神经网络的搭建与各层分析
为什么去西藏的人都会感觉很治愈
拉萨的老中医是这么说的
缺氧脑子短路,很多事想不起来,就会感觉很幸福
一、卷积层
解释:卷积层通过卷积操作对输入数据进行处理。它使用一组可学习的滤波器(也称为卷积核或特征检测器),将滤波器与输入数据进行逐元素的乘法累加操作,从而生成输出特征图。这种滤波器的操作类似于图像处理中的卷积操作,因此得名卷积层。
主要作用:
-
特征提取:卷积层通过滤波器的卷积操作,可以有效地提取输入数据中的局部特征。滤波器可以学习到不同的特征,例如边缘、纹理、形状等,这些特征对于图像识别和分类等任务非常重要。
-
参数共享:卷积层的滤波器在整个输入数据上共享参数。这意味着在不同位置上使用相同的滤波器,从而减少了需要学习的参数数量。这种参数共享的特性使得卷积层具有一定的平移不变性,即对于输入数据的平移操作具有不变性。
-
减少参数数量:相比全连接层(每个神经元与上一层的所有神经元相连),卷积层的参数数量较少。这是因为卷积层的滤波器在空间上共享参数,并且每个滤波器只与输入数据的局部区域进行卷积操作。这种参数共享和局部连接的方式大大减少了需要学习的参数数量,提高了模型的效率和泛化能力。
-
空间结构保持:卷积层在进行卷积操作时,保持了输入数据的空间结构。这意味着输出特征图的每个元素对应于输入数据的相应局部区域,从而保留了输入数据的空间信息。这对于图像处理任务非常重要,因为图像中的相邻像素之间存在一定的关联性。
使用示例:

代码示例:
import torch
import torch.nn.functional as F# 模拟图像
input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])
# 模拟卷积核
kernal = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])# 参数结构转化
input = torch.reshape(input, (1, 1, 5, 5))
kernal = torch.reshape(kernal, (1, 1, 3, 3))print(input.shape)
print(kernal.shape)# 输入经过卷积操作
output = F.conv2d(input, kernal, stride=2, padding=1)
print(output)输出
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[ 1, 4, 8],[ 7, 16, 8],[14, 9, 4]]]])图片数据集经过卷积层输出:
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.nn import Conv2d
from torch import nn
from torch.utils.tensorboard import SummaryWriter# 加载数据集并加载到神经网络中
dataset = torchvision.datasets.CIFAR10("./cifar10", train=False, transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset, batch_size=64)class Lh(nn.Module):def __init__(self):super(Lh, self).__init__()self.conv1 = Conv2d(3, 6, 3, 1)def forward(self, x):x = self.conv1(x)return xlh = Lh()writer = SummaryWriter("logs")
step = 0
for data in dataloader:imgs, targets = dataoutput = lh(imgs)writer.add_images("input", imgs, step)output = torch.reshape(output, (-1, 3, 30, 30))writer.add_images("output", output, step)step += 1
通过tensorboard展示

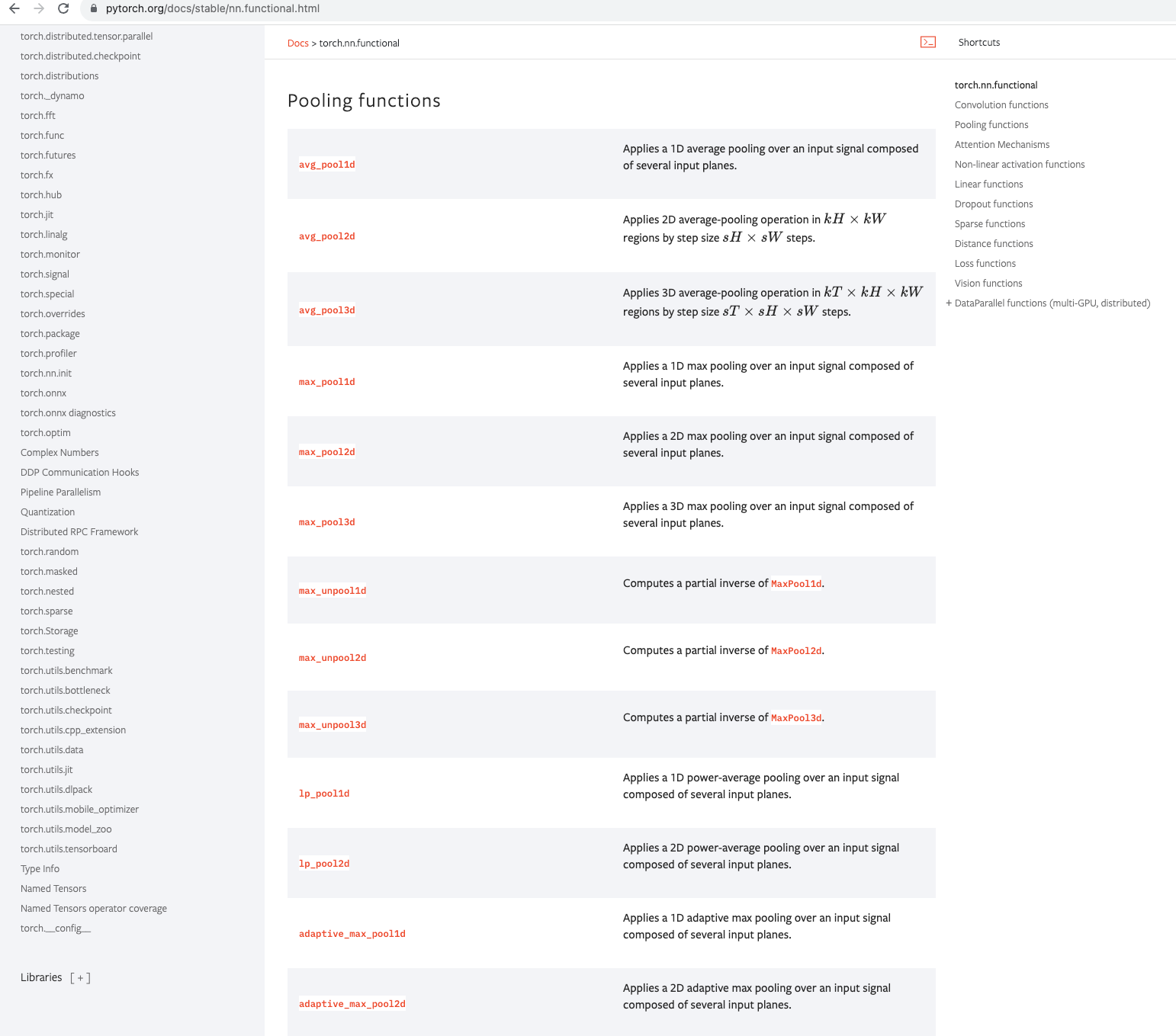
二、最大池化层
解释:它将输入数据划分为不重叠的矩形区域(通常是2x2的窗口),然后在每个区域中选择最大值作为输出。这样,最大池化层通过取每个区域中的最大值来减少数据的维度。
主要作用:
-
特征减少:最大池化层可以减少输入数据的空间尺寸,从而降低了模型的计算复杂度。通过减少特征图的尺寸,最大池化层能够在保留重要特征的同时,减少需要处理的数据量,提高模型的效率。
-
平移不变性:最大池化层具有一定的平移不变性,即对于输入数据的平移操作具有不变性。这是因为在最大池化操作中,只选择每个区域中的最大值,而不考虑其位置信息。这种平移不变性使得神经网络对于输入数据的位置变化具有一定的鲁棒性。
-
特征提取:最大池化层可以帮助提取输入数据中的主要特征。通过选择每个区域中的最大值作为输出,最大池化层能够保留输入数据中的重要特征,并且对于噪声和不重要的细节具有一定的鲁棒性。
最大池化层在神经网络中起到了减少数据维度、提取关键特征和增强模型的鲁棒性等作用(简单来说就是把1080p的视频变成720p的)。它通常与卷积层交替使用,帮助神经网络有效地处理输入数据,提高模型的性能和泛化能力。
使用示例:
import torch
from torch.nn import MaxPool2d
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10('./cifar10', train=False, transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset, 64, False)input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)input = torch.reshape(input, (1, 1, 5, 5))class Lh(nn.Module):def __init__(self):super(Lh, self).__init__()self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):x = self.maxpool(x)return xlh = Lh()writer = SummaryWriter("logs")
step = 0
for data in dataloader:imgs, tagerts = datawriter.add_images("input", imgs, step)output = lh(imgs)writer.add_images("output", output, step)step += 1writer.close()
使用torchboard打卡

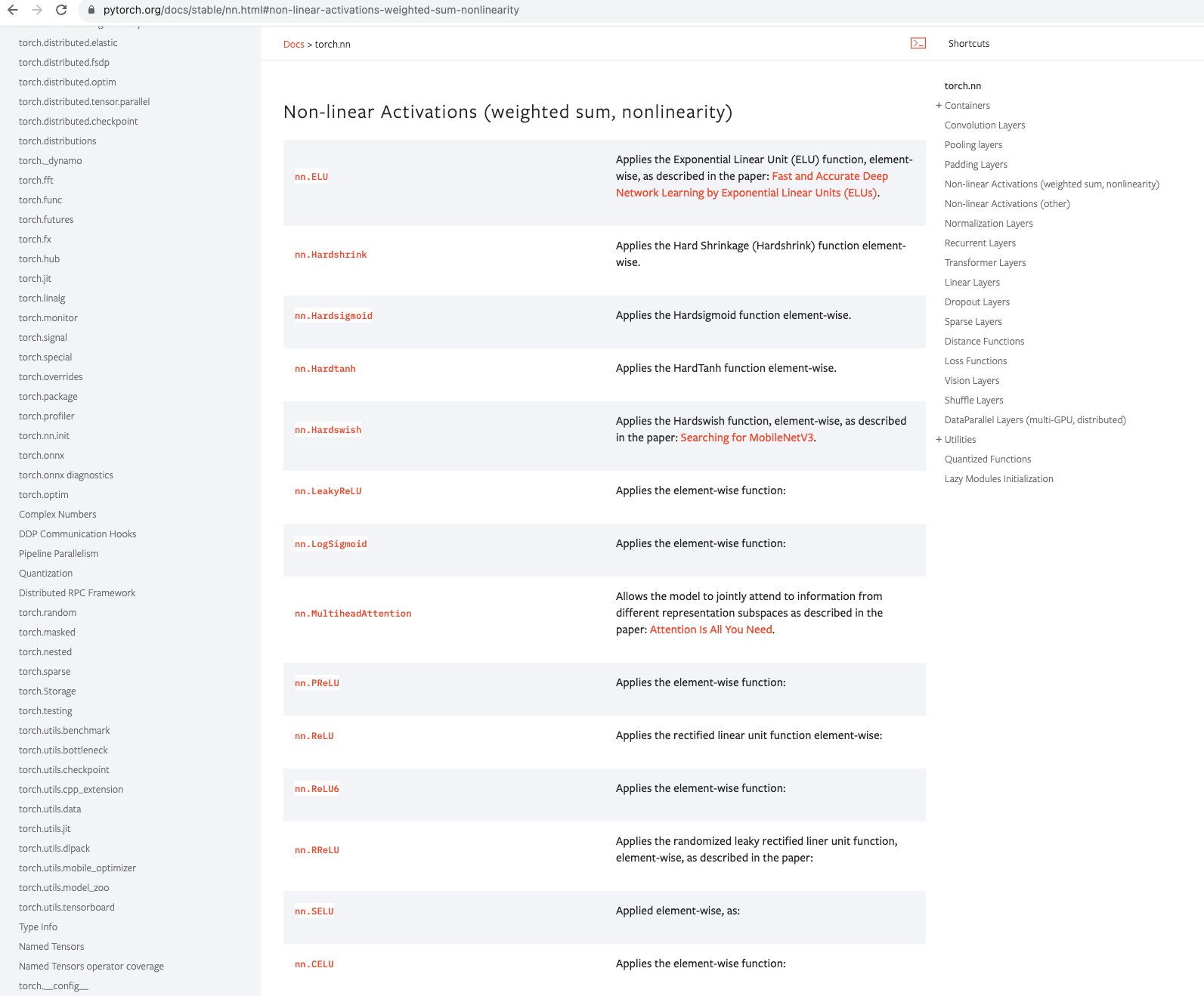
三、非线性激活函数
解释:神经网络的非线性激活函数是在神经网络的每个神经元上引入非线性变换的函数。它的作用是为神经网络引入非线性能力,从而使网络能够学习和表示更加复杂的函数关系。
主要作用:
-
引入非线性:线性变换的组合只能表示线性关系,而神经网络的层级结构和参数学习能力使其具备了更强大的函数逼近能力。非线性激活函数的引入打破了线性关系的限制,使得神经网络可以学习和表示非线性的函数关系,从而更好地适应复杂的数据模式。
-
增强模型的表达能力:非线性激活函数可以增强神经网络的表达能力,使其能够学习和表示更加复杂的特征和模式。通过引入非线性变换,激活函数可以对输入信号进行非线性映射,从而提取和表示更多种类的特征,帮助网络更好地理解输入数据。
-
解决分类问题的非线性可分性:在处理分类问题时,输入数据通常是非线性可分的。非线性激活函数可以帮助神经网络学习并表示类别之间的非线性边界,从而提高分类准确性。例如,常用的激活函数如ReLU、Sigmoid和Tanh等都是非线性的,它们可以帮助神经网络学习并表示复杂的决策边界。
-
缓解梯度消失问题:在深层神经网络中,反向传播算法需要通过链式法则计算梯度并更新参数。线性激活函数(如恒等映射)会导致梯度的乘积变得非常小,从而导致梯度消失问题。而非线性激活函数可以通过引入非线性变换,使得梯度能够在网络中传播并保持较大的幅度,从而缓解了梯度消失问题,有助于更好地训练深层网络。
使用示例:
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterinput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)input = torch.reshape(input, (-1, 1, 5, 5))dataset = torchvision.datasets.CIFAR10("./cifar10", False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, 64)class Lh(nn.Module):def __init__(self):super(Lh, self).__init__()self.relu1 = ReLU()self.sigmoid = Sigmoid()def forward(self, input):return self.sigmoid(input)lh = Lh()step = 0
writer = SummaryWriter("logs")for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, step)output = lh(imgs)writer.add_images("output", output, step)step += 1writer.close()print("end")
使用torchboard打开

四、其它层与神经网络模型
查看pytorch的官方文档可以看到,神经网络中不同层及其使用
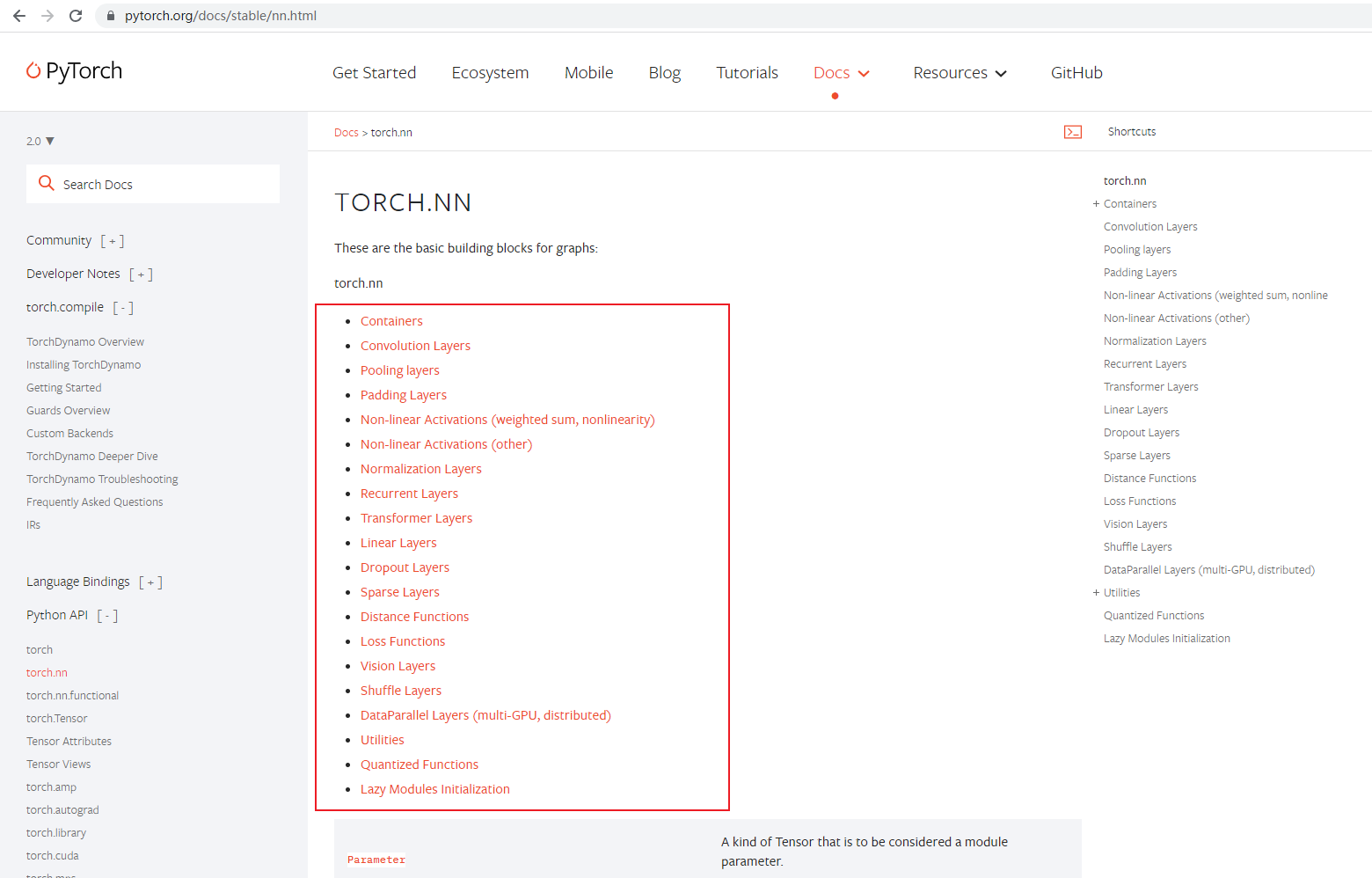
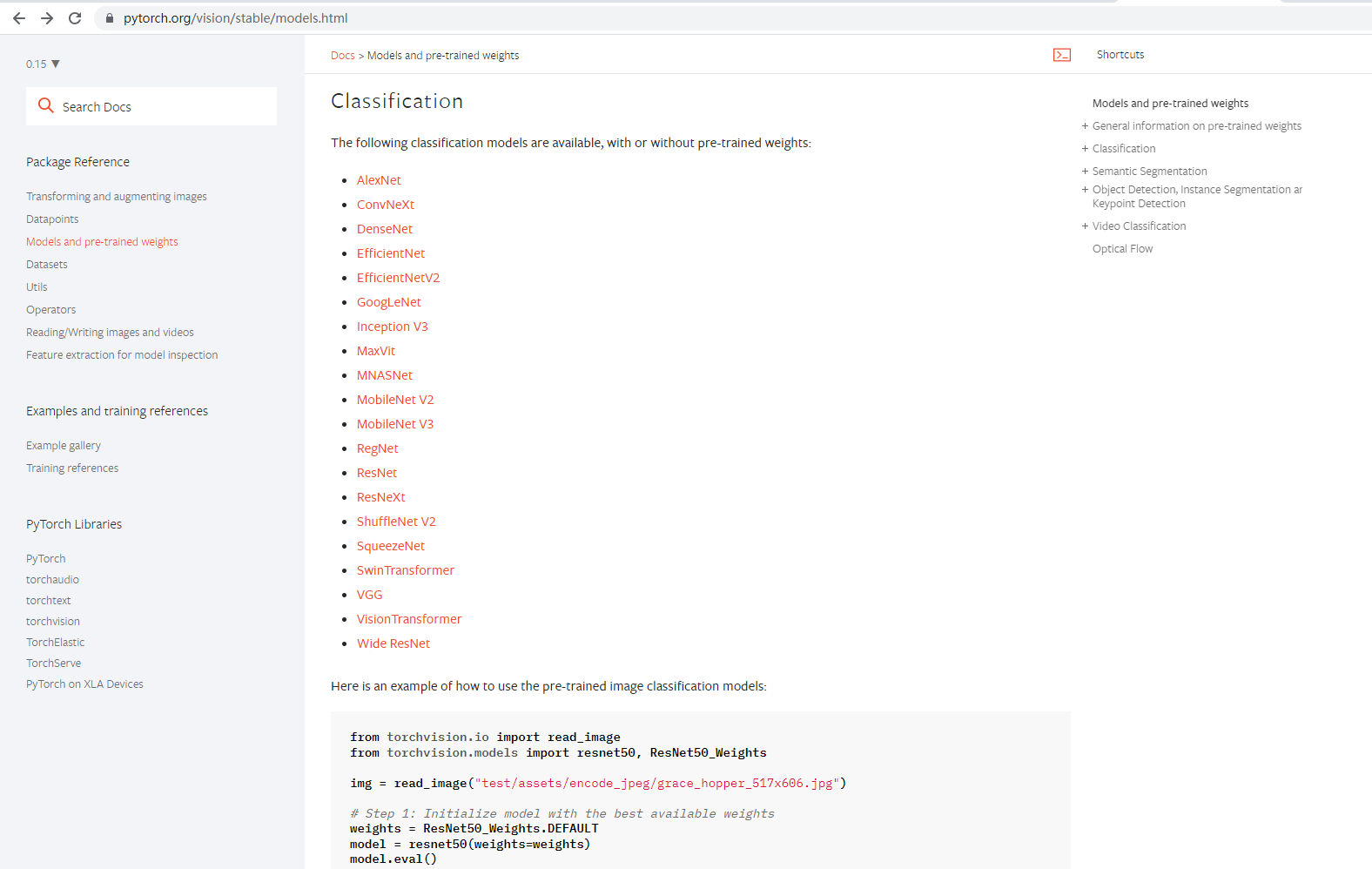
你可以创建自己的神经网络,然后自由搭配里面的网络层进行模型的训练。但是一般情况下我们不用手动去一层一层构建,因为官网提供了很多已经搭配好的神经网络模型,这些模型的训练效果都非常不错,我们只需要选择构建好的模型使用即可。
如 torchvision.models
五、神经网络搭建小实战
crfar10 model structure

根据上图,以input为 3@32 * 32为例,可更据公式计算pandding

代码示例:
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
import torchclass Lh(nn.Module):def __init__(self):super(Lh, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xlh = Lh()
input = torch.ones((64,3,32,32))
print(input.shape)
output = lh(input)
print(output.shape)
可以使用tensorboard绘制神经网络流程图
writer = SummaryWriter('logs')
writer.add_graph(lh, input)
writer.close()六、损失函数
损失函数用于衡量模型的预测输出与真实标签之间的差异,并且在训练过程中用于优化模型的参数。
常用的损失函数及其简单使用方法:
1. 均方误差损失(Mean Squared Error, MSE):
均方误差损失函数用于回归问题,计算预测值与真实值之间的平均平方差。它可以通过torch.nn.MSELoss()来创建。
import torch
import torch.nn as nnloss_fn = nn.MSELoss()predictions = torch.tensor([0.5, 0.8, 1.2])
targets = torch.tensor([1.0, 1.0, 1.0])loss = loss_fn(predictions, targets)
print(loss)
2. 交叉熵损失(Cross Entropy Loss):
交叉熵损失函数常用于分类问题,特别是多分类问题。它计算预测概率分布与真实标签之间的交叉熵。在PyTorch中,可以使用torch.nn.CrossEntropyLoss()来创建交叉熵损失函数。
import torch
import torch.nn as nnloss_fn = nn.CrossEntropyLoss()predictions = torch.tensor([[0.2, 0.3, 0.5], [0.8, 0.1, 0.1]])
targets = torch.tensor([2, 0]) # 真实标签loss = loss_fn(predictions, targets)
print(loss)
3. 二分类交叉熵损失(Binary Cross Entropy Loss):
二分类交叉熵损失函数适用于二分类问题,计算预测概率与真实标签之间的交叉熵。在PyTorch中,可以使用torch.nn.BCELoss()来创建二分类交叉熵损失函数。
import torch
import torch.nn as nnloss_fn = nn.BCELoss()predictions = torch.tensor([0.2, 0.8])
targets = torch.tensor([0.0, 1.0]) # 真实标签loss = loss_fn(predictions, targets)
print(loss)
将损失函数运用到前面的神经网络模型中:
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10('./cifar10', False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)class Lh(nn.Module):def __init__(self):super(Lh, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss()
lh=Lh()
for data in dataloader:imgs, targets = dataoutputs = lh(imgs)result_loss = loss(outputs, targets)result_loss.backward()print(result_loss)
七、优化器
优化器用于更新模型的参数以最小化损失函数。
常用的优化器及其简单使用方法:
1. 随机梯度下降(Stochastic Gradient Descent, SGD):
随机梯度下降是最基本的优化算法之一,它通过计算损失函数关于参数的梯度来更新参数。在PyTorch中,可以使用torch.optim.SGD来创建SGD优化器。
import torch
import torch.optim as optimmodel = MyModel() # 自定义模型optimizer = optim.SGD(model.parameters(), lr=0.01)# 在训练循环中使用优化器
optimizer.zero_grad() # 清零梯度
loss = compute_loss() # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
2. Adam优化器:
Adam是一种自适应学习率优化算法,它结合了动量(momentum)和自适应学习率调整。在PyTorch中,可以使用torch.optim.Adam来创建Adam优化器。
import torch
import torch.optim as optimmodel = MyModel() # 自定义模型optimizer = optim.Adam(model.parameters(), lr=0.001)# 在训练循环中使用优化器
optimizer.zero_grad() # 清零梯度
loss = compute_loss() # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
3. 其他优化器:
PyTorch还提供了其他优化器,如Adagrad、RMSprop等。这些优化器都可以在torch.optim模块中找到,并使用类似的方式进行使用。
结合前面的神经网络模型代码示例:
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
import torchdataset = torchvision.datasets.CIFAR10('./cifar10', False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)class Lh(nn.Module):def __init__(self):super(Lh, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss()
lh=Lh()
optis = torch.optim.SGD(lh.parameters(), lr=0.1)for epoch in range(10):running_loss = 0for data in dataloader:imgs, targets = dataoutputs = lh(imgs)result_loss = loss(outputs, targets)optis.zero_grad()result_loss.backward() # 设置对应的梯度optis.step()running_loss += result_lossprint(running_loss)相关文章:
神经网络的搭建与各层分析
为什么去西藏的人都会感觉很治愈 拉萨的老中医是这么说的 缺氧脑子短路,很多事想不起来,就会感觉很幸福 一、卷积层 解释:卷积层通过卷积操作对输入数据进行处理。它使用一组可学习的滤波器(也称为卷积核或特征检测器)…...
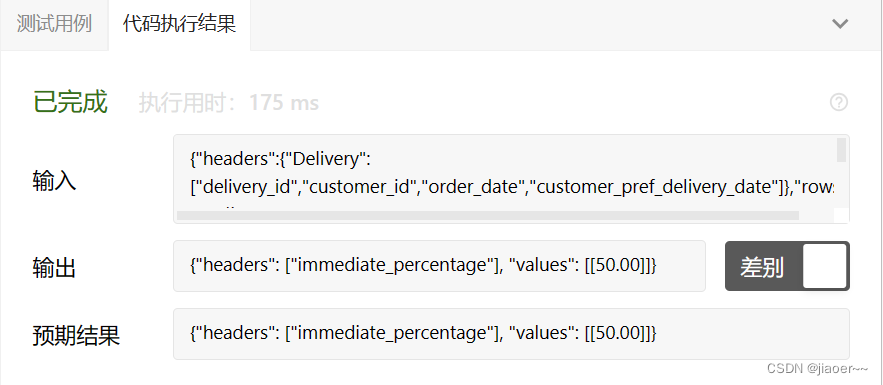
SQL-每日一题【1174. 即时食物配送 II】
题目 配送表: Delivery 如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。 「首次订单」是顾客最早创建的订单。我们保证一个顾客只会有一个「首次订单」。 写一条 SQL 查询语句获取即时订单在所有用户的首次订…...

MySQL学习记录:第一章 DQL语言
文章目录 第一章 查询语言,DQL语言一、基础查询1、查询表中单个字段2、查询表中多个字段3、查询表中所有字段4、查询常量值5、查询表达式6、查询函数7、起别名8、去重9、+号的作用二、条件查询1、按条件表达式筛选2、按逻辑表达式筛选三、模糊查询四、排序查询五、常见函数1、…...
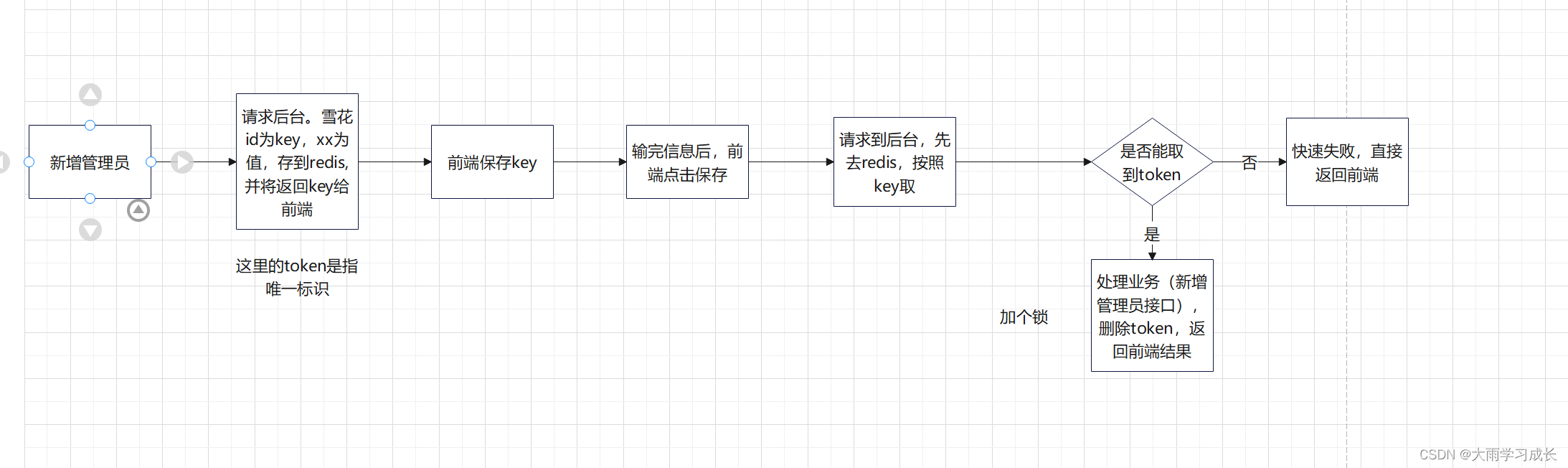
redis+token+分布式锁确保接口的幂等性
目录 1.幂等性是什么? 2.如何实现幂等性呢? 1.新增管理员,出弹窗的同时,请求后台。 2.后端根据雪花算法生成唯一标识key,以雪花数为key存到redis。并返回key给前端。 3.前端保存后端传过来的key。 4.前端输入完成…...
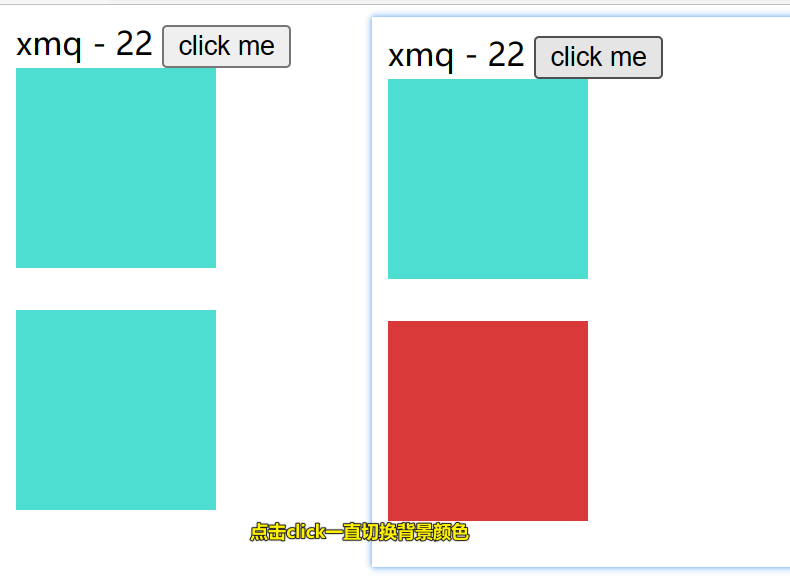
Vue模版语法
目录 接下来学习click 例题:修改背景颜色 例题:反复点击button按钮,可以不断切换背景颜色 先看以下例题是回顾vue的用法 <body><div id"box">{{myname}} - {{myage}}</div><script>var vm new Vue({el…...

新一代开源流数据湖平台Apache Paimon入门实操-上
文章目录 概述定义核心功能适用场景架构原理总体架构统一存储基本概念文件布局 部署环境准备环境部署 实战Catalog文件系统Hive Catalog 创建表创建Catalog管理表查询创建表(CTAS)创建外部表创建临时表 修改表修改表修改列修改水印 概述 定义 Apache Pa…...
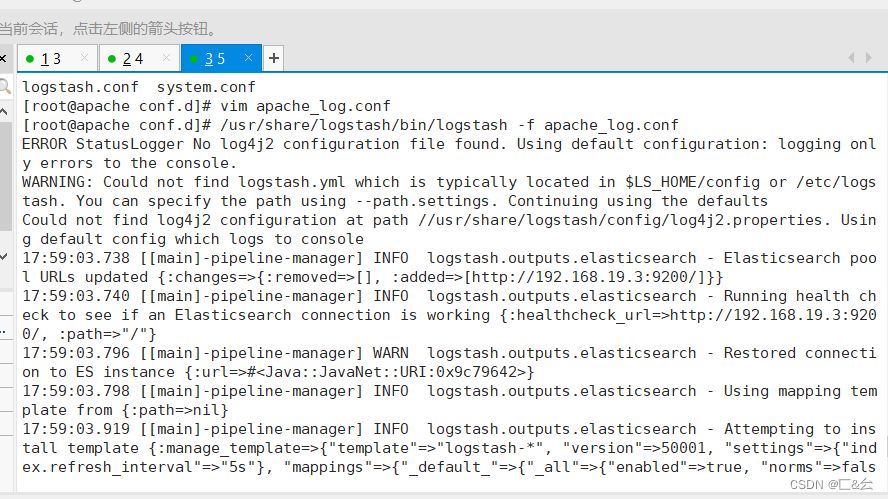
ELK 企业级日志分析系统(一)
目录 一、ELK 简介 1.1 组件说明 1.2 为什么要使用ELK 1.3 完整日志系统的基本特征 1.4 ELK工作原理 二、Elasticsearch的介绍 2.1 Elasticsearch的核心: 三、Logstash 3.1 Logstash简介 四、Kibana 五、部署ELK日志分析系统 5.1 服务器配置 5.2 ELK Elasticse…...

2023-08-01力扣今日二题-Hard-DPLIS优先队列-好题
链接: 354. 俄罗斯套娃信封问题 题意: 一个信封有长宽,如果一个信封的长宽均严格大于另一个信封,那么大的这个信封可以装下小的这个信封 求最多能套娃几个信封 解: 类似普通的最长上升子序列,但是信封…...

并发 如何创建线程 多线程
进程:一个程序的执行过程 线程:一个方法就是一个线程 并发:多个线程抢夺一个资源 操作同一个对象 创建线程方法1 //创建线程方法1 继承Thread类 重写润方法 调用start开启线程 public class TestThead extends Thread{Overridepublic voi…...

亚马逊鲲鹏系统是怎么引流的?
亚马逊鲲鹏系统有三种引流方式,可设置通过亚马逊站点搜索、站外引流、直接访问产品页面进入到相关产品页面进行操作。 1、通过亚马逊站点搜索 正常的登录到我们的亚马逊主页,然后通过设置关键词及asin,最后进入你指定的产品,进行…...
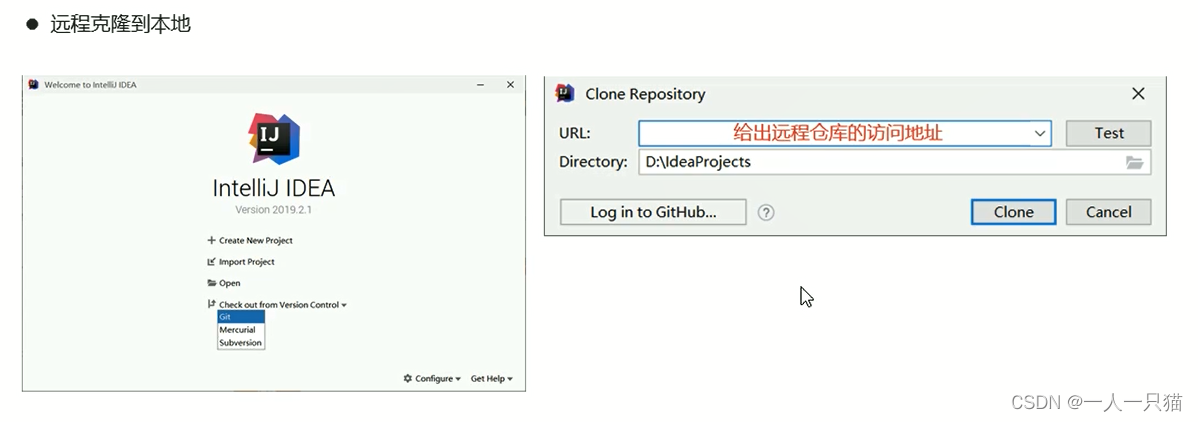
第五章 Git
5-1、Git的安装 1、为什么要使用代码版本控制系统 【1】版本控制 【2】开发中存在的麻烦 2、Git和SVN的对比 【1】Git和SVN对比 (1)SVN (2)Git 3、Git下载和安装 【1】下载 【2】安装 一路下一步就好了,更换安装…...

无涯教程-Lua - 变量声明
变量的名称可以由字母,数字和下划线字符组成。它必须以字母或下划线开头,由于Lua区分大小写,因此大写和小写字母是不同的。 在Lua中,尽管无涯教程没有变量数据类型,但是根据变量的范围有三种类型。 全局变量(Global) …...

vue3学习-组件基础、深入组件
组件 基本概述 单独的 .vue文件 单文件组件(SFC)(single file component) 使用子组件 导入,无需注册,直接使用编译时,区分大小写可使用 />关闭标签 传递 props 需要再组件上声明注册 def…...
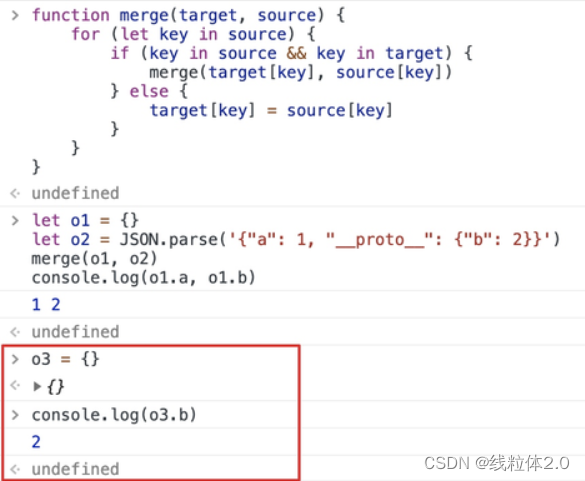
原型链污染分析
原型链污染问题 原型链原型的继承原型链污染 原型链 原型的继承 先创建一个对象,查看一下属性 const obj { prop1: 111, prop2: 222,} 这里的Object.prototype就是对象的原型。 原型里面有许多的属性,这里面的constructor是我们需要着重关注的。 除此…...

RF PCB的9条改进型建议
1.小功率的RF的PCB设计中,主要使用标准的FR4材料(绝缘特性好、材质均匀、介电常数ε=4,10%)。主要使用4层~6层板,在成本非常敏感的情况下可以使用厚度在1mm以下的双面板,要保证反面是一个完整的地层,同时由于双面板的厚度在1mm以上,使得地层和信号层之间的FR4介质较厚,…...
网络安全(黑客)自学就业
前段时间,遇到网友提问,说为什么我信息安全专业的找不到工作? 造成这个结果主要是有两大方面的原因。 第一个原因,求职者本身的学习背景问题。那这些问题就包括学历、学校学到的知识是否扎实,是否具备较强的攻防实战…...

uni-app选择器( uni-data-picker)选择任意级别
背景说明 uni-app 官方的插件市场有数据驱动选择器,可以用作多级分类的场景。引入插件后,发现做不到只选择年级,不选择班级(似乎,只能到最后子节点了)。 需求中,有可能选择的不是叶子。比如&a…...

网络入侵探测器Pi.Alert
什么是 Pi.Alert ? Pi.Alert 是 WIFI/LAN 入侵探测器。通过扫描连接到您的 WIFI/LAN 的设备,提醒您未知设备的连接。它还警告断开“始终连接”的设备。 Pi.Alert 使用了三种扫描方式 方式1:arp-scan。arp扫描系统实用程序用于使用 arp 帧搜索…...
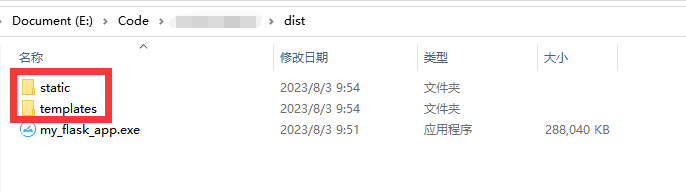
Flask项目打包为exe(附带项目资源,静态文件)
1.在项目根目录创建my_app.spec文件,内容如下: # -*- mode: python ; coding: utf-8 -*-block_cipher Nonea Analysis([server.py], # flask入口pathex[],binaries[], datas[("E:/**/templates","/templates"),("E:/**/s…...

无代码开发(BIP旗舰版-YonBuilder)
目录 我的应用 新建领域 菜单管理 应用构建 新建应用 对象建模 新增业务对象 新增业务实体 页面建模 新增页面 编辑页面 发布管理 我的应用 角色管理 yonbuilder开发平台,提供标准服务和专业开发服务; 本篇文章只演示标准服务的可视化应用…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...

SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南
SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...
)
【独家首发】DeepSeek边缘计算白皮书未公开章节:3类典型场景QoS SLA保障公式(含实测RTT抖动衰减模型)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek边缘计算架构全景概览 DeepSeek边缘计算架构以“轻量、协同、自治”为核心设计理念,面向AI推理密集型场景构建端—边—云三级协同的分布式智能执行体。该架构并非传统云中心化模型的…...

终极指南:如何用ESP32打造专业级蓝牙游戏手柄
终极指南:如何用ESP32打造专业级蓝牙游戏手柄 【免费下载链接】ESP32-BLE-Gamepad Bluetooth LE Gamepad library for the ESP32 项目地址: https://gitcode.com/gh_mirrors/es/ESP32-BLE-Gamepad 你是否曾经想过用ESP32开发板制作一个自定义的游戏控制器&am…...

SillyTavern桌面版终极指南:三步打造你的专属AI聊天桌面应用
SillyTavern桌面版终极指南:三步打造你的专属AI聊天桌面应用 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 还在为复杂的命令行启动和浏览器标签混乱而烦恼吗?Sill…...

小学阶段物理学习书籍推荐
结合小学阶段认知特点,推荐以下几本兼具趣味性和实用性的物理启蒙书籍,适配不同年级孩子的学习需求: 一、低龄(1-2年级/6-8岁):趣味感知,激发好奇 1、漫画物理全套6册 用孩子最喜欢的漫画形式拆…...
的使用场景)
Python运算符:成员运算符(in/not in)的使用场景
Python运算符:成员运算符(in/not in)的使用场景📚 本章学习目标:深入理解成员运算符(in/not in)的使用场景的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最…...

突破百度网盘速度壁垒:Python直链解析工具的技术实现与应用
突破百度网盘速度壁垒:Python直链解析工具的技术实现与应用 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享的时代,百度网盘作为国内主流…...