记一次Oracle归档日志异常增长问题的排查过程
Oracle归档日志是Oracle数据库的重要功能,用于将数据库的重做日志文件(Redo Log)保存到归档日志文件(Archive Log)中。归档日志的作用是提供数据库的备份和恢复功能,以及支持数据库的持续性和数据完整性。
当数据库处于归档模式时,数据库引擎会将已经写满的重做日志文件保存到归档日志文件中,而不是覆盖已有的重做日志。这样可以确保数据库的完整性,并且可以使用归档日志文件进行数据库的恢复操作。
归档日志对于数据库的备份和恢复非常重要。通过定期备份归档日志文件,可以保证数据库在发生故障时能够进行恢复。同时,归档日志还允许将数据库恢复到特定的时间点,以满足特定业务需求。
基础操作
在Oracle数据库中,可以通过以下步骤来设置和查看归档日志空间:
- 首先,确认数据库是否处于归档模式。可以通过以下SQL语句查询:
SQL> SELECT log_mode FROM v$database;
LOG_MODEARCHIVELOG
如果log_mode的值为ARCHIVELOG,则数据库处于归档模式;如果值为NOARCHIVELOG,则数据库未启用归档模式。
- 如果数据库未启用归档模式,可以通过以下SQL语句将其切换到归档模式:
修改归档模式的操作只能在 mount 状态下进行,不能处于 open 状态
SQL> shutdown immediate
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 3290345472 bytes
Fixed Size 2180224 bytes
Variable Size 2382367616 bytes
Database Buffers 889192448 bytes
Redo Buffers 16605184 bytes
数据库装载完毕。
SQL> alter database archivelog;
数据库已更改。
SQL> alter database open;
数据库已更改。
- 确认数据库已切换到归档模式后,可以设置归档日志空间的大小。可以通过以下SQL语句设置归档日志空间的大小为50MB(根据需求进行调整):
52428800 = 50 * 1024 * 1024
SQL> alter system set db_recovery_file_dest_size= 52428800;
系统已更改。
- 使用以下SQL语句查询当前归档日志空间的使用情况:
select name,space_limit / 1024 / 1024 / 1024 || 'GB' as 空间限制,space_used / 1024 / 1024 / 1024 || 'GB' 已使用from v$recovery_file_dest
这将显示归档日志目标的名称、空间限制和已使用的空间。
问题发生
下面进入对一次因归档日志空间占满,导致系统停止服务的故障在某个阳光明媚的周末发生后的处理过程。
- 系统停止响应,数据库登录有以下提示:
ORA-00257:archiver error. Connect internal only,until freed
- 很明显,归档日志满了,立即删除归档日志,保留最近3天。
rman
RMAN> connect target 用户名/密码;
连接到目标数据库: ORCL (DBID=1616110362)
RMAN> delete archivelog until time 'sysdate-3';
- 问题未解决,查看归档空间占用情况。
select name,space_limit / 1024 / 1024 / 1024 || 'GB' as 空间限制,space_used / 1024 / 1024 / 1024 || 'GB' 已使用from v$recovery_file_dest
- 发现占用空间未释放,接着删除所有归档:
RMAN> delete archivelog all;
- 系统恢复。过了几个小时,问题再次发生。
- 再次删除所有归档日志,系统恢复,开始排查问题原因。
排查过程
- 按天统计
select to_char(COMPLETION_TIME, 'yyyymmdd'), count(*)from v$archived_log twhere COMPLETION_TIME > sysdate - 7group by to_char(COMPLETION_TIME, 'yyyymmdd')order by to_char(COMPLETION_TIME, 'yyyymmdd');
这是一个查询语句,用于查询过去7天内完成的归档日志数量,并按照日期进行分组和排序。
发现前6天正常,当天归档日志异常增长。
2. 按小时统计
select to_char(FIRST_TIME, 'yyyymmddhh24'), count(*)from sys.v_$archived_log twhere t.FIRST_TIME > trunc(sysdate)group by to_char(FIRST_TIME, 'yyyymmddhh24')order by to_char(FIRST_TIME, 'yyyymmddhh24')
该SQL用于查询当天开始的归档日志数量,并按照小时进行分组和排序。
3. 按天和小时综合统计
SELECT TO_CHAR(FIRST_TIME,'YYYY-MM-DD') DAY,TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'00',1,0)),'999') "00",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'01',1,0)),'999') "01",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'02',1,0)),'999') "02",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'03',1,0)),'999') "03",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'04',1,0)),'999') "04",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'05',1,0)),'999') "05",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'06',1,0)),'999') "06",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'07',1,0)),'999') "07",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'08',1,0)),'999') "08",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'09',1,0)),'999') "09",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'10',1,0)),'999') "10",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'11',1,0)),'999') "11",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'12',1,0)),'999') "12",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'13',1,0)),'999') "13",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'14',1,0)),'999') "14",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'15',1,0)),'999') "15",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'16',1,0)),'999') "16",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'17',1,0)),'999') "17",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'18',1,0)),'999') "18",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'19',1,0)),'999') "19",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'20',1,0)),'999') "20",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'21',1,0)),'999') "21",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'22',1,0)),'999') "22",TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'23',1,0)),'999') "23"
FROM V$LOG_HISTORY
GROUP BY TO_CHAR(FIRST_TIME,'YYYY-MM-DD')
ORDER BY 1 DESC;
此SQL语句,用于统计每天每个小时的日志数量,并按照日期倒序排序
3. 根据按小时统计分析,发现归档日志集中在当天2个时间段,其他时间段基本正常。怀疑是在相关时间自动执行的后台任务造成,经深入排查予以否认。
4. AWR报告生成
sqlplus /nolog
conn / as sysdba
@?/rdbms/admin/awrrpt.sql
报告生成失败,原因是没有快照(Snap)
5. 分析没有快照(Snap)原因,网上说一般是SYSAUX表空间不足造成的,查询表空间占用情况,果然满了
6. 清理表空间
select distinct 'truncate table ' || segment_name || ';',s.bytes / 1024 / 1024 MBfrom dba_segments swhere s.segment_name like 'WRH$%'and segment_type in ('TABLE PARTITION', 'TABLE')and s.bytes / 1024 / 1024 > 100order by s.bytes / 1024 / 1024 desc;
此SQL可生成清理以 ‘WRH$’ 开头的、大于100MB的表的SQL。生成后执行,完成表空间清理。
- 问题解决,真是阴差阳错。
猜测的原因:
因SYSAUX表空间满,造成连锁反应,表现为归档日志异常增长。
一般情况分析
归档日志增长一般是DML操作大量数据造成的,而由SYSAUX表空间满的原因所造成的则比较少见,故记之。
排查归档日志暴增的方法,一般包括以下三个手段:
- SQL语句
- AWR
- 挖掘归档日志
本文到此结束,感谢您的观看!!!
相关文章:

记一次Oracle归档日志异常增长问题的排查过程
Oracle归档日志是Oracle数据库的重要功能,用于将数据库的重做日志文件(Redo Log)保存到归档日志文件(Archive Log)中。归档日志的作用是提供数据库的备份和恢复功能,以及支持数据库的持续性和数据完整性。 …...

Java设计模式——类之间的关系
1.继承关系(泛化) 类与子类的关系,指一个类继承另外的一个类。 2.实现关系 一个类可以实现多个接口,实现所有接口的功能。 3.依赖关系 类B作为类A方法中的局部变量或者参数出现,表示A依赖B。 4.关联关系 类B作为类A中的成员变量出现&#…...

Dockerfile构建Redis镜像
建立工作目录 [rootlocalhost ~]# mkdir redis [rootlocalhost ~]# cd redis/ 编写Dockerfile文件 [rootlocalhost redis]# vim Dockerfile FROM centos:7 MAINTAINER dddd <dddd163.com> RUN yum -y install epel-release && yum -y install redis RUN sed -i …...
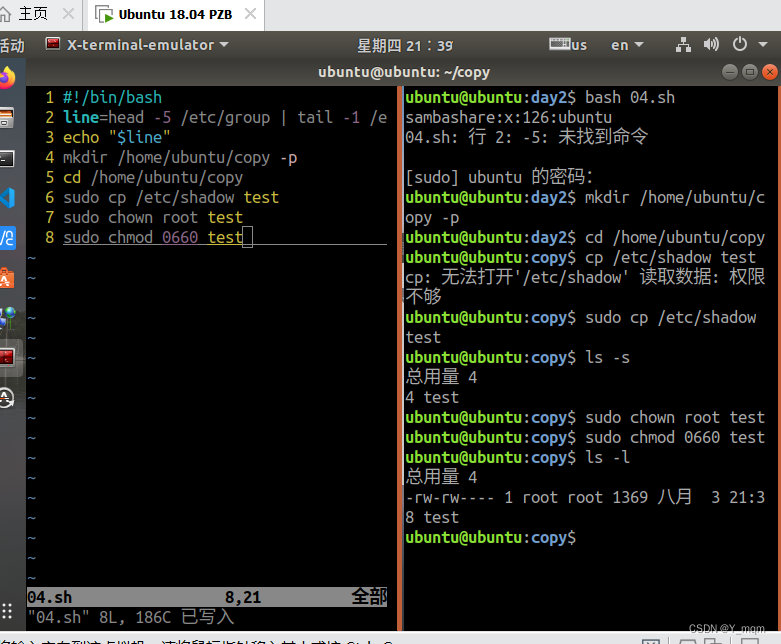
C高级DAY2
1.思维导图 2. 递归实现,输入一个数,输出这个数的每一位 递归实现,输入一个数,输出这个数的二进制c 写一个脚本,包含以下内容: 显示/etc/group文件中第五行的内容创建目录/home/ubuntu/copy切换工作路径到…...

Linux 服务管理
在Linux上,服务管理是指对系统中运行的服务进行启动、停止、重启、监控和配置的过程。以下是一些常用的Linux服务管理工具和命令: 1. systemctl:systemctl 是一个Linux系统服务管理工具,可以管理Systemd初始化系统的服务。常见的…...

问题记录 1 页面初始化触发el-form必填校验
bug: 先编辑table某条数据,然后关闭,再去新增的时候就会触发el-form必填校验, 网上搜了一下是因为 rules里触发的方式为change时,赋值数据的格式不一致导致触发校验, 最后也没找到正确的解决方法, 只能用很low方式去解决了 方案1. 把trigger改为 blur 失焦后触发 方案2. 初始化…...
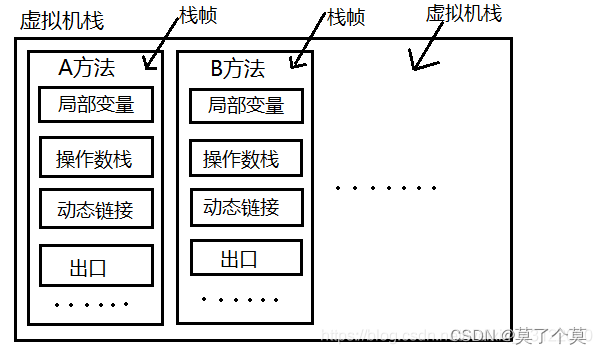
后端整理(JVM、Redis、反射)
1. JVM 文章仅为自身笔记 详情查看一篇文章掌握整个JVM,JVM超详细解析!!! 1.1 什么是JVM jvm是Java虚拟机 1.2 Java文件的编译过程 程序员编写代码形成.java文件经过javac编译成.class文件再通过JVM的类加载器进入运行时数据…...

1. CUDA中的grid和block
1. CUDA中的grid和block基本的理解 Kernel: Kernel不是CPU,而是在GPU上运行的特殊函数。你可以把Kernel想象成GPU上并行执行的任务。当你从主机(CPU)调用Kernel时,它在GPU上启动,并在许多线程上并行运行。 Grid: 当你…...

宝存科技企业级固态硬盘解决方案助力企业应用性能提升
企业级固态硬盘解决方案的核心 企业级固态硬盘市场具有产品附加值高、同时进入门槛高的特征,由于国内外巨头和初创企业竞争依然激烈。想要在竞争中脱颖而出,根本还是要靠产品本身的品质和厂商实力。 企业级固态硬盘适用于各类企业应用场景 企业级固态硬盘…...

《练习100》31~35
题目31 # press any key to change color,do you want to try it. Please hurry up!# 第一种使用颜色配置输出 # 向终端输出彩色字符,色彩的设置由目标终端文字系统和转义字符控制,与具体的编程语言无关 # 参数名称 参数值 # 文字效果 0:终端…...

额外题目第4天|132 673 841 127 684 657
132 我发现困难题往往是在中等题的基础上再多了一步 分割最少次数的回文子串 这道题就是在之前动态规划法找回文子串 (leetcode第5题) 的基础上更多 这题还是用动规来写 思路参考代码随想录 dp数组表示的意义是从0到i最少切割的次数 递推公式是 取0到i中间值 j 如果从 j1到…...

HTTP 状态码的分类和含义
HTTP(Hypertext Transfer Protocol)状态码是由服务器向客户端传输的 HTTP 响应中的一个三位数字代码。它们提供了关于请求的处理状态和结果的信息。以下是一些常见的 HTTP 状态码及其含义: 1xx 信息响应:指示服务器已收到请求&…...
)
Linux Bridge(网桥)
Linux Bridge简介 Linux Bridge(Linux网桥)是一个软件层面的网络设备,用于在Linux系统中创建和管理网络桥接。它允许将多个物理或虚拟网络接口连接在一起,以创建一个共享相同网络段的网络。 下面是Linux Bridge的一些关键特点和…...

【数据结构】优先队列
优先队列 API初级实现使用堆实现由下至上的堆有序化(上浮)由上至下的堆有序化(下沉)插入和删除元素具体实现 很多情况下我们需要有序的处理输入的元素,但是又不需要输入的元素全部有序,或者不需要一次将它们…...

如何在 Ubuntu 22.04 下编译 StoneDB for MySQL 8.0 | StoneDB 使用教程 #1
作者:双飞(花名:小鱼) 杭州电子科技大学在读硕士 StoneDB 内核研发实习生 ❝ 大家好,我是 StoneDB 的实习生小鱼,目前正在做 StoneDB 8.0 内核升级相关的一些事情。刚开始接触数据库开发没多久,…...

AMEYA360:尼得科科宝旋转型DIP开关系列汇总
旋转型DIP开关 S-4000 电路:BCD(十进制) 代码格式:实码 安装类型:表面贴装 调整位置:顶部 可水洗:无 端子类型:J 引线, 鸥翼型 旋转型DIP开关 SA-7000 电路:BCD(十进制), BCH(十六进制) 代码格式…...
为什么感觉 C/C++ 不火了?
首先C和C是两个非常不一样的编程语言。 C语言在系统开发领域地位非常稳固,几乎没有替代产品。应用层开发近年来略微有被Rust取代的迹象。 C由于支持的编程范式过多,导致不同水平的人写出来的代码质量差异太大,这给软件的稳健性带来了很大的…...

【Linux】在服务器上创建Crontab(定时任务),自动执行shell脚本
业务场景:该文即为上次编写shell脚本的姊妹篇,在上文基础上,将可执行的脚本通过linux的定时任务自动执行,节省人力物力,话不多说,开始操作! 一、打开我们的服务器连接工具 连上服务器后,在任意位置都可以执行:crontab -e 如果没有进入编辑cron任务模式 根据提示查看…...
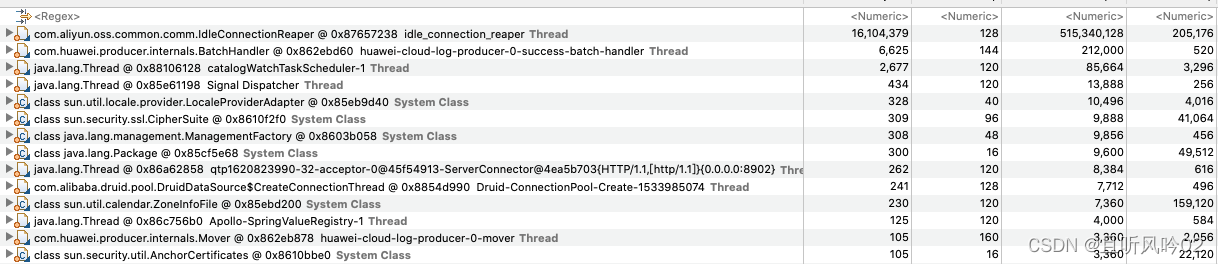
内存分析工具之Mat
自定义类MatClazz内存个数为9521。当前对象占用内存为16个字节。不包括其属性bytes的字节数。 通过查看MatClazz引用的类之byte数组之bytes。其单个数组占用的字节数为10256。整个内存MatClazz中属性bytes占用的byte[]字节数为97746376,与直方图统计趋近。 通过选…...

【逗老师的PMP学习笔记】项目的运行环境
一、影响项目运行的因素 主要分两种因素 事业环境因素(更多的是制约和限制因素)组织过程资产(可以借鉴的经验和知识) 1、细说事业环境因素(更多的是制约和限制因素) 资源可用性 例如包括合同和采购制约…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...