实现
这道题的核心是高效维护nums1的区间反转操作,因为数据规模达到10^5,暴力反转会超时。需要用到线段树(区间更新区间查询)或BitSet来优化。下面给出Java实现,采用线段树 懒标记的方案:class Solution {publi…...
)
DeepSeek V2多模态支持真相(官方未公开的API隐藏能力全披露)
更多请点击: https://codechina.net 第一章:DeepSeek V2多模态支持真相(官方未公开的API隐藏能力全披露) DeepSeek V2 官方文档明确声明为纯文本大模型,但逆向分析其生产环境 API 流量与响应头后发现:其底…...

淘宝淘金币自动化终极指南:如何用5分钟完成30分钟日常任务
淘宝淘金币自动化终极指南:如何用5分钟完成30分钟日常任务 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi …...

【设计模式 14】责任链:谁来拍板
这一课讲责任链模式。什么在变:处理链路经常调整,审批层级和条件经常变。怎么挡:处理者串成链,每个只决定"签还是传"。那张采购申请单在三个部门之间转了十七天。 十七天。买的东西是一批进口检测设备,总价两…...

UE5 GAS中安全修改Attribute值的四种正确方式
1. 这不是简单的“赋值操作”,而是GAS系统中一次精准的属性干预在UE5的Gameplay Ability System(GAS)架构下,修改一个Attribute的值——比如让角色的生命值从100变成120,或者让法力值在施法后扣减30点——表面看只是调…...

今年小满不一般,老辈农谚里藏着农事提醒
2026 年的小满节气在 5 月 21 日 8:36:28 交节,不少人说今年小满不一般,老辈农谚里总结了三个特点,对农事有不少参考意义。1. 白天小满,昼夜温差变化大“白天小满凉嗖嗖,晚上小满热死牛”这句农谚是说,如果…...

Wot Design Uni异步上传功能:从基础到高级的完整指南
Wot Design Uni异步上传功能:从基础到高级的完整指南 【免费下载链接】wot-design-uni 一个基于Vue3TS开发的uni-app组件库,提供70高质量组件,支持暗黑模式、国际化和自定义主题。 项目地址: https://gitcode.com/gh_mirrors/wo/wot-design…...