4 Promethues监控主机和容器
目录
目录
1. 监控节点
1.1 安装Node exporter
解压包
拷贝至目标目录
查看版本
1.2 配置Node exporter
1.3 配置textfile收集器
1.4 启动systemd收集器
1.5 基于Docker节点启动node_exporter
1.6 抓取Node Exporter
1.7 过滤收集器
2. 监控Docker容器
2.1 运行cAdvisor
2.2 抓取cAdvisor
2.3 Node Exporter和cAdvisor指标
2.3.1 USE方法
CPU利用率
计算每种CPU模式的每秒使用率
计算每台主机的平均CPU使用率
计算每个主机5分钟范围内使用率的平均百分比
CPU饱和度
计算mode模式为idle的主机上的CPU数量,使用count函数做聚合:
计算CPU饱和度
内存使用率
计算可用内存的百分比
内存饱和度
计算内存饱和度
磁盘使用率
计算主机使用磁盘空间的百分比
使用正则表达式匹配多个挂载点
计算未来使用磁盘空间趋势(提前规避磁盘用尽的风险)
2.3.2 服务状态
查看docker服务状态
查看已经active的docker
2.3.3 可用性和up指标
2.3.4 metadata指标
2.4 查询持久性
2.4.1 记录规则
配置记录规则
添加记录配置
更新规则组为每10秒运行一次
3. 可视化
3.1 安装Grafana
3.1.1 在Ubuntu上安装Grafana
3.1.2 启动和配置Grafana
3.1.3 配置Grafana Web界面
采用Prometheus作为数据源
点击Data sources
add data source
配置Promethues地址编辑
保存并测试配置
3.1.4 使用仪表板
Add visualization
选择data sources
选择指标查询,并保存
仪表盘查看图表结果
图标结果
这里将在1台运行docker守护进程的unbuntu主机上进行演示。我们将在主机上安装exporter,然后配置节点和Docker指标让Promethues来抓取。
基本的主机资源监控,包括:
- CPU
- 内存
- 磁盘
- 可用性
当然月可以使用Grafana,并对收集的数据进行基本的可视化。
1. 监控节点
Promethues使用exporter工具来暴露主机和服务上的指标,目前有很多用于各种目的的exporter。Node exporter是Go语言编写的,提供了一个可用于收集各种主机指标数据(含CPU、内存和磁盘)的库。它还有个textfile收集器,允许导出静态指标。
在监控中有时候术语“节点”可以用来指代主机。
除了exporter,还有其他支持Promethues的主机监控客户端,如collectd。
在linux主机上,下载并安装Node exporter,同时选择一个Docker守护进程主机。
官方下载地址:Releases · prometheus/node_exporter · GitHub
1.1 安装Node exporter
解压包
tar -xzf node_exporter-1.6.0.linux-amd64.tar.gz
拷贝至目标目录
sudo cp node_exporter-1.6.0.linux-amd64/node_exporter /usr/local/bin/查看版本
/usr/local/bin/
1.2 配置Node exporter
可以通过参数来对node_exporter进行配置,使用--help查看完整的参数列表。
node_exporter --help默认情况下,node_exporter在端口9100上运行,并在路径/metrics上暴露指标。可以通过--web.listen-address和-web.telemetry-path参数来设置端口和路径,如下所示:
node_exporter --web.listen-address=":9600" --web.telemetry-path="/node_metrics"这会将node_exporter绑定到端口9600并在路径、node-metrics上暴露指标。

通过浏览器访问,已经暴露以下指标

可以看到以上有许多指标,也就是说许多收集器默认都是启用的。可以通过使用 no- 前缀来修改状态。如暴露/proc/net/arp 统计信息的arp收集器是默认启动的,可以通过参数 --collector.arp控制。禁止次收集器,需要运行如下指令:
node_exporter --web.listen-address=":9600" --web.telemetry-path="/node_metrics" --node-collector.arp
1.3 配置textfile收集器
textfile收集器非常有用,它允许我们暴露自定义指标。这些自定义指标可能是批处理或cron作业等无法抓起的,可能是没有exporter的源,甚至可能是为主机提供上下文的静态指标。
收集器通过扫描指定目录中的文件,提取所有格式为Promethues指标的字符串,然后暴露它们以便抓取。
在设置收集器前,需要先创建一个目录来保存指标定义文件。
sudo mkdir -p /var/lib/node_exporter/textfile_collector现在在该目录中创建一个新指标,指标在以.prom结尾的文件内定义,并且使用Promethues的特定文本格式。
特定的文本格式允许指定Promethues支持的所有指标类型,即计数型、测量型、计时型等。
我们使用此格式创建一个包含有关此主机的元数据指标。
metadata{role="docker_server",datacenter="CD"} 1这里包含了一个指标名称(metadata)和两个标签。一个标签role定义节点的角色。在示例中,标签的值为docker_server。另一个标签datacenter定义主机的地理位置在成都。最后,指标的值为1,表示该指标不是计数型、测量型或计时型,而是提供上下文。
接着将指标添加到textfile_collector目录下的metadata.prom文件中。
echo 'metadata{role="docker_server",datacenter="CD"} 1'|sudo tee /var/lib/node_exporter/textfile_collector/metadata.prom
当然在真实环境中,建议使用配置管理工具来编辑该文件。比如在配置新主机时,可以从模板创建元数据指标,这样可以自动对主机和服务进行分类。
Node exporter默认加载textfile收集器,不需要通过参数指定textfile收集器,但需要指定textfile_exporter目录,以便于Node exporter知道在哪里可以找到自定义指标。因此,需要指定--collector.textfile.directory参数。
node_exporter --web.listen-address=":9600" --web.telemetry-path="/node_metrics" --no-collector.arp --collector.textfile.directory="/var/lib/node_exporter/textfile_collector"以上配置指定了textfile收集器地址,能看到对应的结果如下:
1.4 启动systemd收集器
systemd收集器记录systemd中的服务和系统状态。这个收集器收集了很多指标,当我们不想收集其所有指标时,可以指定指标进行收集。如下我们将特定的服务列入白名单,智手机以下服务的指标:
- docker.service ,Docker守护进程
- ssh.service ,SSH守护进程
- rsyslog.service ,RSyslog守护进程
使用--collerctor.systemd.unit-whitelist参数来进行配置,它会匹配systemd的正则表达式。
1.5 基于Docker节点启动node_exporter
node_exporter --web.listen-address=":9600" --collector.textfile.directory /var/lib/node_exporter/textfile_collector --collector.systemd --collector.systemd.unit-whitelist="(docker|ssh|rsyslog).service"1.6 抓取Node Exporter
通过配置新作业来抓取Node Exporter导出的数据。查看当前prometheus.yml文件和抓取配置中的scrape_configs部分。

要获取新数据,需要为配置添加另一个作业,配置如下:
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["localhost:9090"]- job_name: "node"static_configs:- targets: ["localhost:9600"]
可以看到有两个作业,名为node的新作业和已有的prometheus的旧作业。重启Prometheus后,配置将被重新加载且服务器会开始抓取,很快能看到时间序列数据开始流入Prometheus服务器中。

1.7 过滤收集器
Node Exporter可以返回很多指标,除了通过本地配置来控制Node Exporter在本地运行哪些收集器外,Prometheus还提供了一种方式来限制收集器从服务器端实际抓取的数据,尤其是在你无法控制正抓取的主机的配置时,这种方式很有效。
Prometheus 通过添加特定收集器列表来实现作业配置。
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["localhost:9090"]- job_name: "node"static_configs:- targets: ["localhost:9600"]params:collect[]:- cpu- meminfo- diskstats- netdev- netstat- filefd- filesystem- xfs- systemd
~ 指定CPU参数访问结果如下:

2. 监控Docker容器
Prometheus提供了几种方法来监控Docker,包括一些自定义的exporter,但一般推荐使用Google的cAdvisor工具。在Docker守护进程上,cAdvisor作为Docker容器运行,单个cAdvisor容器返回针对Docker守护进程和所有正在运行的容器指标。Prometheus支持通过它导出指标,并将数据传输到其他各种存储系统,如InfluxDB、Elasticsearch和kafka。
2.1 运行cAdvisor
由于cAdvisor只是Docker主机上的另一个容器,因此可以使用docker run命令启动它。
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor google/cadvisor:latest启动后结果如下:

通过浏览器访问,确认它是正常运行的。
通过metrics可以看见指标数据。

2.2 抓取cAdvisor
我们需要告诉 Prometheus cAdvisor 是在Docker守护进程上进行的,可以在配置中添加第三个作业。
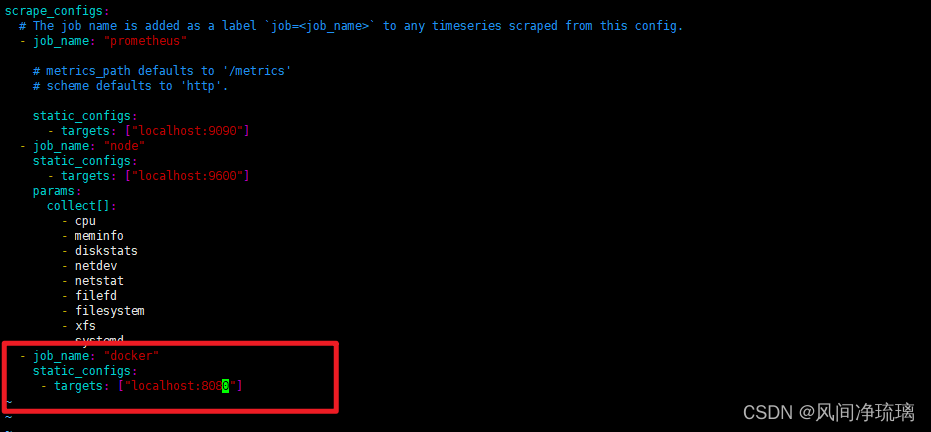
修改配置后重启Prometheus ,即可开始进行抓取。

2.3 Node Exporter和cAdvisor指标
现在从主机中收集总共3组独立的指标:
- Prometheus 服务器自己的指标
- 主机Node Exporter指标
- 主机cAdvisor指标

2.3.1 USE方法
USE方法关注的是使用率、饱和度和错误指标,以帮助进行性能诊断,经常被用在CPU、内存和磁盘监控。
CPU利用率
为了获得USE中的使用率,我们将使用Node Exporter收集的名为node_cpu_seconds_total的指标。如下所示:
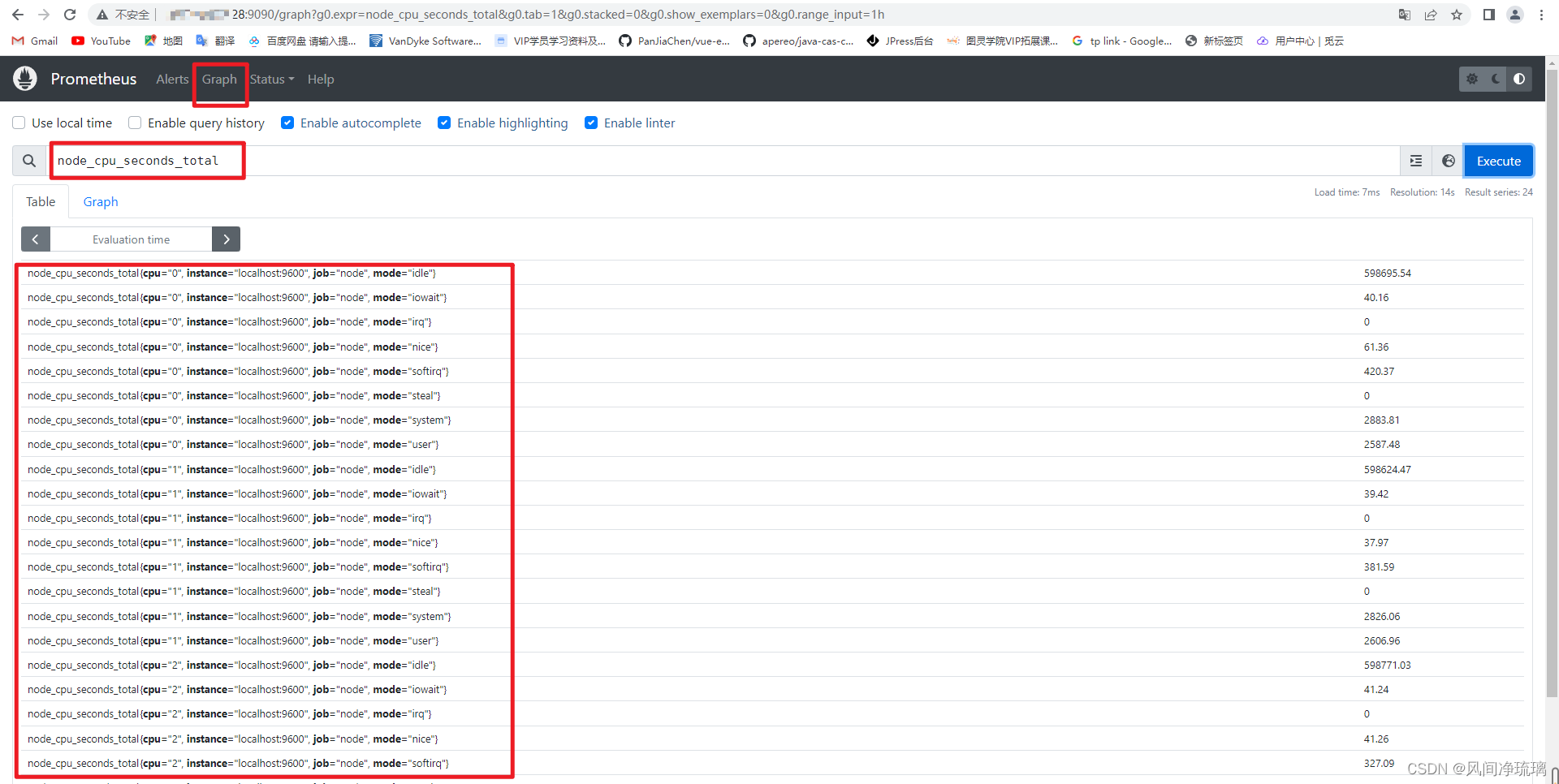
可以看见指标列表如下格式:
node_cpu_seconds_total{cpu="0", instance="localhost:9600", job="node", mode="idle"}node_cpu_seconds_total 指标包含许多标签,包括instance和job标签,分别标识它来自哪个主机以及被哪个作业抓取。
当然以上的指标列表作用并不大。对于性能分析需要使用PromQL将其转换成更有用的指标。
计算每种CPU模式的每秒使用率

计算每台主机的平均CPU使用率

计算每个主机5分钟范围内使用率的平均百分比

CPU饱和度
在主机上获得CPU饱和的一种方法是跟踪平均负载,实际上它是将主机上的CPU数量考虑在内的一段时间内的平均运行队列长度。平均负载少于CPU的数量通常是正常的,长时间内超过该数字的平均值则表示CPU已经饱和。
查看主机的平均负载,可以通过 node_load*指标,它显示了1分钟、5分钟和15分钟的平均负载。我们将使用1分钟的平均负载:node_load1.
计算mode模式为idle的主机上的CPU数量,使用count函数做聚合:
count by (instance) (node_cpu_seconds_total{mode="idle"})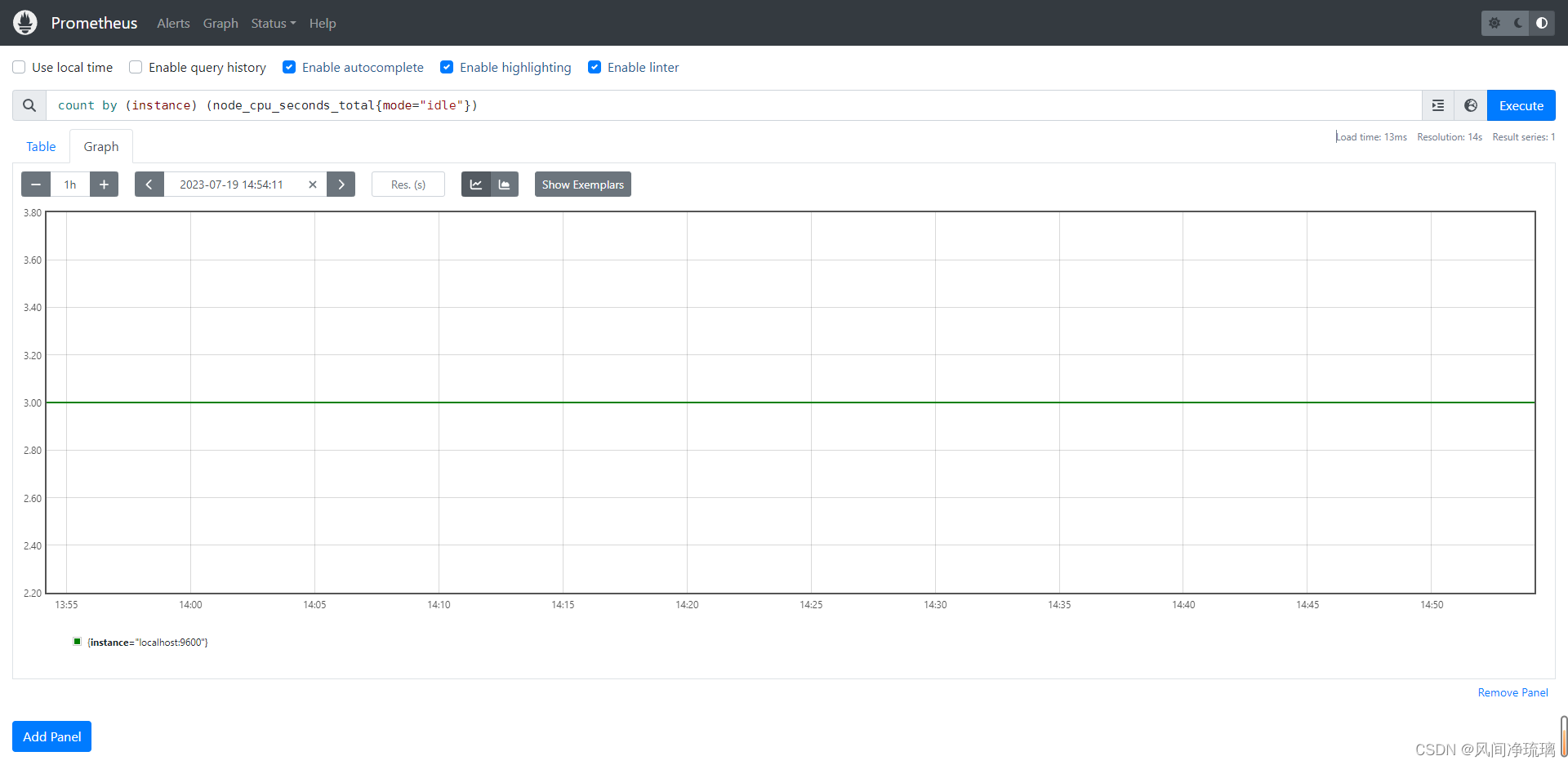
可以看见主机上有三个CPU。
计算CPU饱和度
查询mode为idle,1分钟的平均负载超过主机CPU数量的2倍的结果。
node_load1 >on (instance) 2*count by (instance) (node_cpu_seconds_total{mode="idle"})
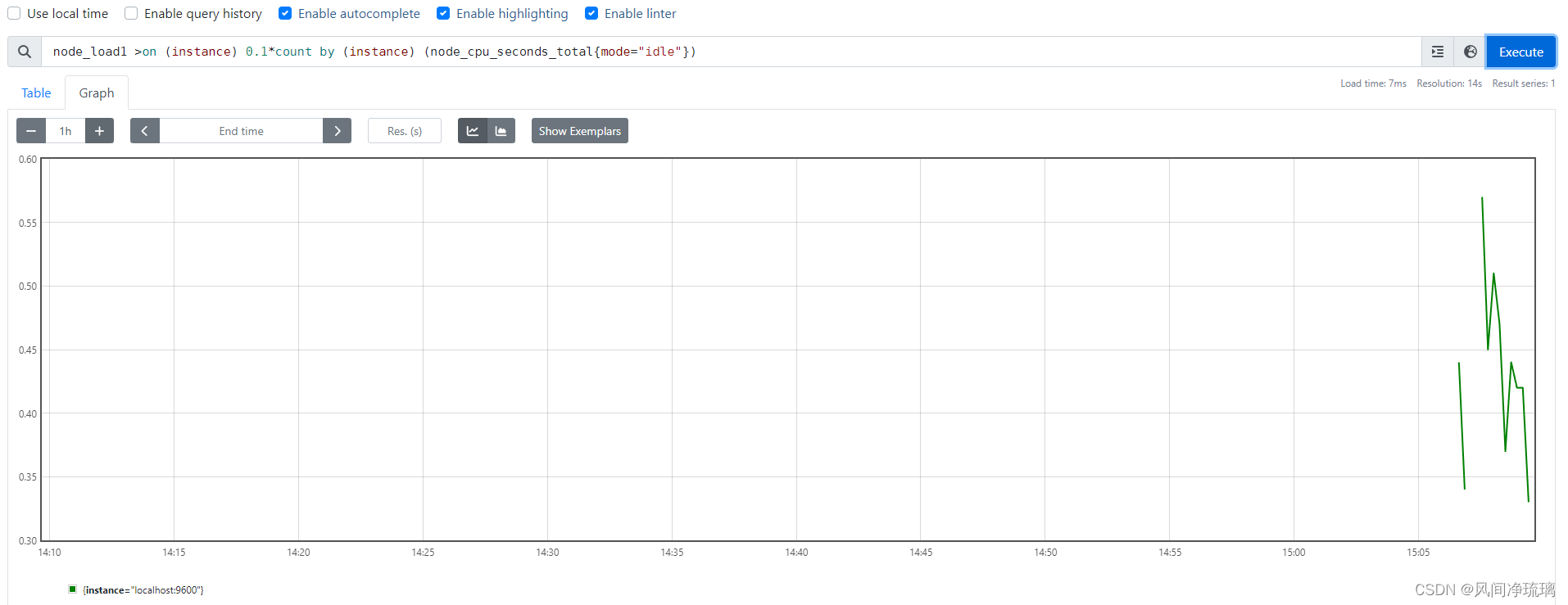
可以看见2倍没有数据,0.1倍有数据,CPU饱和度很低。
内存使用率
Node Exporter的内存指标按内存的类型和使用率进行细分,可以以node_memory为前缀的指标列表中找到它们,如下:
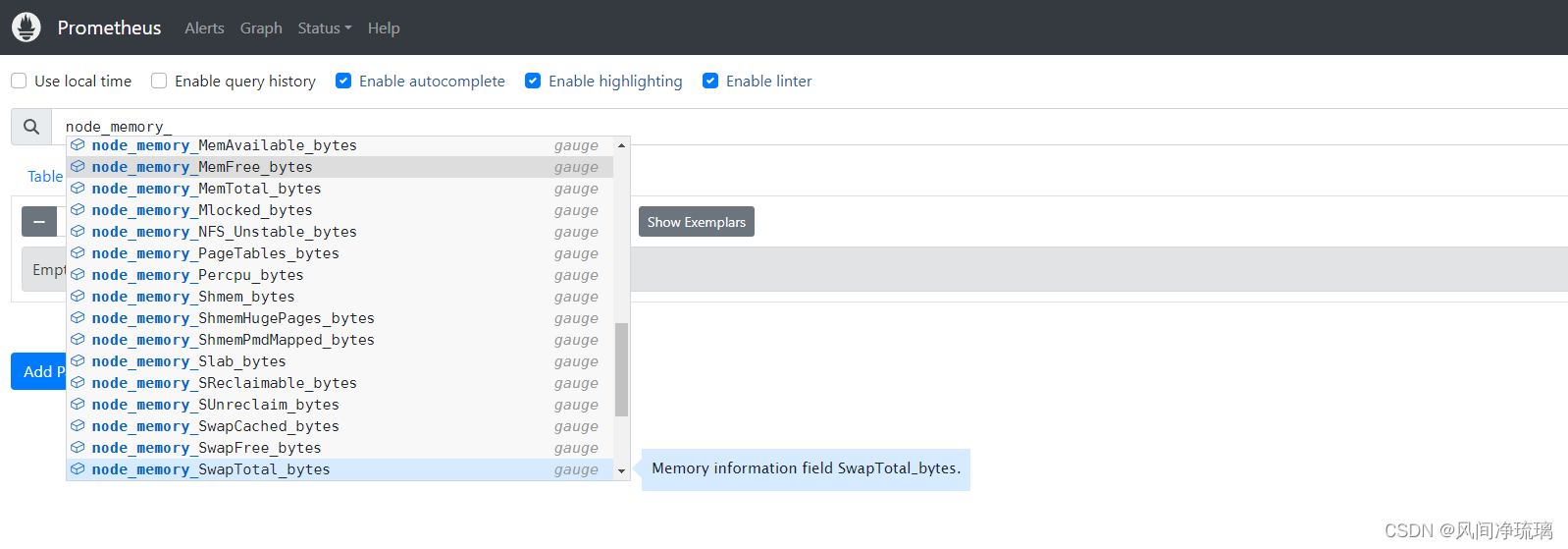
虽然关于内存的指标很多,但这里我们主要以以下指标获得使用率。
- node_memory_MemFree_bytes:主机上的可用内存。
- node_memory_MemTotal_bytes: 主机上的总内存。
- node_memory_Buffers_bytes:缓冲缓存中的内存。
- node_memory_Cached_bytes:页面缓存中的内存。
所有这些指标都是以字节为单位来表示的。
计算可用内存的百分比
(node_memory_MemTotal_bytes-(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes))/node_memory_MemTotal_bytes*100
内存饱和度
可通过检查内存和磁盘的读写来监控内存饱和度。可以使用从/proc/vmstat收集的两个Node Exporter指标:
- node_vmstat_pswpin:系统每秒从磁盘读到内存的字节数。
- node_vmstat_pswpout:系统每秒从内存读到磁盘的字节数。
两者都是自上次启动以来的字节数,以KB为单位。
计算内存饱和度
为了获取饱和度指标,我们对每个指标计算一分钟的速率,将两个速率相加再乘以1024以获得字节数。
1024 *sum by (instance) (rate(node_vmstat_pswpin[1m])+rate(node_vmstat_pswpout[1m]))
磁盘使用率
对于磁盘,我们只测量磁盘使用情况而不是使用率、饱和度或者错误情况。这是因为在大多数情况下,它是对可视化和警报最有用的数据。Node Exporter的磁盘使用指标位于以 node_filesystem为前缀的指标列表中。如下:

计算主机使用磁盘空间的百分比
node_filesystem_size_bytes指标显示了被监控的每个文件系统挂载的大小。可以使用与内存指标类似的查询来生成在主机上使用的磁盘空间的百分比。
(node_filesystem_size_bytes{mountpoint="/"}-node_filesystem_free_bytes{mountpoint="/"})/node_filesystem_size_bytes{mountpoint="/"}*100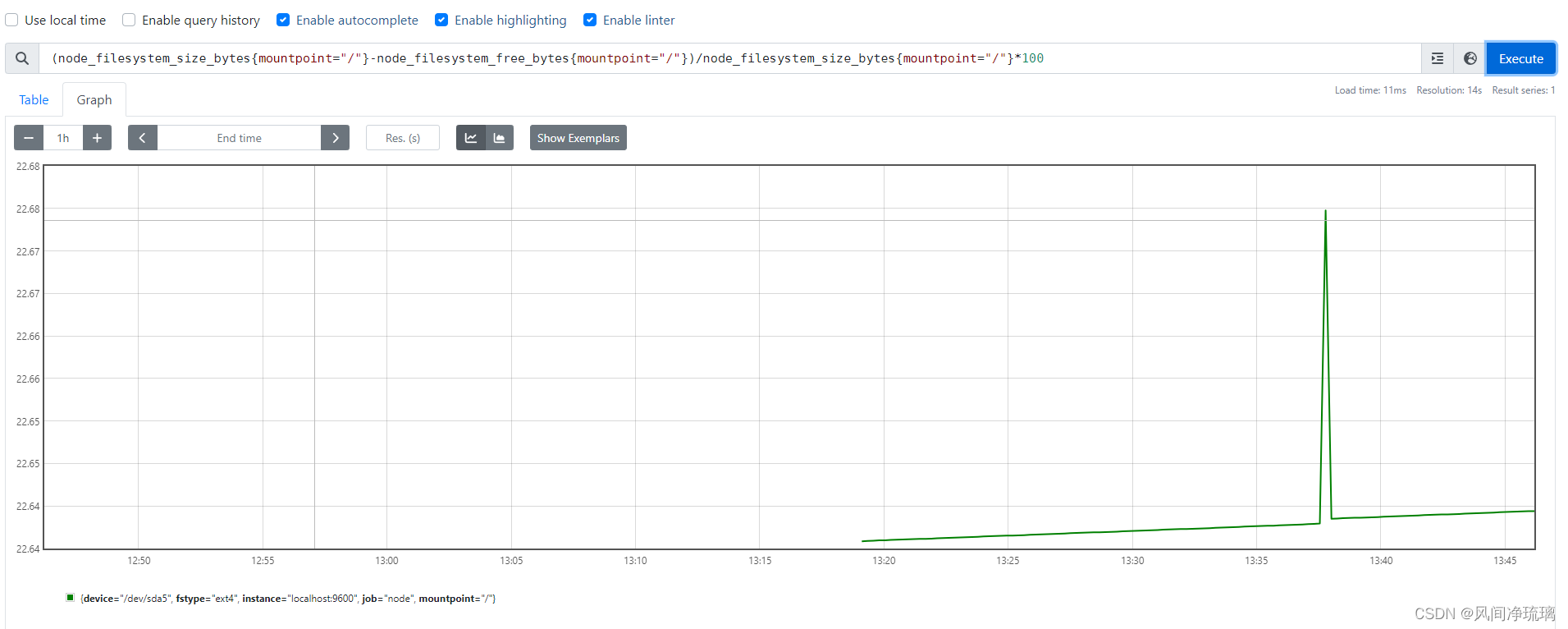
与内存指标不同,我们在主机的每个挂载点都有文件系统指标。所以我们添加了mountpoint标签。特别是根文件系统"/"挂载。
如果想要监控特定挂载点,可以添加查询。如监控/run挂载点,使用查询语句如下:
(node_filesystem_size_bytes{mountpoint="/run"}-node_filesystem_free_bytes{mountpoint="/run"})/node_filesystem_size_bytes{mountpoint="/run"}*100
使用正则表达式匹配多个挂载点
将操作符从 = 更改为 =~,告诉Prometheus右侧值是正则表达式,可以同时匹配/run和/根文件。
(node_filesystem_size_bytes{mountpoint=~"/|/run"}-node_filesystem_free_bytes{mountpoint=~"/|/run"})/node_filesystem_size_bytes{mountpoint=~"/|/run"}*100
计算未来使用磁盘空间趋势(提前规避磁盘用尽的风险)
选择1小时的时间窗口[1h],并将此时间序列快照放在predict_linear函数中。该函数使用简单的线性回归,根据以前的增长情况来确定文件系统何时会耗尽空间。该函数包括一个范围向量(即1小时时间窗口),以及未来需要预测的时间点。这些都是以秒为单位的,因此这里使用4*3600秒,即4小时。
predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h],4*3600)<0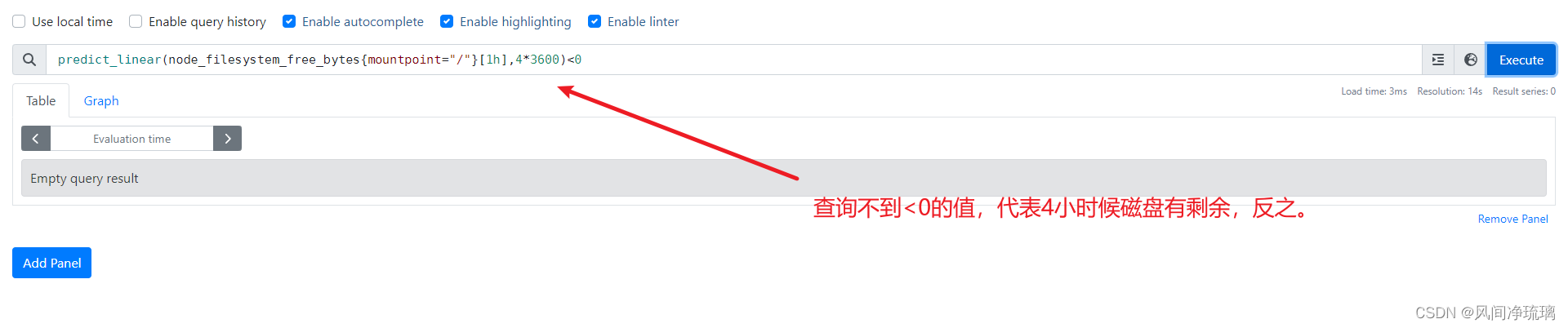
2.3.2 服务状态
服务状态在 node_systemd_unit_state 指标中暴露出来。如下:

查看docker服务状态
node_systemd_unit_state{name="docker.service"}
查看已经active的docker
服务有failed、inactive、active等状态,其中表示当前服务状态的指标的值为1.

2.3.3 可用性和up指标
还可以使用 up指标 来监控特定节点状态。
up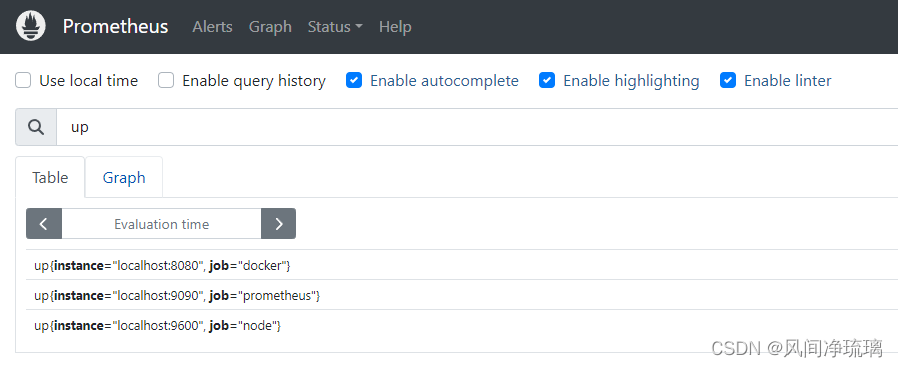
2.3.4 metadata指标
使用Node Exporter的textfile收集器来查看我们创建的metadata指标,结合日志输出到对应的matadata或许是一种比较灵活的指标上报方式。

2.4 查询持久性
截至当前,我们在浏览器中输入表达式进行查询,虽然查询输出结果很方便,但结果还是临时存储在Prometheus服务器上的。我们可以通过以下三种方式使查询持久化:
- 记录规则:根据查询创建新指标
- 警报规则:从查询生成警报
- 可视化:使用Grafana等仪表板可视化查询。
2.4.1 记录规则
记录规则使一种根据已有时间序列计算新时间序列(特别使聚合时间序列)的方法,这样做是为了:
- 跨多个时间序列生成聚合。
- 预先计算消耗大的查询。
- 产生可用于生成警报的时间序列。
配置记录规则
记录规则存储在Prometheus服务器上,位于Prometheus服务器加载的文件中。规则是自动计算的,频率则是由prometheus.yml配置文件中的global块中的evaluation_interval参数控制的。
global:
scrape_interval: 15s
evaluation_interval: 15s
规则文件在 Prometheus配置文件的rule_files块中指定
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
在Prometheus配置文件prometheus.yml的rule_files块中添加这个文件。
rule_files:- "rules/node_rules.yml"添加记录配置
把CPU、内存和磁盘计算转换为记录规则。监控主机时,要对节点预先计算这三个指标的查询,这样就可以将这些计算作为指标,然后可以设置警报或者通过Grafana等仪表板进行可视化。
groups:
- name: node_rulesrules:- record: instance:node_cpu:avg_rate5mexpr: 100 -avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) *100
记录规则在规则组中定义,这里的规则组叫做node_rules。规则组名称在服务器中必须是唯一的。规则组内的规则以固定间隔顺序执行。默认情况下,通过全局evaluate_interval来控制的。
规则组内规则执行的顺序性质意味着你可以在后续规则中使用之前创建的规则。这允许你根据规则创建指标,然后在之后的规则中重用这些指标。这仅在规则组内适用,规则组是并行运行的,因此不建议跨组使用规则。
更新规则组为每10秒运行一次
groups:
- name: node_rulesinterval: 10srules:- record: instance:node_cpu:avg_rate5mexpr: 100 -avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) *100
其中record记录规则产生的新的时间序列命名一般的推荐格式为:
level:metric:operations(1)level 表示聚合级别
(2)metric 是指标名称
(3)operations 是应用于指标的操作列表,一般最新的操作放在前面。这里cpu查询命名将为:instance:node_cpu:avg_rate5m

此外我们通过指定一个expr字段来保存生成新时间序列的查询。通过添加labels块向新时间序列添加新标签。根据规则创建的时间序列会继承用于创建它们的时间序列的相关标签,但你也可以添加或者覆盖标签。如下。
groups:
- name: node_rulesinterval: 10srules:- record: instance:node_cpu:avg_rate5mexpr: 100 -avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) *100labels:metric_type: aggregation 让我们再创建一些查询,并添加它们。
groups:
- name: node_rulesinterval: 10srules:- record: instance:node_cpu:avg_rate5mexpr: 100 -avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) *100labels:metric_type: aggregation- record: instance:node_memory_usage:percentageexpr: (node_memory_MemTotal_bytes-(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes))/node_memory_MemTotal_bytes*100- record: instance:root:node_filesystem_usage:percentageexpr: (node_filesystem_size_bytes{mountpoint="/"}-node_filesystem_free_bytes{mountpoint="/"})/node_filesystem_size_bytes{mountpoint="/"}*100
ps:需要重启Prometheus服务器或者进行SIGHUP才能激活新规则。
3. 可视化
Prometheus虽然有内置的仪表板和图形界面,但非常简单,通常最适合查看指标和呈现单个图表。为了给Prometheus添加一个功能更全面的可视化界面,该平台选择与开源仪表板工具Grafana集成。Grafana接受来自不同数据源(如Graphite、Elasticsearch和Promethues)的数据,然后提供可视化仪表板。
3.1 安装Grafana
Grafana支持在Linux、windows、mac上进行安装部署,这里选择在Linux上部署。
3.1.1 在Ubuntu上安装Grafana
官方下载及安装教程见: https://grafana.com/grafana/download
单节点安装只需要下载 tar.gz包就好,如grafana-enterprise-10.0.3.linux-amd64.tar.gz,解压后启动脚本。
3.1.2 启动和配置Grafana
有两个地方可以配置Grafana: 本地配置文件和Grafana Web界面。本地配置文件主要用于配置服务器级的设置(如身份验证和网络),文件在不同系统的位置不一样,安装方式也会导致文件不一样。
笔者是通过tar.gz压缩包安装的,该文件在/usr/local/grafana/grafana-10.0.3/conf/defaults.ini
启动指令:
sudo ./grafana-server3.1.3 配置Grafana Web界面
Grafana是一个基于Go的Web应用服务,默认在端口3000上运行(注意访问Linux是需要开放该端口权限)。默认的登录账号和密码都为admin和admin,当然可以在上面提到的defaults.ini配置文件中的[security]部分进行控制。

当然也可以配置用户身份验证,包括与Google验证、Github验证或者本地用户身份验证的集成。Grafana配置文档中包含用户管理和身份验证。针对我们的意图,我们将假设控制台位于内部环境中并继续使用本地身份验证。
采用Prometheus作为数据源
首先将Grafana与我们的Prometheus数据关联起来。
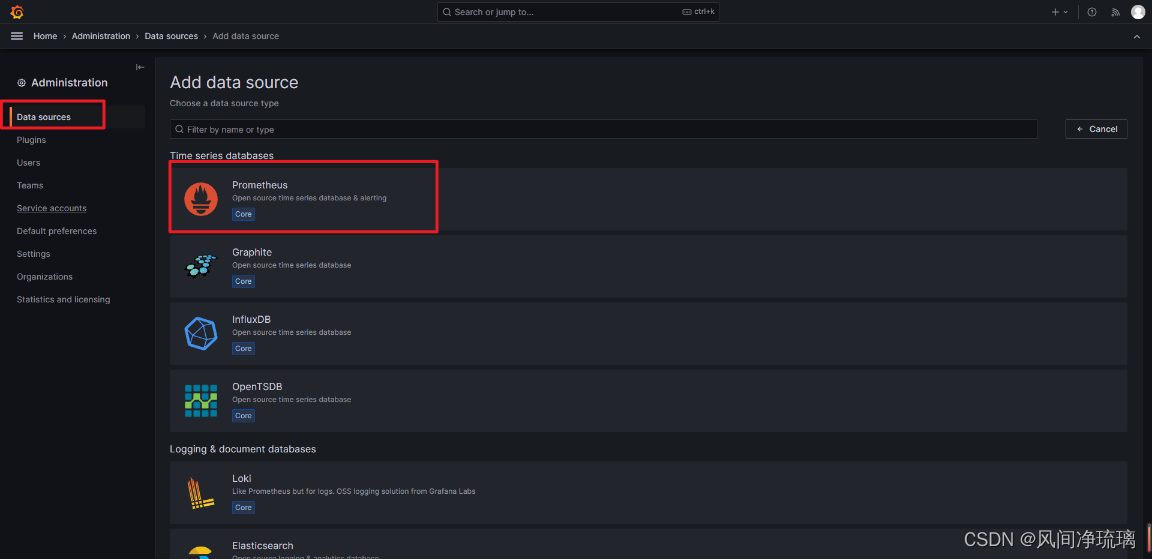
点击Data sources

add data source
这里选择Promethues
配置Promethues地址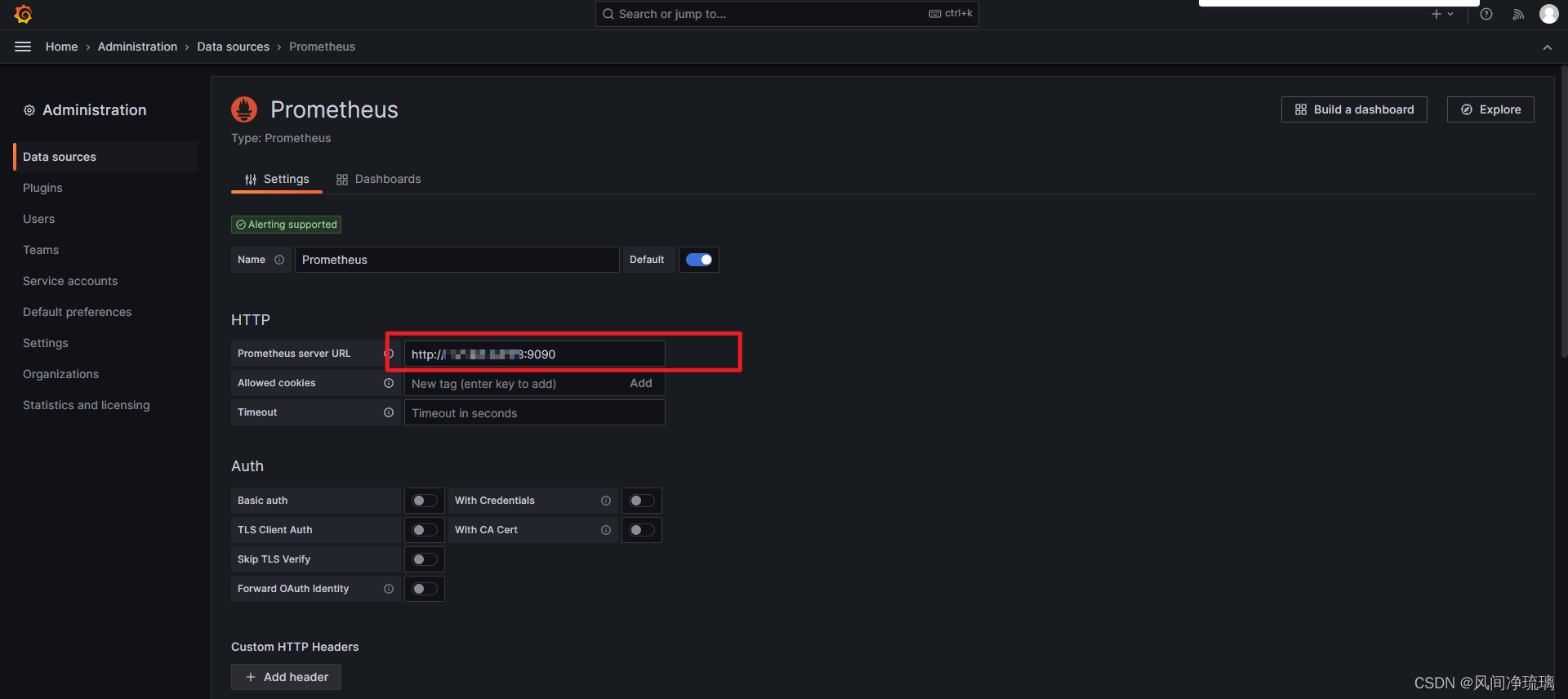
保存并测试配置
滑动到该页面最下方,点击save&test,如果出现以下页面就算配置成功。
3.1.4 使用仪表板
退回到主页,现在可以看见data sources已经配置成功,可以开始配置仪表盘了。
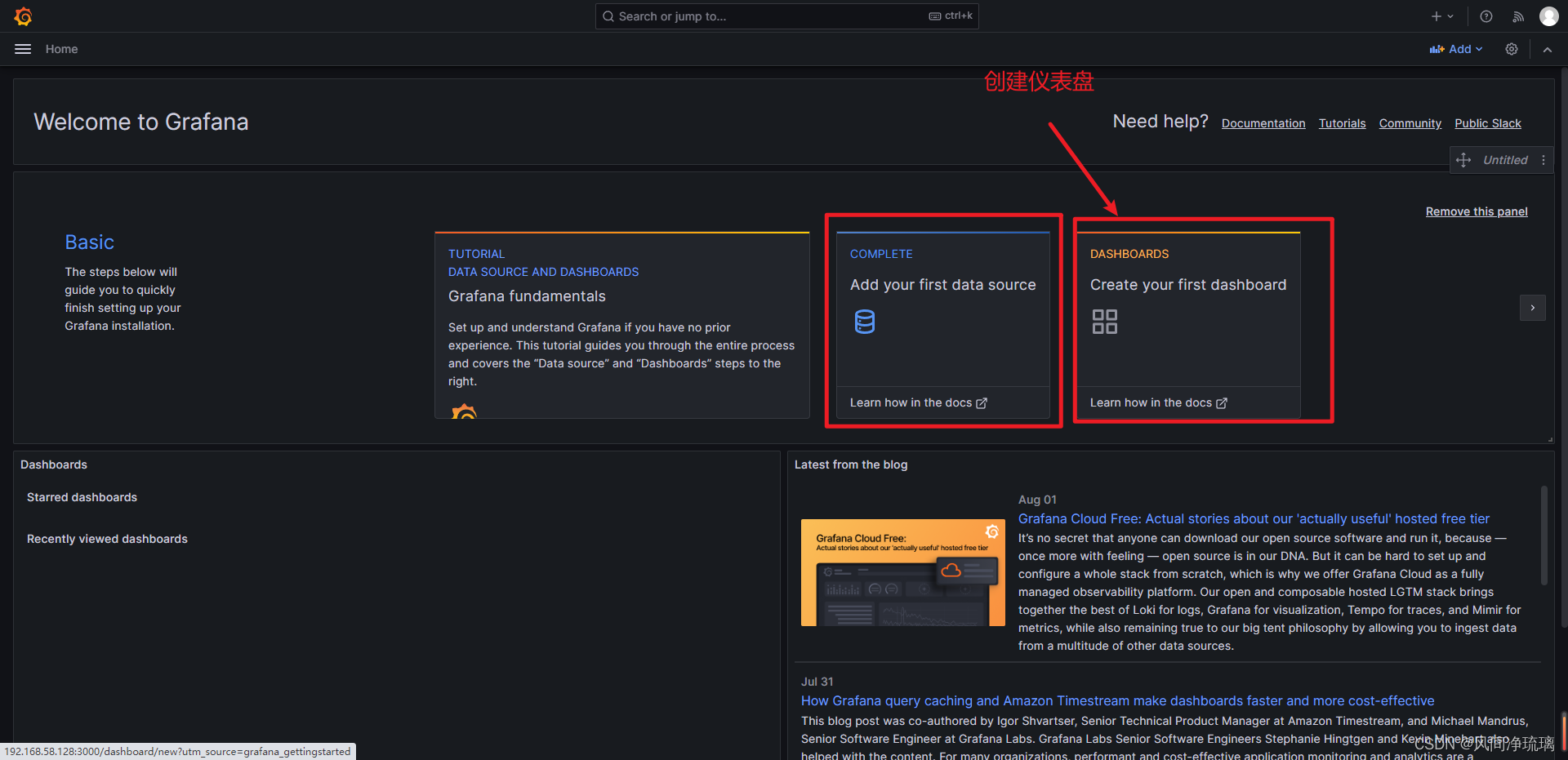
下面以创建CPU核数为例子。
Add visualization

选择data sources
这里只能选择上面配置的promethues的datasources。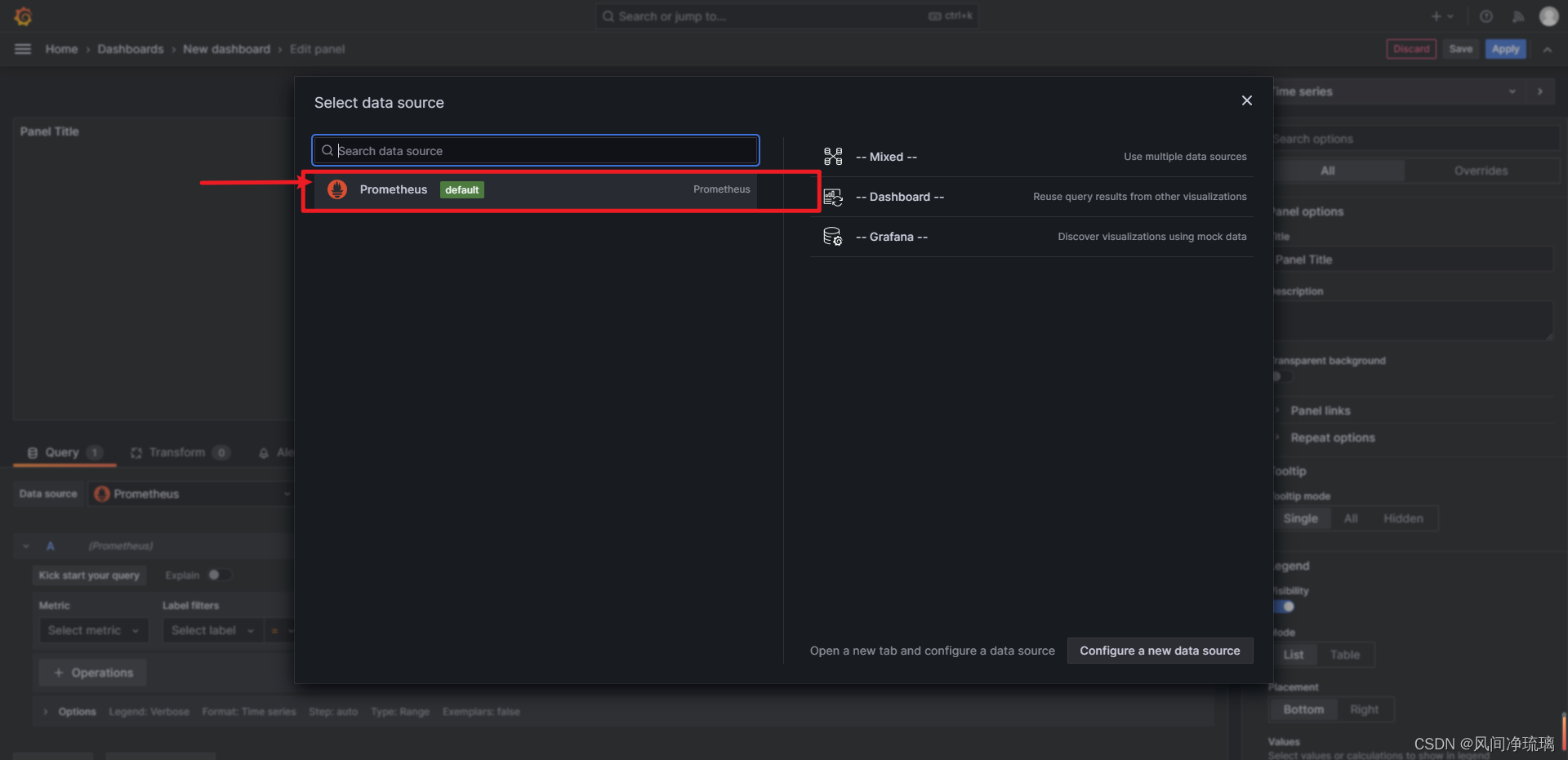
选择指标查询,并保存
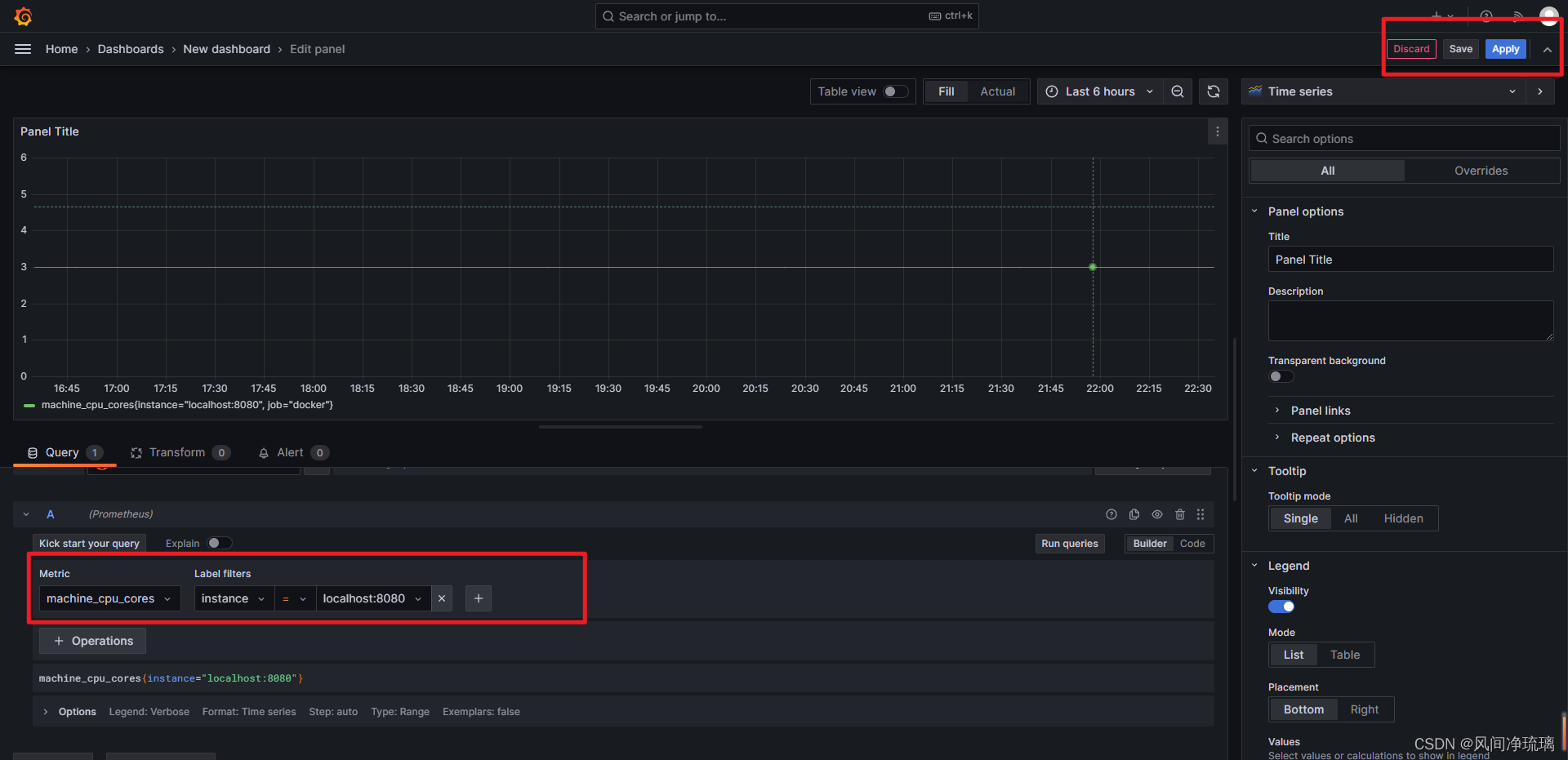
仪表盘查看图表结果
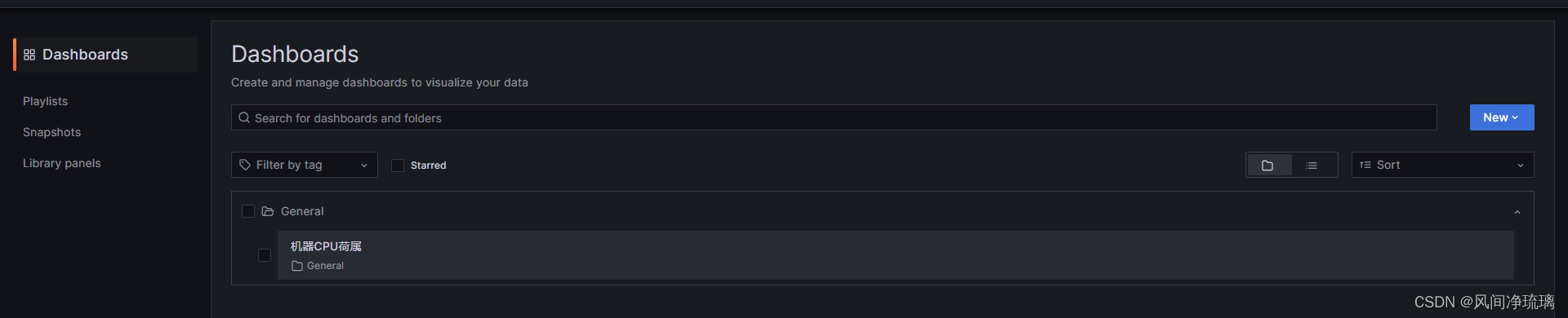
图标结果
具体的教程见:Get started | Grafana documentation
当然Mysql和Redis的监控比较模板化,可以预先构建Grafana仪表板以满足其监控需求。
相关文章:
4 Promethues监控主机和容器
目录 目录 1. 监控节点 1.1 安装Node exporter 解压包 拷贝至目标目录 查看版本 1.2 配置Node exporter 1.3 配置textfile收集器 1.4 启动systemd收集器 1.5 基于Docker节点启动node_exporter 1.6 抓取Node Exporter 1.7 过滤收集器 2. 监控Docker容器 2.1 运行cAdviso…...
亚马逊买家账号ip关联怎么处理
对于亚马逊买家账号,同样需要注意IP关联问题。在亚马逊的眼中,如果多个买家账号共享相同的IP地址,可能会被视为潜在的操纵、违规或滥用行为。这种情况可能导致账号受到限制或处罚。 处理亚马逊买家账号IP关联问题,建议采取以下步骤…...
NO4 实验四:生成Web工程
1、说明 使用 mvn archetype:generate 命令生成 Web 工程时,需要使用一个专门的 archetype。这个专门生成 Web 工程骨架的 archetype 可以参照官网看到它的用法: 2、操作 注意:如果在上一个工程的目录下执行 mvn archetype&…...
【linux】进程
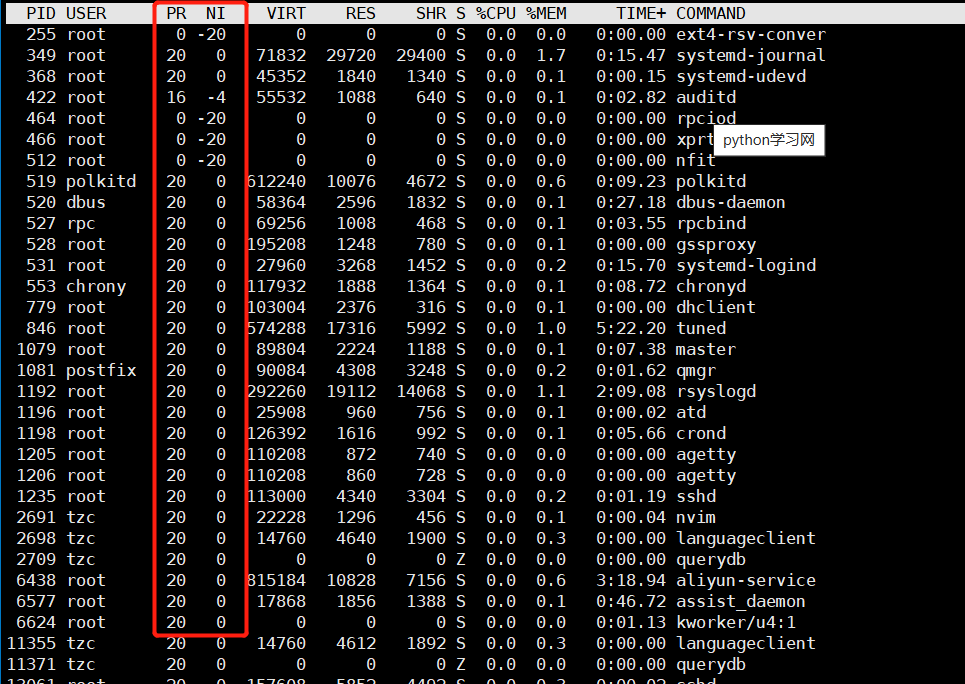
文章目录 前言一、概念基本概念进程-PCBtask_structtask_struct内容分类 二、查看和创建进程查看进程PID创建进程 三、进程状态五、僵尸进程和孤儿进程僵尸进程孤儿进程获取进程退出码 四、进程优先级基本概念查看系统进程PRI and NI用top命令更改已存在进程的nice 前言 我们常…...

电商高并发设计之SpringBoot整合Redis实现布隆过滤器
文章目录 问题背景前言布隆过滤器原理使用场景基础中间件搭建如何实现布隆过滤器引入依赖注入RedisTemplate布隆过滤器核心代码Redis操作布隆过滤器验证 总结 问题背景 研究布隆过滤器的实现方式以及使用场景 前言 本篇的代码都是参考SpringBootRedis布隆过滤器防恶意流量击穿缓…...

SpringBoot第25讲:SpringBoot集成MySQL - MyBatis 注解方式
SpringBoot第25讲:SpringBoot集成MySQL - MyBatis 注解方式 本文是SpringBoot第25讲,上文主要介绍了Spring集成MyBatis访问MySQL,采用的是XML配置方式;我们知道除了XML配置方式,MyBatis还支持注解方式。本文主要介绍Sp…...

服务器返回 413 Request Entity Too Large
问题 上传一个大于1.5M的文件时,报错:413 Request Entity Too Large 使用的配置 1、用的是docker环境,还有一层代理,代理用的镜像是:jwilder/nginx-proxy 2、docker里是有php和nginx 确认配置 docker里的php和ngi…...
如何一目了然地监控远程 Linux 系统
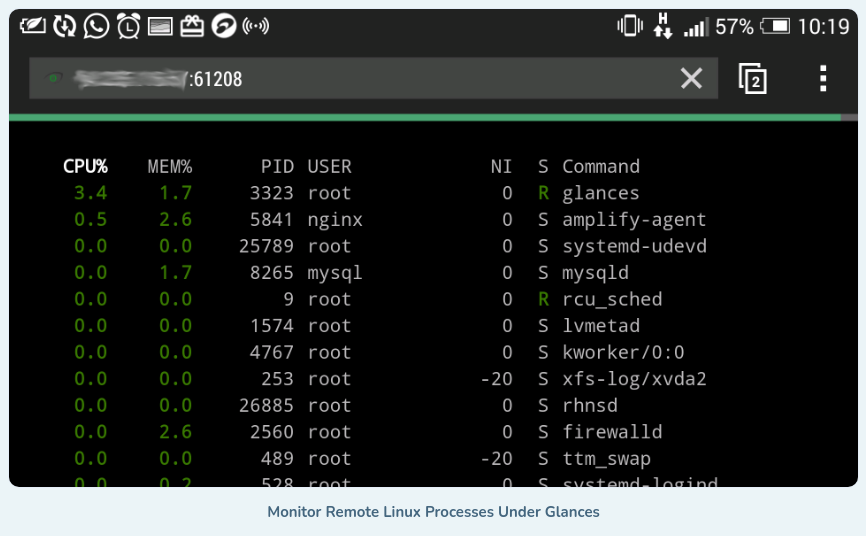
动动发财的小手,点个赞吧! Glances 是一款免费的开源、现代、跨平台、实时 top 和类似 htop 的系统监控工具,与同类工具相比,它提供了先进的功能,并且可以在不同的模式下运行:作为独立模式、客户端/服务器模…...
9.环境对象和回调函数
9.1环境对象 指的是函数内部特殊的变量this,它代表着当前函数运行时所处的环境 作用: 弄清楚this的指向,可以让我们代码更简洁 ➢函数的调用方式不同,this指代的对象也不同 ➢[谁调用,this 就指代谁] 是判断this指向的…...
实验例程软件分析概览)
51单片机(普中HC6800-EM3 V3.0)实验例程软件分析概览
本专栏将分析普中HC6800-EM3 V3.0 (9.22)\5--实验程序\基础实验例程中的各个例程的代码。 引言:本专栏将对历程中的关键代码进行分析与拓展,再学习一遍51,记录与各位一起进步。 下面是文件列表: E:\USER\000study\000_51单片机\000普中HC6800-EM3 V3.0 (9.22)\5--实…...
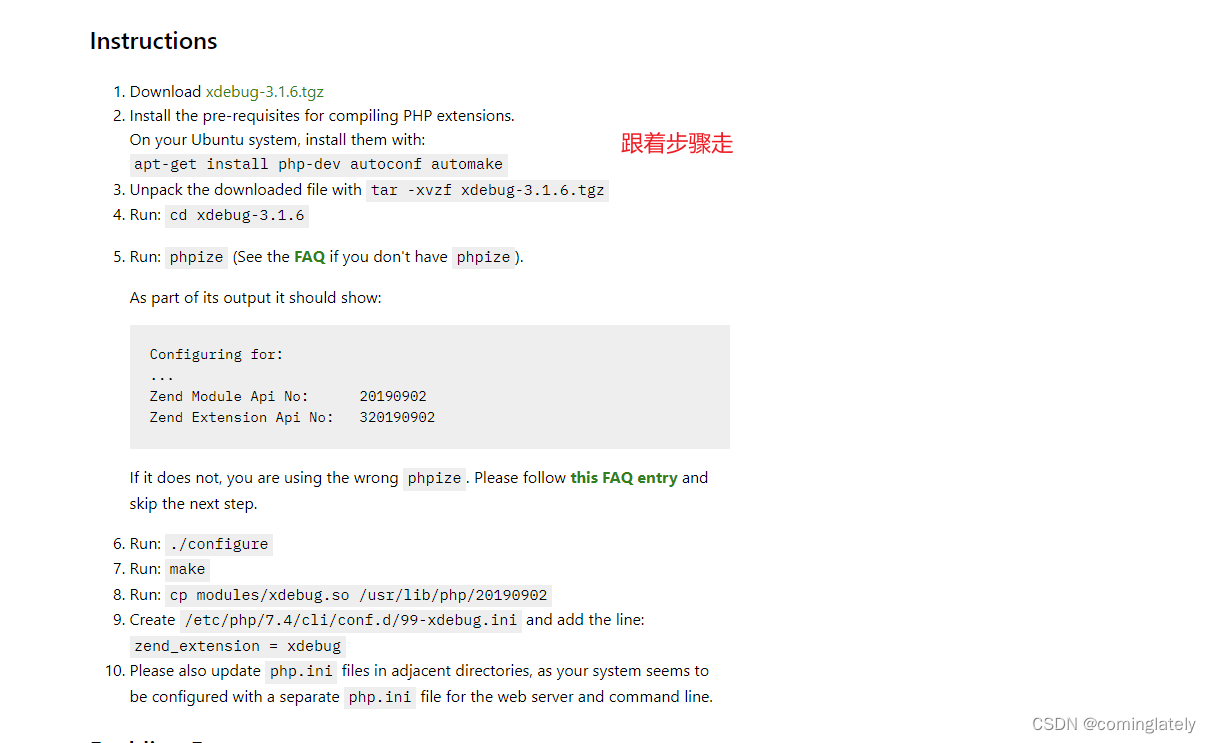
ubuntu18.04 安装php7.4-xdebug
文章目录 场景解决 场景 apt install php7.4-xdebug 下载失败, 只好通过编译解决了 解决 https://xdebug.org/wizard 输入php -i的执行结果...
java 定时任务不按照规定时间执行
这里写目录标题 使用异步启动可能出现的问题排查代码中添加的定时任务步骤是否正确排查是否任务阻塞,如果定时任务出现异常阻塞后,将不会在次执行java中多个Scheduled定时器不执行为了让Scheduled效率更高,我们可以通过两种方法将定时任务变成…...

Android复习(Android基础-四大组件)—— Activity
Activity作为四大组件之首,是使用最为频繁的一种组件,中文直接翻译为"活动",不过如果被翻译为"界面"会更好理解。正常情况,除了Window,Dialog和Toast , 我们能见到的界面只有Activity。…...
Linux系统安装部署MongoDB完整教程(图文详解)
前言:本期给大家分享一下目前最新Linux系统安装部署MongoDB完整教程,我的服务器采用的是Centos7,在部署之前我重装了我的服务器,目的是为了干净整洁的给大家演示我是如何一步步的操作的,整体部署还是挺简洁,…...
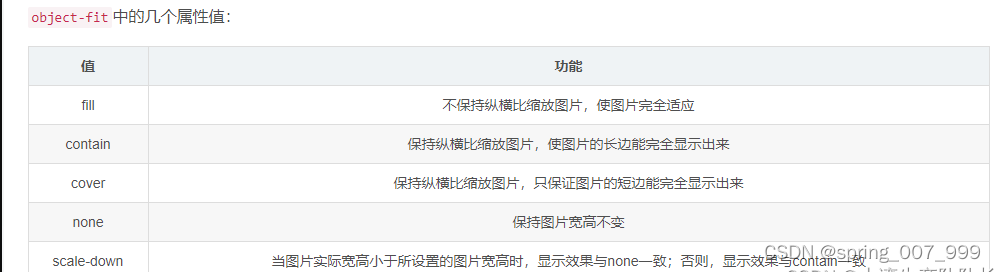
CSS图片放到<div>里面,自适应宽高全部显示,点击图片跳到新页面预览,点击旋转按钮图片可旋转
有一个需求是图片放到一个固定宽高的<div>里面,不管是横图还是竖图,都要全部显示出来并且保持图片的长宽比例不变形,点击图片可以跳到一个新页面预览,代码如下: <!DOCTYPE html> <html> <head>…...
二阶段web基础与http协议
dns与域名 网络是基于tcp/ip协议进行通信和连接的 应用层-----传输层-----网络层-----数据链路层-----物理层 ip地址,每一台主机都有一个唯一的地址标识(固定的ip地址) 1.区分用户和计算机 2.通信 ip地址的问题在于32位二进制数组成的&…...

SpringBoot+Freemark根据html模板动态导出PDF
SpringBootFreemark根据html模板导出PDF 1、引入maven2、两个工具类2.1 test.html模板2.2 test.html模板中的Freemark语法 3、controller导出pdf 1、引入maven 导出pdf的一些必要jar包 <dependency><groupId>org.projectlombok</groupId><artifactId>…...
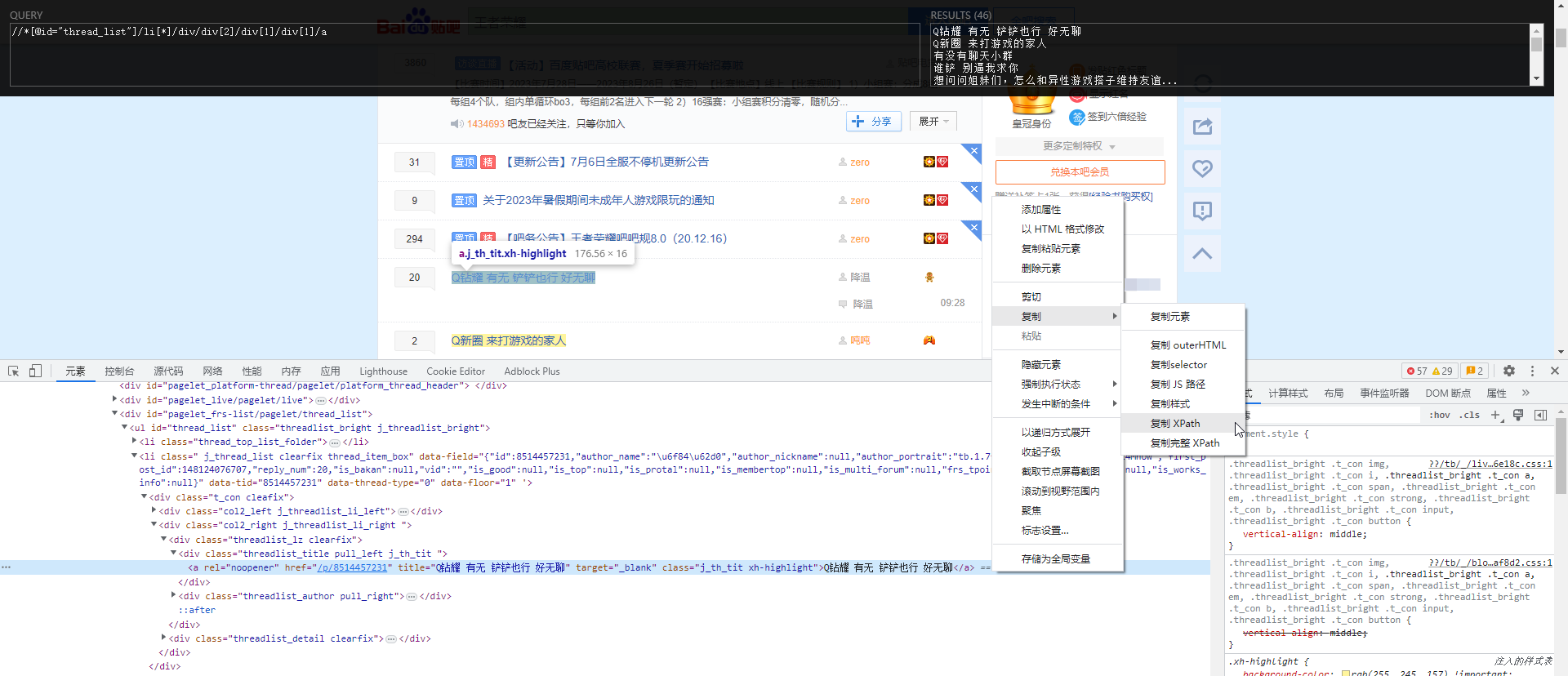
XPath数据提取与贴吧爬虫应用示例
XPath数据提取与贴吧爬虫应用示例 XpathXpath概述Xpath Helper插件 XPath语法基本语法查找特定节点选取未知节点选取若干路径 lxml模块使用说明使用示例 百度贴吧爬虫 Xpath Xpath概述 XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语…...

字符串匹配-KMP算法
KMP算法,字符串匹配算法,给定一个主串S,和一个字串T,返回字串T与之S匹配的数组下标。 在学KMP算法之前,对于两个字符串,主串S,和字串T,我们根据暴力匹配,定义两个指针,i指…...
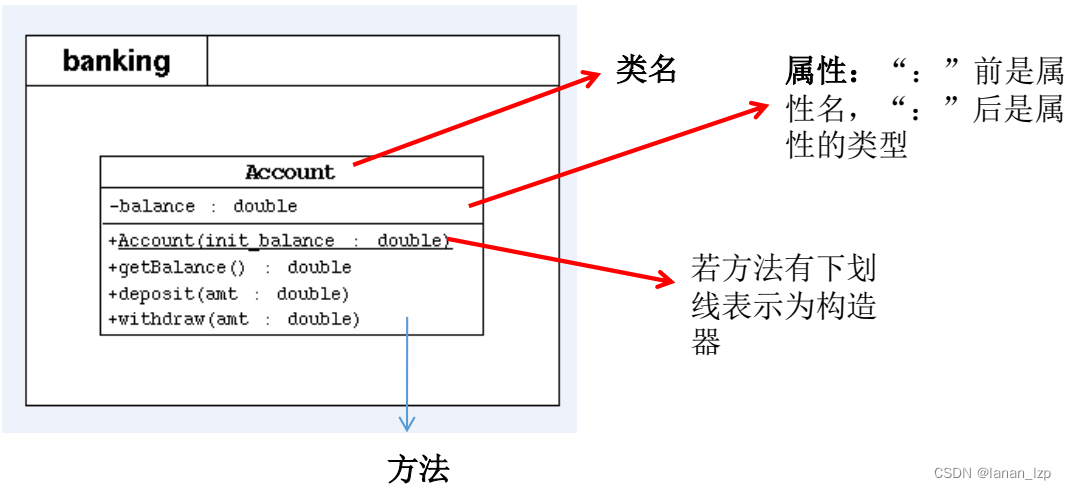
Java面向对象之UML类图
UML类图 表示 public 类型, - 表示 private 类型,#表示protected类型方法的写法:方法的类型(、-) 方法名(参数名: 参数类型):返回值类型...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...