XPath数据提取与贴吧爬虫应用示例
XPath数据提取与贴吧爬虫应用示例
- Xpath
- Xpath概述
- Xpath Helper插件
- XPath语法
- 基本语法
- 查找特定节点
- 选取未知节点
- 选取若干路径
- lxml模块
- 使用说明
- 使用示例
- 百度贴吧爬虫
Xpath
Xpath概述
XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语言。它提供了一种简洁的方式来遍历和提取XML文档中的数据。
XPath使用路径表达式来选取XML文档中的节点或者节点集。
简言之,Xpath是通过一定的语法规则从HTML、XML文件中提取需要的数据。
Xpath Helper插件
XPath Helper是一款浏览器插件,可用于在浏览器中轻松测试和调试XPath表达式。它提供了一个用户友好的界面,能够直接在浏览器中输入XPath表达式,并立即查看匹配的结果。
通过XPath Helper插件,可以快速验证和调试XPath表达式,以确保它们能够准确地选择所需的节点。
使用XPath Helper插件的步骤:
安装XPath Helper插件:在谷歌浏览器的插件商店中搜索XPath Helper,并按照指示进行安装。打开要调试的网页:在浏览器中打开包含XML或HTML文档的网页。启动XPath Helper插件:在浏览器工具栏中找到XPath Helper插件的图标,并点击它以打开插件界面。输入XPath表达式:在XPath Helper插件界面的输入框中输入XPath表达式。查看结果:XPath Helper插件将立即在页面上显示与XPath表达式匹配的节点。
进入chrome应用商店,搜索XPath Helper进行下载。
下载链接:XPath Helper
XPath语法
基本语法
提取属性或文本内容
| 表达式 | 描述 |
|---|---|
| nodename | 选中该元素 |
| / | 从根节点选取、或者是元素和元素间的过渡 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
示例
| 路径表达式 | 说明 |
|---|---|
| //h1/text() | 选择所有的h1下的文本 |
| //a/@href | 获取所有的a标签的href属性 |
| /html/head/title/text() | 获取html下的head下的title的文本 |
| //div/h2 | 选取属于div的子元素的所有h2标签 |
查找特定节点
可以根据标签的属性值、下标等来获取特定的节点
在xpath中,第一个元素的位置是1,最后一个元素的位置是last(),倒数第二个是last()-1
| 路径表达式 | 结果 |
|---|---|
| //title[@lang=“en”] | 选择lang属性值为en的所有title元素 |
| /people/user[1] | 选择属于 people 子元素的第一个 user元素 |
| /people/user[last()] | 选择属于people子元素的最后一个 user元素 |
| /people/user[last()-1] | 选择属于 people子元素的倒数第二个 user元素 |
| /people/user[position()>1] | 选择people下面的user元素,从第二个开始选择 |
| //user/title[text()=‘Java’] | 选择所有user下的title元素,仅选择文本为Java的title元素 |
| //user/title[contains(text(),‘Java’)] | 选择所有user下的title元素,仅选择文本包含Java的title元素 |
| //user/title[starts-with(text(),‘Java’)] | 选择所有user下的title元素,仅选择文本 以Java开头的title元素 |
| /people/user[age>20]/title | 选择people元素中的 user元素的所有 title 元素,且其中的 age元素的值须大于20 |
选取未知节点
通过通配符来选取未知的html、xml的元素
| 通配符 | 描述 |
|---|---|
* | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
示例
| 路径表达式 | 说明 |
|---|---|
| /people/* | 选取people元素的所有子元素 |
| //* | 选取文档中的所有元素 |
| //title[@*] | 选取所有带有属性的 title 元素 |
| //node() | 匹配任何类型的节点 |
选取若干路径
通过在路径表达式中使用“|”运算符,可以选取若干个路径
| 路径表达式 | 结果 |
|---|---|
| //user/name丨 //user/age | 选取user元素的所有 name和age元素 |
| //name丨 //age | 选取文档中的所有name和age元素 |
| /people/user/name丨 //age | 选取属于people元素的user元素的所有name元素,以及文档中所有的age元素 |
lxml模块
在Python中,可以使用第三方库lxml来解析和处理XML文档,并使用lxml库提供的XPath函数来执行XPath查询。
安装
pip install lxml
使用说明
导入lxml的etree库
from lxml import etree
可以将bytes类型和str类型的数据转化为Element对象,该对象具有xpath的方法,返回结果列表
# 可以自动补全标签
html = etree.HTML(data) list = html.xpath("xpath表达式")
返回列表存在三种情况
返回空列表:根据xpath语法规则字符串,没有定位到任何元素返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
Element对象转化为字符串,返回bytes类型结果
etree.tostring(element)
使用示例
创建test.html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<div><ul><li class="class01"><span index="1">H1</span></li><li class="class02"><span index="2" class="span2">H2</span></li><li class="class03"><span index="3">H3</span></li></ul></div>
</body>
</html>
使用lxml模块提取test.html文件数据
# 导入lxml的etree库
from lxml import etreedata = None
with open("test.html", 'r', encoding='UTF-8') as f:data = f.read()f.close()# 将字符串转化为Element对象。能够接受bytes类型和str类型的数据
html = etree.HTML(data)
# Element对象具有xpath的方法,返回结果列表
print("获取所有li标签: ", html.xpath('//li'))
print("获取所有span标签的内容: ", html.xpath('//span/text()'))
print("获取li标签的所有class属性: ", html.xpath('//li/@class'))
print("获取li标签下index属性=2为的span标签: ", html.xpath('//li/span[@index="2"]'))
print("获取li标签下的span标签里的有class的标签: ", html.xpath('//li/span/@class'))
print("获取最后一个li标签的span标签的index属性值: ", html.xpath('///li[last()]/span/@index'))
print("获取倒数第二个li元素的内容: ", html.xpath('//li[last()-1]//text()'))
提取结果
获取所有li标签: [<Element li at 0x247cb1ea880>, <Element li at 0x247cb1ea8c0>, <Element li at 0x247cb1ea900>]
获取所有span标签的内容: ['H1', 'H2', 'H3']
获取li标签的所有class属性: ['class01', 'class02', 'class03']
获取li标签下index属性=2为的span标签: [<Element span at 0x247cb1eaa40>]
获取li标签下的span标签里的有class的标签: ['span2']
获取最后一个li标签的span标签的index属性值: ['3']
获取倒数第二个li元素的内容: ['H2']
百度贴吧爬虫
百度贴吧:https://tieba.baidu.com/f?kw=王者荣耀&ie=utf-8&pn=50
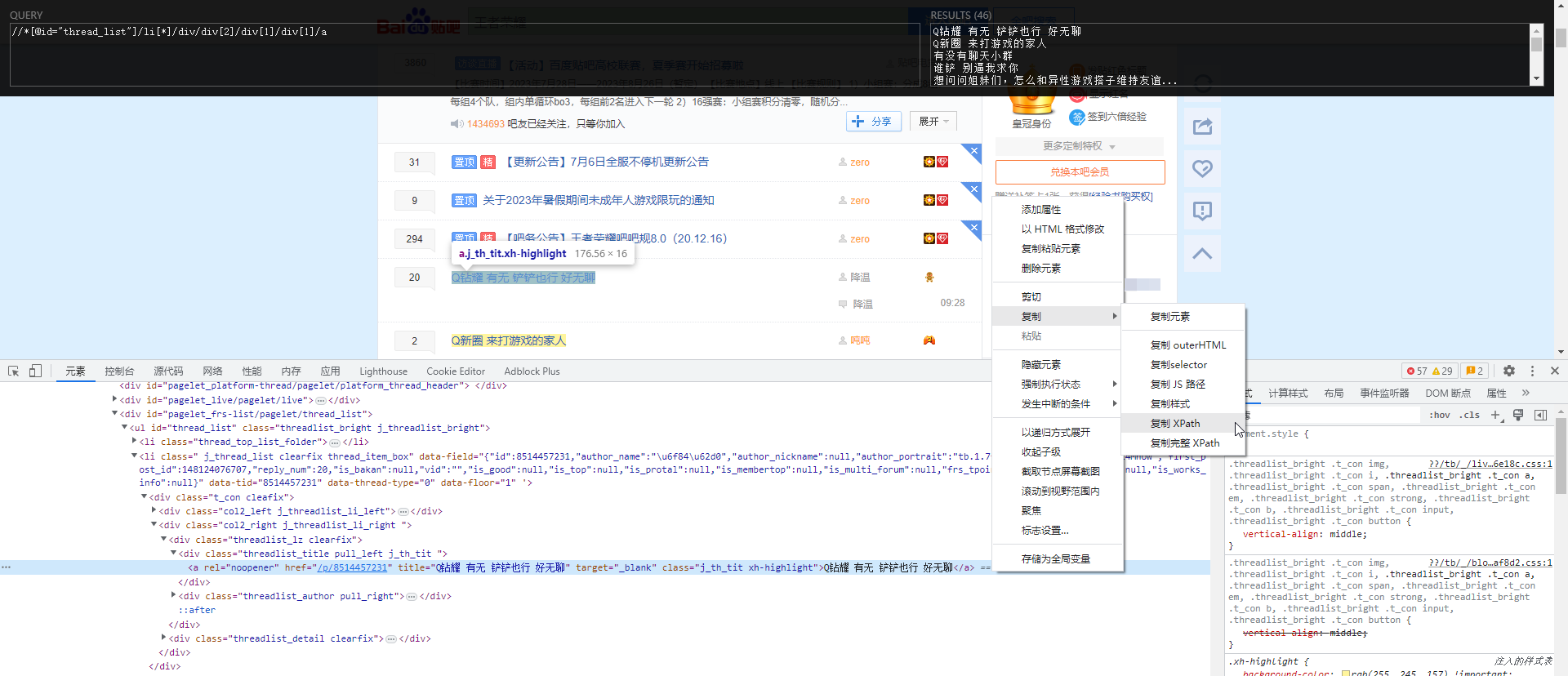
浏览器进行元素选择,复制XPath路径表达式,打开Xpath Helper插件进行调试,辅助进行数据提取。
Xpath Helper插件使用示例:
import datetime
import json
from time import sleepimport requests
from lxml import etreeclass TiebaSpider():def __init__(self, kw, max_pn, fileName):self.base_url = "https://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}"self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"}self.kw = kwself.max_pn = max_pnself.fileName = fileNamepassdef get_url_list(self):'''return [self.base_url.format(self.kw,pn) for pn in range(0,self.max_pn + 1,50)]'''url_list = []for pn in range(0, self.max_pn + 1, 50):url = self.base_url.format(self.kw, pn)url_list.append(url)return url_listdef get_content(self, url):response = requests.get(url=url,headers=self.headers)return response.contentdef get_items(self, content, idx):# 注意:响应页面需要抓取数据是被注释了的。处理方式2种:1.替换注释 2.使用低版本浏览器的响应头html = content.decode('utf-8').replace("<!--", "").replace("-->", "")eroot = etree.HTML(html)# 提取行数据li_list = eroot.xpath('//*[@id="thread_list"]/li/div/div[2]/div[1]/div[1]/a')data = []for li in li_list:item = {}item["title"] = li.xpath('./text()')[0]item["link"] = 'https://tieba.baidu.com' + li.xpath('./@href')[0]data.append(item)# next_url = 'https:' + eroot.xpath('//*[@id="frs_list_pager"]/a/@href')return datadef save_items(self, items, fileName):for data in items:print(data)# 将字典转换为字符串,将字符串编码为UTF-8字节流data_str = json.dumps(data).encode("utf-8")self.write(data_str, fileName)def write(self, item, fileName):# 打开文件进行追加写入with open(fileName, "a") as file:# 写入数据 将字节流解码为字符串file.write(item.decode("utf-8"))file.write("\n")def run(self):# 获取url列表url_list = self.get_url_list()fileName = self.fileNamefor url in url_list:print("*" * 100)# 发送请求获取响应content = self.get_content(url)sleep(5)# 从响应中提取数据items = self.get_items(content, url_list.index(url) + 1)# 保存数据self.save_items(items, fileName)passif __name__ == '__main__':user_input = input("请输入贴吧名称: ")# 获取当前日期和时间current_datetime = datetime.datetime.now()# 构建文件名,精确到小时和分钟fileName = current_datetime.strftime("%Y-%m-%d-%H-%M.txt")# kw:贴吧关键字 max_pn:最大贴吧条数spider = TiebaSpider(kw=user_input, max_pn=150, fileName=fileName)spider.run()
控制台
请输入贴吧名称: 王者荣耀
****************************************************************************************************
{'title': '赛季上分答案①-上官婉儿教学', 'link': 'https://tieba.baidu.com/p/8509192314'}
{'title': 'Q钻耀 有无 铲铲也行 好无聊', 'link': 'https://tieba.baidu.com/p/8514457231'}
{'title': '好奇很久了,,你们说的一杯奶茶钱一般指多少。', 'link': 'https://tieba.baidu.com/p/8512445812'}
{'title': '有没有人处或者好朋友', 'link': 'https://tieba.baidu.com/p/8514390098'}
{'title': 'qy vy聊天打游戏', 'link': 'https://tieba.baidu.com/p/8512823062'}
{'title': '接p钻耀5r', 'link': 'https://tieba.baidu.com/p/8514461207'}
{'title': '已到工位 来点vy', 'link': 'https://tieba.baidu.com/p/8514458179'}
{'title': '恋爱dd 要巨粘人的 游戏厉害一点声音好听一点稍微涩一点。', 'link': 'https://tieba.baidu.com/p/8514452627'}
{'title': '收个闲鱼自己用', 'link': 'https://tieba.baidu.com/p/8514428795'}
{'title': 'qy 固聊 我很无聊', 'link': 'https://tieba.baidu.com/p/8514440871'}
{'title': '死学不会什么叫意识和操作,家人们谁懂吖。', 'link': 'https://tieba.baidu.com/p/8514341952'}
{'title': 'QQ区钻耀来个瑶。', 'link': 'https://tieba.baidu.com/p/8514459651'}
{'title': '玩走地鸡的长这样', 'link': 'https://tieba.baidu.com/p/8514390800'}
{'title': 'V小群+++', 'link': 'https://tieba.baidu.com/p/8514449634'}
{'title': '求求别口嗨了,v区钻耀开个打游戏的,评论的每一个来的', 'link': 'https://tieba.baidu.com/p/8514453252'}
{'title': '有没有人处对象', 'link': 'https://tieba.baidu.com/p/8514271361'}
{'title': '有没有一起玩的 q区星耀', 'link': 'https://tieba.baidu.com/p/8514459727'}
{'title': 'q钻石有无一起玩的', 'link': 'https://tieba.baidu.com/p/8514425372'}
相关文章:
XPath数据提取与贴吧爬虫应用示例
XPath数据提取与贴吧爬虫应用示例 XpathXpath概述Xpath Helper插件 XPath语法基本语法查找特定节点选取未知节点选取若干路径 lxml模块使用说明使用示例 百度贴吧爬虫 Xpath Xpath概述 XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语…...

字符串匹配-KMP算法
KMP算法,字符串匹配算法,给定一个主串S,和一个字串T,返回字串T与之S匹配的数组下标。 在学KMP算法之前,对于两个字符串,主串S,和字串T,我们根据暴力匹配,定义两个指针,i指…...
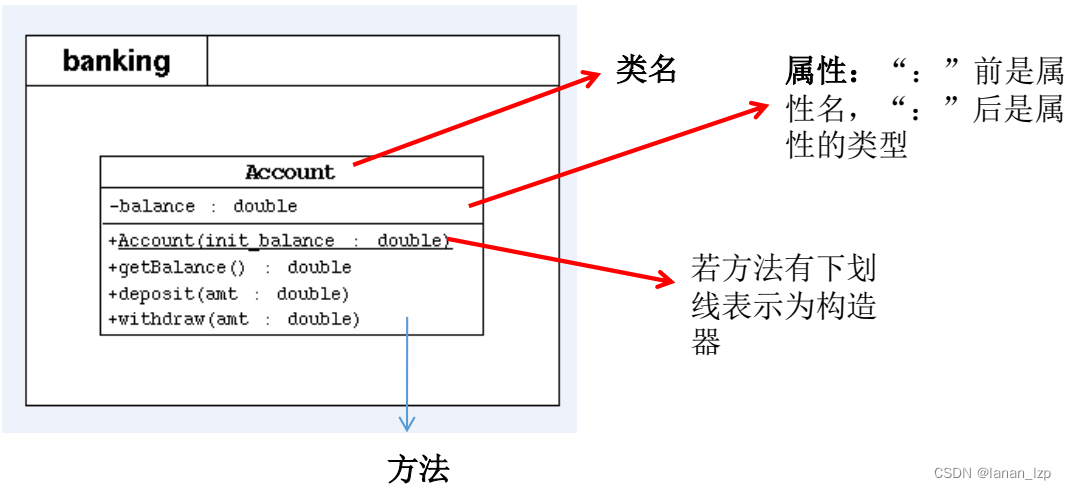
Java面向对象之UML类图
UML类图 表示 public 类型, - 表示 private 类型,#表示protected类型方法的写法:方法的类型(、-) 方法名(参数名: 参数类型):返回值类型...

【机器学习】西瓜书学习心得及课后习题参考答案—第4章决策树
这一章学起来较为简单,也比较好理解。 4.1基本流程——介绍了决策树的一个基本的流程。叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集&a…...

2023.8.2
2022河南萌新联赛第(三)场:河南大学\神奇数字.cpp //题意:给定三个正整数a b c,求x满足满足abc同余x的个数。 //这个考虑同余的性质,就是两个数的差去取模为0的数肯定是这两个数的同余数,。因此我们计算三个数两两之…...

windows运行窗口常用快捷键命令
winr打开运行窗口,然后输入快捷命令:(当然utools和win11搜索也挺好用的) cmd : 命令行窗口(命令提示符窗口、cmd窗口)regedit : 注册表mspaint : 画图工具services.msc : 本地服务设置(比如查看mysql服务是否启动成功)devmgmt.ms…...
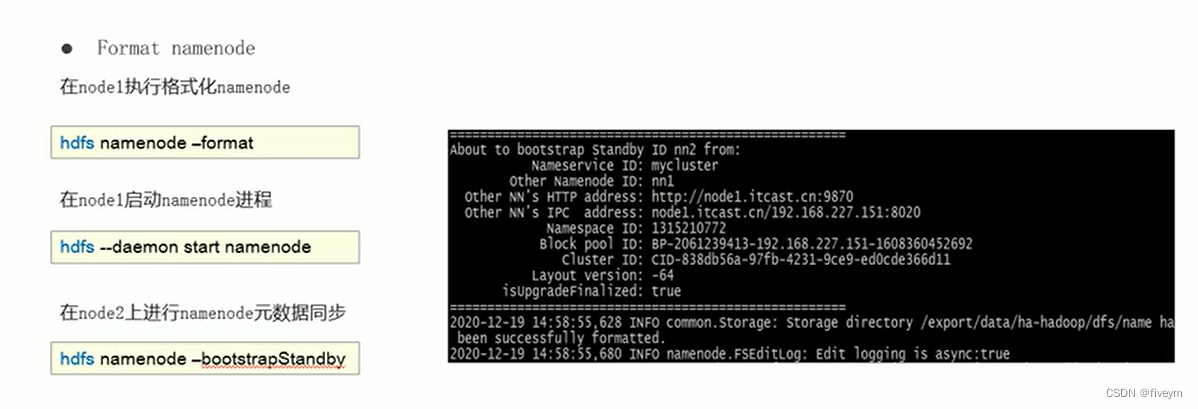
HDFS的QJM方案
Quorum Journal Manager仲裁日志管理器 介绍主备切换,脑裂问题解决---ZKFailoverController(zkfc)主备切换,脑裂问题解决-- Fencing(隔离)机制主备数据状态同步问题解决 HA集群搭建集群基础环境准备HA集群规…...
安装win版本的neo4j(2023最新版本)
安装win版本的neo4j 写在最前面安装 win版本的neo4j1. 安装JDK2.下载配置环境变量(也可选择直接点击快捷方式,就可以不用配环境了)3. 启动neo4j 测试代码遇到的问题及解决(每次环境都太离谱了,各种问题)连接…...

ChatGPT结合知识图谱构建医疗问答应用 (二) - 构建问答流程
一、ChatGPT结合知识图谱 上篇文章对医疗数据集进行了整理,并写入了知识图谱中,本篇文章将结合 ChatGPT 构建基于知识图谱的问答应用。 下面是上篇文章的地址: ChatGPT结合知识图谱构建医疗问答应用 (一) - 构建知识图谱 这里实现问答的流程…...

聊天系统登录后端实现
定义返回的数据格式 # Restful API from flask import jsonifyclass HttpCode(object):# 响应正常ok 200# 没有登陆错误unloginerror 401# 没有权限错误permissionerror 403# 客户端参数错误paramserror 400# 服务器错误servererror 500def _restful_result(code, messa…...
)
Ajax笔记_01(知识点、包含代码和详细解析)
Ajax_01笔记 前置知识点 在JavaScript中 问题1:将数组转为字符串,以及字符串转为数组的方式。 问题2、将对象转为字符串,以及字符串转为对象的方法。 方法: 问题1: 将数组转为字符串可以使用 join() 方法。例如&…...

Eureka 学习笔记2:EurekaClient
版本 awsVersion ‘1.11.277’ EurekaClient 接口实现了 LookupService 接口,拥有唯一的实现类 DiscoveryClient 类。 LookupService 接口提供以下功能: 获取注册表根据应用名称获取应用根据实例 id 获取实例信息 public interface LookupService<…...

Spring引入并启用log4j日志框架-----Spring框架
<?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://ma…...

Redis实现延时队列
缓存队列延时向接口报工,并支持多实例部署。 引入依赖 <dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-data</artifactId><version>3.17.4</version> </dependency> 注入RedisClient …...

无限遍历,Python实现在多维嵌套字典、列表、元组的JSON中获取数据
目录 背景 思路 新建两个函数A和B,函数 A处理字典数据,被调用后,判断传递的参数,如果参数为字典,则调用自身; 如果是列表或者元组,则调用列表处理函数B; 函数 B处理列表&#x…...

信息学奥赛一本通——1180:分数线划定
文章目录 题目【题目描述】【输入】【输出】【输入样例】【输出样例】【提示】 AC代码 题目 【题目描述】 世博会志愿者的选拔工作正在 A 市如火如荼的进行。为了选拔最合适的人才,A市对所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入…...

SpringApplication对象的构建及spring.factories的加载时机
构建SpringApplication对象源码: 1、调用启动类的main()方法,该方法中调用SpringApplication的run方法。 SpringBootApplication public class SpringbootdemoApplication {public static void main(String[] args) {SpringApplication.run(SpringbootdemoApplication.class, …...

基于传统检测算法hog+svm实现图像多分类
直接上效果图: 代码仓库和视频演示b站视频005期: 到此一游7758258的个人空间-到此一游7758258个人主页-哔哩哔哩视频 代码展示: 数据集在datasets文件夹下 运行01train.py即可训练 训练结束后会保存模型在本地 运行02pyqt.py会有一个可视化…...
 方法,使用 concat() 方法, [...originalArray],find(filter),移出类名 removeAttr())
slice() 方法,使用 concat() 方法, [...originalArray],find(filter),移出类名 removeAttr()
在JavaScript中,在 JavaScript 中,clone 不是一个原生的数组方法。但是你可以使用其他方法来实现克隆数组的功能。 以下是几种常见的克隆数组的方法: 使用 slice() 方法: const originalArray [1, 2, 3]; const clonedArray …...

Zabbix报警机制、配置钉钉机器人、自动发现、主动监控概述、配置主动监控、zabbix拓扑图、nginx监控实例
day02 day02配置告警用户数超过50,发送告警邮件实施验证告警配置配置钉钉机器人告警创建钉钉机器人编写脚本并测试添加报警媒介类型为用户添加报警媒介创建触发器创建动作验证自动发现配置自动发现主动监控配置web2使用主动监控修改配置文件,只使用主动…...

从CID到SCR:一张SD卡的‘身份证’里到底藏了多少秘密?聊聊厂商、版本与总线宽度的那些事
从CID到SCR:一张SD卡的‘身份证’里到底藏了多少秘密?聊聊厂商、版本与总线宽度的那些事 当你从抽屉里翻出一张积灰的SD卡,除了容量标签和品牌Logo,是否想过这张小塑料片里还藏着完整的"身份档案"?就像法医通…...

技术赋能:BilibiliDown如何用智能解析引擎重塑视频下载工作流
技术赋能:BilibiliDown如何用智能解析引擎重塑视频下载工作流 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mi…...

如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南
如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 还在为编写技术文档时需要在代码编辑器与图表预览工…...

从FPS相机到无人机控制:在Unity中实战Pitch、Yaw、Roll角的应用与调试技巧
从FPS相机到无人机控制:在Unity中实战Pitch、Yaw、Roll角的应用与调试技巧 在游戏开发中,相机控制和物体旋转是构建沉浸式体验的核心技术。无论是第一人称射击游戏中玩家视角的流畅转动,还是飞行模拟器中飞机的真实运动,都离不开对…...

MarkdownViewer++:5分钟让Notepad++变身专业Markdown编辑器的终极指南
MarkdownViewer:5分钟让Notepad变身专业Markdown编辑器的终极指南 【免费下载链接】MarkdownViewerPlusPlus A Notepad Plugin to view a Markdown file rendered on-the-fly 项目地址: https://gitcode.com/gh_mirrors/ma/MarkdownViewerPlusPlus 你是否还在…...

终极免费ThinkPad双风扇智能控制方案:TPFanControl2完全指南
终极免费ThinkPad双风扇智能控制方案:TPFanControl2完全指南 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 在ThinkPad笔记本的日常使用中,散热…...

联想笔记本BIOS隐藏设置解锁工具:专业指南与深度解析
联想笔记本BIOS隐藏设置解锁工具:专业指南与深度解析 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.com/gh_mirrors/le…...

第11代酷睿工业主板PICO-TGU4:边缘AI与机器视觉的紧凑型解决方案
1. 项目概述:当紧凑型工业主板遇上第11代酷睿在工业自动化、边缘计算和智能零售这些领域里,我们常常面临一个经典的矛盾:一方面,应用场景对计算性能的要求越来越高,无论是机器视觉的实时图像处理,还是AI推理…...
保姆级配置与排错指南)
别再为VMware里Kali上不了网发愁了!三种网络模式(桥接/NAT/仅主机)保姆级配置与排错指南
VMware中Kali Linux网络配置全攻略:从原理到实战排错 当你第一次在VMware中启动Kali Linux准备大展身手时,却发现连最基本的网络连接都无法建立——这种挫败感我深有体会。作为网络安全学习和渗透测试的必备工具,Kali在虚拟机中的网络配置往往…...

Ormar 性能优化:10 个提升数据库查询效率的技巧
Ormar 性能优化:10 个提升数据库查询效率的技巧 【免费下载链接】ormar python async orm with fastapi in mind and pydantic validation 项目地址: https://gitcode.com/gh_mirrors/or/ormar Ormar 是一个专为 FastAPI 设计的 Python 异步 ORM,…...