[用go实现解释器]笔记1-词法分析
本文是《用go实现解释器》的读书笔记

https://malred-blogmalred.github.io/2023/06/03/ji-suan-ji-li-lun-ji-shu-ji/shi-ti/go-compile/yong-go-yu-yan-shi-xian-jie-shi-qi/go-compiler-1/#toc-heading-6![]() http://个人博客该笔记地址
http://个人博客该笔记地址
github.com/malred/malang![]() http://代码仓库
http://代码仓库
1. 词法分析
1.1 词法分析
为了解释源代码,需要将其转换为易于理解的形式, 最终对代码求值之前, 需要两次转换源代码的表示形式
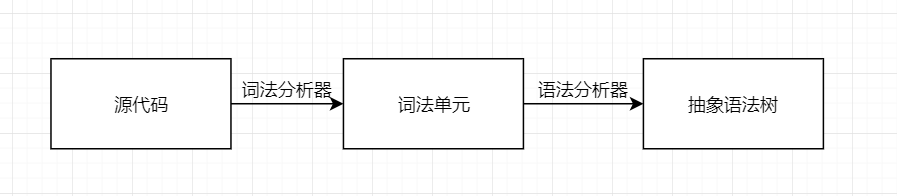
词法分析器的作用如下:
let x = 5 + 5; -> [LET,INDENTIFIER(“x”),EQUAL_SIGN,INTERGER(5),PLUS_SIGN,INTERGER(5),SEMICOLON] 设 x = 5 + 5;-> [LET,INDENTIFIER(“X”),EQUAL_SIGN,INTERGER(5),PLUS_SIGN,INTERGER(5),SEMICOLON]
不同词法分析器生成的词法单元会有区别
-
空白字符不会被识别(python 等语言会)
-
完整的词法分析器还可将行列号和文件名附加到词法单元中,后续语法分析可以更好地报错
1.2 定义词法单元
先定义词法分析器输出的词法单元 这是要解析的语句段(Monkey 语言)
let five = 5;
let ten = 10;let add = fn(x,y) {x + y;
}let result = add(five, ten);-
数字都是整数,按字面量处理,并赋予单独的类型
-
变量名和数字等语言,统一用作标识符
-
还有一些看着像标识符的,但实际是关键字,会特殊处理
定义 Token 数据结构,属性有 1.词法单元类型;2.字面量 词法单元类型定义为字符串,消耗一些性能,但是调试使用方便
// token/token.go
package token// 词法单元类型
type TokenType string// 词法单元
type Token struct {Type TokenType// 字面量Literal string
}将词法单元类型定义为常量
const (// 特殊类型ILLEGAL = "ILLEGAL" // 未知字符EOF = "EOF" // 文件结尾// 标识符+字面量IDENT = "IDENT" // add, foobar, x, yINT = "INT" // 1343456// 运算符ASSIGN = "="PLUS = "+"// 分隔符COMMA = ","SEMICOLON = ";"LPAREN = "("RPAREN = ")"LBRACE = "{"RBRACE = "}"// 关键字FUNCTION = "FUNCTION"LET = "LET"
) 1.3 词法分析器
词法分析器接收源代码(字符串),然后调用 NextToken()逐个遍历字符进行词法分析 生产环境,将文件名和行号附加到词法单元,最好使用 io.Reader 加上文件名来初始化词法分析器
// lexer/lexer.go
package lexertype Lexer struct {input stringposition int // 输入的字符串中的当前位置(指向当前字符)readPosition int // 输入的字符串中的当前读取位置(指向当前字符串之后的一个字符(ch))ch byte // 当前正在查看的字符
}func New(input string) *Lexer {l := &Lexer{input: input}return l
}// 读取下一个字符
func (l *Lexer) readChar() {if l.readPosition >= len(l.input) {l.ch = 0 // NUL的ASSII码(0)} else {// 读取l.ch = l.input[l.readPosition]}// 前移l.position = l.readPositionl.readPosition += 1
}-
readChar 的作用是读取 input 中下个字符,然后将索引前推,NUL 字符的 ASCII 码是 0,表示”尚未读取任何内容”或”文件结尾”
-
该分析器只支持 ASCII 字符,不能支持所有 Unicode 字符,如果要支持,则 l.ch 要改为 rune 类型,并且要修改读取下一个字符的方式,字符也有可能会是多字节,l.input[l.readPosition]将无法工作
在 New 中调用 readChar 以初始化
func New(input string) *Lexer {l := &Lexer{input: input}// 初始化 l.ch,l.position,l.readPositionl.readChar()return l
}第一版 NextToken
// lexer/lexer.go
package lexerimport ("go-monkey-compiler/token"
)// 创建词法单元的方法
func newToken(tokenType token.TokenType, ch byte) token.Token {return token.Token{Type: tokenType,Literal: string(ch),}
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Tokenswitch l.ch {case '=':tok = newToken(token.ASSIGN, l.ch)case ';':tok = newToken(token.SEMICOLON, l.ch)case '(':tok = newToken(token.LPAREN, l.ch)case ')':tok = newToken(token.RPAREN, l.ch)case ',':tok = newToken(token.COMMA, l.ch)case '+':tok = newToken(token.PLUS, l.ch)case '{':tok = newToken(token.LBRACE, l.ch)case '}':tok = newToken(token.RBRACE, l.ch)case 0:tok.Literal = ""tok.Type = token.EOF}l.readChar()return tok
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input := `=+(){},;`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.ASSIGN, "="},{token.PLUS, "+"},{token.LPAREN, "("},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.RBRACE, "}"},{token.COMMA, ","},{token.SEMICOLON, ";"},{token.EOF, ""},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got==%q", i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got==%q", i, tt.expectedLiteral, tok.Literal)}}}go test ./lexer

添加标识符/关键字/数字的处理
// lexer/lexer.go
// 判断读取到的字符是不是字母
func isLetter(ch byte) bool {return 'a' <= ch && ch <= 'z' || 'A' <= ch && ch <= 'Z' || ch == '_'
}// 读取字母(标识符/关键字)
func (l *Lexer) readIdentifier() string {position := l.positionfor isLetter(l.ch) {// 如果接下来还有字母,就一直移动指针到不是字母l.readChar()}return l.input[position:l.position]
}func (l *Lexer) NextToken() token.Token {var tok token.Tokenswitch l.ch {// ...default:if isLetter(l.ch) {tok.Literal = l.readIdentifier()tok.Type = token.LookupIdent(tok.Literal)return tok} else {tok = newToken(token.ILLEGAL, l.ch)}}l.readChar()return tok
}在 token.go 里添加识别关键字和用户定义标识符的方法
// 关键字map
var keywords = map[string]TokenType{"fn": FUNCTION,"let": LET,
}func LookupIdent(ident string) TokenType {// 从关键字map里找,找到了就说明是关键字if tok, ok := keywords[ident]; ok {return tok}// 标识符return IDENT
}此时如果遇到空白字段,会报错 IDENT!=ILLEGAL,需要添加跳过空格的方法
// lexer/lexer.go// 跳过空格
func (l *Lexer) skipWhitespace() {for l.ch == ' ' || l.ch == '\t' || l.ch == '\n' || l.ch == '\r' {l.readChar()}
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {// ...}// ...
}现在添加将数字转为词法单元的功能 数字的识别还可以是浮点数/16 进制/8 进制等,但是书中为了教学而简化了
// 跳过空格
func (l *Lexer) skipWhitespace() {for l.ch == ' ' || l.ch == '\t' || l.ch == '\n' || l.ch == '\r' {l.readChar()}
}// 判断是否是数字
func isDigit(ch byte) bool {return '0' <= ch && ch <= '9'
}// 读取数字
func (l *Lexer) readNumber() string {// 记录起始位置position := l.positionfor isDigit(l.ch) {l.readChar()}return l.input[position:l.position]
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {// ...default:if isLetter(l.ch) {tok.Literal = l.readIdentifier()tok.Type = token.LookupIdent(tok.Literal)// 因为readIdentifier会调用readChar,所以提前return,不需要后面再readCharreturn tok} else if isDigit(l.ch) {tok.Type = token.INTtok.Literal = l.readNumber()return tok} else {tok = newToken(token.ILLEGAL, l.ch)}}l.readChar()return tok
}拓展测试用例,处理开头提到的那个 Monkey 代码段
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x,y) {x + y;};let result = add(five, ten);`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.EOF, ""},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got==%q", i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got==%q", i, tt.expectedLiteral, tok.Literal)}}}1.4 拓展词法单元和词法分析器
添加对 == ! != - / * < > 和关键字 true false if else return 的支持 可分为
-
单字符语法单元(如-,!)
-
双字符语法单元(如==) <- 后续添加支持
-
关键字语法定义(如 return)
添加对- / * < > 的支持 token 常量中添加新定义
const (// ...// 运算符ASSIGN = "="PLUS = "+"MINUS = "-"BANG = "!"ASTERISK = "*"SLASH = "/"LT = "<"GT = ">"// ...
)lexer.go 的 switch 中添加新的词法单元生成
// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {case '=':tok = newToken(token.ASSIGN, l.ch)case '+':tok = newToken(token.PLUS, l.ch)case '-':tok = newToken(token.MINUS, l.ch)case '!':tok = newToken(token.BANG, l.ch)case '/':tok = newToken(token.SLASH, l.ch)case '*':tok = newToken(token.ASTERISK, l.ch)case '<':tok = newToken(token.LT, l.ch)case '>':tok = newToken(token.GT, l.ch)// ...}l.readChar()return tok
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x, y) {x + y;};let result = add(five, ten);!-/*5;5 < 10 > 5;`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.BANG, "!"},{token.MINUS, "-"},{token.SLASH, "/"},{token.ASTERISK, "*"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.GT, ">"},{token.INT, "5"},{token.SEMICOLON, ";"},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q",i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",i, tt.expectedLiteral, tok.Literal)}}
}进一步拓展,添加新关键字的解析 true false if else return 将新关键字分别添加到 token 的常量列表和 keywords 关键字 map 里
const (// ...// 关键字FUNCTION = "FUNCTION"LET = "LET"TRUE = "TRUE"FALSE = "FALSE"IF = "IF"ELSE = "ELSE"RETURN = "RETURN"
)// 关键字map
var keywords = map[string]TokenType{"fn": FUNCTION,"let": LET,"true": TRUE,"false": FALSE,"if": IF,"else": ELSE,"return": RETURN,
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x, y) {x + y;};let result = add(five, ten);!-/*5;5 < 10 > 5;if (5 < 10) {return true;} else {return false;}`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.BANG, "!"},{token.MINUS, "-"},{token.SLASH, "/"},{token.ASTERISK, "*"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.GT, ">"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.IF, "if"},{token.LPAREN, "("},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.TRUE, "true"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.ELSE, "else"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.FALSE, "false"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q",i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",i, tt.expectedLiteral, tok.Literal)}}
}拓展,添加对!=和==的支持 添加常量
const (// ...EQ = "=="NOT_EQ = "!="// ...
)因为每次读入一个字符,所以不能直接 case !=来判别,应该复用!和=的判断分支,根据下一个字符来决定是返回=还是==
// 向前查看一个字符,但是不移动指针
func (l *Lexer) peekChar() byte {if l.readPosition >= len(l.input) {return 0} else {return l.input[l.readPosition]}
}// 根据当前的ch创建词法单元
func (l *Lexer) NextToken() token.Token {var tok token.Token// 跳过空格l.skipWhitespace()switch l.ch {case '=':if l.peekChar() == '=' {// 记录当前ch (=)ch := l.chl.readChar()literal := string(ch) + string(l.ch)tok = token.Token{Type: token.EQ, Literal: literal}} else {tok = newToken(token.ASSIGN, l.ch)}// ...case '!':if l.peekChar() == '=' {// 记录当前ch (!)ch := l.chl.readChar()literal := string(ch) + string(l.ch)tok = token.Token{Type: token.NOT_EQ, Literal: literal}} else {tok = newToken(token.BANG, l.ch)}// ...}l.readChar()return tok
}测试
// lexer/lexer_test.go
package lexerimport ("go-monkey-compiler/token""testing"
)func TestNextToken(t *testing.T) {input :=`let five = 5;let ten = 10;let add = fn(x, y) {x + y;};let result = add(five, ten);!-/*5;5 < 10 > 5;if (5 < 10) {return true;} else {return false;}10 == 10;10 != 9;`tests := []struct {expectedType token.TokenTypeexpectedLiteral string}{{token.LET, "let"},{token.IDENT, "five"},{token.ASSIGN, "="},{token.INT, "5"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "ten"},{token.ASSIGN, "="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "add"},{token.ASSIGN, "="},{token.FUNCTION, "fn"},{token.LPAREN, "("},{token.IDENT, "x"},{token.COMMA, ","},{token.IDENT, "y"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.IDENT, "x"},{token.PLUS, "+"},{token.IDENT, "y"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.SEMICOLON, ";"},{token.LET, "let"},{token.IDENT, "result"},{token.ASSIGN, "="},{token.IDENT, "add"},{token.LPAREN, "("},{token.IDENT, "five"},{token.COMMA, ","},{token.IDENT, "ten"},{token.RPAREN, ")"},{token.SEMICOLON, ";"},{token.BANG, "!"},{token.MINUS, "-"},{token.SLASH, "/"},{token.ASTERISK, "*"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.GT, ">"},{token.INT, "5"},{token.SEMICOLON, ";"},{token.IF, "if"},{token.LPAREN, "("},{token.INT, "5"},{token.LT, "<"},{token.INT, "10"},{token.RPAREN, ")"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.TRUE, "true"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.ELSE, "else"},{token.LBRACE, "{"},{token.RETURN, "return"},{token.FALSE, "false"},{token.SEMICOLON, ";"},{token.RBRACE, "}"},{token.INT, "10"},{token.EQ, "=="},{token.INT, "10"},{token.SEMICOLON, ";"},{token.INT, "10"},{token.NOT_EQ, "!="},{token.INT, "9"},{token.SEMICOLON, ";"},{token.EOF, ""},}l := New(input)for i, tt := range tests {tok := l.NextToken()if tok.Type != tt.expectedType {t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q",i, tt.expectedType, tok.Type)}if tok.Literal != tt.expectedLiteral {t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",i, tt.expectedLiteral, tok.Literal)}}
}1.5 编写 REPL
REPL 即 Read-Eval-Print-Loop(读取-求值-打印循环) REPL 读取输入,传给解释器求值,任何输出,并重复之前的步骤 这里是输入源代码,然后每次读取一行,直到遇到 EOF,期间输出词法生成器生成的词法单元
// repl/repl.go
package replimport ("bufio""fmt""go-monkey-compiler/token""go-monkey-compiler/lexer""io"
)const PROMPT = ">> "func Start(in io.Reader, out io.Writer) {scanner := bufio.NewScanner(in)for {scanned := scanner.Scan()if !scanned {return}line := scanner.Text()l := lexer.New(line)for tok := l.NextToken(); tok.Type != token.EOF; tok = l.NextToken() {fmt.Fprintf(out, "%+v\n", tok)}}
}创建 main.go,启动 REPL
// main.go
package mainimport ("fmt""go-monkey-compiler/repl""os""os/user"
)func main() {user, err := user.Current()if err != nil {panic(err)}fmt.Printf("Hello %s! This is the Monkey programming language!\n", user.Username)fmt.Printf("Feel free to type in commands\n")repl.Start(os.Stdin, os.Stdout)
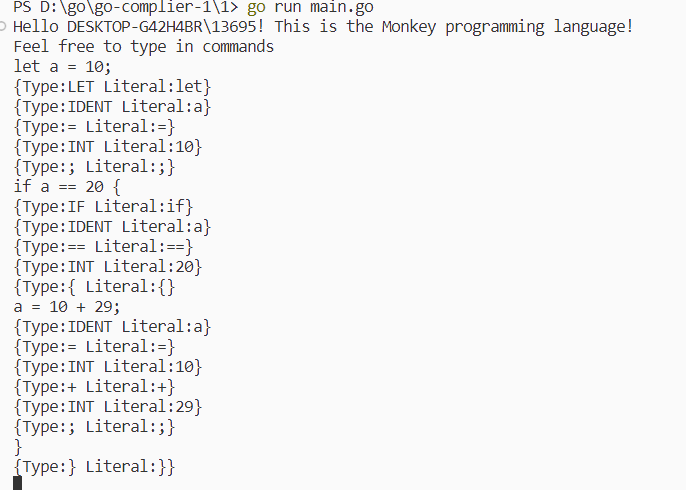
}测试
相关文章:
[用go实现解释器]笔记1-词法分析
本文是《用go实现解释器》的读书笔记 https://malred-blogmalred.github.io/2023/06/03/ji-suan-ji-li-lun-ji-shu-ji/shi-ti/go-compile/yong-go-yu-yan-shi-xian-jie-shi-qi/go-compiler-1/#toc-heading-6http://个人博客该笔记地址 github.com/malred/malanghttp:/…...

在 spark-sql / spark-shell / hive / beeline 中粘贴 sql、程序脚本时的常见错误
一个很小的问题,简单记录一下。有时候我们会粘贴一段已经成功运行过的SQL或程序脚本,但是在spark-sql / spark-shell / hive / beeline 中执行时可能会报这样的错误: hive> CREATE EXTERNAL TABLE IF NOT EXISTS ORDERS(> Display all…...
关于视频汇聚融合EasyCVR平台多视频播放协议的概述
视频监控综合管理平台EasyCVR具备视频融合能力,平台基于云边端一体化架构,具有强大的数据接入、处理及分发能力,平台既具备传统安防视频监控的能力与服务,也支持AI智能检测技术的接入,可应用在多行业领域的智能化监管场…...

三星书画联展:三位艺术家开启国风艺术之旅
7月22日,由广州白云区文联、白云区工商联主办的“三星书画联展”,在源美术馆正式开展。本次书画展展出的艺术种类丰富,油画、国画、彩墨画、书法等作品异彩纷呈。广东省政协原副主席、农工党省委书画院名誉院长马光瑜,意大利艺术研…...
在腾讯云服务器OpenCLoudOS系统中安装nginx(有图详解)
1. 创建安装目录 2. 下载、安装、编译 进入安装目录: cd /app/soft/nginx/ 下载: wget https://nginx.org/download/nginx-1.21.6.tar.gz 解压: tar -zxvf nginx-1.21.6.tar.gz 安装插件: yum -y install pcre-devel 安装…...

大数据课程E5——Flume的Selector
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Selector的概念和配置属性; ⚪ 掌握Selector的使用方法; 一、简介 1. 概述 1. Selector本身是Source的子组件,决定了将数据分发给哪个Channel。 2. Selector中提供了两种模式: …...

在线查看浏览器
随着网络的兴起,电影和电视剧已经成为我们生活中必不可少的乐趣。然而,像爱奇艺、优酷、腾讯、芒果等等这些平台,我们想要看好视频,需要开通VIP,虽然价格不是很高,但是我们能省则省啊,今天我就给…...
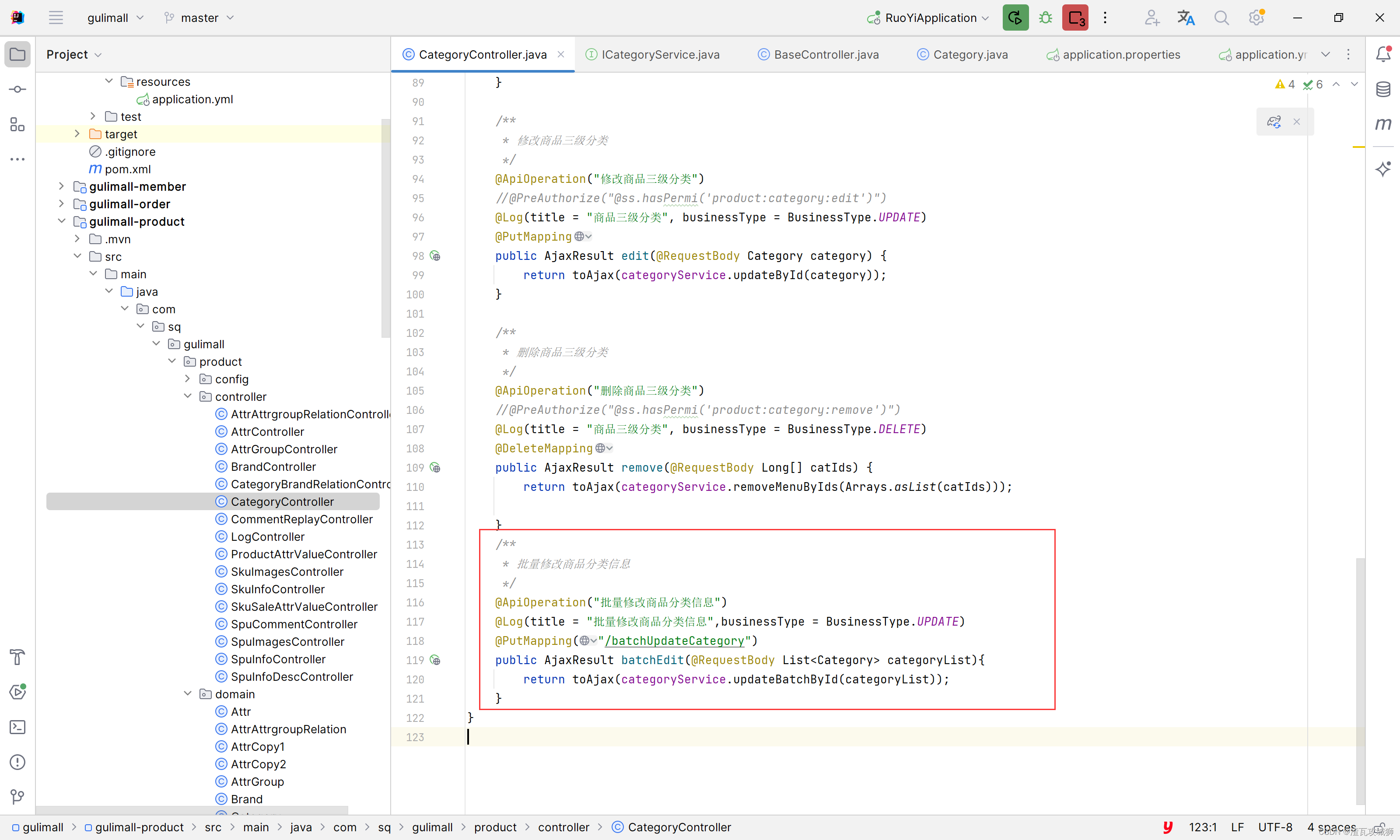
谷粒商城第七天-商品服务之分类管理下的分类的拖拽功能的实现
目录 一、总述 1.1 前端思路 1.2 后端思路 二、前端实现 2.1 判断是否能进行拖拽 2.2 收集受影响的节点,提交给服务器 三、后端实现 四、总结 一、总述 这个拖拽功能对于这种树形的列表,整体的搬迁是很方便的。但是其实现却并不是那么的简单。 …...
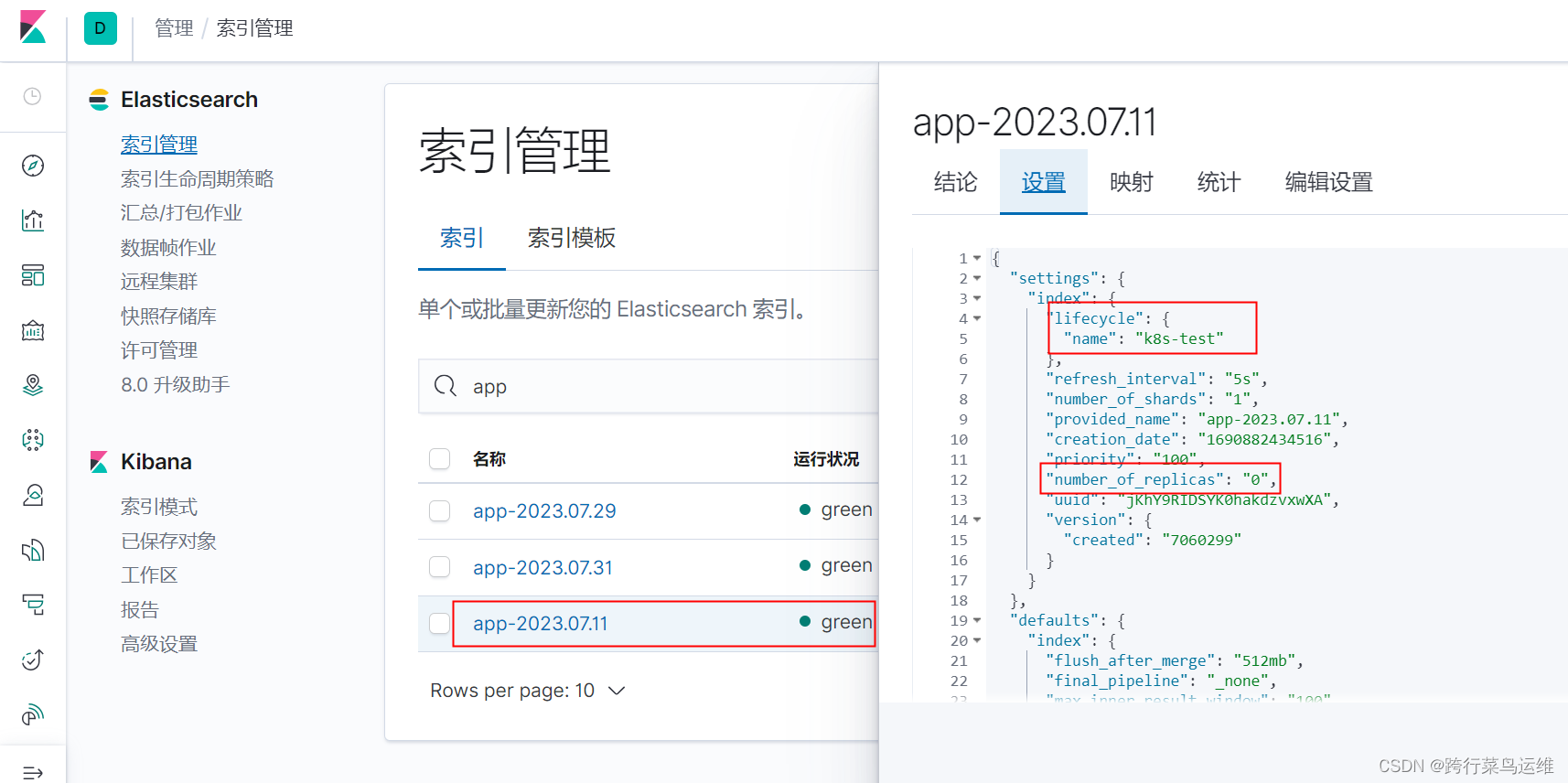
解决单节点es索引yellow
现象 单节点的es,自动创建索引后,默认副本个数为1,索引状态为yellow 临时解决 修改副本个数为0 永久解决 方法1、修改elasticsearch.yml文件,添加配置并重启es number_of_replicas:副本分片数,默认…...

Java虚拟机在类加载阶段都做了些什么,才使得我们可以运行Java程序
前言: 今天和大家探讨一道Java中经典的面试题,这道面试题经常出现在各个公司的面试中,结合周志明,老师的《深入理解Java虚拟机》书籍,本篇文章主要讲解Java类加载机制的知识。该专栏比较适合刚入坑Java的小白以及准备秋…...

华为认证 | 学HCIE,想培训需要注意啥?
HCIE(华为认证网络专家)是华为技术认证体系中的最高级别认证,对于网络工程师来说考试难度也比较高,一般来说,需要进行培训。 那么HCIE考试培训需要注意啥? 01 充分了解认证要求 在开始准备HCIE认证之前&a…...

这所211考数一英二,学硕降分33分,十分罕见!
一、学校及专业介绍 合肥工业大学(Hefei University of Technology),简称“合工大”,校本部位于安徽省合肥市,是中华人民共和国教育部直属的全国重点大学,是国家“双一流”建设高校, 国家“211工…...
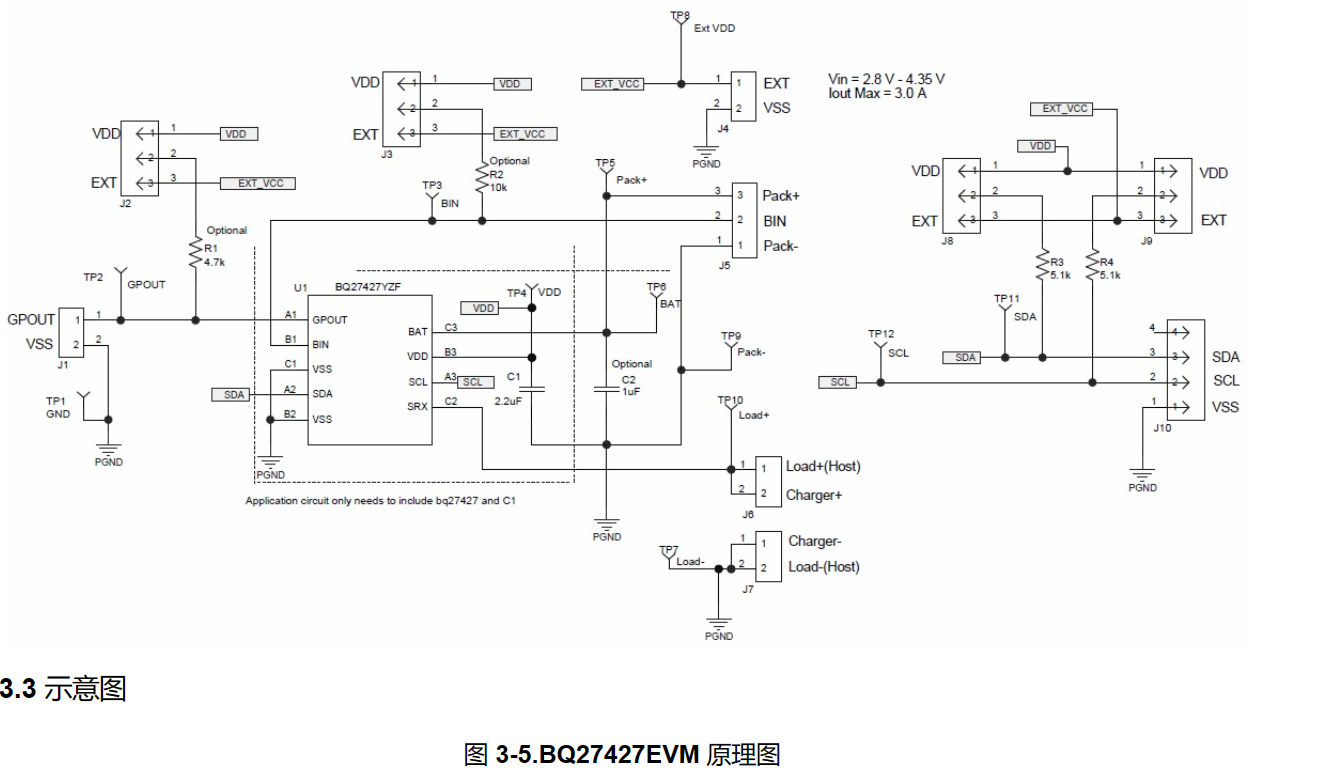
关于BQ27427的配置问题
EVM是TI家做的BQ27427的开发板,这款芯片还挺新的。 大概是这样,一块开发板要一千多块钱,使用的时候还出现了一些奇怪的问题。 配置使用的是买的盗版的EV2400,就是黑色的那个东西,使用的通信方式IIC。 TI手册上写的软件…...

试卷还原成空白卷怎么做?分享个简单的方法
在进行考试时,可能会填错答案或想要重新测试,此时需要正确擦除填写的试卷答案。下面介绍一些需要注意的事项以及正确的擦除方法。 使用橡皮擦或橡皮 正确的擦除方法是使用橡皮擦或橡皮对填写的答案进行擦除。首先,将橡皮擦或橡皮放置在试卷上…...

查看学校名称中含北京的用户
查看学校名称中含北京的用户_牛客题霸_牛客网 1.like select device_id,age,university from user_profile where university like %北京%; 注意虽然按实际需求,北京一般是排在最前面,即北京%,但是严格意义上来说,搜索含有北京…...
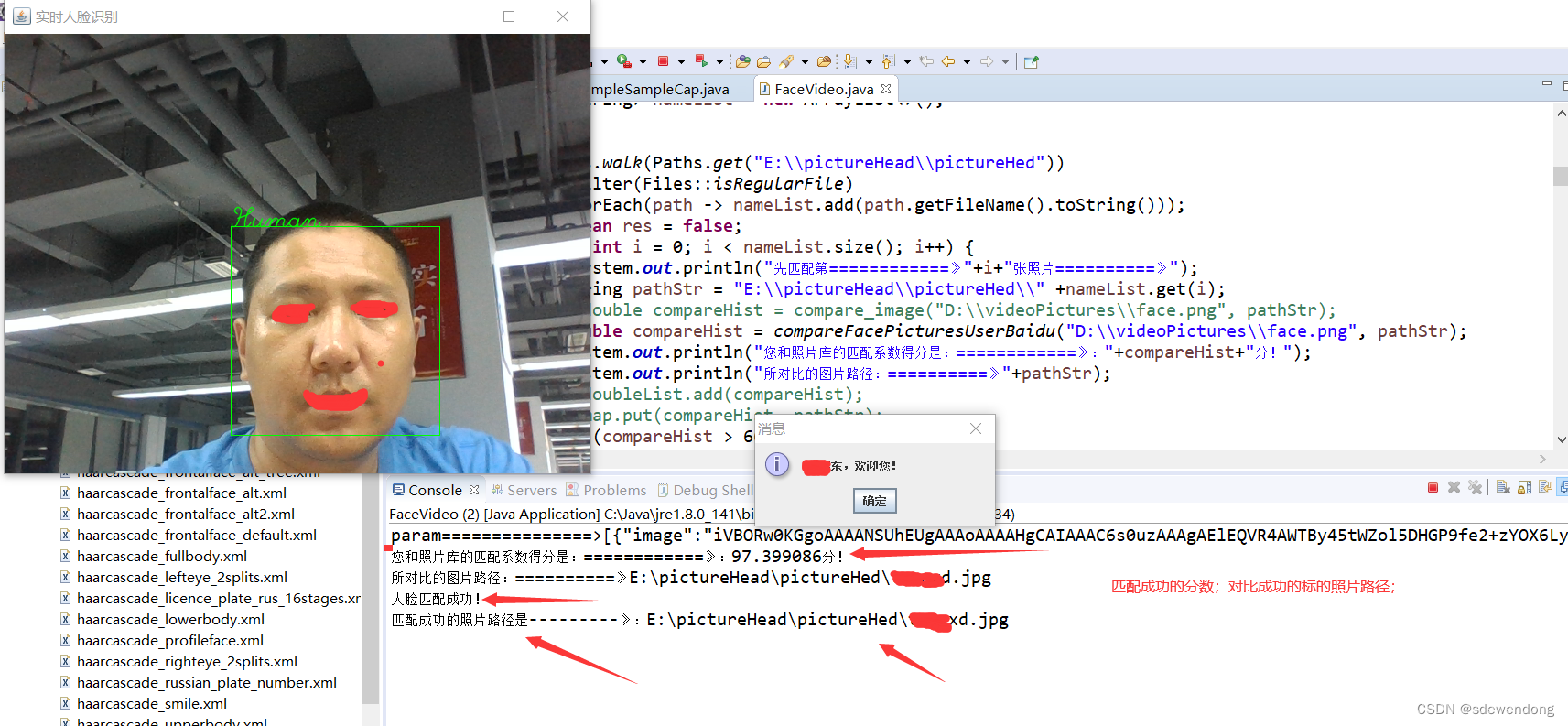
快速开发人脸识别系统Java版本
简介: 先说下什么是人脸识别系统:举个例子,公司门口有个人脸识别系统,员工站到门口,看着摄像头,大屏幕上会抓拍到你的人脸,然后和公司的员工照片库里的照片比对,比对成功就提示&…...

Reinforcement Learning with Code 【Code 1. Tabular Q-learning】
Reinforcement Learning with Code 【Code 1. Tabular Q-learning】 This note records how the author begin to learn RL. Both theoretical understanding and code practice are presented. Many material are referenced such as ZhaoShiyu’s Mathematical Foundation o…...

解决:Uncaught (in promise) SyntaxError: “[object Object]“ is not valid JSON 问题的过程
1、问题描述: 其一、报错为: Uncaught (in promise) SyntaxError: "[object Object]" is not valid JSON 中文为: 未捕获(承诺中)语法错误:“[object Object]”不是有效的 JSON 其二、问题描…...

机器学习-New Optimization
机器学习(New Optimization) 前言: 学习资料 videopptblog 下面的PPT里面有一些符号错误,但是我还是按照PPT的内容编写公式,自己直到符号表示什么含义就好了 Notation 符号解释 θ t \theta_t θt第 t 步时,模型的参数 Δ L …...

3d虚拟vr汽车实景展厅吸引更多潜在消费者
随着人们对生活品质的追求,越来越多的消费者开始关注汽车的外观设计、内饰配置等方面。传统的展示方式已经不能满足消费者的需求,车辆VR虚拟漫游展示应运而生。借助VR虚拟现实和web3d开发建模技术,对汽车的外观、造型及信息数据进行数字化处理…...

企业AI知识库搭建实战:从文件管理到智能检索的完整方案
2025年我们团队做过一个调研,找了37家用了AI知识库的企业,发现一个有意思的规律:真正用起来的不到1/3,剩下2/3基本都卡在同一个地方——知识库和文件管理系统是割裂的。 你让员工把文件再上传一遍到知识库?没人干。你让…...

星露谷物语SMAPI模组加载器:从新手到专家的终极指南
星露谷物语SMAPI模组加载器:从新手到专家的终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾梦想为星露谷物语添加全新的游戏体验?SMAPI模组加载器正是实现这…...

Sunshine游戏串流服务器:如何5分钟内搭建私人云游戏平台?
Sunshine游戏串流服务器:如何5分钟内搭建私人云游戏平台? 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下,将你的高性能游戏PC变成一个…...

从游戏主机到云端:如何用Sunshine打造你的私人游戏串流服务器
从游戏主机到云端:如何用Sunshine打造你的私人游戏串流服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经想过,在客厅的电视上玩电脑游戏&am…...

Google三星AI眼镜来了,开发者该关注什么
AI 眼镜又回来了,但这次不只是换个硬件外壳AI 眼镜这个话题,最近又被推到了台前。Google 在 I/O 2026 展示了基于 Android XR 的智能眼镜方向,并把三星、Gentle Monster、Warby Parker 等合作方一起摆上台面。按照目前公布的信息,…...

帕鲁杯第二届应急响应:jumpserver,waf,mysql,sshserver,server01,Palu03,Palu02,每个靶机的漏洞总结
一、题目描述1.提交堡垒机中留下的flag2.提交waf中隐藏的flag3.提交mysql中留下的flag4.提交攻击者的攻击IP5.提交攻击者的最早攻击时间6.提交web服务泄露的关键文件名7.提交泄露的邮箱地址作为flag进行提交8.提交立足点服务器ip地址9.提交攻击者使用的提权用户密码10.提交攻击…...
IPsec VPN,实现分支互访)
保姆级教程:用H3C设备搭建星型(Hub-Spoke)IPsec VPN,实现分支互访
企业级星型IPsec网络架构实战:基于H3C设备的Hub-Spoke模型部署指南 当企业业务规模从单一总部扩展到多分支机构时,网络架构的复杂性和安全性需求呈指数级增长。某零售企业在全国部署300家门店后,发现传统的点对点网络连接方式导致设备配置量激…...
到CFS再到EEVDF)
Linux调度器演进:从O(1)到CFS再到EEVDF
Linux 进程调度演化史:从 O(n) 到 CFS 再到 EEVDF,30 年调度器的三次跃迁 进程调度是操作系统的脉搏。这篇文章不堆概念,带你从 Linux 0.01 走到内核 6.6,看懂调度器为什么这样设计,以及每次重构到底解决了什么问题。 …...

2025-2026年护眼灯品牌推荐:十大排行产品专业评测熬夜加班防眼干疲劳性价比高注意事项
摘要 当家庭与办公场景对光环境的要求从“照亮”升级为“护眼”,决策者面临的核心挑战已转变为如何在纷繁的技术参数与品牌承诺中,识别出真正能长期守护视觉健康、并适配多元场景的专业解决方案。根据全球市场研究机构Grand View Research的报告…...
,两种群稀疏学习算法来提取故障脉冲,第一种仅利用故障脉冲的群稀疏性,第二种则利用故障脉冲的额外周期性行为(Matlab代码实现))
【轴承故障诊断】一种用于轴承故障诊断的稀疏贝叶斯学习(SBL),两种群稀疏学习算法来提取故障脉冲,第一种仅利用故障脉冲的群稀疏性,第二种则利用故障脉冲的额外周期性行为(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...