CNN-NER论文详解
论文:https://arxiv.org/abs/2208.04534
代码:https://github.com/yhcc/CNN_Nested_NER/tree/master
文章目录
- 有关工作
- 前期介绍
- CNN-NER
- 模型介绍
- 代码讲解
- 主类
- 多头biaffine
- CNN
- Loss
- 解码
- 数据传入格式
- 参考资料
有关工作
前期介绍
过去一共主要有四类方式用来解决嵌套命名实体识别的任务:
- 基于序列标注(sequence labeling)
- 基于超图(hypergraph)
- 基于序列到序列(Seq2Seq)
- 基于片段分类(span classification)
本文跟进了《Named Entity Recognition as Dependency Parsing》这一论文的工作,同样采用基于片段分类的方案。
该论文提出采用起始、结束词来指明对应的片段,并利用双仿射(Biaffine Decoder)来得到一个评分矩阵,其元素(i,j)代表对应片段(开始位置为第i个词,结束位置为第j个词)为实体的分数,这一基于片段的方法在计算上易于并行,因此得到了广泛的采用
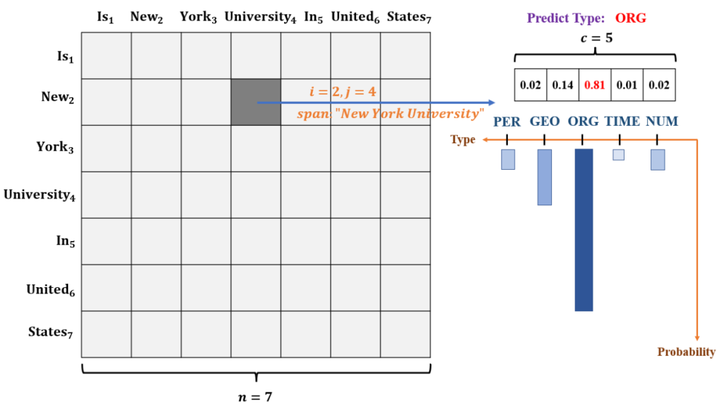
下图给出一个直观的例子理解评分矩阵。这里由概率可得span(start=2,end=4)=“New York University”最可能是ORG实体
CNN-NER
作者在此基础上注意到了过往的工作忽视了相邻片段间的彼此联系,并通过对评分矩阵的观察分析发现了临近的片段具有非常明显的空间关联。如下图所示

- o:中心的span
- a:后端的字符序列与中心span冲突
- b:前端的字符序列与中心span冲突
- c:包含中心span
- d:被中心span包含
- e:无冲突
针对左上角第一个矩阵:o(2-4),New York University
a(1-3),Is New York
c(1-4),Is New York University
c(1-5),Is New York University in
d(2-3),New York
c(2-5),New York University in
d(3-3),York
d(3-4),York University
b(3-5),York University in针对右下角第二个矩阵:o(6-6),United
e(5-5),in
c(5-6),in United
c(5-7),in United States
c(6-5),in United
c(6-7),United States
c(7-5),in United States
c(7-6),United States
c(7-7),States
作者把这种针对每一个中心span的张量理解成一种通道数,进一步采用了计算机视觉领域常用的卷积神经网络(CNN)来建模这种空间联系,最终得到一个简单但颇具竞争力的嵌套命名实体解决方案,将其命名为CNN-NER
模型介绍
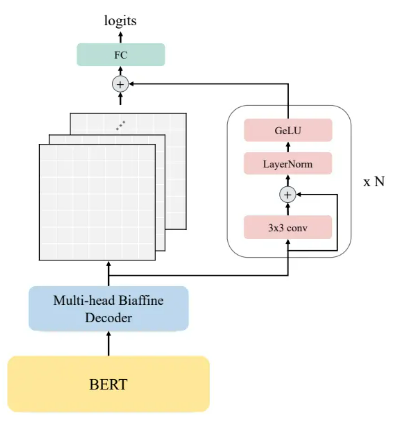
首先使用编码器(BERT-Encoder)对输入序列进行编码。在获得上下文有关的词嵌入(embedding)后,过去的工作通常将其与静态的词嵌入以及字符级别的嵌入拼接起来送入BiLSTM中获得聚合的词表示,但本文为了让模型架构比较简单,就没有采用更多的嵌入也没有额外引入LSTM层。
然后仿照之前的工作,采用双头仿射解码器(multi-head Biaffine Decoder)获取表示所有可能的片段对应的特征矩阵。
接下来,从维度上考察特征矩阵,将其视作多通道的图片,采用若干个常见的卷积块提取特征矩阵的空间特征。
最后通过FC和sigmoid函数预测对应片段是命名实体的“概率”。训练的损失函数采用的是常见的二元交叉熵(BCE)
本文使用了与之前工作相同的方法解码模型输出的概率,即采用如下的贪心选择:首先丢弃所有预测概率低于0.5的片段,然后按照预测概率从高到低对片段进行排序,依次选择当前预测概率最高的片段,如果其不与之前已经解码出的命名实体冲突,则将该片段解码成一个新的命名实体,否则将其丢弃。如此迭代进行就得到了模型预测的输入序列的所有互不冲突的命名实体

代码讲解
主类
class CNNNer(BaseModel):def __init__(self, num_ner_tag, cnn_dim=200, biaffine_size=200,size_embed_dim=0, logit_drop=0, kernel_size=3, n_head=4, cnn_depth=3):super(CNNNer, self).__init__()self.pretrain_model = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, segment_vocab_size=0)hidden_size = self.pretrain_model.configs['hidden_size']if size_embed_dim!=0:n_pos = 30self.size_embedding = torch.nn.Embedding(n_pos, size_embed_dim)_span_size_ids = torch.arange(512) - torch.arange(512).unsqueeze(-1)_span_size_ids.masked_fill_(_span_size_ids < -n_pos/2, -n_pos/2)_span_size_ids = _span_size_ids.masked_fill(_span_size_ids >= n_pos/2, n_pos/2-1) + n_pos/2self.register_buffer('span_size_ids', _span_size_ids.long())hsz = biaffine_size*2 + size_embed_dim + 2else:hsz = biaffine_size*2+2biaffine_input_size = hidden_sizeself.head_mlp = nn.Sequential(nn.Dropout(0.4),nn.Linear(biaffine_input_size, biaffine_size),nn.LeakyReLU(),)self.tail_mlp = nn.Sequential(nn.Dropout(0.4),nn.Linear(biaffine_input_size, biaffine_size),nn.LeakyReLU(),)self.dropout = nn.Dropout(0.4)if n_head>0:self.multi_head_biaffine = MultiHeadBiaffine(biaffine_size, cnn_dim, n_head=n_head)else:self.U = nn.Parameter(torch.randn(cnn_dim, biaffine_size, biaffine_size))torch.nn.init.xavier_normal_(self.U.data)self.W = torch.nn.Parameter(torch.empty(cnn_dim, hsz))torch.nn.init.xavier_normal_(self.W.data)if cnn_depth>0:self.cnn = MaskCNN(cnn_dim, cnn_dim, kernel_size=kernel_size, depth=cnn_depth)self.down_fc = nn.Linear(cnn_dim, num_ner_tag)self.logit_drop = logit_dropdef forward(self, input_ids, indexes):last_hidden_states = self.pretrain_model([input_ids])state = scatter_max(last_hidden_states, index=indexes, dim=1)[0][:, 1:] # b * l * hidden_sizelengths, _ = indexes.max(dim=-1)head_state = self.head_mlp(state)# b * l * l * biaffine_sizetail_state = self.tail_mlp(state)# b * l * l * biaffine_sizeif hasattr(self, 'U'):scores1 = torch.einsum('bxi, oij, byj -> boxy', head_state, self.U, tail_state)else:scores1 = self.multi_head_biaffine(head_state, tail_state)#b * cnn_dim * l * lhead_state = torch.cat([head_state, torch.ones_like(head_state[..., :1])], dim=-1)# b * l * l * biaffine_size + 1tail_state = torch.cat([tail_state, torch.ones_like(tail_state[..., :1])], dim=-1)# b * l * l * biaffine_size + 1affined_cat = torch.cat([self.dropout(head_state).unsqueeze(2).expand(-1, -1, tail_state.size(1), -1),self.dropout(tail_state).unsqueeze(1).expand(-1, head_state.size(1), -1, -1)], dim=-1)## b * l * l * 2(biaffine_size + 1)if hasattr(self, 'size_embedding'):size_embedded = self.size_embedding(self.span_size_ids[:state.size(1), :state.size(1)])# l * l * size_embed_dimaffined_cat = torch.cat([affined_cat, self.dropout(size_embedded).unsqueeze(0).expand(state.size(0), -1, -1, -1)], dim=-1)# b * l * l * (2(biaffine_size + 1) + size_embed_dim)scores2 = torch.einsum('bmnh,kh->bkmn', affined_cat, self.W) # b x cnn_dim x L x Lscores = scores2 + scores1# b x cnn_dim x L x Lif hasattr(self, 'cnn'): batch_size = lengths.shape[0]broad_cast_seq_len = torch.arange(int(lengths.max())).expand(batch_size, -1).to(lengths)mask = broad_cast_seq_len < lengths.unsqueeze(1)mask = mask[:, None] * mask.unsqueeze(-1)pad_mask = mask[:, None].eq(0)u_scores = scores.masked_fill(pad_mask, 0)if self.logit_drop != 0:u_scores = F.dropout(u_scores, p=self.logit_drop, training=self.training)u_scores = self.cnn(u_scores, pad_mask)# b x cnn_dim x L x Lscores = u_scores + scoresscores = self.down_fc(scores.permute(0, 2, 3, 1))return scores # b * L * L * num_ner_tag
多头biaffine
class MultiHeadBiaffine(nn.Module):def __init__(self, dim, out=None, n_head=4):super(MultiHeadBiaffine, self).__init__()assert dim%n_head==0in_head_dim = dim//n_headout = dim if out is None else outassert out%n_head == 0out_head_dim = out//n_headself.n_head = n_headself.W = nn.Parameter(nn.init.xavier_normal_(torch.randn(self.n_head, out_head_dim, in_head_dim, in_head_dim)))self.out_dim = outdef forward(self, h, v):""":param h: bsz x max_len x dim:param v: bsz x max_len x dim:return: bsz x max_len x max_len x out_dim"""bsz, max_len, dim = h.size()h = h.reshape(bsz, max_len, self.n_head, -1)v = v.reshape(bsz, max_len, self.n_head, -1)w = torch.einsum('blhx,hdxy,bkhy->bhdlk', h, self.W, v)w = w.reshape(bsz, self.out_dim, max_len, max_len)return w
CNN
class MaskConv2d(nn.Module):def __init__(self, in_ch, out_ch, kernel_size=3, padding=1, groups=1):super(MaskConv2d, self).__init__()self.conv2d = nn.Conv2d(in_ch, out_ch, kernel_size=kernel_size, padding=padding, bias=False, groups=groups)def forward(self, x, mask):x = x.masked_fill(mask, 0)_x = self.conv2d(x)return _xclass MaskCNN(nn.Module):def __init__(self, input_channels, output_channels, kernel_size=3, depth=3):super(MaskCNN, self).__init__()layers = []for _ in range(depth):layers.extend([MaskConv2d(input_channels, input_channels, kernel_size=kernel_size, padding=kernel_size//2),LayerNorm((1, input_channels, 1, 1), dim_index=1),nn.GELU()])layers.append(MaskConv2d(input_channels, output_channels, kernel_size=3, padding=3//2))self.cnns = nn.ModuleList(layers)def forward(self, x, mask):_x = x # 用作residualfor layer in self.cnns:if isinstance(layer, LayerNorm):x = x + _xx = layer(x)_x = xelif not isinstance(layer, nn.GELU):x = layer(x, mask)else:x = layer(x)return _x
Loss
class Loss(object):def __call__(self, scores, y_true):matrix, _ = y_trueassert scores.shape[-1] == matrix.shape[-1]flat_scores = scores.reshape(-1)flat_matrix = matrix.reshape(-1)mask = flat_matrix.ne(-100).float().view(scores.size(0), -1)flat_loss = F.binary_cross_entropy_with_logits(flat_scores, flat_matrix.float(), reduction='none')loss = ((flat_loss.view(scores.size(0), -1)*mask).sum(dim=-1)).mean()return loss
解码
class Evaluator(Callback):"""评估与保存"""def __init__(self):self.best_val_f1 = 0.def on_epoch_end(self, steps, epoch, logs=None):f1, p, r, e_f1, e_p, e_r = self.evaluate(valid_dataloader)if e_f1 > self.best_val_f1:self.best_val_f1 = e_f1# model.save_weights('best_model.pt')print(f'[val-token level] f1: {f1:.5f}, p: {p:.5f} r: {r:.5f}')print(f'[val-entity level] f1: {e_f1:.5f}, p: {e_p:.5f} r: {e_r:.5f} best_f1: {self.best_val_f1:.5f}\n')def evaluate(self, data_loader, threshold=0.5):def cal_f1(c, p, r):if r == 0 or p == 0:return 0, 0, 0r = c / r if r else 0p = c / p if p else 0if r and p:return 2 * p * r / (p + r), p, rreturn 0, p, rpred_result = []label_result = []total_ent_r = 0total_ent_p = 0total_ent_c = 0for data_batch in tqdm(data_loader, desc='Evaluate'):(tokens_ids, indexes), (matrix, ent_target) = data_batchscores = torch.sigmoid(model.predict([tokens_ids, indexes])).gt(threshold).long()scores = scores.masked_fill(matrix.eq(-100), 0) # mask掉padding部分# token粒度mask = matrix.reshape(-1).ne(-100)label_result.append(matrix.reshape(-1).masked_select(mask).cpu())pred_result.append(scores.reshape(-1).masked_select(mask).cpu())# 实体粒度ent_c, ent_p, ent_r = self.decode(scores.cpu().numpy(), ent_target)total_ent_r += ent_rtotal_ent_p += ent_ptotal_ent_c += ent_clabel_result = torch.cat(label_result)pred_result = torch.cat(pred_result)p, r, f1, _ = precision_recall_fscore_support(label_result.numpy(), pred_result.numpy(), average="macro")e_f1, e_p, e_r = cal_f1(total_ent_c, total_ent_p, total_ent_r)return f1, p, r, e_f1, e_p, e_rdef decode(self, outputs, ent_target):ent_c, ent_p, ent_r = 0, 0, 0for pred, label in zip(outputs, ent_target):ent_r += len(label)pred_tuple = []for item in range(pred.shape[-1]):if pred[:, :, item].sum() > 0:_index = np.where(pred[:, :, item]>0)tmp = [(i, j, item) if j >= i else (j, i, item) for i, j in zip(*_index)]pred_tuple.extend(list(set(tmp)))ent_p += len(pred_tuple)ent_c += len(set(label).intersection(set(pred_tuple)))return ent_c, ent_p, ent_r
数据传入格式
初步处理
class MyDataset(ListDataset):@staticmethoddef get_new_ins(bpes, spans, indexes):bpes.append(tokenizer._token_end_id)cur_word_idx = indexes[-1]indexes.append(0)# int8范围-128~127matrix = np.zeros((cur_word_idx, cur_word_idx, len(label2idx)), dtype=np.int8)ent_target = []for _ner in spans:s, e, t = _nermatrix[s, e, t] = 1matrix[e, s, t] = 1ent_target.append((s, e, t))assert len(bpes)<=maxlen, len(bpes)return [bpes, indexes, matrix, ent_target]def load_data(self, filename):D = []word2bpes = {}with open(filename, encoding='utf-8') as f:f = f.read()for l in tqdm(f.split('\n\n'), desc='Load data'):if not l:continue_raw_words, _raw_ents = [], []for i, c in enumerate(l.split('\n')):char, flag = c.split(' ')_raw_words += charif flag[0] == 'B':_raw_ents.append([i, i, flag[2:]])elif flag[0] == 'I':_raw_ents[-1][1] = iif len(_raw_words) > maxlen - 2:continuebpes = [tokenizer._token_start_id]indexes = [0]spans = []ins_lst = []_indexes = []_bpes = []for idx, word in enumerate(_raw_words, start=0):if word in word2bpes:__bpes = word2bpes[word]else:__bpes = tokenizer.encode(word)[0][1:-1]word2bpes[word] = __bpes_indexes.extend([idx]*len(__bpes))_bpes.extend(__bpes)next_word_idx = indexes[-1]+1if len(bpes) + len(_bpes) <= maxlen:bpes = bpes + _bpesindexes += [i + next_word_idx for i in _indexes]spans += [(s+next_word_idx-1, e+next_word_idx-1, label2idx.get(t), ) for s, e, t in _raw_ents]else:new_ins = self.get_new_ins(bpes, spans, indexes)ins_lst.append(new_ins)indexes = [0] + [i + 1 for i in _indexes]spans = [(s, e, label2idx.get(t), ) for s, e, t in _raw_ents]bpes = [tokenizer._token_start_id] + _bpesD.append(self.get_new_ins(bpes, spans, indexes))return D
传入的是:
- bpes:对应input_ids
- indexes:“CLS”、"SEP"为0,其他字符按照所在句子的位置的索引
- matrix:[cur_word_idx, cur_word_idx, len(label2idx)],第三个维度表明若是某个实体,则设为1
- ent_target:在当前句子中存在实体的的[start,ent,ent_type]
def collate_fn(data):tokens_ids, indexes, matrix, ent_target = map(list, zip(*data))tokens_ids = torch.tensor(sequence_padding(tokens_ids), dtype=torch.long, device=device)indexes = torch.tensor(sequence_padding(indexes), dtype=torch.long, device=device)seq_len = max([i.shape[0] for i in matrix])matrix_new = np.ones((len(tokens_ids), seq_len, seq_len, len(label2idx)), dtype=np.int8) * -100for i in range(len(tokens_ids)):matrix_new[i, :len(matrix[i][0]), :len(matrix[i][0]), :] = matrix[i]matrix = torch.tensor(matrix_new, dtype=torch.long, device=device)return [tokens_ids, indexes], [matrix, ent_target]
- 对tokens_ids、indexes进行填充为0
- 对matrix填充为-100
参考资料
https://zhuanlan.zhihu.com/p/565824221
参照代码:
https://github.com/Tongjilibo/bert4torch/blob/master/examples/sequence_labeling/task_sequence_labeling_ner_CNN_Nested_NER.py
相关文章:
CNN-NER论文详解
论文:https://arxiv.org/abs/2208.04534 代码:https://github.com/yhcc/CNN_Nested_NER/tree/master 文章目录 有关工作前期介绍CNN-NER模型介绍 代码讲解主类多头biaffineCNNLoss解码数据传入格式 参考资料 有关工作 前期介绍 过去一共主要有四类方式…...

利用ChatGPT制作行业应用:哪些行业最受益
引言 随着人工智能技术的快速发展,ChatGPT(Chat Generative Pre-trained Transformer)成为了一种引人注目的工具,它能够生成自然流畅的对话内容。这种技术不仅在娱乐领域有着广泛的应用,还可以在各个行业中发挥重要作…...

【SA8295P 源码分析】60 - QNX Host 如何新增 android_test 分区给 Android GVM 挂载使用
【SA8295P 源码分析】60 - QNX Host 如何新增 android_test 分区给 Android GVM 挂载使用 一、QNX 侧:创建分区、配置下载、配置透传1.1 修改分区表,新增 android_test 分区,大小为 2GByte1.2 配置下载 android_test.img 镜像1.3 配置 /dev/disk/android_test_a 分区透传到 …...
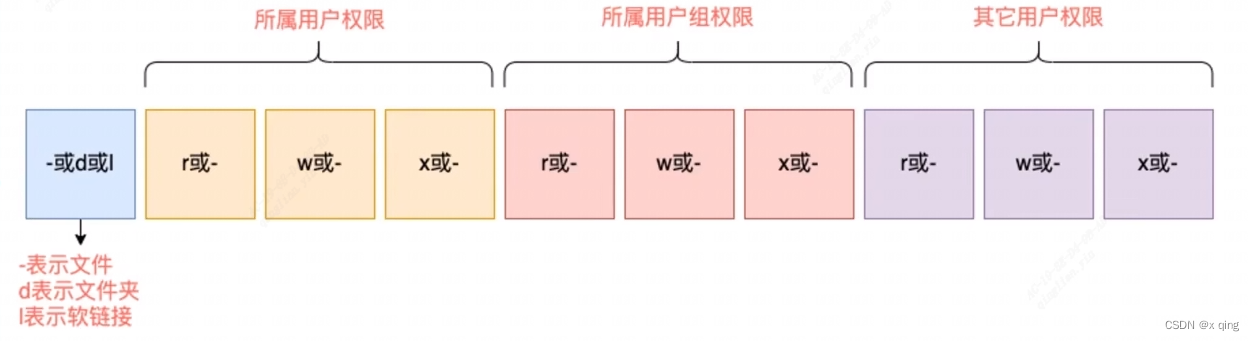
Linux 用户和权限
一、root 用户 root 用户(超级管理员) 无论是windows、Macos、Linux均采用多用户的管理模式进行权限管理。在Linux系统中,拥有最大权限的账户名为:root (超级管理员)。 root用户拥有最大的系统操作权限,而普通用户在许多地方的权限是受限的。…...
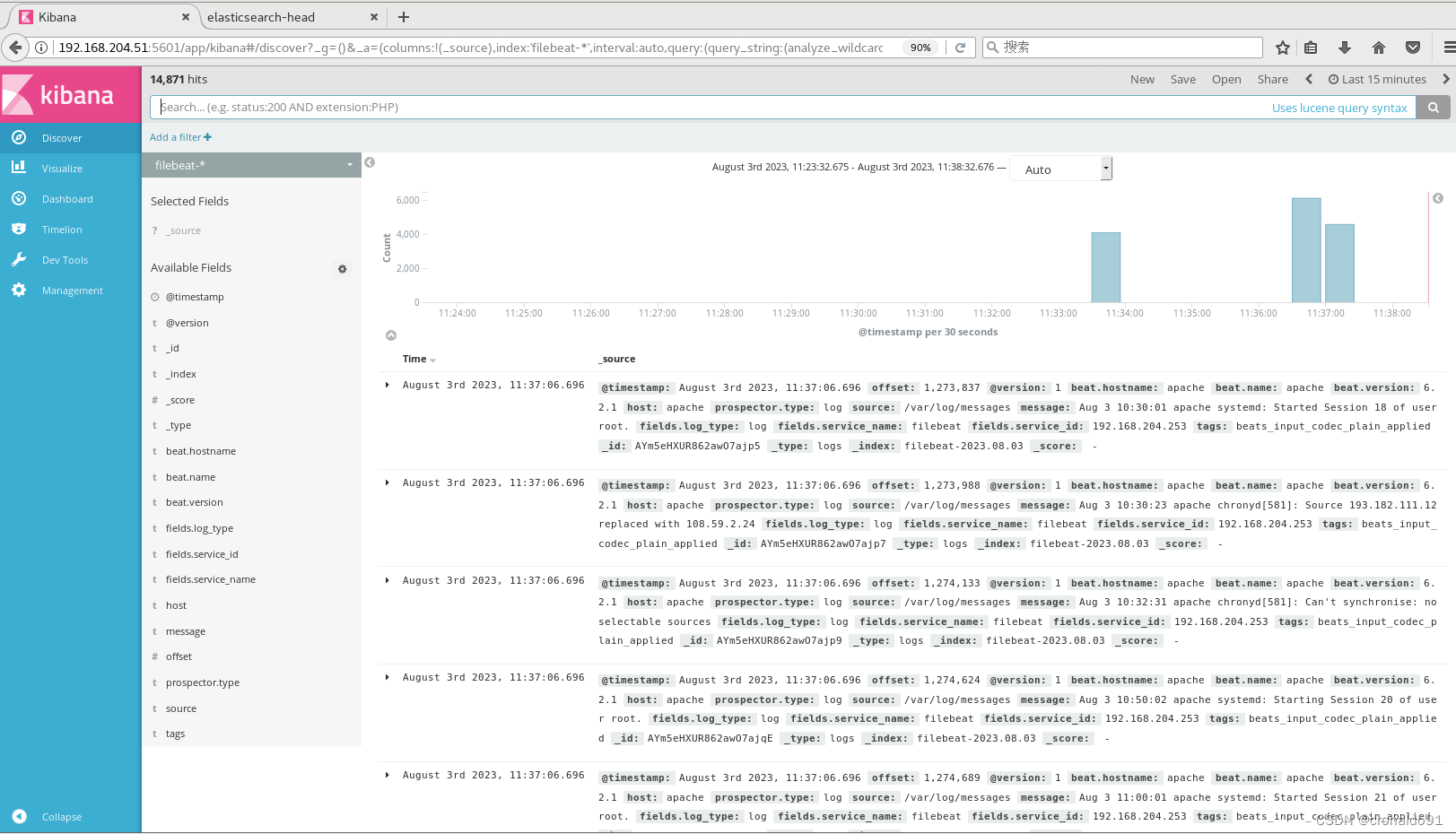
分布式应用:ELFK集群部署
目录 一、理论 1.ELFK集群 2.filebeat 3.部署ELK集群 二、实验 1. ELFK集群部署 三、总结 一、理论 1.ELFK集群 (1)概念 ELFK集群部署(FilebeatELK),ELFK ES logstashfilebeatkibana 。 数据流 架构 2.fi…...
Quartz使用文档,使用Quartz实现动态任务,Spring集成Quartz,Quartz集群部署,Quartz源码分析
文章目录 一、Quartz 基本介绍二、Quartz Java 编程1、文档2、引入依赖3、入门案例4、默认配置文件 三、Quartz 重要组件1、Quartz架构体系2、JobDetail3、Trigger(1)代码实例(2)SimpleTrigger(3)CalendarI…...

Go -- 测试 and 项目实战
没有后端基础,学起来真是费劲,所以打算速刷一下,代码跟着敲一遍,有个印象,大项目肯定也做不了了,先把该学的学了,有空就跟点单体项目,还有该看的书.... 目录 🍌单元测试…...

GitHub基本使用
GitHub搜索 直接搜索 直接搜索关键字 明确搜索仓库标题 语法:in:name [关键词]展示:比如我们想在GitHub仓库中标题中搜索带有SpringBoot关键词的,我们可以样搜: in:name SpringBoot 明确搜索描述 语法:in:description [关键词]展…...
微信小程序生成带参数的二维码base64转png显示
getQRCode() {var that this;wx.request({url: http://localhost:8080/getQRCode?ID 13,header: {content-type: application/json},method: POST,responseType: arraybuffer,//将原本按文本解析修改为arraybuffersuccess(res) {that.setData({getQRCode: wx.arrayBufferToB…...

量子计算机:下一代计算技术的奇点
介绍 量子计算机是一种基于量子力学原理的全新计算技术,它利用量子比特的特性进行计算,具有破解当前经典计算机难以解决问题的潜力。在过去几十年里,量子计算机一直是计算机科学领域的一个热门话题。本篇博客将深入探讨量子计算机的基本原理…...

【ChatGPT】ChatGPT是如何训练得到的?
前言 ChatGPT是一种基于语言模型的聊天机器人,它使用了GPT(Generative Pre-trained Transformer)的深度学习架构来生成与用户的对话。GPT是一种使用Transformer编码器和解码器的预训练模型,它已被广泛用于生成自然语言文本的各种…...

Docker设置代理、Linux系统设置代理
使用方式 新建或修改~/.docker/config.json文件,设置可用的代理地址。 {"proxies": {"default": {"httpProxy": "http://192.168.0.32:1080","httpsProxy": "http://192.168.0.32:1080","noPro…...

C# 进程
C# 进程 进程的命名空间是: using System.Diagnostics;1.获取当前计算机正在运行所有的进程 Process[] processes Process.GetProcesses(); for (int i 0; i < processes.Length; i) {Console.WriteLine(processes[i]); } Console.ReadKey();2.通过进程打开…...
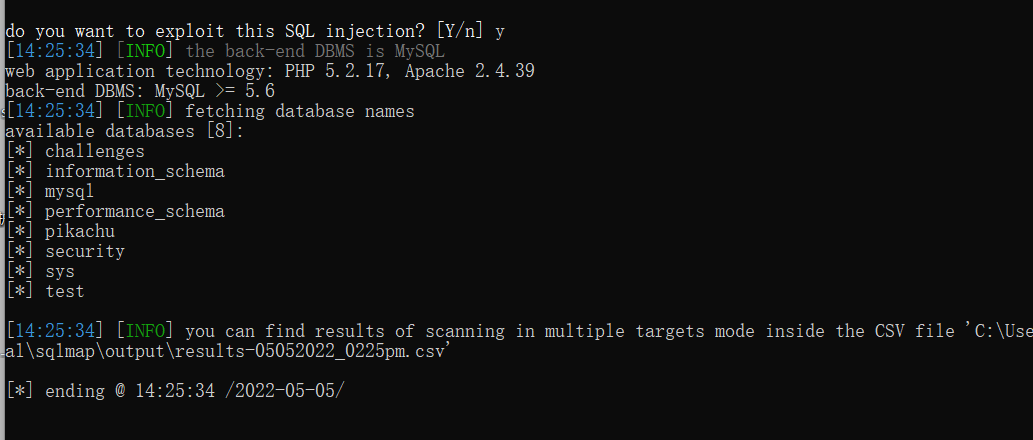
SQL注入之sqlmap
SQL注入之sqlmap 6.1 SQL注入之sqlmap安装 sqlmap简介: sqlmap是一个自动化的SQL注入工具,其主要功能是扫描,发现并利用给定的URL的SQL注入漏洞,目前支持的数据库是MS-SQL,MYSQL,ORACLE和POSTGRESQL。SQLMAP采用四种独特的SQL注…...

Flutter 命名路由
我们可以通过创建一个新的Route,使用Navigator来导航到一个新的页面,但是如果在应用中很多地方都需要导航到同一个页面(比如在开发中,首页、推荐、分类页都可能会跳到详情页),那么就会存在很多重复的代码。…...

Stephen Wolfram:神经网络
Neural Nets 神经网络 OK, so how do our typical models for tasks like image recognition actually work? The most popular—and successful—current approach uses neural nets. Invented—in a form remarkably close to their use today—in the 1940s, neural nets …...
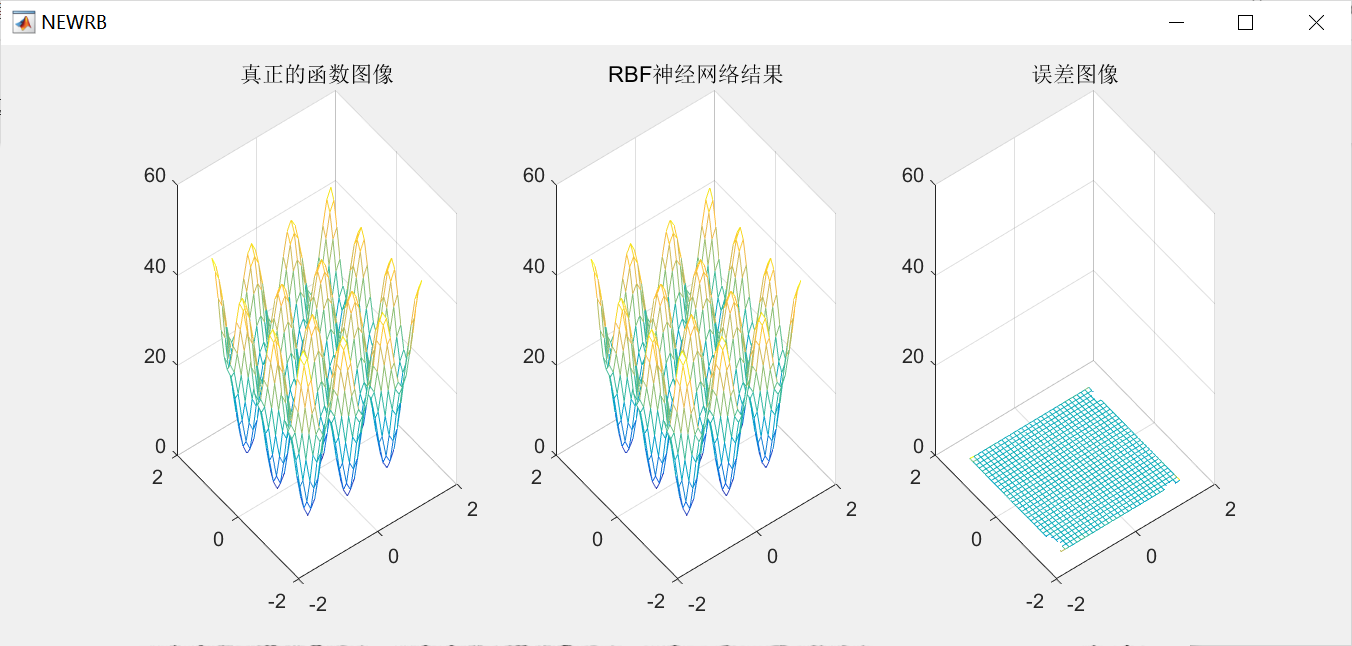
RBF神经网络原理和matlab实现
1.案例背景 1.1 RBF神经网络概述 径向基函数(Radical Basis Function,RBF)是多维空间插值的传统技术,由Powell于1985年提出。1988年, Broomhead和 Lowe根据生物神经元具有局部响应这一特点,将 RBF引入神经网络设计中,产生了RBF神经网络。1989 年,Jackson论证了…...
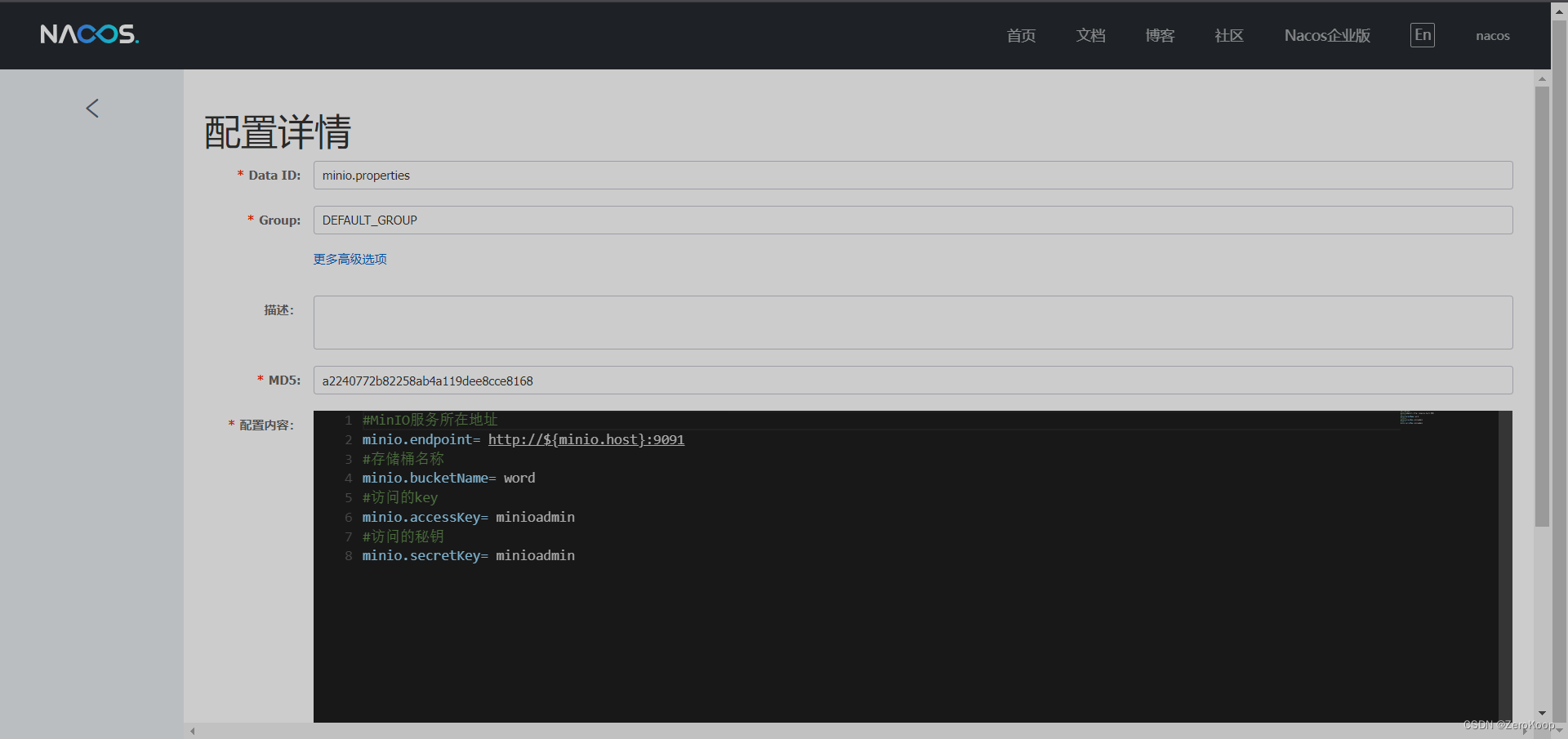
Nacos 抽取公共配置
文章目录 创建一个公共配置文件其他配置文件引用springboot配置文件 创建一个公共配置文件 其他配置文件引用 ${变量} springboot配置文件 spring:cloud:nacos:discovery:server-addr: current.ip:8848namespace: word_register_proconfig:server-addr: current.ip:8848auto-r…...

Promise、Async/Await 详解
一、什么是Promise Promise是抽象异步处理对象以及对其进行各种操作的组件。Promise本身是同步的立即执行函数解决异步回调的问题, 当调用 resolve 或 reject 回调函数进行处理的时候, 是异步操作, 会先执行.then/catch等,当主栈完成后&#…...

PoseiSwap:基于 Nautilus Chain ,构建全新价值体系
在 DeFi Summer 后,以太坊自身的弊端不断凸显,而以 Layer2 的方式为其扩容成为了行业很长一段时间的叙事方向之一。虽然以太坊已经顺利的从 PoW 的 1.0 迈向了 PoS 的 2.0 时代,但以太坊创始人 Vitalik Buterin 表示, Layer2 未来…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

微信红包助手终极指南:无需ROOT的智能抢红包解决方案
微信红包助手终极指南:无需ROOT的智能抢红包解决方案 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址: ht…...

5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南
5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专为Windows设计的鼠…...

每日一书㉗ | 刻意练习:为什么有些人努力一辈子还是平庸?
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”先问你一个问题。你身边有没有这样的人:入行时间比你短,但能力已经甩你好几条街。他们好像没有特别刻苦,但…...

如何永久保存微信聊天记录?WeChatMsg终极数据导出指南
如何永久保存微信聊天记录?WeChatMsg终极数据导出指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

Hyper-V离散设备分配图形化解决方案:企业级虚拟化性能优化实践
Hyper-V离散设备分配图形化解决方案:企业级虚拟化性能优化实践 【免费下载链接】DDA 实现Hyper-V离散设备分配功能的图形界面工具。A GUI Tool For Hyper-Vs Discrete Device Assignment(DDA). 项目地址: https://gitcode.com/gh_mirrors/dd/DDA 在数字化转…...