D2L学习记录-10-词嵌入word2vec
NLP-1-词嵌入(word2vec)
参考:
《动手学深度学习 Pytorch 第1版》第10章 自然语言处理 第1、2、3 和 4节 (词嵌入)
词嵌入 (word2vec):
- 词向量:自然语言中,词是表义的基本单元。词向量是用来表示词的向量。
- 词嵌入 (word embedding):将词映射为实数域向量的技术称为词嵌入。
- 词嵌入出现的原因:由于
one-hot编码的词向量不能准确表达不同词之间的相似度(任何两个不同词的one-hot向量的余弦相似度都为0),为了解决这个问题而出现了词嵌入方法word2vec。word2vec将每个词表示为一个定长的向量,而且这些向量能够表达不同词之间的相似性。word2vec包含两个模型:跳字模型 (skip-gram) 和 连续词袋模型 (continuous bag of words, CBOW)。
skip-gram
skip-gram:基于某个词来生成它在文本序列周围的词,即以某个词为中心,与距离该中心不超过窗口大小的背景词出现的条件概率。- 在
skip-gram中,每个词被表示为两个d维向量(中心词的向量和背景词的向量),用以计算背景词出现的条件概率。 skip-gram训练结束后,对于任意一个索引为i的词,都可得到该词为中心词和背景词的两组向量 v i v_i vi和 u i u_i ui。- 在 NLP 中,一般使用
skip-gram的中心词向量作为词的表征向量。
CBOW
CBOW与skip-gram类似,但最大区别在于CBOW基于某个中心词在文本序列前后的背景词来生成该中心词。【简单来说:skip-gram假设基于中心词来生成背景词;CBOW假设基于背景词来生成中心词】CBOW中,因为背景词有多个,所以将这些背景词向量取平均,再使用和skip-gram一样的方法计算条件概率。- 在 NLP 中,一般使用
CBOW的背景词向量作为词的表征向量。
word2vec 的整个过程实现:
1. word2vec 的数据集的预处理:
所用数据集是 Penn Tree Bank (PTB),该语料库曲取自“华尔街日报”。
1.1 下载数据集:
## 导入模块
import math
import os
import random
import torch
from d2l_model import d2l_torch as d2l
## 使用 d2l 封装的方法下载 PTB 数据集
d2l.DATA_HUB["ptb"] = (d2l.DATA_URL + 'ptb.zip','319d85e578af0cdc590547f26231e4e31cdf1e42')def read_ptb():data_dir = d2l.download_extract("ptb") ## 该方法用来读取zip或者tar文件,返回的数据所在的路径with open(os.path.join(data_dir, "ptb.train.txt")) as f:raw_text = f.read()return [line.split() for line in raw_text.split("\n")] ## 返回文本中每一行句子中以空格分开的每个词所构成的列表#sentences = read_ptb()
#f'# sentences数: {len(sentences)}'
1.2 下采样:
删掉文本中某些高频词,缩短句子长度,加快训练。
def subsample(sentences, vocab):sentences = [[token for token in line if vocab[token]!=vocab.unk] for line in sentences] ## 如果 token 不是 <unk> 的话,就会被保留下来counter = d2l.count_corpus(sentences) ## 统计 token 出现的次数num_tokens = sum(counter.values())def keep(token):return (random.uniform(0,1) < math.sqrt(1e-4 / counter[token]*num_tokens)) ## 如果满足条件,则返回Truereturn ([[token for token in line if keep(token)] for line in sentences], counter)
1.3 中心词和上下文词的提取:
从 corpus 中提取所有中心词和上下文词。
随机采样[1:max_window_size]之间的证书作为上下文窗口。
对于任意一个中心词,与其不超过上下文窗口大小的词为它的上下文词。
def get_centers_and_contexts(corpus, max_window_size):centers, contexts = [], []for line in corpus:if len(line) < 2: ## 要构成“中心词-上下文词”对,每个句子至少有2个词continuecenters += line ## 所有句子中的每一个词都可作为中心词for i in range(len(line)):window_size = random.randint(1, max_window_size) ## 生成一个随机整数作为窗口大小indices = list(range(max(0, i-window_size), min(len(line), i+1+window_size))) ## 以i为中心,获取[i-window: i+window]范围内的词indices.remove(i) ## 去掉中心词i本身,剩下上下文词contexts.append([line[idx] for idx in indices])return centers, contexts
1.4 负采样:
使用负采样进行近似训练,根据定义的分布对噪声词进行采样。
class RandomGenerator:def __init__(self, sampling_weights):self.population = list(range(1, len(sampling_weights)+1))self.sampling_weights = sampling_weightsself.candidates = []self.i = 0def draw(self):if self.i == len(self.candidates):## 缓存 k 个随机采样结果,每次从里面取一个,取完后再生成新的缓存结果self.candidates = random.choices(self.population, self.sampling_weights, k=10000) ## 按照 sampling_weight 采样概率对 population 进行采样,采样k次self.i = 0self.i += 1return self.candidates[self.i-1]
## 负采样
def get_negatives(all_contexts, vocab, counter, K):sampling_weights = [counter[vocab.to_tokens(i)]**0.75 for i in range(1, len(vocab))] ## 采样权重 = token出现次数 * 0.75all_negatives, generator = [], RandomGenerator(sampling_weights)for contexts in all_contexts:negatives = []while len(negatives) < len(contexts) * K: ## K 对于一对“中心词-上下文词”,随机抽取的噪声词的个数neg = generator.draw()if neg not in contexts: ## 噪声词不能是该中心词的上下文词,其他的上下文词是可以的negatives.append(neg)all_negatives.append(negatives)return all_negatives
1.5 定义 dataloader 的处理方式:
class PTBDataset(torch.utils.data.Dataset):def __init__(self, centers, contexts, negatives):assert len(centers) == len(contexts) == len(negatives) ## 不成立则引发AssertionErrorself.centers = centersself.contexts = contextsself.negatives = negativesdef __getitem__(self, index):return (self.centers[index], self.contexts[index], self.negatives[index])def __len__(self):return len(self.centers)def batchify(data):max_len = max(len(c) + len(n) for _, c, n in data) ## 因为不同中心词对应的上下文、负采样的向量长度不一样,所以按照最长的进行填充centers, contexts_negatives, masks, labels = [], [], [], []for center, context, negative in data: ## 中心词、上下文、负采样cur_len = len(context) + len(negative)centers += [center]contexts_negatives += [context + negative + [0]*(max_len - cur_len)] ## 用0进行填充masks += [[1]*cur_len + [0]*(max_len - cur_len)] ## 填充部分用0标记,非填充部分用1标记 (主要用于计算损失时,填充部分不参与计算)labels += [[1]*len(context) + [0]*(max_len - len(context))] ## 标签,上下文词为1,其他(负采样部分、填充部分)为0return (torch.tensor(centers).reshape((-1,1)),\torch.tensor(contexts_negatives),\torch.tensor(masks),\torch.tensor(labels)) ## reshape((-1,1)) => .shape=(n,1)## 中心词(centers), 上下文及负采样(context_negatives), 掩码(masks),标签(labels)
代码合并及数据集的生成:
包括上面的1.1, 1.2, 1.3, 1.4, 1.5
def load_data_ptb(batch_size, max_window_size, num_noise_words):#num_workers = d2l.get_dataloader_workers() ## 使用4个进程读取数据(但实际操作会出错)sentences = read_ptb() ## 第一步的读取数据vocab = d2l.Vocab(sentences, min_freq=10) ## 第一步中用 "<unk>" 替换低频词subsampled, counter = subsample(sentences, vocab) ## 第二步下采样,去掉某些意义不大的高频词,缩短句子长度corpus = [vocab[line] for line in subsampled] ## 第二步将下采样后的句子映射为词表中的索引all_centers, all_contexts = get_centers_and_contexts(corpus, max_window_size) ## 第三步,中心词和上下文词(上或下文词数目不超过max_window_size)all_negatives = get_negatives(all_contexts, vocab, counter, num_noise_words) ## 第四步负采样,生成噪声词dataset = PTBDataset(all_centers, all_contexts, all_negatives)data_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True,collate_fn=batchify, ## collate_fn 定义了小批量数据加载后需要做的处理(可见http://t.csdn.cn/4zhEj 的评论)num_workers=0)return data_iter, vocab
## 生成数据集
batch_size, max_window_size, num_noise_words = 512, 5, 5
data_iter, vocab = load_data_ptb(batch_size, max_window_size, num_noise_words)
2. 预训练 word2vec:
构建并训练模型。
from torch import nn
2.1 构建嵌入层:
- 嵌入层将词元的索引映射到其特征向量 (上面数据预处理已经得到了词元的索引)。
- 嵌入层的权重是一个矩阵,行数等于字典大小,列数等于向量的维数。
- 在嵌入层训练完成之后,权重矩阵就是所需要的。每一行都是一个词的特征向量。
- 该层的输入就是词元的索引,对于任何词元索引 i i i,其向量表示可以从嵌入层中的权重矩阵的第 i i i行获得。
2.2 定义 skip-gram:
通过 embedding 层将索引映射为特征向量。
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):v = embed_v(center)u = embed_u(contexts_and_negatives)pred = torch.bmm(v, u.permute(0,2,1))return pred
2.3 定义二元交叉熵损失函数:
class SigmoidBCELoss(nn.Module):def __init__(self):super().__init__()def forward(self, inputs, target, mask=None):out = nn.functional.binary_cross_entropy_with_logits(inputs, target, weight=mask, reduce="none")return out.mean()loss = SigmoidBCELoss()
2.3 定义初始化模型参数:
## 两个嵌入层,特征向量维度为100
## 第一层计算中心词,第二层计算上下文词embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),embedding_dim=embed_size),nn.Embedding(num_embeddings=len(vocab),embedding_dim=embed_size))
2.4 训练:
## 定义训练函数
def train(net, data_iter, lr, num_epochs, device=d2l.try_gpu()):## 模型初始化def init_weights(m):if type(m) == nn.Embedding:nn.init.xavier_uniform_(m.weight) ## 函数最后有一个下划线表示该函数输出直接替换net.apply(init_weights)net = net.to(device)optimizer = torch.optim.Adam(net.parameters(), lr=lr)animator = d2l.Animator(xlabel="epoch", ylabel="loss", xlim=[1, num_epochs]) ## 训练过程中的 epoch-loss 进行可视化metric = d2l.Accumulator(2) ## 加快求和计算的速度for epoch in range(num_epochs):timer, num_batches = d2l.Timer(), len(data_iter)for i, batch in enumerate(data_iter):optimizer.zero_grad()center, conter_negative, mask, label = [data.to(device) for data in batch]pred = skip_gram(center, conter_negative, net[0], net[1])l = (loss(pred.reshape(label.shape).float(), label.float(), mask) / mask.sum(axis=1)*mask.shape[1])l.sum().backward()optimizer.step()metric.add(l.sum(), l.numel())if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i+1)/num_batches, (metric[0]/metric[1],))print(f'loss {metric[0] / metric[1]:.3f}, 'f'{metric[1] / timer.stop():.1f} tokens/sec on {str(device)}')
## 进行训练
lr, num_epochs = 0.001, 10
train(net, data_iter, lr, num_epochs)
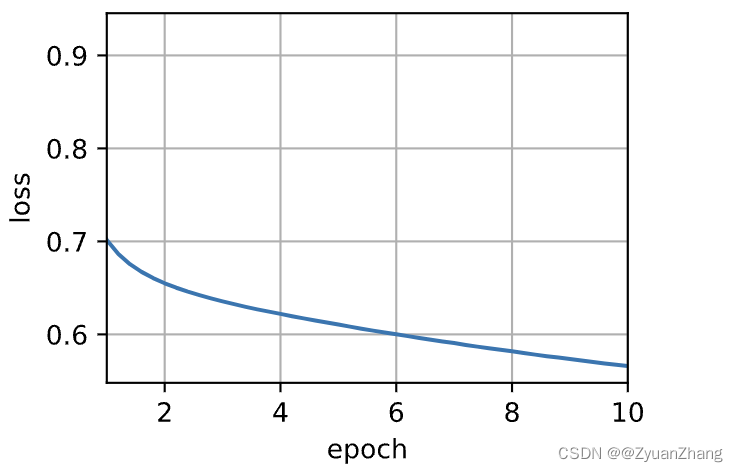
loss 0.566, 223737.2 tokens/sec on mps
3. 使用预训练的word2vec寻找语义上相近的词:
def get_similar_tokens(query_token, k, embed):W = embed.weight.data ## 我们预训练词嵌入就是为了得到这个权重矩阵,该权重矩阵就是由每个词的特征向量构成的x = W[vocab[query_token]]## 计算余弦相似度cos = torch.mv(W,x) / torch.sqrt(torch.sum(W*W, dim=1) * torch.sum(x*x)+1e-9)topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype("int32")for i in topk[1:]:print(f'cosine sim={float(cos[i]):.3f}: {vocab.to_tokens(i)}')get_similar_tokens('chip', 3, net[0])
cosine sim=0.777: intel
cosine sim=0.714: bugs
cosine sim=0.647: computer
相关文章:
D2L学习记录-10-词嵌入word2vec
NLP-1-词嵌入(word2vec) 参考: 《动手学深度学习 Pytorch 第1版》第10章 自然语言处理 第1、2、3 和 4节 (词嵌入) 词嵌入 (word2vec): 词向量:自然语言中,词是表义的基本单元。词向量是用来表示词的向量。词嵌入 (word embedding)&#x…...

海外独立站怎么搭建?7个海外独立站搭建指南
在海外搭建独立站(独立网站)有几个关键步骤,以下是一个简要的指南: 选择域名和主机: 首先,选择一个适合你网站主题的域名。确保它简洁、易记,并且与你的品牌或内容相关联。 然后,…...

flask中实现restful-api
flask中实现restful-api 举例,我们可以创建一个用于管理任务(Task)的API。在这个例子中,我们将有以下API: GET /tasks: 获取所有任务POST /tasks: 创建一个新的任务GET /tasks/<id>: 获取一个任务的详情PUT /t…...

Centos7 安装man中文版手册
查找man中文安装包: yum search man-pages 安装man-pages-zh-CN.noarch: yum install -y man-pages-zh-CN.noarch...

untiy代码打压缩包,可设置密码
1、简单介绍: 用的是一个插件SharpZipLib,在vs的Nuget下载,也可以去github下载https://github.com/icsharpcode/SharpZipLib 用这个最主要的是因为,这个不用请求windows的文件读写权限,关于这个权限我搞了好久&#…...
【iOS】—— UIKit相关问题
文章目录 UIKit常用的UIKit组件懒加载的优势 CALayer和UIView区别关系 UITableViewUITableView遵循的两个delegate以及必须实现的方法上述四个必须实现方法执行顺序其他方法的执行顺序: UICollectionView和UITableView的区别UICollectionViewFlowLayout和UICollecti…...

Linux系统防火墙Firewalld
目录 Firewalld概述 Firewalld和iptables的区别 Firewalld网络区域 区域介绍与概念 9个预定义区域 Firewalld数据处理流程 firewalld检查数据包的源地址的规则 Firewalld防火墙的配置方式 常用的firewall-cmd命令选项 服务管理 端口管理 Firewalld概述 Firewalld防火…...
)
STM3232 GPIO的配置寄存器(为了移植IIC)
参考 https://blog.csdn.net/qq_45539458/article/details/129481019 https://blog.csdn.net/weixin_43314829/article/details/125573448?spm1001.2014.3001.5502 https://blog.csdn.net/m0_71548440/article/details/125894236?spm1001.2014.3001.5502 正点原子mini板 stm…...
K8s的详细介绍
1.编写yaml文件的方式 2.yaml里面的内容介绍 Pod实现机制:(1)共享网络(2)共享存储 共享网络:通过Pause容器,把其他业务容器加入到Pause容器里面,让所有业务容器在同一个名称空间中,…...
JavaWeb(8)——前端综合案例2(节流和防抖)
目录 一、节流和防抖概念 🚀 二、实例演示 💘 三、需要注意的 📡 一、节流和防抖概念 🚀 二、实例演示 💘 Lodash 简介 | Lodash中文文档 | Lodash中文网 (lodashjs.com) <!DOCTYPE html> <html lang&q…...
Spring优雅的在事务提交/回滚前后插入业务逻辑
业务背景 业务那边想要统计下我们这边每天注册商户成功和失败的数量,你看看怎么给他弄下这个功能 功能实现 TransactionSynchronizationManager.registerSynchronization,发现这是spring事务提供的注册回调接口的方法。 在事务注解方法中,…...
day48-ajax+SSM分页
AjaxSSM分页 非分页版controller及html: 分页模糊查询controller: Postman测试(无网页): 分页网页: 分页网页中添加模糊查询: 分页网页中实现添加功能: (1&am…...

如何在本地环境使用 CodeQL 扫描出代码中的安全漏洞?
CodeQL 是什么? CodeQL 是用于自动执行安全检查的分析引擎。在 CodeQL 中,代码被视为数据。 安全漏洞、bug 和其他错误被建模为可针对从代码中提取的数据库执行的查询。可以运行由 Github 研究人员和社区参与者编写的标准 CodeQL 查询,也可以…...
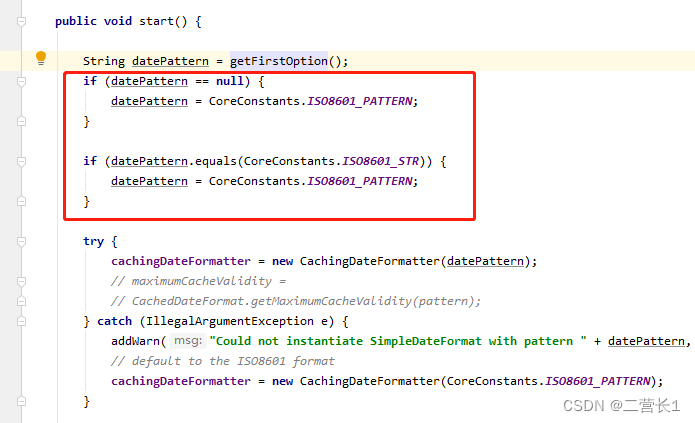
关于领导要求logback日志时间格式要求为“年-月-日 时:分:秒,毫秒”
今天接到领导邮件要求整改系统输出日志规范,有一条要求调整输出日志时间格式为标题所述格式,例:2022-02-21 14:13:32,489 项目目前logback.xml里的配置是这样: <pattern>%d{yyyyMMdd hh:mm:ss} [%p][%c][%M][%L]-> %m%…...

软件测试--一些生命周期
目录 1.需求生命周期 2.开发生命周期 3.测试生命周期 4.缺陷声生命周期 1.需求生命周期 需求生命周期是指在软件测试过程中,需求从提出到最终完成的整个过程。它涵盖了需求的识别、分析、定义、验证和管理等阶段。 需求识别:在此阶段,项目…...
Mr. Cappuccino的第57杯咖啡——简单手写Mybatis大致原理
简单手写Mybatis大致原理 大致原理项目结构项目代码代码测试 大致原理 底层基于JDK动态代理技术实现 项目结构 项目代码 pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns…...

机房环境、动力、网络、安防,帮您提高运维效率,确保机房安全
机房作为单位的核心部门,由计算机、服务器、网络设备、存储设备等关键设备组成,智能化计算机机房这个概念在各个领域中,已经占据了很重要的地位,伴随着国家大力倡导的,东数西算,数字经济、云计算、5G大数据…...

大数据课程E1——Flume的概述
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Ganglia的概念; ⚪ 了解Ganglia的拓扑结构和执行流程; ⚪ 掌握Ganglia的安装操作; 一、简介 1. 概述 1. Flume原本是由Cloudera公司开发的后来贡献给了Apache的一套分布式的、可…...

01.Redis实现发送验证码
学习目标: 提示:学习如何利用Redis来实现发送验证码功能 学习产出: 1. 准备pom环境 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><…...

Vue中对组件的调用
在Vue中,你可以在一个页面中调用其他组件,以实现组件的复用和组合效果。以下是在Vue中实现调用页面组件的几种常见方法之一: 1.使用Vue的组件标签: 你可以在Vue的模板中使用已注册的组件标签,以调用和渲染其他组件。首…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...
)
Perplexity历史资料搜索失效真相大起底(时间戳偏移、缓存策略与知识图谱断层深度解析)
更多请点击: https://intelliparadigm.com 第一章:Perplexity历史资料搜索失效真相大起底(时间戳偏移、缓存策略与知识图谱断层深度解析) Perplexity 的历史资料检索能力在近期高频出现“查无结果”或“返回过期摘要”现象&#…...

AI 智能体 8 层架构:生产级系统构建指南
AI 智能体(Agentic AI)革命的关键不在更好的提示词,而在于系统化的架构设计。随着企业竞相部署能够自主感知、推理、规划和行动的 AI 智能体(AI Agent),真正的挑战已经从"我们能构建吗?“转变为"…...

Taotoken用量看板与账单追溯为团队开发带来的成本管控体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与账单追溯为团队开发带来的成本管控体验 对于依赖大模型API进行开发的团队而言,成本的可观测与可控性…...

Cadence Virtuoso计算器函数面板:从仿真波形到关键指标,手把手教你提取运放GBW和相位裕度
Cadence Virtuoso计算器函数实战:运放AC特性自动化评估指南 在模拟电路设计的日常工作中,我们常常需要面对这样的场景:完成运放AC仿真后,面对密密麻麻的波形曲线,如何快速准确地提取出增益带宽积(GBW)和相位裕度(PM)这…...
)
告别手动挖洞:用Netsparker自动化扫描你的Web应用(附实战报告解读)
告别手动挖洞:用Netsparker自动化扫描你的Web应用(附实战报告解读) 在快节奏的Web开发环境中,安全测试往往成为项目后期被压缩的环节。传统手动渗透测试需要安全专家投入数十小时,而中小团队常面临资源不足的困境。Net…...

如何通过Excel MCP Server实现无Excel环境下的自动化表格处理
如何通过Excel MCP Server实现无Excel环境下的自动化表格处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否曾因没有安装Microsoft Excel而无…...

体验Taotoken多模型路由带来的高稳定性与低延迟响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型路由带来的高稳定性与低延迟响应 在构建依赖大模型能力的应用时,开发者最关心的两个核心指标往往是…...
)
51单片机入门实战:用Keil+Proteus做个带蜂鸣器报警的按键计数器(附完整代码)
51单片机实战:从零构建带蜂鸣器报警的按键计数器 项目背景与核心功能 对于刚接触51单片机的开发者来说,独立完成一个小型综合项目往往能带来巨大的成就感。这次我们要实现的是一个结合按键计数、数码管显示和蜂鸣器报警的完整系统。当用户按下按键时&a…...

2026产品专员学习数据分析的价值与路径
一、数据分析对产品专员的核心价值数据分析能力帮助产品专员量化用户行为、验证假设并优化产品决策。通过数据驱动的方法,减少主观猜测,提升需求优先级判断的准确性。掌握基础分析工具(如Excel、SQL)和可视化工具(如Ta…...