【计算机视觉中的 GAN 】如何稳定GAN训练(3)
一、说明
在上一篇文章中,我们达到了理解未配对图像到图像翻译的地步。尽管如此,在实现自己的超酷深度GAN模型之前,您必须了解一些非常重要的概念。如本文所提的GAN模型新成员的引入:Wasserstein distance,boundary equilibrium 和 progressively growing GAN三个方面。
二、关于:瓦瑟斯坦距离、边界平衡,逐渐增长的GAN值
GAN主导着深度学习任务,如图像生成和图像翻译。
在上一篇文章中,我们达到了理解未配对图像到图像翻译的地步。尽管如此,在实现自己的超酷深度GAN模型之前,您必须了解一些非常重要的概念。
在这一部分中,我们将看看一些基础工作。我们将看到最常见的GAN距离函数及其工作原因。然后,我们将 GAN 的训练视为试图找到双人博弈的平衡。最后,我们将看到一项革命性的增量训练工作,它首次实现了逼真的百万像素图像分辨率。
我们将探索的研究主要解决模式崩溃和训练不稳定性。从未训练过GAN的人很容易争辩说我们总是提到这两个轴。在现实生活中,为新问题训练大规模 GAN 可能是一场噩梦。
如果您开始阅读和实施最新的方法,则几乎不可能在新问题中成功训练新的 GAN。实际上,这就像中了彩票一样。
当你离开最常见的数据集(CIFAR、MNIST、CELEBA)时,你就陷入了混乱。
通常情况下,您尝试直观地将学习曲线理解为调试,以便猜测可能更好地工作的超参数。但是GAN训练非常不稳定,以至于这个过程往往是浪费时间。这部可爱的工作是最早为 GAN 培训计划提供广泛理论依据的工作之一。有趣的是,他们发现了分布之间所有现有距离之间的模式。
2.1 核心理念
核心思想是有效地测量模型分布与实际分布的接近程度。因为选择测量距离的方式直接影响模型的收敛性。正如我们现在所知,GAN 可以表示低维流形(噪声 z)的分布。
直观地说,这个距离越弱,就越容易定义从参数空间(θ-space)到概率空间的映射,因为事实证明,分布更容易收敛。
我们有理由要求这种连续映射。主要是因为可以定义一个连续函数来满足这种连续映射,该映射给出所需的概率空间或生成的样本。
出于这个原因,这项工作引入了一个新的距离,称为Wasserstein-GAN。它是推土机(EM)距离的近似值,理论上表明它可以逐步优化GAN的训练。令人惊讶的是,在训练期间不需要平衡D和G,也不需要网络架构的特定设计。通过这种方式,减少了 GAN 中固有存在的模式崩溃。
2.2 了解瓦瑟斯坦距离
在我们深入研究拟议的损失之前,让我们看一些数学。正如 wiki 中完美描述的那样,偏序集合的子集的上确界 (sup) 是大于或等于 的所有元素的最小元素。因此,上确界也被称为最小上限。我个人将其称为可以在 T 中找到的所有可能组合的子集的最大值。
现在,让我们在GAN术语中引入这个概念。T 是我们可以从 G 和 D 得到的所有可能的对函数近似 f。S 将是那些函数的子集,我们将约束这些函数以使训练更好(某种正则化)。排序自然来自计算的损失函数。基于上述,我们最终可以看到测量两个分布 Pr 和 Pθ 之间距离的 Wasserstein 损失函数。
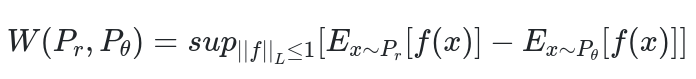
严格的数学约束称为 K-Lipschitz 函数,用于获取子集 S。但是,如果数学得到广泛证明,则不需要了解更多。但是,我们如何引入这种约束呢?
解决这个问题的一种方法是大致近似这个约束,方法是训练一个神经网络,其权重位于一个紧凑的空间中。 为了实现这一目标,最简单的方法是将砝码夹紧到固定范围内。
就是这样,重量剪辑可以按照我们想要的方式工作!因此,在每次梯度更新后,我们将w范围裁剪为[−0.01,0.01]。这样,我们就可以显著地强制执行 Lipschitz 约束。简单,但我可以向你保证它有效!
事实上,有了这个距离损失函数,当然,它是连续的和可微的,我们现在可以用提出的准则训练D,直到最优,而其他距离则饱和。饱和意味着鉴别器的损耗为零,生成的样本仅在某些情况下有意义。所以现在,饱和(自然导致模式崩溃)得到了缓解,我们可以在所有训练范围内使用更线性风格的梯度进行训练。让我们看一个例子来澄清这一点:
![图片来自WGAN论文[https://arxiv.org/abs/1701.07875]](https://img-blog.csdnimg.cn/img_convert/8cebb9a87ad6c45a6b5a8dd644662932.png)
为了在实践中查看所有以前的数学,我们在 Pytorch 中提供了 WGAN 编码方案。您可以直接修改项目以包含此损失标准。通常,最好在实际代码中看到它。值得一提的是,要保存子集并取上限,这意味着我们必须取很多对。这就是为什么你会看到我们每隔几次训练生成器,以便鉴别器获得更新。这样,我们就有了定义上确界的集合。请注意,为了接近上确界,我们还可以在升级 D 之前为 G 做很多步骤。
在后来的工作中,证明即使这个想法是可靠的,重量裁剪也是强制执行所需约束的糟糕方法。强制函数成为K-Lipschitz的另一种方法是梯度惩罚。
关键思想是相同的:将重量保持在紧凑的空间内。然而,他们通过约束批评家输出相对于其输入的梯度范数来做到这一点。
我们不会介绍本文,但为了用户的一致性和易于实验,我们提供了代码作为原版 wgan 的改进替代方案。
2.3 结果和讨论
按照我们的简要描述,我们现在可以跳入一些结果。很高兴看到GAN在训练过程中如何学习,如下图所示:
![图片来自WGAN论文[https://arxiv.org/abs/1701.07875]](https://img-blog.csdnimg.cn/img_convert/d6edfc49cd295d37987918f4b12ba437.png)
DCGAN发电机的瓦瑟斯坦损耗准则。如您所见,损失迅速稳定地减少,而样品质量提高。这项工作被认为是GAN理论方面的基础,可以总结为:
TL;RL
- Wasserstein 准则允许我们训练 D 直到最优。当标准达到最佳值时,它只是为生成器提供损失,我们可以像任何其他神经网络一样训练该生成器。
- 我们不再需要正确平衡 G 和 D 容量。
- Wasserstein损失导致训练G的梯度质量更高。
- 据观察,WGAN在生成器和超参数调优的架构选择方面比普通GAN更健壮
的确,我们确实提高了优化过程的稳定性。但是,没有什么是零成本的。WGAN训练在基于动量的优化器(如Adam)以及高学习率下变得不稳定。这是合理的,因为标准损失是高度非平稳的,因此基于动量的优化器似乎表现得更差。这就是他们使用RMSProp的原因,众所周知,RMSProp在非平稳问题上表现良好。
最后,理解本文的一种直观方法是对层内激活函数的历史进行梯度类比。具体来说,sigmoid 和 tanh 激活的梯度消失了,取而代之的是 ReLU,因为整个值范围内的梯度有所改善。
三、开始(边界均衡生成对抗网络2017)
我们经常看到判别器在训练开始时进步太快。尽管如此,平衡鉴别器和生成器的收敛性仍然是一个现有的挑战。
这是第一部能够控制图像多样性和视觉质量之间权衡的工作。用简单的模型架构和标准的训练方案获取高分辨率图像。
为了实现这一点,作者引入了一个技巧来平衡生成器和鉴别器的训练。BEGIND的核心思想是这种新实施的均衡,它与描述的Wasserstein距离相结合。为此,他们训练了一个基于自动编码器的鉴别器。有趣的是,由于D现在是一个自动编码器,它产生图像作为输出,而不是标量。在我们继续之前,让我们记住这一点!
正如我们所看到的,匹配误差的分布而不是直接匹配样本的分布更有效。关键的一点是,这项工作旨在优化自动编码器损失分布之间的Wasserstein距离,而不是样本分布之间的Wasserstein距离。BEGIND的一个优点是它没有明确要求判别器受到K-Lipschitz约束。自动编码器通常使用 L1 或 L2 范数进行训练。
3.1 两人博弈均衡的表述
为了用博弈论来表达这个问题,增加了一个平衡判别器和生成器的均衡项。假设我们可以理想地生成无法区分的样本。然后,它们的误差分布应该是相同的,包括它们的预期误差,这是我们在处理每批后测量的误差。完全平衡的训练将导致 L(x) 和 L(G(z) 的预期值相等。然而,事实并非如此!因此,BEGIN决定量化余额比率,定义为:
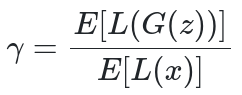
此数量在网络中建模为超参数。因此,新的训练方案涉及两个相互竞争的目标:a)自动编码真实图像和b)区分
从生成的图像中真实。γ术语让我们平衡这两个目标。较低的γ值会导致较低的图像多样性,因为鉴别器更侧重于自动编码真实图像。但是,当预期损失发生变化时,如何控制此超参数呢?
3.2 边界平衡GAN(开始)
答案很简单:我们只需要引入另一个落在 [0, 1] 范围内的变量 kt。此变量将设计用于控制训练期间放在 L(G(z)) 上的焦点。
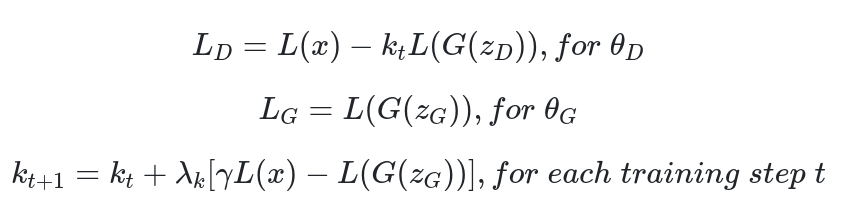
它初始化为 k0 = 0,λ_k在本研究中也被定义为 k 的比例增益(使用 0.001)。这可以看作是闭环反馈控制的一种形式,其中kt在每一步都进行调整,以保持所选超参数γ所需的平衡。
请注意,在早期训练阶段,G 倾向于为 D 生成易于重建的数据。同时,尚未准确学习真实的数据分布。基本上,L(x)>L(G(z))。与许多 GAN 相反,BEGIN 不需要预训练,可以使用 Adam 进行优化。最后,利用均衡概念推导出收敛的全局度量。
从本质上讲,可以将收敛过程表述为找到 a) 最接近的重建 L(x) 和 b) 控制算法的最低绝对值 ||γ L(x)−L(G(z)) ||.加上这两个术语,我们可以识别网络何时收敛。
3.3 模型体系结构
模型架构非常简单。一个主要区别是引入了指数线性单位而不是 ReLU。他们使用带有深度编码器和解码器的自动编码器。超参数化旨在避免典型的GAN训练技巧。
![图片来自 BEGIN [https://arxiv.org/abs/1703.10717] 论文。模型体系结构](https://img-blog.csdnimg.cn/img_convert/82e5e6c2f937aa269de01b4b233e27cf.png)
使用 U 形架构,无需跳跃连接。下采样实现为子采样卷积,内核为 3,步幅为 2。另一方面,上采样是通过最近邻插值完成的。在编码器和解码器之间,处理数据的张量通过全连接层映射,之后没有任何非线性。
3.4 结果和讨论
在下面的 128x128 插值图像中可以看到一些呈现的视觉结果:
![图片来源:BEGAN[https://arxiv.org/abs/1703.10717] .由 BEGIN 生成的插值 128x128 图像](https://img-blog.csdnimg.cn/img_convert/dc3c7613159b6eaa18e0fe5adfff5b0b.png)
图片来源:BEGAN[https://arxiv.org/abs/1703.10717] .由 BEGIN 生成的插值 128x128 图像
值得注意的是,观察到多样性随着γ而增加,但伪像(噪点)也是如此。可以看出,插值显示出良好的连续性。在第一行,头发过渡和发型被改变。还值得注意的是,左图中的某些特征消失了(香烟)。第二行和最后一行显示简单的旋转。虽然旋转很平稳,但我们可以看到个人资料图片并没有完美捕获。
最后,使用BEGIND平衡方法,网络收敛到多样化且视觉上令人愉悦的图像。在 128x128 分辨率下,只需稍作修改,情况仍然如此。训练稳定、快速,并且对微小的参数变化具有鲁棒性。
但是让我们看看在真正的高分辨率下会发生什么!
四、渐进式 GAN(GANs 的渐进增长以提高质量、稳定性和变化 2017)
到目前为止,我们描述的方法会产生清晰的图像。但是,它们仅以相对较小的分辨率和有限的变化生成图像。分辨率保持较低的原因之一是训练不稳定。如果您已经部署了自己的GAN模型,您可能知道,由于计算空间的复杂性,大分辨率需要较小的小批量。这样,时间复杂度的问题也随之上升,这意味着你需要几天的时间来训练一个GAN。
4.1 增量增长架构
为了解决这些问题,作者逐渐增加了生成器和鉴别器,从低分辨率图像到高分辨率图像。
直觉是,随着训练的进行,新添加的层旨在捕获与高分辨率图像相对应的更高频率的细节。
但是,是什么让这种方法如此出色呢?
答案很简单:模型不必同时学习所有尺度,而是首先发现大规模(全局)结构,然后发现局部细粒度细节。增量训练性质旨在朝这个方向发展。需要注意的是,在整个训练过程中,所有层都是可训练的,并且网络架构是对称的(镜像)。所述体系结构的图示如下所示:
![图片来自 GAN 论文的渐进增长 [https://arxiv.org/abs/1710.10196]](https://img-blog.csdnimg.cn/img_convert/3a01ad4a7ecca5ce78a97cabc80450a4.png)
图片来自 GAN 论文的渐进增长 [https://arxiv.org/abs/1710.10196]
然而,由于不健康的竞争,模式崩溃仍然存在,这增加了G和D中误差信号的大小。
4.2 在过渡之间引入平滑层
这项工作的关键创新是新增加的层数平稳过渡,以稳定训练。但是每次过渡后会发生什么?
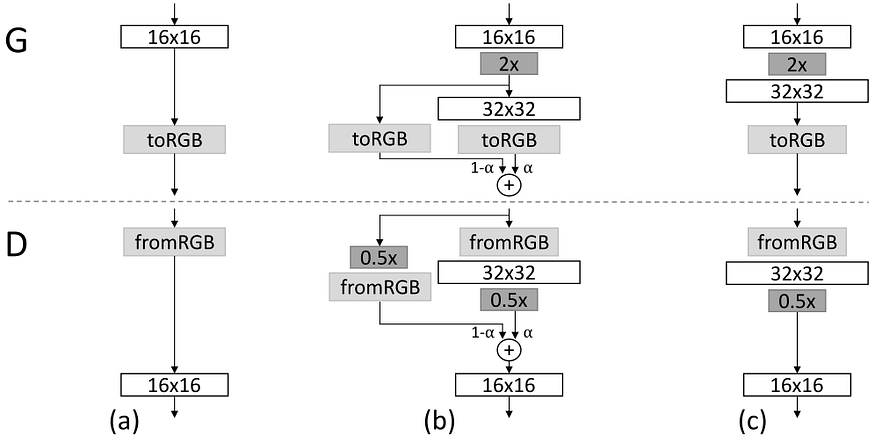
图片来自 GAN 论文的渐进式增长,链接:https://arxiv.org/abs/1710.10196
真正发生的事情是图像分辨率翻了一番。因此,在 G 和 D 上添加了一个新层。这就是魔术发生的地方。在过渡期间,以更高分辨率运行的层被用作残差跳跃连接块,其权重 (α) 从 0 线性增加到 1。一个表示跳过连接被丢弃。
所描绘的 toRGB 块表示将一维特征向量投影并重塑为 RGB 颜色的层。它可以被视为始终使图像具有正确形状的连接层。同时,fromRGB 执行相反的操作,而两者都使用 1 × 1 卷积。真实图像相应地缩小以匹配当前尺寸。
有趣的是,在过渡期间,作者在真实图像的两种分辨率之间进行插值,类似于类似GAN的学习。此外,对于渐进式 GAN,大多数迭代都是以较低的分辨率执行的,导致 2 到 6 个列车加速。因此,这是第一部达到百万像素分辨率的作品,即 1024x1024。
与遇到协方差偏移的下游任务不同,GAN 表现出不断增加的误差信号幅度和竞争问题。为了解决这些问题,他们使用正态分布初始化和每层权重归一化,通过每批动态计算的标量。这被认为可以使模型学习尺度不变性。为了进一步约束信号幅度,它们还将像素特征向量归一化为生成器中的单位长度。这可以防止特征图的升级,同时不会显着恶化结果。随附的视频可能有助于理解设计选择。官方代码在TensorFlow中发布在这里。
4.3 DR:结果和讨论
结果可以总结如下:
1)网络容量的逐渐增加解释了融合性的改善。直观地说,现有层学习较低的比例,因此在过渡之后,引入的层的任务只是通过越来越小的比例效果来细化表示。
2)渐进式增长的加速随着输出分辨率的提高而增加。这首次能够生成 1024x1024 的清晰图像。
3)尽管实现这样的架构确实很困难,并且缺少许多培训细节(即何时进行过渡以及为什么过渡),但它仍然是我个人喜欢的令人难以置信的工作。

图片来自 GANs的渐进增长,百万像素分辨率,链接:https://arxiv.org/abs/1710.10196
4.4 结论
在这篇文章中,我们遇到了一些即使在今天也使用的最高级培训概念。我们专注于涵盖这些重要培训方面的原因是能够进一步介绍更高级的应用程序。如果你想从更多的博弈论角度看待GANs,我们强烈建议你观看Daskalakis的演讲。最后,对于我们的数学爱好者,这里有一篇精彩的文章,更详细地介绍了向 WGAN 的过渡。
总而言之,我们已经找到了几种通过增量训练来处理模式崩溃、大规模数据集和百万像素分辨率的方法。对于整个文章系列,请随时访问AI之夏。
五、引用
[1] Arjovsky, M., Chintala, S., & Bottou, L. (2017).瓦瑟斯坦甘。arXiv预印本arXiv:1701.07875。
[2] Berthelot, D., Schumm, T., & Metz, L. (2017).开始:边界均衡生成对抗网络。arXiv预印本arXiv:1703.10717。
[3] Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017).逐步生长甘氏,以提高质量、稳定性和变化。arXiv预印本arXiv:1710.10196。
[4] Daskalakis, C., Ilyas, A., Syrgkanis, V., & Zeng, H. (2017).训练人乐观。arXiv预印本arXiv:1711.00141。
[5] Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., & Courville, A. C. (2017).改进了瓦瑟斯坦甘斯的训练。神经信息处理系统进展(第5767-5777页)。
相关文章:
【计算机视觉中的 GAN 】如何稳定GAN训练(3)
一、说明 在上一篇文章中,我们达到了理解未配对图像到图像翻译的地步。尽管如此,在实现自己的超酷深度GAN模型之前,您必须了解一些非常重要的概念。如本文所提的GAN模型新成员的引入:Wasserstein distance,boundary eq…...

一文讲清楚地图地理坐标系
前言 我最近在做一个和地图有关的项目,这里本人地图采用的是mapbox,其中涉及一个功能需要根据用户输入的地点直接定位到地图上的对应的位置,本人开始想的是直接调用百度的接口根据地名直接获取坐标,发现在地图上的位置有偏移不够…...
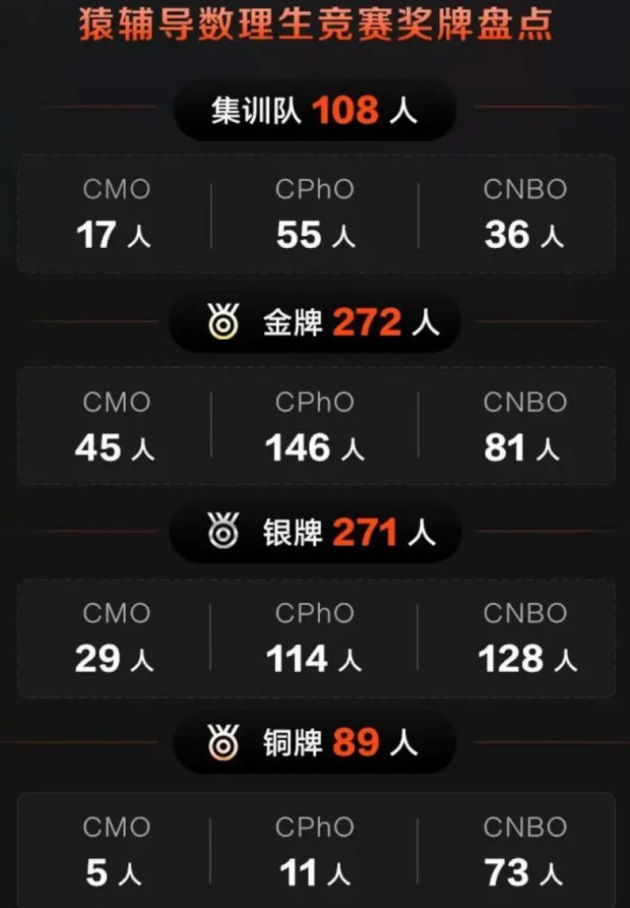
助力青少年科技创新人才培养,猿辅导投资1亿元设立新基金
近日,在日本千叶县举办的2023年第64届国际数学奥林匹克(IMO)竞赛公布比赛结果,中国队连续5年获得团体第一。奖牌榜显示,代表中国参赛的6名队员全部获得金牌。其中,猿辅导学员王淳稷、孙启傲分别以42分、39分…...
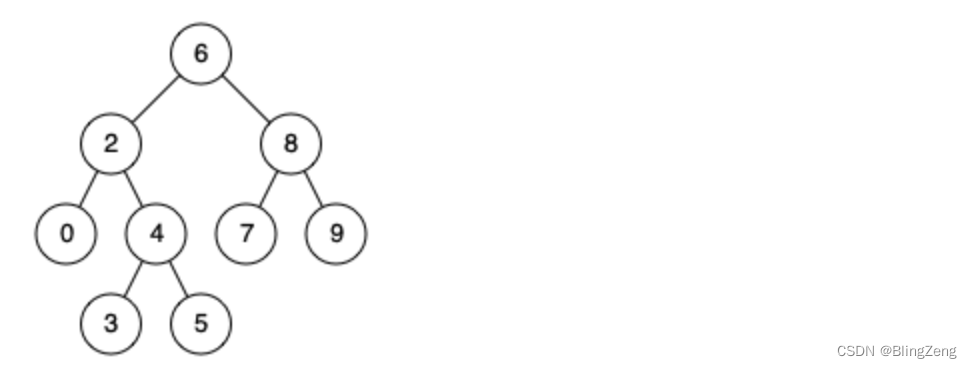
代码随想录算法训练营之JAVA|第十八天| 235. 二叉搜索树的最近公共祖先
今天是第 天刷leetcode,立个flag,打卡60天,如果做不到,完成一件评论区点赞最高的挑战。 算法挑战链接 235. 二叉搜索树的最近公共祖先https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-search-tree/descriptio…...
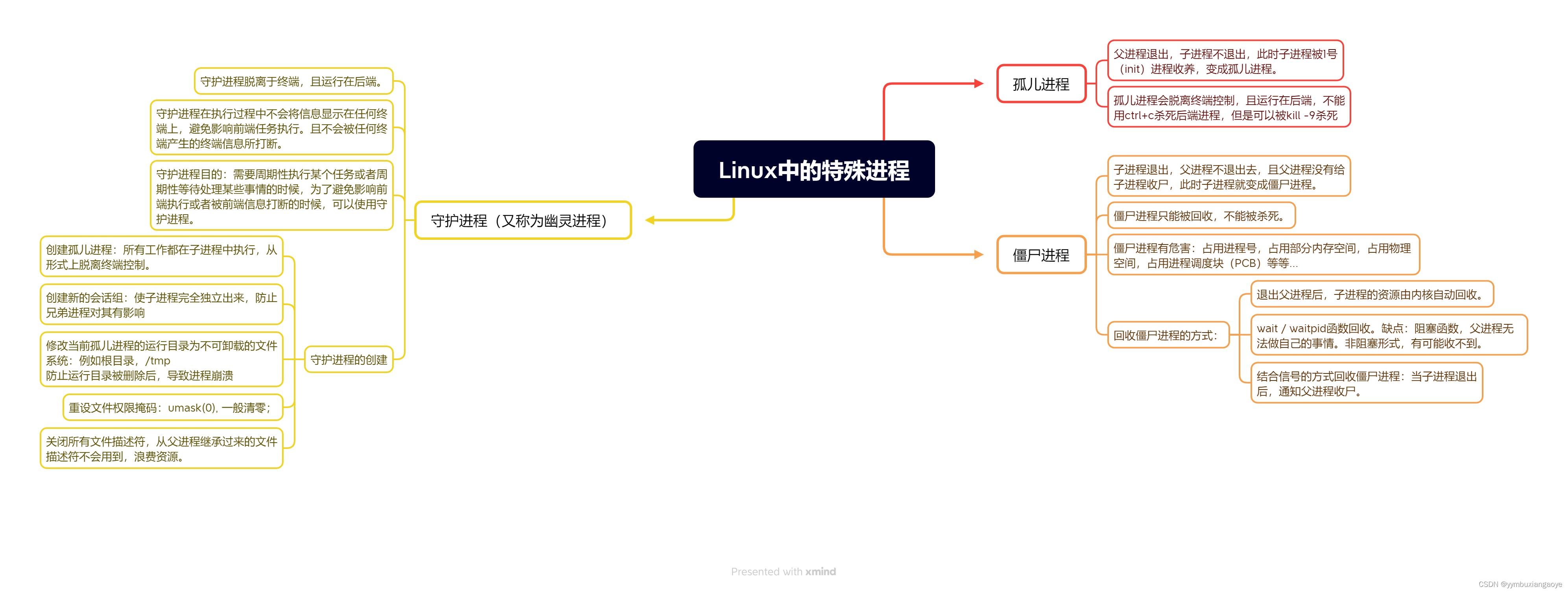
IO进程线程第五天(8.2)进程函数+XMind(守护进程(幽灵进程),输出一个时钟,终端输入quit时退出时钟)
1.守护进程(幽灵进程) #include<stdio.h> #include<head.h> int main(int argc, const char *argv[]) {pid_t cpid fork();if(0cpid){ //创建新的会话pid_t sidsetsid();printf("sid%d\n",sid);//修改运行目录为不可卸载的文件…...

物联网远程智能控制设备——开关量/正反转百分比控制
如今生产生活的便利性极大程度上得益于控制技术的发展,它改变了传统的工作模式,并将人们从【纯劳力】中解放出来。如今,随着科学技术的进步,控制器的种类及应用领域也越来越多。 物联网远程智能控制设备就是一种新型的、能够用于…...

echarts图表基本使用
折线图 import * as echarts from echarts;const chartDom document.getElementById(main); const myChart echarts.init(chartDom); const option {xAxis: {type: category,data: [Mon, Tue, Wed, Thu, Fri, Sat, Sun]},yAxis: {type: value},series: [{data: [820, 932, …...

排序进行曲-v1.0
排序 排序是将一组数据按照一定的规则进行排列的过程。在计算机科学中,排序是一 种常见的算法问题,通常用于对数据进行整理、查找、统计等操作。概念解读 基本概念 排序算法:排序算法是实现数据排序的具体方法。常见的排序算法包括冒泡排序…...
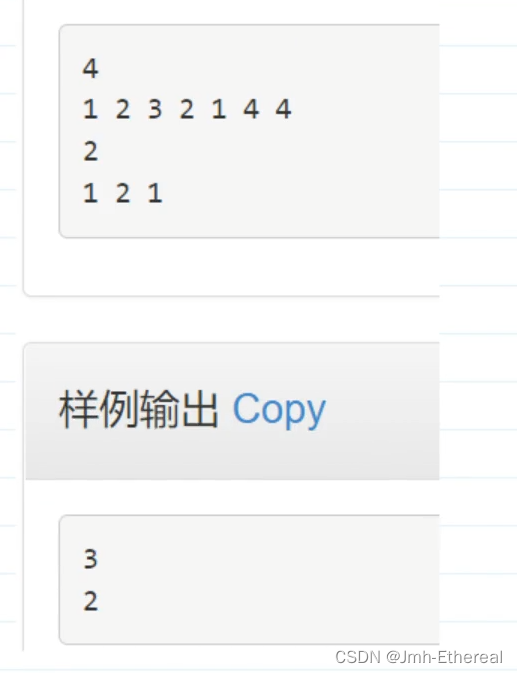
算法入门篇——用位运算解决一些问题
目录 1.判断一个数是2的次方数 2.统计一个数,它的二进制数中,1的个数 3.在2*(n-1)个数中,找到只出现一次的那个数 1.判断一个数是2的次方数 这个问题有好几种做法,但是最优雅的解法是用’位运算‘来做。…...
腾讯云-宝塔添加MySQL数据库
1. 数据库菜单 2. 添加数据库 3. 数据库添加成功 4. 上传数据库文件 5. 导入数据库文件 6. 开启数据库权限 7. 添加安全组 (宝塔/腾讯云) 8. Navicat 连接成功...

【雕爷学编程】MicroPython动手做(27)——物联网之掌控板小程序
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...

Mysql删除重复数据通用SQL
在日常开发过程中,可能会出现一些 bug,导致 Mysql 数据库数据重复,需要删除重复数据,这里记录下删除重复数据的通用 SQL ,方便以后需要时查阅 1、写法一 DELETE t1 FROMtbl_name t1 INNER JOIN tbl_name t2 WHEREt1.…...

“快速入门Spring Boot:从零开始构建Web应用程序“
标题:快速入门Spring Boot:从零开始构建Web应用程序 摘要:本文将介绍如何使用Spring Boot从零开始构建一个简单的Web应用程序。我们将学习如何配置和启动Spring Boot应用程序,创建控制器和路由,以及如何使用模板引擎来…...
微信小程序tab加列表demo
一、效果 代码复制即可使用,记得把图标替换成个人工程项目图片。 微信小程序开发经常会遇到各种各样的页面组合,本demo为list列表与tab组合,代码如下: 二、json代码 {"usingComponents": {},"navigationStyle&q…...

深入挖掘地核和地幔之间的相互作用
一本新书介绍了我们在理解地核-地幔相互作用和共同进化方面的重大进展,并展示了提高我们对地球深层过程的洞察力的技术发展。 与地核-地幔共同演化相关的地球深层结构和动力学的图示。图片来源:白石千寻 Editors Vox是 AGU 出版部的博客。 地球深层内部很…...
网络:SecureCRT介绍
1. 使用Tab键补全时出现^I,如下操作...

我的512天创作纪念日
眼馋csdn发的虚拟徽章,所以写此文。个人总结,无技术分享。 机缘 写代码的机缘,在于听说这个挣钱多,坐办公室,凤吹不着,雨淋不着。 而写blog的机缘,则在于是自己的技术的总结,经常是…...

mysql进阶-用户密码的设置和管理
一、修改密码 1.1 修改自己的密码 方式一: 推荐使用 alter user user() identified by 新密码;方式二: set password 新密码;演示 [rootVM-4-6-centos /]# mysql -uzhang3 -pZhangSan123456 mysql: [Warning] Using a password on the command line…...
2023年最新智能优化算法之——切诺贝利灾难优化器 (CDO),附MATLAB代码和文献
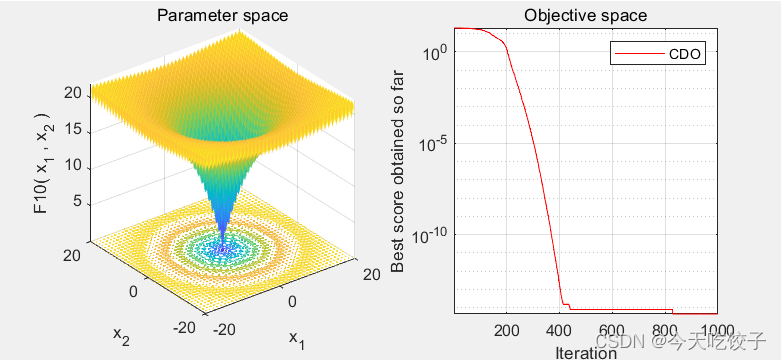
切诺贝利灾难优化器Chernobyl Disaster Optimizer (CDO)是H. Shehadeh于2023年提出的新型智能优化算法。该方法是受到切尔诺贝利核反应堆堆芯爆炸而来的启发。在CDO方法中,放射性的发生是由于核的不稳定性,核爆炸会发出不同类型的辐射。这些辐射中最常见…...
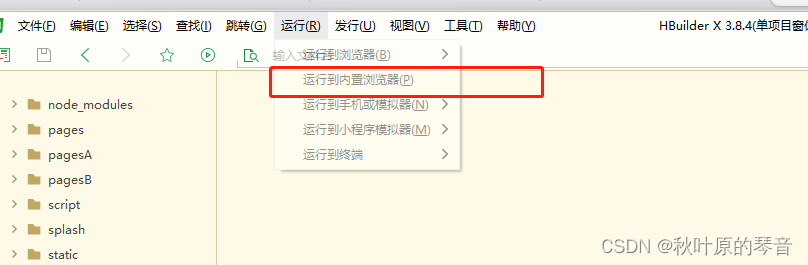
uniapp跨域解决
uniapp跨域解决 跨域是什么 跨域指的是浏览器不能执行其他网站的脚本,当一个网页去请求另一个域名的资源时,域名、端口、协议任一不同,就会存在跨域。跨域是由浏览器的同源策略造成的,是浏览器对JavaScript施加的安全限制。 报错…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

新能源车轻量化为什么开始盯上高强镁合金?
续航,是悬在每一台纯电动汽车头上的达摩克利斯之剑。多充一度电、多堆一些正极材料,是一条路;但还有另一条路——把车造得更轻。 SAE(美国汽车工程师学会)的测算已经被反复引用:整车每减重100千克ÿ…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...