【ChatGPT】ChatGPT是如何训练得到的?
前言
ChatGPT是一种基于语言模型的聊天机器人,它使用了GPT(Generative Pre-trained Transformer)的深度学习架构来生成与用户的对话。GPT是一种使用Transformer编码器和解码器的预训练模型,它已被广泛用于生成自然语言文本的各种应用程序,例如文本生成,机器翻译和语言理解。

在本文中,我们将探讨如何使用Python和PyTorch来训练ChatGPT,以及如何使用已经训练的模型来生成对话。
1.准备数据
在训练ChatGPT之前,我们需要准备一个大型的对话数据集。这个数据集应该包含足够的对话,覆盖各种主题和领域,以及各种不同的对话风格。这个数据集可以是从多个来源收集的,例如电影脚本,电视节目,社交媒体上的聊天记录等。
在本文中,我们将使用Cornell Movie Dialogs Corpus,一个包含电影对话的大型数据集。这个数据集包含超过22,000个对话,涵盖了多个主题和风格。
我们可以使用以下代码下载和解压缩Cornell Movie Dialogs Corpus,这个数据集也可以从[这里](https://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html)手动下载。
import os
import urllib.request
import zipfileDATA_URL = 'http://www.cs.cornell.edu/~cristian/data/cornell_movie_dialogs_corpus.zip'
DATA_DIR = './cornell_movie_dialogs_corpus'
DATA_FILE = os.path.join(DATA_DIR, 'cornell_movie_dialogs_corpus.zip')if not os.path.exists(DATA_DIR):os.makedirs(DATA_DIR)if not os.path.exists(DATA_FILE):print('Downloading data...')urllib.request.urlretrieve(DATA_URL, DATA_FILE)print('Extracting data...')
with zipfile.ZipFile(DATA_FILE, 'r') as zip_ref:zip_ref.extractall(DATA_DIR)2.数据预处理
在准备好数据集之后,我们需要对数据进行预处理,以便将其转换为模型可以处理的格式。在本教程中,我们使用了一个简单的预处理步骤,该步骤包括下列几步:
- 将数据拆分成句子pairs(上下文,回答)
- 去除标点符号和特殊字符
- 将所有的单词转换成小写
- 将单词映射到一个整数ID
- 将句子填充到相同的长度
下面是用于预处理数据的代码:
import re
import random
import numpy as np
import torchdef load_conversations():id2line = {}with open(os.path.join(DATA_DIR, 'movie_lines.txt'), errors='ignore') as f:for line in f:parts = line.strip().split(' +++$+++ ')id2line[parts[0]] = parts[4]inputs = []outputs = []with open(os.path.join(DATA_DIR, 'movie_conversations.txt'), 'r') as f:for line in f:parts = line.strip().split(' +++$+++ ')conversation = [id2line[id] for id in parts[3][1:-1].split(',')]for i in range(len(conversation) - 1):inputs.append(conversation[i])outputs.append(conversation[i+1])return inputs, outputsdef preprocess_sentence(sentence):sentence = re.sub(r"([?.!,])", r" \1 ", sentence)sentence = re.sub(r"[^a-zA-Z?.!,]+", r" ", sentence)sentence = sentence.lower()return sentencedef tokenize_sentence(sentence, word2index):tokenized = []for word in sentence.split(' '):if word not in word2index:continuetokenized.append(word2index[word])return tokenizeddef preprocess_data(inputs, outputs, max_length=20):pairs = []for i in range(len(inputs)):input_sentence = preprocess_sentence(inputs[i])output_sentence = preprocess_sentence(outputs[i])pairs.append((input_sentence, output_sentence))word_counts = {}for pair in pairs:for sentence in pair:for word in sentence.split(' '):if word not in word_counts:word_counts[word] = 0word_counts[word] += 1word2index = {}index2word = {0: '<pad>', 1: '<start>', 2: '<end>', 3: '<unk>'}index = 4for word, count in word_counts.items():if count >= 10:word2index[word] = indexindex2word[index] = wordindex += 1inputs_tokenized = []outputs_tokenized = []for pair in pairs:input_sentence, output_sentence = pairinput_tokenized = [1] + tokenize_sentence(input_sentence, word2index) + [2]output_tokenized = [1] + tokenize_sentence(output_sentence, word2index) + [2]if len(input_tokenized) <= max_length and len(output_tokenized) <= max_length:inputs_tokenized.append(input_tokenized)outputs_tokenized.append(output_tokenized)inputs_padded = torch.nn.utils.rnn.pad_sequence(inputs_tokenized, batch_first=True, padding_value=0)outputs_padded = torch.nn.utils.rnn.pad_sequence(outputs_tokenized, batch_first=True, padding_value=0)return inputs_padded, outputs_padded, word2index, index2word
3.训练模型
在完成数据预处理之后,我们可以开始训练ChatGPT模型。对于本文中的示例,我们将使用PyTorch深度学习框架来实现ChatGPT模型。
首先,我们需要定义一个Encoder-Decoder模型结构。这个结构包括一个GPT解码器,它将输入的上下文句子转换为一个回答句子。GPT解码器由多个Transformer解码器堆叠而成,每个解码器都包括多头注意力和前馈神经网络层。
import torch.nn as nn
from transformers import GPT2LMHeadModelclass EncoderDecoder(nn.Module):def __init__(self, num_tokens, embedding_dim=256, hidden_dim=512, num_layers=2, max_length=20):super().__init__()self.embedding = nn.Embedding(num_tokens, embedding_dim)self.decoder = nn.ModuleList([GPT2LMHeadModel.from_pretrained('gpt2') for _ in range(num_layers)])self.max_length = max_lengthdef forward(self, inputs, targets=None):inputs_embedded = self.embedding(inputs)outputs = inputs_embeddedfor decoder in self.decoder:outputs = decoder(inputs_embedded=outputs)[0]return outputsdef generate(self, inputs, temperature=1.0):inputs_embedded = self.embedding(inputs)input_length = inputs.shape[1]output = inputs_embeddedfor decoder in self.decoder:output = decoder(inputs_embedded=output)[0][:, input_length-1, :]output_logits = output / temperatureoutput_probs = nn.functional.softmax(output_logits, dim=-1)output_token = torch.multinomial(output_probs, num_samples=1)output_token_embedded = self.embedding(output_token)output = torch.cat([output, output_token_embedded], dim=1)return output[:, input_length:, :]然后,我们需要定义一个训练函数,该函数将使用梯度下降方法优化模型参数,并将每个epoch的损失和正确率记录到一个日志文件中。
def train(model, inputs, targets, optimizer, criterion):model.train()optimizer.zero_grad()outputs = model(inputs, targets[:, :-1])loss = criterion(outputs.reshape(-1, outputs.shape[-1]), targets[:, 1:].reshape(-1))loss.backward()optimizer.step()return loss.item()def evaluate(model, inputs, targets, criterion):model.eval()with torch.no_grad():outputs = model(inputs, targets[:, :-1])loss = criterion(outputs.reshape(-1, outputs.shape[-1]), targets[:, 1:].reshape(-1))return loss.item()def train_model(model, inputs, targets, word2index, index2word, num_epochs=10, batch_size=64, lr=1e-3):device = torch.device('cuda' if torch.cuda.is_available() else 'cpu相关文章:
【ChatGPT】ChatGPT是如何训练得到的?
前言 ChatGPT是一种基于语言模型的聊天机器人,它使用了GPT(Generative Pre-trained Transformer)的深度学习架构来生成与用户的对话。GPT是一种使用Transformer编码器和解码器的预训练模型,它已被广泛用于生成自然语言文本的各种…...

Docker设置代理、Linux系统设置代理
使用方式 新建或修改~/.docker/config.json文件,设置可用的代理地址。 {"proxies": {"default": {"httpProxy": "http://192.168.0.32:1080","httpsProxy": "http://192.168.0.32:1080","noPro…...

C# 进程
C# 进程 进程的命名空间是: using System.Diagnostics;1.获取当前计算机正在运行所有的进程 Process[] processes Process.GetProcesses(); for (int i 0; i < processes.Length; i) {Console.WriteLine(processes[i]); } Console.ReadKey();2.通过进程打开…...
SQL注入之sqlmap
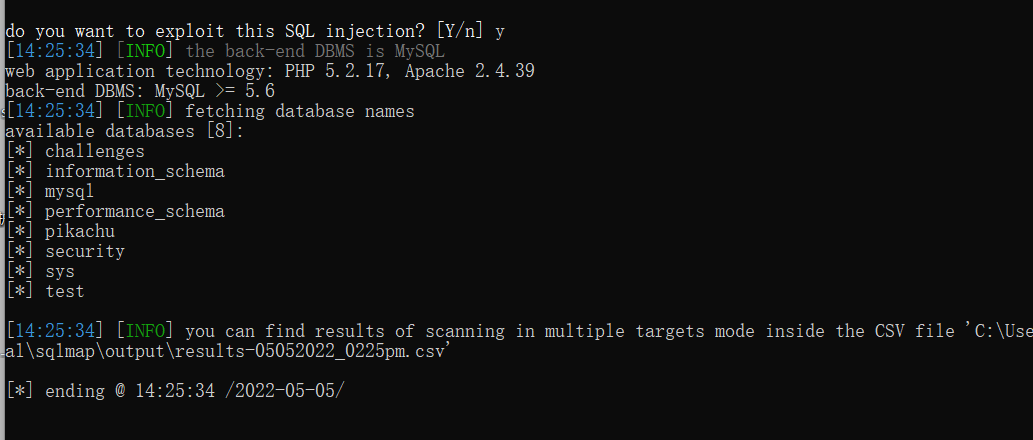
SQL注入之sqlmap 6.1 SQL注入之sqlmap安装 sqlmap简介: sqlmap是一个自动化的SQL注入工具,其主要功能是扫描,发现并利用给定的URL的SQL注入漏洞,目前支持的数据库是MS-SQL,MYSQL,ORACLE和POSTGRESQL。SQLMAP采用四种独特的SQL注…...

Flutter 命名路由
我们可以通过创建一个新的Route,使用Navigator来导航到一个新的页面,但是如果在应用中很多地方都需要导航到同一个页面(比如在开发中,首页、推荐、分类页都可能会跳到详情页),那么就会存在很多重复的代码。…...

Stephen Wolfram:神经网络
Neural Nets 神经网络 OK, so how do our typical models for tasks like image recognition actually work? The most popular—and successful—current approach uses neural nets. Invented—in a form remarkably close to their use today—in the 1940s, neural nets …...
RBF神经网络原理和matlab实现
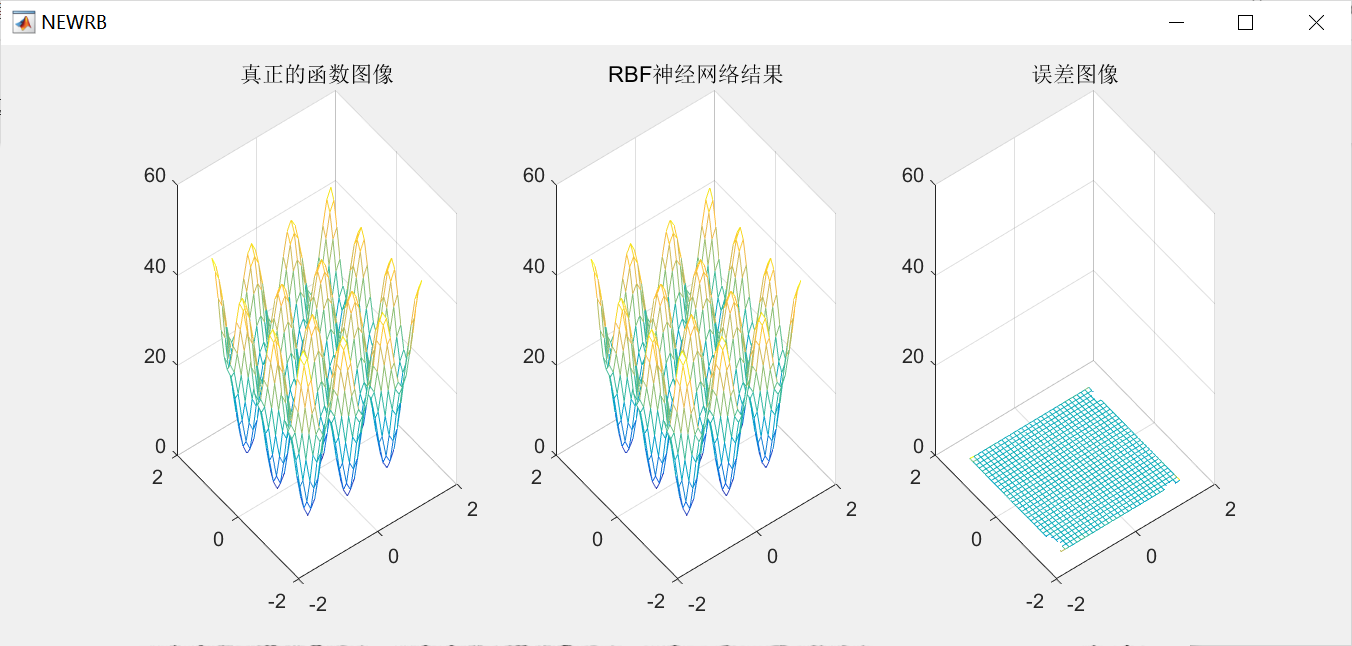
1.案例背景 1.1 RBF神经网络概述 径向基函数(Radical Basis Function,RBF)是多维空间插值的传统技术,由Powell于1985年提出。1988年, Broomhead和 Lowe根据生物神经元具有局部响应这一特点,将 RBF引入神经网络设计中,产生了RBF神经网络。1989 年,Jackson论证了…...
Nacos 抽取公共配置
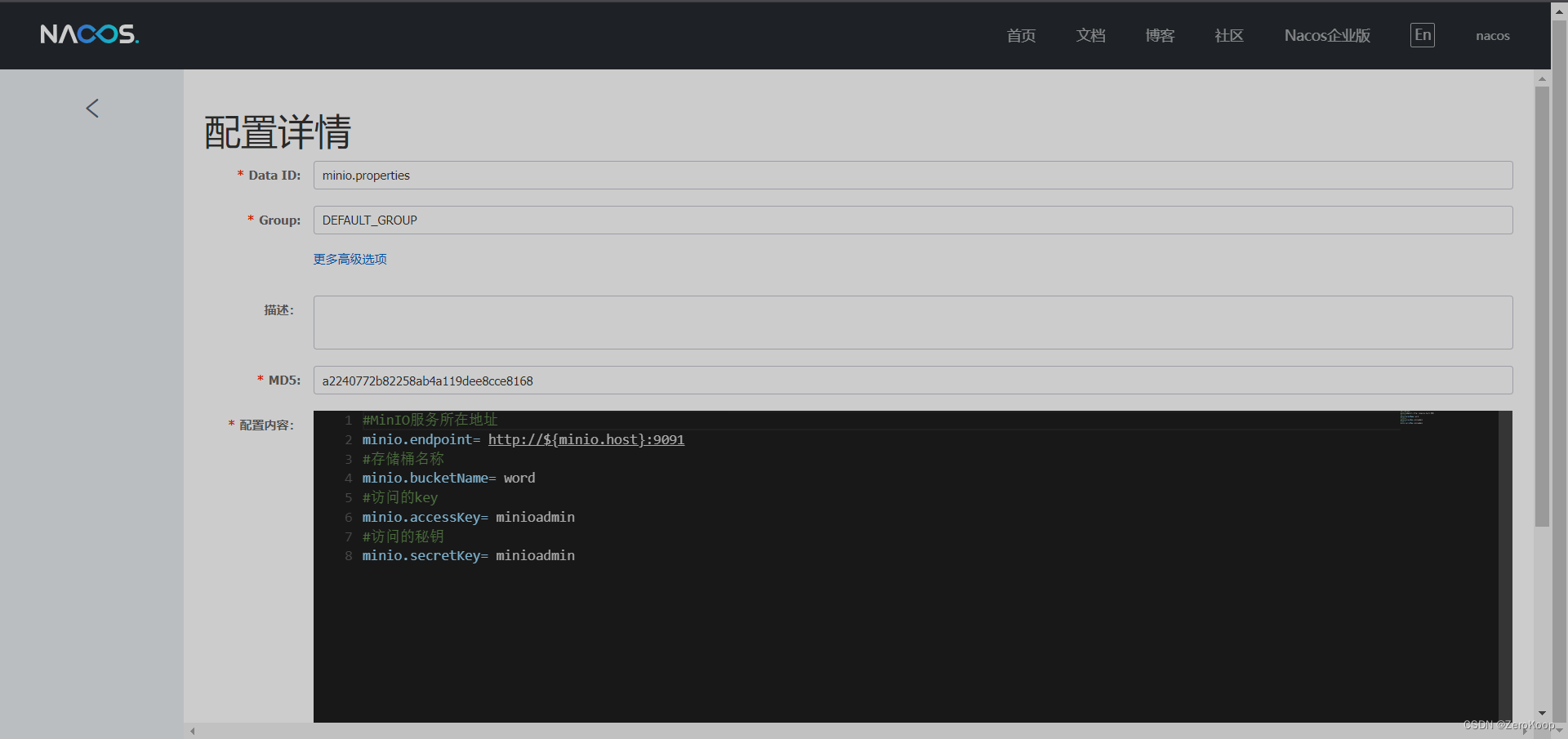
文章目录 创建一个公共配置文件其他配置文件引用springboot配置文件 创建一个公共配置文件 其他配置文件引用 ${变量} springboot配置文件 spring:cloud:nacos:discovery:server-addr: current.ip:8848namespace: word_register_proconfig:server-addr: current.ip:8848auto-r…...

Promise、Async/Await 详解
一、什么是Promise Promise是抽象异步处理对象以及对其进行各种操作的组件。Promise本身是同步的立即执行函数解决异步回调的问题, 当调用 resolve 或 reject 回调函数进行处理的时候, 是异步操作, 会先执行.then/catch等,当主栈完成后&#…...

PoseiSwap:基于 Nautilus Chain ,构建全新价值体系
在 DeFi Summer 后,以太坊自身的弊端不断凸显,而以 Layer2 的方式为其扩容成为了行业很长一段时间的叙事方向之一。虽然以太坊已经顺利的从 PoW 的 1.0 迈向了 PoS 的 2.0 时代,但以太坊创始人 Vitalik Buterin 表示, Layer2 未来…...

uC-OS2 V2.93 STM32L476 移植:串口打印篇
前言 前几篇已经 通过 STM32CubeMX 搭建了 NUCLEO-L476RG 的 STM32L476RG 的 裸机工程,下载了 uC-OS2 V2.93 的源码,并把 uC-OS2 的源文件加入 Keil MDK5 工程,通过适配 Systick 系统定时器与 PendSV 实现任务调度,初步让 uC-OS2 …...

代码随想录算法训练营第四十六天| 139.单词拆分 背包问题总结
代码随想录算法训练营第四十六天| 139.单词拆分 背包问题总结 一、力扣139.单词拆分 题目链接: 思路:确定dp数组,dp[i]为true表示从0到i切分的字串都在字典中出现过。 确定递推公式,dp[i] 为true要求 s[j, i] 在字典中出现&…...
【机器学习】西瓜书习题3.3Python编程实现对数几率回归
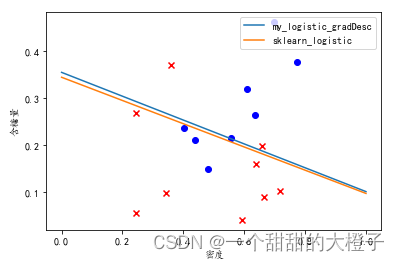
参考代码 结合自己的理解,添加注释。 代码 导入相关的库 import numpy as np import pandas as pd import matplotlib from matplotlib import pyplot as plt from sklearn import linear_model导入数据,进行数据处理和特征工程 # 1.数据处理&#x…...
Blazor前后端框架Known-V1.2.9
V1.2.9 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行。 Gitee: https://gitee.com/known/KnownGithub:https://github.com/known/Known 概述 基于C#和Blazor…...

【3D捏脸功能实现】
文章目录 一、技术方案介绍二、技术核心三、底层技术实现选型进行模型建模编写逻辑代码 四、功能落地五、总结 一、技术方案介绍 3D捏脸功能是一种利用3D技术实现用户自定义头像的功能。通常实现这种功能需要以下技术: 3D建模技术。通过3D建模技术可以创建一个可以…...
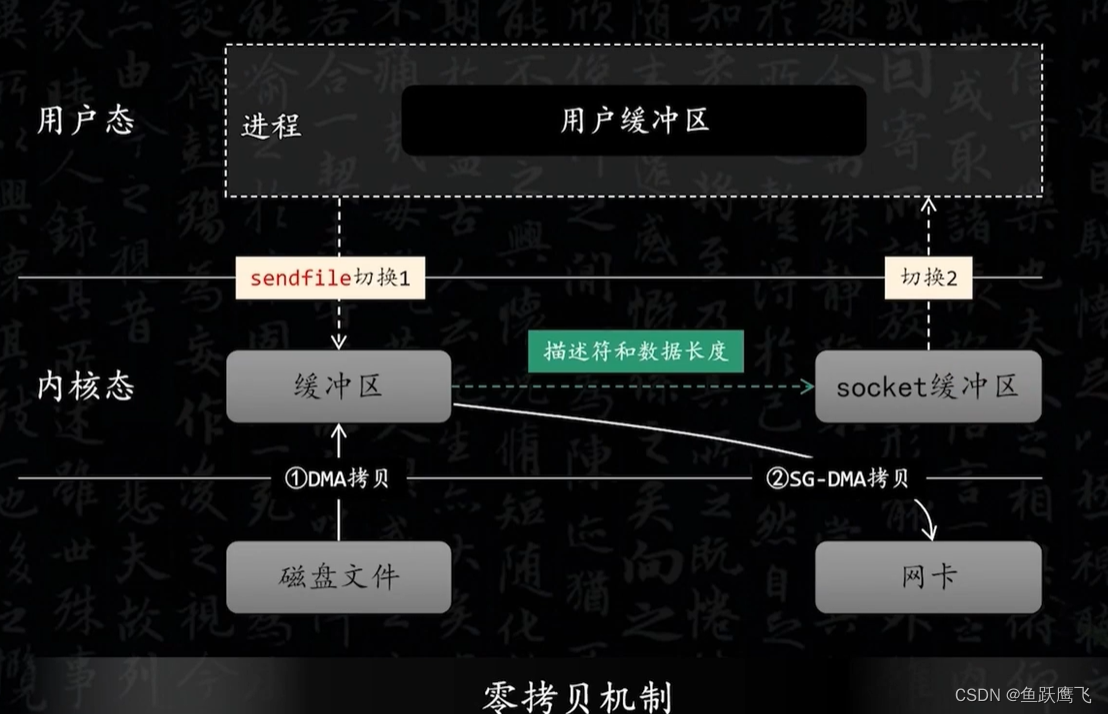
Kafka的零拷贝
传统的IO模型 如果要把磁盘中的某个文件发送到远程服务器需要经历以下几个步骤 (1) 从磁盘中读取文件的内容,然后拷贝到内核缓冲区 (2) CPU把内核缓冲区的数据赋值到用户空间的缓冲区 (3) 在用户程序中调用write方法,把用户缓冲区的数据拷贝到内核下面…...

如何使用Python进行数据分析?
Python是一个非常流行的编程语言,也是数据科学家和数据分析师最常用的语言之一。 Python的生态系统非常丰富,有很多强大的库和工具可以用来进行数据分析,如NumPy、Pandas、Matplotlib、SciPy等。 Python教程,8天python从入门到精…...

概率论与数理统计复习总结3
概率论与数理统计复习总结,仅供笔者复习使用,参考教材: 《概率论与数理统计》/ 荣腾中主编. — 第 2 版. 高等教育出版社《2024高途考研数学——概率基础精讲》王喆 概率论与数理统计实际上是两个互补的分支:概率论 在 已知随机…...

PHP正则绕过解析
正则绕过 正则表达式PHP正则回溯PHP中的NULL和false回溯案例案例1案例2 正则表达式 在正则中有许多特殊的字符,不能直接使用,需要使用转义符\。如:$,(,),*,,.,?,[,,^,{。 这里大家会有疑问:为啥小括号(),这个就需要两个来转义&a…...

Hive巡检脚本
Hive巡检脚本的示例: #!/bin/bash# 设置Hive连接信息 HIVE_HOST"your_hive_host" HIVE_PORT"your_hive_port" HIVE_USER"your_hive_username" HIVE_PASSWORD"your_hive_password"# 设置巡检结果输出文件路径 OUTPUT_FILE&…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

CANN-昇腾NPU-RAG推理-检索增强生成怎么部署
RAG(Retrieval-Augmented Generation)是 LLM 知识库的组合:先检索相关文档,再让 LLM 基于文档回答。昇腾NPU 上部署 RAG 需要两个组件:Embedding 模型(做向量检索)和 LLM(做生成&am…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

Jetson Orin上TVA模型DLA精准卸载配置
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...