R语言中数据重塑(长宽表的转化)
学习笔记,仅供学习使用。
目录
1-什么是整洁的数据?
2-宽表变成长表
示例1:
示例2:
示例3:
3-长表变宽表
示例1:
示例2:
1-什么是整洁的数据?
按照Hadley的表述,整洁的数据具有如下特点:
- 每个变量构成一列,即属性相同的变量自成一列;
- 每个观测构成一行;
- 每个观测的每个变量值构成一个单元格;
不满足上述条件的数据称为脏的、不整洁的数据,它们往往具有如下特点:
- 列名不是变量名,是值;
- 多个变量放在一列;
- 变量既放在行,又放在列;
- 多种类型的观测单元在同一个单元格,即每个单元格不是一个数值;
- 一个观测单元放在多个表;
数据重塑:tidyverse系列包中的函数操作的都是整洁的数据框,而不整洁的数据,首先需要把它们变成整洁的数据,这个过程就是数据重塑;
数据重塑包括:长宽表转化、拆分/合并列、方形化。其中长宽表转化使用的是pivot_longer()和pivot_wider()函数
脏数据示例及说明:

这个示例中,男和女都属于性别,所以可以将男、女归为一个变量。违反了整洁数据要求中的第一条,一列是一个变量。
 在这个示例中,因为年龄和体重这两个变量放到了一列中,虽然使用了反斜杠分隔开,人类按照常识很容易理解,但是计算机并不会懂,其只会讲两列本来是数值类型的数据当成是字符串来处理,这违反了整洁数据的第三条,每个观测的每个变量构成一个单元格。
在这个示例中,因为年龄和体重这两个变量放到了一列中,虽然使用了反斜杠分隔开,人类按照常识很容易理解,但是计算机并不会懂,其只会讲两列本来是数值类型的数据当成是字符串来处理,这违反了整洁数据的第三条,每个观测的每个变量构成一个单元格。
这个示例中,整洁数据的三条要求均未满足。
让数据变整洁的关键是,要学会区分变量、观测、值。
2-宽表变成长表
宽表:指数据集对所有的变量进行了明确的细分,表比较宽,本来该放在单元格中的值,却放在了列名上,比如男性,女性,应该放在单元格中的内容,却成了某两列的列名;
长表:指数据集中包含分类变量的数据。
使用tidyr包中的pivot_longer()函数可以将宽表转换为长表,使用pivot_wider()函数可以将长表转换为宽表,它是pivot_longer()函数的逆变换。
语法介绍:
pivot_longer(data, cols, names_to, values_to, values_drop_na, ...)
其中
- data:要重塑的数据框;
- cols:用选择列语法 选择要变形的列,即要处理的列;
- names_to:设置列名,具体来说,为了存放 要处理的列 的列名,新建一列或者几列(根据具体问题),对新建的列设置一个新的列名;
- values_to: 设置列名,具体来说, 存放 要处理的列,其下单元格中的值,为这一列设置一个新的列名。
- values_drop_na:是否忽略变形列中的缺失值(NA,not available)
- 如果变形列的列名除了想要的“内容”外,还包括前缀、变量名+分隔符、正则表达式分组捕获模式,则可以借助参数names_prefix、names_sep、names_pattern来提取出想要的“内容”,注意,这里的“内容”,指的是列名中想要的部分。
示例1:
宽表 变 长表 (将要重塑的列的列名 存放在一列中)
> df <- read.csv("配套数据/分省年度GDP.csv")
> df地区 X2019年 X2018年 X2017年
1 北京市 35371.28 33105.97 28014.94
2 天津市 14104.28 13362.92 18549.19
3 河北省 35104.52 32494.61 34016.32
4 黑龙江省 13612.68 12846.48 15902.68> df %>%
+ pivot_longer(-地区, names_to = "年份", values_to="GDP")
# A tibble: 12 × 3地区 年份 GDP<chr> <chr> <dbl>1 北京市 X2019年 35371.2 北京市 X2018年 33106.3 北京市 X2017年 28015.4 天津市 X2019年 14104.5 天津市 X2018年 13363.6 天津市 X2017年 18549.7 河北省 X2019年 35105.8 河北省 X2018年 32495.9 河北省 X2017年 34016.
10 黑龙江省 X2019年 13613.
11 黑龙江省 X2018年 12846.
12 黑龙江省 X2017年 15903.df是一个宽表,除了地区列,剩下的所有列是我们想要重塑的列,在pivot_longer()函数中,第一个参数是我们要处理的数据框,由于这里使用的是管道操作,所以这个函数的第一个参数就省略掉了,第二个参数是要重塑的列,这里表示除了地区外,剩下的所有列都是我们要重塑的,第三个参数names_to="年份",表示原始数据中我们要重塑的列,这列的列名存放在一个新列中,我们通过names_to为这个新列取一个列名,在这个案例中,为这个新列取名为“年份”。第四个参数是values_to=“GDP”,表示原始数据中我们要重塑的列,这列的单元格中存放的值,现在放在一个新列中,我们需要为这个新列取一个列名,这个列名为“GDP”。
从这个示例中可以看到,我们重塑的列,把这些重塑列的列名提取出来,放在一个新列的单元格中,并且进行循环重复出现,即x2019, x2018,x2017为一个循环。
示例2:
宽表变长表 (将要重塑的列的列名 存放在多个列中)
原始数据:宽表

目标 转化为如下长表
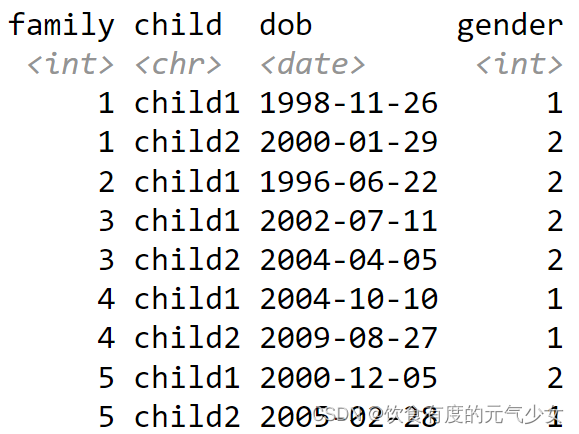
分析:
这个数据是收集每个家庭小孩的信息,比如家庭1中,有两个孩子,child1和child2,并收集这些小孩的出生日期和性别。
原始数据中,我们要重塑的列是除了family列之外的所有列,这些列的列名使用下划线进行了分割,我们想要让数据变成3列,即child列、dob出生日期、gender性别。其中dob、gender这两列保持不变,不用进行任何的操作,child1,child2变成新的一列,并为这一列取名为child。
> load("配套数据/family.rda")
> knitr::kable(family, align="c")| family | dob_child1 | dob_child2 | gender_child1 | gender_child2 |
|:------:|:----------:|:----------:|:-------------:|:-------------:|
| 1 | 1998-11-26 | 2000-01-29 | 1 | 2 |
| 2 | 1996-06-22 | NA | 2 | NA |
| 3 | 2002-07-11 | 2004-04-05 | 2 | 2 |
| 4 | 2004-10-10 | 2009-08-27 | 1 | 1 |
| 5 | 2000-12-05 | 2005-02-28 | 2 | 1 |
>
> family %>%
+ pivot_longer(-family,
+ names_to = c(".value", "child"),
+ names_sep="_",
+ values_drop_na = TRUE)
# A tibble: 9 × 4family child dob gender<int> <chr> <date> <int>
1 1 child1 1998-11-26 1
2 1 child2 2000-01-29 2
3 2 child1 1996-06-22 2
4 3 child1 2002-07-11 2
5 3 child2 2004-04-05 2
6 4 child1 2004-10-10 1
7 4 child2 2009-08-27 1
8 5 child1 2000-12-05 2
9 5 child2 2005-02-28 1代码解释:
- -family,表示要变形的列是除了family列之外的列。
- .names_sep="_"表示重塑的列的列名使用下划线进行分割。
- names_to=c(".value","child")用于设置长表中新创建的列的列名。具体来说,要重塑的列的列名名,使用下划线分为两部分,第一部分为出生年月和性别,第二部分是小孩1和小孩2.
- 第一部分产生的列信息(列名+其下的单元格内容)保持不变;
- "child"为新创建的列的列名,这个列用来存放要重塑列的列名的第二部分的内容,即小孩1和小孩2.
- values_drop_na=TRUE:表示在数据重塑中忽略要变形列中的缺失值NA。
示例3:
宽表变长表 (将要重塑的列的列名 存放在多个列中)
原始数据宽表

目标:转化为如下形式的长表

> df <- read.csv("配套数据/参赛队信息.csv")
> df队员1姓名 队员1专业 队员2姓名 队员2专业 队员3姓名 队员3专业
1 张三 数学 李四 英语 王五 统计学
2 赵六 经济学 钱七 数学 孙八 计算机
>
> df %>%
+ pivot_longer(everything(),
+ names_to=c("队员", ".value"),
+ names_pattern = "(.*\\d)(.*)")
# A tibble: 6 × 3队员 姓名 专业 <chr> <chr> <chr>
1 队员1 张三 数学
2 队员2 李四 英语
3 队员3 王五 统计学
4 队员1 赵六 经济学
5 队员2 钱七 数学
6 队员3 孙八 计算机语法解释:
- everything():表示选择所有列,即要重塑的列为所有的列;
- names_pattern= "(.*\\d)(.*)" :使用该参数 和 正则表达式进行分组捕获。\\d表示匹配数字即0-9,*表示除换行以外的任何字符、字母、数字,*至少匹配一次。
- names_to=c("队员", ".value")表示新创建列的列名,新创建的列的列名为“队员”,剩下的列及信息保持不变。具体来说,将要重塑的列的列名使用正则表达式分成了两部分,第一部分的内容为child1,child2,这里为第一部分列名创建一个新列,设置该新列的列名为child,第二部分为列的信息(列名和单元格部分,保持不变,比如,这个例子中第二部分的列名有两个,姓名 和专业,这两列保持不变,保持原来的列名和列下的单元格内容)
3-长表变宽表
使用tidyr包中的pivot_wider()函数来实现 长表变宽表
pivot_wider(data, id_cols, names_from, values_from, values_fill,...)
其中:
- data:表示要重塑的数据框;
- id_cols:唯一识别观测的列,默认是除了names_from,values_from指定列之外的列。
- names_from:指定列名来自哪个变量列;
- values_from:指定列值来自哪个变量列
- values_fill:若表变宽之后,单元格值确实,要设置用何值填充。
- 还有一些用于帮助修复列名的参数:names_prefix, names_sep, names_glue.
示例1:
只有一个列名和一个列值,
列名:来自Type 这一列
列值:来自Heads 这一列
在整洁数据中,可以使用列名来访问这一整列的信息。
> load("配套数据/animals.rda")
> animals
# A tibble: 228 × 3Type Year Heads<chr> <int> <dbl>1 Sheep 2015 24943.2 Cattle 1972 2189.3 Camel 1985 559 4 Camel 1995 368.5 Camel 1997 355.6 Goat 1977 4411.7 Cattle 1979 2477.8 Cattle 2014 3414.9 Cattle 1996 3476.
10 Cattle 2017 4388.
# ℹ 218 more rows
# ℹ Use `print(n = ...)` to see more rows
>
> animals %>%
+ pivot_wider(names_from=Type, values_from=Heads, values_fill = 0)
# A tibble: 48 × 6Year Sheep Cattle Camel Goat Horse<int> <dbl> <dbl> <dbl> <dbl> <dbl>1 2015 24943. 3780. 368. 23593. 3295.2 1972 13716. 2189. 625. 4338. 2239.3 1985 13249. 2408. 559 4299. 1971 4 1995 0 3317. 368. 8521. 2684.5 1997 14166. 3613. 355. 10265. 2893.6 1977 13430. 2388. 609 4411. 2104.7 1979 14400. 2477. 614. 4715. 2079.8 2014 23215. 3414. 349. 22009. 0 9 1996 13561. 3476. 358. 9135. 2770.
10 2017 30110. 4388. 434. 27347. 3940.
# ℹ 38 more rows
# ℹ Use `print(n = ...)` to see more rows可以看到animals这个原始数据的第一列Type中值是重复出现的,将这一列中的单元格内容,即动物的种类,作为新的变量,有几个种类,就创建几列,使用names_from指定新创建的列名来自原始数据的哪列,这里使用的数据框的列名,表示可以访问这一列的信息(列名+单元格内容),values_from用于指定新创建的列的单元格的内容 来自原始数据的哪一列。
示例2:
只有多个列名列或多个值列。下面这个例子,展示了有两个值列,即estimate和moe
> us_rent_income#tidyr自带的数据集;
# A tibble: 104 × 5GEOID NAME variable estimate moe<chr> <chr> <chr> <dbl> <dbl>1 01 Alabama income 24476 1362 01 Alabama rent 747 33 02 Alaska income 32940 5084 02 Alaska rent 1200 135 04 Arizona income 27517 1486 04 Arizona rent 972 47 05 Arkansas income 23789 1658 05 Arkansas rent 709 59 06 California income 29454 109
10 06 California rent 1358 3
# ℹ 94 more rows
# ℹ Use `print(n = ...)` to see more rows
> us_rent_income%>%
+ pivot_wider(names_from=variable, values_from=c(estimate, moe))
# A tibble: 52 × 6GEOID NAME estimate_income estimate_rent moe_income moe_rent<chr> <chr> <dbl> <dbl> <dbl> <dbl>1 01 Alabama 24476 747 136 32 02 Alaska 32940 1200 508 133 04 Arizona 27517 972 148 44 05 Arkansas 23789 709 165 55 06 California 29454 1358 109 36 08 Colorado 32401 1125 109 57 09 Connecticut 35326 1123 195 58 10 Delaware 31560 1076 247 109 11 District of Col… 43198 1424 681 17
10 12 Florida 25952 1077 70 3
# ℹ 42 more rows
# ℹ Use `print(n = ...)` to see more rows宽表和长表:
宽表变长表过程中,要将待重塑的列,“整合”成几列,抽象看来,就是多列,“整合”成比之前少的列,即将一个宽表 变成一个 长表。这里整合是打引号的,是说将要重塑的列的信息进行整合,通过创建新列和保留某些列来完成这个整合操作,将分类变量,比如男性和女性,男性作为一个变量,自成一列,女性作为一个变量自成一列,宽表变长表这个过程,是将男性和女性归为分为变量中,取名为性别,在创建新列的时候,势必要为列取列名,这个取列名一定是一个字符串"性别",这个性别列的单元格内容由男和女重复循环出现,原始数据列名为男的这一列,下面的单元格内容和女性的这一列下面的单元格内容自成一列,也需要为这个单元格值创建新列的时候,取一个列名,列名通常使用字符串表示。
长表变宽表的过程中,长表的变量(即一列)下面的内容是重复出现的,这个时候,要把重复出现的内容,提取出来,让这些值变成新的列名,所以设置names_from,即新的列名来自原始数据的哪一列,此时该参数后面等于的是列名,而不是字符串。有了新的列名之后,我们需要为新的列,下面的单元格内容进行填充,用什么值进行填充?使用的是原始长表的某几列(具体问题具体分析)的值进行填充,因此,values_from后面填写的是 原始数据的列名,不带引号的,不是字符串。
示例数据来源:
R语言编程:基于tidyverse-异步社区-致力于优质IT知识的出版和分享 (epubit.com)
参考:
《R语言编程》(2023年2月出版,人民邮电出版社)

《R数据科学实战:工具详解与案例分析》(2019年6月出版,机械工业出版社)

R语言数据可视化实战(微视频全解版)---大数据专业图表从入门到精通。(2022年2月出版,电子工业出版社)

相关文章:
R语言中数据重塑(长宽表的转化)
学习笔记,仅供学习使用。 目录 1-什么是整洁的数据? 2-宽表变成长表 示例1: 示例2: 示例3: 3-长表变宽表 示例1: 示例2: 1-什么是整洁的数据? 按照Hadley的表述…...
:依赖注入)
C# Blazor 学习笔记(10):依赖注入
文章目录 前言Blazor 依赖注入依赖注入用于解决什么问题?依赖注入的生命周期。测试代码 总结 前言 Blazor 具有前后端不分离模式,但是如何直接调用需要一定的设置 Blazor 依赖注入 依赖注入在spring里面很常见,毕竟.NET 是个巨型融合怪。只…...
接口请求(get、post、head等)详解
一.接口请求的六种常见方式: 1、Get 向特定资源发出请求(请求指定页面信息,并返回实体主体) 2、Post 向指定资源提交数据进行处理请求(提交表单、上传文件),又可能导致新的资源的建…...

【【萌新的STM32学习-4】】
萌新的STM32学习-4 STM32系统框架 1.1 Cortex M 内核& 芯片 F1有四个驱动单元 四个被动单元 AHB 高级高性能总线 APB 高级外围总线 部分系统结构 最上面的ICode 总线直接连接到了内部Flash 不需要通过总线矩阵 . D Code 总线(D - Bus) 这是Cort…...

C++ Primer Plus第五章 习题
目录 复习题: 1.入口条件循环和出口条件循环之间的区别是什么?各种c循环分别属于其中的哪一种? 2.如果下面的代码片段是有效程序的组成部分,它将打印什么内容? 3.如果下面的代码片段是有效程序的组成部分࿰…...

软考A计划-系统集成项目管理工程师-信息文档和配置管理-上
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例点击跳转>软考全系列点击跳转>蓝桥系列 👉关于作者 专注于Android/Unity和各种游…...
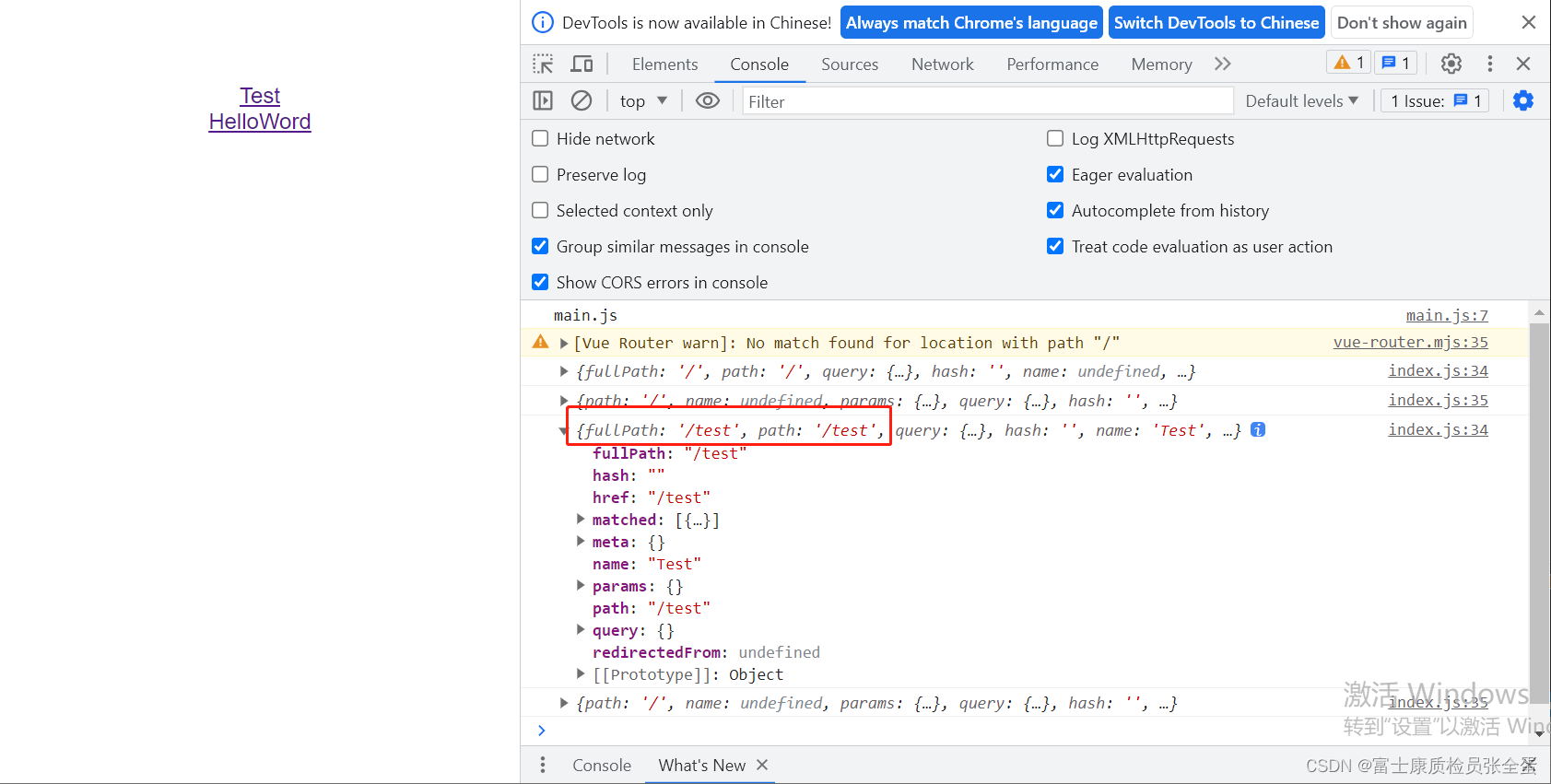
Vue 路由 路由守卫
路由守卫 正如其名, vue-router 提供的导航守卫主要用来通过跳转或取消的方式守卫导航。简单来说,就是在路由跳转 时候的一些钩子,当从一个页面跳转到另一个页面时,可以在跳转前、中、后做一些事情。 当你打开一个页面的前后需…...

基于springboot的课程作业管理系统【附开题|ppt|万字文档(LW)和搭建文档】
主要功能 学生登录: ①首页、个人中心:修改密码、个人信息管理等 ②公告信息管理、课程信息管理、学生选课管理、作业布置管理、作业提交管理、作业评分管理、课程评价管理、课程资源管理 教师登录: ①首页、个人中心:修改密码、…...
关于个人微信API接口的开发
个人微信开发API接口可拓展功能说明 1、个人微信多账号管理、聚合聊天、多个微信号同时登陆、多个微信号集中在一个窗口进行聊天,实现一人多号同时沟通快速提升沟通效率,提升微信营销效率。 2、客服灵活分配:客服主管可自由分配微信号给指定…...

华为PMS API client token auth failed
对接华为pms时出现问题,提示华为PMS API client token auth failed 主要是权限的问题,创建项目的时候选择N/A...

【Java面试丨消息中间件】Kafka
一、kafka是如何保证消息不丢失 1. 介绍 使用kafka在消息的收发过程都有可能会出现消息丢失 (1)生产者发送消息到broker丢失 (2)消息在broker中存储丢失 (3)消费者从broker接收消息丢失 2. 生产者发送消…...

7.数组(一维数组、二维数组、C99中的变长数组、二分查找法)
数组 1.数组的概念2.一维数组2.1 一维数组的创建2.2 一维数组的类型2.3 一维数组的初始化2.4 一维数组的下标2.5 一维数组的输入与输出2.6 一维数组在内存中的存储2.7 利用sizeof()计算数组元素的个数 3.二维数组3.1 二维数组的概念3.2 二维数组的创建3.3 二维数组的初始化3.4 …...

ubuntu服务器配置ftp服务
需求:配置ftp服务用于在windows电脑上直接浏览、下载、上传ubuntu服务器上的文件,用于文件共享,方便实用 效果:用户打开windows资源管理器后输入ftp://xxx.xxx.xxx.xxx (公网IP地址)后,即可浏览…...
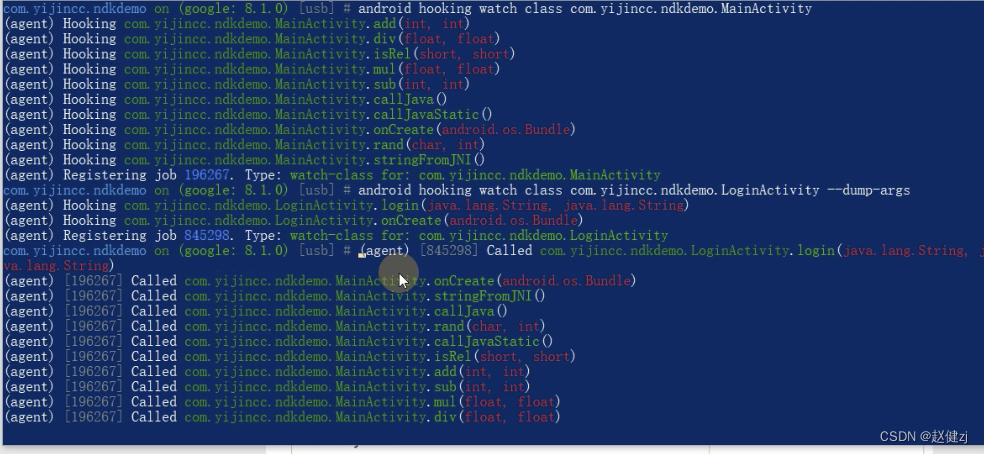
IDA+Frida分析CTF样本和Frid源码和objection模块
文章目录 一些资料IDA调试命令IDA调试安卓的10个技巧objection基本使用 Wallbreaker1frida源码阅读之frida-java 第一个实例EasyJNI第二个实例objection资料 art_trace2.pyart_trace2.js IDAFrida分析CTF样本和Frid源码和objection模块 一些资料 IDA调试命令 adb devices adb…...
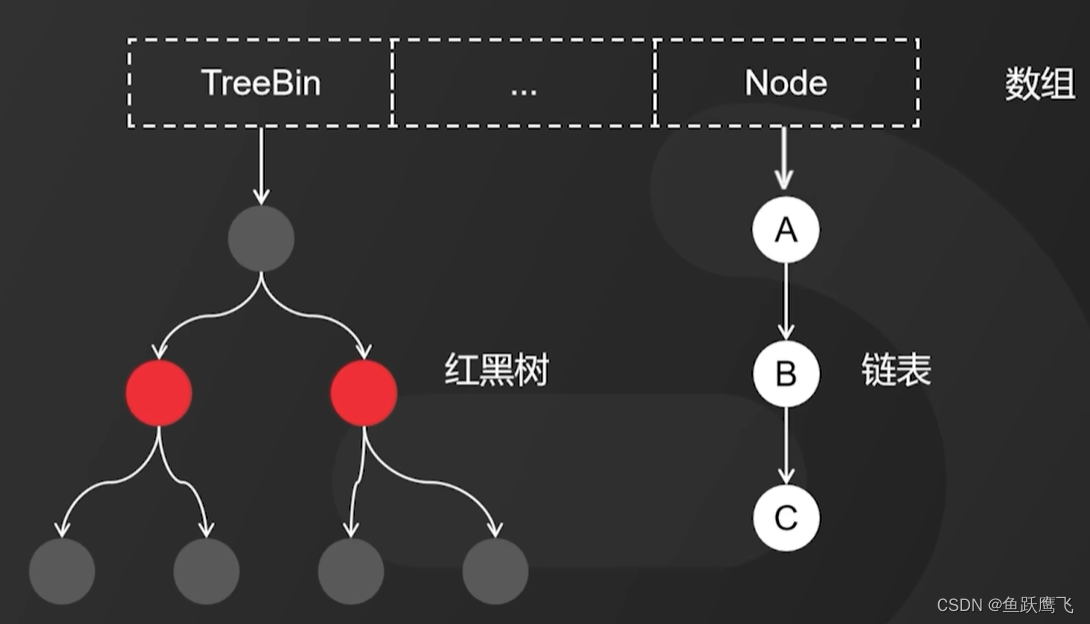
ConCurrentHashMap常见面试题
1. JDK1.7和JDK1.8中ConCurrentHashMap的实现有什么不同? JDK1.7中的实现可以认为是大数组套小数组,大数组是Segment数组,小数组是HashEntry数组,锁是锁在大数组的元素上(Segment),力度比较大&…...

mysql数据备份并重置
mysql数据备份并重置 1.备份mysql数据 mysqldump -uroot --single-transaction -R -E --databases lc2 cpm a10_goods self_warehouse > /mnt/vdc1/var/lib/mysql/datadir/lc2_cpm_a10_goods_self_warehouse.sql -p Y6B2wb 2.初始化mysql mysqld --initialize; 3.修改配…...
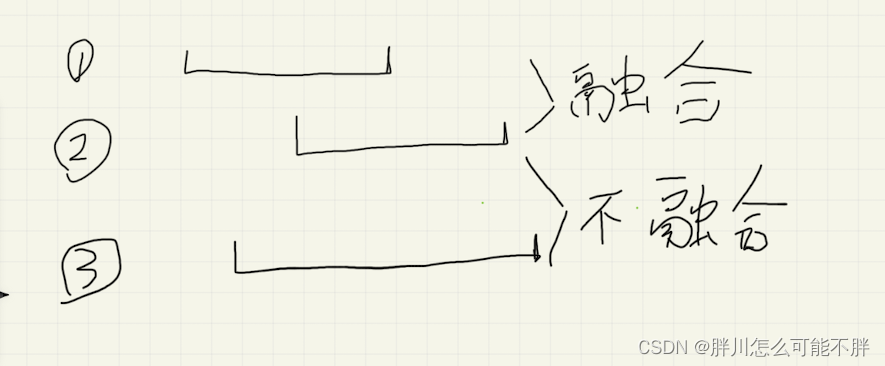
I- yh的线段(2023河南萌新联赛第(四)场:河南大学)
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 yh喜欢好线段,好线段即两条线段相交且不与其他线段重合的线段。 两条线段[l1,r1]和[l2,r2]相交(如果存在至少一个x,使得l1≤x≤r1和l2≤x≤r2,则认为两个线段…...

python与深度学习(十四):CNN和IKUN模型二
目录 1. 说明2. IKUN模型的CNN模型测试2.1 导入相关库2.2 加载模型2.3 设置保存图片的路径2.4 加载图片2.5 图片预处理2.6 对图片进行预测2.7 显示图片 3. 完整代码和显示结果4. 多张图片进行测试的完整代码以及结果 1. 说明 本篇文章是对上篇文章猫狗大战训练的模型进行测试。…...

chrome扩展在popup、background、content之间通信解决传输文件问题
文章目录 背景介绍案例介绍代码示例popup页面,上传文件页面popup页面,js上传代码,file文件转base64background监听消息,base64转file文件,axios上传 附-转base64后直接下载 背景介绍 示例扩展API版本MV2。 以弹…...

Oracle获取创建对象的DDL脚本
Oracle获取创建对象的DDL脚本 Oracle获取创建对象的DDL脚本查看 dbms_metadata.get_ddl()函数的定义 Oracle获取创建对象的DDL脚本 例如,对tzq schema下的表 test2,查看DDL脚本的SQL如下: SELECT SELECT dbms_metadata.get_ddl(upper(table…...

深入解析RX/TX:通信世界的收发核心
目录 引言 RX/TX的基本概念与原理 定义与功能 信号转换原理 RX/TX在不同通信场景中的应用 有线通信 无线通信 卫星通信 RX/TX技术的发展趋势 高速化 集成化 智能化 结论 引言 在当今高度数字化、信息化的时代,通信技术如同神经脉络,将世界的各个角落…...

从复古游戏到电子墨水屏:聊聊Floyd-Steinberg抖动算法的那些神奇应用场景
从复古游戏到电子墨水屏:Floyd-Steinberg抖动算法的跨时代魔法 1983年,任天堂红白机设计师面临一个棘手问题:如何在仅支持52色的硬件上呈现《超级马里奥兄弟》中碧蓝的海水与翠绿的管道?答案藏在一项诞生于1976年的图像处理技术中…...

从多模态到模型之争:Java开发者的AI认知升级与转型指南
写在前面“多模态是什么?ChatGPT和DeepSeek到底有什么区别?在现在AI浪潮的冲击下,我作为一个Java后端开发者,到底要不要学AI?”这是很多Java开发者正在面对的困惑。AI领域日新月异,概念层出不穷,…...

052篇:NLP文本分类:判断邮件是投诉还是咨询
1. 前言 在RPA自动化中,经常会遇到需要理解文本内容的场景: 客户发来的邮件是投诉还是咨询? 工单描述属于哪个部门处理? 用户评价是正面还是负面? NLP(自然语言处理)可以自动分析文本,判断类别和情感。本文以百度NLP为例,讲解如何调用情感分析和自定义分类接口,并将…...

从CAN到CANFD:一文搞懂协议差异、电平实测与车载网络升级实战
从CAN到CANFD:车载通信协议的深度解析与实战升级指南 引言 在智能汽车快速发展的今天,车载电子控制单元(ECU)数量呈指数级增长,传统的CAN总线技术已逐渐显露出带宽瓶颈。我曾参与过多个车载网络升级项目,亲…...

5分钟掌握League Akari:英雄联盟终极智能助手使用指南
5分钟掌握League Akari:英雄联盟终极智能助手使用指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于英雄…...

小白分享如何Go 语言中的图形界面开发:从 GUI 到 WebAssembly
编程语言里的Go 语言凭借其高效、简洁以及强大的并发能力,已经成为了众多开发者的心头好。而图形界面开发,一直是编程领域中一个重要的分支,它能够让用户与程序进行直观的交互。Go 语言在图形界面开发方面也有不少的探索和实践,从…...

如何使用Sverchok实现CNC加工全流程:从参数化设计到G代码生成的完整指南
如何使用Sverchok实现CNC加工全流程:从参数化设计到G代码生成的完整指南 【免费下载链接】sverchok Sverchok 项目地址: https://gitcode.com/gh_mirrors/sv/sverchok Sverchok是Blender的强大节点式几何编程插件,它能将复杂的参数化设计直接转化…...

3步搞定缠论分析:ChanlunX插件让技术分析变简单
3步搞定缠论分析:ChanlunX插件让技术分析变简单 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 还在为复杂的缠论理论头疼吗?ChanlunX缠论可视化插件将复杂的缠论分析变得直观易懂…...

ComfyUI ControlNet Aux完整指南:30+预处理器一键配置与高效AI绘画控制方案
ComfyUI ControlNet Aux完整指南:30预处理器一键配置与高效AI绘画控制方案 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 还在为AI绘画中的细…...