具有非线性动态行为的多车辆列队行驶问题的基于强化学习的方法
论文地址:
Reinforcement Learning Based Approach for Multi-Vehicle Platooning Problem with Nonlinear Dynamic Behavior
摘要
协同智能交通系统领域的最新研究方向之一是车辆编队。研究人员专注于通过传统控制策略以及最先进的深度强化学习 (RL) 方法解决自动驾驶车辆控制的各种方法。在这项研究中,除了提出基于 RL 的最优间隙控制器之外,还重新引入了详细的非线性动力车辆模型,这通过具有深度确定性策略梯度算法的 actor critic 策略进行了证明。生成的智能体针对可变速度和可变间隙侵略性场景进行模拟,并与模型预测控制 (MPC) 性能进行比较。结果表明,准确性和学习时间之间存在权衡。但是,两个控制器都具有接近最佳的性能。
前言
存在的问题
从上述文献来看,在利用 RL 作为队列中动态车辆模型的控制器方面存在研究空白。一些研究人员使用传统控制器来解决队列问题。
此外,[12] 提到了各种应用基于深度 RL 的控制器的研究,这些研究仅考虑点质量运动学模型,而没有加速延迟动力学的影响。
其他研究人员专注于在单个车辆或跟车问题上使用基于 RL 的控制器,而没有考虑相对距离控制。如以下各节所述,本研究填补了上述研究空白。
问题描述
车辆动力学模型
在这项研究中,所考虑的队列配置由异构车辆组成,即车辆的质量、长度或最重要的是车辆的阻力系数可能不同。
此外,该队列有四辆车、一辆领队和任意数量的随车,其中领队位于第一个位置。描述运动曲线的领导者状态是 x0˙\dot{x_0}x0˙ 和x0¨\ddot{x_0}x0¨,分别代表领导者的速度和加速度。此外,两辆车之间的距离 dg(i)d^{(i)}_ gdg(i)是本车在位置 iii 的前保险杠与前车在位置 i−1i − 1i−1 的后保险杠之间的距离。
此外,假定领导者遵循仅为其预定义的速度轨迹。其他车辆的目标是跟随前面车辆的轨迹,同时保持定义的相对距离dg(i)d^{(i)}_ gdg(i) 。因此,假设存在完美的车对车 (V2V) 通信,即所有车辆都可以观察到前车的状态,并且第iii辆车的位置 x(i)x(i)x(i) 是从车辆的质心测量的。对于本节的其余部分,将对用于表示车辆行为的模型进行进一步调查。
然而,阻力进一步研究。由于这项研究的目的是调查队列中的行为,因此更现实的做法是考虑由于队列配置而减少作用在自我车辆上的阻力的影响。在上述原因下,单个队列成员的动力学由方程式 1 建模。
x¨=Tt−Tbr−(Fd+Fr+Fg)⋅Rm⋅R+IwR\begin{equation} \begin{aligned} \ddot{x}=\frac{T_t-T_{br}-(F_d+F_r+F_g) \cdot R}{m\cdot R+\frac{I_w}{R}} \end{aligned} \end{equation} x¨=m⋅R+RIwTt−Tbr−(Fd+Fr+Fg)⋅R
其中 TtT_tTt 是由发动机产生并导致车辆向前运动的牵引扭矩,TbrT_brTbr 是由制动系统产生的用于控制车辆减速的扭矩,FdF_dFd、FrF_rFr 和 FgF_gFg 是阻力、滚动阻力和重力。阻力乘以减阻比,该减阻比模拟前车对本车阻力的影响,如 [15] 中所示。最后,m、R和Iwm、R 和 I_wm、R和Iw 分别是车辆质量、车轮半径和车轮转动惯量。
状态空间模型
控制器智能体只观察两辆连续车辆之间的差距、速度和加速度的误差。对于领导者,设计了一个单独的速度控制器智能体来维持设定的速度 x˙ref(0)\dot{x}^{(0)}_{ref}x˙ref(0) 。队列中所有车辆的车辆模型与第 3 节中导出的相同。此外,控制器用于控制队列的车辆间距。
说明拓扑是TPF双前车跟随式。
奖励设置
领航车的奖励
Rl,t=−(ut−12+0.05u˙t−12+0.1evl,t2)+Ql,t\begin{equation} R_{l,t}=-(u_{t-1}^2+0.05\dot{u}_{t-1}^2+0.1e_{vl,t}^2)+Q_{l,t} \end{equation} Rl,t=−(ut−12+0.05u˙t−12+0.1evl,t2)+Ql,t
其中$ u_{t−1}$ 是前一时刻的控制力(加速度)ut−1˙\dot{ u_{t−1}}ut−1˙是前一时刻的控制力(加速度)的导数。evl,te_{vl,t}evl,t是设定参考速度与当前领导者速度 vref−x0˙v_{ref} − \dot{x_0}vref−x0˙ 之间的速度误差,Ql,tQ_{l,t}Ql,t是基于逻辑方程的正奖励:
Ql,t=∣evl,t∣≤ϑv∧t≥τQ_{l,t}=\left|e_{vl,t}\right|\leq\vartheta_v\wedge t\geq\tau Ql,t=∣evl,t∣≤ϑv∧t≥τ
其中ϑv\vartheta_vϑv是可接受的速度误差容差的阈值,τ\tauτ是奖励存在的阈值时间。
奖励负数部分的平方是为了说明所描述术语中的正值或负值。第一项说明加速度的最小化,而第二项说明加速度的变化。因此,最大限度地减少控制工作中的抖动并确保信号的平滑度。第三项消除了速度误差以实现控制器的预期行为。 Q 部分是在设定点周围给予智能体正奖励,以抑制控制超调,而不是将控制器收紧到严格的值。延迟条件对于确保控制器仅在实际处于正确速度时才收到正奖励非常重要,并防止因初始领导者速度与设定速度接近零误差而产生的任何假正奖励。
跟随车辆的奖励
Rf,t=−(ut−12+0.05u˙t−12+(1vmaxevf,t)2+(1dgmaxeg,t)2)+Qf,tR_{f,t}=-\left(u_{t-1}^2+0.05\dot{u}_{t-1}^2+\left(\dfrac{1}{v_{max}}e_{vf,t}\right)^2+\left(\dfrac{1}{d_{gmax}}e_{g,t}\right)^2\right)+Q_{f,t} Rf,t=−(ut−12+0.05u˙t−12+(vmax1evf,t)2+(dgmax1eg,t)2)+Qf,t
它具有与等式(2)中相同的控制努力参数。然而,evf,te_{vf,t}evf,t是当前速度与前车速度之间的速度误差 vi−vi−1v_i − v_{i−1}vi−vi−1,而 $e_{g,t} $是间隙误差 gapdesired−dgi{gap}_{desired}−d^i_ggapdesired−dgi,Qf,tQ_{f,t}Qf,t是正奖励基于逻辑等式:
Qf,t=∣ev,t∣≤ϑv∧∣eg,t∣≤ϑg∧t≥τQ_{f,t}=|e_{v,t}|\leq\vartheta_v\wedge|e_{g,t}|\leq\vartheta_g\wedge t\geq\tau Qf,t=∣ev,t∣≤ϑv∧∣eg,t∣≤ϑg∧t≥τ
等式 (222) 和 (3) 中的项的相同原因用于等式 (4) 和 (5) 中,增加了间隙项中的误差以消除实现所需控制器的误差。等式 (4) 中速度和间隙误差的增益用于对值进行归一化。因此,智能体可以比非标准化函数更容易满足多目标奖励函数。
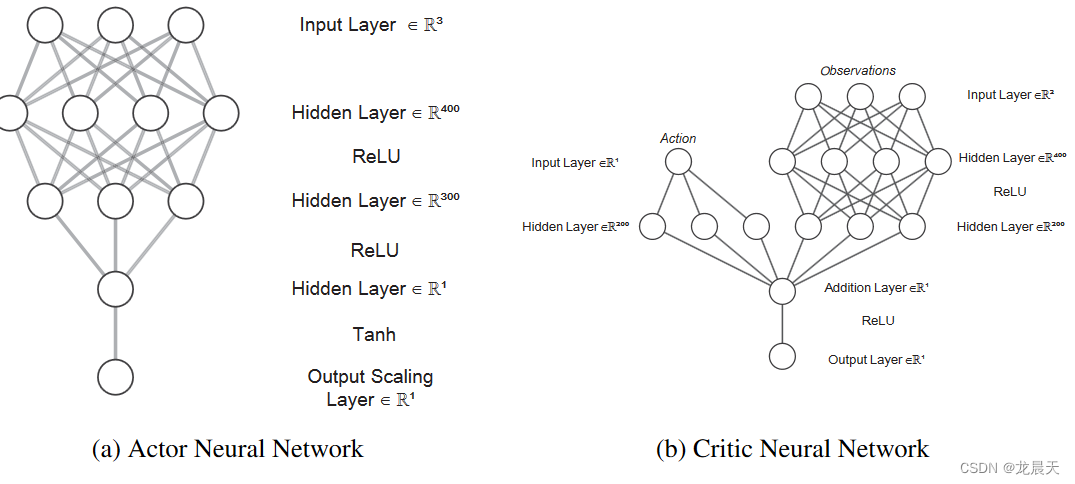
网络结构
演员网络具有三个完全连接的隐藏层,分别具有 400、300 和一个神经元,而对于评论家网络,动作路径具有一个具有 300 个神经元的隐藏层。状态路径有两个隐藏层,分别有 400、300 个神经元。两条路径都通过加法层合并到输出层。 RL 模型以 0.1 秒的采样时间运行,奖励折扣因子为 0.99,噪声模型方差为 0.6。对于训练过程,小批量大小为 128,而演员和评论家网络的学习率分别为 10−4 和 10−3。
实验结果
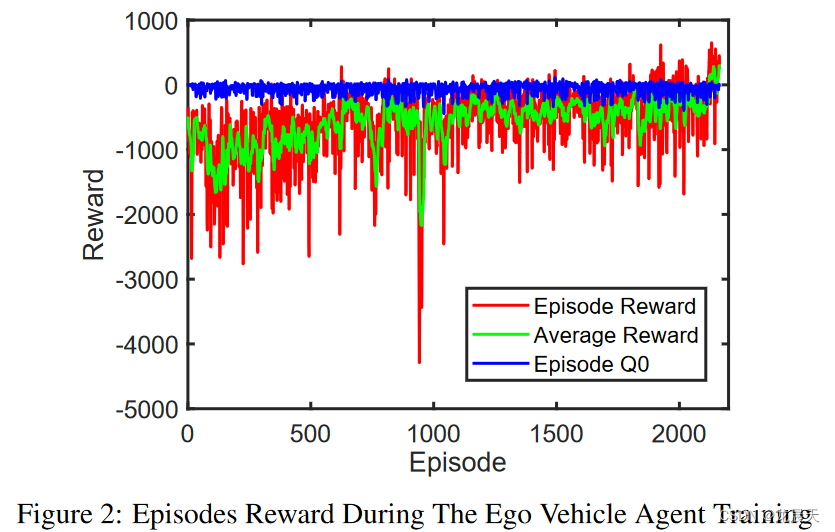
自我车辆控制器的训练进行了 2163 集,总步数为 973,186,持续了大约 9.5 小时。如图 2 所示,基于公式 4 的最终平均奖励为 326.8。车辆速度和位置的初始条件在每一集开始前随机更改,以确保智能体在任何给定的现实场景中的可靠性并防止模型对某些场景的过度拟合。因此,每一集都有不同的初始间隙误差和不同的初始速度误差。
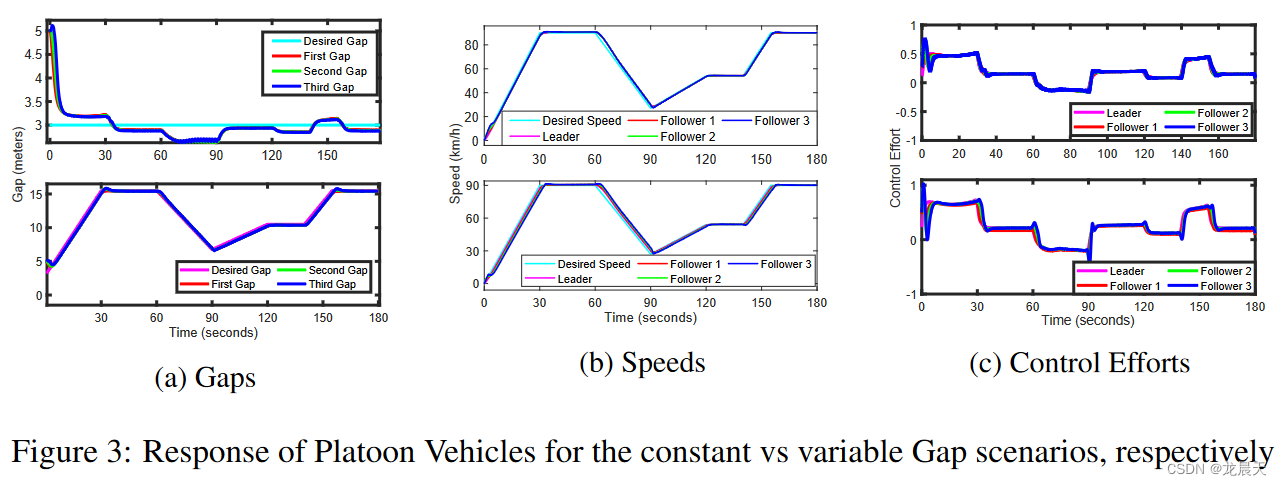
关于恒定距离间隙场景,智能体以可接受的误差容限 (∼∣eg,t∣≤0.3∼ |e_{g,t}| ≤ 0.3∼∣eg,t∣≤0.3) 实现了所需的间隙,这满足了等式 5 中的奖励函数。稳定时间非常接近 MPC 的响应,即[13] 中三个控制器中最快的一个。整体响应类似于 MPC,如图 5 所示,这是有道理的,可以从 RL 和 MPC 都试图解决优化问题以分别找到最优策略 π* 或控制律 u* 的事实中推导出来.此外,据观察,对于预定义的速度轨迹,控制工作是平稳且现实的。间隙控制器已证明能够在目标奖励函数中指定的公差范围内以令人满意的方式处理简单和激进的场景。
可变间隙参考轨迹是根据速度轨迹设计的,其中所需间隙等于 3 米的安全距离加上一个定时间隙,其幅度为速度的一半(以米/秒为单位)。此外,智能体的响应以令人满意的方式对具有平滑速度轨迹的间隙变化做出快速反应,如图 3b 所示。必须指出的是,在间隙变化的部分,跟随器的速度相对于参考速度存在恒定的偏移,从而导致间隙的增加或减小。
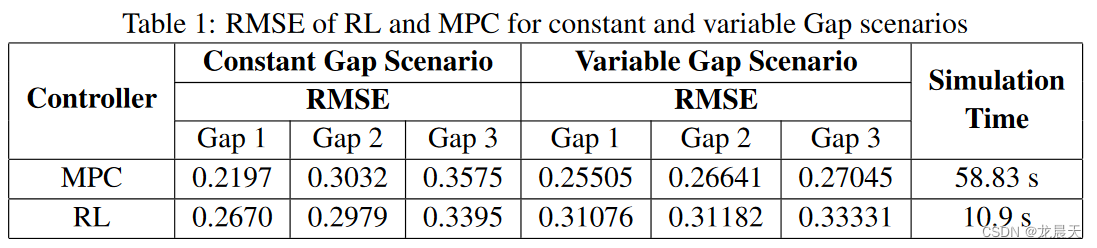
如表 1 所示,RL 智能体为之前在 [13] 中讨论的控制器提供了类似的均方根误差 (RMSE)。然而,就计算时间而言,RL 智能体的模拟速度明显快于之前提出的最优控制 MPC。以这种方式,RL 智能体在建议的最优控制器之间展示了准确性和计算时间之间的良好平衡。
可以进行进一步的分析以研究 RL 和 MPC 控制器之间的性能差异。应该指出的是,比较中没有使用先前在 [13] 中使用的相同参数。或者,对 R 和 Q(分别为控制输入和状态的权重矩阵)进行参数研究。之后,选择 R 和 Q 矩阵的最佳组合,使其实现三个间隙的最小累积 RMSE。研究结果见图 4。
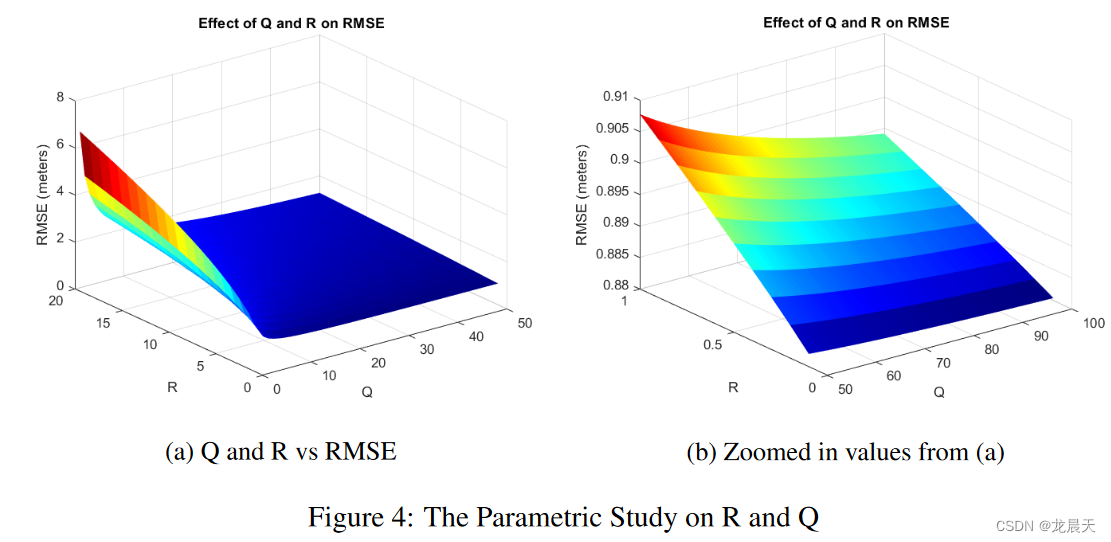
图 5b 还展示了可变间隙场景中 MPC 的间隙、速度和控制力。考虑到图 3 中 RL 智能体的响应,可以得出结论,两个控制器都以令人满意的方式满足给定的间隙和速度曲线,几乎没有显着差异。另一方面,RL 智能体通过实现更平滑的轨迹来保持其在控制工作中的主导地位。

结论
本研究解决了管理一队列异构车辆中的车辆间距的问题,其中在现有的详细非线性纵向动力学模型上开发了一个更成熟的模型,可以分别减少每辆车的空气阻力。 RL 被用作为领导者和跟随者车辆设计控制器的工具。提出了一种具有多目标奖励函数的间隙和速度控制器。该智能体基于 DDPG 算法与参与者和评论家网络进行训练。从仿真获得的结果来看,强化学习智能体在奖励函数、控制力度和速度轨迹跟踪方面表现令人满意。优化控制器的分析证实,RL 控制器在计算时间和控制工作量方面优于 MPC,特别是在更现实和复杂的场景中,同时在车辆间距中保持相似的 RMSE。
此外,建议继续在调整参数上训练模型,以获得关于可调整奖励函数的最佳性能。此外,可以延续 RL 控制器训练以满足其他目标,而不会与当前目标相抵触。硬件在环模拟器可以在广泛而逼真的模拟中使用控制器,以研究车辆在其他场景和环境下的行为。
相关文章:
具有非线性动态行为的多车辆列队行驶问题的基于强化学习的方法
论文地址: Reinforcement Learning Based Approach for Multi-Vehicle Platooning Problem with Nonlinear Dynamic Behavior 摘要 协同智能交通系统领域的最新研究方向之一是车辆编队。研究人员专注于通过传统控制策略以及最先进的深度强化学习 (RL) 方法解决自动…...
TrueNas篇-硬盘直通
硬盘直通 在做硬盘直通之前,在trueNas(或者其他虚拟机)内是检测不到安装的硬盘的。 在pve节点查看硬盘信息 打开pve的shell控制台 输入下面的命令查看硬盘信息: ls -l /dev/disk/by-id/该命令会显示出实际所有的硬盘设备信息,其中ata代…...

手机子品牌的“性能战事”:一场殊途同归的大混战
在智能手机行业进入存量市场后,竞争更加白热化。当各国产手机品牌集体冲高端,旗下子品牌们也正厮杀正酣,显现出刀光剑影。处理器、屏幕、内存、价格等各方面无不互相对标,激烈程度并不亚于高端之争。源于OPPO的中端手机品牌realme…...
dockerfile自定义镜像安装jdk8,nginx,后端jar包和前端静态文件,并启动容器访问
dockerfile自定义镜像安装jdk8,nginx,后端jar包和前端静态文件,并启动容器访问简介centos7系统里面我准备的服务如下:5gsignplay-web静态文件内容如下:nginx.conf配置文件内容如下:Dockerfile内容如下:run.sh启动脚本内容如下:制作镜像并启动访问简介 通过用docker…...
MongoDB 全文检索
MongoDB 全文检索 全文检索对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。 这个过程类似于通过字典中的检索字表查字的过…...

JS中声明变量,使用 var、let、const的区别
一、var 的使用 1.1、var 的作用域 1、var可以在全局范围声明或函数/局部范围内声明。当在最外层函数的外部声明var变量时,作用域是全局的。这意味着在最外层函数的外部用var声明的任何变量都可以在windows中使用。 2、当在函数中声明var时,作用域是局…...

汽车改装避坑指南:大尾翼
今天给大家讲一个改装的误区:大尾翼 很多车友看到一些汽车加了大尾翼,非常的好看,就想给自己的车也加装一个。 那你有没有想过,尾翼这东西你真的需要吗? 赛车为什么加尾翼?尾翼主要是给车尾部的一个压低提供…...

【Unity资源下载】POLYGON Dungeon Realms - Low Poly 3D Art by Synty
$149.99 Synty Studios 一个史诗般的低多边形资产包,包括人物、道具、武器和环境资产,用于创建一个以奇幻为主题的多边形风格游戏。 模块化的部分很容易在各种组合中拼凑起来。 包包含超过1,118个详细预制件。 主要特点 ◼ ◼ 完全模块化的地下城!包…...

知识汇总:Python办公自动化应该学习哪些内容
当前python自动化越来越受到欢迎,python一度成为了加班族的福音。还有大部分人想利用python自动化来简化工作,不知道从何处下手,所以,这里整理了一下python自动化过程中的各种办公场景以及需要用到的python知识点。 Excel办公自动…...

软件架构知识5-架构设计流程
一、识别复杂度 举例:设计一个亿级用户平台设计,直接对标腾讯的 QQ,按照腾讯 QQ的用户量级和功能复杂度进行设计,高性能、高可用、可扩展、安全等技术一应俱全,一开始就设计出了 40 多个子系统,然后投入大…...
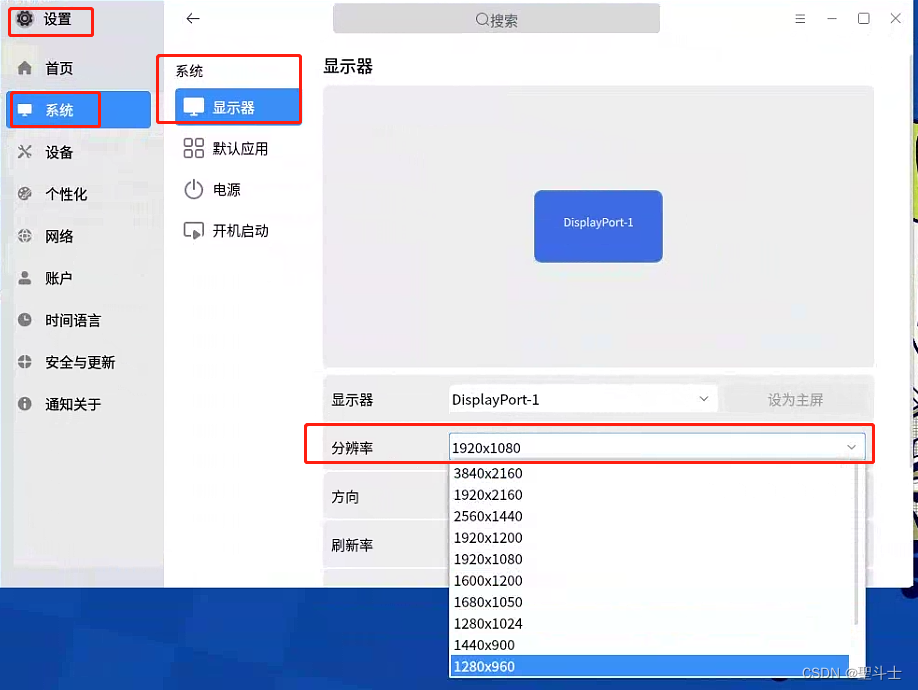
【银河麒麟V10操作系统】修改屏幕分辨率的方法
文章目录前言系统概述方法1:使用命令行修改方法2:写文件修改方法3:界面端修改的方法前言 本文记录了银河麒麟V10系统修改分辨率的方法。 使用命令行修改写文件修改界面端修改的方法 系统概述 方法1:使用命令行修改 打开终端&am…...
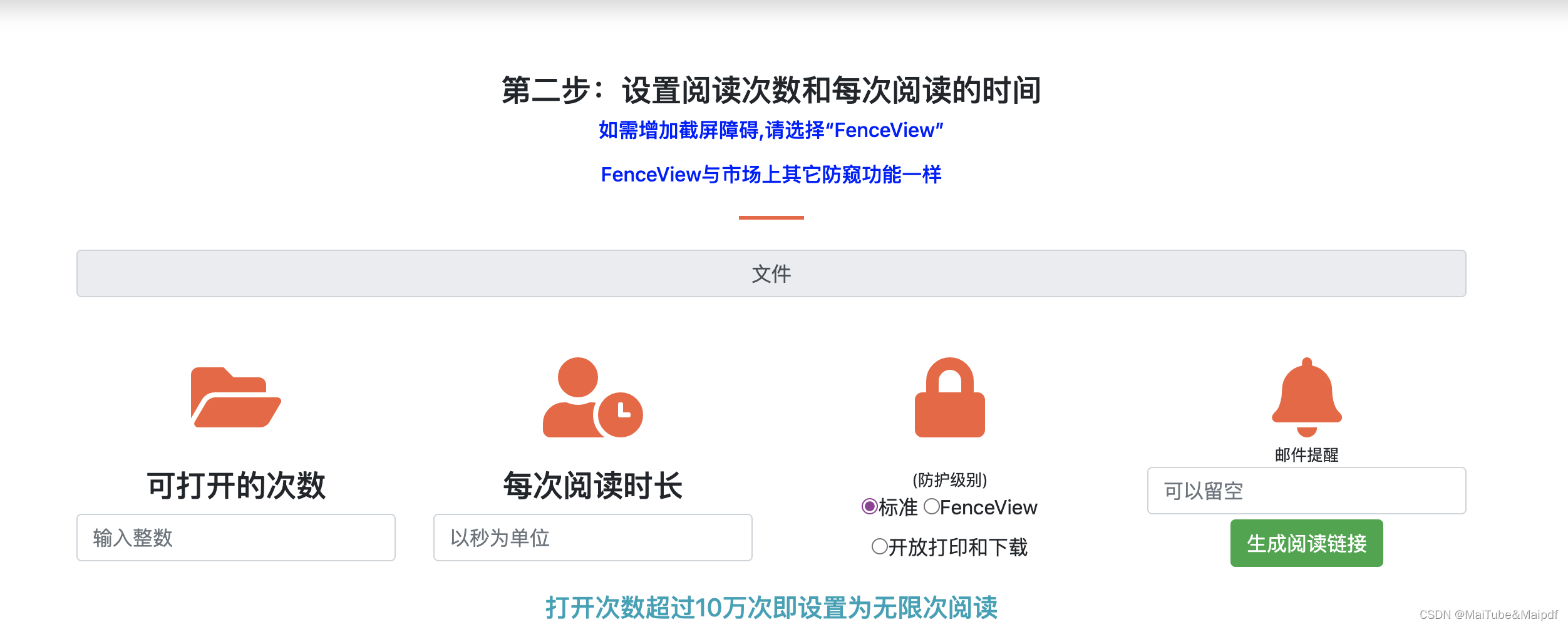
pdf生成为二维码
当今数字时代,人们越来越依赖在线工具来处理各种任务,比如合并、拆分和压缩PDF等。Mai File就是这样一个在线工具,它可以将PDF文件转换成在线链接,方便您和他人轻松地查看和共享文件。 Mai File的使用非常简单,您只需…...

Yaklang websocket劫持教程
背景 随着Web应用的发展与动态网页的普及,越来越多的场景需要数据动态刷新功能。在早期时,我们通常使用轮询的方式(即客户端每隔一段时间询问一次服务器)来实现,但是这种实现方式缺点很明显: 大量请求实际上是无效的,这导致了大量…...

基于AIOT技术的智慧校园空调集中管控系统设计与实现
毕业论文(设计)题 目 基于AIOT技术的智慧校园空调集中管控系统设计与实现指导老师 XXXX 专业班级 电子商务2XXXX 姓 名 XXXX 学 号 20XXXXXXXXX 20XX年XX月XX日摘要近年来,随着物联网技术和人工智能技术的快速发展,智慧校园逐渐…...

【每日一题】 将一句话单词倒置,标点不倒置
用C语言将一句话的单词倒置,标点不倒置。 比如输入: i like shanghai. 输出得到: shanghai. like i 这道题目有很多种做法,既可以用递归,也可以分成两部分函数来写,本文就详细来讲解分装为两个函数的做法。…...

宽刈幅干涉雷达高度计SWOT(Surface Water and Ocean Topography)卫星进展(待完善)
> 以下信息搬运自SWOT官方网站等部分文献资料,如有侵权请联系:sunmingzhismz163.com > 排版、参考文献、部分章节待完善 > 2023.02.17.22:00 初稿概况 2022年12月16日地表水与海洋地形卫星SWOT (Surface Water and Ocean Topography)在加利福尼…...

openjdk源码==类加载过程
jdk\src\share\bin\main.c main JLI_Launch jdk\src\share\bin\java.c JLI_Launch jdk\src\solaris\bin\java_md_solinux.c JVMInit ContinueInNewThread JavaMain InitializeJVM jdk\src\share\bin\java.h CreateJavaVM 调用JNI hotspot\src\share\vm\prims\j…...

vue2的后台管理系统 迁移到 vue3后台管理系统
重构的流程1.新建项目,确定脚手架版本2.项目整体迁移3.重构路由,axios,element-plus等项目所需要的依赖4.迁移组件内容(需要的配置项移步到5目录and6目录)4-1.Login页面4-2. Home页4-3.Students管理内部的页面4-3-1.studentList(学生列表)4-3-2.InfoList(信息列表)4-3-3.InfoLi…...

2023年美赛F题
关键点1.绿色GDP(GGDP)是否比传统GDP更好好的衡量标准?2.如果GGDP成为经济健康的主要量标准,可能会对环境产生什么影响?3建立一个简单的模型,估计GGDP取代GDP作为经济健康的主要衡量标准,对减缓气候变化产生的影响。4.GGDP取代GDP可能会遇到…...

【数据结构与算法分析】介绍蛮力法以及相关程序案例
文章目录蛮力法之排序选择排序冒泡排序实际应用蛮力法之最近对和凸包问题最近对问题凸包问题蛮力法(brute force),其本质跟咱常说的暴力法是一样的,都是一种简单直接地解决问题的方法,通常直接基于问题的描述和所涉及的概念定义进行求解。 蛮…...

face-recognition.js 模型训练与保存:构建可复用的人脸识别系统
face-recognition.js 模型训练与保存:构建可复用的人脸识别系统 【免费下载链接】face-recognition.js Simple Node.js package for robust face detection and face recognition. JavaScript and TypeScript API. 项目地址: https://gitcode.com/gh_mirrors/fa/f…...

BepInEx IL2CPP启动失败终极解决指南:从异常诊断到游戏正常运行
BepInEx IL2CPP启动失败终极解决指南:从异常诊断到游戏正常运行 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity游戏插件框架,为玩家和开发…...

Claude代码自动模式:跳过权限的更安全方式 Claude Code auto mode: a safer way to skip permissions —— Anthropic
Claude Code auto mode: a safer way to skip permissions Claude代码自动模式:跳过权限的更安全方式 https://www.anthropic.com/engineering/claude-code-auto-mode Claude Code users approve 93% of permission prompts. We built classifiers to automate so…...

基于PSCAD的光伏-火电打捆直流送出系统建模与扰动特性仿真研究
基于PSCAD的光伏-火电打捆直流送出系统建模与扰动特性仿真研究 摘要 随着我国“双碳”目标的深入推进,以光伏为代表的新能源发电装机规模持续快速增长。然而,光伏发电具有间歇性和波动性特征,大规模并网对电力系统的安全稳定运行提出了严峻挑战。将光伏与火电打捆经高压直…...

从AMD Ryzen数据误读看硬件市场分析:如何辨别数据信号与噪声
1. 从一则旧闻谈起:数据解读的陷阱与行业洞察2017年7月,一则关于AMD Ryzen处理器市场份额的新闻在科技圈引发了不小的讨论。当时,多家媒体援引第三方基准测试软件Passmark的数据,宣称AMD凭借新发布的Ryzen架构,正在从英…...

如何用SketchUp STL插件轻松实现3D打印:从设计到实物的完整指南
如何用SketchUp STL插件轻松实现3D打印:从设计到实物的完整指南 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 你…...

Python: Condition Variable Pattern
项目结构: # encoding: utf-8 # 版权所有 2026 ©涂聚文有限公司™ # 许可信息查看:言語成了邀功盡責的功臣,還需要行爲每日來值班嗎 # 描述:Condition Variable Pattern 条件变量模式 # Author : geovindu,Geovin Du …...

GitHub Actions 工作流中的输出处理
在现代软件开发中,CI/CD(持续集成和持续交付)是确保代码质量和自动化部署的关键环节。GitHub Actions 作为 GitHub 提供的 CI/CD 工具,支持通过工作流文件定义自动化任务。本文将结合一个实际的 GitHub Actions 工作流实例,探讨如何处理 Python 脚本的输出,并根据该输出决…...

基于RAG的AI知识库构建:从原理到工程实践
1. 项目概述:一个面向AI的知识库构建方案最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何让大语言模型(LLM)更精准、更可靠地使用你自己的数据?无论是想打造一个能回答公司内部文档问题的智能客…...

手把手教你排查华为MDC-300F与激光雷达的通信故障:从接口定义到信号测量
手把手教你排查华为MDC-300F与激光雷达的通信故障:从接口定义到信号测量 当自动驾驶系统的传感器突然"失声",整个项目进度可能因此停滞。作为硬件工程师,我们常常在深夜的实验室里面对着一堆闪烁的指示灯和沉默的设备——MDC-300F与…...