利用MMPreTrain微调图像分类模型
前言
MMPreTrain是一款基于PyTorch的开源深度学习预工具箱,是OpenMMLab项目的成员之一MMPreTrain的主要特性有:- 支持多元化的主干网络与预训练模型
- 支持多种训练策略(有监督学习,无监督学习,多模态学习等)
- 提供多种训练技巧
- 大量的训练配置文件
- 高效率和高可扩展性
- 功能强大的工具箱,有助于模型分析和实验
- 支持多个开箱即用的推理任务
- 图片分类
- 图片描述(图片说明)
- 视觉问答(Visual Question Answering)
- 视觉定位(Visual Grounding)
- 搜索(图搜图,图搜文,文搜图)
- 本文主要演示如何使用
MMPreTrain,对图像分类任务,微调vision_transformer模型 - 分类数据使用
kaggle平台中的Animal Faces数据集,运行环境为kaggle GPU P100
环境安装
-
因为需要对模型进行可解释分析,需要安装
grad-cam包,mmcv的安装方式在我前面的mmdetection和mmsegmentation教程中都有写到。这里不再提 -
mmpretrain安装方法最好是使用git,如果没有git工具,可以使用mim install mmpretrain -
最后在项目文件夹下新建
checkpoint、outputs、data文件夹,分别用来存放模型预训练权重、模型输出结果、训练数据
from IPython import display
!pip install "grad-cam>=1.3.6"
!pip install -U openmim
!pip install -q /kaggle/input/frozen-packages-mmdetection/mmcv-2.0.1-cp310-cp310-linux_x86_64.whl!git clone https://github.com/open-mmlab/mmpretrain.git
%cd mmpretrain
!mim install -e .!mkdir checkpoint
!mkdir outputs
!mkdir datadisplay.clear_output()
- 在上面的安装工作完成后,我们检查一下环境,以及核对一下安装版本
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
import mmpretrain
print('MMCV版本', mmcv.__version__)
print('mmpretrain版本', mmpretrain.__version__)
print('CUDA版本', get_compiling_cuda_version())
print('编译器版本', get_compiler_version())
输出:
MMCV版本 2.0.1
mmpretrain版本 1.0.0
CUDA版本 11.8
编译器版本 GCC 11.3
- 因为
mmpretrain适用于很多种任务,因此在进行图像分类模型微调时先查看一下支持该任务的模型有哪些,可以调用list_models函数查看,因为我们想要微调vision_transformer模型,可以加上限制条件vit进行更精准的筛选
from mmpretrain import list_models, inference_model
list_models(task='Image Classification',pattern='vit')
- 这里以候选列表中的
vit-base-p32_in21k-pre_3rdparty_in1k-384px模型为例
模型推理
- 进入项目文件夹
configs/vision_transformer,查看模型型号对应预训练权重及config文件

- 下载预训练权重,对示例图片进行推理

from mmpretrain import ImageClassificationInferencer
# 待输入图像路径
img_path = 'mmpretrain/demo/bird.JPEG'
model = 'vit-base-p32_in21k-pre_3rdparty_in1k-384px'
# 预训练权重
pretrained = './checkpoints/vit-base-p32_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-9cea8599.pth'
# 推理预测
inferencer = ImageClassificationInferencer(model=model, pretrained=pretrained, device='cuda:0')result = inferencer('demo/bird.JPEG', show_dir="./visualize/")display.clear_output()
- 查看推理结果
result[0].keys()
输出:
dict_keys(['pred_scores', 'pred_label', 'pred_score', 'pred_class'])
- 打印分类置信度最高类别的名称,以及置信度
# 置信度最高类别的名称
print(result[0]['pred_class'])
# 置信度最高类别的置信度
print('{:.3f}'.format(result[0]['pred_score']))
house finch, linnet, Carpodacus mexicanus
0.985
微调模型
- 将数据集移到
data目录下,准备训练
# animal数据集移动
shutil.copytree('/kaggle/input/animal-faces/afhq', './data/animal')
配置文件解析
MMPreTrain配置文件和mmdetection、mmsegmentation有点不太一样,当你打开vit-base-p32_in21k-pre_3rdparty_in1k-384px的配置文件vit-base-p32_64xb64_in1k-384px.py时,会发现配置文件中只显式的定义了数据管道及处理方式- 但实际上数据处理和优化器参数都被隐形定义在
_base_下了,详细情况可以看下面的代码注释
_base_ = ['../_base_/models/vit-base-p32.py', # 模型配置'../_base_/datasets/imagenet_bs64_pil_resize.py', # 数据配置'../_base_/schedules/imagenet_bs4096_AdamW.py', # 训练策略配置'../_base_/default_runtime.py' # 默认运行设置
]# model setting
# 输入图像大小
model = dict(backbone=dict(img_size=384)) # dataset setting
# 输入的图片数据通道以 'RGB' 顺序
data_preprocessor = dict(mean=[127.5, 127.5, 127.5], # 输入图像归一化的 RGB 通道均值std=[127.5, 127.5, 127.5], # 输入图像归一化的 RGB 通道标准差to_rgb=True, # 是否将通道翻转,从 BGR 转为 RGB 或者 RGB 转为 BGR
)train_pipeline = [dict(type='LoadImageFromFile'), # 读取图像dict(type='RandomResizedCrop', scale=384, backend='pillow'), # 随机放缩裁剪dict(type='RandomFlip', prob=0.5, direction='horizontal'), # 随机水平翻转dict(type='PackInputs'), # 准备图像以及标签
]test_pipeline = [dict(type='LoadImageFromFile'), # 读取图像dict(type='ResizeEdge', scale=384, edge='short', backend='pillow'), # 缩放短边尺寸至384pxdict(type='CenterCrop', crop_size=384), # 中心裁剪dict(type='PackInputs'), # 准备图像以及标签
]train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
test_dataloader = dict(dataset=dict(pipeline=test_pipeline))# schedule设定
optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
- 打开
../_base_/models/vit-base-p32.py文件,查看模型配置
model = dict(type='ImageClassifier', # 主模型类型(对于图像分类任务,使用 `ImageClassifier`)backbone=dict(type='VisionTransformer', # 主干网络类型arch='b',img_size=224, # 输入模型图像大小patch_size=32, # patch数drop_rate=0.1, # dropout率init_cfg=[ # 初始化参数方式dict(type='Kaiming',layer='Conv2d',mode='fan_in',nonlinearity='linear')]),neck=None,head=dict(type='VisionTransformerClsHead', # 分类颈网络类型num_classes=1000, # 分类数in_channels=768, # 输入通道数loss=dict(type='CrossEntropyLoss', loss_weight=1.0), # 损失函数配置信息topk=(1, 5), # 评估指标,Top-k 准确率, 这里为 top1 与 top5 准确率))
- 打开
../_base_/datasets/imagenet_bs64_pil_resize.py文件,查看数据配置
dataset_type = 'ImageNet' # 预处理配置
data_preprocessor = dict(num_classes=1000,mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True,
)train_pipeline = [dict(type='LoadImageFromFile'),dict(type='RandomResizedCrop', scale=224, backend='pillow'),dict(type='RandomFlip', prob=0.5, direction='horizontal'),dict(type='PackInputs'),
]test_pipeline = [dict(type='LoadImageFromFile'),dict(type='ResizeEdge', scale=256, edge='short', backend='pillow'),dict(type='CenterCrop', crop_size=224),dict(type='PackInputs'),
]train_dataloader = dict(batch_size=64, # 每张 GPU 的 batchsizenum_workers=5, # 每个 GPU 的线程数dataset=dict( # 训练数据集type=dataset_type,data_root='data/imagenet',split='train',pipeline=train_pipeline),sampler=dict(type='DefaultSampler', shuffle=True), # 默认采样器
)val_dataloader = dict(batch_size=64,num_workers=5,dataset=dict(type=dataset_type,data_root='data/imagenet',split='val',pipeline=test_pipeline),sampler=dict(type='DefaultSampler', shuffle=False),
)# 验证集评估设置,使用准确率为指标, 这里使用 topk1 以及 top5 准确率
val_evaluator = dict(type='Accuracy', topk=(1, 5))test_dataloader = val_dataloader
test_evaluator = val_evaluator
- 打开
../_base_/schedules/imagenet_bs4096_AdamW.py文件,查看训练策略配置
optim_wrapper = dict(optimizer=dict(type='AdamW', lr=0.003, weight_decay=0.3), # 使用AdamW优化器# vit预训练专用配置paramwise_cfg=dict(custom_keys={'.cls_token': dict(decay_mult=0.0),'.pos_embed': dict(decay_mult=0.0)}),
)# 学习率策略
param_scheduler = [# 预热学习率调度器dict(type='LinearLR',start_factor=1e-4,by_epoch=True,begin=0,end=30,# 根据iter更新convert_to_iter_based=True),# 主要的学习策略dict(type='CosineAnnealingLR',T_max=270,by_epoch=True,begin=30,end=300,)
]# train, val, test设置,max_epoch和验证频率
train_cfg = dict(by_epoch=True, max_epochs=300, val_interval=1)
val_cfg = dict()
test_cfg = dict()auto_scale_lr = dict(base_batch_size=4096)
- 打开
../_base_/default_runtime.py文件,查看默认运行设置
# 默认所有注册器使用的域
default_scope = 'mmpretrain'# 配置默认的 hook
default_hooks = dict(# 记录每次迭代的时间timer=dict(type='IterTimerHook'),# 每 100 次迭代打印一次日志logger=dict(type='LoggerHook', interval=100),# 启用默认参数调度 hookparam_scheduler=dict(type='ParamSchedulerHook'),# 每个 epoch 保存检查点checkpoint=dict(type='CheckpointHook', interval=1),# 在分布式环境中设置采样器种子sampler_seed=dict(type='DistSamplerSeedHook'),# 验证结果可视化,默认不启用,设置 True 时启用visualization=dict(type='VisualizationHook', enable=False),
)# 配置环境
env_cfg = dict(# 是否开启 cudnn benchmarkcudnn_benchmark=False,# 设置多进程参数mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),# 设置分布式参数dist_cfg=dict(backend='nccl'),
)# 设置可视化工具
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(type='UniversalVisualizer', vis_backends=vis_backends)# 设置日志级别
log_level = 'INFO'# 从哪个检查点加载
load_from = None# 是否从加载的检查点恢复训练
resume = False# 默认随机数种子
randomness = dict(seed=None, deterministic=False)
修改配置文件
- 根据上述说明,这里提供两种修改配置文件的方法。
- 第1种是将共5个配置文件的信息写在一个新的配置文件
vit-base-p32_1xb64_in1k-384px_animal.py中,然后修改其中的内容。 - 首先将配置文件
vit-base-p32_64xb64_in1k-384px.py中的内容更新到继承的键值对中,比如model中的img_size=384,train_pipeline和test_pipeline也都需要改 - 然后更改
num_classes、dataset_type、train_dataloader、val_dataloader、val_evaluator、lr、param_scheduler、default_hooks、randomness - 需要注意的是
dataset_type要改成'CustomDataset',而'CustomDataset'中是没有split键的,所以要删掉train_dataloader、val_dataloader中的split键 - 因为分类数量较少,不足5类,所以将
val_evaluator中的topk由(1, 5)改成5 lr要与原batch的lr进行等比例缩放,缩放率为32/(64 * 64)(由配置文件名64xb64可知,原batch_size为64 * 64)- 因为只训练100个
epoch,所以LinearLR scheduler中的end键也进行等比例缩放,即除以3。则CosineAnnealingLR scheduler中的T_max、begin、end相应变化 - 因为模型在前20个
epoch可能没有学习成果,所以没有验证的必要,这里加入val_begin键,表示从第20个epoch开始在验证集上计算指标,验证的频率也不需要1个epoch一次,这里改成5个epoch验证一次 - 我们想要模型没10个epoch自动保存一次权重,并且最多同时保留两个训练权重,同时根据指标自动保留精度最高的训练权重
checkpoint = dict(type='CheckpointHook', interval=10, max_keep_ckpts=2, save_best='auto') - 记录频率
100(单位:iter)有点太低,我们改成10 - 最后固定随机数种子
randomness
custom_config = """
model = dict(type='ImageClassifier', # 主模型类型(对于图像分类任务,使用 `ImageClassifier`)backbone=dict(type='VisionTransformer', # 主干网络类型arch='b',img_size=384, # 输入模型图像大小patch_size=32, # patch数drop_rate=0.1, # dropout率init_cfg=[ # 初始化参数方式dict(type='Kaiming',layer='Conv2d',mode='fan_in',nonlinearity='linear')]),neck=None,head=dict(type='VisionTransformerClsHead', # 分类颈网络类型num_classes=3, # 分类数in_channels=768, # 输入通道数loss=dict(type='CrossEntropyLoss', loss_weight=1.0), # 损失函数配置信息topk=(1, 5), # 评估指标,Top-k 准确率, 这里为 top1 与 top5 准确率))dataset_type = 'CustomDataset' # 预处理配置
data_preprocessor = dict(mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],to_rgb=True,
)train_pipeline = [dict(type='LoadImageFromFile'),dict(type='RandomResizedCrop', scale=384, backend='pillow'),dict(type='RandomFlip', prob=0.5, direction='horizontal'),dict(type='PackInputs'),
]test_pipeline = [dict(type='LoadImageFromFile'),dict(type='ResizeEdge', scale=384, edge='short', backend='pillow'),dict(type='CenterCrop', crop_size=384),dict(type='PackInputs'),
]train_dataloader = dict(batch_size=64, # 每张 GPU 的 batchsizenum_workers=2, # 每个 GPU 的线程数dataset=dict( # 训练数据集type=dataset_type,data_root='./data/animal/train',pipeline=train_pipeline),sampler=dict(type='DefaultSampler', shuffle=True), # 默认采样器
)val_dataloader = dict(batch_size=64,num_workers=2,dataset=dict(type=dataset_type,data_root='./data/animal/val',pipeline=test_pipeline),sampler=dict(type='DefaultSampler', shuffle=False),
)# 验证集评估设置,使用准确率为指标, 这里使用 topk1 以及 top5 准确率
val_evaluator = dict(type='Accuracy', topk=1)test_dataloader = val_dataloader
test_evaluator = val_evaluatoroptim_wrapper = dict(optimizer=dict(type='AdamW', lr=0.003 * 32 / (64 * 64), weight_decay=0.3),# vit预训练专用配置paramwise_cfg=dict(custom_keys={'.cls_token': dict(decay_mult=0.0),'.pos_embed': dict(decay_mult=0.0)}),clip_grad=dict(max_norm=1.0)
)# 学习率策略
param_scheduler = [# 预热学习率调度器dict(type='LinearLR',start_factor=1e-4,by_epoch=True,begin=0,end=10,# 根据iter更新convert_to_iter_based=True),# 主要的学习策略dict(type='CosineAnnealingLR',T_max=90,by_epoch=True,begin=10,end=100,)
]# train, val, test设置,max_epoch和验证频率
train_cfg = dict(by_epoch=True, max_epochs=100, val_begin=20, val_interval=5)
val_cfg = dict()
test_cfg = dict()# 默认所有注册器使用的域
default_scope = 'mmpretrain'# 配置默认的 hook
default_hooks = dict(# 记录每次迭代的时间timer=dict(type='IterTimerHook'),# 每 10 次迭代打印一次日志logger=dict(type='LoggerHook', interval=10),# 启用默认参数调度 hookparam_scheduler=dict(type='ParamSchedulerHook'),checkpoint=dict(type='CheckpointHook', interval=10, max_keep_ckpts=2, save_best='auto'),# 在分布式环境中设置采样器种子sampler_seed=dict(type='DistSamplerSeedHook'),# 验证结果可视化,默认不启用,设置 True 时启用visualization=dict(type='VisualizationHook', enable=False),
)# 配置环境
env_cfg = dict(# 是否开启 cudnn benchmarkcudnn_benchmark=False,# 设置多进程参数mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),# 设置分布式参数dist_cfg=dict(backend='nccl'),
)# 设置可视化工具
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(type='UniversalVisualizer', vis_backends=vis_backends)# 设置日志级别
log_level = 'INFO'# 从哪个检查点加载
load_from = None# 是否从加载的检查点恢复训练
resume = False# 默认随机数种子
randomness = dict(seed=2023, deterministic=False)
"""
# 写入vit-base-p32_1xb64_in1k-384px_pets.py文件中
animal_config=f'./configs/vision_transformer/vit-base-p32_1xb64_in1k-384px_pets.py'
with open(animal_config, 'w') as f:f.write(custom_config)
- 第2种方法是先将默认配置文件读取,然后再通过python的字典特性进行更改,优点是,只改动需要改动的地方,逻辑清晰
- 缺点是有些在配置文件中的中间变量无效了,比如在配置文件中可以只用定义
dataset_type,后面train_dataloader、val_dataloader可以直接使用,但是用字典特性要改两遍 - 参数的改变和上面的一样,但是代码少很多
# 读取配置文件
from mmengine import Config
cfg = Config.fromfile('./configs/vision_transformer/vit-base-p32_64xb64_in1k-384px.py')
max_epochs = 100
batch_size = 64
lr_scale_factor = batch_size/(64 * 64)
epoch_scale_factor = max_epochs/cfg.train_cfg.max_epochscfg.model.head.num_classes = 3cfg.load_from = './checkpoints/vit-base-p32_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-9cea8599.pth'
cfg.work_dir = './work_dir'cfg.dataset_type = 'CustomDataset'cfg.train_dataloader.batch_size = batch_size
cfg.train_dataloader.num_workers = 2
cfg.train_dataloader.dataset.type = cfg.dataset_type
cfg.train_dataloader.dataset.data_root = './data/animal/train'
del cfg.train_dataloader.dataset['split']cfg.val_dataloader.batch_size = cfg.train_dataloader.batch_size
cfg.val_dataloader.num_workers = cfg.train_dataloader.num_workers
cfg.val_dataloader.dataset.data_root = './data/animal/valid'
cfg.val_dataloader.dataset.type = cfg.dataset_type
del cfg.val_dataloader.dataset['split']cfg.test_dataloader = cfg.val_dataloadercfg.val_evaluator = dict(type='Accuracy', topk=1)
cfg.test_evaluator = cfg.val_evaluatorcfg.optim_wrapper.optimizer.lr = cfg.optim_wrapper.optimizer.lr * lr_scale_factor# LinearLR scheduler end epoch
cfg.param_scheduler[0].end = cfg.param_scheduler[0].end * epoch_scale_factor# CosineAnnealingLR scheduler
cfg.param_scheduler[1].T_max = max_epochs - cfg.param_scheduler[0].end
cfg.param_scheduler[1].begin = cfg.param_scheduler[0].end
cfg.param_scheduler[1].end = max_epochscfg.train_cfg.max_epochs = max_epochs
cfg.train_cfg.val_begin = 20
cfg.train_cfg.val_interval = 5cfg.default_hooks.checkpoint = dict(type='CheckpointHook', interval=10, max_keep_ckpts=2, save_best='auto')
cfg.default_hooks.logger.interval = 50cfg.randomness.seed = 2023#------------------------------------------------------
animal_config=f'./configs/vision_transformer/vit-base-p32_1xb64_in1k-384px_pets.py'
with open(animal_config, 'w') as f:f.write(cfg.pretty_text)
启动训练
!python tools/train.py {animal_config}
- 由于输出日志太长,这里就不全部展示了,打印一下精度最高的模型权重
07/30 13:33:50 - mmengine - INFO - Epoch(val) [55][24/24] accuracy/top1: 99.9333 data_time: 0.2443 time: 0.5068
- 可以看到模型在验证集上的精度为99.93%,可以说非常不错
模型推理
- 加载精度最高的模型,并对图片进行推理
import glob
ckpt_path = glob.glob('./work_dir/best_accuracy_top1*.pth')[0]
img_path = '/kaggle/input/animal-faces/afhq/train/cat/flickr_cat_000052.jpg'inferencer = ImageClassificationInferencer(animal_config, pretrained=ckpt_path)result = inferencer(img_path)
result
输出:
[{'pred_scores': array([9.9998045e-01, 1.3512783e-05, 6.0256166e-06], dtype=float32),'pred_label': 0,'pred_score': 0.9999804496765137,'pred_class': 'cat'}]
绘制混淆矩阵
- 我们可以绘制混淆矩阵进一步检查模型精度
python tools/analysis_tools/confusion_matrix.py \{animal_config} \{ckpt_path}\--show
类别激活图(CAM)可视化
- 使用类别激活图(CAM)对分类图像进行解释,更多参数设置请参照官方文档
!python tools/visualization/vis_cam.py \{img_path} \{animal_config} \{ckpt_path} \--method GradCAM \--save-path cam.jpg \--vit-like
display.clear_output()
from PIL import Image
Image.open('cam.jpg')

T-SNE可视化
- 通过降维可视化可以进一步观察模型对类别分界线是否明显,还可以找到模型容易误判的类别
python tools/visualization/vis_tsne.py \{animal_config}\--checkpoint {ckpt_path}
相关文章:
利用MMPreTrain微调图像分类模型
前言 MMPreTrain是一款基于PyTorch的开源深度学习预工具箱,是OpenMMLab项目的成员之一MMPreTrain的主要特性有: 支持多元化的主干网络与预训练模型支持多种训练策略(有监督学习,无监督学习,多模态学习等)提…...

express学习笔记3 - 三大件
便于统一管理router,创建 router 文件夹,创建 router/index.js: const express require(express)// 注册路由 const router express.Router() router.get(/,function(req,res){res.send(让我们开始express之旅) }) /*** 集中处理404请求的…...
Java课题笔记~Maven基础
2、Maven 基础 2.1 Maven安装与配置 下载安装 配置:修改安装目录/conf/settings.xml 本地仓库:存放的是下载的jar包 中央仓库:要从哪个网站去下载jar包 - 阿里云的仓库 2.2 创建Maven项目...

三步问题(力扣)n种解法 JAVA
目录 题目:1、dfs:2、dfs 备忘录(剪枝):(1)神器 HashMap 备忘录:(2)数组 memo 备忘录: 3、动态规划:4、利用 static 的储存功能:&…...

flask---》登录认证装饰器/配置文件/路由系统
登录认证装饰器 # 0 装饰器的本质原理-# 类装饰器:1 装饰类的装饰器 2 类作为装饰器 # 1 装饰器使用位置,顺序 # 3 flask路由下加装饰器,一定要加endpoint-如果不指定endpoint,反向解析的名字都是函数名,不加装饰器…...
)
Jvm实际运行情况-JVM(十七)
上篇文章说jmap和jstat的命令,如何查看youngGc和FullGc耗时和次数。 Jmap-JVM(十六) Jvm实际运行情况 背景: 机器配置:2核4G JVM内存大小:2G 系统运行天数:7天 期间发生FULL GC次数和耗时…...
【BASH】回顾与知识点梳理(二)
【BASH】回顾与知识点梳理 二 二. Shell 的变量功能2.1 什么是变量?2.2 变量的取用与设定: echo, 变量设定规则: set/unset2.3 环境变量的功能用 set 观察所有变量 (含环境变量与自定义变量)export: 自定义变量转成环境变量那如何将环境变量转成自定义变…...

【分布式训练】Accelerate 多卡训练,单卡评测,进程卡住的解决办法
最近想把之前的一个模型的改成多卡训练的。我并不懂DDP,DP。一开始打算使用Transformers的Trainer,但是配置的过程踩了很多坑也没有弄成功。【我是自己写的评测方法,但是我找不到能让触发Trainer去用我的方法评测的路劲】,后来偶然…...

时间复杂度为O(nlogn)的两种排序算法
1.归并排序 归并排序的核心思想:如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。 归并排序使用的就是分治思想。分治&#x…...

java调用onnx模型,支持yolov5和yolov7
不点star不给解答问题 可直接运行主文件:ObjectDetection_1_25200_n.java 或者 ObjectDetection_n_7.java 都可以直接运行两个可以运行的主文件是为了支持不用网络结构的模型,即使是onnx模型,输出的结果参数也不一样,支持以下两种…...
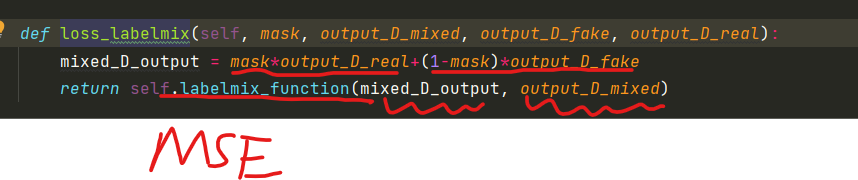
DP-GAN损失
在前面我们看了生成器和判别器的组成。 生成器损失公式: 首先将fake image 和真实的 image输入到判别器中: 接着看第一个损失:参数分别为fake image经过判别器的输出mask,和真实的label进行损失计算。对应于: 其中l…...

自监督去噪:Noise2Void原理和调用(Tensorflow)
文章原文: https://arxiv.org/abs/1811.10980 N2V源代码: https://github.com/juglab/n2v 参考博客: https://zhuanlan.zhihu.com/p/445840211https://zhuanlan.zhihu.com/p/133961768https://zhuanlan.zhihu.com/p/563746026 文章目录 1. 方法原理1.1 Noise2Noise回…...
Mac 安装配置adb命令环境(详细步骤)
一、注意:前提要安装java环境。 因为android sdk里边开发的一些包都是依赖java语言的,所以,首先要确保已经配置了java环境。 二、在Mac下配置android adb命令环境,配置方式如下: 1、下载并安装IDE (andr…...
 GDALRasterBand篇 代码示例 翻译 自学)
GDAL C++ API 学习之路 (2) GDALRasterBand篇 代码示例 翻译 自学
GDALRasterBand Class <gdal_priv.h> GDALRasterBand是GDAL中用于表示栅格数据集中一个波段的类。栅格数据集通常由多个波段组成,每个波段包含了特定的数据信息,例如高程、红、绿、蓝色等, 用于表示影像的不同特征。提供了许…...

springboot对静态资源的支持
1、spring boot默认静态路径支持 Spring Boot 默认将 / 所有访问映射到以下目录:** classpath:/static classpath:/public classpath:/resources classpath:/META-INF/resources也就是说什么也不用配置,通过浏览器可以直接访问这几个目录下的文件。 1…...

WPF实战学习笔记27-全局通知
新建消息事件 添加文件:Mytodo.Common.Events.MessageModel.cs using Prism.Events; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Diagnostics;namespace Mytod…...

openSUSE安装虚拟化 qemu kvm
1) 第一种:图形界面yast安装虚拟化 左下角开始菜单搜索yast 点一下就能安装,是不是很简单呢 2)第二种: 命令行安装 网上关于openSUSE安装qemu kvm的教程比较少,可以搜索centos7 安装qemu kvm的教程,然后…...
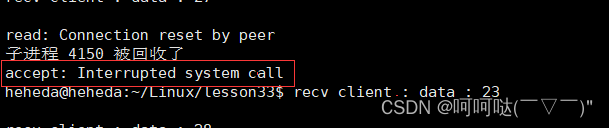
基于linux下的高并发服务器开发(第四章)- 多进程实现并发服务器(回射服务器)
1. socket // 套接字通信分两部分: - 服务器端:被动接受连接,一般不会主动发起连接 - 客户端:主动向服务器发起连接 2.字节序转换函数 当格式化的数据在两台使用不同字节序的主机之间直接传递时,接收端必然错误…...

【程序分析】符号执行
符号执行入门 参考:https://zhuanlan.zhihu.com/p/26927127 给定一个结果,求解对应的程序输入。 经典符号执行与动态符号执行 参考:https://p1kk.github.io/2021/04/04/others/%E7%AC%A6%E5%8F%B7%E6%89%A7%E8%A1%8C&%E6%B1%A1%E7%82…...

实验笔记之——Windows下的Android环境开发搭建
好久一段时间没有进行Android开发了,最新在用的电脑也没有了Android studio了。为此,本博文记录一下最近重新搭建Android开发的过程。本博文仅为本人学习记录用(**别看) 之前博客也对配置Android做过记录 Android学习笔记之——A…...

实用购机指南:屏幕出色、流畅耐用续航拉满的手机
一、前言2026 年上半年,智能手机市场迎来新一轮旗舰迭代,用户购机核心需求已从单一参数比拼,转向流畅不卡顿、性能强劲、屏幕护眼优质、续航持久耐用的全能体验,同时兼顾影像创作与美学设计。为帮消费者精准筛选高适配机型&#x…...

DDD 中的代码组织:按技术层分 vs 按领域模块分,哪种才是正解?
前言 在实践领域驱动设计(DDD)时,你可能见过两种截然不同的代码组织方式:一种是传统的按技术层划分文件夹,另一种是按业务模块划分文件夹。两种写法的人都声称自己在做 DDD,那到底哪种更合理?本…...

我的日常开发工具迭代|MonkeyCode实测存档
做开发日常,其实大部分编码需求都很琐碎,根本用不上繁杂的专业工具。但市面上的AI编程软件,要么收费贵、额度抠搜,要么功能臃肿、操作繁琐,用起来处处受限。我一直在找一款适配个人日常使用、不折腾、无套路的轻量化编…...
)
Win11系统下,Java开发环境配置保姆级教程(JDK 8u201安装+环境变量避坑指南)
Win11系统Java开发环境配置全攻略:从零开始避坑指南 刚接触Java编程的新手们,面对陌生的开发环境配置往往感到无从下手。特别是对于非计算机专业背景的学习者来说,那些晦涩的术语和复杂的系统设置就像一堵高墙,让人望而生畏。本文…...

别只懂SARA归档删除!SAP数据生命周期管理实战:归档、查询与长期保留指南
SAP数据生命周期管理实战:从归档策略到长期可查询架构 在数字化转型浪潮中,企业数据量呈现指数级增长。某跨国制造企业的SAP系统仅物料凭证表每年就新增超过200万条记录,导致月结操作耗时从2小时延长至8小时。这不仅是存储空间的问题——系统…...

AI Agent落地元年:从对话交互到自主工作流的技术演进与落地实践
2026年被行业公认为AI Agent落地元年,生成式AI彻底告别单纯的参数内卷与对话式交互,进入自主决策、自动执行、闭环迭代的全新阶段。相较于传统大模型被动响应的工作模式,AI Agent凭借感知、规划、执行、复盘的完整闭环能力,成为企…...
超详细全解:从诞生背景到工作原理)
【Linux驱动开发】第11天:设备树(Device Tree)超详细全解:从诞生背景到工作原理
一、设备树的诞生背景:传统驱动的致命痛点 在设备树出现之前(Linux 3.0之前),Linux内核采用硬编码的方式描述所有硬件信息。这意味着: 每一个开发板的寄存器地址、中断号、GPIO号,都直接写死在驱动代码里换…...
)
名胜古迹旅游网站的设计与实现(10076)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

GNSS信号丢了也不怕:这款组合导航系统真硬核
在无人系统快速发展的今天,精准可靠的定位导航已成为各类智能装备的核心刚需。然而,传统高精度组合导航系统往往价格昂贵,让许多项目团队望而却步。ER-GNSS/MINS-03为了打破这一僵局——将战术级MEMS惯性器件与全系统全频点双天线GNSS模块深度…...

RK3588 Android系统签名实战:为APK获取系统权限完整指南
1. 项目概述与核心价值在嵌入式Android开发领域,尤其是基于瑞芯微(Rockchip)平台如RK3588进行产品研发时,我们常常会遇到一个核心需求:如何让一个普通的第三方APK应用,获得系统级(System&#x…...