filebeat介绍
1、filebeat概述
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash或kafka进行索引
1.1 Filebeat两个主要组件
prospector 和 harvester。
prospector:探测者
harvester:采集器
prospector 负责管理harvester并找到所有要读取的文件来源。 如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。
Prospector*(勘测者):**负责管理Harvester并找到所有读取源。Prospector会找到/apps/logs/目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
Harvester**(收割机):**负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
Filebeat如何记录文件状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Filebeat目前支持两种prospector类型:log和stdin。
负责读取单个文件的内容。 如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
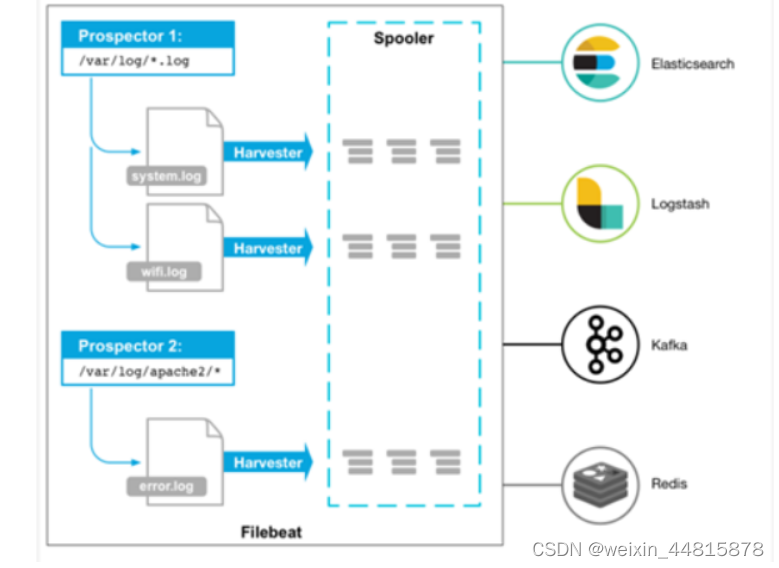
总结:
1.Prospectors:检测和采集日志数据的组件,可以检测新的日志文件或文件增量,并向Harvesters发送读取请求。
2.Harvesters:读取日志文件的组件,会读取Prospector传来的日志文件,进行过滤和捕捉,并将事件发送给Spooler。
3.Spooler:收集Harvester读取的事件,并进行缓冲,最后批量发送给输出(Output)。
4.Registry记录哪些文件被读取过,和读取到的Offset,用于下次检测文件增量。
5.Filebeat通过不断反复以上步骤,来持续监控和采集日志数据。
在 /usr/local/filebeat-7.8.0-linux-x86_64/data/registry/filebeat
2.filebeat 和logstarch 对比优缺点?
Filebeat和Logstash都是ELK栈中的重要组件,但有以下主要优缺点对比:
2.1 filebeat优缺点
filebeat优点:
1.轻量级,资源消耗小,易于在每台服务器部署。
2.模块化设计,支持丰富的输入和输出插件,易于扩展。
3.能保存状态并支持断点续传,避免重复发送数据。
4.文件采集不依赖inotify,适用于各环境。
Filebeat缺点:
1.依赖其他组件(如Logstash)进行复杂的数据处理和分析。
2.不支持实时数据分析,有一定延迟。
Harvester 和 Spooler 采用的是批量采集和批量发送的方式,因此存在一定的延迟,无法做到实时数据分析。
延迟的主要原因有两个:
-
缓存策略导致的延迟:Harvester 采集到的数据会先缓存在本地磁盘中,等待 Spooler 进行批量传输。如果缓存的事件数量较少,或者数据采集频率较低,可能需要等待一段时间才能达到一定的批量大小,从而导致延迟。
-
网络传输导致的延迟:Spooler 批量传输数据到目标数据存储也需要一定的时间,特别是当目标数据存储和 Harvester 所在服务器之间的网络较慢或不稳定时,会导致更大的延迟。
因此,如果需要实现实时数据分析,需要采用实时数据传输的方式,例如使用 Kafka 等消息队列,将数据采集和数据分析解耦,实现高效实时的数据传输和处理。同时,还需要优化数据采集和传输的性能和稳定性,以保证数据的实时性和准确性。
3.支持的日志格式有限,很多格式需要自定义parser。
2.2 logstash优缺点
Logstash优点:
1.功能强大,支持丰富的数据过滤、转换和输出。
2.支持实时数据处理和分析。
3.支持的日志格式和数据源广泛,社区支持强大。
4.配置灵活,Pipeline可以组合多种filter和output,实现复杂的数据处理逻辑。
Logstash缺点:
1.资源消耗较大,不易在大规模服务器上部署。
2.配置和管理复杂,Pipeline的调试和维护难度较大。
3.不保存状态,无法断点续传,会重复处理以发送数据。
4.依赖Filebeat等工具进行数据采集,本身不具备文件监控能力。
总结:Filebeat跟Logstash虽然位于ELK栈的不同层面,但可以相互配合,形成完整的日志采集和处理体系。Filebeat专注于高效稳定的日志采集,Logstash专注于强大灵活的数据处理。Filebeat的轻量级和Logstash的功能强大,可以很好的弥补彼此的不足。所以在实际应用中,常常会同时使用Filebeat和Logstash,实现日志数据的采集、过滤、转换、丰富和输出。通过理解两者的优缺点,可以让我们更好的利用ELK栈,构建高效、灵活且易于维护的日志解决方案
相关文章:
filebeat介绍
1、filebeat概述 Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash或kafka进行索引 1.1 Filebeat两个主要组件 prospector 和 harvester。 prospector&a…...
使用SSM框架实现个人博客管理平台以及实现Web自动化测试
文章目录 前言1. 项目概述2. 项目需求2.1功能需求2.2 其他需求2.3 系统功能模块图 3. 开发环境4. 项目结构5. 部分功能介绍5.1 数据库密码密文存储5.2 统一数据格式返回5.3 登录拦截器 6. 项目展示7. 项目测试7.1 测试用例7.2 执行部分自动化测试用例 前言 在几个月前实现了一…...

【深度学习】MAT: Mask-Aware Transformer for Large Hole Image Inpainting
论文:https://arxiv.org/abs/2203.15270 代码:https://github.com/fenglinglwb/MAT 文章目录 AbstractIntroductionRelated WorkMethod总体架构卷积头Transformer主体Adjusted Transformer Block Multi-Head Contextual Attention Style Manipulation Mo…...

PyTorch BatchNorm2d详解
通常和卷积层,激活函数一起使用...
慕课网Go-4.package、单元测试、并发编程
package 1_1_User.go package usertype User struct {Name string }1_1_UserGet.go package userfunc GetCourse(c User) string {return c.Name }1_1_UserMain.go package mainimport ("fmt"Userch03 "goproj/IMOOC/ch03/user"//别名,防止同名…...

[JavaWeb]SQL介绍-DDL-DML
SQL介绍-DDL-DML 一.SQL简介1.简介2.SQL通用语法3.SQL语言的分类 二.DDL-操作数据库与表1.DDL操作数据库2.DDL操作表①.查询表(Retrieve)②.创建表(Create)③.修改表(Update)④.删除表(Delete) 三.Navicat的安装与使用四.DML-操作表数据1.添加(Insert)2.修改(Update)3.删除(Del…...
)
git源码安装(无sudo权限)
git源码安装(无sudo权限) 下载源码解压安装添加到环境变量 下载源码 去https://mirrors.edge.kernel.org/pub/software/scm/git/下载需要的版本。我下载的是2.41.0版本 wget https://mirrors.edge.kernel.org/pub/software/scm/git/git-2.41.0.tar.gz解…...
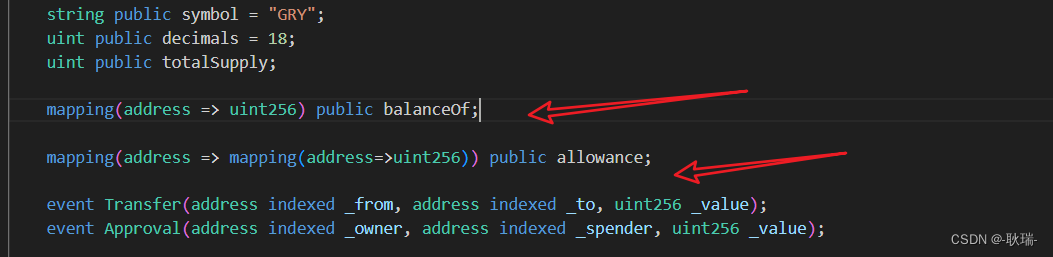
Web3 叙述交易所授权置换概念 编写transferFrom与approve函数
前文 Web3带着大家根据ERC-20文档编写自己的第一个代币solidity智能合约 中 我们通过ERC-20一种开发者设计的不成文规定 也将我们的代币开发的很像个样子了 我们打开 ERC-20文档 我们transfer后面的函数就是transferFrom 这个也是 一个账号 from 发送给另一个账号 to 数量 val…...
Redis系列二:Clion+MAC+Redis环境搭建
1. ClionMACRedis-3.0-annotated环境搭建 参考: https://github.com/huangz1990/redis-3.0-annotated https://gitee.com/dumpcao/redis-3.0-annotated-cmake-in-clion https://tool.4xseo.com/a/12910.html 1.1 下载并导入Clion git clone https://gitee.com/dum…...
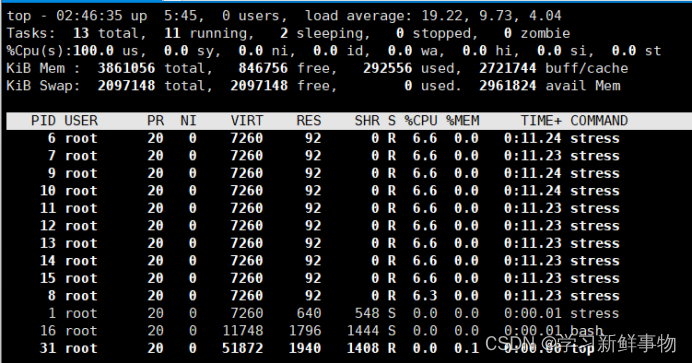
Linux下 Docker容器引擎基础(2)
目录 创建私有仓库 将修改过的nginx镜像做标记封装,准备上传到私有仓库 将镜像上传到私有仓库 从私有仓库中下载镜像到本地 CPU使用率 CPU共享比例 CPU周期限制 CPU 配额控制参数的混合案例 内存限制 Block IO 的限制 限制bps 和iops 创建私有仓库 仓库&a…...

现场服务管理系统有哪些?5个现场服务管理软件对比
现场售后服务管理软件的使用者通常是机械设备、家电、仪表仪器、医疗器械等厂商的工程师和客服调度人员。现场售后服务管理软件可将服务过程标准化,包括工单派发、服务过程步骤、配件订购出货和付款、客户评价都有系统支持,有的现场售后服务软件还支持数…...
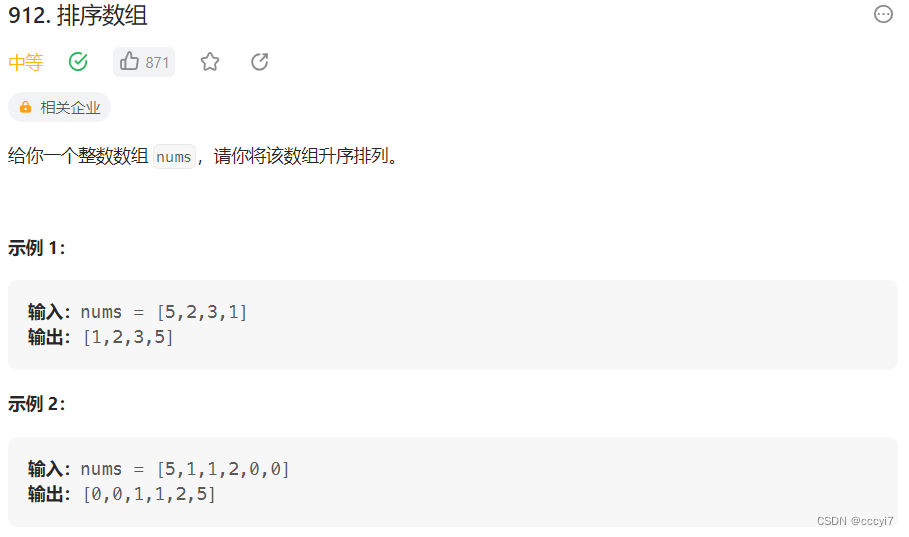
leetcode 912.排序数组
⭐️ 题目描述 🌟 leetcode链接:排序数组 思路: 此题如果使用冒泡插入选择这些时间复杂度 O ( N 2 ) O(N^2) O(N2) 的算法会超时,使用快排 优化也过不去,因为里面有一个测试用例全是 2 即使加了三数取中也会是 O (…...

利用MMPreTrain微调图像分类模型
前言 MMPreTrain是一款基于PyTorch的开源深度学习预工具箱,是OpenMMLab项目的成员之一MMPreTrain的主要特性有: 支持多元化的主干网络与预训练模型支持多种训练策略(有监督学习,无监督学习,多模态学习等)提…...

express学习笔记3 - 三大件
便于统一管理router,创建 router 文件夹,创建 router/index.js: const express require(express)// 注册路由 const router express.Router() router.get(/,function(req,res){res.send(让我们开始express之旅) }) /*** 集中处理404请求的…...
Java课题笔记~Maven基础
2、Maven 基础 2.1 Maven安装与配置 下载安装 配置:修改安装目录/conf/settings.xml 本地仓库:存放的是下载的jar包 中央仓库:要从哪个网站去下载jar包 - 阿里云的仓库 2.2 创建Maven项目...

三步问题(力扣)n种解法 JAVA
目录 题目:1、dfs:2、dfs 备忘录(剪枝):(1)神器 HashMap 备忘录:(2)数组 memo 备忘录: 3、动态规划:4、利用 static 的储存功能:&…...

flask---》登录认证装饰器/配置文件/路由系统
登录认证装饰器 # 0 装饰器的本质原理-# 类装饰器:1 装饰类的装饰器 2 类作为装饰器 # 1 装饰器使用位置,顺序 # 3 flask路由下加装饰器,一定要加endpoint-如果不指定endpoint,反向解析的名字都是函数名,不加装饰器…...
)
Jvm实际运行情况-JVM(十七)
上篇文章说jmap和jstat的命令,如何查看youngGc和FullGc耗时和次数。 Jmap-JVM(十六) Jvm实际运行情况 背景: 机器配置:2核4G JVM内存大小:2G 系统运行天数:7天 期间发生FULL GC次数和耗时…...
【BASH】回顾与知识点梳理(二)
【BASH】回顾与知识点梳理 二 二. Shell 的变量功能2.1 什么是变量?2.2 变量的取用与设定: echo, 变量设定规则: set/unset2.3 环境变量的功能用 set 观察所有变量 (含环境变量与自定义变量)export: 自定义变量转成环境变量那如何将环境变量转成自定义变…...

【分布式训练】Accelerate 多卡训练,单卡评测,进程卡住的解决办法
最近想把之前的一个模型的改成多卡训练的。我并不懂DDP,DP。一开始打算使用Transformers的Trainer,但是配置的过程踩了很多坑也没有弄成功。【我是自己写的评测方法,但是我找不到能让触发Trainer去用我的方法评测的路劲】,后来偶然…...

SpaceX披露IPO招股书:400亿美元数据中心交易、600亿美元收购Cursor,轨道AI计算挑战待解
拿下Anthropic算力大单:每月12.5亿美元,连付3年,双方均可叫停今年5月,SpaceX与Anthropic就访问COLOSSUS和COLOSSUS II两大大型数据中心的算力访问达成了云服务协议。根据协议,Anthropic同意在2029年5月之前每月向Space…...

2026年,IP地理位置精准查询的几个硬核技术变化
关于IP定位相关最近和几个同行交流,发现大家对IP定位的理解还停留在之前,想把自己这段时间的一些实践整理出来,希望能给同样在搞网络或风控的同行一些参考。 IPv6流量超过IPv4、住宅代理攻击泛滥、CGNAT覆盖越来越广……这些变化正在悄悄改变…...

用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定
用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定 在嵌入式开发领域,PWM(脉冲宽度调制)技术堪称"瑞士军刀"般的存在。无论是调节电机转速、控制舵机角度,还是实现LED呼吸灯效果…...

别再只用Selenium了!手把手教你用Python+UIAutomation+Unittest搭建Windows应用自动化测试框架
从Selenium到UIAutomation:Windows GUI自动化测试实战进阶指南 当Web自动化测试工程师首次接触Windows桌面应用测试时,往往会陷入工具选择的困境。传统基于坐标操作的自动化方案难以应对动态界面变化,而商业工具又存在学习成本高、灵活性不足…...

JLink版本不兼容?手把手教你解决APM32F003F6P6在Keil V5.14下的烧写闪退与报错
JLink与Keil版本冲突全解析:APM32F003F6P6烧写难题终极指南 当你深夜加班调试APM32F003F6P6,Keil突然弹出"Error Flash Download failed"然后闪退,JLink软件在你选择芯片型号后直接消失——这种工具链版本冲突带来的"玄学&quo…...

别只懂SARA归档删除!SAP数据生命周期管理实战:归档、查询与长期保留指南
SAP数据生命周期管理实战:从归档策略到长期可查询架构 在数字化转型浪潮中,企业数据量呈现指数级增长。某跨国制造企业的SAP系统仅物料凭证表每年就新增超过200万条记录,导致月结操作耗时从2小时延长至8小时。这不仅是存储空间的问题——系统…...

揭秘硬件安全:ChipWhisperer如何成为嵌入式设备的安全守护神?
揭秘硬件安全:ChipWhisperer如何成为嵌入式设备的安全守护神? 【免费下载链接】chipwhisperer ChipWhisperer - the complete open-source toolchain for side-channel power analysis and glitching attacks 项目地址: https://gitcode.com/gh_mirror…...

2025-2026年护眼灯品牌推荐:十大排行产品专业评测熬夜加班防眼干疲劳性价比高注意事项
摘要 当家庭与办公场景对光环境的要求从“照亮”升级为“护眼”,决策者面临的核心挑战已转变为如何在纷繁的技术参数与品牌承诺中,识别出真正能长期守护视觉健康、并适配多元场景的专业解决方案。根据全球市场研究机构Grand View Research的报告…...

解锁洛可可美学密码:用Midjourney V6实现蓬巴杜夫人级繁复纹样、柔光质感与粉金配色的5步精准控制法
更多请点击: https://intelliparadigm.com 第一章:洛可可美学的数字转译本质与Midjourney V6语义解码机制 洛可可美学以繁复卷曲的曲线、轻盈的不对称构图、粉金柔色调与自然母题(如贝壳、藤蔓、云朵)为标志,其核心并…...

图片去水印怎样快速搞定?2026年实测去水印工具推荐与方法全解
去水印是许多内容创作者和日常用户都会遇到的需求。无论是保存喜欢的图片、重新编辑素材,还是处理自己的作品,都需要用到高效的去水印方法。本文将为你详细介绍2026年最实用的图片去水印工具和操作方法,帮助你快速找到适合自己的解决方案。 小…...