Proxy lab
CSAPP Proxy Lab
本实验需要实现一个web代理服务器,实现逐步从迭代到并发,到最终的具有缓存功能的并发代理服务器。
Web 代理是充当 Web 浏览器和终端服务器之间的中间人的程序。浏览器不是直接联系终端服务器获取网页,而是联系代理,代理将请求转发到终端服务器。当终端服务器回复代理时,代理将回复发送给浏览器。
本实验共三个部分,具体要求如下:
- 在本实验的第一部分,您将设置代理以接受传入连接、读取和解析请求、将请求转发到 Web 服务器、读取服务器的响应并将这些响应转发到相应的客户端。第一部分将涉及学习基本的 HTTP 操作以及如何使用套接字编写通过网络连接进行通信的程序。
- 在第二部分中,您将升级代理以处理多个并发连接。这将向您介绍如何处理并发,这是一个重要的系统概念。
- 在第三部分也是最后一部分,您将使用最近访问的 Web 内容的简单主内存缓存将缓存添加到您的代理。
Part I
实现迭代Web代理,首先是实现一个处理HTTP/1.0 GET请求的基本迭代代理。开始时,我们的代理应侦听端⼝上的传⼊连接,端⼝号将在命令行中指定。建⽴连接后,您的代理应从客⼾端读取整个请求并解析请求。它应该判断客户端是否发送了⼀个有效的 HTTP 请求;如果是这样,它就可以建⽴自⼰与适当的 Web 服务器的连接,然后请求客⼾端指定的对象。最后,您的代理应读取服务器的响应并将其转发给客⼾端。
我们先将tiny.c中的基本框架复制过来,移除不需要的函数,保留doit,parse_uri,clienterror即可,其他还用不到,接下来我们需要修改的是doit和parse_uri,doit应该做的事如下:
- 读取客户端的请求行,判断其是否是GET请求,若不是,调用
clienterror向客户端打印错误信息。 parse_uri调用解析uri,提取出主机名,端口,路径信息。- 代理作为客户端,连接目标服务器。
- 调用
build_request函数构造新的请求报文new_request。 - 将请求报文
build_request发送给目标服务器。 - 接受目标服务器的数据,并将其直接发送给源客户端。
代码如下:
#include <stdio.h>#include "csapp.h"/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr ="User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
static const char *conn_hdr = "Connection: close\r\n";
static const char *proxy_hdr = "Proxy-Connection: close\r\n";void doit(int fd);
void parse_uri(char *uri, char *hostname, char *path, int *port);
void build_request(rio_t *real_client, char *new_request, char *hostname, char *port);
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg);int main(int argc, char **argv) {int listenfd, connfd;char hostname[MAXLINE], port[MAXLINE];socklen_t clientlen;struct sockaddr_storage clientaddr;/* Check command line args */if (argc != 2) {fprintf(stderr, "usage: %s <port>\n", argv[0]);exit(1);}listenfd = Open_listenfd(argv[1]);while (1) {clientlen = sizeof(clientaddr);connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);printf("Accepted connection from (%s, %s)\n", hostname, port);doit(connfd);Close(connfd);}
}void doit(int fd) {int real_server_fd;char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];char hostname[MAXLINE], path[MAXLINE];rio_t rio_client, rio_server;int port;/* Read request line and headers */Rio_readinitb(&rio_client, fd); // 初始化rio内部缓冲区if (!Rio_readlineb(&rio_client, buf, MAXLINE)) return; // 读到0个字符,return// 请求行: GET http://www.cmu.edu/hub/index.html HTTP/1.1sscanf(buf, "%s %s %s", method, uri, version);if (strcasecmp(method, "GET")) {clienterror(fd, method, "501", "Not Implemented", "Tiny does not implement this method");return;}// 解析uriparse_uri(uri, hostname, path, &port);char port_str[10];sprintf(port_str, "%d", port);// 代理作为客户端,连接目标服务器real_server_fd = Open_clientfd(hostname, port_str);Rio_readinitb(&rio_server, real_server_fd); // 初始化riochar new_request[MAXLINE];sprintf(new_request, "GET %s HTTP/1.0\r\n", path);build_request(&rio_client, new_request, hostname, port_str);// 向目标服务器发送http报文Rio_writen(real_server_fd, new_request, strlen(new_request));int char_nums;// 从目标服务器读到的数据直接发送给客户端while ((char_nums = Rio_readlineb(&rio_server, buf, MAXLINE))) Rio_writen(fd, buf, char_nums);
}void parse_uri(char *uri, char *hostname, char *path, int *port) {*port = 80; // 默认端口char *ptr_hostname = strstr(uri, "//");// http://hostname:port/pathif (ptr_hostname)ptr_hostname += 2; // 绝对urielseptr_hostname = uri; // 相对uri,相对url不包含"http://"或"https://"等协议标识符char *ptr_port = strstr(ptr_hostname, ":");if (ptr_port) {// 字符串ptr_hostname需要以'\0'为结尾标记*ptr_port = '\0';strncpy(hostname, ptr_hostname, MAXLINE);sscanf(ptr_port + 1, "%d%s", port, path);} else { // uri中没有端口号char *ptr_path = strstr(ptr_hostname, "/");if (ptr_path) {strncpy(path, ptr_path, MAXLINE);*ptr_path = '\0';strncpy(hostname, ptr_hostname, MAXLINE);} else {strncpy(hostname, ptr_hostname, MAXLINE);strcpy(path, "");}}
}
void build_request(rio_t *real_client, char *new_request, char *hostname, char *port) {char temp_buf[MAXLINE];// 获取client的请求报文while (Rio_readlineb(real_client, temp_buf, MAXLINE) > 0) {if (strstr(temp_buf, "\r\n")) break; // end// 忽略以下几个字段的信息if (strstr(temp_buf, "Host:")) continue;if (strstr(temp_buf, "User-Agent:")) continue;if (strstr(temp_buf, "Connection:")) continue;if (strstr(temp_buf, "Proxy Connection:")) continue;sprintf(new_request, "%s%s", new_request, temp_buf);printf("%s\n", new_request);fflush(stdout);}sprintf(new_request, "%sHost: %s:%s\r\n", new_request, hostname, port);sprintf(new_request, "%s%s%s%s", new_request, user_agent_hdr, conn_hdr, proxy_hdr);sprintf(new_request, "%s\r\n", new_request);
}void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg) {char buf[MAXLINE];/* Print the HTTP response headers */sprintf(buf, "HTTP/1.0 %s %s\r\n", errnum, shortmsg);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "Content-type: text/html\r\n\r\n");Rio_writen(fd, buf, strlen(buf));/* Print the HTTP response body */sprintf(buf, "<html><title>Tiny Error</title>");Rio_writen(fd, buf, strlen(buf));sprintf(buf,"<body bgcolor=""ffffff"">\r\n");Rio_writen(fd, buf, strlen(buf));sprintf(buf, "%s: %s\r\n", errnum, shortmsg);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "<p>%s: %s\r\n", longmsg, cause);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "<hr><em>The Tiny Web server</em>\r\n");Rio_writen(fd, buf, strlen(buf));
}若程序出现错误,printf大法依然是定位错误的好方法。此外可以通过使用curl来模拟操作。需要注意的是需要先运行proxy和tiny再运行curl,tiny就相当于一个目标服务器,curl则相当于一个客户端。

Part II
接下来我们需要改变上面的程序,使其可以处理多个并发请求,这里使用多线程来实现并发服务器。具体如下:
Accept之后通过创建新的线程来完成doit函数。- 注意:由于并发导致的竞争,所以需要注意connfd传入的形式,这里选择将每个已连接描述符分配到它自己的动态分配的内存块。
代码如下,只需要在Part I 基础上略作修改即可。
#include <stdio.h>#include "csapp.h"/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr ="User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
static const char *conn_hdr = "Connection: close\r\n";
static const char *proxy_hdr = "Proxy-Connection: close\r\n";void *doit(void *vargp);
void parse_uri(char *uri, char *hostname, char *path, int *port);
void build_request(rio_t *real_client, char *new_request, char *hostname, char *port);
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg);
int main(int argc, char **argv) {int listenfd, *connfd;char hostname[MAXLINE], port[MAXLINE];socklen_t clientlen;struct sockaddr_storage clientaddr;/* Check command line args */if (argc != 2) {fprintf(stderr, "usage: %s <port>\n", argv[0]);exit(1);}listenfd = Open_listenfd(argv[1]);pthread_t tid;while (1) {clientlen = sizeof(clientaddr);connfd = Malloc(sizeof(int)); // 给已连接的描述符分配其自己的内存块,消除竞争*connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);printf("Accepted connection from (%s, %s)\n", hostname, port);Pthread_create(&tid, NULL, doit, connfd);}
}void *doit(void *vargp) {int fd = *((int *)vargp);Free(vargp);Pthread_detach(Pthread_self());int real_server_fd;char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];char hostname[MAXLINE], path[MAXLINE];rio_t rio_client, rio_server;int port;/* Read request line and headers */Rio_readinitb(&rio_client, fd); // 初始化rio内部缓冲区if (!Rio_readlineb(&rio_client, buf, MAXLINE)) return; // 读到0个字符,return// 请求行: GET http://www.cmu.edu/hub/index.html HTTP/1.1sscanf(buf, "%s %s %s", method, uri, version);if (strcasecmp(method, "GET")) {clienterror(fd, method, "501", "Not Implemented", "Tiny does not implement this method");return;}// 解析uriparse_uri(uri, hostname, path, &port);char port_str[10];sprintf(port_str, "%d", port);// 代理作为客户端,连接目标服务器real_server_fd = Open_clientfd(hostname, port_str);Rio_readinitb(&rio_server, real_server_fd); // 初始化riochar new_request[MAXLINE];sprintf(new_request, "GET %s HTTP/1.0\r\n", path);build_request(&rio_client, new_request, hostname, port_str);// 向目标服务器发送http报文Rio_writen(real_server_fd, new_request, strlen(new_request));int char_nums;// 从目标服务器读到的数据直接发送给客户端while ((char_nums = Rio_readlineb(&rio_server, buf, MAXLINE))) Rio_writen(fd, buf, char_nums);Close(fd);
}void parse_uri(char *uri, char *hostname, char *path, int *port) {*port = 80; // 默认端口char *ptr_hostname = strstr(uri, "//");// http://hostname:port/pathif (ptr_hostname)ptr_hostname += 2; // 绝对urielseptr_hostname = uri; // 相对uri,相对url不包含"http://"或"https://"等协议标识符char *ptr_port = strstr(ptr_hostname, ":");if (ptr_port) {// 字符串ptr_hostname需要以'\0'为结尾标记*ptr_port = '\0';strncpy(hostname, ptr_hostname, MAXLINE);sscanf(ptr_port + 1, "%d%s", port, path);} else { // uri中没有端口号char *ptr_path = strstr(ptr_hostname, "/");if (ptr_path) {strncpy(path, ptr_path, MAXLINE);*ptr_path = '\0';strncpy(hostname, ptr_hostname, MAXLINE);} else {strncpy(hostname, ptr_hostname, MAXLINE);strcpy(path, "");}}
}
void build_request(rio_t *real_client, char *new_request, char *hostname, char *port) {char temp_buf[MAXLINE];// 获取client的请求报文while (Rio_readlineb(real_client, temp_buf, MAXLINE) > 0) {if (strstr(temp_buf, "\r\n")) break; // end// 忽略以下几个字段的信息if (strstr(temp_buf, "Host:")) continue;if (strstr(temp_buf, "User-Agent:")) continue;if (strstr(temp_buf, "Connection:")) continue;if (strstr(temp_buf, "Proxy Connection:")) continue;sprintf(new_request, "%s%s", new_request, temp_buf);printf("%s\n", new_request);fflush(stdout);}sprintf(new_request, "%sHost: %s:%s\r\n", new_request, hostname, port);sprintf(new_request, "%s%s%s%s", new_request, user_agent_hdr, conn_hdr, proxy_hdr);sprintf(new_request, "%s\r\n", new_request);
}void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg) {char buf[MAXLINE];/* Print the HTTP response headers */sprintf(buf, "HTTP/1.0 %s %s\r\n", errnum, shortmsg);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "Content-type: text/html\r\n\r\n");Rio_writen(fd, buf, strlen(buf));/* Print the HTTP response body */sprintf(buf, "<html><title>Tiny Error</title>");Rio_writen(fd, buf, strlen(buf));sprintf(buf,"<body bgcolor=""ffffff"">\r\n");Rio_writen(fd, buf, strlen(buf));sprintf(buf, "%s: %s\r\n", errnum, shortmsg);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "<p>%s: %s\r\n", longmsg, cause);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "<hr><em>The Tiny Web server</em>\r\n");Rio_writen(fd, buf, strlen(buf));
}Part III
第三部分需要添加缓存web对象的功能。根据实验文档的要求我们需要实现对缓存实现读写者问题,且缓存的容量有限,当容量不足是,要按照类似LRU算法进行驱逐。我们先定义缓存的结构,这里使用的是双向链表,选择这个数据结构的原因在于LRU算法的需求,链尾即使最近最少使用的web对象。关于缓存的定义以及相关操作如下:
struct cache {char *url;char *content; // web object,这里只是简单的将目标服务器发来的数据进行保存struct cache *prev;struct cache *next;
};struct cache *head = NULL;
struct cache *tail = NULL;/* 创建缓存节点 */
struct cache *create_cacheNode(char *url, char *content) {struct cache *node = (struct cache *)malloc(sizeof(struct cache));int len = strlen(url);node->url = (char *)malloc(len * sizeof(char));strncpy(node->url, url, len);len = strlen(content);node->content = (char *)malloc(len * sizeof(char));strncpy(node->content, content, len);node->prev = NULL;node->next = NULL;return node;
}
/* 将节点添加到缓存头部 */
void add_cacheNode(struct cache *node) {node->next = head;node->prev = NULL;if (head != NULL) {head->prev = node;}head = node;if (tail == NULL) {tail = node;}total_size += strlen(node->content) * sizeof(char);
}
/* 删除缓存尾部节点 */
void delete_tail_cacheNode() {if (tail != NULL) {total_size -= strlen(tail->content) * sizeof(char);Free(tail->content);Free(tail->url);struct cache *tmp = tail;tail = tail->prev;Free(tmp);if (tail != NULL) {tail->next = NULL;} else {head = NULL;}}
}
/* 移动缓存节点到头部 */
void move_cacheNode_to_head(struct cache *node) {if (node == head) {return;} else if (node == tail) {tail = tail->prev;tail->next = NULL;} else {node->prev->next = node->next;node->next->prev = node->prev;}node->prev = NULL;node->next = head;head->prev = node;head = node;
}
/* 获取缓存数据 */
char *get_cacheData(char *url) {struct cache *node = head;while (node != NULL) {if (strcmp(node->url, url) == 0) {move_cacheNode_to_head(node);return node->content;}node = node->next;}return NULL;
}此外还需要实现读者写者问题,为此定义了如下几个相关变量:
int readcnt = 0; // 目前读者数量
sem_t mutex_read_cnt, mutex_content;
void init() {Sem_init(&mutex_content, 0, 1);Sem_init(&mutex_read_cnt, 0, 1);
}
同时,定义了reader和writer函数作为读者和写者。
int reader(int fd, char *url);其内调用get_cacheData检查是否缓存命中,若是,则将所缓存的数据通过fd发送给客户端,否则返回0表示缓存未命中。void writer(char **url*, char **content*);缓存未命中后,与之前一样进行代理服务,从目标服务器接收数据后发送到客户端,如果web object的大小符号要求的话,再调用writer将接收的数据进行缓存。
总代码如下:
#include <stdio.h>#include "csapp.h"/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400char *content_tmp[MAX_OBJECT_SIZE];
/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr ="User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
static const char *conn_hdr = "Connection: close\r\n";
static const char *proxy_hdr = "Proxy-Connection: close\r\n";int total_size = 0; // 缓存中有效载荷总大小
int readcnt = 0; // 目前读者数量
sem_t mutex_read_cnt, mutex_content;struct cache {char *url;char *content; // web 对象,这里只是简单的将目标服务器发来的数据进行保存struct cache *prev;struct cache *next;
};struct cache *head = NULL;
struct cache *tail = NULL;// 缓存操作辅助函数
char *get_cacheData(char *url);
void move_cacheNode_to_head(struct cache *node);
void delete_tail_cacheNode();
void add_cacheNode(struct cache *node);
struct cache *create_cacheNode(char *url, char *content);void writer(char *url, char *content);
int reader(int fd, char *url);
void init();void *doit(void *vargp);
void parse_uri(char *uri, char *hostname, char *path, int *port);
void build_request(rio_t *real_client, char *new_request, char *hostname, char *port);
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg);int main(int argc, char **argv) {init();int listenfd, *connfd;char hostname[MAXLINE], port[MAXLINE];socklen_t clientlen;struct sockaddr_storage clientaddr;/* Check command line args */if (argc != 2) {fprintf(stderr, "usage: %s <port>\n", argv[0]);exit(1);}listenfd = Open_listenfd(argv[1]);pthread_t tid;while (1) {clientlen = sizeof(clientaddr);connfd = Malloc(sizeof(int)); // 给已连接的描述符分配其自己的内存块,消除竞争*connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);printf("Accepted connection from (%s, %s)\n", hostname, port);Pthread_create(&tid, NULL, doit, connfd);}
}void *doit(void *vargp) {int fd = *((int *)vargp);Free(vargp);Pthread_detach(Pthread_self());int real_server_fd;char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];char hostname[MAXLINE], path[MAXLINE], url[MAXLINE];rio_t rio_client, rio_server;int port;/* Read request line and headers */Rio_readinitb(&rio_client, fd); // 初始化rio内部缓冲区if (!Rio_readlineb(&rio_client, buf, MAXLINE)) return; // 读到0个字符,return// 请求行: GET http://www.cmu.edu/hub/index.html HTTP/1.1sscanf(buf, "%s %s %s", method, uri, version);if (strcasecmp(method, "GET")) {clienterror(fd, method, "501", "Not Implemented", "Tiny does not implement this method");return;}// 解析uriparse_uri(uri, hostname, path, &port);strncpy(url, hostname, MAXLINE);strncat(url, path, MAXLINE);if (reader(fd, url)) {Close(fd);return 1;}// 缓存未命中------char port_str[10];sprintf(port_str, "%d", port);// 代理作为客户端,连接目标服务器real_server_fd = Open_clientfd(hostname, port_str);Rio_readinitb(&rio_server, real_server_fd); // 初始化riochar new_request[MAXLINE];sprintf(new_request, "GET %s HTTP/1.0\r\n", path);build_request(&rio_client, new_request, hostname, port_str);// 向目标服务器发送http报文Rio_writen(real_server_fd, new_request, strlen(new_request));int char_nums;// 从目标服务器读到的数据直接发送给客户端int len = 0;content_tmp[0] = '\0';while ((char_nums = Rio_readlineb(&rio_server, buf, MAXLINE))) {len += char_nums;if (len <= MAX_OBJECT_SIZE) strncat(content_tmp, buf, char_nums);Rio_writen(fd, buf, char_nums);}if (len <= MAX_OBJECT_SIZE) {writer(url, content_tmp);}Close(fd); //--------------------------------------------------------
}void parse_uri(char *uri, char *hostname, char *path, int *port) {*port = 80; // 默认端口char *ptr_hostname = strstr(uri, "//");// http://hostname:port/pathif (ptr_hostname)ptr_hostname += 2; // 绝对urielseptr_hostname = uri; // 相对uri,相对url不包含"http://"或"https://"等协议标识符char *ptr_port = strstr(ptr_hostname, ":");if (ptr_port) {// 字符串ptr_hostname需要以'\0'为结尾标记*ptr_port = '\0';strncpy(hostname, ptr_hostname, MAXLINE);sscanf(ptr_port + 1, "%d%s", port, path);} else { // uri中没有端口号char *ptr_path = strstr(ptr_hostname, "/");if (ptr_path) {strncpy(path, ptr_path, MAXLINE);*ptr_path = '\0';strncpy(hostname, ptr_hostname, MAXLINE);} else {strncpy(hostname, ptr_hostname, MAXLINE);strcpy(path, "");}}
}
void build_request(rio_t *real_client, char *new_request, char *hostname, char *port) {char temp_buf[MAXLINE];// 获取client的请求报文while (Rio_readlineb(real_client, temp_buf, MAXLINE) > 0) {if (strstr(temp_buf, "\r\n")) break; // end// 忽略以下几个字段的信息if (strstr(temp_buf, "Host:")) continue;if (strstr(temp_buf, "User-Agent:")) continue;if (strstr(temp_buf, "Connection:")) continue;if (strstr(temp_buf, "Proxy Connection:")) continue;sprintf(new_request, "%s%s", new_request, temp_buf);printf("%s\n", new_request);fflush(stdout);}sprintf(new_request, "%sHost: %s:%s\r\n", new_request, hostname, port);sprintf(new_request, "%s%s%s%s", new_request, user_agent_hdr, conn_hdr, proxy_hdr);sprintf(new_request, "%s\r\n", new_request);
}
void init() {Sem_init(&mutex_content, 0, 1);Sem_init(&mutex_read_cnt, 0, 1);
}
/* 创建缓存节点 */
struct cache *create_cacheNode(char *url, char *content) {struct cache *node = (struct cache *)malloc(sizeof(struct cache));int len = strlen(url);node->url = (char *)malloc(len * sizeof(char));strncpy(node->url, url, len);len = strlen(content);node->content = (char *)malloc(len * sizeof(char));strncpy(node->content, content, len);node->prev = NULL;node->next = NULL;return node;
}
/* 将节点添加到缓存头部 */
void add_cacheNode(struct cache *node) {node->next = head;node->prev = NULL;if (head != NULL) {head->prev = node;}head = node;if (tail == NULL) {tail = node;}total_size += strlen(node->content) * sizeof(char);
}
/* 删除缓存尾部节点 */
void delete_tail_cacheNode() {if (tail != NULL) {total_size -= strlen(tail->content) * sizeof(char);Free(tail->content);Free(tail->url);struct cache *tmp = tail;tail = tail->prev;Free(tmp);if (tail != NULL) {tail->next = NULL;} else {head = NULL;}}
}
/* 移动缓存节点到头部 */
void move_cacheNode_to_head(struct cache *node) {if (node == head) {return;} else if (node == tail) {tail = tail->prev;tail->next = NULL;} else {node->prev->next = node->next;node->next->prev = node->prev;}node->prev = NULL;node->next = head;head->prev = node;head = node;
}
/* 获取缓存数据 */
char *get_cacheData(char *url) {struct cache *node = head;while (node != NULL) {if (strcmp(node->url, url) == 0) {move_cacheNode_to_head(node);return node->content;}node = node->next;}return NULL;
}int reader(int fd, char *url) {int find = 0;P(&mutex_read_cnt);readcnt++;if (readcnt == 1) // first inP(&mutex_content);V(&mutex_read_cnt);char *content = get_cacheData(url);if (content) { // 命中Rio_writen(fd, content, strlen(content));find = 1;}P(&mutex_read_cnt);readcnt--;if (readcnt == 0) // last outV(&mutex_content);V(&mutex_read_cnt);return find;
}
void writer(char *url, char *content) {P(&mutex_content);while (total_size + strlen(content) * sizeof(char) > MAX_CACHE_SIZE) {delete_tail_cacheNode();}struct cache *node = create_cacheNode(url, content_tmp);add_cacheNode(node);V(&mutex_content);
}
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg) {char buf[MAXLINE];/* Print the HTTP response headers */sprintf(buf, "HTTP/1.0 %s %s\r\n", errnum, shortmsg);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "Content-type: text/html\r\n\r\n");Rio_writen(fd, buf, strlen(buf));/* Print the HTTP response body */sprintf(buf, "<html><title>Tiny Error</title>");Rio_writen(fd, buf, strlen(buf));sprintf(buf,"<body bgcolor=""ffffff"">\r\n");Rio_writen(fd, buf, strlen(buf));sprintf(buf, "%s: %s\r\n", errnum, shortmsg);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "<p>%s: %s\r\n", longmsg, cause);Rio_writen(fd, buf, strlen(buf));sprintf(buf, "<hr><em>The Tiny Web server</em>\r\n");Rio_writen(fd, buf, strlen(buf));
}总结
测试结果如下,顺利拿下满分。
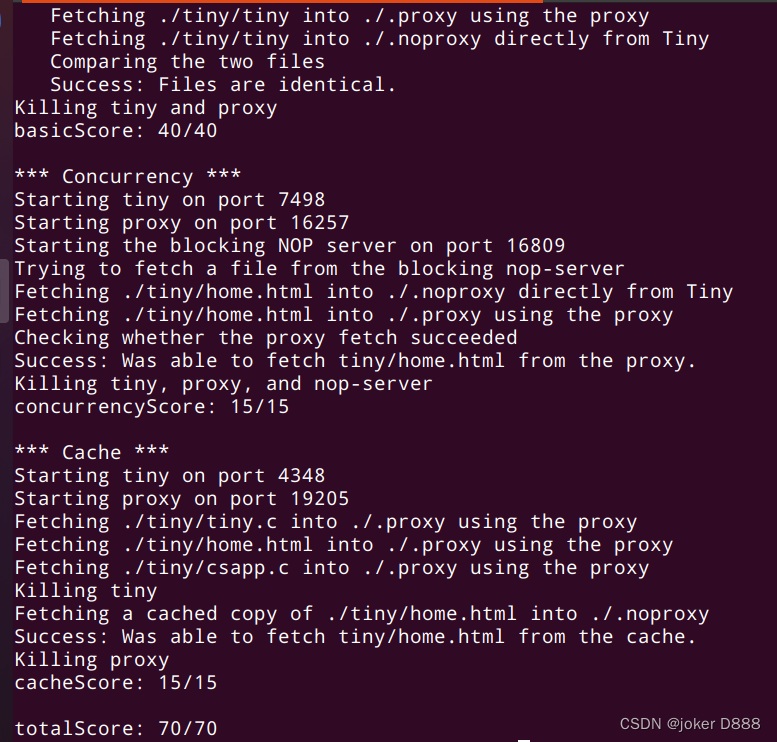
本实验和上一个malloclab实验就不是一个级别的,可以说此实验是很简单的,也就比datalab略难一下。由于本身也有一些web服务器的学习经验,所以做起来还是比较轻松的,但此实验无疑新手练习多线程和并发的好实验。
至此CSAPP的最后一个lab也完成了,一共8个,除开malloclab得了98分外,其他7个实验均拿下满分。全部lab见这里。
相关文章:
Proxy lab
CSAPP Proxy Lab 本实验需要实现一个web代理服务器,实现逐步从迭代到并发,到最终的具有缓存功能的并发代理服务器。 Web 代理是充当 Web 浏览器和终端服务器之间的中间人的程序。浏览器不是直接联系终端服务器获取网页,而是联系代理&#x…...

【机器学习】Sklearn 集成学习-投票分类器(VoteClassifier)
前言 在【机器学习】集成学习基础概念介绍中有提到过,集成学习的结合策略包括: 平均法、投票法和学习法。sklearn.ensemble库中的包含投票分类器(Voting Classifier) 和投票回归器(Voting Regressor),分别对回归任务和分类任务的…...

Day892.MySql读写分离过期读问题 -MySQL实战
MySql读写分离过期读问题 Hi,我是阿昌,今天学习记录的是关于MySql读写分离过期读问题的内容。 一主多从架构的应用场景:读写分离,以及怎么处理主备延迟导致的读写分离问题。 一主多从的结构,其实就是读写分离的基本…...

无线蓝牙耳机哪个品牌音质好?性价比高音质好的蓝牙耳机排行榜
其实蓝牙耳机购买者最担忧的就是音质问题,怕拿到手的蓝牙耳机低频过重又闷又糊,听歌闷耳的问题,但从2021年蓝牙技术开始突飞猛进后,蓝牙耳机的音质、连接甚至是功能都发生了很大的变化,下面我分享几款性价比高音质的蓝…...
店铺微信公众号怎么创建?
有些小伙伴问店铺微信公众号怎么创建,在解答这个问题之前,先简单说说店铺和微信公众号关系: 店铺一般是指小程序店铺,商家通过小程序店铺来卖货;微信公众号则是一个发布信息的平台。但是两者之间可以打通,…...

goLang Mutex用法案例详解
Golang以其并发性Goroutines而闻名。不仅是并发,还有更多。 因此,在这种情况下,我们必须确保多个goroutines不应该同时试图修改资源,从而导致冲突。 为了确保资源一次只能被一个goroutine访问,我们可以使用一个叫做sync.Mutex的东西。 This concept is called mutual ex…...

java常见的异常
异常分类 Throwable 是java异常的顶级类,所有异常都继承于这个类。 Error,Exception是异常类的两个大分类。 Error Error是非程序异常,即程序不能捕获的异常,一般是编译或者系统性的错误,如OutOfMemorry内存溢出异常等。 Exc…...

从0开始学python -33
Python3 输入和输出 -1 在前面几个章节中,我们其实已经接触了 Python 的输入输出的功能。本章节我们将具体介绍 Python 的输入输出。 — 输出格式美化 Python两种输出值的方式: 表达式语句和 print() 函数。 第三种方式是使用文件对象的 write() 方法ÿ…...

ModuleNotFoundError: No module named ‘glfw‘ 解决方案
错误描述 env gym.make(env_id) File "/opt/conda/envs/WNPG/lib/python3.8/site-packages/gym/envs/registration.py", line 619, in make env_creator load(spec_.entry_point) File "/opt/conda/envs/WNPG/lib/python3.8/site-packages/gym/envs/r…...

RadZen运行和部署,生成业务web应用程序
RadZen运行和部署,生成业务web应用程序 快速简单地生成业务web应用程序,可视化地构建和启动web程序,而我们为您创建新代码。 从信息开始 连接到数据库。Radzen推断您的信息并生成一个功能完备的web应用程序。支持MSSQL REST服务。 微调 添加页面或编辑生…...
分享7个比B站更刺激的老司机网站,别轻易点开
俗话说摸鱼一时爽,一直摸一直爽,作为一个程序员老司机了,一头乌黑浓密的头发还时不时被同事调侃,就靠这10个网站让我健康生活,不建议经常性使用,因为还有一句俗话,那就是“摸鱼一时爽࿰…...

浅析:如何在Vue3+Vite中使用JSX
目录 0. Vue3,Vite,JSX 三者的关系 JSX介绍 在 Vue3 中使用 JSX 安装插件(vitejs/plugin-vue-jsx) 新建 jsx 文件 语法 补充知识:注意事项 0. Vue3,Vite,JSX 三者的关系 Vue3、Vite 和 …...

开发小程序需要什么技术?
小程序是一种新的开发能力,相比于原生APP 开发周期短,开发者可以快速地开发一个小程序。小程序可以在微信内被便捷地获取和传播,同时具有出色的使用体验。 开发小程序需要什么技术? 前端技术基础:html、js、css。具体到小程序&a…...

7个营销人员常见的社交媒体问题以及解决方法
在如今的数字营销时代,许多营销人员都害怕在社交媒体上犯错。他们担心他们的社交媒体中的失误会演变成一场公关危机。面对一些常见的社交媒体问题,您需要知道如何避免和解决。对于数字营销人员来说,在现在这个信息互通,每时每刻都…...

BFC 是什么
在页面布局的时候,经常出现以下情况: 这个元素高度怎么没了?这两栏布局怎么没法自适应?这两个元素的间距怎么有点奇怪的样子?...... 原因是元素之间相互的影响,导致了意料之外的情况,这里就涉及…...
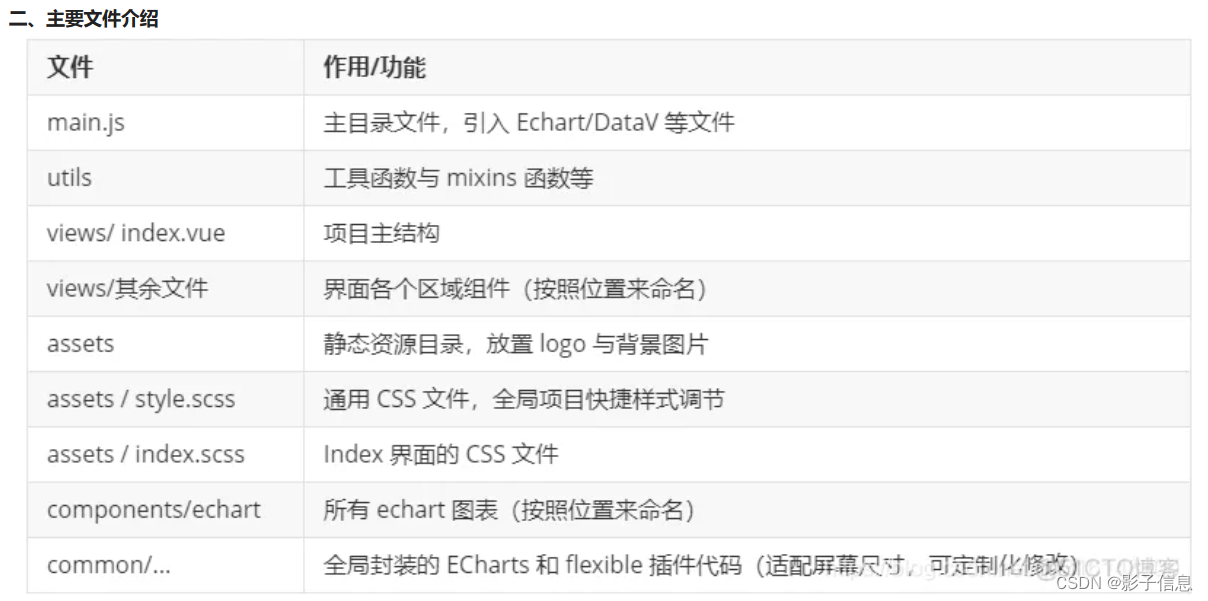
07 react+echart+大屏
reactechart大屏大屏ECharts 图表实际步骤React Typescript搭建大屏项目,并实现屏幕适配flexible rem实现适配1. 安装插件对echarts进行的React封装,可以用于React项目中,支持JS、TS如何使用完整例子官网参考大屏 ECharts 图表 ECharts 图…...
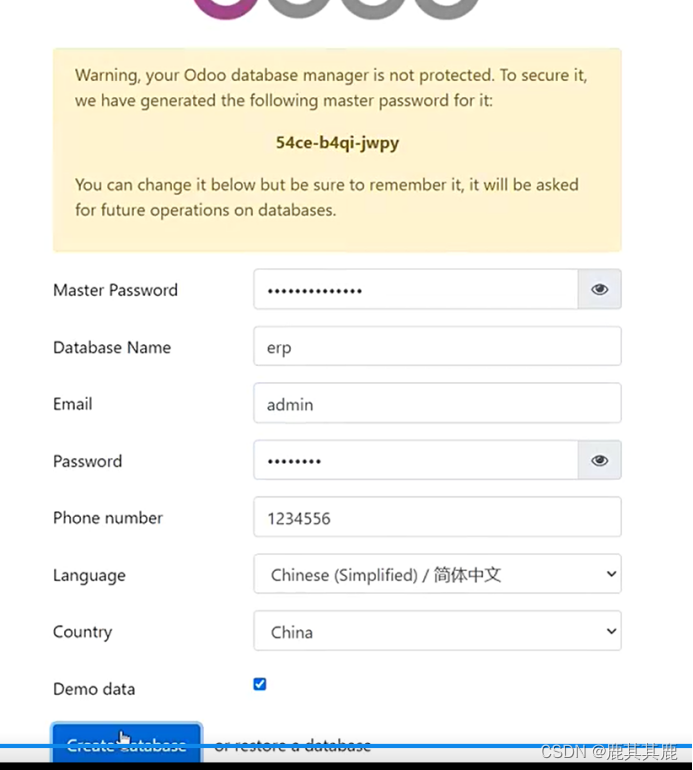
Linux/Ubuntu安装部署Odoo15仓管系统,只需不到十步---史上最成功
sudo apt-get update sudo apt install postgresql -y sudo apt-get -f install sudo dpkg -i /home/ubuntu/odoo_15.0.latest_all.deb —报错再次执行上一条命令再执行 —安装包地址:http://nightly.odoo.com/15.0/nightly/deb/–翻到最下面 sudo apt-get ins…...

Python奇异值分解
当AAA是方阵时,可以很容易地进行特征分解:AWΣW−1AW\Sigma W^{-1}AWΣW−1,其中Σ\SigmaΣ是AAA的特征值组成的对角矩阵。如果WWW由标准正交基组成,则W−1WTW^{-1}W^TW−1WT,特征分解可进一步写成WTΣWW^T\Sigma WWTΣ…...
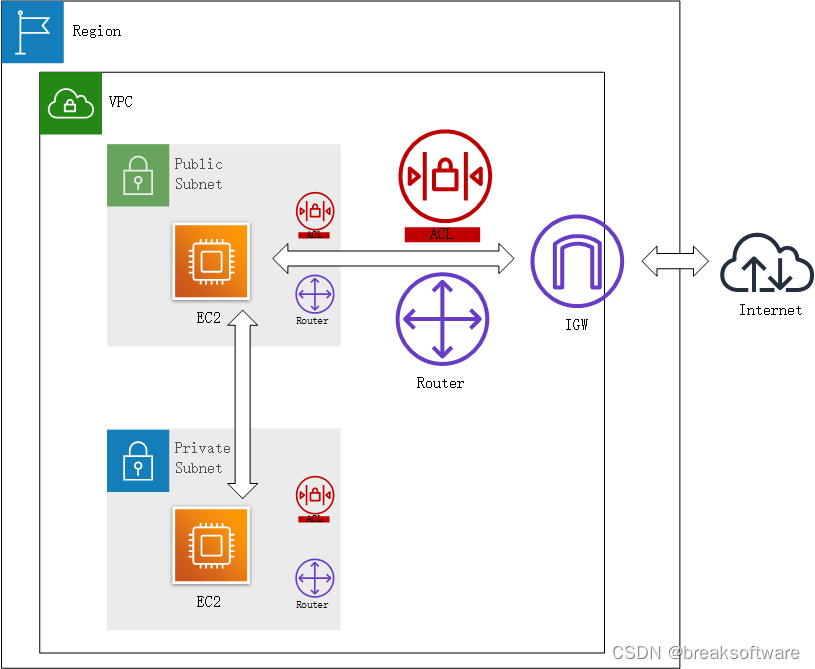
AWS攻略——子网
文章目录分配子网给Public子网分配互联网网关创建互联网网关附加到VPC给Public子网创建路由表关联子网打通Public子网和互联网网关创建Public子网下的EC2进行测试配置Private子网路由给Private子网创建路由表附加在Private子网创建Private子网下的EC2进行测试创建实例在跳板机上…...

java面试 - mq
RocketMq和RabbitMq的优缺点 1、RabbitMQ 优点:rabbitMq 几万级数据量,基于erlang语言开发,因此响应速度快些,并且社区活跃度比较活跃,可视化界面。 缺点:数据吞吐量相对与小一些,并且是基于er…...

FPGA高生产力设计:从RTL到C语言的演进与实践
1. 现代FPGA设计方法论的演进背景 在当今的电子系统设计中,FPGA因其可重构性和并行处理能力,已成为视频处理、无线通信、数据中心加速等领域的核心器件。但随着工艺节点不断进步,现代FPGA的容量已突破百万逻辑单元级别,传统RTL&am…...

无线充电技术:从手机标配到多场景应用的挑战与机遇
1. 无线充电市场现状:繁荣表象下的应用困境手机无线充电,现在几乎成了旗舰机的标配。从咖啡馆、机场到汽车中控台,充电垫的身影随处可见。作为一名在电源管理和消费电子领域摸爬滚打了十几年的工程师,我亲眼见证了Qi标准从实验室走…...

软件设计原则之OCP开闭原则
(OCP) 开闭原则 Open Closed Principle核心原则对扩展开放,对修改关闭。场景描述还是拿 UserInfo 进行举例。在开发过程中我们需要对我们使用的对象进行多步的组合操作,比如这里要打印账户和密码信息。常规的方式就是在外部直接进行调用,或者…...

【STM32F407 DSP实战】矩阵运算基础:从初始化到加减法与求逆的嵌入式实现
1. 为什么要在STM32F407上实现矩阵运算 在嵌入式开发中,矩阵运算可以说是无处不在。从简单的PID控制到复杂的图像处理算法,都离不开矩阵这个基础数据结构。就拿我最近做的一个四轴飞行器项目来说,姿态解算部分就需要频繁地进行矩阵乘法、求逆…...

为什么电路中的阻抗需要引入复数?
1、方便计算说法▼无他,就是图个方便计算而已。请看下题,求如图所示电路中电流的大小。电流的频率与电压频率相同,无非就是求解幅值的变化和相位的变化。▼引用一下以前我的一个知乎回答,数学中的数先是从一维数轴开始。▼因电路的…...

时序逻辑与值函数分解在强化学习中的应用
1. 时序逻辑与值函数分解的核心原理 时序逻辑(Temporal Logic, TL)作为形式化方法的重要分支,其本质是通过数学语言描述系统在时间维度上的行为约束。在控制理论与强化学习领域,TL的价值在于将复杂的任务需求转化为可计算的优化目…...

构建可信AI系统:从黑箱到透明决策的工程实践
1. 项目概述:当AI开始“思考”自己是谁最近和几个做AI安全的朋友聊天,大家不约而同地提到了一个越来越棘手的问题:我们怎么知道一个AI系统在“想”什么?或者说,我们怎么判断它给出的答案、做出的决策,是“可…...
)
SITS 2026发布12项技术白皮书+7套开源工具链:附CSDN认证工程师亲测部署清单(含GitHub直达链接)
更多请点击: https://intelliparadigm.com 第一章:CSDN主办SITS 2026:2026奇点智能技术大会亮点全解析 SITS 2026(Singularity Intelligence Technology Summit)由CSDN联合中国人工智能学会、中科院自动化所共同主办&…...

从磁带机到物联网:LRC纵向冗余校验的‘复古’算法,为何今天还在用?
从磁带机到物联网:LRC纵向冗余校验的‘复古’算法为何历久弥新 在工业自动化控制柜里,一组Modbus ASCII协议的数据帧正通过RS-485总线传输。帧尾的E2校验码看似简单,却承载着从1960年代磁带存储时代延续至今的设计智慧。当工程师在调试终端看…...

通过 Python 快速将你的应用接入 Taotoken 支持的多种大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 Python 快速将你的应用接入 Taotoken 支持的多种大模型 如果你正在使用 Python 开发基于大语言模型的应用,并且希…...