稍微深度踩坑haystack + whoosh + jieba
说到django的全文检索,网上基本推荐的都是 haystack + whoosh + jieba 的方案。
由于我的需求对搜索时间敏感度较低,但是要求不能有数据的错漏。
但是没有调试的情况下,搜索质量真的很差,搞得我都想直接用Like搜索数据库算了。
但是峰回路转,还是让我找到几个信息,稍微优化了一下搜索结果。
1.haystack
haystack这层我增加了一个模糊搜索,即原本的text='q’变成了text__contains=‘q’。
搜索从原本的的content切换成了contains,不再需要完全匹配就能命中。
比如词“下雨”在用content的时候搜“雨”是没办法命中的,换成contain之后就可以了。(需要搭配第二点中的自定义全量分词,默认分词不行。具体原因不知,不过应该不是index的问题,因为我测试过用默认分词rebuild_index后,再切换ChineseAnalyzer而不重新rebuild_index依然可以搜索到结果,猜测原因应该是对搜索词的分词,但是我就一个字有啥好分词的?有懂得大佬麻烦教我一下。)
class LynSearchForm(SearchForm):def search(self):if not self.is_valid():return self.no_query_found()if not self.cleaned_data.get("q"):return self.no_query_found()# 原设置搜索条件的语句,被我替换成下面的语句# sqs = self.searchqueryset.auto_query(self.cleaned_data["q"]) sqs = self.searchqueryset.filter(text__contains=self.cleaned_data["q"])if self.load_all:sqs = sqs.load_all()return sqs
我写这篇文章的时间是2023年8月,haystack已经进行了大的更新。从原本的views.SearchView 切换到了 generic_views.SearchView。把接口都给换了,然后代码里面还是旧的内容,各位看官看的时候要注意。
新流程以SearchView为例:
form = self.get_form(form_class)
self.queryset = form.search()
context = self.get_context_data({self.form_name: form})
get_context_data是django的view的函数,所以我们要做的是在form上面做手脚。
2.whoosh + jieba
除了上面的操作外,还需要对jieba的ChineseAnalyzer进行自定义,修改成全量分词。
代码来源 州的先生 大佬写的MrDoc我从中受益良多,大家有兴趣可以多多支持
# coding:utf-8
# @文件: chinese_analyzer.py
# @创建者:州的先生
# #日期:2020/11/22
# 博客地址:zmister.comfrom whoosh.compat import u, text_type
from whoosh.analysis.filters import LowercaseFilter
from whoosh.analysis.filters import StopFilter, STOP_WORDS
from whoosh.analysis.morph import StemFilter
from whoosh.analysis.tokenizers import default_pattern
from whoosh.lang.porter import stem
from whoosh.analysis import Tokenizer, Token
from whoosh.util.text import rcompile
import jiebaclass ChineseTokenizer(Tokenizer):"""使用正则表达式从文本中提取 token 令牌。>>> rex = ChineseTokenizer()>>> [token.text for token in rex(u("hi there 3.141 big-time under_score"))]["hi", "there", "3.141", "big", "time", "under_score"]"""def __init__(self, expression=default_pattern, gaps=False):""":param expression: 一个正则表达式对象或字符串,默认为 rcompile(r"\w+(\.?\w+)*")。表达式的每一个匹配都等于一个 token 令牌。第0组匹配(整个匹配文本)用作 token 令牌的文本。如果你需要更复杂的正则表达式匹配处理,只需要编写自己的 tokenizer 令牌解析器即可。:param gaps: 如果为 True, tokenizer 令牌解析器会在正则表达式上进行分割,而非匹配。"""self.expression = rcompile(expression)self.gaps = gapsdef __eq__(self, other):if self.__class__ is other.__class__:if self.expression.pattern == other.expression.pattern:return Truereturn Falsedef __call__(self, value, positions=False, chars=False, keeporiginal=False,removestops=True, start_pos=0, start_char=0, tokenize=True,mode='', **kwargs):""":param value: 进行令牌解析的 Unicode 字符串。:param positions: 是否在 token 令牌中记录 token 令牌位置。:param chars: 是否在 token 中记录字符偏移。:param start_pos: 第一个 token 的位置。例如,如果设置 start_pos=2, 那么 token 的位置将是 2,3,4,...而非 0,1,2,...:param start_char: 第一个 token 中第一个字符的偏移量。例如, 如果设置 start_char=2, 那么文本 "aaa bbb" 解析的两个字符串位置将体现为 (2,5),(6,9) 而非 (0,3),(4,7).:param tokenize: 如果为 True, 文本应该被令牌解析。"""# 判断传入的文本是否为字符串,如果不为字符串则抛出assert isinstance(value, text_type), "%s is not unicode" % repr(value)t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs)if not tokenize:t.original = t.text = valuet.boost = 1.0if positions:t.pos = start_posif chars:t.startchar = start_chart.endchar = start_char + len(value)yield telif not self.gaps:# The default: expression matches are used as tokens# 默认情况下,正则表达式的匹配用作 token 令牌# for pos, match in enumerate(self.expression.finditer(value)):# t.text = match.group(0)# t.boost = 1.0# if keeporiginal:# t.original = t.text# t.stopped = False# if positions:# t.pos = start_pos + pos# if chars:# t.startchar = start_char + match.start()# t.endchar = start_char + match.end()# yield tseglist = jieba.cut(value, cut_all=True)for w in seglist:t.original = t.text = wt.boost = 1.0if positions:t.pos = start_pos + value.find(w)if chars:t.startchar = start_char + value.find(w)t.endchar = start_char + value.find(w) + len(w)yield telse:# When gaps=True, iterate through the matches and# yield the text between them.# 当 gaps=True, 遍历匹配项并在它们之间生成文本。prevend = 0pos = start_posfor match in self.expression.finditer(value):start = prevendend = match.start()text = value[start:end]if text:t.text = textt.boost = 1.0if keeporiginal:t.original = t.textt.stopped = Falseif positions:t.pos = pospos += 1if chars:t.startchar = start_char + startt.endchar = start_char + endyield tprevend = match.end()# If the last "gap" was before the end of the text,# yield the last bit of text as a final token.if prevend < len(value):t.text = value[prevend:]t.boost = 1.0if keeporiginal:t.original = t.textt.stopped = Falseif positions:t.pos = posif chars:t.startchar = prevendt.endchar = len(value)yield tdef ChineseAnalyzer(expression=default_pattern, stoplist=None,minsize=2, maxsize=None, gaps=False, stemfn=stem,ignore=None, cachesize=50000):"""Composes a RegexTokenizer with a lower case filter, an optional stopfilter, and a stemming filter.用小写过滤器、可选的停止停用词过滤器和词干过滤器组成生成器。>>> ana = ChineseAnalyzer()>>> [token.text for token in ana("Testing is testing and testing")]["test", "test", "test"]:param expression: 用于提取 token 令牌的正则表达式:param stoplist: 一个停用词列表。 设置为 None 标识禁用停用词过滤功能。:param minsize: 单词最小长度,小于它的单词将被从流中删除。:param maxsize: 单词最大长度,大于它的单词将被从流中删除。:param gaps: 如果为 True, tokenizer 令牌解析器将会分割正则表达式,而非匹配正则表达式:param ignore: 一组忽略的单词。:param cachesize: 缓存词干词的最大数目。 这个数字越大,词干生成的速度就越快,但占用的内存就越多。使用 None 表示无缓存,使用 -1 表示无限缓存。"""ret = ChineseTokenizer(expression=expression, gaps=gaps)chain = ret | LowercaseFilter()if stoplist is not None:chain = chain | StopFilter(stoplist=stoplist, minsize=minsize,maxsize=maxsize)return chain | StemFilter(stemfn=stemfn, ignore=ignore,cachesize=cachesize)
重点是这个:

在PS2里面,结巴的大佬有提到有新功能(11年前的)jieba.cut_for_search()也可以试试
然后在whoosh_cn_backend.py里面修改ChineseAnalyzer。
from .chinese_analyzer import ChineseAnalyzer
# from jieba.analyse import ChineseAnalyzer
PS:这个jieba自带的ChineseAnalyzer也是我换的,如果你第一次搞这个,可以参考
https://blog.csdn.net/qiqiyingse/article/details/110299639
PS
1.HayStack
As of version 2.4 the views in haystack.views.SearchView are
deprecated in favor of the new generic views in
haystack.generic_views.SearchView which use the standard Django
class-based views which are available in every version of Django which
is supported by Haystack.
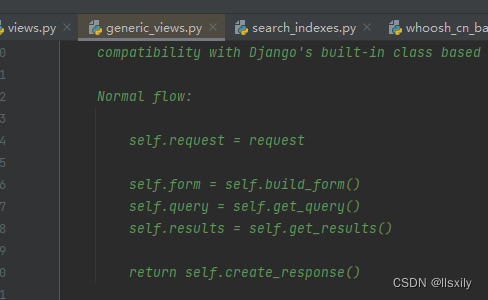
新代码,旧流程,可真有你的。
2.CSDN
稍微吐槽下CSDN,STONE大哥的文章里面,下面结巴的大佬在评论区有回复,结果评论显示的是2条,还好我点开看了一下。不然就错过了这么重要的信息。
https://blog.csdn.net/wenxuansoft/article/details/8169842
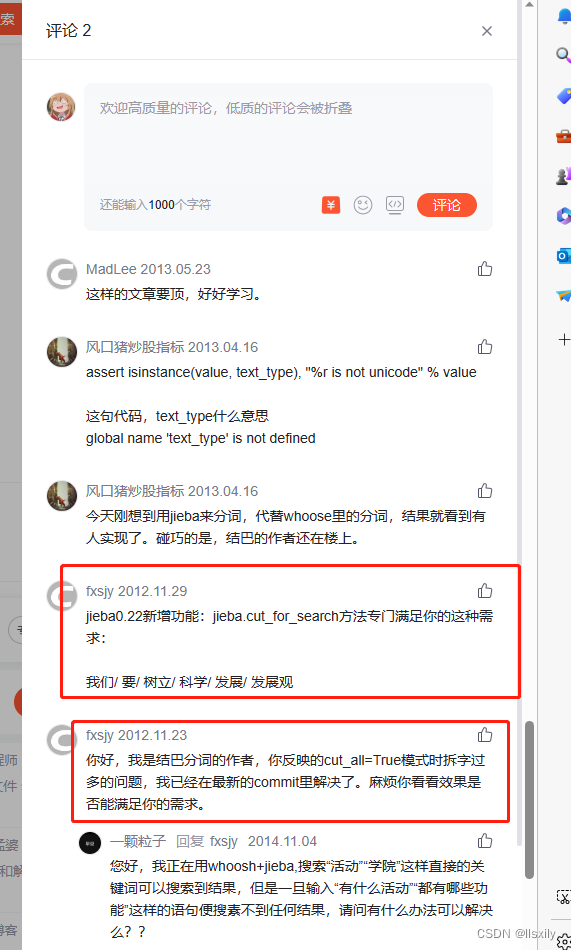
然后显示的热评是个灌水回答。。
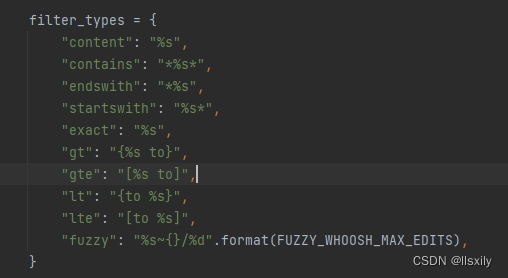
3.其他筛选参数
关于筛选的类型,在whoosh_cn_backend.py文件中,基本和django的差不多。
相关文章:
稍微深度踩坑haystack + whoosh + jieba
说到django的全文检索,网上基本推荐的都是 haystack whoosh jieba 的方案。 由于我的需求对搜索时间敏感度较低,但是要求不能有数据的错漏。 但是没有调试的情况下,搜索质量真的很差,搞得我都想直接用Like搜索数据库算了。 但是…...

微信小程序(van-tabs) 去除横向滚动条样式(附加源码解决方案+报错图)
问题描述 今天第一次接触vant组件库。 ant官网地址适用于Vue3 支持Vue2、Vue3、微信小程序等 我在使用van-tabs组件时遇到了一个问题,如下图所示: 从图片上可以看到有个灰色的横向滚动条,一开始领导给我说这个问题,我反反复复都…...

激光切割机所发出的辐射是否会对人体产生危害呢
激光切割设备所发出的激光作为一种特殊的能量光源,在一定程度上是存在辐射的。由于光纤激光器的功率通常大于半导体激光器,因此其辐射安全性也受到我们的关注。那么这种辐射的危害究竟有多大呢? 第一级:在正常操作下,不会发出对人…...
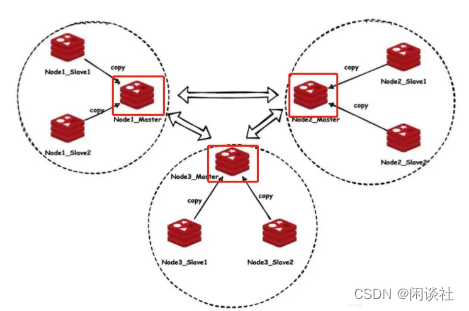
Redis 高可用:主从复制、哨兵模式、集群模式
文章目录 一、redis高可用性概述二、主从复制2.1 主从复制2.2 数据同步的方式2.2.1 全量数据同步2.2.2 增量数据同步 2.3 实现原理2.3.1 服务器 RUN ID2.3.2 复制偏移量 offset2.3.3 环形缓冲区 三、哨兵模式3.1 原理3.2 配置3.3 流程3.4 使用3.5 缺点 四、cluster集群4.1 原理…...

在GitHub上管理和协作的完全指南
介绍 GitHub 是一个强大的版本控制和协作平台,它不仅可以帮助你管理和跟踪项目的变化,还可以与他人进行协作。本文将详细介绍如何使用 GitHub 的各种功能来管理和协作项目。 目录 注册GitHub账号创建和管理仓库 创建仓库添加和管理文件分支管理合并请…...

git管理工具学习(图解使用git工作流程)
目录 GIT 简介一个最简单的GIT操作流程git的工作流程&命令 GIT 简介 git是什么,在维基百科上是这么介绍的:git是一个分布式的版本控制软件 分布式是相对于集中式而言的,分布式即每一个git库都是一个完整的库。 每个库的地位都是平等的&am…...
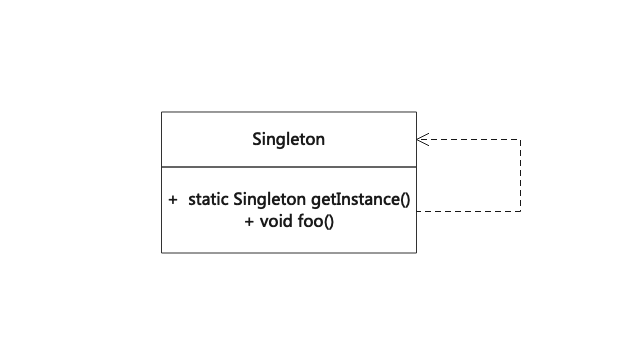
单例模式(Singleton)
单例模式保证一个类仅有一个实例,并提供一个全局访问点来访问它,这个类称为单例类。可见,在实现单例模式时,除了保证一个类只能创建一个实例外,还需提供一个全局访问点。 Singleton is a creational design pattern t…...

2023-08-02 LeetCode每日一题(翻转卡片游戏)
2023-08-02每日一题 一、题目编号 822. 翻转卡片游戏二、题目链接 点击跳转到题目位置 三、题目描述 在桌子上有 N 张卡片,每张卡片的正面和背面都写着一个正数(正面与背面上的数有可能不一样)。 我们可以先翻转任意张卡片,…...
)
JAVAWEB项目--POST完整交互(servlet,axios,JavaScript)
post交互 js: axios.post("/mycsdn/blog/pageSer", {currentPage:currentPage,}).then(function (response) {window.location.href url;}).catch(function (error) {console.error("分页未遂", error);}); 后端servlet: public…...
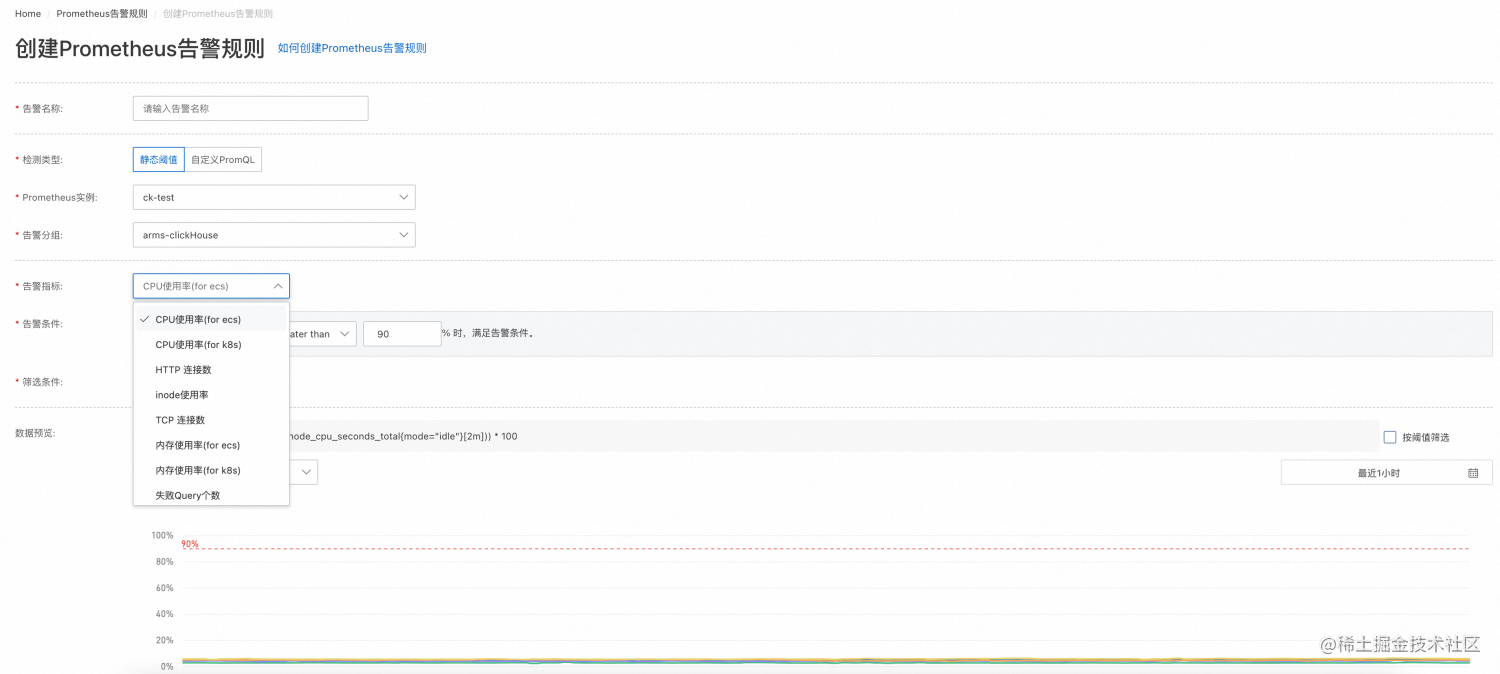
统一观测|借助 Prometheus 监控 ClickHouse 数据库
引言 ClickHouse 作为用于联机分析(OLAP)的列式数据库管理系统(DBMS), 最核心的特点是极致压缩率和极速查询性能。同时,ClickHouse 支持 SQL 查询,在基于大宽表的聚合分析查询场景下展现出优异的性能。因此,获得了广泛的应用。本文旨在分享阿…...

【Golang】基于录制,自动生成go test接口自动化用例
目录 背景 框架 ginkgo初始化 抓包&运行脚本 目录说明 ∮./business ∮./conf ∮./utils ∮./testcase testcase 用例目录结构规则 示例 实现思路 解析Har数据 定义结构体 解析到json 转换请求数据 转换请求 转换请求参数 写业务请求数据 写gotest测试…...

使用快捷键在Unity中快速锁定和解锁Inspector右上角的锁功能
使用快捷键在Unity中快速锁定和解锁Inspector右上角的锁功能 在Unity中,Inspector窗口是一个非常重要的工具,它允许我们查看和编辑选定对象的属性。有时候,我们可能希望锁定Inspector窗口,以防止意外更改对象的属性。幸运的是&am…...

服务器硬件、部署LNMP动态网站、部署wordpress、配置web与数据库服务分离、配置额外的web服务器
day01 day01项目实战目标单机安装基于LNMP结构的WordPress网站基本环境准备配置nginx配置数据库服务部署wordpressweb与数据库服务分离准备数据库服务器迁移数据库配置额外的web服务器 项目实战目标 主机名IP地址client01192.168.88.10/24web1192.168.88.11/24web2192.168.88…...

面试总被问高并发负载测试,你真的会么?
本文将介绍使用50K并发用户测试轻松运行负载测试所需的步骤(以及最多200万用户的更大测试)。 ❶ 写你的剧本 ❷ 使用JMeter在本地测试 ❸ BlazeMeter SandBox测试 ❹ 使用一个控制台和一个引擎设置每引擎用户数量 ❺ 设置和测试群集(一个…...
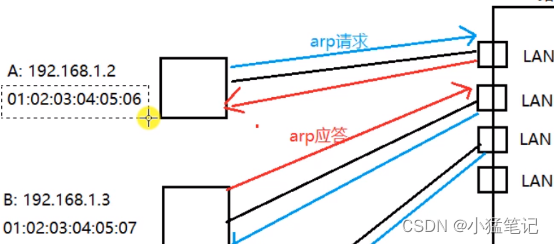
ARP协议请求
文章目录 作用请求与应答流程数据包ARP协议以太网帧协议具体应用 作用 通过 IP地址 查找 MAC地址。 请求与应答流程 A:数据发送主机 B:目标主机 目前只知道目标主机IP地址,想把数据发送过去,需要查询到目标主机的MAC地址&#x…...

前端小练-仿掘金导航栏
文章目录 前言项目结构导航实现创作中心移动小球消息提示 完整代码 前言 闲的,你信嘛,还得开发一个基本的门户社区网站,来给到Hlang,不然我怕说工作量不够。那么这个的话,其实也很好办,主要是这个门户网站的UI写起来麻…...
PDF.js实现搜索关键词高亮显示效果
在static\PDF\web\viewer.js找到定义setInitialView方法 大约是在1202行,不同的pdf.js版本不同 在方法体最后面添加如下代码: // 高亮显示关键词---------------------------------------- var keyword new URL(decodeURIComponent(location)).searchP…...

Linux服务器安装JDK20
一、下载安装包 访问官网,找到JDK20,复制下载链接 我复制的链接是:JDK20 二、Linux服务器操作 1.服务器根目录下创建一个新的文件夹 cd /mkdir jdkscd /jdks2.将下载好的jdk-20上传到jdks下 3.解压缩 tar -zxvf jdk-20_linux-x64_bin.tar…...
vue强制刷新的方法
前言 在开发过程中,有时候会遇到这么一种情况: 1.切换页面页面没有更新 2.通过动态的赋值,但是dom没有及时更新,能够获取到动态赋的值,但是无法获取到双向绑定的dom节点, 这就需要我们手动进行强制刷新组件,下面这篇文章主要给大家介绍了关于vue组件强制刷新的方案…...
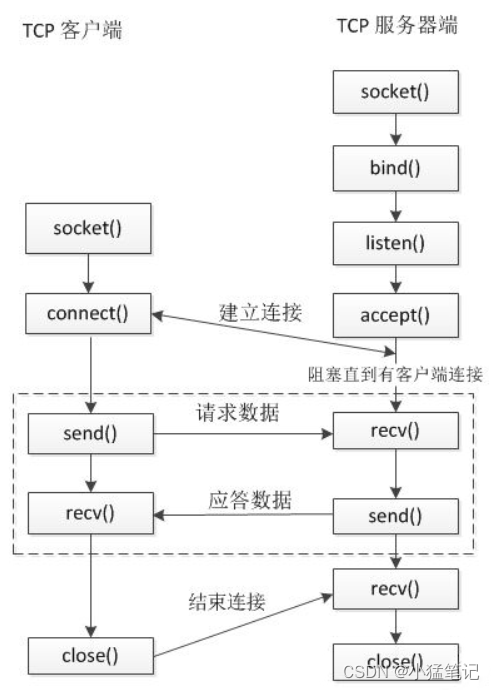
Linux下TCP网络服务器与客户端通信程序入门
文章目录 目标服务器与客户端通信流程TCP服务器代码TCP客户端代码 目标 实现客户端连接服务器,通过终端窗口发送信息给服务器端,服务器接收到信息后对信息数据进行回传,客户端读取回传信息并返回。 服务器与客户端通信流程 TCP服务器代码 …...

在Node.js后端服务中集成Taotoken实现多模型异步调用的教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken实现多模型异步调用的教程 对于需要在后端服务中调用大语言模型的Node.js开发者而言,…...
GitGitHub实操图文详解教程(09)—git log命令)
(最新版)GitGitHub实操图文详解教程(09)—git log命令
版权声明 本文原创作者:谷哥的小弟 作者博客地址:http://blog.csdn.net/lfdfhl 1. 应用场景 git log用于查看项目的提交历史。前面我们已经学习了git add和git commit,其中git commit会将暂存区中的内容保存为一次正式提交。随着项目不断开发,本地仓库中会逐渐产生多次提交…...

推荐几款实测有效的降重工具,要求同时对付查重系统和AIGC检测
毕业季论文两大 “生死关”—— 知网 / 维普 / 格子达等查重标红、AIGC 疑似率超标,已成为无数学生的噩梦。普通降重工具仅能降重复率,改写后仍难逃 AI 检测;AI 写作工具生成内容流畅度高,却自带明显 AI 痕迹,双检极易…...

ARM P-Channel接口设计与低功耗SoC电源管理实践
1. ARM P-Channel接口深度解析在低功耗SoC设计中,电源管理接口的可靠性和时序一致性直接决定了系统的能效表现。ARM P-Channel作为专为电源管理设计的标准化接口协议,通过独特的四阶段握手机制,为设备与电源控制器之间建立了高效的状态协商通…...
)
Perplexity数据验证功能全链路解析(98.7%准确率背后的4层校验架构)
更多请点击: https://kaifayun.com 第一章:Perplexity数据验证功能全链路解析(98.7%准确率背后的4层校验架构) Perplexity 的数据验证并非单一规则匹配,而是融合语义一致性、来源可信度、时效性约束与逻辑闭环性的四维…...

终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题!
终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题! 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备无法…...

AI率总超标?2026年AI论文平台排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重总不通过?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!Ἴ…...

Firefox Android与Firefox Focus对比分析:选择最适合你的浏览器
Firefox Android与Firefox Focus对比分析:选择最适合你的浏览器 【免费下载链接】firefox-android :warning: This repository hosts the Firefox for Android (Fenix), Focus for Android, and Mozilla Android Components projects. It is now developed and main…...

2026年管棒材检测系统十强厂商最新深度评测
进入2026年下半年,全球管棒材检测系统行业正式迈入高质量发展攻坚期,行业发展主线聚焦于AI多模态融合与全流程数字化转型,技术迭代呈现“多技术协同、全场景适配”的核心特征。其中,相控阵超声(PAUT)、全聚…...

LabVIEW 32位版如何调用Halcon 17.12的.NET库?手把手教你打通图像处理流程
LabVIEW 32位版与Halcon 17.12 .NET库深度兼容指南:从原理到实战 在工业视觉和自动化测试领域,LabVIEW与Halcon的组合堪称黄金搭档。但当我们试图在32位LabVIEW环境中调用Halcon 17.12的.NET库时,常常会遇到各种"拦路虎"——从神秘…...