【电影推荐系统】实时推荐
概览
技术方案:
- 日志采集服务:通过利用Flume-ng对业务平台中用户对于电影的一次评分行为进行采集,实时发送到Kafka集群。
- 消息缓冲服务:项目采用Kafka作为流式数据的缓存组件,接受来自Flume的数据采集请求。并将数据推送到项目的实时推荐系统部分。
- 实时推荐服务:项目采用Spark Streaming作为实时推荐系统,通过接收Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到MongoDB数据库。
1. 实现思路
我们应该如何实现?
- 首先应该redis安装,这里存储用户的第K次评分(用户评分存入redis中)
- 安装zookeeper,安装kafka,都是standlone模式
- 测试Kafka与Spark Streaming 联调。Kafka生产一条数据,Spark Streaming 可以消费成功,并根据redis中的数据和MongoDB数据进行推荐,存入MongoDB中
- 在业务系统写埋点信息,测试时写入本地文件,之后再远程测试写入云服务器log文件中
- flume配置文件书写,kafka创建两个topic,对整个过程进行测试
2 环境准备
1.1 redis 安装
- redis安装redis安装
- 密码:123456
- 存入redis一些数据 lpush uid:1 mid:score
- redis 教程:教程
1.2 zookeeper单机版安装
- zookeeper安装:zookeeper安装
- 版本:3.7.1
- 遇到的坑:8080端口连接占用,我们需要在zoo.cpg文件中加上
admin.serverPort=8001重新启动即可。
1.3 kafka单机安装
- kafka安装:官网下载地址
- 安装使用的为:127.0.0.1
- 启动kafka:kafka教程
bin/kafka-server-start.sh config/server.properties
- 创建一个topic
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic recommender
- 生产一个消息
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic recommender
- 消费一个消息
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic recommender --from-beginning
3 测试kafka与spark streaming联调
- kafka版本:2.2.0
- spark版本:2.3.0
- 因此使用
spark-streaming-kafka-0-10

- 启动kafka,生产一条信息
- 书写程序
// 定义kafka连接参数val kafkaParam = Map("bootstrap.servers" -> "服务器IP:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "recommender","auto.offset.reset" -> "latest")// 通过kafka创建一个DStreamval kafkaStream = KafkaUtils.createDirectStream[String, String]( ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String]( Array(config("kafka.topic")), kafkaParam ))// 把原始数据UID|MID|SCORE|TIMESTAMP 转换成评分流// 1|31|4.5|val ratingStream = kafkaStream.map{msg =>val attr = msg.value().split("\\|")( attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt )}
- 若是kafka报错,如果你同样也是云服务器,请注意kafka的配置信息(很重要!)
(1)解决方法:修改kafka配置文件,设置为设置listeners为内网ip,设置外网ip
- 解决方案修改内网ip
(2)重新启动,成功
- 内网外网分流:内网外网分流
- kafka入门教程:入门教程
- redis报错:开启保护模式了,需要修改conf文件
效果
在kafka生产一个数据,可以在MongoDB中得到推荐的电影结果
4 后端埋点
前端进行评分后,触发click事件,后端进行测试埋点,利用log4j写入本地文件中。
4.1 本地测试
- log4j配置文件
log4j.rootLogger=INFO, file, stdout# write to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n# write to file
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.FILE.Append=true
log4j.appender.FILE.Threshold=INFO
log4j.appender.file.File=F:/demoparent/business/src/main/log/agent.txt
log4j.appender.file.MaxFileSize=1024KB
log4j.appender.file.MaxBackupIndex=1
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
- 埋点实现
//埋点日志
import org.apache.log4j.Logger;// 关键代码
Logger log = Logger.getLogger(MovieController.class.getName());
log.info(MOVIE_RATING_PREFIX + ":" + uid +"|"+ mid +"|"+ score +"|"+ System.currentTimeMillis()/1000)
4.2 写入远程测试
- Linux安装syslog服务,进行测试
- 主机log4j配置文件设置服务器ip
- log4j配置:写入远程服务器
log4j.appender.syslog=org.apache.log4j.net.SyslogAppender
log4j.appender.syslog.SyslogHost= 服务器IP
log4j.appender.syslog.Threshold=INFO
log4j.appender.syslog.layout=org.apache.log4j.PatternLayout
log4j.appender.syslog.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%20t] %-130c:(line:%4L) : %m%n
5 flume配置
- flume对接kafka:flume对接文件
- flume设置source和sink,source为文件地址,sink为kafka的log
# log-kafka.properties
agent.sources = exectail
agent.channels = memoryChannel
agent.sinks = kafkasink
agent.sources.exectail.type = exec
agent.sources.exectail.command = tail -f /project/logs/agent.log agent.sources.exectail.interceptors=i1 agent.sources.exectail.interceptors.i1.type=regex_filter agent.sources.exectail.interceptors.i1.regex=.+MOVIE_RATING_PREFIX.+ agent.sources.exectail.channels = memoryChannelagent.sinks.kafkasink.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.kafkasink.kafka.topic = log agent.sinks.kafkasink.kafka.bootstrap.servers = 服务器地址:9092 agent.sinks.kafkasink.kafka.producer.acks = 1 agent.sinks.kafkasink.kafka.flumeBatchSize = 20 agent.sinks.kafkasink.channel = memoryChannel
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 10000
6 实时推荐
ratingStream.foreachRDD{rdds => rdds.foreach{case (uid, mid, score, timestamp) => {println("rating data coming! >>>>>>>>>>>>>>>>")println(uid+",mid:"+mid)// 1. 从redis里获取当前用户最近的K次评分,保存成Array[(mid, score)]val userRecentlyRatings = getUserRecentlyRating( MAX_USER_RATINGS_NUM, uid, ConnHelper.jedis )println("用户最近的K次评分:"+userRecentlyRatings)// 2. 从相似度矩阵中取出当前电影最相似的N个电影,作为备选列表,Array[mid]val candidateMovies = getTopSimMovies( MAX_SIM_MOVIES_NUM, mid, uid, simMovieMatrixBroadCast.value )println("电影最相似的N个电影:"+candidateMovies)// 3. 对每个备选电影,计算推荐优先级,得到当前用户的实时推荐列表,Array[(mid, score)]val streamRecs = computeMovieScores( candidateMovies, userRecentlyRatings, simMovieMatrixBroadCast.value )println("当前用户的实时推荐列表:"+streamRecs)// 4. 把推荐数据保存到mongodbsaveDataToMongoDB( uid, streamRecs )}}
}
def computeMovieScores(candidateMovies: Array[Int],userRecentlyRatings: Array[(Int, Double)],simMovies: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]]): Array[(Int, Double)] ={// 定义一个ArrayBuffer,用于保存每一个备选电影的基础得分val scores = scala.collection.mutable.ArrayBuffer[(Int, Double)]()// 定义一个HashMap,保存每一个备选电影的增强减弱因子val increMap = scala.collection.mutable.HashMap[Int, Int]()val decreMap = scala.collection.mutable.HashMap[Int, Int]()for( candidateMovie <- candidateMovies; userRecentlyRating <- userRecentlyRatings){// 拿到备选电影和最近评分电影的相似度val simScore = getMoviesSimScore( candidateMovie, userRecentlyRating._1, simMovies )if(simScore > 0.7){// 计算备选电影的基础推荐得分scores += ( (candidateMovie, simScore * userRecentlyRating._2) )if( userRecentlyRating._2 > 3 ){increMap(candidateMovie) = increMap.getOrDefault(candidateMovie, 0) + 1} else{decreMap(candidateMovie) = decreMap.getOrDefault(candidateMovie, 0) + 1}}}// 根据备选电影的mid做groupby,根据公式去求最后的推荐评分scores.groupBy(_._1).map{// groupBy之后得到的数据 Map( mid -> ArrayBuffer[(mid, score)] )case (mid, scoreList) =>( mid, scoreList.map(_._2).sum / scoreList.length + log(increMap.getOrDefault(mid, 1)) - log(decreMap.getOrDefault(mid, 1)) )}.toArray.sortWith(_._2>_._2)
}
7 启动顺序
- 启动hadoop、spark的容器
cd /dockerdocker-compose up -ddocker-compose ps
- 启动mongodb和redis服务
netstat -lanp | grep "27017"bin/redis-server etc/redis.conf
- 启动zookeeper、kafka服务
./zkServer.sh startbin/kafka-server-start.sh config/server.properties
- 启动flume服务
bin/flume-ng agent -c ./conf/ -f ./conf/log-kafka.properties -n agent
实现效果
前端评分成功后写入日志文件,flume对接log日志文件无问题,kafka对接flume无问题,spark streaming处理收到的一条数据,进行推荐,存入MongoDB中。

总结
由于时间匆忙,写的有些匆忙,如果有需要前端设计代码和后端的代码可以评论我,我整理整理发到github上。
前端设计部分没有时间去详细做,后续再对前端页面进行美化。本科当时整合了一个管理系统,现在也没有时间做,总之,一周多时间把当时的系统快速复现了下,算是一个复习。
在进行开发时,遇到许多问题,版本问题、服务器内网外网问题、docker容器相关问题、协同过滤算法设计问题,但帮着自己复习了下Vue和SpringBoot。
遇到问题时
- 遇到问题不应该盲目解决,应该静下心看看报错原因,想想为何报错
- 版本尤其重要,因此最好在一个project的pom设定版本
- 使用服务器搭建docker-compose,利用该方法来搭建集群,快速简单,但涉及的端口转发等一些网络知识需要耐下心来看
- Vue-Cli+Element-ui搭配起来开发简单
- 写程序时,我们应该提前约定好接口,否则后续会很混乱…
后续
- 后续将优化下前端页面,设计更多功能
- 改进推荐算法
- 增加冷启动方案
相关文章:
【电影推荐系统】实时推荐
概览 技术方案: 日志采集服务:通过利用Flume-ng对业务平台中用户对于电影的一次评分行为进行采集,实时发送到Kafka集群。消息缓冲服务:项目采用Kafka作为流式数据的缓存组件,接受来自Flume的数据采集请求。并将数据推…...

Delphi 开发不一样的窗体标题栏:TTitleBarPanel
目录 TTitleBarPanel 的使用 TTitleBarPanel 的使用进阶 一、设置标题栏高度、颜色 二、个性化标题栏的关闭等按键 我们在用Delphi开发程序的时候,窗体的标题栏一般都是标准的windows标题栏,上面包括:程序图标、标题、最小化、最大化、关闭…...

Quartz中禁止并发机制源码级解析
文章目录 Quartz进行任务调度时通常会要求一个任务禁止并发执行,此时只需要在Job类上面添加一个注解DisallowConcurrentExecution即可。在保存到数据库里面时,对应QRTZ_JOB_DETAILS表中的IS_NONCONCURRENT字段的值为1(true)。那么…...

为什么从公有云迁移到私有云的越来越多?
随着云计算的快速发展,越来越多的组织开始考虑将其IT基础设施从公有云迁移到私有云。这种转变背后存在着一系列的原因和动机,下面我们将探讨一些常见的迁移原因。 首先,数据安全和隐私是许多组织选择私有云的主要原因之一。在公有云中&#…...

用shell实现MySQL分库分表操作
#!/bin/bash mysql_cmd-uroot -p123 #定义变量保存密码 exclude_dbinformation_schema|performance_schema|sys #数据库 bak_path/backup/db #备份路径 mysql ${mysql_cmd} -e show databases -N | egrep -v "${exclude_db}" > dbname while read line do …...

php 适配器模式
一,适配器模式,属于结构设计模式的一种,用于将一个类的接口转换成客户期望的接口。 1,目标接口(Target Interface):是客户期望的接口,定义了客户要调用的方法。 2,适配器…...
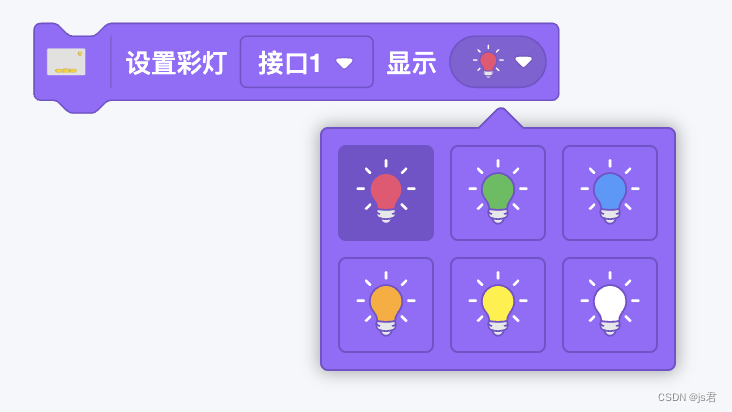
Scratch Blocks自定义组件之「下拉图标」
一、背景 由于自带的下拉图标是给水平布局的block使用,放在垂直布局下显得别扭,而且下拉选择后回修改image字段的图片,这让我很不爽,所以在原来的基础上稍作修改,效果如下: 二、使用说明 (1&am…...
Robot Framweork之UI自动化测试---分层设计
Robot Framework 的分层思想是一种测试设计和代码组织的模式,它将测试用例的实现和测试执行逻辑分离,以提高测试的可维护性、可读性和可扩展性。 一、分层思想 在实际项目中,一般分为三层:元素层,流程层,用…...

MySQL8.0/8.x更新用户密码命令
authentication_string 这是Mysql8.0新做出的修改,在旧版本中使用的是password()函数。 2,在网上找到的mysql忘记密码的解决方案中,大多会使用 UPDATE user SET authentication_string12345 WHERE userroot; 来直接将密码改成12345࿰…...

【MySQL】下载安装以及SQL介绍
1,数据库相关概念 以前我们做系统,数据持久化的存储采用的是文件存储。存储到文件中可以达到系统关闭数据不会丢失的效果,当然文件存储也有它的弊端。 假设在文件中存储以下的数据: 姓名 年龄 性别 住址 张三 23 男 北京…...

算法题--二叉树(二叉树的最近公共祖先、重建二叉树、二叉搜索树的后序遍历序列)
目录 二叉树 题目 二叉树的最近公共祖先 原题链接 解析 二叉搜索树的最近公共节点 核心思想 答案 重建二叉树 题目链接 解析 核心思想 答案 二叉搜索树的后序遍历序列 原题链接 解析 核心思想 答案 二叉树 该类题目的解决一般是通过节点的遍历去实现&#x…...

mysql的基础面经-索引、事务
1 聚簇索引 1 和主键索引的关系 2 和非聚簇索引的关系,其叶子节点存储的是聚簇索引中的主键 3 索引覆盖机制使得非聚簇索引不用回表二次查询 2 举一个使用索引覆盖的例子 我的项目中没有使用到覆盖索引,但是可以举一个例子,比如我直接为年…...

Windows下双网卡配置静态路由,实现内外网同时使用
怎么样设置双网卡?内网外网两个网络这么同时连接? 接下来听好了,赶紧动手 情况描述: 我使用的Windows10电脑,支持双网卡工作 目前我工作需要使用的使用内网,但是又需要使用外网,需要同时使用&a…...

Spring整合Mybatis、Spring整合JUnit
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaweb 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Spring整合 一、Spring整合Mybatis1.1 整合Mybatis&#x…...
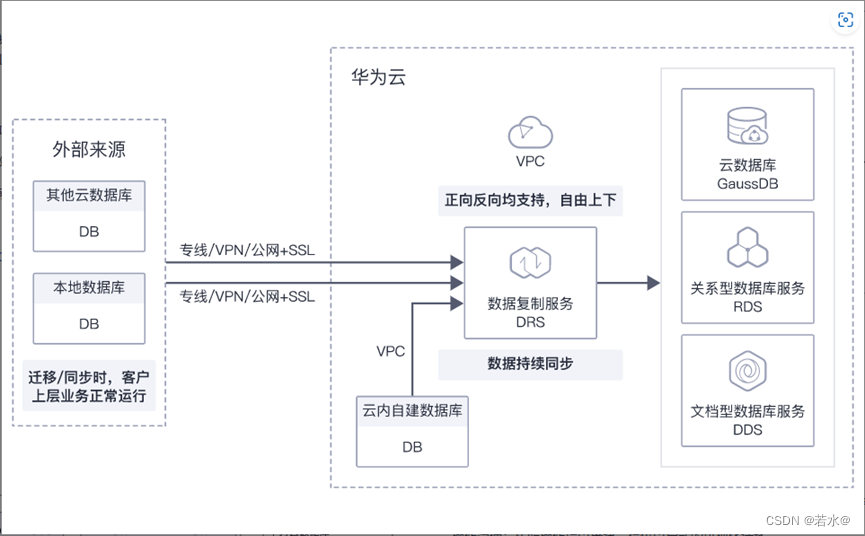
Devops系统中jira平台迁移
需求:把aws中的devops系统迁移到华为云中,其中主要是jira系统中的数据迁移,主要方法为在华为云中建立一套 与aws相同的devops平台,再把数据库和文件系统中的数据迁移,最后进行测试。 主要涉及到的服务集群CCE、数据库mysql、弹性文件服务SFS、数据复制DRS、弹性负载均衡ELB。 迁…...

【雕爷学编程】MicroPython动手做(29)——物联网之SIoT
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...
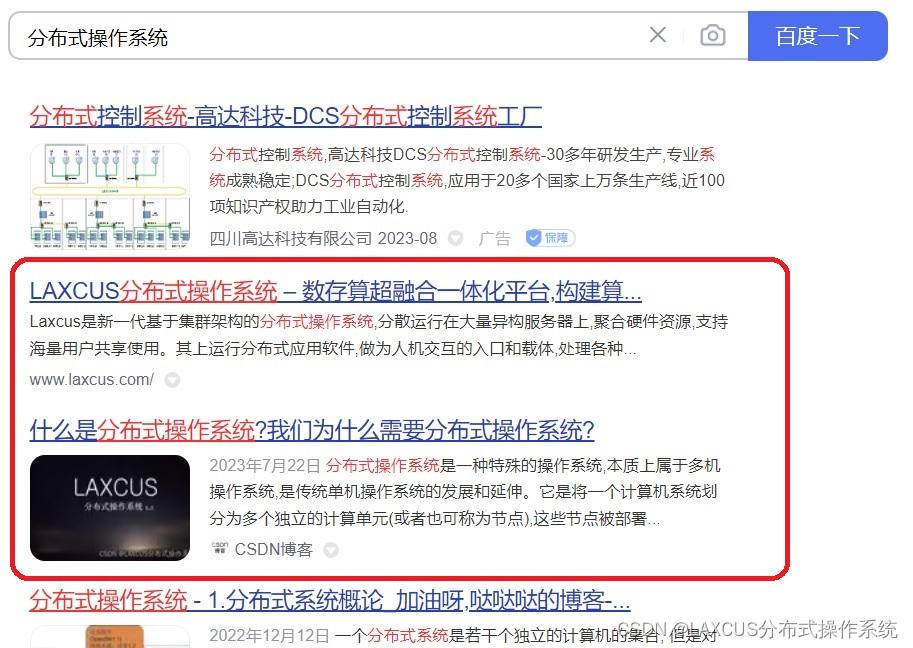
LAXCUS分布式操作系统引领科技潮流,进入百度首页
信息源自某家网络平台,以下原样摘抄贴出。 随着科技的飞速发展,分布式操作系统做为通用基础平台,为大数据、高性能计算、人工智能提供了强大的数据和算力支持,已经成为了当今计算机领域的研究热点。近日,一款名为LAXCU…...

Linux--按行读取数据:fgets
函数定义: char *fgets(char *s,int size,FILE *stream); S是指接受数据缓冲区,用于存放stream里读取的数据 size是指缓冲区的大小 返回值为NULL表明读取失败,反之读取成功...

express学习笔记5 - 自定义路由异常处理中间件
修改router/index.js,添加异常处理中间件 *** 自定义路由异常处理中间件* 注意两点:* 第一,方法的参数不能减少* 第二,方法的必须放在路由最后*/ router.use((err, req, res, next) > {console.log(err);const msg (err &…...
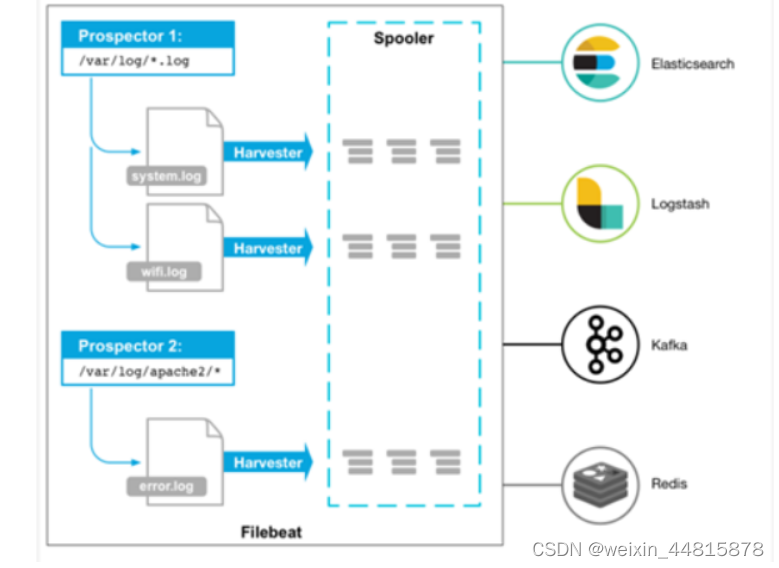
filebeat介绍
1、filebeat概述 Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash或kafka进行索引 1.1 Filebeat两个主要组件 prospector 和 harvester。 prospector&a…...

通过用量看板分析不同模型在taotoken上的实际token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析不同模型在taotoken上的实际token消耗差异 效果展示类,分享一名开发者在完成一个多轮对话项目后&…...

从MySQL分区到OceanBase分区:迁移老手教你平滑过渡与性能调优
从MySQL分区到OceanBase分区:迁移老手教你平滑过渡与性能调优 当MySQL分区表遇上OceanBase分布式架构,传统设计思维往往成为性能瓶颈的源头。本文将揭示两种数据库分区机制的本质差异,并提供一套经过生产验证的迁移方法论,帮助您避…...

健身房会员行为可视化涨点改进 | 全网独家复现,健康洞察实战篇 引入多维度可视化+用户分层分析,助力会员留存、课程优化、个性化指导有效涨点
目录 一、实战背景与核心目标(贴合健身房实际运营场景) 1.1 实战背景 1.2 核心目标 1.3 数据集说明(可直接获取,确保复现) 二、完整代码实现(全流程可复现,标注详细注释) 2.1 环境配置(明确版本,避免兼容问题) 2.2 数据加载与初步探索(补充异常值、冗余数据…...

嵌入式MCU性能评估:CoreMark移植、测试与深度分析指南
1. 项目概述:为什么我们需要CoreMark?在嵌入式开发领域,尤其是基于ARM Cortex-M这类资源受限的微控制器(MCU)进行选型或性能优化时,一个最直接也最令人头疼的问题就是:这颗芯片到底有多“快”&a…...

Midjourney中画幅风格不生效?5个致命配置错误正在 silently 毁掉你的成片率
更多请点击: https://kaifayun.com 第一章:Midjourney中画幅风格失效的真相与底层机制 Midjourney 中的中画幅(Medium Format)风格常被用户以 --style medium-format 或关键词 medium format film 调用,但大量实测表…...

Kimi LeetCode 2547. 拆分数组的最小代价 C++实现
这道题的核心思路是动态规划 记忆化搜索。我们定义 dfs(i) 为从下标 i 开始拆分数组的最小代价,答案即为 dfs(0)。关键观察子数组的重要性 k trimmed(subarray).length。其中 trimmed 操作会移除子数组中只出现一次的数字。如果我们用 cnt[x] 记录数字 x 在当前子…...

【卷卷观察】Google I/O 炸场背后:AI 行业正在经历一场“越南战争“
Google I/O 2026 开完了,朋友圈和推特上全是"智能体时代来了"的刷屏。但说实话,我越看越觉得不对劲。不是因为 Google 发布的东西不好——Gemini Spark 确实酷,93 个 Agent 并行写操作系统也确实震撼。而是因为这种"震撼"…...

Java 程序员第 24 阶段:多 Agent 高阶实战,复杂业务场景完整落地实现
在多 Agent 基础篇中,我们探讨了角色协同、任务拆分的基本模式。本文进一步深入,聚焦高阶架构设计、跨服务协作与复杂场景完整落地,帮助读者构建生产级别的多 Agent 系统。一、高阶架构:从简单协同到生产级系统1.1 三层架构模型成…...

启XX辰-头部安全公司面试提问
自我介绍 对称加密有哪些,非对称加密有哪些,两者之间的主要差异 有过JS逆向的经验吗 非对称加密如何获取加密前的内容,已知公钥 如果就给你一个登录框,给出你的测试思路 对于在工作时,给你一个企业名,给出你…...

【限时解密】ElevenLabs未公开的瑞典文语料权重配置表:仅限前200名开发者获取的/sv-SE/声道微调参数
更多请点击: https://codechina.net 第一章:瑞典文语音合成的技术背景与ElevenLabs架构定位 瑞典语作为北日耳曼语支的重要语言,拥有丰富的元音系统(9个长元音、9个短元音)、独特的声调重音(accent 1 和 a…...