ChatGPT结合知识图谱构建医疗问答应用 (二) - 构建问答流程
一、ChatGPT结合知识图谱
上篇文章对医疗数据集进行了整理,并写入了知识图谱中,本篇文章将结合 ChatGPT 构建基于知识图谱的问答应用。
下面是上篇文章的地址:
ChatGPT结合知识图谱构建医疗问答应用 (一) - 构建知识图谱
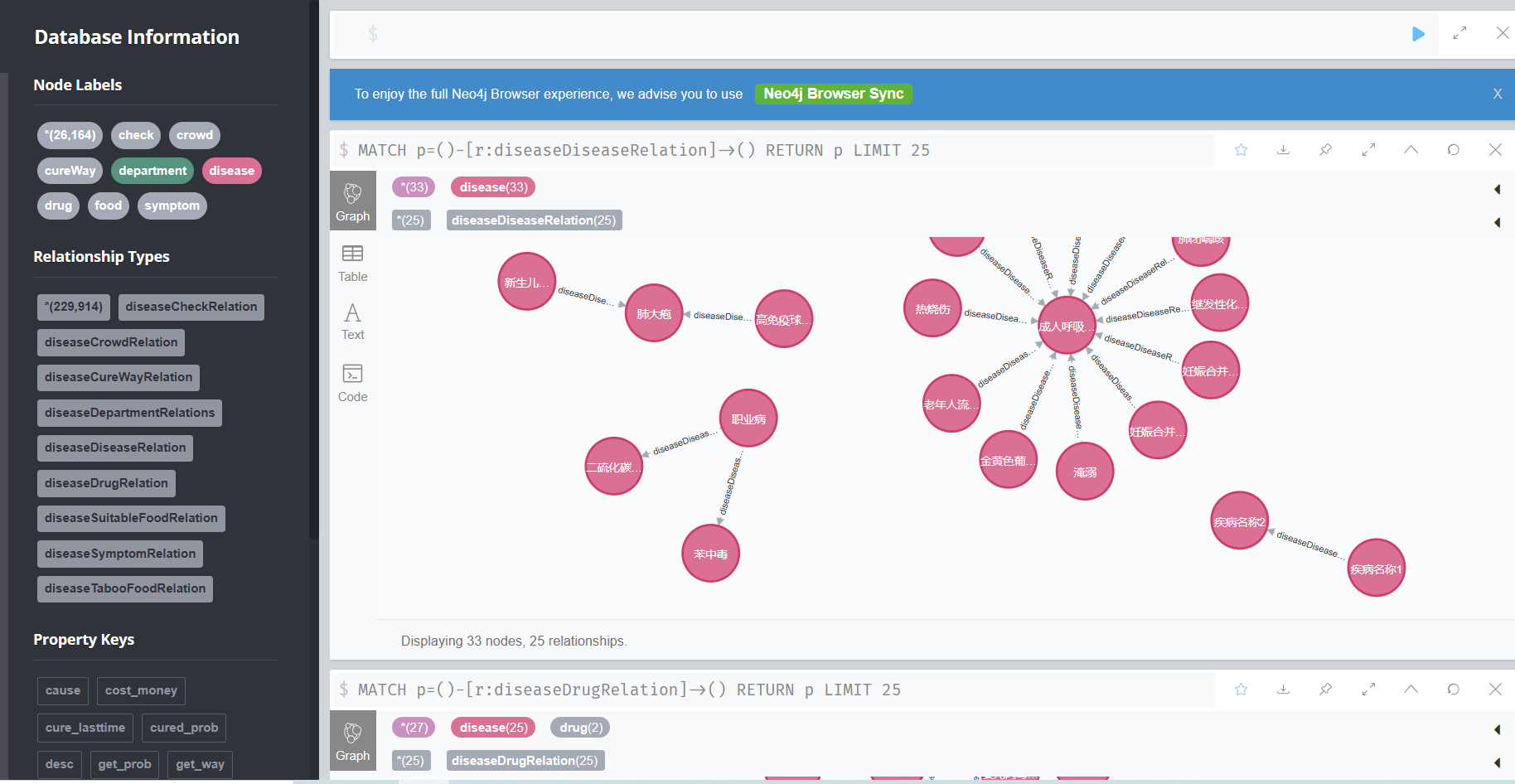
这里实现问答的流程如下所示:
二、问答流程构建
opencypher_llm.py 根据问题理解生成 opencypher 语句
import os
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
import jsonclass OpenCypherLLM():def __init__(self):# 输出格式化self.response_schemas = [ResponseSchema(name="openCypher", description="生成的 OpenCypher 检索语句")]self.output_parser = StructuredOutputParser.from_response_schemas(self.response_schemas)self.format_instructions = self.output_parser.get_format_instructions()# prompt 模版self.prompt = """你是一个知识图谱方面的专家, 现有一个医疗相关的知识图谱,图谱中的实体解释如下:\n--------------disease:疾病,存储着各种疾病的基础信息\ndepartment:科室,疾病所对应的科室\nsymptom:疾病的症状\ncureWay:疾病的治疗方式\ncheck:疾病的检查项目\ndrug:疾病的用药\ncrowd:疾病易感染人群\nfood:食物,包括宜吃和忌吃食物\n--------------\n实体与实体之间的关系如下,每个关系都可以是双向的,v表示实体、e表示关系:\n--------------\n疾病科室关系:(v:disease)-[e:diseaseDepartmentRelations]->(v:department);疾病症状关系:(v:disease)-[e:diseaseSymptomRelation]->(v:symptom);疾病治疗关系:(v:disease)-[e:diseaseCureWayRelation]->(v:cureWay);疾病检查项目关系:(v:disease)-[e:diseaseCheckRelation]->(v:check);疾病用药关系:(v:disease)-[e:diseaseDrugRelation]->(v:drug);疾病易感染人群关系:(v:disease)-[e:diseaseCrowdRelation]->(v:crowd);疾病宜吃食物关系:(v:disease)-[e:diseaseSuitableFoodRelation]->(v:food);疾病忌吃食物关系:(v:disease)-[e:diseaseTabooFoodRelation]->(v:food);疾病并发症关系:(v:disease)-[e:diseaseDiseaseRelation]->(v:disease);--------------\n实体中的主要属性信息如下:\n--------------\ndisease: {name:疾病名称,desc:疾病简介,prevent:预防措施,cause:疾病病因,get_prob:发病率,get_way:传染性,cure_lasttime:治疗周期,cured_prob:治愈概率,cost_money:大概花费}\ndepartment: {name:科室名称}\nsymptom: {name:疾病症状}\ncureWay: {name:治疗方式}\ncheck: {name:检查项目}\ndrug: {name:药物名称}\ncrowd: {name:感染人群}\nfood: {name:食物}\n--------------根据以上背景结合用户输入的问题,生成 OpenCypher 图谱检索语句,可以精准检索到相关的知识信息作为背景。\n注意: 仅使用上述提供的实体、关系、属性信息,不要使用额外未提供的内容。实体与实体之间的关系仅使用背景给出的关系\n"""self.prompt = self.prompt + self.format_instructionsself.chat = ChatOpenAI(temperature=1, model_name="gpt-3.5-turbo")def run(self, questions):res = self.chat([SystemMessage(content=self.prompt),HumanMessage(content="用户输入问题:" + questions)])res = res.contentres = res.replace("```json", "").replace("```", "")res = json.loads(res)return res["openCypher"]gc_llm.py 根据检索结果总结答案
import os
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
from langchain import PromptTemplateclass GCLLM():def __init__(self):# prompt 模版self.template = """你是一个知识图谱方面的专家,图谱中的基本信息如下:\n--------------disease:疾病实体,存储着各种疾病的基础信息\ndepartment:科室,疾病所对应的科室\nsymptom:疾病的症状\ncureWay:疾病的治疗方式\ncheck:疾病的检查项目\ndrug:疾病的用药\ncrowd:疾病易感染人群\nfood:食物,存吃包括宜吃和忌吃食物\n--------------\n上一步你生成的 OpenCypher 语句为:--------------\n{OpenCypher}--------------\nOpenCypher 语句查询的结果如下:--------------\n{content}--------------\n结合上述背景,并回答用户问题,如果提供的背景和用户问题没有相关性,则回答 “这个问题我还不知道怎么回答”注意:最后直接回复用户问题即可,不要添加 "根据查询结果" 等类似的修饰词"""self.prompt = PromptTemplate(input_variables=["OpenCypher", "content"],template=self.template,)self.chat = ChatOpenAI(temperature=1, model_name="gpt-3.5-turbo")def run(self, OpenCypher, content, questions):res = self.chat([SystemMessage(content=self.prompt.format(OpenCypher=OpenCypher, content=content)),HumanMessage(content="用户输入问题:" + questions)])return res.content过程整合
from py2neo import Graph
from opencypher_llm import OpenCypherLLM
from gc_llm import GCLLM
import osclass QA():def __init__(self, kg_host, kg_port, kg_user, kg_password):self.graph = Graph(host=kg_host,http_port=kg_port,user=kg_user,password=kg_password)self.openCypherLLM = OpenCypherLLM()self.gcLLM = GCLLM()def execOpenCypher(self, cql):if "limit" not in cql and "LIMIT" not in cql:cql = cql + " LIMIT 10 "res = self.graph.run(cql)list = []for record in res:list.append(str(record))if len(list) == 0:return ""return "\n".join(list)def run(self, questions):if not questions or questions == '':return "输入问题为空,无法做出回答!"# 生成检索语句openCypher = self.openCypherLLM.run(questions)if not openCypher or openCypher == '':return "这个问题我还不知道怎么回答"print("========生成的CQL==========")print(openCypher)# 执行检索res = self.execOpenCypher(openCypher)print("========查询图谱结果==========")print(res)if not res or res == "":return "这个问题我还不知道怎么回答"return self.gcLLM.run(openCypher, res, questions)if __name__ == '__main__':kg_host = "127.0.0.1"kg_port = 7474kg_user = "neo4j"kg_password = "123456"qa = QA(kg_host, kg_port, kg_user, kg_password)while True:questions = input("请输入问题: \n ")if questions == "q":breakres = qa.run(questions)print("========问题回答结果==========")print(res)
三、效果测试
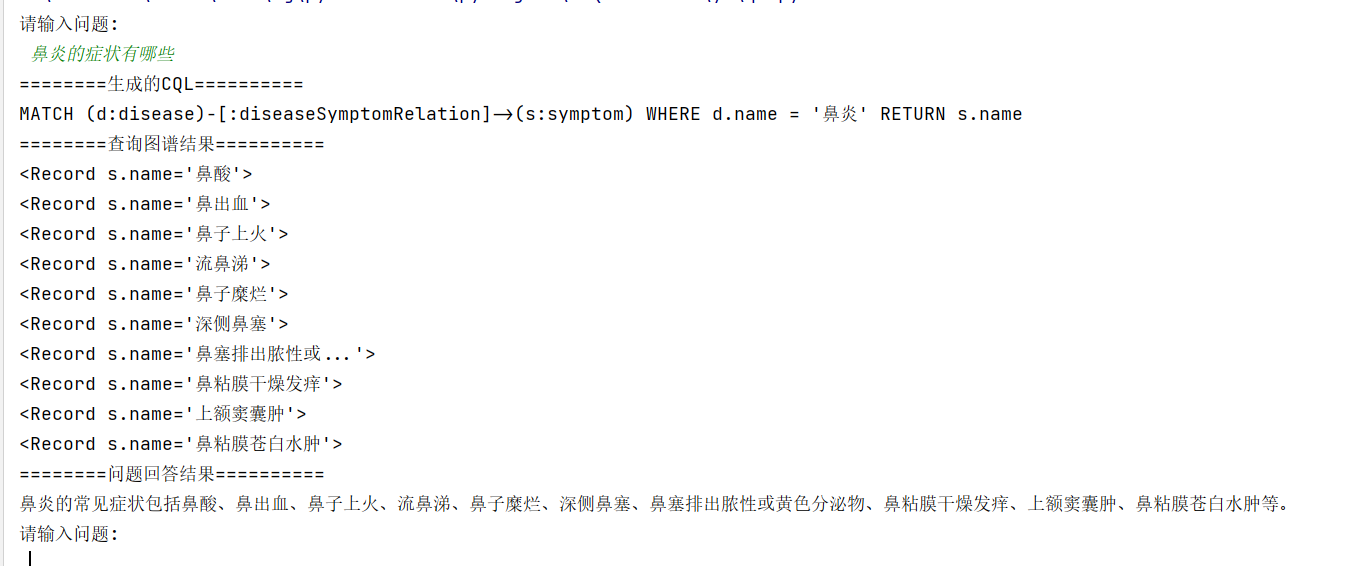
1. 鼻炎的症状有哪些
2. 鼻炎的治疗周期多久

3. 鼻炎不适合吃什么东西

3. 和鼻炎有类似症状的病有哪些

4. 鼻炎应该检查哪些项目

四、总结
上面基于医疗的知识图谱大致实现了问答的过程,可以感觉出加入ChatGPT后实现的流程非常简单,但上述流程也还有需要优化的地方,例如用户输入疾病错别字的情况如果 ChatGPT 没有更正有可能导致检索为空,还有就是有些疾病可能有多个名称但名称不在图谱中导致检索失败等等,后面可以考虑加入语义相似度的检索。
相关文章:
ChatGPT结合知识图谱构建医疗问答应用 (二) - 构建问答流程
一、ChatGPT结合知识图谱 上篇文章对医疗数据集进行了整理,并写入了知识图谱中,本篇文章将结合 ChatGPT 构建基于知识图谱的问答应用。 下面是上篇文章的地址: ChatGPT结合知识图谱构建医疗问答应用 (一) - 构建知识图谱 这里实现问答的流程…...

聊天系统登录后端实现
定义返回的数据格式 # Restful API from flask import jsonifyclass HttpCode(object):# 响应正常ok 200# 没有登陆错误unloginerror 401# 没有权限错误permissionerror 403# 客户端参数错误paramserror 400# 服务器错误servererror 500def _restful_result(code, messa…...
)
Ajax笔记_01(知识点、包含代码和详细解析)
Ajax_01笔记 前置知识点 在JavaScript中 问题1:将数组转为字符串,以及字符串转为数组的方式。 问题2、将对象转为字符串,以及字符串转为对象的方法。 方法: 问题1: 将数组转为字符串可以使用 join() 方法。例如&…...

Eureka 学习笔记2:EurekaClient
版本 awsVersion ‘1.11.277’ EurekaClient 接口实现了 LookupService 接口,拥有唯一的实现类 DiscoveryClient 类。 LookupService 接口提供以下功能: 获取注册表根据应用名称获取应用根据实例 id 获取实例信息 public interface LookupService<…...

Spring引入并启用log4j日志框架-----Spring框架
<?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://ma…...

Redis实现延时队列
缓存队列延时向接口报工,并支持多实例部署。 引入依赖 <dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-data</artifactId><version>3.17.4</version> </dependency> 注入RedisClient …...

无限遍历,Python实现在多维嵌套字典、列表、元组的JSON中获取数据
目录 背景 思路 新建两个函数A和B,函数 A处理字典数据,被调用后,判断传递的参数,如果参数为字典,则调用自身; 如果是列表或者元组,则调用列表处理函数B; 函数 B处理列表&#x…...

信息学奥赛一本通——1180:分数线划定
文章目录 题目【题目描述】【输入】【输出】【输入样例】【输出样例】【提示】 AC代码 题目 【题目描述】 世博会志愿者的选拔工作正在 A 市如火如荼的进行。为了选拔最合适的人才,A市对所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入…...

SpringApplication对象的构建及spring.factories的加载时机
构建SpringApplication对象源码: 1、调用启动类的main()方法,该方法中调用SpringApplication的run方法。 SpringBootApplication public class SpringbootdemoApplication {public static void main(String[] args) {SpringApplication.run(SpringbootdemoApplication.class, …...

基于传统检测算法hog+svm实现图像多分类
直接上效果图: 代码仓库和视频演示b站视频005期: 到此一游7758258的个人空间-到此一游7758258个人主页-哔哩哔哩视频 代码展示: 数据集在datasets文件夹下 运行01train.py即可训练 训练结束后会保存模型在本地 运行02pyqt.py会有一个可视化…...
 方法,使用 concat() 方法, [...originalArray],find(filter),移出类名 removeAttr())
slice() 方法,使用 concat() 方法, [...originalArray],find(filter),移出类名 removeAttr()
在JavaScript中,在 JavaScript 中,clone 不是一个原生的数组方法。但是你可以使用其他方法来实现克隆数组的功能。 以下是几种常见的克隆数组的方法: 使用 slice() 方法: const originalArray [1, 2, 3]; const clonedArray …...

Zabbix报警机制、配置钉钉机器人、自动发现、主动监控概述、配置主动监控、zabbix拓扑图、nginx监控实例
day02 day02配置告警用户数超过50,发送告警邮件实施验证告警配置配置钉钉机器人告警创建钉钉机器人编写脚本并测试添加报警媒介类型为用户添加报警媒介创建触发器创建动作验证自动发现配置自动发现主动监控配置web2使用主动监控修改配置文件,只使用主动…...
ELK日志分析系统概述及部署
ELK 平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kibana 三个开源工具配合使用,完成更强大的用户对日志的查询、排序、统计需求。 一、ELK概述 1、组件说明 ①ElasticSearch ElasticSearch是基于Lucene(一个全文…...

HTML拖拽
拖拽的流程:鼠标按下(mousedown)→鼠标移动(mousemove)→鼠标松开(moveup) 需要理解的几个api: clientX/clientY: 相对于浏览器视窗内的位置坐标(不包括浏览器收藏夹和顶部网址部分)pageX/pageY: 该属性会考虑滚动,如…...
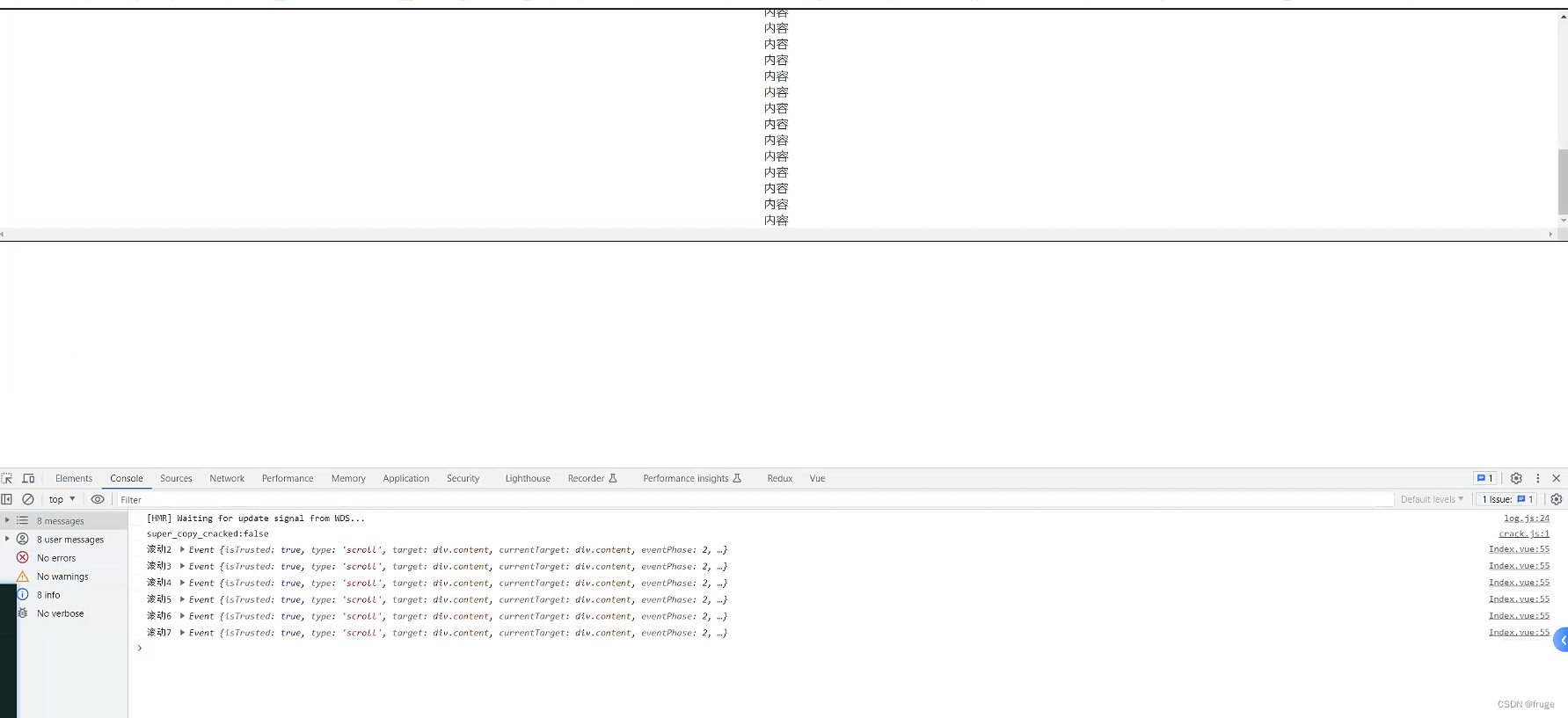
【vue】 vue2 监听滚动条滚动事件
代码 直接上代码,vue单文件 index.vue <template><div class"content" scroll"onScroll"><p>内容</p><p>内容</p><p>内容</p><p>内容</p><p>内容</p><p>内容…...

k8s目录
k8s笔记目录,更新中... 一 概念篇 1.1概念介绍 1.2 pod 1.3 controller 1.3.1 deployment 1.3.2 statefulset 1.3.3 daemonset 1.3.4 job和cronJob1 1.4 serivce和ingress 1.5 配置与存储 1.5.1 configMap 1.5.2 secret 1.5.3 持久化存储 1.5.4 pv和…...
设计模式行为型——解释器模式
目录 什么是解释器模式 解释器模式的实现 解释器模式角色 解释器模式类图 解释器模式举例 解释器模式代码实现 解释器模式的特点 优点 缺点 使用场景 注意事项 实际应用 什么是解释器模式 解释器模式(Interpreter Pattern)属于行为型模式&…...

使用 Webpack 优化前端开发流程
在现代前端开发中,构建工具的选择和优化流程的设计至关重要。Webpack 是一个功能强大的前端构建工具,能够优化我们的开发流程,提高开发效率和项目性能。本文将介绍如何使用 Webpack 来优化前端开发流程。 代码优化和资源管理也是前端项目中不…...

mysql的分库分表脚本
目录 一.分库分表优点二.过程思路脚本实现验证 一.分库分表优点 1,提高系统的可扩展性和性能:通过分库分表,可以将数据分布在多个节点上,从而提高系统的负载能力和处理性能。 2,精确备份和恢复:分库分表备…...

JavaEE初阶之文件操作 —— IO
目录 一、认识文件 1.1认识文件 1.2树型结构组织 和 目录 1.3文件路径(Path) 1.4其他知识 二、Java 中操作文件 2.1File 概述 2.2代码示例 三、文件内容的读写 —— 数据流 3.1InputStream 概述 3.2FileInputStream 概述 3.3代码示例 3.4利用 Scanner 进行字…...

OpenStack部署避坑实录:从网络不通到Dashboard白屏,我踩过的那些‘坑’及解决办法
OpenStack部署避坑指南:从时间同步到Dashboard白屏的实战解决方案 部署OpenStack云平台时,即使按照官方文档一步步操作,也难免会遇到各种"坑"。本文将分享我在实际部署过程中遇到的五个典型问题及其解决方案,帮助你在遇…...

汽车软件测试实战指南:从MiL到HiL的测试体系与工程实践
1. 汽车软件测试:从术语迷雾到实战地图 干了十几年嵌入式,从消费电子一路干到汽车电子,最深的感触就是: “隔行如隔山” ,这话在汽车软件测试领域体现得淋漓尽致。刚入行那会儿,听到同事讨论MiL、SiL、Hi…...

首次使用Taotoken从注册到发出第一个API请求的全流程指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 首次使用Taotoken从注册到发出第一个API请求的全流程指南 对于初次接触大模型API的开发者来说,从注册平台到成功发出第…...

独立开发者如何利用Taotoken快速上线并迭代AI功能原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken快速上线并迭代AI功能原型 对于独立开发者或小型工作室而言,验证一个AI产品创意的关键在于…...

AndroidCupsPrint:构建企业级Android打印服务架构的技术实践
AndroidCupsPrint:构建企业级Android打印服务架构的技术实践 【免费下载链接】AndroidCupsPrint Port of cups4j to Android. Allows wireless printing from any Android device to any CUPS-enabled print server or network printer. 项目地址: https://gitcod…...

【普中 51-Ai8051 开发攻略】-- 第 30 章 OLED 液晶显示实验-硬件 IIC
(1)实验平台: 普中 51-Ai8051 开发板https://item.taobao.com/item.htm?abbucket17&id1026052331067(2)资料下载 :普中科技-各型号产品资料下载链接 前面已经使用 IO 口软件模拟 IIC 时序与 OLED 通信实现字符汉字的显示。 本章学习使用 AI805…...

OMNeT++ 6.0.1 实战:手把手教你搞定INET 4.5.0与TSN仿真环境搭建
OMNeT 6.0.1 实战:手把手教你搞定INET 4.5.0与TSN仿真环境搭建 在当今网络技术飞速发展的背景下,时间敏感网络(TSN)因其能够提供确定性延迟和可靠数据传输的特性,正逐渐成为工业自动化、汽车电子和音视频传输等领域的核…...

Claude Code + OpenCode + OpenSpec 规范驱动开发实战:AI 驱动智能客服管理系统开发
当 AI 编程从“凭感觉聊天”升级为“按规范执行的流水线” 一、引言:AI 编程的“效率悖论” 2024 年 Google DORA 报告揭示了一个令人困惑的数据:AI 编码助手采用率每提升 25%,软件交付稳定性反而下降 7.2%。主观上开发者觉得用 AI 写代码速…...

负载电阻从500Ω到10kΩ:用Multisim深度解读谐振放大器选择性变化的底层逻辑
负载电阻从500Ω到10kΩ:用Multisim深度解读谐振放大器选择性变化的底层逻辑 在电子电路设计中,谐振放大器是一个经典而重要的电路结构。许多工程师和爱好者都能熟练地搭建电路并进行基础测试,但当被问及"为什么负载电阻的变化会影响放大…...

CANN/asc-devkit SIMD数据搬运API
LoadUnzipIndex 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...