分布式应用:ELFK集群部署
目录
一、理论
1.ELFK集群
2.filebeat
3.部署ELK集群
二、实验
1. ELFK集群部署
三、总结
一、理论
1.ELFK集群
(1)概念
ELFK集群部署(Filebeat+ELK),ELFK= ES + logstash+filebeat+kibana 。
数据流
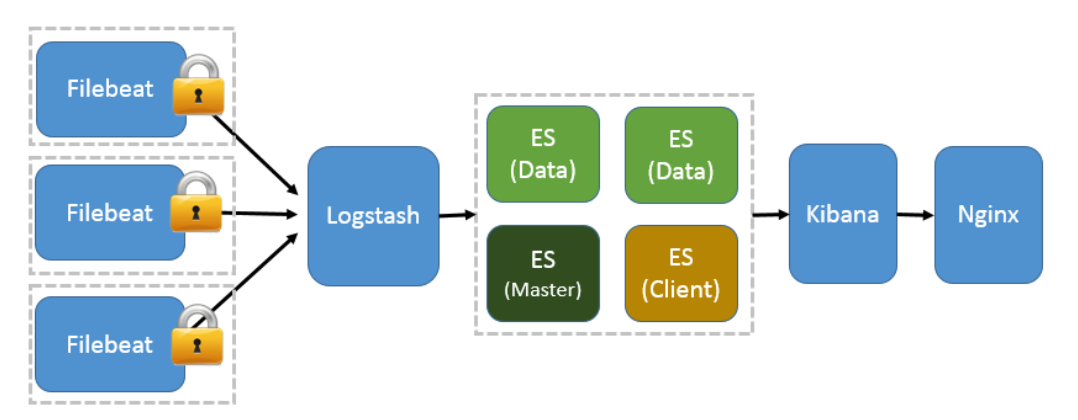
架构
2.filebeat
(1)filebeat和beats的关系
首先filebeat是Beats中的一员。
Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
目前Beats包含六种工具:
Packetbeat:网络数据(收集网络流量数据)
Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
Filebeat:日志文件(收集文件数据)
Winlogbeat:windows事件日志(收集Windows事件日志数据)
Auditbeat:审计数据(收集审计日志)
Heartbeat:运行时间监控(收集系统运行时的数据)
(2)filebeat简介
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
工作的流程图如下: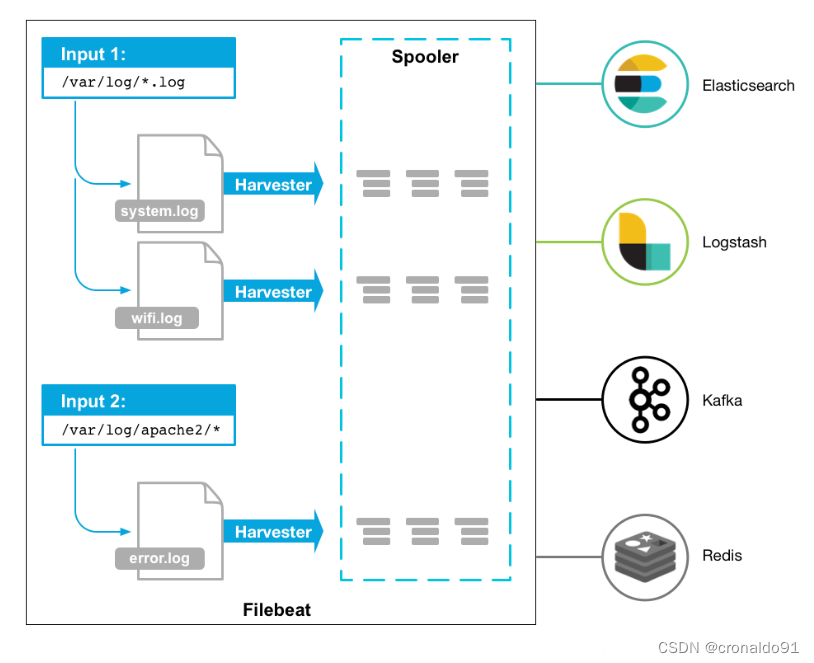
(3)filebeat和logstash的关系
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,加入http://elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。
(4)filebeat的构成
filebeat结构:由两个组件构成,分别是inputs(输入)和harvesters(收集器),这些组件一起工作来跟踪文件并将事件数据发送到您指定的输出,harvester负责读取单个文件的内容。harvester逐行读取每个文件,并将内容发送到输出。为每个文件启动一个harvester。harvester负责打开和关闭文件,这意味着文件描述符在harvester运行时保持打开状态。如果在收集文件时删除或重命名文件,Filebeat将继续读取该文件。这样做的副作用是,磁盘上的空间一直保留到harvester关闭。默认情况下,Filebeat保持文件打开,直到达到close_inactive
关闭harvester可以会产生的结果:
文件处理程序关闭,如果harvester仍在读取文件时被删除,则释放底层资源。
只有在scan_frequency结束之后,才会再次启动文件的收集。
如果该文件在harvester关闭时被移动或删除,该文件的收集将不会继续
一个input负责管理harvesters和寻找所有来源读取。如果input类型是log,则input将查找驱动器上与定义的路径匹配的所有文件,并为每个文件启动一个harvester。每个input在它自己的Go进程中运行,Filebeat当前支持多种输入类型。每个输入类型可以定义多次。日志输入检查每个文件,以查看是否需要启动harvester、是否已经在运行harvester或是否可以忽略该文件。
(5)filebeat如何保存文件的状态
Filebeat保留每个文件的状态,并经常将状态刷新到磁盘中的注册表文件中。该状态用于记住harvester读取的最后一个偏移量,并确保发送所有日志行。如果无法访问输出(如Elasticsearch或Logstash),Filebeat将跟踪最后发送的行,并在输出再次可用时继续读取文件。当Filebeat运行时,每个输入的状态信息也保存在内存中。当Filebeat重新启动时,来自注册表文件的数据用于重建状态,Filebeat在最后一个已知位置继续每个harvester。对于每个输入,Filebeat都会保留它找到的每个文件的状态。由于文件可以重命名或移动,文件名和路径不足以标识文件。对于每个文件,Filebeat存储唯一的标识符,以检测文件是否以前被捕获。
(6)filebeat何如保证至少一次数据消费
Filebeat保证事件将至少传递到配置的输出一次,并且不会丢失数据。是因为它将每个事件的传递状态存储在注册表文件中。在已定义的输出被阻止且未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到输出确认已接收到事件为止。如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有事件后再关闭。当Filebeat重新启动时,将再次将Filebeat关闭前未确认的所有事件发送到输出。这样可以确保每个事件至少发送一次,但最终可能会有重复的事件发送到输出。通过设置shutdown_timeout选项,可以将Filebeat配置为在关机前等待特定时间
(7)输入输出
支持的输入组件:
Multilinemessages,Azureeventhub,CloudFoundry,Container,Docker,GooglePub/Sub,HTTPJSON,Kafka,Log,MQTT,NetFlow,Office365ManagementActivityAPI,Redis,s3,Stdin,Syslog,TCP,UDP(最常用的额就是log)
支持的输出组件:
Elasticsearch,Logstash,Kafka,Redis,File,Console,ElasticCloud,Changetheoutputcodec(最常用的就是Elasticsearch,Logstash)
(8)keystore的使用
keystore主要是防止敏感信息被泄露,比如密码等,像ES的密码,这里可以生成一个key为ES_PWD,值为es的password的一个对应关系,在使用es的密码的时候就可以使用${ES_PWD}使用
创建一个存储密码的keystore:filebeat keystore create
然后往其中添加键值对,例如:filebeatk eystore add ES_PWD
使用覆盖原来键的值:filebeat key store add ES_PWD–force
删除键值对:filebeat key store remove ES_PWD
查看已有的键值对:filebeat key store list
(8)filebeat.yml配置(log输入类型为例)
详情见官网:Log input | Filebeat Reference [8.9] | Elastic
type: log #input类型为log
enable: true #表示是该log类型配置生效
paths: #指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
- /var/log/* /*.log #则只会去/var/log目录的所有子目录中寻找以".log"结尾的文件,而不会寻找/var/log目录下以".log"结尾的文件。
recursive_glob.enabled: #启用全局递归模式,例如/foo/**包括/foo, /foo/*, /foo/*/*
encoding:#指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的
exclude_lines: ['^DBG'] #不包含匹配正则的行
include_lines: ['^ERR', '^WARN'] #包含匹配正则的行
harvester_buffer_size: 16384 #每个harvester在获取文件时使用的缓冲区的字节大小
max_bytes: 10485760 #单个日志消息可以拥有的最大字节数。max_bytes之后的所有字节都被丢弃而不发送。默认值为10MB (10485760)
exclude_files: ['\.gz$'] #用于匹配希望Filebeat忽略的文件的正则表达式列表
ingore_older: 0 #默认为0,表示禁用,可以配置2h,2m等,注意ignore_older必须大于close_inactive的值.表示忽略超过设置值未更新的
文件或者文件从来没有被harvester收集
close_* #close_ *配置选项用于在特定标准或时间之后关闭harvester。 关闭harvester意味着关闭文件处理程序。 如果在harvester关闭
后文件被更新,则在scan_frequency过后,文件将被重新拾取。 但是,如果在harvester关闭时移动或删除文件,Filebeat将无法再次接收文件
,并且harvester未读取的任何数据都将丢失。
close_inactive #启动选项时,如果在制定时间没有被读取,将关闭文件句柄
读取的最后一条日志定义为下一次读取的起始点,而不是基于文件的修改时间
如果关闭的文件发生变化,一个新的harverster将在scan_frequency运行后被启动
建议至少设置一个大于读取日志频率的值,配置多个prospector来实现针对不同更新速度的日志文件
使用内部时间戳机制,来反映记录日志的读取,每次读取到最后一行日志时开始倒计时使用2h 5m 来表示
close_rename #当选项启动,如果文件被重命名和移动,filebeat关闭文件的处理读取
close_removed #当选项启动,文件被删除时,filebeat关闭文件的处理读取这个选项启动后,必须启动clean_removed
close_eof #适合只写一次日志的文件,然后filebeat关闭文件的处理读取
close_timeout #当选项启动时,filebeat会给每个harvester设置预定义时间,不管这个文件是否被读取,达到设定时间后,将被关闭
close_timeout 不能等于ignore_older,会导致文件更新时,不会被读取如果output一直没有输出日志事件,这个timeout是不会被启动的,
至少要要有一个事件发送,然后haverter将被关闭
设置0 表示不启动
clean_inactived #从注册表文件中删除先前收获的文件的状态
设置必须大于ignore_older+scan_frequency,以确保在文件仍在收集时没有删除任何状态
配置选项有助于减小注册表文件的大小,特别是如果每天都生成大量的新文件
此配置选项也可用于防止在Linux上重用inode的Filebeat问题
clean_removed #启动选项后,如果文件在磁盘上找不到,将从注册表中清除filebeat
如果关闭close removed 必须关闭clean removed
scan_frequency #prospector检查指定用于收获的路径中的新文件的频率,默认10s
tail_files:#如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,
而不是从文件开始处重新发送所有内容。
symlinks:#符号链接选项允许Filebeat除常规文件外,可以收集符号链接。收集符号链接时,即使报告了符号链接的路径,
Filebeat也会打开并读取原始文件。
backoff: #backoff选项指定Filebeat如何积极地抓取新文件进行更新。默认1s,backoff选项定义Filebeat在达到EOF之后
再次检查文件之间等待的时间。
max_backoff: #在达到EOF之后再次检查文件之前Filebeat等待的最长时间
backoff_factor: #指定backoff尝试等待时间几次,默认是2
harvester_limit:#harvester_limit选项限制一个prospector并行启动的harvester数量,直接影响文件打开数tags #列表中添加标签,用过过滤,例如:tags: ["json"]
fields #可选字段,选择额外的字段进行输出可以是标量值,元组,字典等嵌套类型
默认在sub-dictionary位置
filebeat.inputs:
fields:
app_id: query_engine_12
fields_under_root #如果值为ture,那么fields存储在输出文档的顶级位置multiline.pattern #必须匹配的regexp模式
multiline.negate #定义上面的模式匹配条件的动作是 否定的,默认是false
假如模式匹配条件'^b',默认是false模式,表示讲按照模式匹配进行匹配 将不是以b开头的日志行进行合并
如果是true,表示将不以b开头的日志行进行合并
multiline.match # 指定Filebeat如何将匹配行组合成事件,在之前或者之后,取决于上面所指定的negate
multiline.max_lines #可以组合成一个事件的最大行数,超过将丢弃,默认500
multiline.timeout #定义超时时间,如果开始一个新的事件在超时时间内没有发现匹配,也将发送日志,默认是5smax_procs #设置可以同时执行的最大CPU数。默认值为系统中可用的逻辑CPU的数量。name #为该filebeat指定名字,默认为主机的hostname3.部署ELK集群
(1)环境
| 节点 | IP地址 | 安装服务 |
| node1节点 | 192.168.204.51 | JDK、elasticsearch-5.5.0、node-v8.2.1、phantomjs-2.1.1、elasticsearch-head、kibana-5.5.1 |
| node2节点 | 192.168.204.52 | JDK、elasticsearch-5.5.0、node-v8.2.1、phantomjs-2.1.1、elasticsearch-head、 |
| apache节点 | 192.168.204.53 | JDK、apache、logstash-5.5.1、filebeat-6.2.1 |
(2)安装 Filebeat(在apache节点操作)
#上传软件包 filebeat-6.2.4-linux-x86_64.tar.gz 到/opt目录tar zxvf filebeat-6.2.4-linux-x86_64.tar.gzmv filebeat-6.2.4-linux-x86_64/ /usr/local/filebeat
(3) 设置 filebeat 的主配置文件
cd /usr/local/filebeatvim filebeat.ymlfilebeat.prospectors:- type: log #指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/messages #指定监控的日志文件- /var/log/*.logtags: ["sys"] #设置索引标签fields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: filebeatlog_type: syslogfrom: 192.168.80.13--------------Elasticsearch output-------------------(全部注释掉)----------------Logstash output---------------------output.logstash:hosts: ["192.168.204.53:5044"] #指定 logstash 的 IP 和端口#启动 filebeatnohup ./filebeat -e -c filebeat.yml > filebeat.out &#-e:输出到标准输出,禁用syslog/文件输出#-c:指定配置文件#nohup:在系统后台不挂断地运行命令,退出终端不会影响程序的运行
(4) 在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.dvim filebeat.confinput {beats {port => "5044"}}output {elasticsearch {hosts => ["192.168.204.51:9200","192.168.204.52:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}}#启动 logstashlogstash -f filebeat.conf
(5)浏览器访问
浏览器访问 http://192.168.204.51:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
4.Logstash的过滤模块
(1)Logstash配置文件中的模块
① input {}
指定输入流,通过file、beats、kafka、redis中获取数据
② filter {}
常用插件:
grok:对若干个大文本字段进行再分割,分割成一些小字段 (?<字段名>正则表达式) 字段名:正则表示匹配到的内容
date:对数据中的时间进行统一格式化
mutate:对一些无用的字段进行剔除,或增加字段
mutiline:对多行数据进行统一编排,多行合并和拆分
③ ourput {}
elasticsearch stdout
(2)Filter(过滤模块)中的插件
而对于 Logstash 的 Filter,这个才是 Logstash 最强大的地方。Filter 插件也非常多,我们常用到的 grok、date、mutate、mutiline 四个插件。
对于 filter 的各个插件执行流程,可以看下面这张图:
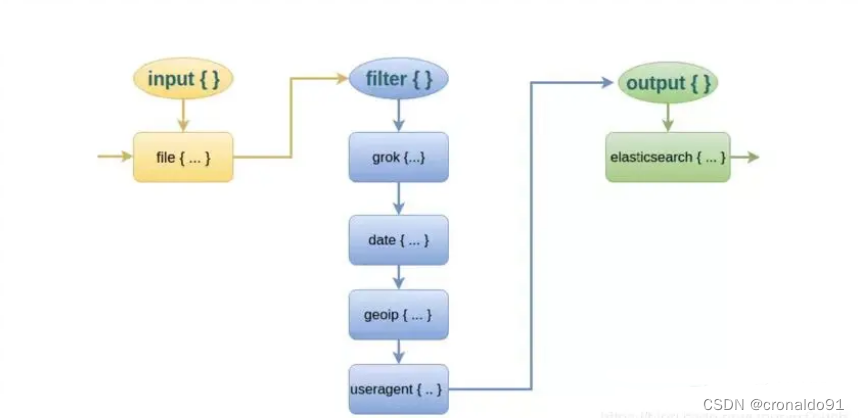
grok插件(通过grok插件实现对字段的分割,使用通配符)
这里就要用到 logstash 的 filter 中的 grok 插件。filebeat 发送给 logstash 的日志内容会放到message 字段里面,logstash 匹配这个 message 字段就可以了。
格式:
匹配格式:(?<字段名>正则表达式)# 字段名:正则表达式匹配到的内容
实例:
实例1:(?<remote_addr>%{IPV6}|%{IPV4} )(?<other_info>.+)#对数据进行分割ip字段名为remote_addr, 其他字段名为other_info实例2:(?<remote_addr>%{IPV6}|%{IPV4} )[\s-]+[(?<log_time>.+)](?<other_info>.+)#添加匹配时间字段实例3:#分割多个字段(?<remote_addr>%{IPV6}|%{IPV4})[\s-]+[(?<log_time>.+)]\s+"(?<http_method>\S+)\s+(?<url-path>.+)"\s+(?<rev_code>\d+)(?<other_info>.+)实例4:cd /etc/logstash/conf.d/cp filebeat.conf filter.confvim filter.confinput {beats {port => "5044"}}filter {grok {match =>["message","(?<remote_addr>%{IPV6}|%{IPV4} )[\s-]+[(?<log_time>.+)]\s+"(?<http_method>\S+)\s+(?<url-path>.+)"\s+(?<rev_code>\d+)(?<other_info>.+)"]}}output {elasticsearch {hosts => ["192.168.239.10:9200","192.168.239.20:9200"]index => "{[filter][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}}logstash -f filter.conf #启动
二、实验
1. ELFK集群部署
(1)已部署ELK群集
(2)安装 Filebeat(在apache节点操作)


(3)设置 filebeat 的主配置文件

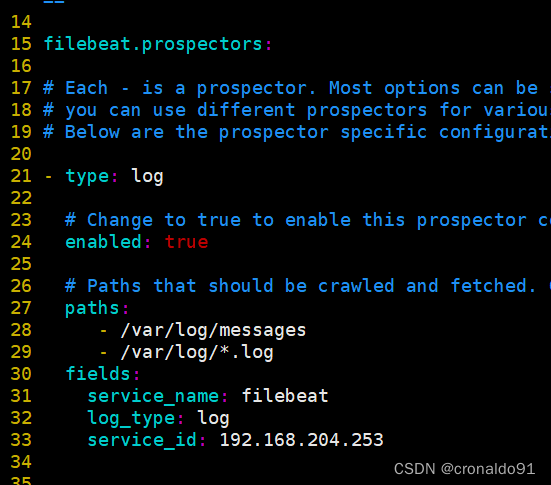
全部注释
 指定 logstash 的 IP 和端口
指定 logstash 的 IP 和端口
(4)在 Logstash 组件所在节点上新建一个 Logstash 配置文件

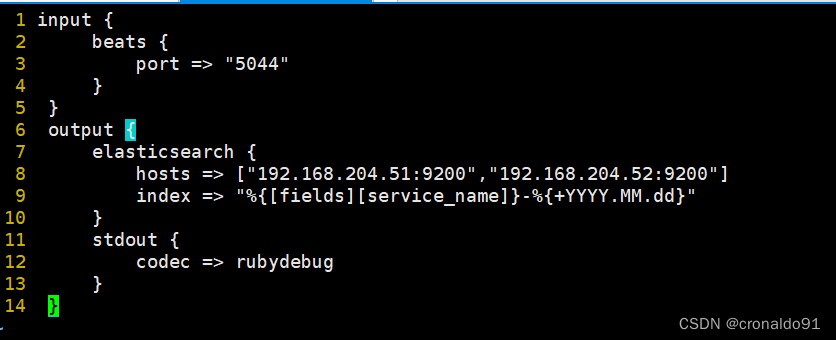
启动 logstash
(5)浏览器访问
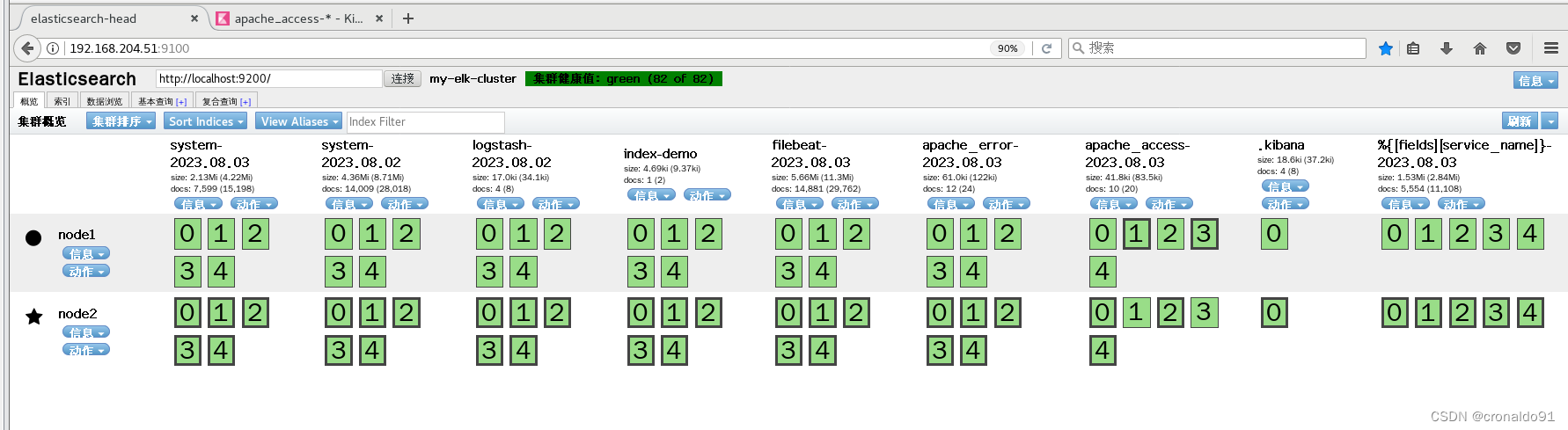
浏览器访问 http://192.168.204.51:9100
浏览器访问 http://192.168.204.51:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建

单击 “Discover” 按钮可查看图表信息及日志信息。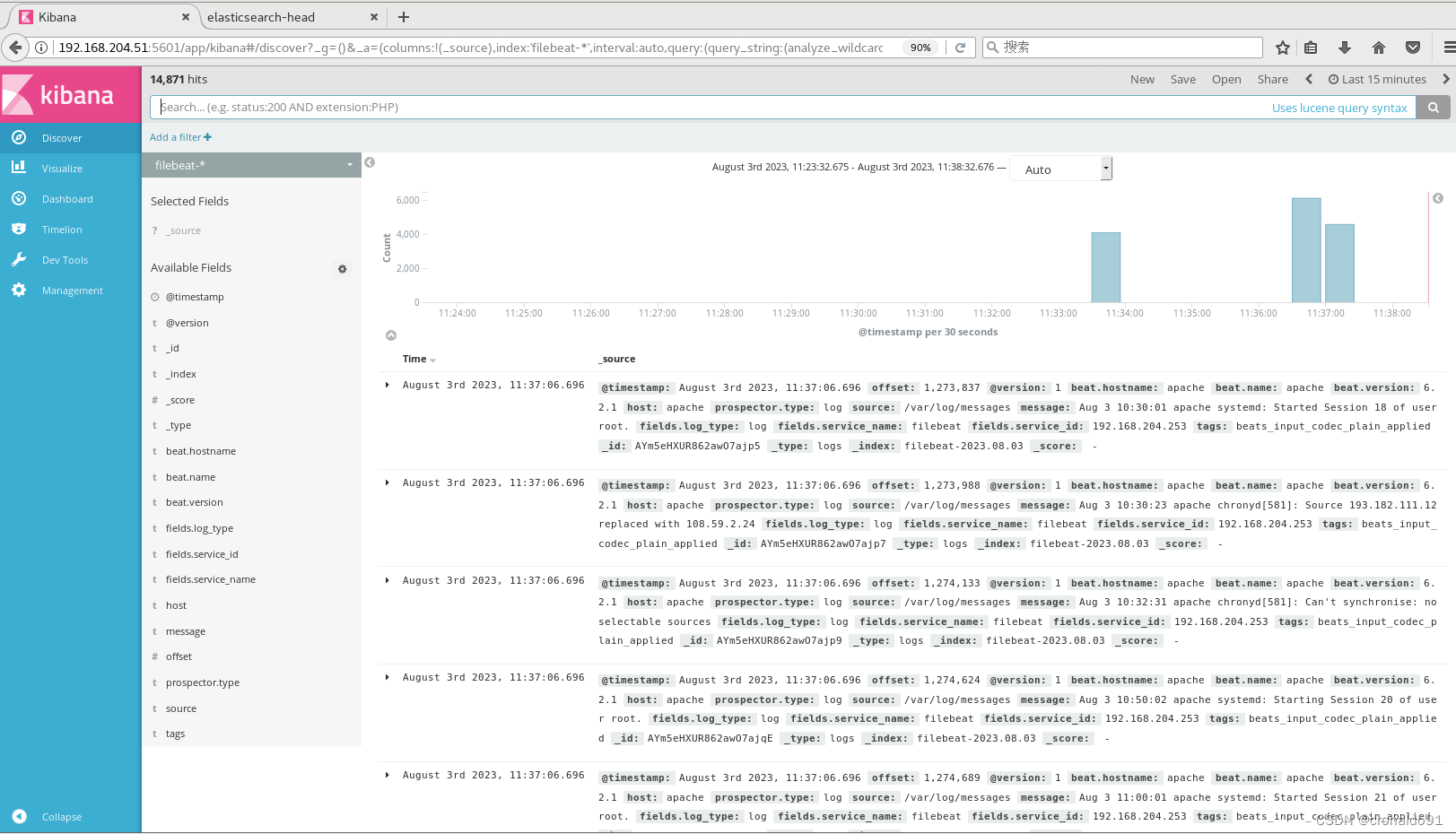
三、总结
ELFK集群环境下,Logstash 组件所在节点的/etc/logstash/conf.d目录下,不需要创建system.conf配置文件,即Logstash不需要收集系统日志,因为系统日志将由filebeat收集后发送给Logstash。(安装filebeat后,Logstash会创建filebeat.conf配置文件获取filebeat传来的数据)。
filebeat配置
cd /usr/local/filebeatvim filebeat.ymlfilebeat基本命令
#启动 filebeatnohup ./filebeat -e -c filebeat.yml > filebeat.out &#-e:输出到标准输出,禁用syslog/文件输出#-c:指定配置文件#nohup:在系统后台不挂断地运行命令,退出终端不会影响程序的运行export #导出
run #执行(默认执行)
test #测试配置
keystore #秘钥存储
modules #模块配置管理
setup #设置初始环境相关文章:
分布式应用:ELFK集群部署
目录 一、理论 1.ELFK集群 2.filebeat 3.部署ELK集群 二、实验 1. ELFK集群部署 三、总结 一、理论 1.ELFK集群 (1)概念 ELFK集群部署(FilebeatELK),ELFK ES logstashfilebeatkibana 。 数据流 架构 2.fi…...
Quartz使用文档,使用Quartz实现动态任务,Spring集成Quartz,Quartz集群部署,Quartz源码分析
文章目录 一、Quartz 基本介绍二、Quartz Java 编程1、文档2、引入依赖3、入门案例4、默认配置文件 三、Quartz 重要组件1、Quartz架构体系2、JobDetail3、Trigger(1)代码实例(2)SimpleTrigger(3)CalendarI…...

Go -- 测试 and 项目实战
没有后端基础,学起来真是费劲,所以打算速刷一下,代码跟着敲一遍,有个印象,大项目肯定也做不了了,先把该学的学了,有空就跟点单体项目,还有该看的书.... 目录 🍌单元测试…...

GitHub基本使用
GitHub搜索 直接搜索 直接搜索关键字 明确搜索仓库标题 语法:in:name [关键词]展示:比如我们想在GitHub仓库中标题中搜索带有SpringBoot关键词的,我们可以样搜: in:name SpringBoot 明确搜索描述 语法:in:description [关键词]展…...
微信小程序生成带参数的二维码base64转png显示
getQRCode() {var that this;wx.request({url: http://localhost:8080/getQRCode?ID 13,header: {content-type: application/json},method: POST,responseType: arraybuffer,//将原本按文本解析修改为arraybuffersuccess(res) {that.setData({getQRCode: wx.arrayBufferToB…...

量子计算机:下一代计算技术的奇点
介绍 量子计算机是一种基于量子力学原理的全新计算技术,它利用量子比特的特性进行计算,具有破解当前经典计算机难以解决问题的潜力。在过去几十年里,量子计算机一直是计算机科学领域的一个热门话题。本篇博客将深入探讨量子计算机的基本原理…...

【ChatGPT】ChatGPT是如何训练得到的?
前言 ChatGPT是一种基于语言模型的聊天机器人,它使用了GPT(Generative Pre-trained Transformer)的深度学习架构来生成与用户的对话。GPT是一种使用Transformer编码器和解码器的预训练模型,它已被广泛用于生成自然语言文本的各种…...

Docker设置代理、Linux系统设置代理
使用方式 新建或修改~/.docker/config.json文件,设置可用的代理地址。 {"proxies": {"default": {"httpProxy": "http://192.168.0.32:1080","httpsProxy": "http://192.168.0.32:1080","noPro…...

C# 进程
C# 进程 进程的命名空间是: using System.Diagnostics;1.获取当前计算机正在运行所有的进程 Process[] processes Process.GetProcesses(); for (int i 0; i < processes.Length; i) {Console.WriteLine(processes[i]); } Console.ReadKey();2.通过进程打开…...
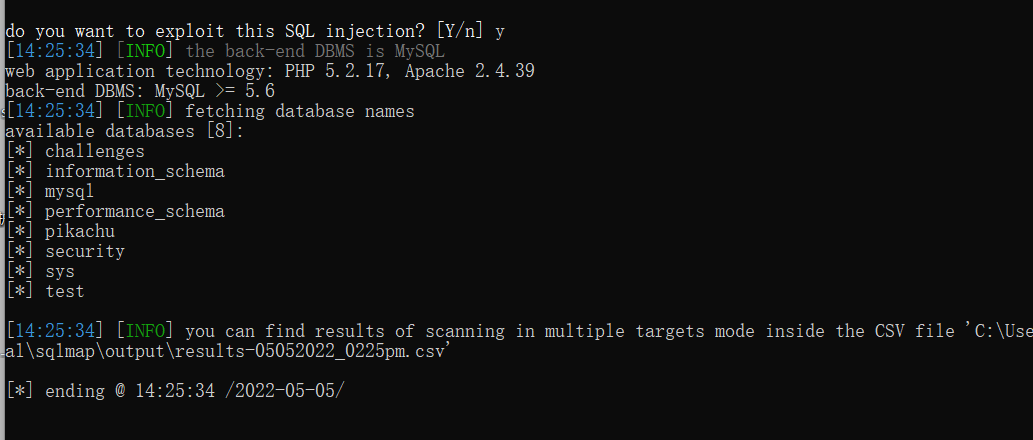
SQL注入之sqlmap
SQL注入之sqlmap 6.1 SQL注入之sqlmap安装 sqlmap简介: sqlmap是一个自动化的SQL注入工具,其主要功能是扫描,发现并利用给定的URL的SQL注入漏洞,目前支持的数据库是MS-SQL,MYSQL,ORACLE和POSTGRESQL。SQLMAP采用四种独特的SQL注…...

Flutter 命名路由
我们可以通过创建一个新的Route,使用Navigator来导航到一个新的页面,但是如果在应用中很多地方都需要导航到同一个页面(比如在开发中,首页、推荐、分类页都可能会跳到详情页),那么就会存在很多重复的代码。…...

Stephen Wolfram:神经网络
Neural Nets 神经网络 OK, so how do our typical models for tasks like image recognition actually work? The most popular—and successful—current approach uses neural nets. Invented—in a form remarkably close to their use today—in the 1940s, neural nets …...
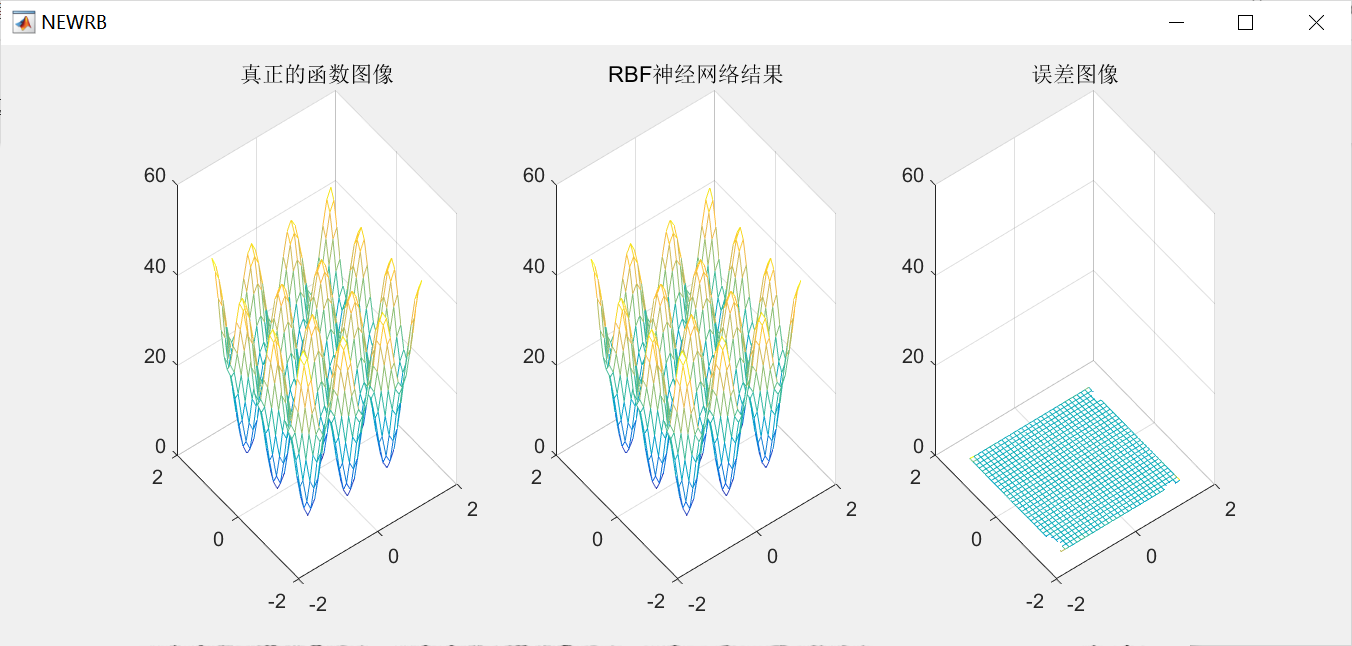
RBF神经网络原理和matlab实现
1.案例背景 1.1 RBF神经网络概述 径向基函数(Radical Basis Function,RBF)是多维空间插值的传统技术,由Powell于1985年提出。1988年, Broomhead和 Lowe根据生物神经元具有局部响应这一特点,将 RBF引入神经网络设计中,产生了RBF神经网络。1989 年,Jackson论证了…...
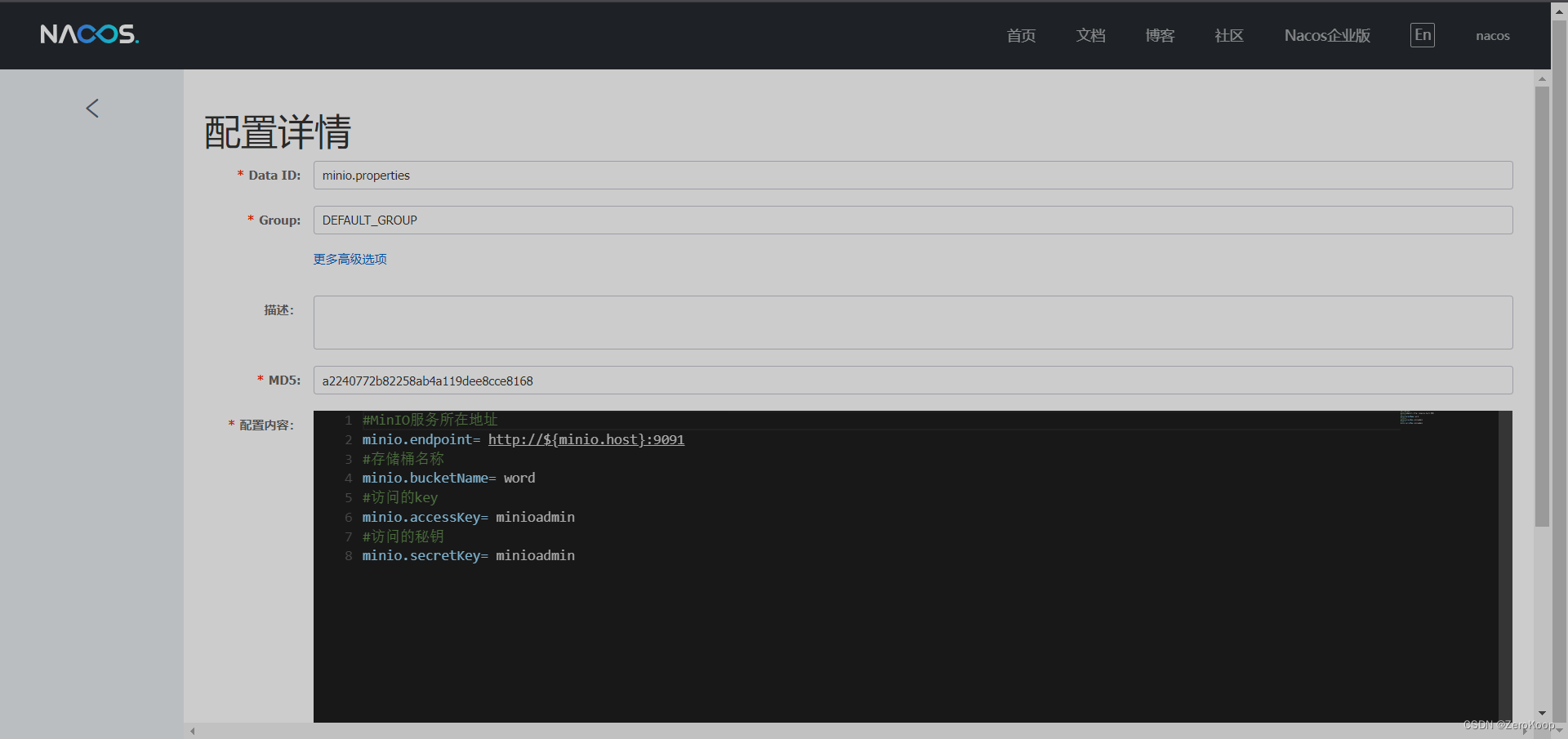
Nacos 抽取公共配置
文章目录 创建一个公共配置文件其他配置文件引用springboot配置文件 创建一个公共配置文件 其他配置文件引用 ${变量} springboot配置文件 spring:cloud:nacos:discovery:server-addr: current.ip:8848namespace: word_register_proconfig:server-addr: current.ip:8848auto-r…...

Promise、Async/Await 详解
一、什么是Promise Promise是抽象异步处理对象以及对其进行各种操作的组件。Promise本身是同步的立即执行函数解决异步回调的问题, 当调用 resolve 或 reject 回调函数进行处理的时候, 是异步操作, 会先执行.then/catch等,当主栈完成后&#…...

PoseiSwap:基于 Nautilus Chain ,构建全新价值体系
在 DeFi Summer 后,以太坊自身的弊端不断凸显,而以 Layer2 的方式为其扩容成为了行业很长一段时间的叙事方向之一。虽然以太坊已经顺利的从 PoW 的 1.0 迈向了 PoS 的 2.0 时代,但以太坊创始人 Vitalik Buterin 表示, Layer2 未来…...

uC-OS2 V2.93 STM32L476 移植:串口打印篇
前言 前几篇已经 通过 STM32CubeMX 搭建了 NUCLEO-L476RG 的 STM32L476RG 的 裸机工程,下载了 uC-OS2 V2.93 的源码,并把 uC-OS2 的源文件加入 Keil MDK5 工程,通过适配 Systick 系统定时器与 PendSV 实现任务调度,初步让 uC-OS2 …...

代码随想录算法训练营第四十六天| 139.单词拆分 背包问题总结
代码随想录算法训练营第四十六天| 139.单词拆分 背包问题总结 一、力扣139.单词拆分 题目链接: 思路:确定dp数组,dp[i]为true表示从0到i切分的字串都在字典中出现过。 确定递推公式,dp[i] 为true要求 s[j, i] 在字典中出现&…...
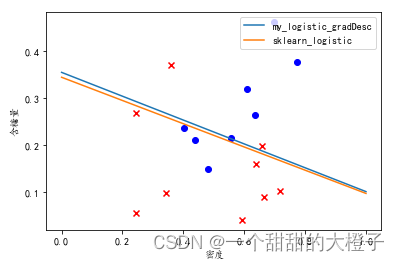
【机器学习】西瓜书习题3.3Python编程实现对数几率回归
参考代码 结合自己的理解,添加注释。 代码 导入相关的库 import numpy as np import pandas as pd import matplotlib from matplotlib import pyplot as plt from sklearn import linear_model导入数据,进行数据处理和特征工程 # 1.数据处理&#x…...
Blazor前后端框架Known-V1.2.9
V1.2.9 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行。 Gitee: https://gitee.com/known/KnownGithub:https://github.com/known/Known 概述 基于C#和Blazor…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...