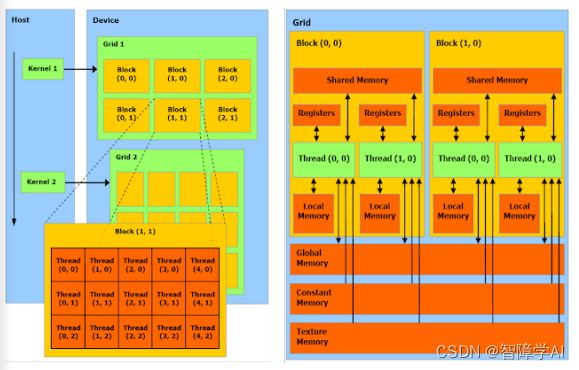
1. CUDA中的grid和block
1. CUDA中的grid和block基本的理解
-
Kernel: Kernel不是CPU,而是在GPU上运行的特殊函数。你可以把Kernel想象成GPU上并行执行的任务。当你从主机(CPU)调用Kernel时,它在GPU上启动,并在许多线程上并行运行。
-
Grid: 当你启动Kernel时,你会定义一个网格(grid)。网格是一维、二维或三维的,代表了block的集合。
-
Block: 每个block内部包含了许多线程。block也可以是一维、二维或三维的。
-
Thread: 每个线程是Kernel的单个执行实例。在一个block中的所有线程可以共享一些资源,并能够相互通信。
你正确地指出,grid、block和thread这些概念在硬件级别上并没有直接对应的实体,它们是抽象的概念,用于组织和管理GPU上的并行执行。然而,GPU硬件是专门设计来支持这种并行计算模型的,所以虽然线程在物理硬件上可能不是独立存在的,但是它们通过硬件架构和调度机制得到了有效的支持。
另外,对于线程的管理和调度,GPU硬件有特定的线程调度单元,如NVIDIA的warp概念。线程被组织成更小的集合,称为warps(在NVIDIA硬件上),并且这些warps被调度到硬件上以供执行。
所以,虽然这些概念是逻辑和抽象的,但它们与硬件的实际执行密切相关,并由硬件特性和架构直接支持。
一般来说:
• 一个kernel对应一个grid
• 一个grid可以有多个block,一维~三维
• 一个block可以有多个thread,一维~三维
2. 1D traverse
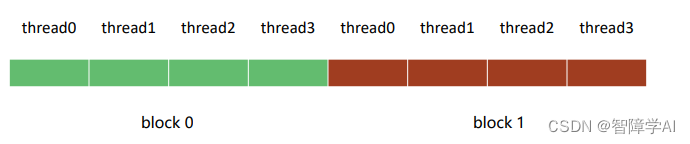
void print_one_dim(){int inputSize = 8;int blockDim = 4;int gridDim = inputSize / blockDim; // 2// 定义block和grid的维度dim3 block(blockDim); // 说明一个block有多少个threadsdim3 grid(gridDim); // 说明一个grid里面有多少个block /* 这里建议大家吧每一函数都试一遍*/print_idx_kernel<<<grid, block>>>();// print_dim_kernel<<<grid, block>>>();// print_thread_idx_per_block_kernel<<<grid, block>>>();// print_thread_idx_per_grid_kernel<<<grid, block>>>();cudaDeviceSynchronize();
}
我觉得重点在这两行
-
dim3 block(blockDim);: 这一行创建了一个三维向量block,用来定义每个block的大小。在这个例子中,blockDim是一个整数值4,所以每个block包含4个线程。dim3数据类型是CUDA中的一个特殊数据类型,用于表示三维向量。在这个情况下,你传递了一个整数值,所以block的其余维度将被默认设置为1。这意味着你将有一个包含4个线程的一维block。 -
dim3 grid(gridDim);: 这一行创建了一个三维向量grid,用来定义grid的大小。gridDim的计算基于输入大小(inputSize)和每个block的大小(blockDim)。在这个例子中,inputSize是8,blockDim是4,所以gridDim会是2。这意味着整个grid将包含2个block。与block一样,你传递了一个整数值给grid,所以其余维度将被默认设置为1,得到一个一维grid。
总体来说,这两行代码定义了内核的执行配置,将整个计算空间划分为2个block,每个block包含4个线程。你可以想象这个配置如下:
- Block 0: 线程0, 线程1, 线程2, 线程3
- Block 1: 线程4, 线程5, 线程6, 线程7
然后,当你调用内核时,这些线程将被用来执行你的代码。每个线程可以通过其线程索引和block索引来访问自己在整个grid中的唯一位置。这些索引用于确定每个线程应处理的数据部分。
block idx: 1, thread idx in block: 0, thread idx: 4
block idx: 1, thread idx in block: 1, thread idx: 5
block idx: 1, thread idx in block: 2, thread idx: 6
block idx: 1, thread idx in block: 3, thread idx: 7
block idx: 0, thread idx in block: 0, thread idx: 0
block idx: 0, thread idx in block: 1, thread idx: 1
block idx: 0, thread idx in block: 2, thread idx: 2
block idx: 0, thread idx in block: 3, thread idx: 3
3. 2D打印
// 8个线程被分成了两个
void print_two_dim(){int inputWidth = 4;int blockDim = 2; int gridDim = inputWidth / blockDim;dim3 block(blockDim, blockDim);dim3 grid(gridDim, gridDim);/* 这里建议大家吧每一函数都试一遍*/// print_idx_kernel<<<grid, block>>>();// print_dim_kernel<<<grid, block>>>();// print_thread_idx_per_block_kernel<<<grid, block>>>();print_thread_idx_per_grid_kernel<<<grid, block>>>();cudaDeviceSynchronize();
}
-
dim3 block(blockDim, blockDim);: 这里创建了一个二维的block,每个维度的大小都是blockDim,在这个例子中是2。因此,每个block都是2x2的,包含4个线程。由于dim3定义了一个三维向量,没有指定的第三维度会默认为1。 -
dim3 grid(gridDim, gridDim);: 同样,grid也被定义为二维的,每个维度的大小都是gridDim。由于inputWidth是4,并且blockDim是2,所以gridDim会是2。因此,整个grid是2x2的,包括4个block。第三维度同样默认为1。
因此,整个执行配置定义了2x2的grid,其中包括4个2x2的block,总共16个线程。你可以将整个grid可视化如下:
-
Block (0,0):
- 线程(0,0), 线程(0,1)
- 线程(1,0), 线程(1,1)
-
Block (0,1):
- 线程(2,0), 线程(2,1)
- 线程(3,0), 线程(3,1)
-
Block (1,0):
- 线程(4,0), 线程(4,1)
- 线程(5,0), 线程(5,1)
-
Block (1,1):
- 线程(6,0), 线程(6,1)
- 线程(7,0), 线程(7,1)
输出中的“block idx”是整个grid中block的线性索引,而“thread idx in block”是block内线程的线性索引。最后的“thread idx”是整个grid中线程的线性索引。
请注意,执行的顺序仍然是不确定的。你看到的输出顺序可能在不同的运行或不同的硬件上有所不同。
block idx: 3, thread idx in block: 0, thread idx: 12
block idx: 3, thread idx in block: 1, thread idx: 13
block idx: 3, thread idx in block: 2, thread idx: 14
block idx: 3, thread idx in block: 3, thread idx: 15
block idx: 2, thread idx in block: 0, thread idx: 8
block idx: 2, thread idx in block: 1, thread idx: 9
block idx: 2, thread idx in block: 2, thread idx: 10
block idx: 2, thread idx in block: 3, thread idx: 11
block idx: 1, thread idx in block: 0, thread idx: 4
block idx: 1, thread idx in block: 1, thread idx: 5
block idx: 1, thread idx in block: 2, thread idx: 6
block idx: 1, thread idx in block: 3, thread idx: 7
block idx: 0, thread idx in block: 0, thread idx: 0
block idx: 0, thread idx in block: 1, thread idx: 1
block idx: 0, thread idx in block: 2, thread idx: 2
block idx: 0, thread idx in block: 3, thread idx: 3
4. 3D grid
dim3 block(3, 4, 2);
dim3 grid(2, 2, 2);
-
Block布局 (
dim3 block(3, 4, 2)):- 这定义了每个block的大小为3x4x2,所以每个block包含24个线程。
- 你可以将block视为三维数组,其中
x方向有3个元素,y方向有4个元素,z方向有2个元素。
-
Grid布局 (
dim3 grid(2, 2, 2)):- 这定义了grid的大小为2x2x2,所以整个grid包含8个block。
- 你可以将grid视为三维数组,其中
x方向有2个元素,y方向有2个元素,z方向有2个元素。 - 由于每个block包括24个线程,所以整个grid将包括192个线程。
整体布局可以视为8个3x4x2的block,排列为2x2x2的grid。
如果我们想用文字来表示整个结构,可能会是这样的:
- Grid[0][0][0]:
- Block(3, 4, 2) – 24个线程
- Grid[0][0][1]:
- Block(3, 4, 2) – 24个线程
- Grid[0][1][0]:
- Block(3, 4, 2) – 24个线程
- Grid[0][1][1]:
- Block(3, 4, 2) – 24个线程
- Grid[1][0][0]:
- Block(3, 4, 2) – 24个线程
- Grid[1][0][1]:
- Block(3, 4, 2) – 24个线程
- Grid[1][1][0]:
- Block(3, 4, 2) – 24个线程
- Grid[1][1][1]:
- Block(3, 4, 2) – 24个线程
这种三维结构允许在物理空间中进行非常自然的映射,尤其是当你的问题本身就具有三维的特性时。例如,在处理三维物理模拟或体素数据时,这种映射可能非常有用。
5. 通过维度打印出来对应的thread

比较推荐的打印方式
__global__ void print_cord_kernel(){int index = threadIdx.z * blockDim.x * blockDim.y + \threadIdx.y * blockDim.x + \threadIdx.x;int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",blockIdx.z, blockIdx.y, blockIdx.x,index, x, y);
}
index是线程索引的问题,首先,考虑z维度。对于每一层z,都有blockDim.x * blockDim.y个线程。所以threadIdx.z乘以该数量给出了前面层中的线程总数,从图上看也就是越过了多少个方块
然后,考虑y维度。对于每一行y,都有blockDim.x个线程。所以threadIdx.y乘以该数量给出了当前层中前面行的线程数,也就是在当前方块的xy面我们走了几个y, 几行
最后加上thread x完成索引的坐标
void print_cord(){int inputWidth = 4;int blockDim = 2;int gridDim = inputWidth / blockDim;dim3 block(blockDim, blockDim);dim3 grid(gridDim, gridDim);print_cord_kernel<<<grid, block>>>();// print_thread_idx_per_grid_kernel<<<grid, block>>>();cudaDeviceSynchronize();
}
block idx: ( 0, 1, 0), thread idx: 0, cord: ( 0, 2)
block idx: ( 0, 1, 0), thread idx: 1, cord: ( 1, 2)
block idx: ( 0, 1, 0), thread idx: 2, cord: ( 0, 3)
block idx: ( 0, 1, 0), thread idx: 3, cord: ( 1, 3)
block idx: ( 0, 1, 1), thread idx: 0, cord: ( 2, 2)
block idx: ( 0, 1, 1), thread idx: 1, cord: ( 3, 2)
block idx: ( 0, 1, 1), thread idx: 2, cord: ( 2, 3)
block idx: ( 0, 1, 1), thread idx: 3, cord: ( 3, 3)
block idx: ( 0, 0, 1), thread idx: 0, cord: ( 2, 0)
block idx: ( 0, 0, 1), thread idx: 1, cord: ( 3, 0)
block idx: ( 0, 0, 1), thread idx: 2, cord: ( 2, 1)
block idx: ( 0, 0, 1), thread idx: 3, cord: ( 3, 1)
block idx: ( 0, 0, 0), thread idx: 0, cord: ( 0, 0)
block idx: ( 0, 0, 0), thread idx: 1, cord: ( 1, 0)
block idx: ( 0, 0, 0), thread idx: 2, cord: ( 0, 1)
block idx: ( 0, 0, 0), thread idx: 3, cord: ( 1, 1)
跟之前2D的一样, 同样看起来有点乱,是因为是异步执行的
6. 最后看一个多个grid的案例
void print_coordinates() {dim3 block(3, 4, 2);dim3 grid(2, 2, 2);print_cord_kernel<<<grid, block>>>();cudaDeviceSynchronize(); // 确保内核完成后才继续执行主机代码
}
block idx: ( 0, 1, 0), thread idx: 0, cord: ( 0, 4)
block idx: ( 0, 1, 0), thread idx: 1, cord: ( 1, 4)
block idx: ( 0, 1, 0), thread idx: 2, cord: ( 2, 4)
block idx: ( 0, 1, 0), thread idx: 3, cord: ( 0, 5)
block idx: ( 0, 1, 0), thread idx: 4, cord: ( 1, 5)
block idx: ( 0, 1, 0), thread idx: 5, cord: ( 2, 5)
block idx: ( 0, 1, 0), thread idx: 6, cord: ( 0, 6)
block idx: ( 0, 1, 0), thread idx: 7, cord: ( 1, 6)
block idx: ( 0, 1, 0), thread idx: 8, cord: ( 2, 6)
block idx: ( 0, 1, 0), thread idx: 9, cord: ( 0, 7)
block idx: ( 0, 1, 0), thread idx: 10, cord: ( 1, 7)
block idx: ( 0, 1, 0), thread idx: 11, cord: ( 2, 7)
block idx: ( 0, 1, 0), thread idx: 12, cord: ( 0, 4)
block idx: ( 0, 1, 0), thread idx: 13, cord: ( 1, 4)
block idx: ( 0, 1, 0), thread idx: 14, cord: ( 2, 4)
block idx: ( 0, 1, 0), thread idx: 15, cord: ( 0, 5)
block idx: ( 0, 1, 0), thread idx: 16, cord: ( 1, 5)
block idx: ( 0, 1, 0), thread idx: 17, cord: ( 2, 5)
block idx: ( 0, 1, 0), thread idx: 18, cord: ( 0, 6)
block idx: ( 0, 1, 0), thread idx: 19, cord: ( 1, 6)
block idx: ( 0, 1, 0), thread idx: 20, cord: ( 2, 6)
block idx: ( 0, 1, 0), thread idx: 21, cord: ( 0, 7)
block idx: ( 0, 1, 0), thread idx: 22, cord: ( 1, 7)
block idx: ( 0, 1, 0), thread idx: 23, cord: ( 2, 7)
block idx: ( 1, 1, 1), thread idx: 0, cord: ( 3, 4)
block idx: ( 1, 1, 1), thread idx: 1, cord: ( 4, 4)
block idx: ( 1, 1, 1), thread idx: 2, cord: ( 5, 4)
block idx: ( 1, 1, 1), thread idx: 3, cord: ( 3, 5)
block idx: ( 1, 1, 1), thread idx: 4, cord: ( 4, 5)
block idx: ( 1, 1, 1), thread idx: 5, cord: ( 5, 5)
block idx: ( 1, 1, 1), thread idx: 6, cord: ( 3, 6)
block idx: ( 1, 1, 1), thread idx: 7, cord: ( 4, 6)
block idx: ( 1, 1, 1), thread idx: 8, cord: ( 5, 6)
block idx: ( 1, 1, 1), thread idx: 9, cord: ( 3, 7)
block idx: ( 1, 1, 1), thread idx: 10, cord: ( 4, 7)
block idx: ( 1, 1, 1), thread idx: 11, cord: ( 5, 7)
block idx: ( 1, 1, 1), thread idx: 12, cord: ( 3, 4)
block idx: ( 1, 1, 1), thread idx: 13, cord: ( 4, 4)
block idx: ( 1, 1, 1), thread idx: 14, cord: ( 5, 4)
block idx: ( 1, 1, 1), thread idx: 15, cord: ( 3, 5)
block idx: ( 1, 1, 1), thread idx: 16, cord: ( 4, 5)
block idx: ( 1, 1, 1), thread idx: 17, cord: ( 5, 5)
block idx: ( 1, 1, 1), thread idx: 18, cord: ( 3, 6)
block idx: ( 1, 1, 1), thread idx: 19, cord: ( 4, 6)
block idx: ( 1, 1, 1), thread idx: 20, cord: ( 5, 6)
block idx: ( 1, 1, 1), thread idx: 21, cord: ( 3, 7)
block idx: ( 1, 1, 1), thread idx: 22, cord: ( 4, 7)
block idx: ( 1, 1, 1), thread idx: 23, cord: ( 5, 7)
block idx: ( 0, 1, 1), thread idx: 0, cord: ( 3, 4)
block idx: ( 0, 1, 1), thread idx: 1, cord: ( 4, 4)
block idx: ( 0, 1, 1), thread idx: 2, cord: ( 5, 4)
block idx: ( 0, 1, 1), thread idx: 3, cord: ( 3, 5)
block idx: ( 0, 1, 1), thread idx: 4, cord: ( 4, 5)
block idx: ( 0, 1, 1), thread idx: 5, cord: ( 5, 5)
block idx: ( 0, 1, 1), thread idx: 6, cord: ( 3, 6)
block idx: ( 0, 1, 1), thread idx: 7, cord: ( 4, 6)
block idx: ( 0, 1, 1), thread idx: 8, cord: ( 5, 6)
block idx: ( 0, 1, 1), thread idx: 9, cord: ( 3, 7)
block idx: ( 0, 1, 1), thread idx: 10, cord: ( 4, 7)
block idx: ( 0, 1, 1), thread idx: 11, cord: ( 5, 7)
block idx: ( 0, 1, 1), thread idx: 12, cord: ( 3, 4)
block idx: ( 0, 1, 1), thread idx: 13, cord: ( 4, 4)
block idx: ( 0, 1, 1), thread idx: 14, cord: ( 5, 4)
block idx: ( 0, 1, 1), thread idx: 15, cord: ( 3, 5)
block idx: ( 0, 1, 1), thread idx: 16, cord: ( 4, 5)
block idx: ( 0, 1, 1), thread idx: 17, cord: ( 5, 5)
block idx: ( 0, 1, 1), thread idx: 18, cord: ( 3, 6)
block idx: ( 0, 1, 1), thread idx: 19, cord: ( 4, 6)
block idx: ( 0, 1, 1), thread idx: 20, cord: ( 5, 6)
block idx: ( 0, 1, 1), thread idx: 21, cord: ( 3, 7)
block idx: ( 0, 1, 1), thread idx: 22, cord: ( 4, 7)
block idx: ( 0, 1, 1), thread idx: 23, cord: ( 5, 7)
block idx: ( 1, 0, 0), thread idx: 0, cord: ( 0, 0)
block idx: ( 1, 0, 0), thread idx: 1, cord: ( 1, 0)
block idx: ( 1, 0, 0), thread idx: 2, cord: ( 2, 0)
相关文章:
1. CUDA中的grid和block
1. CUDA中的grid和block基本的理解 Kernel: Kernel不是CPU,而是在GPU上运行的特殊函数。你可以把Kernel想象成GPU上并行执行的任务。当你从主机(CPU)调用Kernel时,它在GPU上启动,并在许多线程上并行运行。 Grid: 当你…...

宝存科技企业级固态硬盘解决方案助力企业应用性能提升
企业级固态硬盘解决方案的核心 企业级固态硬盘市场具有产品附加值高、同时进入门槛高的特征,由于国内外巨头和初创企业竞争依然激烈。想要在竞争中脱颖而出,根本还是要靠产品本身的品质和厂商实力。 企业级固态硬盘适用于各类企业应用场景 企业级固态硬盘…...

《练习100》31~35
题目31 # press any key to change color,do you want to try it. Please hurry up!# 第一种使用颜色配置输出 # 向终端输出彩色字符,色彩的设置由目标终端文字系统和转义字符控制,与具体的编程语言无关 # 参数名称 参数值 # 文字效果 0:终端…...

额外题目第4天|132 673 841 127 684 657
132 我发现困难题往往是在中等题的基础上再多了一步 分割最少次数的回文子串 这道题就是在之前动态规划法找回文子串 (leetcode第5题) 的基础上更多 这题还是用动规来写 思路参考代码随想录 dp数组表示的意义是从0到i最少切割的次数 递推公式是 取0到i中间值 j 如果从 j1到…...

HTTP 状态码的分类和含义
HTTP(Hypertext Transfer Protocol)状态码是由服务器向客户端传输的 HTTP 响应中的一个三位数字代码。它们提供了关于请求的处理状态和结果的信息。以下是一些常见的 HTTP 状态码及其含义: 1xx 信息响应:指示服务器已收到请求&…...
)
Linux Bridge(网桥)
Linux Bridge简介 Linux Bridge(Linux网桥)是一个软件层面的网络设备,用于在Linux系统中创建和管理网络桥接。它允许将多个物理或虚拟网络接口连接在一起,以创建一个共享相同网络段的网络。 下面是Linux Bridge的一些关键特点和…...

【数据结构】优先队列
优先队列 API初级实现使用堆实现由下至上的堆有序化(上浮)由上至下的堆有序化(下沉)插入和删除元素具体实现 很多情况下我们需要有序的处理输入的元素,但是又不需要输入的元素全部有序,或者不需要一次将它们…...

如何在 Ubuntu 22.04 下编译 StoneDB for MySQL 8.0 | StoneDB 使用教程 #1
作者:双飞(花名:小鱼) 杭州电子科技大学在读硕士 StoneDB 内核研发实习生 ❝ 大家好,我是 StoneDB 的实习生小鱼,目前正在做 StoneDB 8.0 内核升级相关的一些事情。刚开始接触数据库开发没多久,…...

AMEYA360:尼得科科宝旋转型DIP开关系列汇总
旋转型DIP开关 S-4000 电路:BCD(十进制) 代码格式:实码 安装类型:表面贴装 调整位置:顶部 可水洗:无 端子类型:J 引线, 鸥翼型 旋转型DIP开关 SA-7000 电路:BCD(十进制), BCH(十六进制) 代码格式…...
为什么感觉 C/C++ 不火了?
首先C和C是两个非常不一样的编程语言。 C语言在系统开发领域地位非常稳固,几乎没有替代产品。应用层开发近年来略微有被Rust取代的迹象。 C由于支持的编程范式过多,导致不同水平的人写出来的代码质量差异太大,这给软件的稳健性带来了很大的…...

【Linux】在服务器上创建Crontab(定时任务),自动执行shell脚本
业务场景:该文即为上次编写shell脚本的姊妹篇,在上文基础上,将可执行的脚本通过linux的定时任务自动执行,节省人力物力,话不多说,开始操作! 一、打开我们的服务器连接工具 连上服务器后,在任意位置都可以执行:crontab -e 如果没有进入编辑cron任务模式 根据提示查看…...
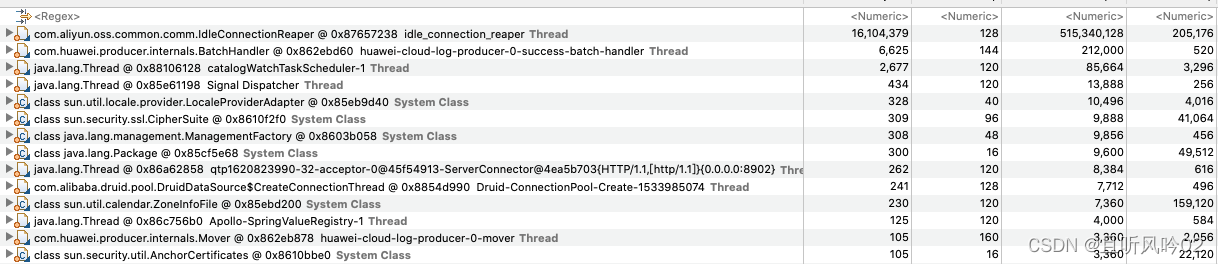
内存分析工具之Mat
自定义类MatClazz内存个数为9521。当前对象占用内存为16个字节。不包括其属性bytes的字节数。 通过查看MatClazz引用的类之byte数组之bytes。其单个数组占用的字节数为10256。整个内存MatClazz中属性bytes占用的byte[]字节数为97746376,与直方图统计趋近。 通过选…...

【逗老师的PMP学习笔记】项目的运行环境
一、影响项目运行的因素 主要分两种因素 事业环境因素(更多的是制约和限制因素)组织过程资产(可以借鉴的经验和知识) 1、细说事业环境因素(更多的是制约和限制因素) 资源可用性 例如包括合同和采购制约…...

Rust- 模块
(1)在项目根目录下创建mylib(里面实现自定义的外部模块) cargo new --lib mylib (2)在 项目名\mylib\src\lib.rs文件中实现新模块 pub mod add_salary {pub fn study(name: String) {println!("Rust…...
【开源源码学习】
C 迷你高尔夫 一款打高尔夫的游戏。亮点是碰撞反应和关卡设计。 GitHub - mgerdes/Open-Golf: A cross-platform minigolf game written in C. TypeScript 俄罗斯方块 复刻经典的俄罗斯方块,项目采用ReactReduxImmutable的技术栈。 GitHub - chvin/react-tetr…...

CNN-NER论文详解
论文:https://arxiv.org/abs/2208.04534 代码:https://github.com/yhcc/CNN_Nested_NER/tree/master 文章目录 有关工作前期介绍CNN-NER模型介绍 代码讲解主类多头biaffineCNNLoss解码数据传入格式 参考资料 有关工作 前期介绍 过去一共主要有四类方式…...

利用ChatGPT制作行业应用:哪些行业最受益
引言 随着人工智能技术的快速发展,ChatGPT(Chat Generative Pre-trained Transformer)成为了一种引人注目的工具,它能够生成自然流畅的对话内容。这种技术不仅在娱乐领域有着广泛的应用,还可以在各个行业中发挥重要作…...

【SA8295P 源码分析】60 - QNX Host 如何新增 android_test 分区给 Android GVM 挂载使用
【SA8295P 源码分析】60 - QNX Host 如何新增 android_test 分区给 Android GVM 挂载使用 一、QNX 侧:创建分区、配置下载、配置透传1.1 修改分区表,新增 android_test 分区,大小为 2GByte1.2 配置下载 android_test.img 镜像1.3 配置 /dev/disk/android_test_a 分区透传到 …...
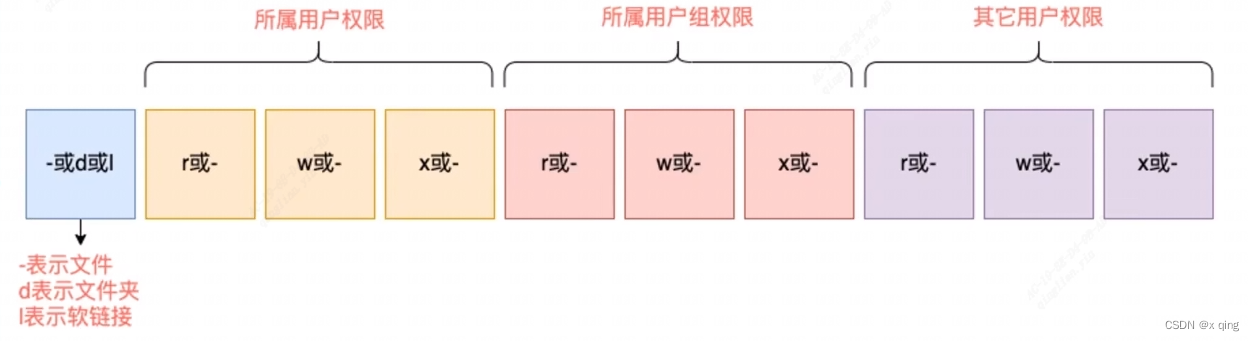
Linux 用户和权限
一、root 用户 root 用户(超级管理员) 无论是windows、Macos、Linux均采用多用户的管理模式进行权限管理。在Linux系统中,拥有最大权限的账户名为:root (超级管理员)。 root用户拥有最大的系统操作权限,而普通用户在许多地方的权限是受限的。…...
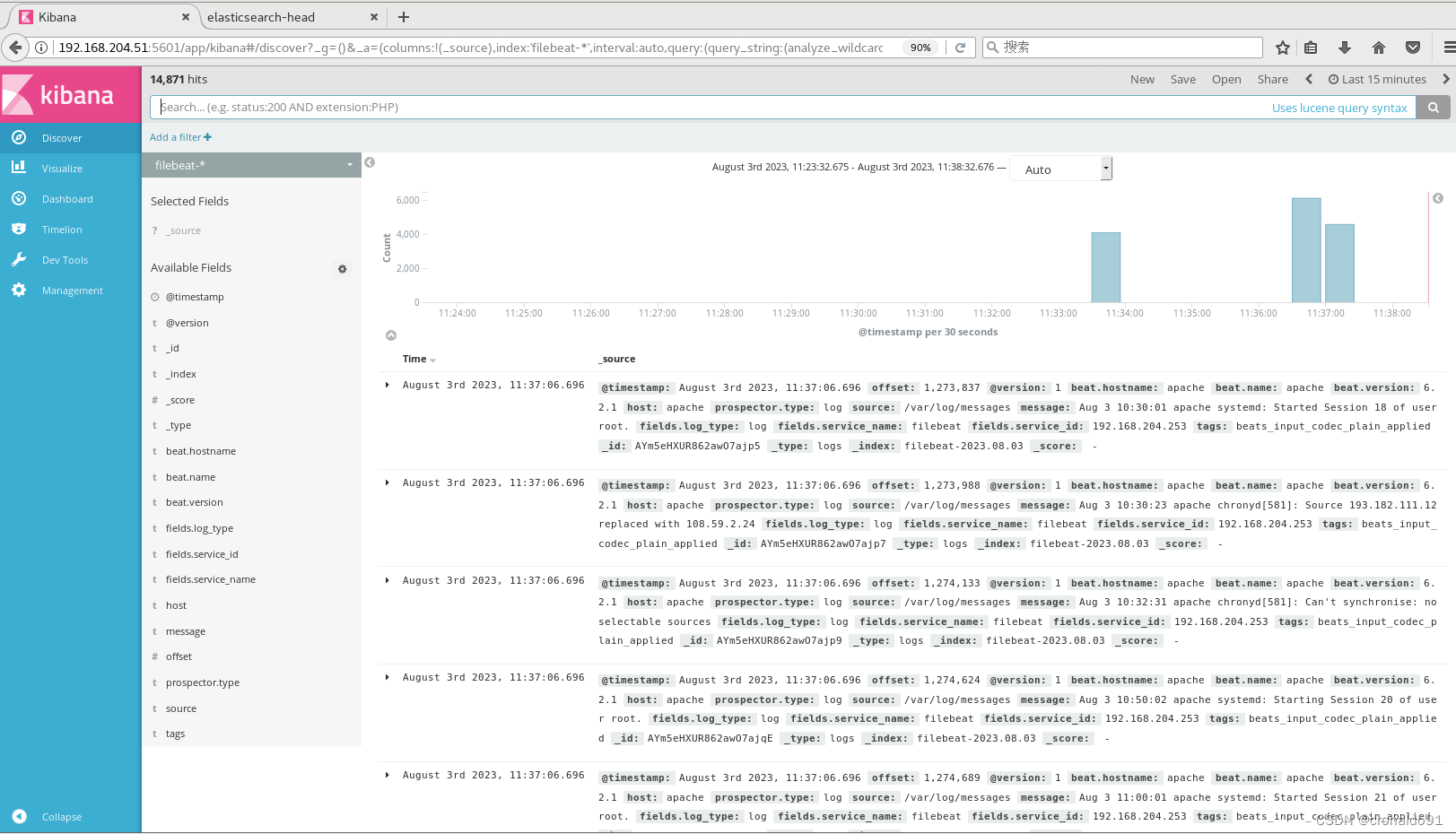
分布式应用:ELFK集群部署
目录 一、理论 1.ELFK集群 2.filebeat 3.部署ELK集群 二、实验 1. ELFK集群部署 三、总结 一、理论 1.ELFK集群 (1)概念 ELFK集群部署(FilebeatELK),ELFK ES logstashfilebeatkibana 。 数据流 架构 2.fi…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

2026论文降AI怎么挑?亲测好用工具附免费降AI指南
“您的论文AIGC率为42%,超出学校30%的合格线,请修改后重新提交。”赶毕业论文的同学这段时间估计没少收到这样的提醒。2026年知网、万方、维普等主流平台的AI检测算法持续迭代,把AI生成内容改到符合学校要求,已经成了毕业生的刚需…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...