解密Redis:应对面试中的缓存相关问题
文章目录
- 1. 缓存穿透问题及解决方案
- 2. 缓存击穿问题及解决方案
- 3. 缓存雪崩问题及解决方案
- 4. Redis的数据持久化
- 5. Redis的过期删除策略和数据淘汰策略
- 6. Redis分布式锁和主从同步
- 7. Redis集群方案
- 8. Redis的数据一致性保障和高可用性方案

导语: 在面试过程中,面试官可能会问到关于Redis缓存的一系列问题。本文将深入探讨Redis缓存相关面试题,并为你提供详细的解答,帮助你在面试中游刃有余。

1. 缓存穿透问题及解决方案
面试官: 什么是缓存穿透?该如何解决?
候选人: 缓存穿透是指查询一个一定不存在的数据,在存储层查不到数据时,不写入缓存。这导致每次请求都需要去数据库查询,可能会造成数据库崩溃。通常这种情况是遭到攻击。
解决方案: 解决缓存穿透问题通常采用布隆过滤器。布隆过滤器是用于检索一个元素是否在一个集合中的数据结构。我们可以使用Redisson实现的布隆过滤器。它在底层使用一个比较大的数组,用二进制的0或1来存储元素的存在状态。通过多次哈希计算,确定元素的位置并将相应位置的值置为1。查询时也是类似的过程。
然而,布隆过滤器有一定的误判率,我们可以通过设置误判率来平衡性能和准确性,通常不会超过5%。
2. 缓存击穿问题及解决方案
面试官: 什么是缓存击穿?该如何解决?
候选人: 缓存击穿是指设置了过期时间的缓存key,在某一时刻同时失效,导致大量请求直接转发到数据库,可能会压垮数据库。
解决方案: 缓解缓存击穿问题的方式有两种:
-
互斥锁: 当缓存失效时,不立即去数据库加载数据,而是先使用例如Redis的
setnx命令设置一个互斥锁。操作成功返回时再进行数据库加载并写入缓存,否则重试获取缓存的方法。 -
设置当前key逻辑过期: 在设置缓存时,同时设置一个过期时间字段存入缓存,而不给当前key设置过期时间。当查询时,先从缓存中取出数据后,判断时间是否过期。如果过期,则开启另一个线程进行数据同步,当前线程正常返回数据,尽管数据不是最新的。
两种方案各有优劣,如果需要强一致性,建议使用互斥锁,虽然性能可能较差,但避免了脏数据和死锁问题。如果对数据的实时性要求不高,可以采用第二种方案来保证高可用性和较好的性能。
3. 缓存雪崩问题及解决方案
面试官: 什么是缓存雪崩?该如何解决?
候选人: 缓存雪崩指的是设置缓存时采用了相同的过期时间,导致多个缓存在某一时刻同时失效,大量请求转发到数据库,使数据库瞬时压力过重,引起性能问题。
解决方案: 缓解缓存雪崩问题的方法是将缓存的过期时间分散开,例如在原有的过期时间基础上增加一个随机值,使每个缓存的过期时间不完全一致,降低缓存失效的重复率,从而减少集体失效事件的发生。
4. Redis的数据持久化
面试官: Redis的数据持久化方式有哪些?
候选人: Redis提供了两种数据持久化方式:RDB和AOF。
-
RDB(Redis Database): 它是一个快照文件,将Redis内存中存储的数据写入磁盘。当Redis实例宕机需要恢复数据时,可以从RDB的快照文件中恢复数据。
-
AOF(Append-Only File): 它是一个追加文件,在AOF模式下,当Redis执行写命令时,会将写命令以日志的形式追加到AOF文件中。当Redis实例宕机需要恢复数据时,会通过重新执行AOF文件中记录的命令来恢复数据。
面试官: RDB和AOF两种持久化方式有什么区别?
候选人: RDB和AOF两种持久化方式有以下区别:
-
数据格式: RDB以二进制格式保存数据,文件较小,恢复速度较快;AOF以文本形式保存数据,文件较大,恢复速度较慢。
-
恢复速度: RDB恢复速度相对较快,因为数据是以二进制格式保存在磁盘上,读取速度快;而AOF恢复速度较慢,因为需要逐行解析AOF文件中的命令。
-
数据安全性: RDB的数据可能存在较小的数据丢失风险,因为RDB采用快照方式保存数据,如果Redis在保存RDB文件时宕机,可能会丢失最后一次快照之后的数据;而AOF可以通过配置不同的fsync策略来保证数据安全性,可以选择每条写命令都立即刷入磁盘(效率较低),或者定期刷入磁盘(效率较高但会增加数据丢失风险)。
-
持久化机制: RDB是定时触发的,可以通过配置定期执行快照操作,或在满足一定条件时执行快照;而AOF是在每次写操作执行时都会追加到AOF文件中,实时记录数据变化。
通常情况下,可以同时开启RDB和AOF两种持久化方式,以提高数据的安全性和恢复效率。
5. Redis的过期删除策略和数据淘汰策略
面试官: Redis的过期删除策略有哪些?
候选人: Redis的过期删除策略包括惰性删除和定期删除两种方式。
-
惰性删除: 在设置了过期时间的key被访问时,会先判断该key是否过期,如果过期则删除;如果未过期,则返回数据。这种方式在获取数据时判断是否过期,如果过期就删除,是一种延迟删除的方式。
-
定期删除: Redis会以一定频率执行检查操作,定期扫描所有key,删除已过期的key。定期删除的两种模式为SLOW模式和FAST模式,前者是定时任务,执行频率默认为10hz,每次不超过25ms,可以通过修改配置文件redis.conf的hz选项调整;后者执行频率不固定,每次事件循环会尝试执行,但两次间隔不低于2ms,每次耗时不超过1ms。
面试官: Redis的数据淘汰策略有哪些?
候选人: Redis的数据淘汰策略包括LRU(最近最少使用)和LFU(最少频率使用)两种方式。
-
LRU(最近最少使用): 根据key的最近访问时间判断,删除最近最少使用的key。
-
LFU(最少频率使用): 统计每个key的访问频率,删除访问频率最低的key。
在Redis中可以通过设置相关配置来选择不同的数据淘汰策略,默认是noeviction,即不删除任何数据。选择LRU和LFU策略时,需要注意性能和数据一致性的权衡。
6. Redis分布式锁和主从同步
面试官: Redis分布式锁如何实现?
候选人: Redis分布式锁的实现主要依赖于Redis的setnx(SET if not exists)命令。由于Redis是单线程的,在使用setnx命令时,只有一个客户端能够成功设置某个key的值,其他客户端会被拒绝。通过这一特性,我们可以使用setnx命令来实现分布式锁。
面试官: 那如何控制Redis实现分布式锁的有效时长呢?
候选人: setnx命令本身并不能控制锁的有效时长。为了解决这个问题,我们可以使用Redisson等Redis的客户端框架来实现分布式锁。这些框架允许手动加锁,并且可以控制锁的失效时间和等待时间。
在Redisson中,我们可以使用锁的lock()方法来手动加锁,通过设置锁的失效时间来控制锁的有效时长。同时,Redisson还提供了看门狗机制,用于检查当前线程是否持有锁,并在合适的时机更新锁的失效时间,从而避免锁的过期。
面试官: Redis分布式锁是可重入的吗?
候选人: 是的,Redis分布式锁是可重入的。在内部实现中,分布式锁会使用类似计数器的方式来实现可重入。当一个线程获取锁时,会增加计数,释放锁时会减少计数。如果同一个线程再次获取锁,会判断是否是当前线程持有的锁,如果是,则增加计数。当计数归零时,锁会被完全释放。
面试官: Redisson实现的分布式锁能解决主从一致性的问题吗?
候选人: Redisson实现的分布式锁不能解决主从一致性问题。例如,当一个线程在主节点上成功加锁后,数据会异步复制到从节点。此时,如果主节点宕机,从节点可能会被提升为新的主节点,而现在来了一个新的线程,再次加锁,就会在新的主节点上成功加锁。这样就导致了两个节点同时持有同一把锁的问题。
为了解决主从一致性问题,可以使用Redisson提供的红锁(RedLock)机制。红锁要求在多个Redis节点上创建锁,并且在大多数节点上成功创建锁,以确保锁的一致性。但是红锁会增加锁的获取复杂性和运维维护成本,并且在高并发场景下性能较差,因此在实际项目中使用较少,甚至官方也废弃了红锁。
面试官: 如果业务需要保证数据的强一致性,你会采取什么样的措施?
候选人: 如果业务需要保证数据的强一致性,Redis本身是无法满足的,因为为了保证强一致性,必然会影响性能。在这种情况下,可以考虑使用其他分布式锁机制,例如ZooKeeper实现的分布式锁。ZooKeeper可以保证强一致性,但相应地增加了运维成本和性能开销。
7. Redis集群方案
面试官: Redis集群有哪些方案?
候选人: Redis提供了三种集群方案:主从复制、哨兵模式和Redis分片集群。
-
主从复制: 主从复制是指一个主节点同步数据到多个从节点的过程。主节点负责写入数据,从节点负责读取数据。当主节点写入数据时,会将数据异步复制到从节点,从节点定时拉取数据。主从复制实现了读写分离,提高了Redis的并发能力和读取性能。
-
哨兵模式: 哨兵模式是用于实现高可用性的方案。在哨兵模式中,有多个Redis实例,其中一个为主节点,其他为从节点。同时有一个哨兵进程监控所有节点的状态,当主节点宕机时,哨兵会自动将某个从节点升级为主节点,保证服务的可用性。
-
Redis分片集群: Redis分片集群是将数据分片存储在多个Redis实例中,实现数据的水平分割。每个实例负责处理其中的一部分数据,从而提高Redis的存储和处理能力。在分片集群中,每个实例都是独立的,没有主从之分。
面试官: 那你来介绍一下主从同步的流程。
候选人: 主从同步分为全量同步和增量同步两个阶段。
-
全量同步: 当从节点与主节点第一次建立连接时,会进行全量同步。流程如下:
-
从节点请求主节点进行数据同步,并携带自己的复制ID(replication ID)和复制偏移量(offset)。
-
主节点判断是否是从节点的第一次请求,主要判断依据是判断从节点的复制ID是否与主节点一致。如果不一致,则认为是第一次同步请求,主节点会发送自己的复制ID和复制偏移量给从节点,让从节点与主节点的信息保持一致。
-
同时,主节点执行
bgsave命令生成RDB文件,并发送给从节点执行。从节点在执行RDB文件时,先清空自己的数据,然后按照主节点发送的RDB文件来恢复数据。这样,主从之间的数据就保持了一致。 -
在全量同步期间,如果有新的写命令到达主节点,主节点会记录这些写命令到缓冲区,缓冲区是一个日志文件。当全量同步完成后,主节点会将缓冲区的日志文件发送给从节点,从节点执行这些写命令来同步数据。
-
-
增量同步: 全量同步完成后,从节点与主节点之间的数据就保持了一致。此后,主节点会将新的写命令以增量方式发送给从节点,从节点执行这些增量命令来保持数据的同步。
面试官: Redis分布式集群中如何处理数据分片和读写操作?
候选人: 在Redis分布式集群中,数据分片是将数据分散存储在多个Redis实例中的过程。通过哈希算法,将相同的key映射到同一个实例中,实现数据的水平分割。
对于读写操作,Redis分片集群使用了一种代理方式来实现:
-
对于写操作,客户端将写请求发送给集群的其中一个实例,该实例会根据哈希算法找到负责该key的实例,并将写命令发送给该实例,实现数据的写入。
-
对于读操作,客户端将读请求发送给集群的其中一个实例,该实例会根据哈希算法找到负责该key的实例,并将读命令发送给该实例,获取数据。
通过数据分片和读写代理,Redis分片集群可以实现数据的均衡存储和负载均衡,提高了数据的处理能力和读写性能。
8. Redis的数据一致性保障和高可用性方案
面试官: Redis的数据一致性如何保障?
候选人: Redis的数据一致性在主从复制和哨兵模式下,由Redis本身提供的复制机制保障。当主节点写入数据时,会将数据异步复制到从节点,确保数据的一致性。在哨兵模式中,哨兵进程会监控主从节点的状态,当主节点宕机时,会自动将某个从节点升级为新的主节点,保证数据的连续性。
然而,对于分片集群来说,数据一致性需要由应用程序来保障。在分片集群中,由于数据被分散存储在多个实例中,每个实例负责处理其中的一部分数据,因此数据的一致性需要应用程序自行处理。一般情况下,可以通过以下方式来保障数据的一致性:
-
使用分布式事务: 在涉及到多个Redis实例的写操作时,可以使用分布式事务来保障数据的一致性。一种常见的实现方式是使用分布式事务管理器,如
XA或TCC,将多个Redis实例的写操作组织成一个事务,要么全部成功,要么全部失败,从而保证数据的一致性。 -
引入数据同步机制: 应用程序可以自行实现数据同步机制,例如在写入数据时,同时将数据写入多个Redis实例,并使用消息队列等方式进行数据同步,以保证数据在多个实例之间的一致性。
面试官: Redis的高可用性方案有哪些?
候选人: Redis的高可用性主要通过哨兵模式和Redis集群来实现。
-
哨兵模式: 哨兵模式是用于实现Redis高可用的方案。在哨兵模式中,有多个Redis实例,其中一个为主节点,其他为从节点。同时有一个哨兵进程监控所有节点的状态,当主节点宕机时,哨兵会自动将某个从节点升级为主节点,保证服务的可用性。哨兵模式实现了自动故障转移,提高了Redis的高可用性。
-
Redis集群: Redis集群是另一种实现Redis高可用的方式。在Redis集群中,数据被分片存储在多个Redis实例中,每个实例负责处理其中的一部分数据,从而提高了Redis的存储和处理能力。当部分实例宕机时,集群仍然可以继续提供服务,保障了系统的高可用性。
面试官: Redis的数据持久化方式有哪些?它们有什么区别?
候选人: Redis的数据持久化方式有两种:RDB(Redis Database)和AOF(Append Only File)。
-
RDB: RDB是Redis的一种快照持久化方式。当启用RDB持久化时,Redis会周期性地将内存中的数据生成一个快照文件(dump.rdb),该文件是二进制格式的,包含了当前数据库中的所有键值对数据。RDB持久化的优点是快速、紧凑,适合用于备份数据和全量恢复。缺点是如果Redis意外宕机,可能会丢失最后一次持久化后的数据。
-
AOF: AOF是Redis的另一种持久化方式。当启用AOF持久化时,Redis会将写命令追加到AOF文件中,记录了数据写操作的命令序列。AOF持久化的优点是可以保证更高的数据安全性,因为它记录了写操作的命令序列,只要重放这些命令,就能完整恢复数据。缺点是相比RDB,AOF文件体积较大,并且在数据恢复时,AOF文件的重放可能比RDB的加载更慢。
面试官: 这两种持久化方式中,哪一种恢复速度比较快呢?
候选人: RDB持久化方式恢复速度比较快。由于RDB文件是二进制格式的,并且在保存时经过压缩处理,所以文件体积较小。在恢复数据时,Redis只需加载RDB文件,将其中的数据读入内存,速度相对较快。
AOF持久化方式恢复数据时,需要重放AOF文件中的写操作命令,这个过程相对于RDB的加载来说,可能会慢一些。但是AOF可以保证更高的数据安全性,因为它记录了完整的写操作序列,避免了数据丢失的风险。
面试官: Redis的过期策略有哪些?
候选人: 在Redis中,有两种数据过期删除策略:
-
惰性删除(lazy expiration): 在设置了过期时间的key被访问时,会先检查该key是否过期,如果过期,则会立即删除;如果没有过期,则返回该key的值。这种策略称为惰性删除,因为Redis并不主动删除过期的key,而是等待访问时才删除。
-
定期删除(定时任务删除): Redis会以一定的频率(默认为每秒钟10次)检查部分设置了过期时间的key,将过期的key删除。这种策略称为定期删除,因为Redis定期地进行key的过期检查和删除操作。
这两种过期策略是配合使用的,Redis会根据需要对过期key进行惰性删除和定期删除,以保证数据的有效过期。
面试官: Redis的数据淘汰策略有哪些?
候选人: Redis中的数据淘汰策略用于在内存不足时,选择哪些数据被删除,从而释放内存空间。Redis提供了多种数据淘汰策略,常见的有以下几种:
-
volatile-lru(LRU算法): 这是Redis的默认数据淘汰策略。在设置了过期时间的key中,Redis会优先淘汰最近最少使用的数据(LRU算法),即那些最近被访问较少的数据。这样可以保留那些经常被访问的热点数据,提高缓存命中率。
-
allkeys-lru(LRU算法): 这种策略是在所有的key中进行LRU算法淘汰,不仅包括设置了过期时间的key,还包括没有设置过期时间的key。这样可以使得Redis保持最新的数据,但是会增加内存压力。
-
volatile-ttl(TTL算法): 在设置了过期时间的key中,Redis会优先淘汰剩余存活时间较短的数据(TTL算法)。这样做可以确保即将过期的数据被优先淘汰,从而避免存活时间很长但已经不再使用的数据占用内存。
-
volatile-random: 在设置了过期时间的key中,Redis会随机选择一部分数据进行淘汰。这种策略适用于对所有缓存数据的存活时间没有特别要求的情况。
-
allkeys-random: 这种策略是在所有的key中进行随机淘汰。类似于
volatile-random,适用于对所有缓存数据的存活时间没有特别要求的情况。
除了以上几种淘汰策略,Redis还提供了volatile-lfu(LFU算法,最少使用频率)和allkeys-lfu(LFU算法)等淘汰策略,可以根据业务需求选择合适的策略。
面试官: Redis如何实现分布式锁?
候选人: Redis实现分布式锁的常见方式是利用SETNX命令(SET if Not eXists)。由于Redis是单线程的,使用SETNX命令可以保证在同一时刻只有一个客户端能够成功地设置某个键的值,从而实现锁的效果。
具体实现步骤如下:
-
客户端尝试通过
SETNX命令设置一个特定的键,该键的值为一个唯一标识(例如,可以使用UUID)。 -
如果
SETNX命令返回1,表示键设置成功,客户端获取到了锁。 -
如果
SETNX命令返回0,表示键已经存在,其他客户端已经持有了锁,当前客户端获取锁失败。 -
当客户端执行完业务操作后,通过
DEL命令释放锁,将键从Redis中删除。
需要注意的是,为了防止死锁,获取锁的客户端在执行完业务操作后,应该及时释放锁。同时,为了防止误删除其他客户端持有的锁,需要在释放锁时校验锁的标识,确保只有持有正确标识的锁才被删除。
面试官: Redis分布式锁有没有什么问题?
候选人: 是的,Redis分布式锁虽然简单高效,但也有一些问题需要注意:
-
死锁问题: 如果一个持有锁的客户端在执行业务操作时发生了异常导致未释放锁,就会出现死锁问题。为了避免死锁,需要在获取锁后设置锁的过期时间,确保即使锁没有被释放,也会在一定时间后自动释放,防止长期占用锁。
-
误删问题: 由于分布式锁是通过设置特定的键值对来实现的,当客户端释放锁时,可能会误删其他客户端持有的锁。为了避免误删问题,可以为每个客户端设置一个唯一的锁标识,释放锁时校验标识确保只删除自己持有的锁。
-
锁竞争问题: 在高并发情况下,多个客户端可能同时竞争一个锁,这会导致锁的频繁竞争和释放,影响性能。为了减少锁竞争问题,可以使用带有重试机制的获取锁操作,避免因竞争失败而频繁重试。
面试官: 很好,你对Redis相关面试题回答得很不错。有没有什么问题想要问我的?
候选人: 是的,我想了解贵公司在使用Redis时,最常见的应用场景和面临的挑战是什么?
面试官: 很好的问题!在我们公司,最常见的Redis应用场景包括缓存加速、会话存储、计数器和分布式锁等。我们利用Redis的高速读写能力,将一些频繁读写的数据存储在Redis缓存中,提高系统的性能和响应速度。同时,我们也使用Redis来存储用户会话信息,实现无状态的会话管理,从而方便水平扩展。
在面对Redis的挑战时,主要集中在数据一致性、高可用性和性能方面。为了保障数据的一致性,我们在使用Redis时会结合其他组件或方案来实现分布式锁和数据同步。例如,在使用Redis作为缓存时,我们会考虑缓存与数据库之间的数据同步,以保证数据的一致性。在高并发的情况下,缓存雪崩和缓存击穿是常见的问题,我们需要采取相应的缓解措施,如设置合理的缓存过期时间和使用热点数据预热等。
另外,高可用性也是一个重要的挑战。为了避免单点故障,我们通常会部署Redis的主从复制或使用Redis集群来实现高可用性。在Redis主从复制中,需要注意主节点故障时的故障转移和从节点数据同步的问题。
此外,性能优化也是我们关注的重点。在使用Redis时,我们需要细心设计缓存数据结构、选择合适的淘汰策略和配置合理的持久化方式,以及合理利用Redis的数据结构和命令来优化性能。
面试官: 你对Redis的应用场景和挑战有了很好的理解。还有其他问题需要咨询吗?
候选人: 是的,我想了解一下贵公司对于技术人才的培养和发展计划。
面试官: 很好的问题!在我们公司,我们非常重视技术人才的培养和发展。我们鼓励员工不断学习和探索新技术,提供丰富的培训和学习资源。我们会定期组织内部技术分享会,让员工有机会分享自己的技术经验和成果。
同时,我们也会根据员工的兴趣和擅长领域,提供个性化的发展计划,帮助员工在自己擅长的领域深耕,并在技术职业道路上不断成长。我们鼓励员工参与开源项目和技术社区,扩展技术视野,与更多的优秀技术人才交流合作。
另外,我们公司也提供良好的晋升机制和职业发展通道。优秀的技术人才有机会晋升为技术专家或技术经理,并参与更具挑战性和复杂的项目,为公司的技术发展贡献更多力量。
面试官: 感谢你的提问!我们非常看重员工的成长和发展,希望员工能在公司里得到充分的锻炼和发展。如果没有其他问题,我们就结束本次面试。
候选人: 非常感谢您的时间和机会,我对贵公司的工作环境和发展前景充满期待。如果有进一步的消息,我会及时跟进。再次感谢!
面试官: 非常感谢你的参与和回答,希望你能尽快收到面试结果。祝你好运!
以上就是对Redis相关面试题的整理和回答,希望对你有所帮助。在面试时,展现自己的知识和技能是非常重要的,同时也要表现出自信和积极的态度。祝你面试顺利,取得理想的工作成果!

相关文章:
解密Redis:应对面试中的缓存相关问题
文章目录 1. 缓存穿透问题及解决方案2. 缓存击穿问题及解决方案3. 缓存雪崩问题及解决方案4. Redis的数据持久化5. Redis的过期删除策略和数据淘汰策略6. Redis分布式锁和主从同步7. Redis集群方案8. Redis的数据一致性保障和高可用性方案 导语: 在面试过程中&#…...
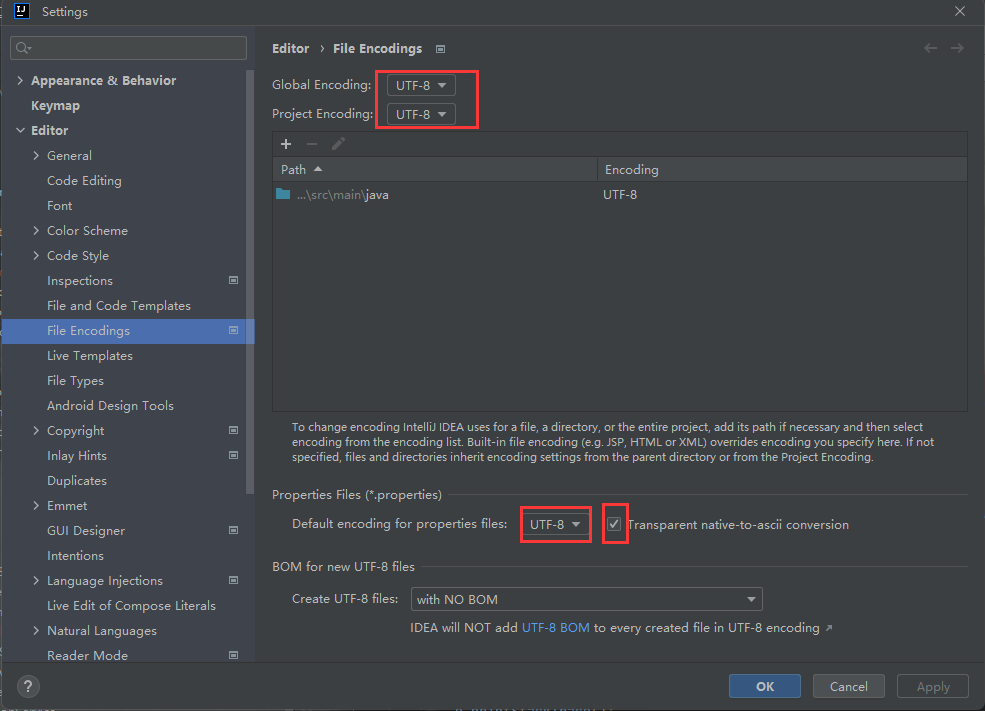
读取application-dev.properties的中文乱码【bug】
读取application-dev.properties的中文编码【bug】 2023-7-30 22:37:46 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博客主页是https://blog.csdn.net/qq_51625007 禁止其他平台发布时删除以上此话 bug 读取application-dev.propert…...

Linux(centos7)如何实现配置iscsi存储多路径 及DM-Multipath的配置文件概述
安装多路径软件(系统默认安装) #第一:安装多路径软件yum -y install device-mapper device-mapper-multipath#第二:在CentOS7中启用多路径模块,mpathconf命令及相关模块加载(可以使用mpathconf -h查看用法&…...

DK7 vs JDK8 vs JDK11特性和功能的对比
JDK7 vs JDK8 vs JDK11特性和功能的对比 Java Development Kit (JDK) 是 Java 程序员所使用的开发工具包,它提供了编译、调试和运行 Java 程序所需的一切。JDK 在不同的版本中引入了许多新的特性和功能,下面我们来比较 JDK7、JDK8 和 JDK11 之间的一些重…...

你觉得企业为什么需要数据分析?
数据对于企业的作用就好比,一位士兵作战需要手枪一样,仅仅只是作为一项工具,帮助我们提高取得胜利的几率或者概率。数据只是数据,不代表业务,所起的作用也是有限的,网上那些夸大数据作用的,没有…...

SVN学习
SVN学习 以下总结是看了一个b站up主的视频总结出来的。 1. 简介 SVN是代码版本管理工具,它能记住每次的修改、查看所有修改记录、恢复到任何历史版本和恢复已经删除的文件。 SVN比起Git的好处就是使用简单,上手快;具备目录级权限控制&…...

vim怎么使用,vim使用教程,vimtutor怎么切换中文 汉化
vim 使用 在安装了 vim 的 unix 系统下可以使用 vimtutor zh_cn 开启下面的教程 序言 欢 迎 阅 读 《 V I M 教 程 》 —— 版本 1.7 Vim 是一个具有很多命令的功能非常强大的编辑器。限于篇幅,在本教程当中就不详细介绍了。本教程的…...

[golang gin框架] 43.Gin商城项目-微服务实战之后台Rbac微服务之管理员的增删改查以及管理员和角色关联
上一节讲解了后台Rbac微服务角色增删改查微服务,这里讲解权限管理Rbac微服务管理员的增删改查微服务以及管理员和角色关联微服务功能 一.实现后台权限管理Rbac之管理员增删改查微服务服务端功能 1.创建Manager模型 要实现管理员的增删改查,就需要创建对应的模型,故在server/r…...
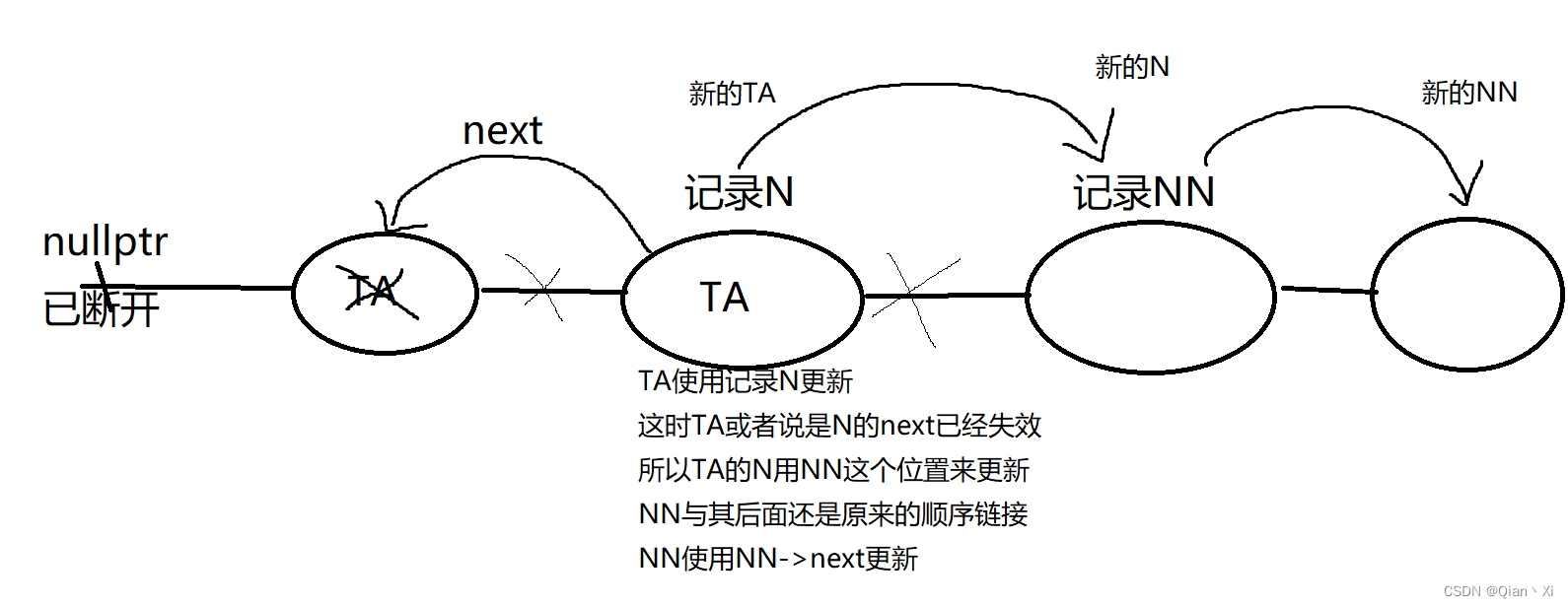
2023-07-31力扣每日一题
链接: 143. 重排链表 题意: 将链表L0 → L1 → … → Ln - 1 → Ln变成L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → … 解: 线性表法还是好写的 这边搞一下翻转法,快慢指针求翻转点(翻转后面一半然后双指针合并…...

接口自动化报告,生成本地服务并自动打开时失败
错误原因: 端口号被占用 首先可以在cmd中调出命令窗口然后执行命令netstat -ano就可以查看所有活动的链接,找到被占用的端口号 1、通过命令taskkill /f /t /im "进程名称" ,根据进程的名称杀掉所有的进程。或者taskkill /f /t /p…...

Git 的基本概念和使用方式
Git 是一种分布式版本控制系统,它能够记录文件内容的变化,并且允许用户在这些变化之间轻松地进行切换。 Git 的基本概念如下: 1. 仓库(Repository):Git 存放项目代码的地方。通常,一个仓库对应一…...
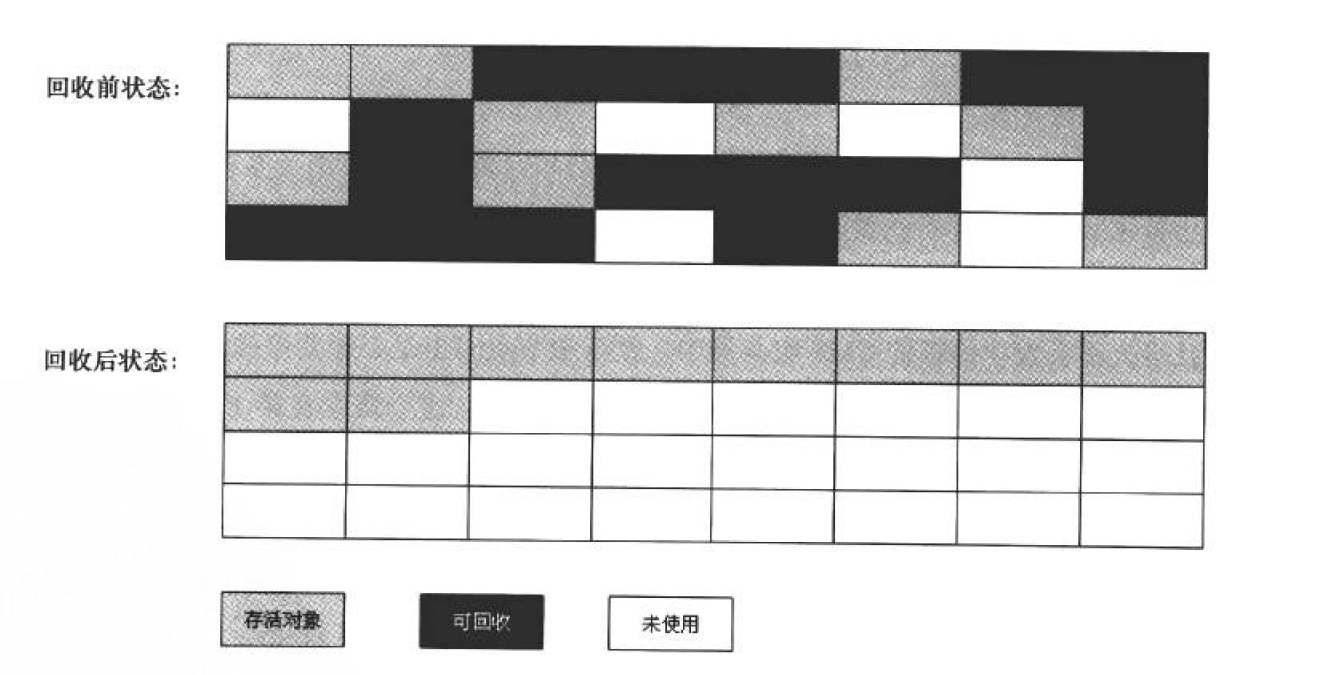
【JVM】(三) 深入理解JVM垃圾回收机制(GC)
文章目录 前言一、死亡对象的判断方法1.1 引用计数算法1.2 可达性分析算法 二、垃圾回收算法2.1 标记-清除算法2.2 复制算法2.3 标记-整理算法2.5 分代算法2.6 Minor GC 和 Major GC 前言 JVM 的垃圾回收机制(Garbage Collection)是 Java 中的重要特性之…...
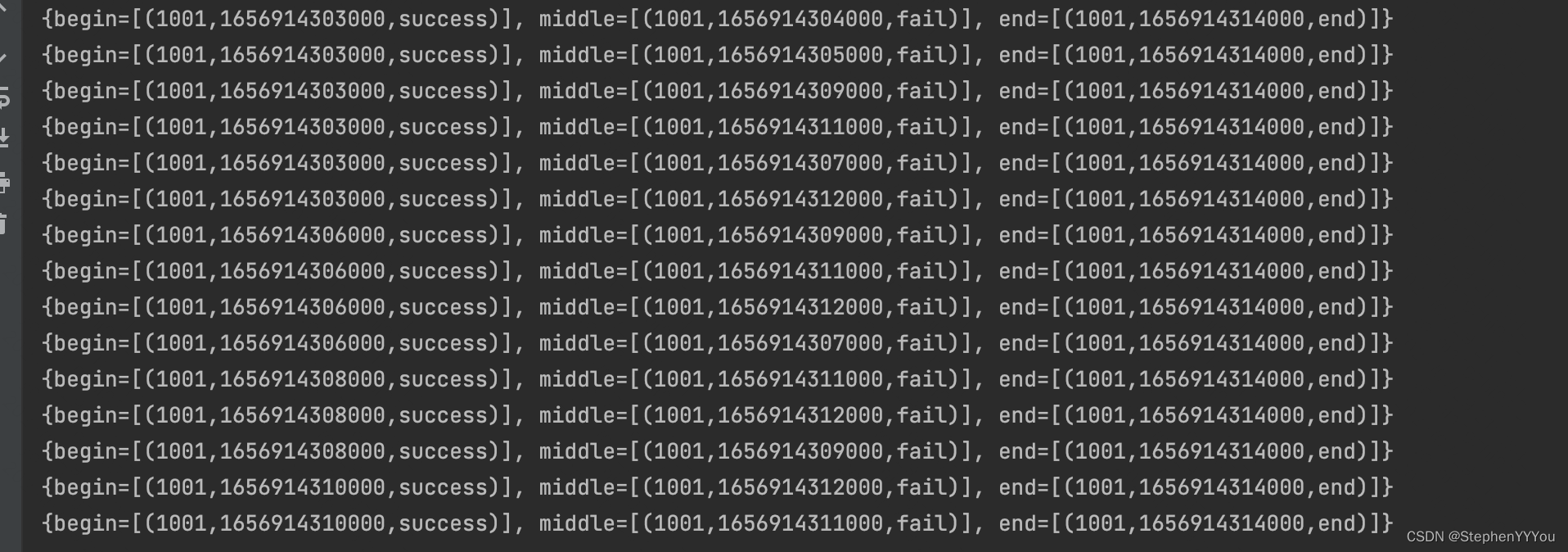
Flink CEP(二) 运行源码解析
通过DemoApp学习一下,CEP的源码执行逻辑。为下一篇实现CEP动态Pattern奠定理论基础。 1. Pattern的定义 Pattern<Tuple3<String, Long, String>,?> pattern Pattern.<Tuple3<String, Long, String>>begin("begin").where(new…...
双指针(下))
剑指Offer-学习计划(四)双指针(下)
剑指 Offer 57. 和为s的两个数字 剑指 Offer 58 - I. 翻转单词顺序 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面 题目一:调整数组顺序使奇数位于偶数前面 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数在数组的…...

深度学习——常见注意力机制
1.SENet SENet属于通道注意力机制。2017年提出,是imageNet最后的冠军 SENet采用的方法是对于特征层赋予权值。 重点在于如何赋权 1.将输入信息的所有通道平均池化。 2.平均池化后进行两次全连接,第一次全连接链接的神经元较少,第二次全连…...

Python 进阶(七):高级文件操作(shutil 模块)
❤️ 博客主页:水滴技术 🌸 订阅专栏:Python 入门核心技术 🚀 支持水滴:点赞👍 收藏⭐ 留言💬 文章目录 1. 简介2. 常用函数2.1 复制文件2.2 复制目录2.3 移动文件或目录2.4 删除文件或目录2.…...
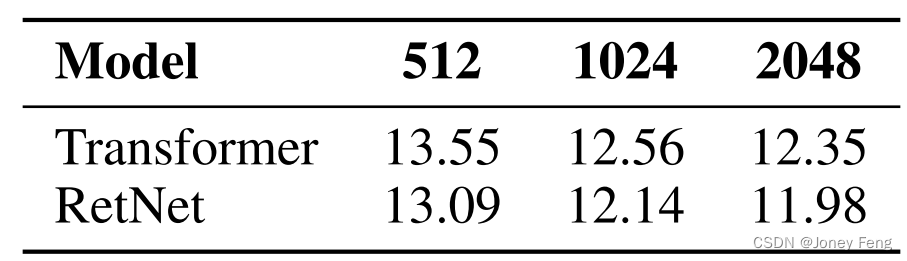
保留网络:大型语言模型的Transformer继任者
原文信息 原文题目:《Retentive Network: A Successor to Transformer for Large Language Models》 原文引用:Sun Y, Dong L, Huang S, et al. Retentive Network: A Successor to Transformer for Large Language Models[J]. arXiv preprint arXiv:2…...

算法通关村第二关——反转链表青铜笔记
LeetCode 206.反转链表 建立虚拟结点辅助翻转 public ListNode reverseList(ListNode head) {ListNode ans new ListNode(-1);ListNode cur head;while(cur!null){ListNode curNext cur.next;cur.next ans.next;ans.next cur;cur curNext;}return ans.next; }不带虚拟头…...
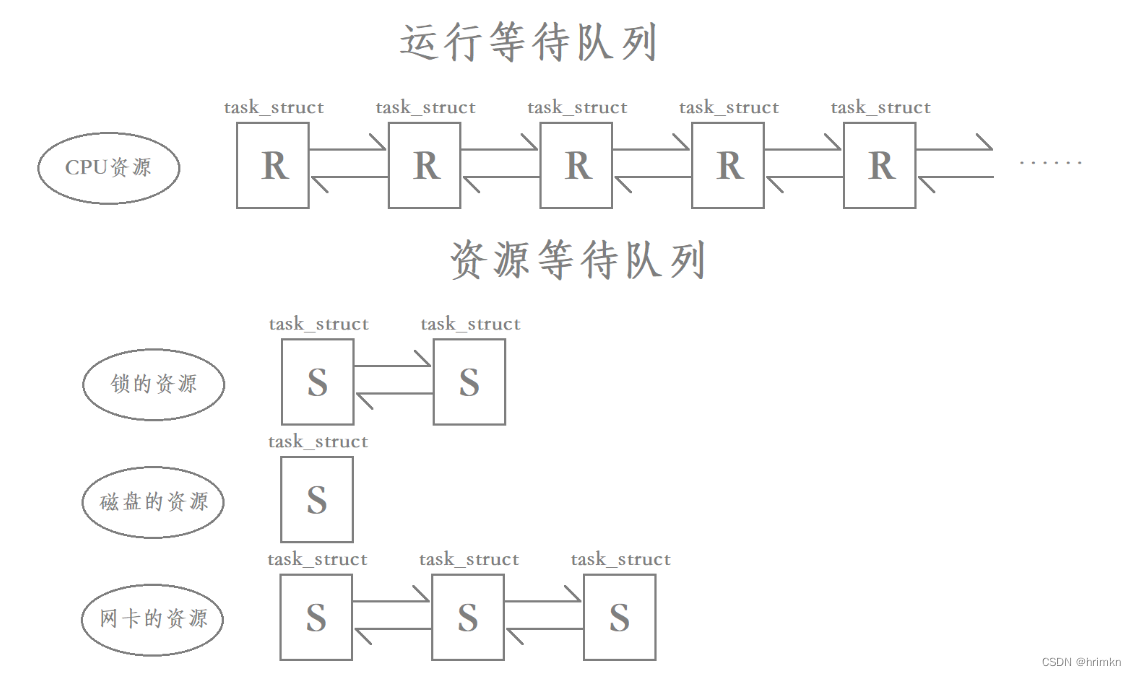
【Linux】——线程安全
目录 关于线程进程的问题 可重入与线程安全 常见的线程安全的情况 常见的不可重入的情况 常见的可重入的情况 可重入与线程安全区别 可重入与线程安全联系 Linux线程互斥 进程线程间的互斥相关概念 互斥量mutex 互斥量mutex常用接口 互斥量改造抢票系统 互斥量的原…...

[React]生命周期
前言 学习React,生命周期很重要,我们了解完生命周期的各个组件,对写高性能组件会有很大的帮助. Ract生命周期 React 生命周期分为三种状态 1. 初始化 2.更新 3.销毁 初始化 1、getDefaultProps() 设置默认的props,也可以用duf…...
)
Cadence 5141实战:手把手教你搞定Bandgap基准电压源电路(附完整仿真流程)
Cadence 5141实战:手把手教你搞定Bandgap基准电压源电路(附完整仿真流程) 在模拟集成电路设计中,基准电压源如同心脏般重要,而Bandgap电路则是这颗心脏的核心技术。无论你是微电子专业的学生,还是刚踏入模拟…...

钉钉知识库日志迁移至Cursor的实践方法和具体操作步骤
一、钉钉知识库导出方法 方法1:手动导出(适合文档数量较少) 操作步骤: 电脑端钉钉 → 左下角【更多】→【文档】→【知识库】 进入目标知识库,打开需要迁移的文档 点击页面左上角 【文档】→【下载为】 选择导出格式:Word (.docx)、PDF 或 长图 文件默认以当前文档…...

终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题!
终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题! 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备无法…...

嵌入式数据存储终极指南:5分钟快速上手FlashDB超轻量级数据库
嵌入式数据存储终极指南:5分钟快速上手FlashDB超轻量级数据库 【免费下载链接】FlashDB An ultra-lightweight database that supports key-value and time series data | 一款支持 KV 数据和时序数据的超轻量级数据库 项目地址: https://gitcode.com/gh_mirrors/…...

用Python实现迷宫寻路:从BFS到‘灌水算法’的保姆级代码解析
Python迷宫寻路算法实战:从BFS到动态赋值的完整实现指南 迷宫寻路问题是计算机科学中经典的算法应用场景,也是游戏开发、机器人导航等领域的核心技术之一。本文将带领你从最基础的广度优先搜索(BFS)算法开始,逐步深入到…...

3步永久激活Windows和Office:开源智能脚本的完整指南
3步永久激活Windows和Office:开源智能脚本的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为电脑屏幕上频繁弹出的"需要激活"提示而烦恼吗?Offi…...

实战场景|一张表单看懂:段落布局才是企业表单 “清晰度天花板”
实战场景|一张表单看懂:段落布局才是企业表单 “清晰度天花板” 在企业级表单开发中,大家常常关注组件够不够用、布局够不够炫,却最容易忽略表单分段这件小事。而真正好用的表单,往往赢在细节 ——层次清晰、模块分明…...
)
大模型时代,小白程序员如何抓住机遇?阿里高薪Offer背后的大模型学习指南(收藏版)
文章主要介绍了阿里在大模型领域的强势发展,包括高薪Offer和招聘趋势,强调了AI技能的重要性。作者建议小白和程序员学习大模型技术,并推荐了“派聪明RAG项目”作为学习资源。同时,文章还探讨了AI工具的实际应用和挑战,…...
)
STM32单片机引脚功能详解——从GPIO到AFIO的标准库配置指南(硬件总结四)
前言 在STM32的开发中,引脚是MCU与外部电路交互的物理桥梁。STM32F103C8T6这款经典的Cortex-M3单片机在LQFP48封装下仅有48个引脚,却能支持GPIO、ADC、USART、SPI、I2C、定时器、USB等多种外设功能——这得益于其灵活的多功能引脚复用机制。深入理解引脚…...

RK3568扩展模块实战:4G/Wi-Fi 6/多串口集成与Linux驱动适配
1. 项目概述:当“小”模块遇上“大”平台最近在折腾一块瑞芯微的RK3568开发板,这板子性能不错,四核A55加上独立的NPU,做边缘计算、多媒体网关或者轻量级服务器都挺合适。但在实际项目落地时,我遇到了一个几乎所有硬件开…...