NLP实战9:Transformer实战-单词预测
目录
一、定义模型
二、加载数据集
三、初始化实例
四、训练模型
五、评估模型
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
模型结构图:

📌 本周任务:
●理解文中代码逻辑并成功运行
●自定义输入一段英文文本进行预测(拓展内容,可自由发挥)
数据集介绍:
这是一个关于使用 Transformer 模型来预测文本序列中下一个单词的教程示例。
本文使用的是Wikitext-2数据集,WikiText 英语词库数据(The WikiText Long Term Dependency Language Modeling Dataset)是一个包含1亿个词汇的英文词库数据,这些词汇是从Wikipedia的优质文章和标杆文章中提取得到,包括WikiText-2和WikiText-103两个版本,相比于著名的 Penn Treebank (PTB) 词库中的词汇数量,前者是其2倍,后者是其110倍。每个词汇还同时保留产生该词汇的原始文章,这尤其适合当需要长时依赖(longterm dependency)自然语言建模的场景。
以下是关于Wikitext-2数据集的一些详细介绍:
1数据来源:Wikitext-2数据集是从维基百科抽取的,包含了维基百科中的文章文本。
2数据内容:Wikitext-2数据集包含维基百科的文章内容,包括各种主题和领域的信息。这些文章是经过预处理和清洗的,以提供干净和可用于训练的文本数据。
3数据规模:Wikitext-2数据集的规模相对较小。它包含了超过2,088,628个词标记(token)的文本,以及其中1,915,997个词标记用于训练,172,430个词标记用于验证和186,716个词标记用于测试。
4数据格式:Wikitext-2数据集以纯文本形式进行存储,每个文本文件包含一个维基百科文章的内容。文本以段落和句子为单位进行分割。
5用途:Wikitext-2数据集通常用于语言建模任务,其中模型的目标是根据之前的上下文来预测下一个词或下一个句子。此外,该数据集也可以用于其他文本生成任务,如机器翻译、摘要生成等。
一、定义模型
from tempfile import TemporaryDirectory
from typing import Tuple
from torch import nn, Tensor
from torch.nn import TransformerEncoder, TransformerEncoderLayer
from torch.utils.data import dataset
import math,os,torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)cuda
class TransformerModel(nn.Module):def __init__(self, ntoken: int, d_model: int, nhead: int, d_hid: int,nlayers: int, dropout: float = 0.5):super().__init__()self.model_type = 'Transformer'self.pos_encoder = PositionalEncoding(d_model, dropout)# 定义编码器层encoder_layers = TransformerEncoderLayer(d_model, nhead, d_hid, dropout)# 定义编码器,pytorch将Transformer编码器进行了打包,这里直接调用即可self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)self.embedding = nn.Embedding(ntoken, d_model)self.d_model = d_modelself.linear = nn.Linear(d_model, ntoken)self.init_weights()# 初始化权重def init_weights(self) -> None:initrange = 0.1self.embedding.weight.data.uniform_(-initrange, initrange)self.linear.bias.data.zero_()self.linear.weight.data.uniform_(-initrange, initrange)def forward(self, src: Tensor, src_mask: Tensor = None) -> Tensor:"""Arguments:src : Tensor, 形状为 [seq_len, batch_size]src_mask: Tensor, 形状为 [seq_len, seq_len]Returns:输出的 Tensor, 形状为 [seq_len, batch_size, ntoken]"""src = self.embedding(src) * math.sqrt(self.d_model)src = self.pos_encoder(src)output = self.transformer_encoder(src, src_mask)output = self.linear(output)return output定义位置编码器PositionalEncoding,用于在Transformer模型中为输入的序列添加位置编码
class PositionalEncoding(nn.Module):def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):super().__init__()self.dropout = nn.Dropout(p=dropout)# 生成位置编码的位置张量position = torch.arange(max_len).unsqueeze(1)# 计算位置编码的除数项div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))# 创建位置编码张量pe = torch.zeros(max_len, 1, d_model)# 使用正弦函数计算位置编码中的奇数维度部分pe[:, 0, 0::2] = torch.sin(position * div_term)# 使用余弦函数计算位置编码中的偶数维度部分pe[:, 0, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x: Tensor) -> Tensor:"""Arguments:x: Tensor, 形状为 [seq_len, batch_size, embedding_dim]"""# 将位置编码添加到输入张量x = x + self.pe[:x.size(0)]# 应用 dropoutreturn self.dropout(x)二、加载数据集
本教程用于torchtext生成 Wikitext-2 数据集。在此之前,你需要安装下面的包:
pip install portalocker
pip install torchdata
batchify()将数据排列成batch_size列。如果数据没有均匀地分成batch_size列,则数据将被修剪以适合。例如,以字母表作为数据(总长度为 26)和batch_size=4,我们会将字母表分成长度为 6 的序列,从而得到 4 个这样的序列。
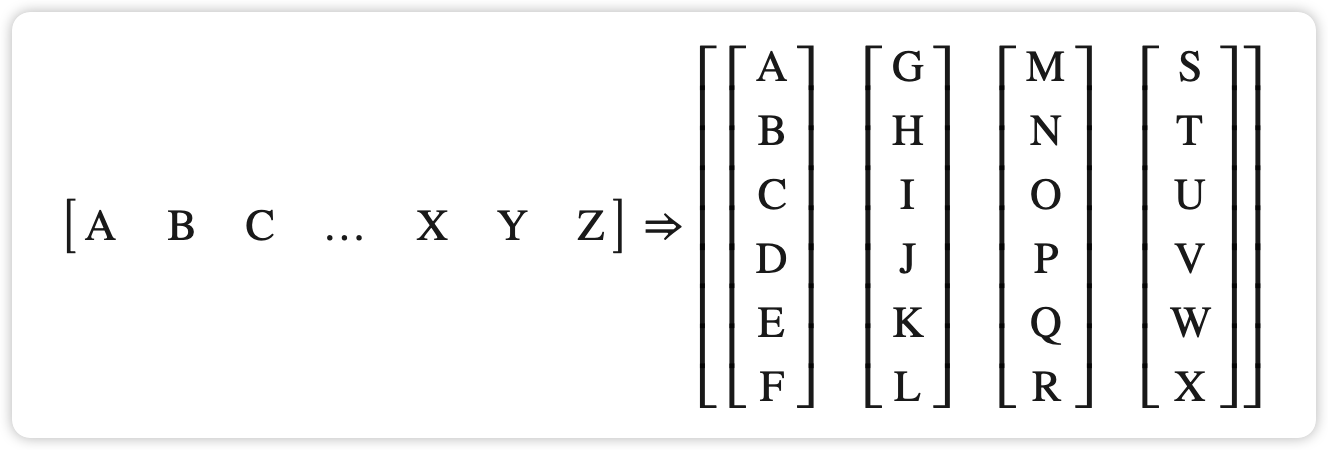
from torchtext.datasets import WikiText2
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator# 从torchtext库中导入WikiText2数据集
train_iter = WikiText2(split='train')# 获取基本英语的分词器
tokenizer = get_tokenizer('basic_english')# 通过迭代器构建词汇表
vocab = build_vocab_from_iterator(map(tokenizer, train_iter), specials=['<unk>'])# 将默认索引设置为'<unk>'
vocab.set_default_index(vocab['<unk>'])def data_process(raw_text_iter: dataset.IterableDataset) -> Tensor:"""将原始文本转换为扁平的张量"""data = [torch.tensor(vocab(tokenizer(item)), dtype=torch.long) for item in raw_text_iter]return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))# 由于构建词汇表时"train_iter"被使用了,所以需要重新创建
train_iter, val_iter, test_iter = WikiText2()# 对训练、验证和测试数据进行处理
train_data = data_process(train_iter)
val_data = data_process(val_iter)
test_data = data_process(test_iter)# 检查是否有可用的CUDA设备,将设备设置为GPU或CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def batchify(data: Tensor, bsz: int) -> Tensor:"""将数据划分为 bsz 个单独的序列,去除不能完全容纳的额外元素。参数:data: Tensor, 形状为``[N]``bsz : int, 批大小返回:形状为 [N // bsz, bsz] 的张量"""seq_len = data.size(0) // bszdata = data[:seq_len * bsz]data = data.view(bsz, seq_len).t().contiguous()return data.to(device)# 设置批大小和评估批大小
batch_size = 20
eval_batch_size = 10# 将训练、验证和测试数据进行批处理
train_data = batchify(train_data, batch_size) # 形状为 [seq_len, batch_size]
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)data.view(bsz, seq_len).t().contiguous()详解如下:
- data.view(bsz, seq_len):使用view方法将数据张量进行重塑,将其形状调整为(bsz, seq_len),其中bsz是批大小,seq_len是序列长度。
- .t():使用.t()方法对重塑后的张量进行转置操作,将原来的行转换为列,原来的列转换为行。这是因为在自然语言处理任务中,通常我们希望对一个批次中的多个句子进行并行处理,因此需要将句子排列为批次维度在前,序列维度在后的形式。
- .contiguous():使用.contiguous()方法确保转置后的张量在内存中是连续存储的。在进行一些操作时,如转换为某些特定类型的张量或进行高效的计算,需要保证张量的内存布局是连续的。
bptt = 35# 获取批次数据
def get_batch(source: Tensor, i: int) -> Tuple[Tensor, Tensor]:"""参数:source: Tensor,形状为 ``[full_seq_len, batch_size]``i : int, 当前批次索引返回:tuple (data, target),- data形状为 [seq_len, batch_size],- target形状为 [seq_len * batch_size]"""# 计算当前批次的序列长度,最大为bptt,确保不超过source的长度seq_len = min(bptt, len(source) - 1 - i)# 获取data,从i开始,长度为seq_lendata = source[i:i+seq_len]# 获取target,从i+1开始,长度为seq_len,并将其形状转换为一维张量target = source[i+1:i+1+seq_len].reshape(-1)return data, target三、初始化实例
ntokens = len(vocab) # 词汇表的大小
emsize = 200 # 嵌入维度
d_hid = 200 # nn.TransformerEncoder 中前馈网络模型的维度
nlayers = 2 #nn.TransformerEncoder中的nn.TransformerEncoderLayer层数
nhead = 2 # nn.MultiheadAttention 中的头数
dropout = 0.2 # 丢弃概率# 创建 Transformer 模型,并将其移动到设备上
model = TransformerModel(ntokens, emsize, nhead, d_hid, nlayers, dropout).to(device)四、训练模型
我们将CrossEntropyLoss与SGD(随机梯度下降)优化器结合使用。学习率最初设置为 5.0 并遵循StepLR。在训练期间,我们使用nn.utils.clip_grad_norm_来防止梯度爆炸。
import timecriterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
lr = 5.0 # 学习率
# 使用随机梯度下降(SGD)优化器,将模型参数传入优化器
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
# 使用学习率调度器,每隔1个epoch,将学习率按0.95的比例进行衰减
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)def train(model: nn.Module) -> None:model.train() # 开启训练模式total_loss = 0.log_interval = 200 # 每隔200个batch打印一次日志start_time = time.time()num_batches = len(train_data) // bptt # 计算总的batch数量for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):data, targets = get_batch(train_data, i) # 获取当前batch的数据和目标output = model(data) # 前向传播output_flat = output.view(-1, ntokens)loss = criterion(output_flat, targets) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播计算梯度torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5) # 对梯度进行裁剪,防止梯度爆炸optimizer.step() # 更新模型参数total_loss += loss.item() # 累加损失值if batch % log_interval == 0 and batch > 0:lr = scheduler.get_last_lr()[0] # 获取当前学习率# 计算每个batch的平均耗时ms_per_batch = (time.time() - start_time) * 1000 / log_interval cur_loss = total_loss / log_interval # 计算平均损失ppl = math.exp(cur_loss) # 计算困惑度# 打印日志信息print(f'| epoch {epoch:3d} | {batch:5d}/{num_batches:5d} batches | 'f'lr {lr:02.2f} | ms/batch {ms_per_batch:5.2f} | 'f'loss {cur_loss:5.2f} | ppl {ppl:8.2f}')total_loss = 0 # 重置损失值start_time = time.time() # 重置起始时间def evaluate(model: nn.Module, eval_data: Tensor) -> float:model.eval() # 开启评估模式total_loss = 0.with torch.no_grad():for i in range(0, eval_data.size(0) - 1, bptt):data, targets = get_batch(eval_data, i) # 获取当前batch的数据和目标seq_len = data.size(0) # 序列长度output = model(data) # 前向传播output_flat = output.view(-1, ntokens)total_loss += seq_len * criterion(output_flat, targets).item() # 计算总损失return total_loss / (len(eval_data) - 1) # 返回平均损失math.exp(cur_loss)是使用数学模块中的 exp() 函数来计算当前损失对应的困惑度值。在这个上下文中,cur_loss 是当前的平均损失值,math.exp() 函数会将其作为指数的幂次,返回 e 的 cur_loss 次方。这个操作是为了计算困惑度(Perplexity),困惑度是一种评估语言模型好坏的指标,通常用于衡量模型对于给定输入数据的预测能力。困惑度越低,表示模型的预测能力越好。
best_val_loss = float('inf') # 初始最佳验证损失为无穷大
epochs = 1 # 训练的总轮数with TemporaryDirectory() as tempdir: # 创建临时目录来保存最佳模型参数# 最佳模型参数的保存路径best_model_params_path = os.path.join(tempdir, "best_model_params.pt") for epoch in range(1, epochs + 1): # 遍历每个epochepoch_start_time = time.time() # 记录当前epoch开始的时间train(model) # 进行模型训练val_loss = evaluate(model, val_data) # 在验证集上评估模型性能,计算验证损失val_ppl = math.exp(val_loss) # 计算困惑度elapsed = time.time() - epoch_start_time # 计算当前epoch的耗时print('-' * 89)# 打印当前epoch的信息,包括耗时、验证损失和困惑度print(f'| end of epoch {epoch:3d} | time: {elapsed:5.2f}s | 'f'valid loss {val_loss:5.2f} | valid ppl {val_ppl:8.2f}')print('-' * 89)if val_loss < best_val_loss: # 如果当前验证损失比最佳验证损失更低best_val_loss = val_loss # 更新最佳验证损失# 保存当前模型参数为最佳模型参数torch.save(model.state_dict(), best_model_params_path) scheduler.step() # 更新学习率# 加载最佳模型参数,即加载在验证集上性能最好的模型model.load_state_dict(torch.load(best_model_params_path))
五、评估模型
test_loss = evaluate(model, test_data)
test_ppl = math.exp(test_loss)
print('=' * 89)
print(f'| End of training | test loss {test_loss:5.2f} | 'f'test ppl {test_ppl:8.2f}')
print('=' * 89)
相关文章:
NLP实战9:Transformer实战-单词预测
目录 一、定义模型 二、加载数据集 三、初始化实例 四、训练模型 五、评估模型 🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有) 🍖 作者:[K同学啊] 模型结构图: &a…...

使用Vue.js和Rust构建高性能的物联网应用
物联网(IoT)应用是现代技术的重要组成部分,它们可以在各种场景中(例如智能家居,工业自动化等)提供无缝的自动化解决方案。在这篇文章中,我们将探讨如何使用Vue.js和Rust构建高性能的物联网应用。 1. 为什么选择Vue.js…...

idea调节文字大小、日志颜色、git改动信息
idea调节菜单栏文字大小: 调节代码文字大小: 按住ctrl滚动滑轮可以调节代码文字大小: 单击文件即可在主窗口上打开显示: idea在控制台对不同级别的日志打印不同颜色 : “grep console”插件 点击某一行的时候&#x…...

避免大龄程序员边缘化:如何在技术行业中保持竞争力
目录 导语持续学习和进修维护专业形象寻找适合自己的领域构建个人品牌和网络拥抱变化和创新实例结语: 导语 导语:随着科技的不断发展,技术行业的竞争日益激烈。对于那些年龄稍长的程序员来说,如何保持竞争力并避免边缘化成为了一…...

Jenkins工具系列 —— 启动 Jenkins 服务报错
错误显示 apt-get 安装 Jenkins 后,自动启动 Jenkins 服务报错。 排查原因 直接运行jenkins命令 发现具体报错log:Failed to start Jetty或Failed to bind to 0.0.0.0/0.0.0.0:8080或Address already in use 说明:这里提示的是8080端口号…...

华为数通HCIA-实验环境ensp简介
ensp 路由器:AR系列、NE系列; 模拟器中使用AR2220; 交换机:S系列、CE系列; 模拟器中使用S5700; 线缆:copper——以太网链路; serial——串行链路,在模拟器中用于模…...

SK5代理与IP代理:网络安全中的爬虫利器
一、什么是IP代理与SK5代理? IP代理: IP代理是一种允许用户通过代理服务器进行网络连接的技术。用户请求经由代理服务器中转,从而实现隐藏真实IP地址,保护用户隐私,并在一定程度上突破IP访问限制。常见的IP代理有HTTP…...
实战:Prometheus+Grafana监控Linux服务器及Springboot项目
文章目录 前言知识积累什么是Prometheus什么是Grafana怎样完成数据采集和监控 环境搭建docker与docker-compose安装docker-compose编写 监控配置grafana配置prometheus数据源grafana配置dashboardLinux Host Metrics监控Spring Boot 监控 写在最后 前言 相信大家都知道一个项目…...
[用go实现解释器]笔记1-词法分析
本文是《用go实现解释器》的读书笔记 https://malred-blogmalred.github.io/2023/06/03/ji-suan-ji-li-lun-ji-shu-ji/shi-ti/go-compile/yong-go-yu-yan-shi-xian-jie-shi-qi/go-compiler-1/#toc-heading-6http://个人博客该笔记地址 github.com/malred/malanghttp:/…...

在 spark-sql / spark-shell / hive / beeline 中粘贴 sql、程序脚本时的常见错误
一个很小的问题,简单记录一下。有时候我们会粘贴一段已经成功运行过的SQL或程序脚本,但是在spark-sql / spark-shell / hive / beeline 中执行时可能会报这样的错误: hive> CREATE EXTERNAL TABLE IF NOT EXISTS ORDERS(> Display all…...
关于视频汇聚融合EasyCVR平台多视频播放协议的概述
视频监控综合管理平台EasyCVR具备视频融合能力,平台基于云边端一体化架构,具有强大的数据接入、处理及分发能力,平台既具备传统安防视频监控的能力与服务,也支持AI智能检测技术的接入,可应用在多行业领域的智能化监管场…...

三星书画联展:三位艺术家开启国风艺术之旅
7月22日,由广州白云区文联、白云区工商联主办的“三星书画联展”,在源美术馆正式开展。本次书画展展出的艺术种类丰富,油画、国画、彩墨画、书法等作品异彩纷呈。广东省政协原副主席、农工党省委书画院名誉院长马光瑜,意大利艺术研…...
在腾讯云服务器OpenCLoudOS系统中安装nginx(有图详解)
1. 创建安装目录 2. 下载、安装、编译 进入安装目录: cd /app/soft/nginx/ 下载: wget https://nginx.org/download/nginx-1.21.6.tar.gz 解压: tar -zxvf nginx-1.21.6.tar.gz 安装插件: yum -y install pcre-devel 安装…...

大数据课程E5——Flume的Selector
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Selector的概念和配置属性; ⚪ 掌握Selector的使用方法; 一、简介 1. 概述 1. Selector本身是Source的子组件,决定了将数据分发给哪个Channel。 2. Selector中提供了两种模式: …...

在线查看浏览器
随着网络的兴起,电影和电视剧已经成为我们生活中必不可少的乐趣。然而,像爱奇艺、优酷、腾讯、芒果等等这些平台,我们想要看好视频,需要开通VIP,虽然价格不是很高,但是我们能省则省啊,今天我就给…...
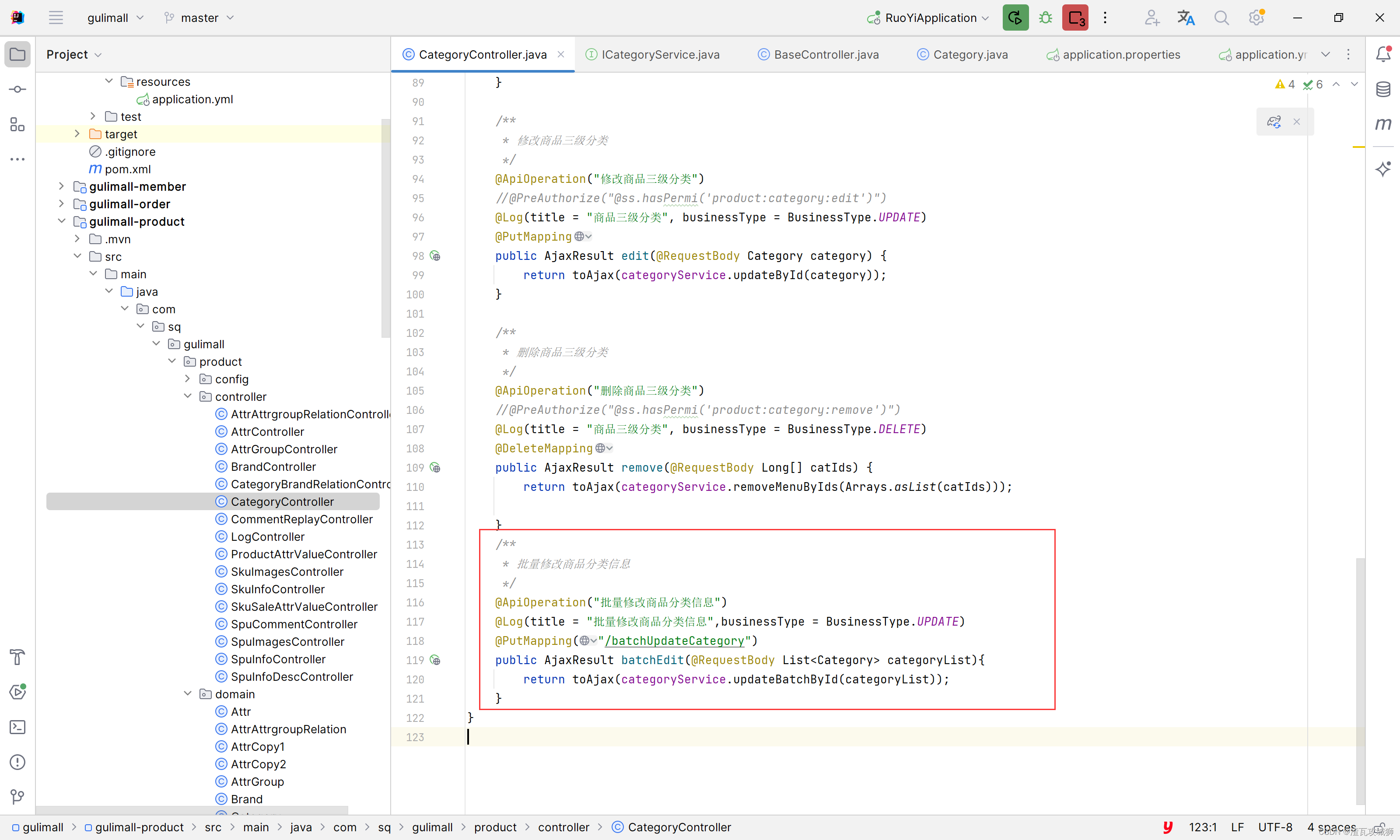
谷粒商城第七天-商品服务之分类管理下的分类的拖拽功能的实现
目录 一、总述 1.1 前端思路 1.2 后端思路 二、前端实现 2.1 判断是否能进行拖拽 2.2 收集受影响的节点,提交给服务器 三、后端实现 四、总结 一、总述 这个拖拽功能对于这种树形的列表,整体的搬迁是很方便的。但是其实现却并不是那么的简单。 …...
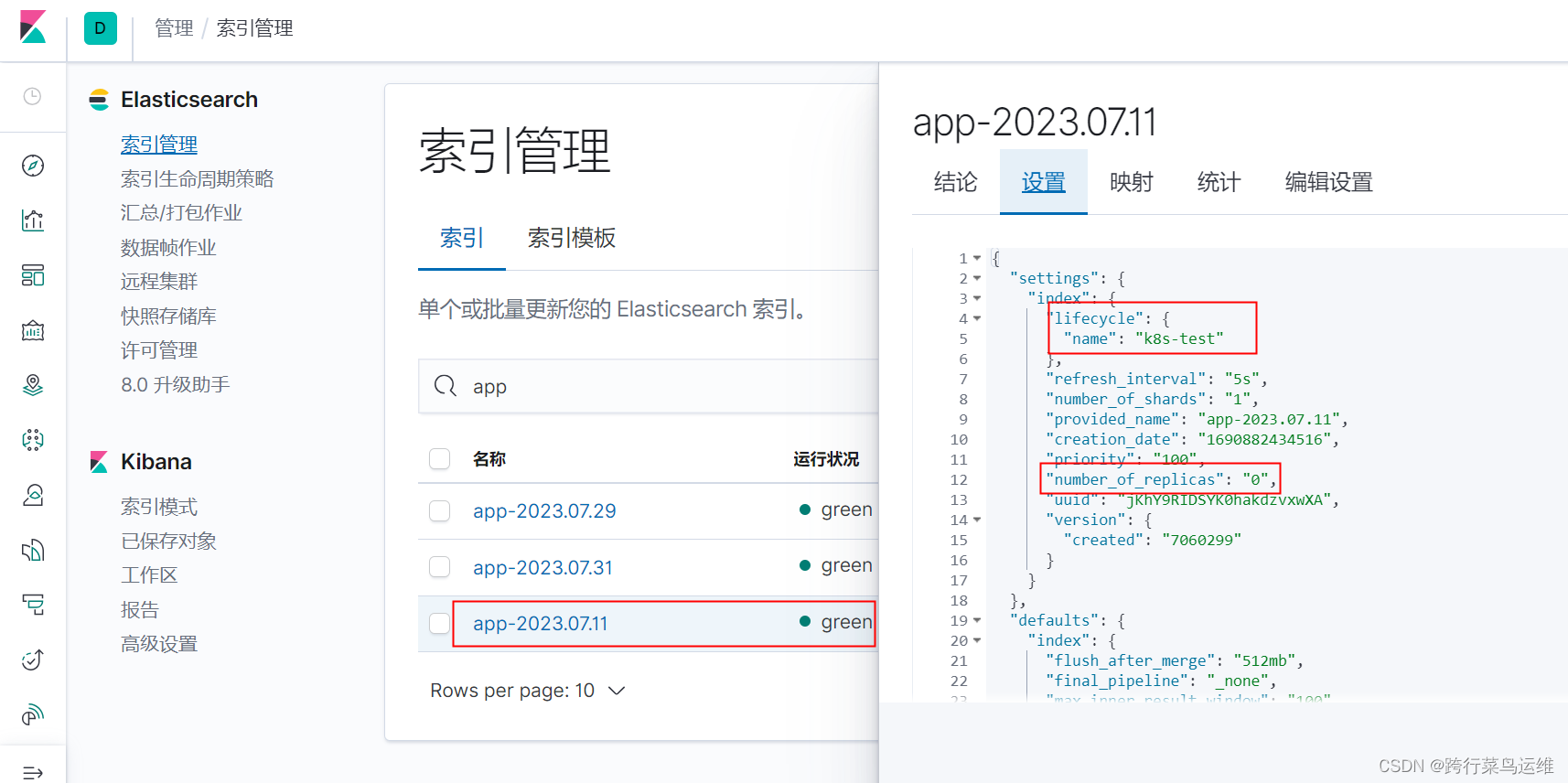
解决单节点es索引yellow
现象 单节点的es,自动创建索引后,默认副本个数为1,索引状态为yellow 临时解决 修改副本个数为0 永久解决 方法1、修改elasticsearch.yml文件,添加配置并重启es number_of_replicas:副本分片数,默认…...

Java虚拟机在类加载阶段都做了些什么,才使得我们可以运行Java程序
前言: 今天和大家探讨一道Java中经典的面试题,这道面试题经常出现在各个公司的面试中,结合周志明,老师的《深入理解Java虚拟机》书籍,本篇文章主要讲解Java类加载机制的知识。该专栏比较适合刚入坑Java的小白以及准备秋…...

华为认证 | 学HCIE,想培训需要注意啥?
HCIE(华为认证网络专家)是华为技术认证体系中的最高级别认证,对于网络工程师来说考试难度也比较高,一般来说,需要进行培训。 那么HCIE考试培训需要注意啥? 01 充分了解认证要求 在开始准备HCIE认证之前&a…...

这所211考数一英二,学硕降分33分,十分罕见!
一、学校及专业介绍 合肥工业大学(Hefei University of Technology),简称“合工大”,校本部位于安徽省合肥市,是中华人民共和国教育部直属的全国重点大学,是国家“双一流”建设高校, 国家“211工…...

终极LaTeX书籍排版指南:如何用ElegantBook打造专业学术著作
终极LaTeX书籍排版指南:如何用ElegantBook打造专业学术著作 【免费下载链接】ElegantBook Elegant LaTeX Template for Books 项目地址: https://gitcode.com/gh_mirrors/el/ElegantBook 在学术出版的世界里,精美的排版不仅是内容的载体ÿ…...

中兴光猫工厂模式解锁神器:zteOnu让你的网络管理权限瞬间升级
中兴光猫工厂模式解锁神器:zteOnu让你的网络管理权限瞬间升级 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾经想过,家里的中兴光猫其实隐藏着更多高级…...

解放双眼:如何用ebook2audiobook将电子书变成专业有声读物
解放双眼:如何用ebook2audiobook将电子书变成专业有声读物 【免费下载链接】ebook2audiobook Generate audiobooks from e-books, voice cloning & 1158 languages! 项目地址: https://gitcode.com/GitHub_Trending/eb/ebook2audiobook 你是否曾经在通勤…...

终极指南:如何3秒破解百度网盘提取码获取难题
终极指南:如何3秒破解百度网盘提取码获取难题 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次找到心仪的学习资料、工作文件或娱乐资源,却卡在…...

如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案
如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

Spring Boot Actuator生产级监控与管理工具包
Spring Boot Actuator 是 Spring Boot 提供的生产级监控与管理工具包,帮你把应用“可观测化”。它提供了一系列内置的端点(Endpoint),用来查看应用的内部状态,比如健康情况、配置信息、内存指标等。你可以把它理解成为…...

服务网格实战:Istio与Linkerd对比选型与落地实践
服务网格实战:Istio与Linkerd对比选型与落地实践 大家好,我是迪哥。服务网格(Service Mesh)是微服务架构的基础设施层,负责服务间的通信、安全、监控和治理。从 Istio 到 Linkerd,我们对比了多种方案&#…...

Unity动态设置Layer与摄像机屏蔽的完整闭环方案
1. 这不是“加个Layer”那么简单:为什么动态设置Layer常被误用却没人深究在Unity项目里,我见过太多人把“给GameObject动态设置Layer”当成一个随手就能调用的API——go.layer 12;,敲完回车,心里就默认“好了”。结果跑起来发现&…...

P2-CIFAR彩色图片识别
● 🍨 本文为🔗365天深度学习训练营中的学习记录博客 ● 🍖 原作者:K同学啊学习目标:1.编写一个完整的深度学习程序 2. 手动推导卷积层与池化层的计算过程一、前期准备1.设置GPUimport torch import torch.nn as nn im…...

你的仿真传感器数据准吗?Gazebo中激光雷达与深度相机的噪声模型配置与Rviz可视化调参实战
高保真机器人仿真:Gazebo传感器噪声模型与Rviz可视化调参全指南 在机器人算法开发中,仿真环境的真实性直接决定了算法测试的有效性。许多SLAM和导航算法在仿真环境中表现优异,一旦部署到真实机器人上却出现各种问题,这往往源于仿真…...