科技云报道:向量数据库:AI时代的下一个热点
科技云报道原创。
最近,又一个概念火了——向量数据库。
随着大模型带来的应用需求提升,4月以来多家海外知名向量数据库创业企业传出融资喜讯。
4月28日,向量数据库平台Pinecone宣布获得1亿美元(约7亿元)B轮融资;
4月22日,向量数据库平台Weaviate宣布获得5000万美元(约3.5亿元)B轮融资;
4月6日Chroma获1800万美元种子轮融资;
4月19日Qdrant获750万美元种子轮融资。
国内方面,星环科技、北交所云创数据等公司的股价连续异动,其中云创数据自底部以来股价已接近翻倍。
7月4日,腾讯云正式发布向量数据库Tencent Cloud VectorDB,预计8月上线腾讯云官网。
一连串的市场动作,都展示了向量数据库的爆红。那么,什么是向量数据库,到底有啥用?

什么是向量数据库?
当你在网上看到一张壁纸,你想知道这是哪个国家的美景,却不知道如何搜索;或者,在阅读一篇文章时,你想深入了解这个话题,寻找更多的观点和资料,却不知道该如何精确描述。
这时,你需要的是一个能够理解你的意图,为你提供最相关的结果,让你轻松找到你想要的信息的工具。
这就是向量数据库(Vector Data Base),它就像一个超级大脑,帮助你解决这些问题。
所谓向量数据库,是一种专门用于存储、 管理、查询、检索向量的数据库,可以把复杂的非结构化数据通过向量化,处理统一成多维空间里的坐标值。
目前,向量数据库主要应用于人工智能、机器学习、数据挖掘等领域。
具体来看,向量数据库被广泛地用于大模型训练、推理和知识库补充等场景:
●支撑训练阶段海量数据的分类、去重和清洗,给大模型的训练降本增效;
●通过新数据的带入,帮助大模型提升处理新问题的能力,突破预训练带来的知识时间限制,避免大模型出现幻觉;
●提供一种私有数据连接大模型的方式,解决私有数据注入大模型带来的安全和隐私问题,加速大模型在产业落地。
简而言之,向量数据库可以解决大模型预训练成本高、没有“长期记忆”、知识更新不足、提示词工程复杂等问题,突破大模型在时间和空间上的限制,加速大模型落地行业场景。
向量数据库的发展
在向量数据库出现之前,大家普遍使用的是关系型数据库,如MySQL、Oracle等,这些数据库以表格的形式存储数据,适合存储结构化数据。但对于非结构化数据,如文本、图像、音频等,处理起来就相对困难。
此外,关系型数据库在处理大规模数据时,性能会下降,不适合大数据处理。这就像是在一个拥挤的图书馆里找一本书,你知道它在哪个书架上,但是找到它还需要花费大量的时间。
而向量数据库和传统数据库的不同点在于,向量数据库处理的是各种AI应用产生的非结构化数据,通过近似查进行模糊匹配,输出的是概率上的提供相对最符合条件的答案,而非精确的标准答案。
举例来说,传统数据库做图片检索可能是通过关键词去搜索,向量数据库是通过语义搜索图片中相同或相近的向量并呈现结果。理论是向量之间的距离越接近,就说明语意越接近,效果也有最相似。
随着时间的推移,向量数据库开始在不同的领域和应用中不断成长和进化。从20世纪90年代末到2000年初,美国国立卫生研究院和斯坦福大学都开始使用向量数据库。
2005年到2015年间,随着基因研究的深入和加速,向量数据库也在并行中增长,像UniVec 数据库这样的工具在2017年就已经被广泛使用,它们在基因序列比对、基因组注释等领域发挥了重要作用。
2017年和2019年之间,向量数据库开始爆炸式增长,它被应用于自然语言处理、计算机视觉、推荐系统等领域。这些领域都需要处理大量和多样化的数据,并从中提取有价值的信息。
向量数据库通过使用诸如余弦相似度、欧氏距离、Jaccard 相似度等度量方法,以及诸如倒排索引、局部敏感哈希、乘积量化等索引技术,实现了高效和准确的向量检索。
目前各大厂商使用的推荐系统、以图搜图、哼唱搜歌、问答机器人等应用,其内核都是向量数据库。
在今年,向量数据库开始被用于与大语言模型结合的应用。
它为大语言模型提供了一个外部知识库,使得大语言模型可以根据用户的查询,在向量数据库中检索相关的数据,并根据数据的内容和语义来更新上下文,从而生成更相关和准确的文本。
这些大语言模型通常使用深度神经网络来学习文本数据中隐含的规律和结构,并能够生成流畅和连贯的文本。
向量数据库 过使用诸如BERT、GPT等预训练模型将文本转换为向量,并使用诸如FAISS、Milvus等开源平台来构建和管理向量数据库。
总体而言,向量数据库成功地解决了很多挑战,并为人们带来了很多价值。
针对传统关系型数据库难以处理的大规模数据、低时延高并发检索、模糊匹配等领域,向量数据库通过数据的向量化来满足特定需求,尤其适用于人工智能领域。
让行业大模型具备know how能力
随着AI大模型的崛起,向量数据库的爆红也就不难理解。
一是,在现实世界里,非结构化数据是“主流”。根据Gartner的数据,非结构化数据占企业生成的新数据比例高达90%,并且增长速度比结构化数据快三倍。
而生成式AI大模型进一步带来了非结构化数据的暴增,也相应推动了对向量数据库的需求。
向量数据库的一大优势在于,能够通过机器学习方法处理和理解来自不同源的多种模态信息,如文本、图像、音频和视频等。
二是,越来越多的大模型从业者认为,所有的行业都值得被AI重新做一遍。
因此,建立在不同行业的垂直大模型,成为大家的切入点,而向量数据库是行业大模型具备“行业knowhow”能力的必经之路。
这背后是,AI大模型的产生,需要经历大量反复的训练和调试。虽然通用AI大模型能回答一般性问题,但在垂直领域服务中,其知识深度、准确度和时效性有限。
而利用向量数据库结合大模型和自有知识资产,可以构建垂直领域的AI能力。向量数据库存储和处理向量数据,提供高效的相似度搜索和检索功能。
正如东北证券观点,AI化的本质则是向量化,向量化计算成本高昂,海量的高维向量势必需要专门的数据库进行存储和处理,向量数据库应运而生。
向量数据库在拓展AI全新应用场景的同时,也将对传统数据库产品形成替代,进而成为AI时代的Killer App。
目前,向量数据库是一个亟待引爆的蓝海市场。
据公开资料显示,向量数据库市场空间巨大,尚处于从0-1阶段,预测到2030年,全球向量数据库市场规模有望达到500亿美元,国内向量数据库市场规模有望超过600亿人民币。
未来随着生成式AI大模型开发量和使用量的增长,向量数据库的应用有望快速增长。
而国内外众多玩家如传统数据库厂商、初创数据库厂商、云厂商、跨界厂商等都已跃跃欲试,提前开始布局向量数据库,做好了应对AI大模型时代的准备。
【关于科技云报道】
专注于原创的企业级内容行家——科技云报道。成立于2015年,是前沿企业级IT领域Top10媒体。获工信部权威认可,可信云、全球云计算大会官方指定传播媒体之一。深入原创报道云计算、大数据、人工智能、区块链等领域。
相关文章:
科技云报道:向量数据库:AI时代的下一个热点
科技云报道原创。 最近,又一个概念火了——向量数据库。 随着大模型带来的应用需求提升,4月以来多家海外知名向量数据库创业企业传出融资喜讯。 4月28日,向量数据库平台Pinecone宣布获得1亿美元(约7亿元)B轮融资&am…...

【更新】119所院校考研重点勾画更新预告!
截至目前,我已经发布了47篇不同院校的择校分析。发布了87套名校信号考研真题以及119所不同院校的考研知识点重点勾画。 另外为了更好服务已经报名的同学,24梦马全程班也到了收尾的阶段。即将封班!需要报名的同学抓紧啦! 去年开始…...
LRU算法(哈希链表法))
【Leetcode】(自食用)LRU算法(哈希链表法)
step by step. 题目: 请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键…...
搜索引擎获取页面内容)
robots.txt 如何禁止蜘蛛(百度,360,搜狗,谷歌)搜索引擎获取页面内容
什么是蜘蛛抓取 搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做robots.txt的纯文本文件。您可以在您的网站中创建一个纯文本文件robots.txt,在文件中声明该网站中不想…...
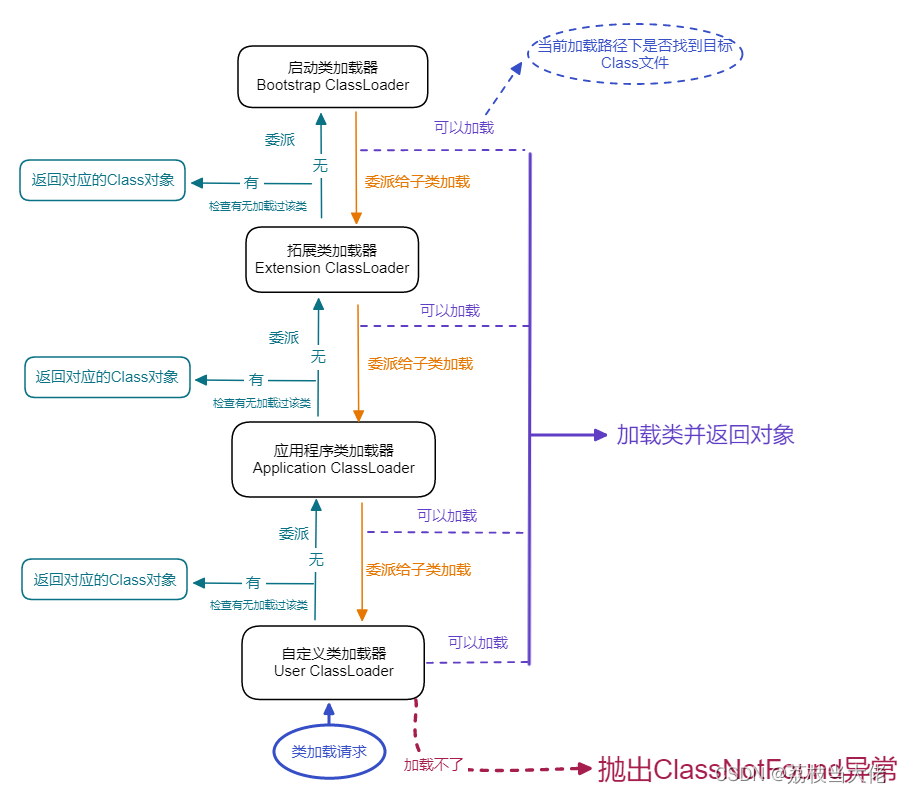
JVM 学习—— 类加载机制
前言 在上一篇文章中,荔枝梳理了有关Java中JVM体系架构的相关知识,其中涉及到的有关Java类加载机制的相关知识并没有过多描述。那么在这篇文章中,荔枝会详细梳理一下有关JVM的类加载机制和双亲委派模型的知识,希望能够帮助到有需要…...

C#实现int类型和字节流的相互在转化
通过TCP协议进行数据传输时,需要将所有传输的内容转为字节流,这里就用到了将int型的数据转为字节流的。代码如下: public static byte[] BytesConvertToInt(int vel) {byte[] hex new byte[4];hex[3] (byte)(vel >> 24) & 0xff)…...

Centos设置固定IP地址,外网访问
查看网络信息 一般会看到enp0s3的网络配置 ip address切换至网络配置路径 cd /etc/sysconfig/network-scripts/编辑配置 vi ifcfg-enp0s3 编辑配置 主要修改 静态ip:BOOTPROTOdhcp --> OOTPROTOstaticDNS(訪問外網):DNS1114.114.114.114本机ip: 192.168.70.121子网掩码…...
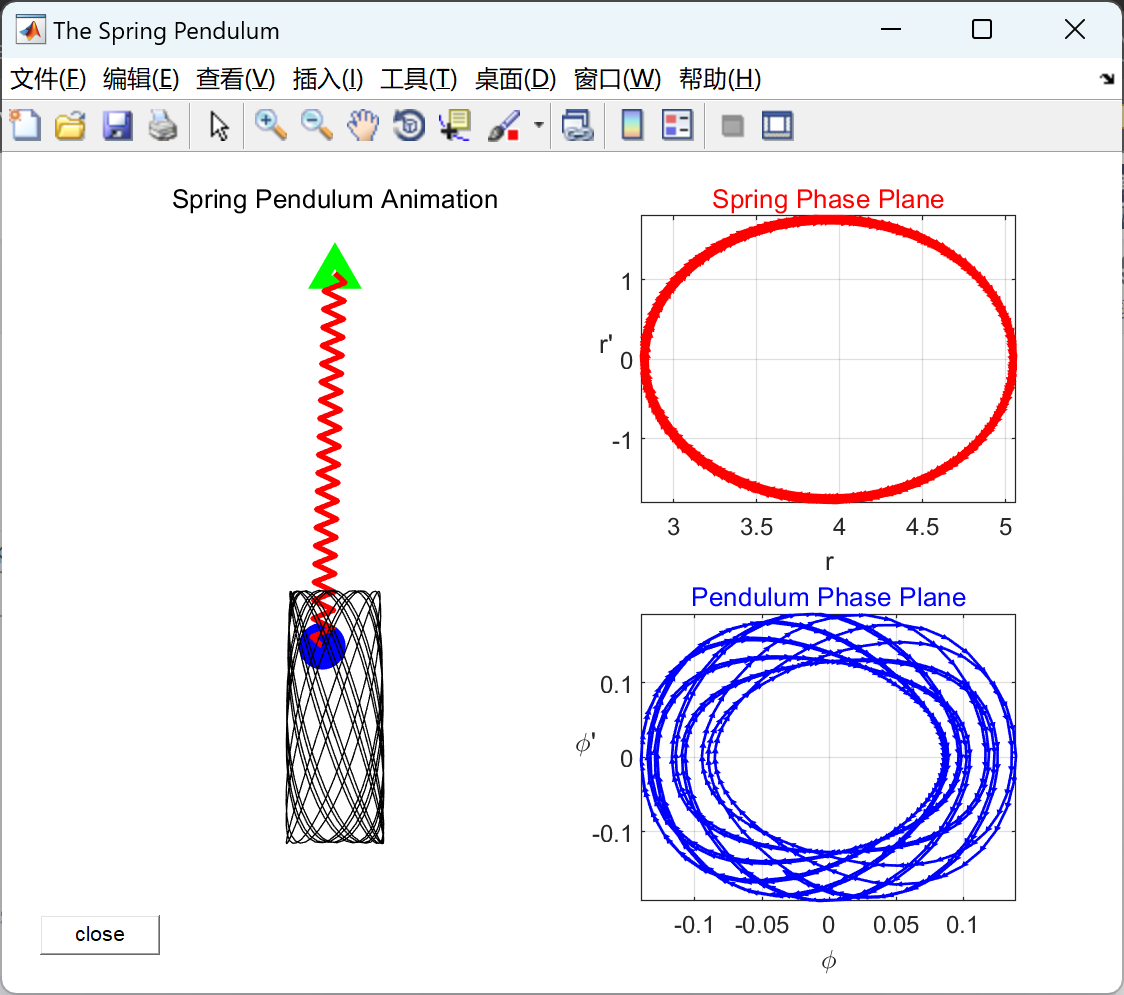
非线性弹簧摆的仿真(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

css实现文字颜色渐变+阴影
效果 代码 <div class"top"><div class"top-text" text"总经理驾驶舱">总经理驾驶舱</div> </div><style lang"scss" scoped>.top{width: 100%;text-align: center;height: 80px;line-height: 80px;fo…...

C++学习笔记总结练习:关联容器
关联容器 0 关联容器概述 关联容器与顺序容器的区别 关联容器和顺序容器有着根本不同。关联容器中的元素是按关键字来把偶才能和访问的。书序容器中的元素是按他们在容器中的位置来顺序保存和访问的。 两个基础类型 map:键值对key-value。关键字是索引,值表示与…...
)
TypeScript技能总结(二)
typescript是js的超集,目前很多前端框架都开始使用它来作为项目的维护管理的工具,还在不断地更新,添加新功能中,我们学习它,才能更好的在的项目中运用它,发挥它的最大功效 //readonly 只能修饰属性&#x…...

整理一些Postgresql工作中常用面试中会问的问题---Postgresql面试题001
1.什么是Postgresql TOAST? TOAST (The Oversized-Attribute Storage Technique,超大尺寸字段存储技术)主要用于存储大字段的值。 PostgreSQL 页面(page)大小是固定的(通常为8KB),且不允许tuples跨多个页面存储。因此不能存储非常大的字段值。为了克服这个限制,大字段…...
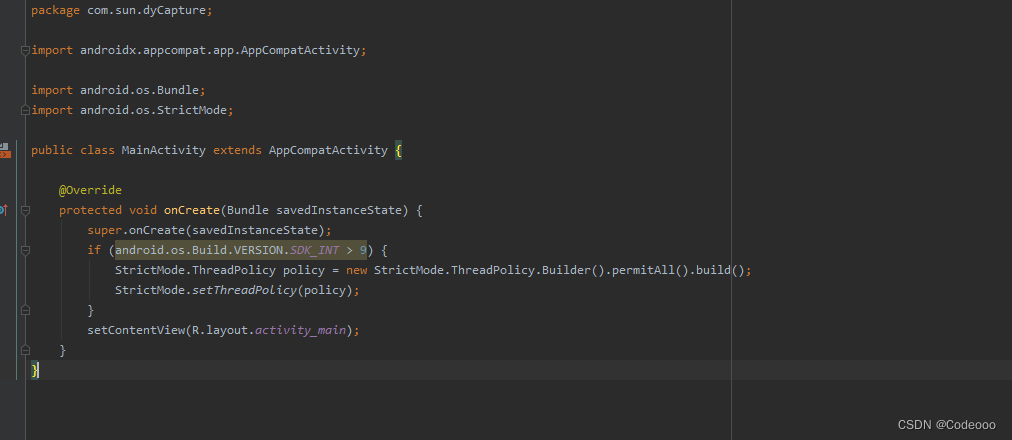
Xposed回发android.os.NetworkOnMainThreadException修复
最近用xposed进行hook回发的时候,又出现了新的问题; android.os.NetworkOnMainThreadException; 在Android4.0以后,写在主线程(就是Activity)中的HTTP请求,运行时都会报错,这是因为…...
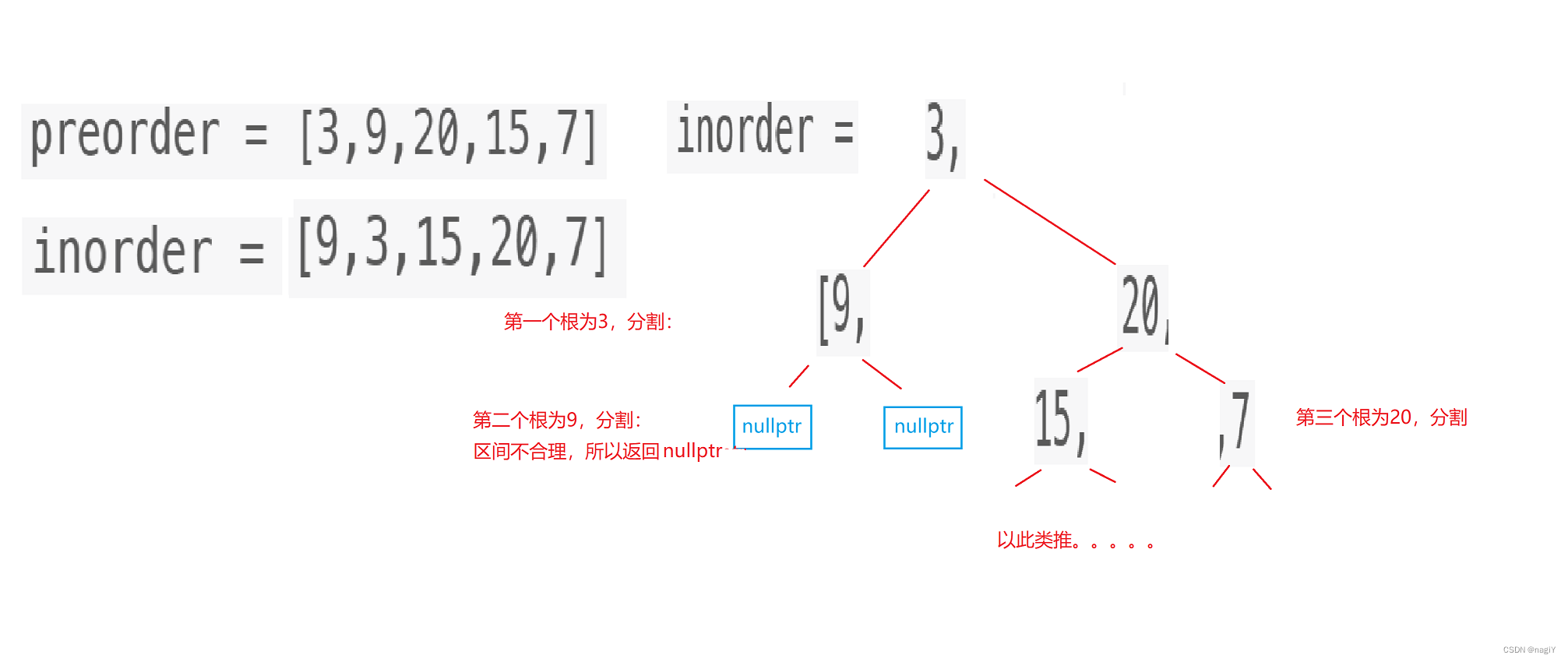
【Leetcode】二叉树的最近公共祖先,二叉搜索树转换成排好序的双向链表,前序遍历与中序遍历构造二叉树
一.二叉树的最近公共祖先 链接 二叉树的最近公共祖先 题目再现 『Ⅰ』思路一:转换成相交链表问题 观察上图,节点1和节点4的最近公共祖先是3,这是不是很像相交链表的问题,关于相交链表,曾经我在另一篇文章里写到过&a…...

途乐证券|互联金融概念爆发,安硕信息“20cm”涨停,高伟达等大涨
互联金融概念4日盘中强势拉升,截至发稿,安硕信息“20cm”涨停,高伟达、卓创资讯、慧博云通涨超12%,恒银科技、极点软件亦涨停,指南针涨超9%,金证股份涨逾7%。 高伟达昨日在投资者互动平台表明,公…...
计数排序算法
计数排序 计数排序说明: 计数排序(Counting Sort)是一种非比较性的排序算法,它通过统计元素出现的次数,然后根据元素出现的次数将元素排列在正确的位置上,从而实现排序。计数排序适用于非负整数或者具有确…...

企业高性能web服务器-nginx
1.nginx简介: nginx是企业高可用的web服务器,nginx也可用来做反向代理服务器器,具有高并发,占用资源少,功能丰富,也可以作为简单的负载均衡。 nginx在企业中的功能: web服务软件 反向代理服务器…...
GaussDB数据库的元数据及其管理简介
目录 一、前言 二、元数据简介 1、元数据定义 2、元数据分类 3、数据库元数据管理 三、GaussDB数据库的元数据管理 1、GaussDB数据库的元数据管理 2、通过“SQL 系统表/系统视图/系统函数”的方式管理(采集)元数据 1)获取表、视图及…...

合并两个有序链表 LeetCode热题100
题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 思路 遍历两个链表比较大小,按从小到大添加到链表即可。 代码 /*** Definition for singly-linked list.* struct ListNode {* int val;* List…...
【C++】模拟实现string
目录 🌞专栏导读 🌛定义string类 🌛构造函数 🌛拷贝构造函数 🌛赋值函数 🌛析构函数 🌛[]操作符重载 🌛c_str、size、capacity函数 🌛比较运算符重载 &#…...

Android 12+ 上 NetworkStatsManager 统计应用流量,为什么你的 queryDetailsForUid 总返回0?
Android 12 流量统计实战:破解 NetworkStatsManager.queryDetailsForUid 返回0的迷局 在开发流量监控类应用时,许多开发者都会遇到一个令人抓狂的问题:明明按照官方文档调用了 queryDetailsForUid 方法,却总是得到0值返回。这就像…...

DiffLinker实战:从环境部署到3D评估的分子骨架跃迁全流程解析
1. DiffLinker环境部署与基础配置 DiffLinker作为一款基于E3等变3D条件扩散模型的分子骨架跃迁工具,其环境部署过程需要特别注意依赖项的版本兼容性。我实测发现,使用conda创建独立环境能有效避免与其他化学信息学工具的冲突。 首先克隆官方仓库…...

别再手动对齐轨迹了!用evo的-a和-s参数,5分钟搞定SLAM轨迹评估与可视化
别再手动对齐轨迹了!用evo的-a和-s参数,5分钟搞定SLAM轨迹评估与可视化 刚接触SLAM或视觉里程计的朋友们,是否曾被这样的场景困扰:明明算法输出的轨迹形状与真实轨迹相似,但两条曲线在坐标系中错位明显,根本…...

5分钟掌握HumanEval:AI代码生成评估的黄金标准工具 [特殊字符]
5分钟掌握HumanEval:AI代码生成评估的黄金标准工具 🚀 【免费下载链接】human-eval Code for the paper "Evaluating Large Language Models Trained on Code" 项目地址: https://gitcode.com/gh_mirrors/hu/human-eval 在人工智能编程…...

ANSYS分析问题:一个或多个远程边界条件的范围限定于大量可能对求解器性能产生不利影响的单元。
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 💌公众号:莱歌数字(B站同名) 📱个人微信:yanshanYH 211、985硕士,从业16年 从…...
)
Vue项目里用ECharts GL 4.8.0搞个炫酷的3D中国地图(带自动轮播和自定义悬浮框)
Vue 3 ECharts GL 4.8.0 打造企业级3D地理可视化组件 最近在数据大屏项目中遇到一个需求:需要在管理后台展示动态3D中国地图,要求支持省区轮播、数据钻取和定制化悬浮框。经过多次迭代,我总结出一套高可复用的解决方案,今天就把核…...

终极指南:如何用AI篮球分析工具快速提升投篮命中率
终极指南:如何用AI篮球分析工具快速提升投篮命中率 【免费下载链接】AI-basketball-analysis :basketball::robot::basketball: AI web app and API to analyze basketball shots and shooting pose. 项目地址: https://gitcode.com/gh_mirrors/ai/AI-basketball-…...

2025届毕业生推荐的六大降AI率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作跟内容创作这个领域当中,文字重复率过于高是较为常见的问题。专业降重…...

Dell Fans Controller:戴尔服务器散热调控的终极解决方案
Dell Fans Controller:戴尔服务器散热调控的终极解决方案 【免费下载链接】dell_fans_controller A tool for control the Dell server fans speed, it sends the control instruction by ipmitool over LAN for Windows, it is a GUI application which is built b…...

QMCDecode终极指南:一键解密QQ音乐加密格式的macOS神器
QMCDecode终极指南:一键解密QQ音乐加密格式的macOS神器 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认…...