深度学习——常见注意力机制
1.SENet
SENet属于通道注意力机制。2017年提出,是imageNet最后的冠军
SENet采用的方法是对于特征层赋予权值。
重点在于如何赋权
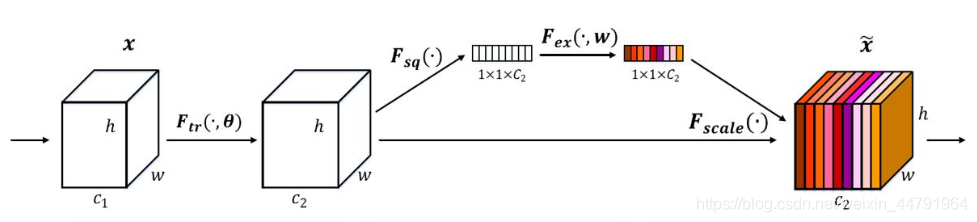
1.将输入信息的所有通道平均池化。
2.平均池化后进行两次全连接,第一次全连接链接的神经元较少,第二次全连接神经元数和通道数一致
3.将Sigmoid的值固定为0-1之间
4.将权值和特征层相乘。
import torch
import torch.nn as nn
import mathclass se_block(nn.Module):def __init__(self, channel, ratio=16):super(se_block, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // ratio, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // ratio, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y2.ECANet
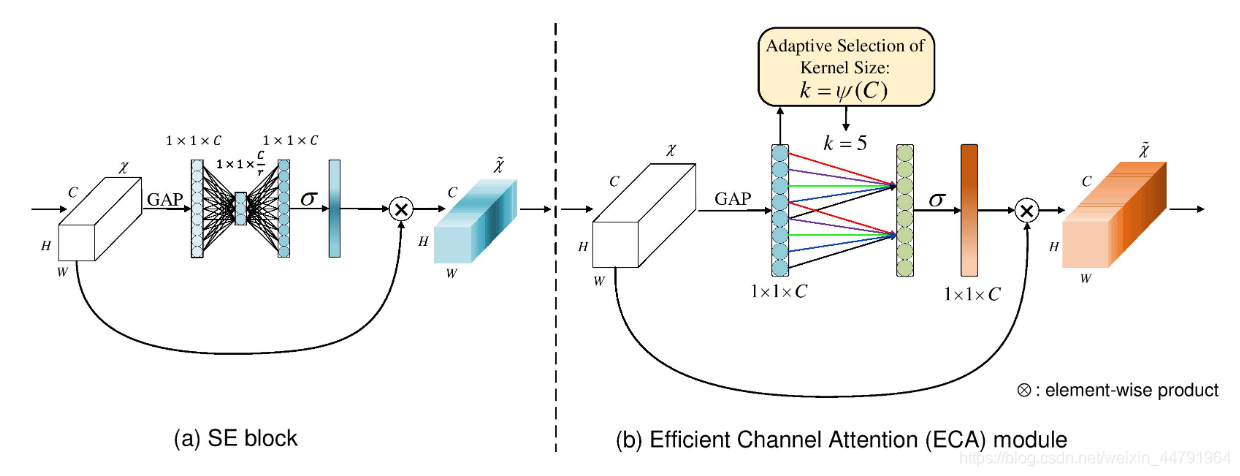
细心的人会发现,全连接其实是一个非常耗费算力的东西,对于边缘设备的压力非常大,所以ECANet觉得SENet并不需要那么多的全连接,我们直接在GAP后做一维卷积,而后取sigmoid为0-1来获取权值即可。
ECANet认为SE的全通道信息捕获是多此一举,而卷积就有很好的跨通道信息获取能力。
class eca_block(nn.Module):def __init__(self, channel, b=1, gamma=2):super(eca_block, self).__init__()kernel_size = int(abs((math.log(channel, 2) + b) / gamma))kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid()def forward(self, x):y = self.avg_pool(x)y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)y = self.sigmoid(y)return x * y.expand_as(x)4.GCNet
GCNet是我们项目的模型中使用的一种注意力机制
GCNet主要借鉴了SENet和NLNet的优点,主要基于NLNet,把NLNet的计算量削减了数倍
先看他是怎么用NLNet的
NLNet原公式
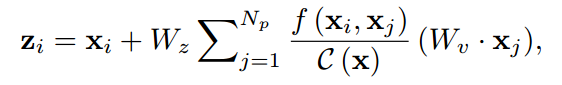
改进后的NLNet公式
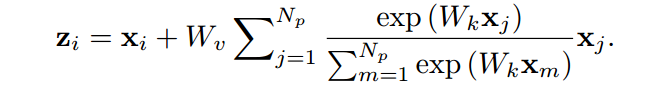
改进的区别就是去掉了Wz系数。
Wz系数的削减主要是对图像中的观察得出的创意。

作者说,attention map在不同位置上计算的结果几乎一致,那么我们只需要计算一次然后共享attention map应该也可以获得很好的效果,并且计算量可以下降到1/(W*H)。
Simple NL Block和NL Block的结构对比如图所示,并且经过文章的实验表明,简化后的性能与原本的性能相当。
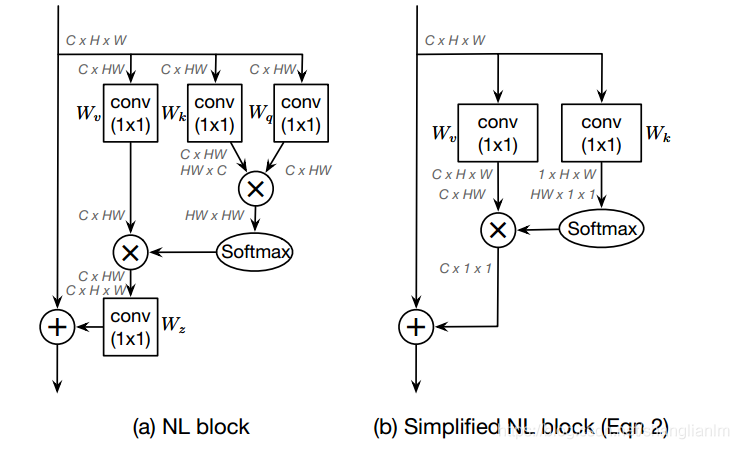
接着,作者基于S-NLNet和SENet的有点提出了GCNet
(1) 相比于SNL,SNL中的transform的1x1卷积在res5中是2048x1x1x2048,其计算量较大,所以借鉴SE的方法,加入压缩因子,为了更好的优化,还加入了layernorm。
(2)相比于SE,一方面是提取的全局信息更加充分(其实在后续的实验中说服力不是很强,单独avg pooling+add,只掉了0.3个点,但是更加简洁),另一方面则是加号和乘号的区别,而且在实验结果上,加号比乘号有显著的优势。
import torch
import torch.nn as nn
import torchvisionclass GlobalContextBlock(nn.Module):def __init__(self,inplanes,ratio,pooling_type='att',fusion_types=('channel_add', )):super(GlobalContextBlock, self).__init__()assert pooling_type in ['avg', 'att']assert isinstance(fusion_types, (list, tuple))valid_fusion_types = ['channel_add', 'channel_mul']assert all([f in valid_fusion_types for f in fusion_types])assert len(fusion_types) > 0, 'at least one fusion should be used'self.inplanes = inplanesself.ratio = ratioself.planes = int(inplanes * ratio)self.pooling_type = pooling_typeself.fusion_types = fusion_typesif pooling_type == 'att':self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)self.softmax = nn.Softmax(dim=2)else:self.avg_pool = nn.AdaptiveAvgPool2d(1)if 'channel_add' in fusion_types:self.channel_add_conv = nn.Sequential(nn.Conv2d(self.inplanes, self.planes, kernel_size=1),nn.LayerNorm([self.planes, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:self.channel_add_conv = Noneif 'channel_mul' in fusion_types:self.channel_mul_conv = nn.Sequential(nn.Conv2d(self.inplanes, self.planes, kernel_size=1),nn.LayerNorm([self.planes, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:self.channel_mul_conv = Nonedef spatial_pool(self, x):batch, channel, height, width = x.size()if self.pooling_type == 'att':input_x = x# [N, C, H * W]input_x = input_x.view(batch, channel, height * width)# [N, 1, C, H * W]input_x = input_x.unsqueeze(1)# [N, 1, H, W]context_mask = self.conv_mask(x)# [N, 1, H * W]context_mask = context_mask.view(batch, 1, height * width)# [N, 1, H * W]context_mask = self.softmax(context_mask)# [N, 1, H * W, 1]context_mask = context_mask.unsqueeze(-1)# [N, 1, C, 1]context = torch.matmul(input_x, context_mask)# [N, C, 1, 1]context = context.view(batch, channel, 1, 1)else:# [N, C, 1, 1]context = self.avg_pool(x)return contextdef forward(self, x):# [N, C, 1, 1]context = self.spatial_pool(x)out = xif self.channel_mul_conv is not None:# [N, C, 1, 1]channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))out = out * channel_mul_termif self.channel_add_conv is not None:# [N, C, 1, 1]channel_add_term = self.channel_add_conv(context)out = out + channel_add_termreturn outif __name__=='__main__':model = GlobalContextBlock(inplanes=16, ratio=0.25)print(model)input = torch.randn(1, 16, 64, 64)out = model(input)print(out.shape)4.CA注意力机制
CA机制也是和之前的GCNet一样对两个已有注意力(SENet和CBAM)进行了改进。
CA提出
1.SENet作为通道注意力机制,侧重通道之前的依赖关系,忽略了空间特征的作用。
2.CBAM可以一定程度弥补,但是CBAM对于长程依赖有待改进。
经过融合改进后,CA机制有以下优点
1、不仅考虑了通道信息,还考虑了方向相关的位置信息。
2、足够的灵活和轻量,能够简单的插入到轻量级网络的核心模块中。
CA机制的算法流程图如下
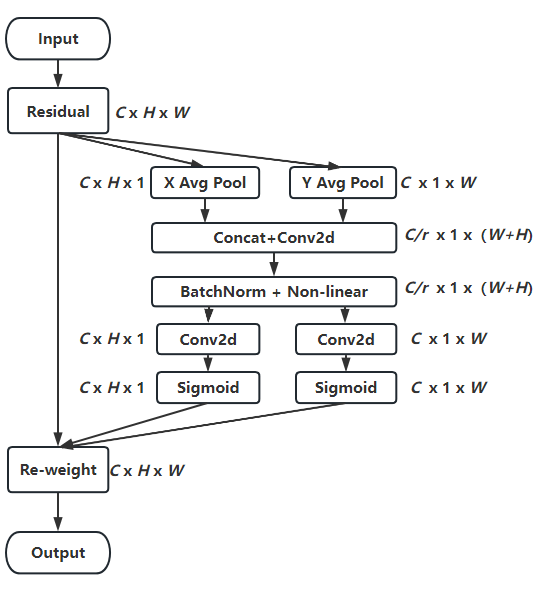
1.CA机制为了避免将空间特征全都压缩到通道中,放弃了全局平均池化,转为分别对x和y方向进行
别生成尺寸为C ∗ H ∗ 1 和C ∗ 1 ∗ W 的attention map
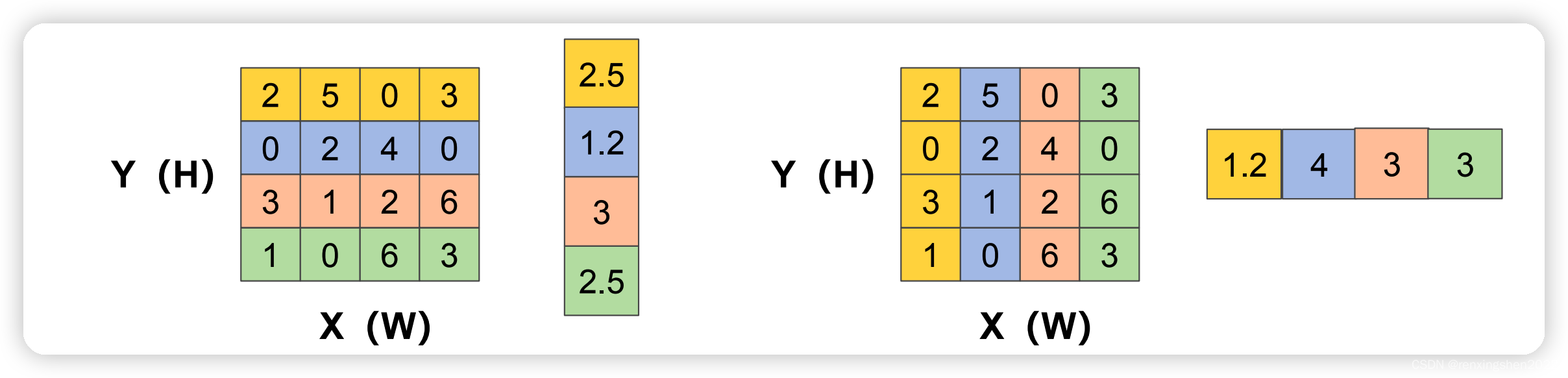
2.将生成的两个attention map进行池化,然后concat,然后进行F1操作(利用1*1卷积核进行降维,如SE注意力中操作)和激活操作,生成特征图f

这图怎么这么大?
3.沿着空间维度,再将f进行split操作,分别得到h和w的特征图后再用1 × 1卷积进行升维度操作,结合sigmoid激活函数得到最后的注意力向量gh和gw
代码
class CoordAtt(nn.Module):def __init__(self, inp, oup, groups=32):super(CoordAtt, self).__init__()self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // groups)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.conv2 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv3 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.relu = h_swish()def forward(self, x):identity = xn,c,h,w = x.size()x_h = self.pool_h(x)x_w = self.pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)y = self.conv1(y)y = self.bn1(y)y = self.relu(y) x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)x_h = self.conv2(x_h).sigmoid()x_w = self.conv3(x_w).sigmoid()x_h = x_h.expand(-1, -1, h, w)x_w = x_w.expand(-1, -1, h, w)y = identity * x_w * x_hreturn y明日:ODConv,数据结构复习,套磁老师
相关文章:
深度学习——常见注意力机制
1.SENet SENet属于通道注意力机制。2017年提出,是imageNet最后的冠军 SENet采用的方法是对于特征层赋予权值。 重点在于如何赋权 1.将输入信息的所有通道平均池化。 2.平均池化后进行两次全连接,第一次全连接链接的神经元较少,第二次全连…...

Python 进阶(七):高级文件操作(shutil 模块)
❤️ 博客主页:水滴技术 🌸 订阅专栏:Python 入门核心技术 🚀 支持水滴:点赞👍 收藏⭐ 留言💬 文章目录 1. 简介2. 常用函数2.1 复制文件2.2 复制目录2.3 移动文件或目录2.4 删除文件或目录2.…...
保留网络:大型语言模型的Transformer继任者
原文信息 原文题目:《Retentive Network: A Successor to Transformer for Large Language Models》 原文引用:Sun Y, Dong L, Huang S, et al. Retentive Network: A Successor to Transformer for Large Language Models[J]. arXiv preprint arXiv:2…...

算法通关村第二关——反转链表青铜笔记
LeetCode 206.反转链表 建立虚拟结点辅助翻转 public ListNode reverseList(ListNode head) {ListNode ans new ListNode(-1);ListNode cur head;while(cur!null){ListNode curNext cur.next;cur.next ans.next;ans.next cur;cur curNext;}return ans.next; }不带虚拟头…...
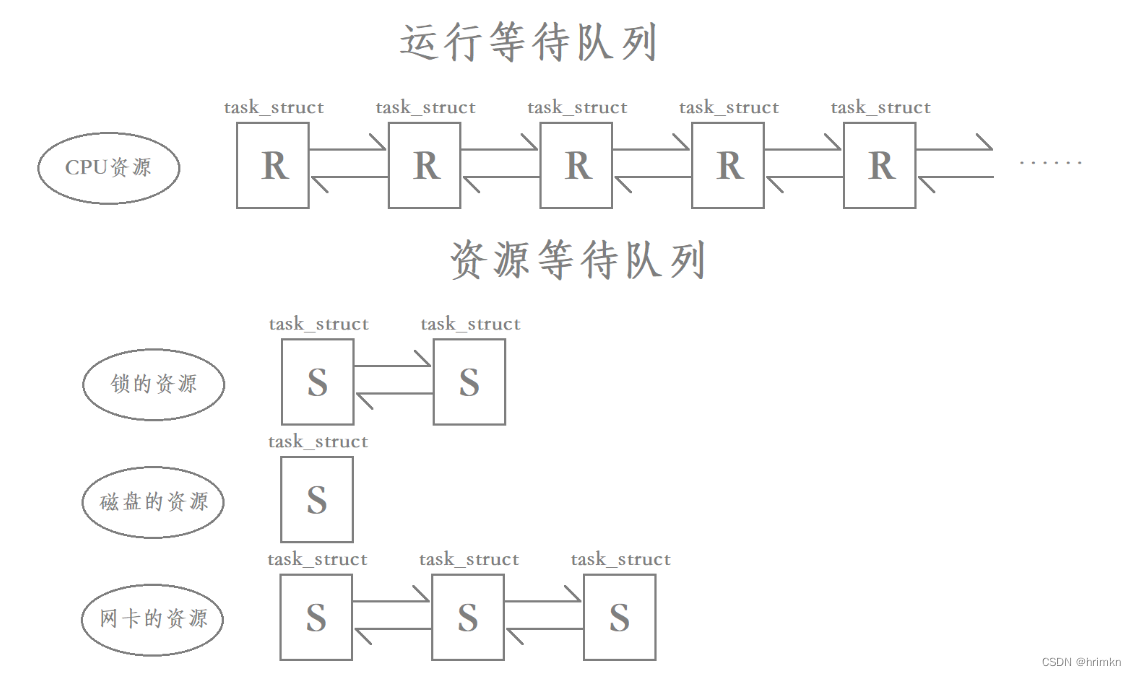
【Linux】——线程安全
目录 关于线程进程的问题 可重入与线程安全 常见的线程安全的情况 常见的不可重入的情况 常见的可重入的情况 可重入与线程安全区别 可重入与线程安全联系 Linux线程互斥 进程线程间的互斥相关概念 互斥量mutex 互斥量mutex常用接口 互斥量改造抢票系统 互斥量的原…...

[React]生命周期
前言 学习React,生命周期很重要,我们了解完生命周期的各个组件,对写高性能组件会有很大的帮助. Ract生命周期 React 生命周期分为三种状态 1. 初始化 2.更新 3.销毁 初始化 1、getDefaultProps() 设置默认的props,也可以用duf…...
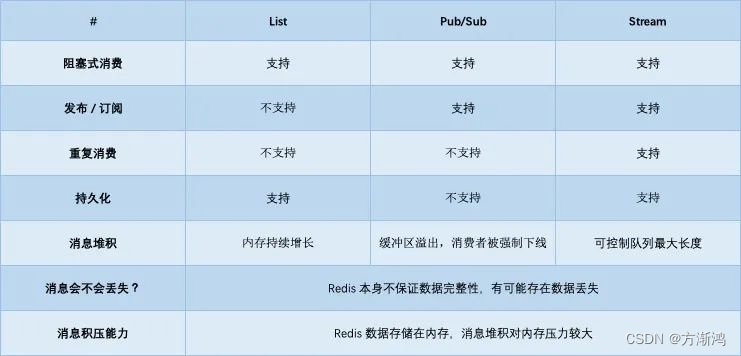
【2023】Redis实现消息队列的方式汇总以及代码实现
Redis实现消息队列的方式汇总以及代码实现 前言开始前准备1、添加依赖2、添加配置的Bean 具体实现一、从最简单的开始:List 队列代码实现 二、发布订阅模式:Pub/Sub1、使用RedisMessageListenerContainer实现订阅2、还可以使用redisTemplate实现订阅 三、…...

ARM裸机-10
1、X210开发板和光盘资料 1.1、配置信息 CPU:三星S5PV210 内存:512M DDR2 SDRAM Flash:4GB iBand LCD:7寸,分辨率800x480 触摸屏:电容触摸屏 2、X210开发板硬件手册 3、X210开发板刷系统 3.1、什么是刷…...

「C/C++」C/C++指针详解
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「UG/NX」NX二次开发「UG/NX」BlockUI集合「VS」Visual Studio「QT」QT5程序设计「C/C」C/C程序设计「Win」Windows程序设计「算法」数据结构与算法「File」数据文件格式 目录 一、术语…...

提高电脑寿命的维护技巧与方法分享
在维护电脑运行方面,我有一些自己觉得非常有用的技巧和方法。下面我将分享一些我常用的维护技巧,并解释为什么我会选择这样做以及这样做的好处。 首先,我经常清理我的电脑内部的灰尘。电脑内部的灰尘会影响散热效果,导致电脑发热…...

React常见面试题
React常见面试题 一、React中的样式管理有哪些方法 内联样式:对象,作用于当前组件普通样式表: 作用于全局,文件名是:xxx.scssCSS模块:类似Vue的scoped, 文件名需是:xxx.module.scs…...

C++中数据的输入输出介绍
C中数据的输入输出介绍 C中数据的输入输出涉及到的文件 <iostream>:这是C标准库中最常用的头文件之一,包含了进行标准输入输出操作的类和对象,如std::cin、std::cout、std::endl等。 <iomanip>:该头文件提供了一些用…...

0101日志-运维-mysql
1 错误日志 错误日志(Error Log):错误日志记录了MySQL引擎在运行过程中出现的错误和异常情况。这些错误可能包括启动和关闭问题、数据库崩溃、权限问题等。错误日志对于排查和解决MySQL引擎问题非常有帮助。 改日志默认开启,默认存…...

LabVIEW使用灰度和边缘检测进行视频滤波
LabVIEW使用灰度和边缘检测进行视频滤波 数字图像处理(DIP)是真实和连续世界的离散表示。除此之外,这种数字图像在通信、医学、遥感、地震学、工业自动化、机器人、航空航天和教育等领域变得非常重要。计算机技术越来越需要视频图像的数字图…...
SpringBoot整合WebService
SpringBoot整合WebService WebService是一个比较旧的远程调用通信框架,现在企业项目中用的比较少,因为它逐步被SpringCloud所取代,它的优势就是能够跨语言平台通信,所以还有点价值,下面来看看如何在SpringBoot项目中使…...

【LangChain】向量存储之FAISS
LangChain学习文档 【LangChain】向量存储(Vector stores)【LangChain】向量存储之FAISS 概要 Facebook AI 相似性搜索(Faiss)是一个用于高效相似性搜索和密集向量聚类的库。它包含的算法可以搜索任意大小的向量集,甚至可能无法容纳在 RAM 中…...
小研究 - 主动式微服务细粒度弹性缩放算法研究(三)
微服务架构已成为云数据中心的基本服务架构。但目前关于微服务系统弹性缩放的研究大多是基于服务或实例级别的水平缩放,忽略了能够充分利用单台服务器资源的细粒度垂直缩放,从而导致资源浪费。为此,本文设计了主动式微服务细粒度弹性缩放算法…...

驱动开发相关内容复盘
并发与竞争 并发 多个“用户”同时访问同一个共享资源。 竞争 并发和竞争的处理方法 处理并发和竞争的机制:原子操作、自旋锁、信号量和互斥体。 1、原子操作 原子操作就是指不能再进一步分割的操作,一般原子操作用于变量或者位操作。 …...

2.2 身份鉴别与访问控制
数据参考:CISP官方 目录 身份鉴别基础基于实体所知的鉴别基于实体所有的鉴别基于实体特征的鉴别访问控制基础访问控制模型 一、身份鉴别基础 1、身份鉴别的概念 标识 实体身份的一种计算机表达每个实体与计算机内部的一个身份表达绑定信息系统在执行操作时&a…...

C++ 注释
程序的注释是解释性语句,您可以在 C 代码中包含注释,这将提高源代码的可读性。所有的编程语言都允许某种形式的注释。 C 支持单行注释和多行注释。注释中的所有字符会被 C 编译器忽略。 C 注释一般有两种: // - 一般用于单行注释。 /* … …...

SPEC CPU 2017基准测试深度解析:从原理到实战调优
1. 项目概述:一次性能基准测试的巅峰对决最近在服务器和芯片圈子里,一个消息炸开了锅:曙光服务器在SPEC CPU 2017基准测试中,一口气刷新了四项世界纪录。对于圈外人来说,这可能只是一条普通的科技新闻,但对…...
)
【计算机组成原理】无符号整数乘法原理(基于移位累加,零基础看懂CPU乘法)
前言在数字电路与计算机组成原理中,加法是最基础的运算,而乘法是高频常用运算。很多初学者疑惑:计算机没有专门的乘法口诀,到底怎么实现二进制乘法?而在数字运算中,乘法是比加法更复杂、但底层逻辑完全依托…...
)
手把手教你用Vector CANape创建第一个AUTOSAR ECU测量工程(附A2L文件配置避坑点)
从零构建AUTOSAR ECU测量工程:Vector CANape实战指南与A2L文件深度解析 在汽车电子开发领域,ECU数据测量与标定是功能验证和性能优化不可或缺的环节。作为Vector工具链中的核心组件,CANape凭借其强大的实时数据采集和分析能力,已成…...

2026降AI率工具红黑榜:降AIGC工具怎么选?照着用就行!
2026年论文降AI率工具竞争激烈,千笔AI、ThouPen、豆包凭借精准适配国内高校AI率检测规范成为红榜首选。黑榜需警惕低质免费工具、无正规检测对接、改写痕迹生硬的产品。选择时应综合考量(降AI效果 - 学术合规性 - 使用成本)三维模型ÿ…...

别再死记硬背了!用这个班级排名的例子,5分钟搞懂R语言dplyr包的四种join函数
班级运动会排名解析:用生活案例彻底掌握R语言dplyr连接函数 刚接触R语言的数据合并操作时,那些inner_join、left_join的术语总让人望而生畏。但数据连接的本质,其实就像学校运动会后整理各班成绩一样简单。想象你手上有两个班级的排名表和运动…...

BiliTools:重新定义B站内容消费的技术解决方案
BiliTools:重新定义B站内容消费的技术解决方案 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 你是否曾…...

CXPatcher:让Mac上的CrossOver性能飞升的终极指南
CXPatcher:让Mac上的CrossOver性能飞升的终极指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 你是否曾经在Mac上尝试运行Windows游戏时感到…...

CANN/asc-devkit SoftMax接口
SoftMax 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

深度解析XGBoost环境配置:从零构建高性能梯度提升库
深度解析XGBoost环境配置:从零构建高性能梯度提升库 【免费下载链接】xgboost Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C and more. Runs on single machine, Hadoop, Spark, Dask, Flink…...

CANN hcomm通道获取API
HcclChannelAcquire 【免费下载链接】hcomm HCOMM(Huawei Communication)是HCCL的通信基础库,提供通信域以及通信资源的管理能力。 项目地址: https://gitcode.com/cann/hcomm 产品支持情况 Ascend 950PR/Ascend 950DT:支…...