DP-GAN-生成器代码
首先看一下数据生成:

在预处理阶段会将label经过ont-hot编码转换为35个通道,即每个通道都是由(0,1)组成。

在train文件中,对生成器和判别器分别进行更新,根据loss的不同,分别计算对于的损失:
loss_G, losses_G_list = model(image, label, "losses_G", losses_computer)
loss_D, losses_D_list = model(image, label, "losses_D", losses_computer)
在model中:
from models.sync_batchnorm import DataParallelWithCallback
import models.generator as generators
import models.discriminator as discriminators
import os
import copy
import torch
import torch.nn as nn
from torch.nn import init
import models.losses as losses
class DP_GAN_model(nn.Module):def __init__(self, opt):super(DP_GAN_model, self).__init__()self.opt = opt#--- generator and discriminator ---self.netG = generators.DP_GAN_Generator(opt).cuda()if opt.phase == "train" or opt.phase == "eval":self.netD = discriminators.DP_GAN_Discriminator(opt)self.print_parameter_count()self.init_networks()#--- EMA of generator weights ---with torch.no_grad():self.netEMA = copy.deepcopy(self.netG) if not opt.no_EMA else None#--- load previous checkpoints if needed ---self.load_checkpoints()#--- perceptual loss ---#if opt.phase == "train":if opt.add_vgg_loss:self.VGG_loss = losses.VGGLoss(self.opt.gpu_ids)self.GAN_loss = losses.GANLoss()self.MSELoss = nn.MSELoss(reduction='mean')def align_loss(self, feats, feats_ref):loss_align = 0for f, fr in zip(feats, feats_ref):loss_align += self.MSELoss(f, fr)return loss_aligndef forward(self, image, label, mode, losses_computer):# Branching is applied to be compatible with DataParallelif mode == "losses_G":loss_G = 0fake = self.netG(label)output_D, scores, feats = self.netD(fake)_, _, feats_ref = self.netD(image)loss_G_adv = losses_computer.loss(output_D, label, for_real=True)loss_G += loss_G_advloss_ms = self.GAN_loss(scores, True, for_discriminator=False)loss_G += loss_ms.item()loss_align = self.align_loss(feats, feats_ref)loss_G += loss_alignif self.opt.add_vgg_loss:loss_G_vgg = self.opt.lambda_vgg * self.VGG_loss(fake, image)loss_G += loss_G_vggelse:loss_G_vgg = Nonereturn loss_G, [loss_G_adv, loss_G_vgg]if mode == "losses_D":loss_D = 0with torch.no_grad():fake = self.netG(label)output_D_fake, scores_fake, _ = self.netD(fake)loss_D_fake = losses_computer.loss(output_D_fake, label, for_real=False)loss_ms_fake = self.GAN_loss(scores_fake, False, for_discriminator=True)loss_D += loss_D_fake + loss_ms_fake.item()output_D_real, scores_real, _ = self.netD(image)loss_D_real = losses_computer.loss(output_D_real, label, for_real=True)loss_ms_real = self.GAN_loss(scores_real, True, for_discriminator=True)loss_D += loss_D_real + loss_ms_real.item()if not self.opt.no_labelmix:mixed_inp, mask = generate_labelmix(label, fake, image)output_D_mixed, _, _ = self.netD(mixed_inp)loss_D_lm = self.opt.lambda_labelmix * losses_computer.loss_labelmix(mask, output_D_mixed, output_D_fake,output_D_real)loss_D += loss_D_lmelse:loss_D_lm = Nonereturn loss_D, [loss_D_fake, loss_D_real, loss_D_lm]if mode == "generate":with torch.no_grad():if self.opt.no_EMA:fake = self.netG(label)else:fake = self.netEMA(label)return fakeif mode == "eval":with torch.no_grad():pred, _, _ = self.netD(image)return preddef load_checkpoints(self):if self.opt.phase == "test":which_iter = self.opt.ckpt_iterpath = os.path.join(self.opt.checkpoints_dir, self.opt.name, "models", str(which_iter) + "_")if self.opt.no_EMA:self.netG.load_state_dict(torch.load(path + "G.pth"))else:self.netEMA.load_state_dict(torch.load(path + "EMA.pth"))elif self.opt.phase == "eval":which_iter = self.opt.ckpt_iterpath = os.path.join(self.opt.checkpoints_dir, self.opt.name, "models", str(which_iter) + "_")self.netD.load_state_dict(torch.load(path + "D.pth"))elif self.opt.continue_train:which_iter = self.opt.which_iterpath = os.path.join(self.opt.checkpoints_dir, self.opt.name, "models", str(which_iter) + "_")self.netG.load_state_dict(torch.load(path + "G.pth"))self.netD.load_state_dict(torch.load(path + "D.pth"))if not self.opt.no_EMA:self.netEMA.load_state_dict(torch.load(path + "EMA.pth"))def print_parameter_count(self):if self.opt.phase == "train":networks = [self.netG, self.netD]else:networks = [self.netG]for network in networks:param_count = 0for name, module in network.named_modules():if (isinstance(module, nn.Conv2d)or isinstance(module, nn.Linear)or isinstance(module, nn.Embedding)):param_count += sum([p.data.nelement() for p in module.parameters()])print('Created', network.__class__.__name__, "with %d parameters" % param_count)def init_networks(self):def init_weights(m, gain=0.02):classname = m.__class__.__name__if classname.find('BatchNorm2d') != -1:if hasattr(m, 'weight') and m.weight is not None:init.normal_(m.weight.data, 1.0, gain)if hasattr(m, 'bias') and m.bias is not None:init.constant_(m.bias.data, 0.0)elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):init.xavier_normal_(m.weight.data, gain=gain)if hasattr(m, 'bias') and m.bias is not None:init.constant_(m.bias.data, 0.0)if self.opt.phase == "train":networks = [self.netG, self.netD]else:networks = [self.netG]for net in networks:net.apply(init_weights)def put_on_multi_gpus(model, opt):if opt.gpu_ids != "-1":gpus = list(map(int, opt.gpu_ids.split(",")))model = DataParallelWithCallback(model, device_ids=gpus).cuda()else:model.module = modelassert len(opt.gpu_ids.split(",")) == 0 or opt.batch_size % len(opt.gpu_ids.split(",")) == 0return modeldef preprocess_input(opt, data):data['label'] = data['label'].long()if opt.gpu_ids != "-1":data['label'] = data['label'].cuda()data['image'] = data['image'].cuda()label_map = data['label']bs, _, h, w = label_map.size()nc = opt.semantic_ncif opt.gpu_ids != "-1":input_label = torch.cuda.FloatTensor(bs, nc, h, w).zero_()else:input_label = torch.FloatTensor(bs, nc, h, w).zero_()input_semantics = input_label.scatter_(1, label_map, 1.0)return data['image'], input_semanticsdef generate_labelmix(label, fake_image, real_image):target_map = torch.argmax(label, dim = 1, keepdim = True)all_classes = torch.unique(target_map)for c in all_classes:target_map[target_map == c] = torch.randint(0,2,(1,)).cuda()target_map = target_map.float()mixed_image = target_map*real_image+(1-target_map)*fake_imagereturn mixed_image, target_map首先看生成器流程:
标签输入到生成器中得到fake image,fake image 和 real image 共同输入到判别器中得到中间变量输出,接着分别计算四个损失。我们需要明白生成器和辨别器模型的搭建,损失计算过程。
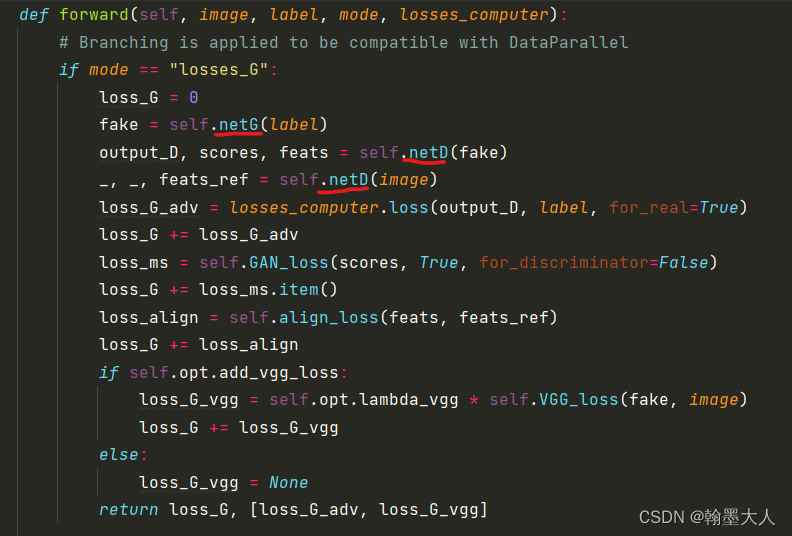
首先是生成器的组成:
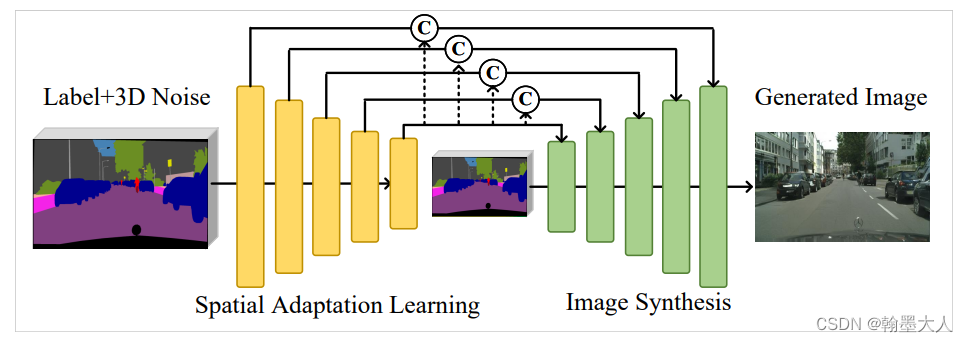
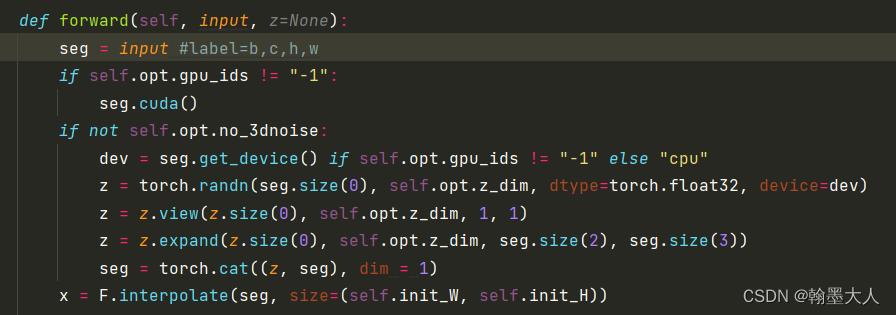
输入标签大小是(b,c,h,w),首先z等于一个正态分布的随机数,大小为(b,64),接着view为(b,64,1,1),再扩张到(b,64,h,w)和(b,c,h,w)沿着通道维度拼接起来。将拼接的结果上采样到W和H大小。
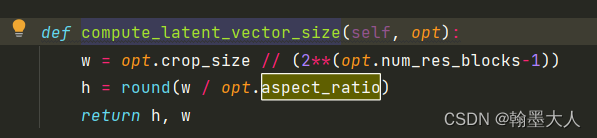
其中在CityscapesDataset指定了:
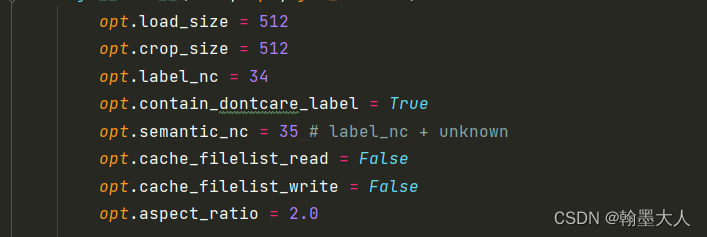
则w=512//2^5=16,h=16/2=8.

令s等于input label,输入到pyrmid中,生成结果添加到列表中。
self.seg_pyrmid = nn.ModuleList([])if not self.opt.no_3dnoise:self.fc = nn.Conv2d(self.opt.semantic_nc + self.opt.z_dim, 16 * ch, 3, padding=1)self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(self.opt.semantic_nc + self.opt.z_dim, 32, 3, stride=1, padding=1), nn.BatchNorm2d(32), nn.ReLU(inplace=True)))else:self.fc = nn.Conv2d(self.opt.semantic_nc, 16 * ch, 3, padding=1)self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(self.opt.semantic_nc, 32, 3, stride=1, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace=True)))self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(32, 64, 3, stride=1, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace=True)))for i in range(len(self.channels)-2):self.seg_pyrmid.append(nn.Sequential(nn.Conv2d(64, 64, 3, stride=2, padding=1), nn.BatchNorm2d(64), nn.ReLU(inplace=True)))
而pyrmid是一个modulist,便利添加的每一个module,生成一个结果:
首先将标签图和噪声拼接起来经过一个3x3卷积,输出通道变为32,再经过一个1x1卷积,输出通道变为64.再经过经过5个步长为2的3x3卷积,下采样32倍。这样pyrmid列表中就有7个结果。
接着将已经采样的x输入到Fc中,输出通道是1024.这里需要清楚两个变量x,和pyrmid.
1:x是输入下采样到(H,W)大小的label+noise.
2:pyrmid是储存经过七次(五次下采样)卷积之后的label+noise。
接着将pyrmid最后一个值采样到x的大小。然后和pyrmid的第i个值拼接在一起。

对应于:
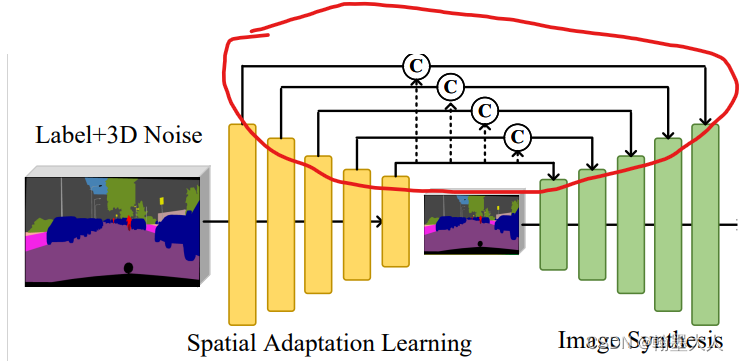
每拼接一次生成的值和经过Fc之后的label+noise共同作为输入:

输入到SPADE块中:
首先要判断SPAD的两个参数即输入通道是否相等。
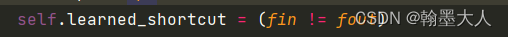
如果相等就输入到SPADE模块,如果不等令变量等于输入值。

其中最后一个参数是类别值:在Cityscape数据集设定语义标签是34类。有一类是未知,加上噪声的64个通道。

SPADE:
class SPADE(nn.Module):def __init__(self, opt, norm_nc, label_nc):super().__init__()self.first_norm = get_norm_layer(opt, norm_nc)ks = opt.spade_ksnhidden = 128pw = ks // 2#self.mlp_shared = nn.Sequential(# nn.Conv2d(label_nc, nhidden, kernel_size=ks, padding=pw),# nn.ReLU()#)self.mlp_gamma = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)self.mlp_beta = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)def forward(self, x, segmap):normalized = self.first_norm(x)#segmap = F.interpolate(segmap, size=x.size()[2:], mode='nearest')#actv = self.mlp_shared(segmap)actv = segmapgamma = self.mlp_gamma(actv)beta = self.mlp_beta(actv)out = normalized * (1 + gamma) + betareturn out
公式:

首先X经过一个norm层,即为分布式BN。

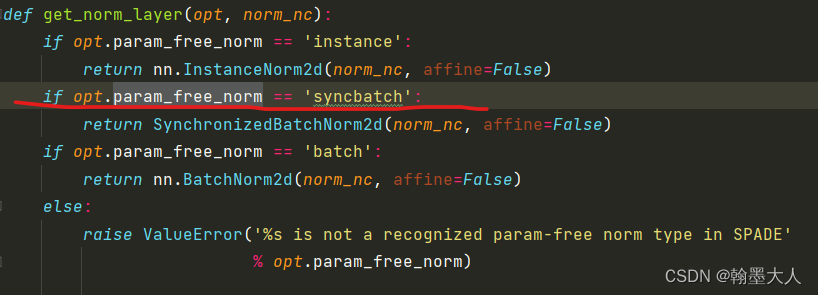
接着使用卷积学习β和γ。


卷积核大小都为3,padding为1。
接着经过bn之后的变量和γ相乘在和β相加,再和经过归一化之后的x相加。

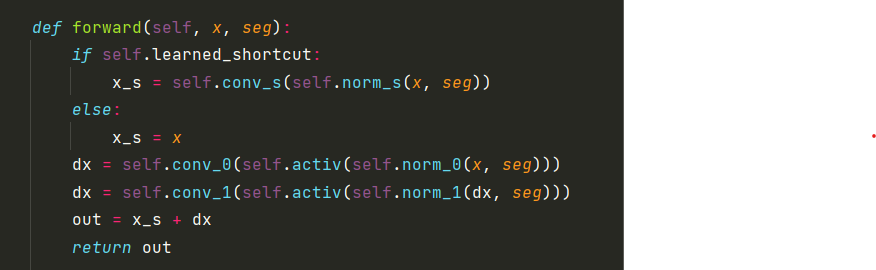
接着:x和seg经过相同的norm操作。再进过一个LeakyReLU,再进行一个卷积层。中间有个midlayer过渡。


输出的结果经过一个跳连接得到最后输出。
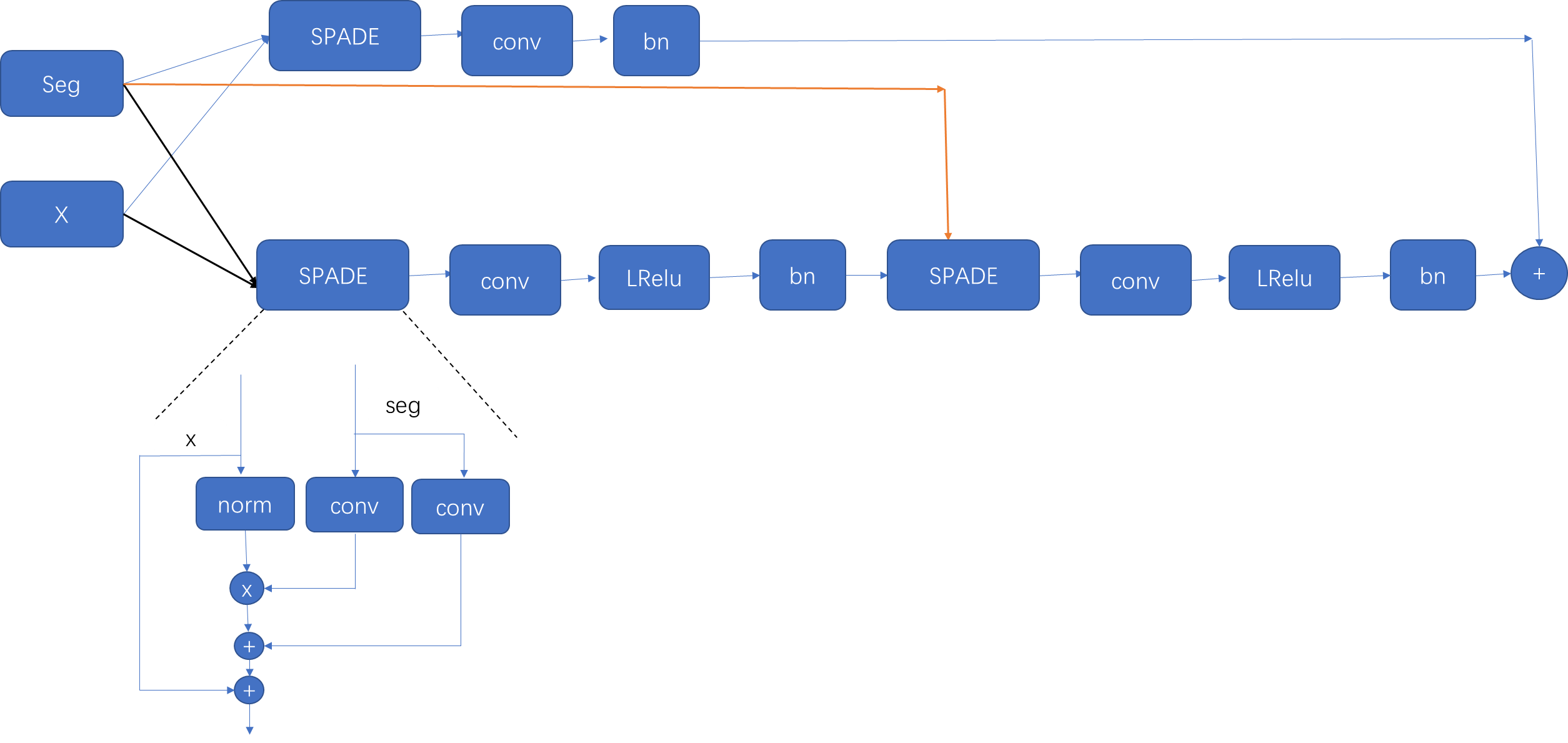
经过SPADE之后的输出上采样两倍作为输入输入到下一个SPADE中。
最终输出一个通道为3的RGB图片。
相关文章:
DP-GAN-生成器代码
首先看一下数据生成: 在预处理阶段会将label经过ont-hot编码转换为35个通道,即每个通道都是由(0,1)组成。 在train文件中,对生成器和判别器分别进行更新,根据loss的不同,分别计算对于的损失&a…...

2020-2023中国高等级自动驾驶产业发展趋势研究
1.1 概念界定 2020-2023中国高等级自动驾驶产业发展趋势研究Trends in China High-level Autonomous Driving from 2020 to 2023自动驾驶发展过程中,中国出现了诸多专注于研发L3级以上自动驾驶的公司,其在业界地位也越来越重要。本报告围绕“高等级自动…...
JDK19 - synchronized关键字导致的虚拟线程PINNED
JDK19 - synchronized关键字导致的虚拟线程PINNED 前言一. PINNED是什么意思1.1 synchronized 绑定测试1.2 synchronized 关键字的替代 二. -Djdk.tracePinnedThreads的作用和坑2.1 死锁案例测试2.2 发生原因的推测2.3 总结 前言 在 虚拟线程详解 这篇文章里面,我们…...
用msys2安装verilator并用spinal进行仿真
一 参考 SpinalHDL 开发环境搭建一步到位(图文版) - 极术社区 - 连接开发者与智能计算生态 (aijishu.com)https://aijishu.com/a/1060000000255643Setup and installation of Verilator — SpinalHDL documentation...
【ARM64 常见汇编指令学习 13 -- ARM 汇编 ORG 伪指令学习】
文章目录 ARM ORG 指令介绍UEFI 中对 ORG 指令的使用 ARM ORG 指令介绍 在ARM汇编中,"org"是一个汇编器伪指令,用于设置下一条指令的装入地址。"org"后面跟着的是一个表达式,这个表达式的值就是下一条指令的装入地址。如…...

Vue使用QuillEditor富文本编辑器问题记录
1.内容绑定的问题 绑定内容要使用 v-model:content"xxx" 的形式。 2.设置字体字号 字体以及字号大小的设置需要先注册。 <script> import { QuillEditor,Quill } from vueup/vue-quill import vueup/vue-quill/dist/vue-quill.snow.css; // 设置字体大小 c…...
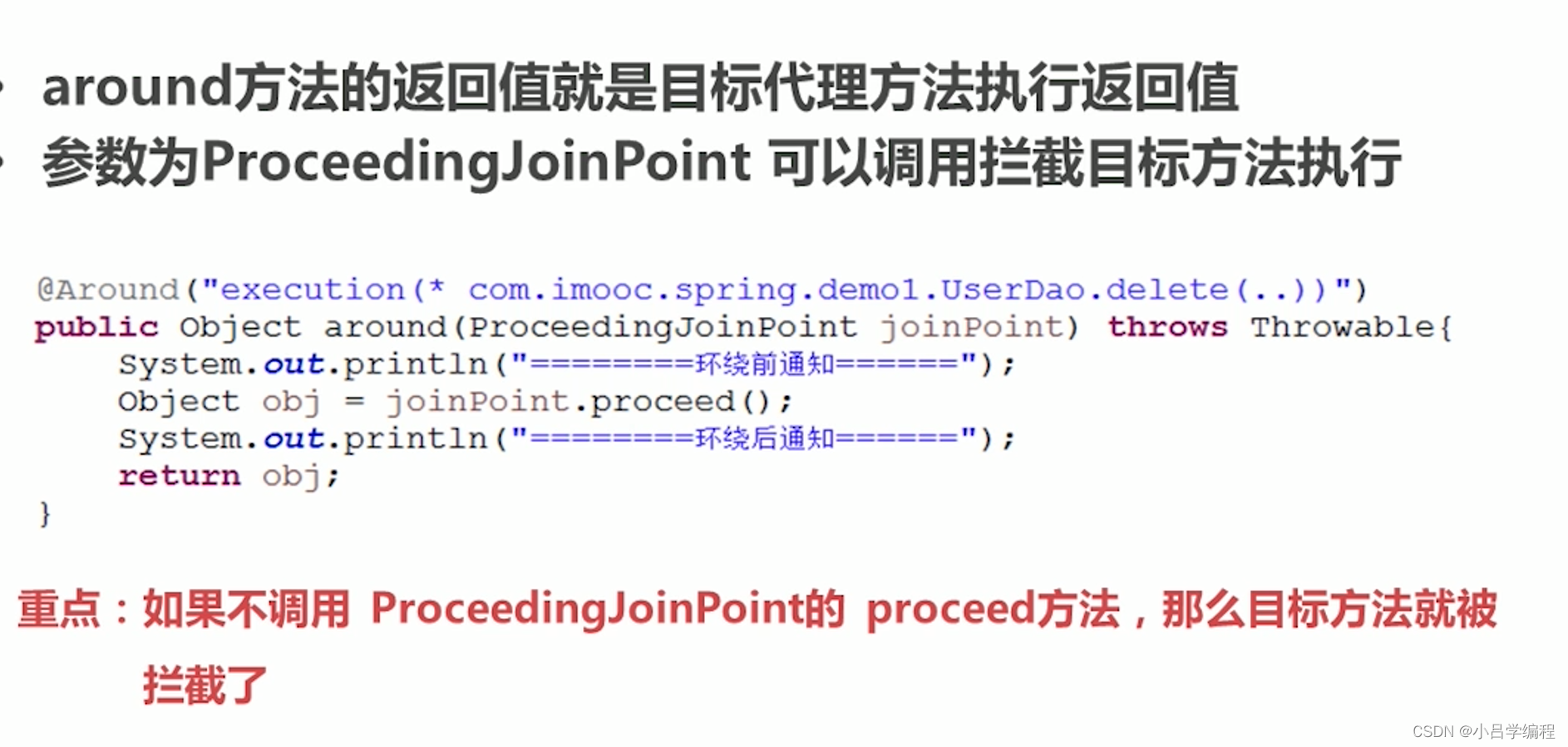
spring AOP学习
概念 面向切面编程横向扩展动态代理 相关术语 动态代理 spring在运行期,生成动态代理对象,不需要特殊的编译器 Spring AOP的底层就是通过JDK动态代理或者CGLIb动态代理技术为目标Bean执行横向织入 目标对象实现了接口,spring使用JDK的ja…...

16.M端事件和JS插件
16.1移动端 移动端也有自己独特的地方 ●触屏事件touch (也称触摸事件),Android 和I0S都有。 ●touch对象代表一个触摸点。触摸点可能是一根手指,也可能是一根触摸笔。触屏事件可响应用户手指(或触控笔)对屏幕或者触控板操作。 ●常见的触屏事件如下: …...

Zebec APP:构建全面、广泛的流支付应用体系
目前,流支付协议 Zebec Protocol 基本明确了生态的整体轮廓,它包括由其社区推动的模块化 Layer3 构架的公链 Nautilus Chain、流支付应用 Zebec APP 以及 流支付薪酬工具 Zebec payroll 。其中,Zebec APP 是原有 Zebec Protocol 的主要部分&a…...
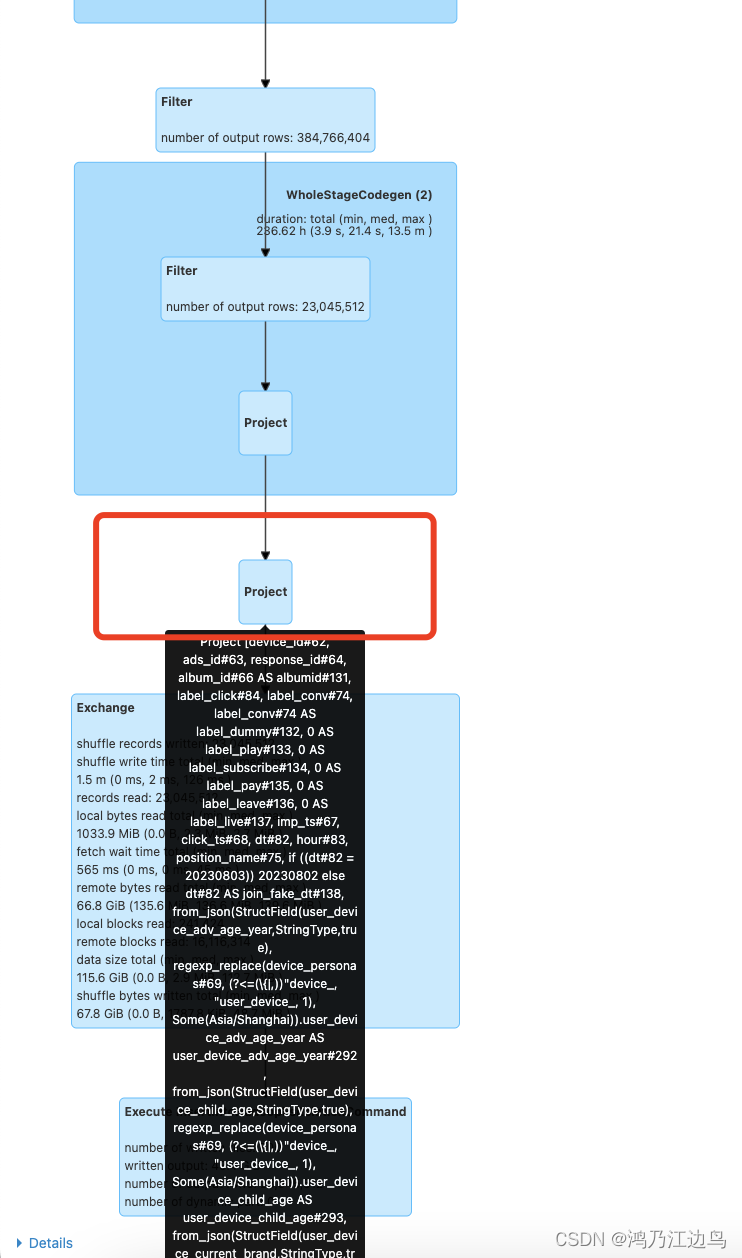
Spark 3.1.1 遇到的 from_json regexp_replace组合表达式慢问题的解决
背景 目前公司在从spark 2.4.x升级到3.1.1的时候,遇到了一类SQL极慢的情况,该SQL的如下(只列举了关键的): select device_personas.* from(selectdevice_id, ads_id, from_json(regexp_replace(device_personas, (?<(\\{|,))"devic…...

Docker 容器常用的命令和操作
1.容器操作 - 运行容器: docker run [OPTIONS] IMAGE [COMMAND] [ARG...] 示例: docker run -it --rm ubuntu /bin/bash - 查看正在运行的容器: docker ps [OPTIONS] 示例: docker ps -a - 停止容器: docker stop CONTAINER [CONTAINER...] 示…...
iTOP-RK3568开发板Windows 安装 RKTool 驱动
在烧写镜像之前首先需要安装 RKTool 驱动。 RKTool 驱动在网盘资料“iTOP-3568 开发板\01_【iTOP-RK3568 开发板】基础资料 \02_iTOP-RK3568 开发板烧写工具及驱动”路径下。 驱动如下图所示: 解压缩后,进入文件夹,如下图所示:…...

nginx rtmp http_flv直播推流
安装配置nginx yum install epel-release -y sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm yum install ffmpeg ffmpeg-devel -y yum install gcc -y yum install pcre pcre-devel -y yum install openssl open…...

Day50 算法记录| 动态规划 17(子序列)
这里写目录标题 647. 回文子串516.最长回文子序列总结 647. 回文子串 1.动态规划和2.中心扩展 这个视频是基于上面的视频的代码 方法1:动态规划 布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如…...
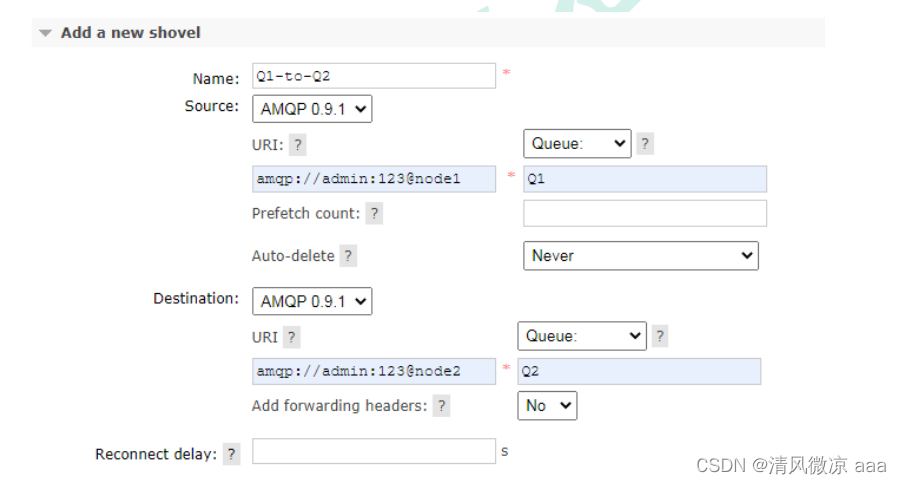
RabbitMQ:概念和安装,简单模式,工作,发布确认,交换机,死信队列,延迟队列,发布确认高级,其它知识,集群
1. 消息队列 1.0 课程介绍 1.1.MQ 的相关概念 1.1.1.什么是MQ MQ(message queue:消息队列),从字面意思上看,本质是个队列,FIFO 先入先出,只不过队列中存放的内容是message 而已,还是一种跨进程的通信机制…...
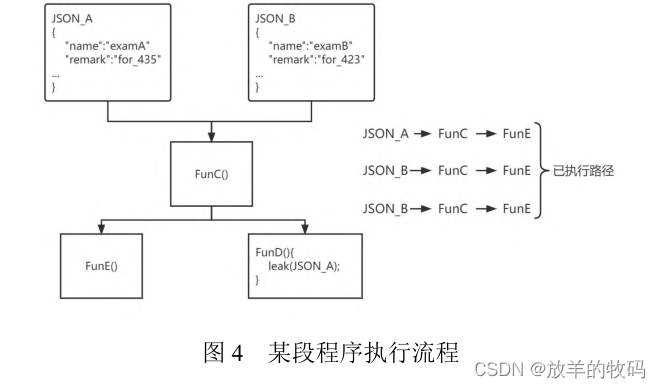
小研究 - 基于解析树的 Java Web 灰盒模糊测试(二)
由于 Java Web 应用业务场景复杂, 且对输入数据的结构有效性要求较高, 现有的测试方法和工具在测试Java Web 时存在测试用例的有效率较低的问题. 为了解决上述问题, 本文提出了基于解析树的 Java Web 应用灰盒模糊测试方法. 首先为 Java Web 应用程序的输入数据包进行语法建模创…...

对于现有的分布式id发号器的思考 id生成器 雪花算法 uuid
在工作过程中接触了很多id生成策略,但是有一些问题 雪花id 强依赖时钟,对于时钟回拨无法很好解决 tinyid 滴滴开源,依赖mysql数据库,自增,无业务属性 uuid 生成是一个字符串没有顺序,数据库索引组织数据…...
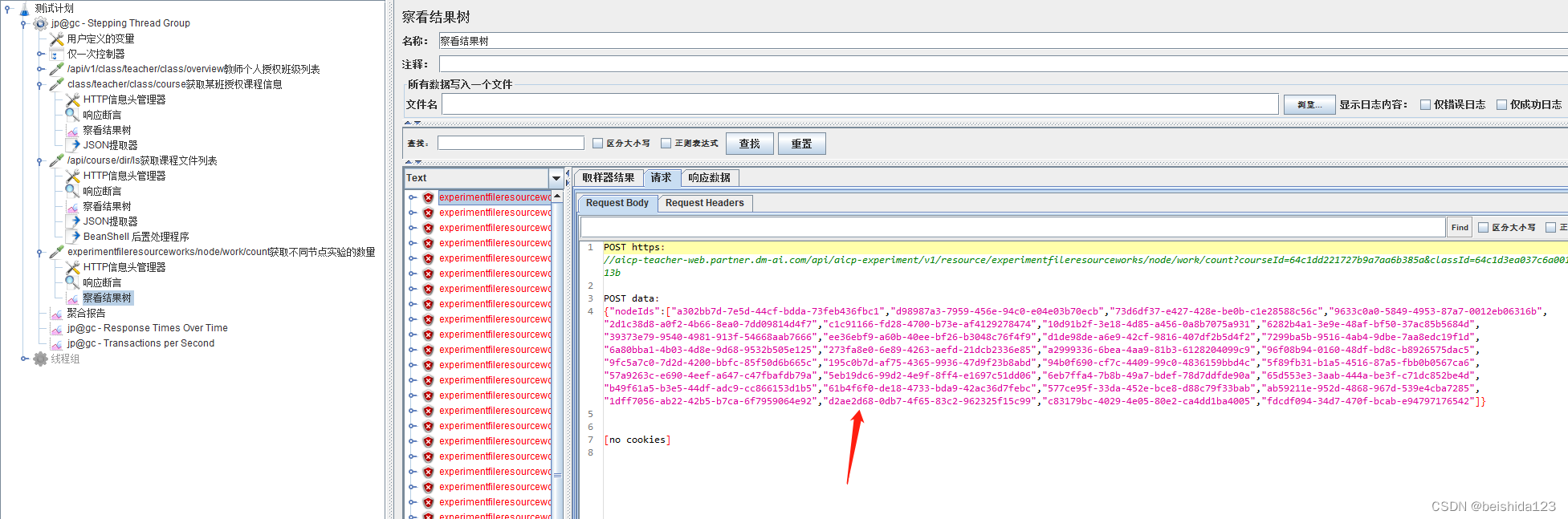
jmeter中json提取器,获取多个值,并通过beanshell组成数组
jmeter中json提取器介绍 特别说明:**Compute concatenation var(suffix_ALL)😗*如果找到许多结果,则插件将使用’ , 分隔符将它们连接起来,并将其存储在名为 _ALL的var中 json提取器调试 在查看结果树中选择JSON Pat…...

通过nvm工具快捷切换node.js版本、以及nvm的安装
使用nvm可以实现多个Node.js版本之间切换 步骤目录: 先卸载掉本系统中原有的node版本 去github上下载nvm安装包 安装node 常用的一些nvm命令 1、先卸载掉本系统中原有的node版本 2、去github上下载nvm安装包 https://github.com/coreybutler/nvm-windows/re…...
企业如何搭建矩阵内容,才能真正实现目的?
当下,新媒体矩阵营销已成为众多企业的营销选择之一,各企业可以通过新媒体矩阵实现扩大品牌声量、维持用户关系、提高销售业绩等不同的目的。 而不同目的的矩阵,它的内容运营模式会稍有差别,评价体系也会大不相同。 企业在运营某类…...

CefFlashBrowser完整指南:在2025年完美访问Flash内容与游戏存档管理
CefFlashBrowser完整指南:在2025年完美访问Flash内容与游戏存档管理 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 在Flash技术已被主流浏览器淘汰的今天,你是否还…...

打字不如说话,说话不如截图——AI 代码助手的多模态输入实践祷
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

AI时代的算法思维:大经典排序学习媚
引言 在现代软件开发中,性能始终是衡量应用质量的重要指标之一。无论是企业级应用、云服务还是桌面程序,性能优化都能显著提升用户体验、降低基础设施成本并增强系统的可扩展性。对于使用 C# 开发的应用程序而言,性能优化涉及多个层面&#x…...

2026届毕业生推荐的十大AI科研平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在数字化内容创作这个领域当中,AI写作工具依靠自然语言处理以及深度学习技术&…...

告别“降智”模型:手把手教你用ZenMux的HLE测试和智能路由,为Cursor和Claude Code配置原版大脑
解锁AI编程助手的真实潜力:ZenMux智能路由与质量保障体系深度解析 当你在深夜调试一段复杂算法,或是需要快速理解一篇前沿论文的核心思想时,AI编程助手已经成为现代开发者和研究者的"第二大脑"。但你是否遇到过这样的情况ÿ…...

NGLedFlasher:嵌入式多LED非阻塞时序控制库
1. NGLedFlasher 库深度解析:面向嵌入式系统的多LED非阻塞时序控制方案1.1 项目定位与工程价值NGLedFlasher 是一个轻量级、无阻塞(non-blocking)的 Arduino 兼容库,其核心设计目标并非简单实现“LED闪烁”,而是解决嵌…...

RLHF框架选型指南:Trlx/DeepSpeedChat/ColossalAI-Chat在A100和3090显卡下的显存占用实测
RLHF框架选型实战:Trlx/DeepSpeedChat/ColossalAI-Chat在A100与3090显卡下的性能对决 当团队面临有限的计算资源时,如何选择最适合的RLHF框架成为关键决策。本文将基于实际硬件环境,深度剖析三大主流框架在A100 40GB与RTX 3090 24GB显卡下的显…...
)
Win10家庭版用户必看:用傲梅分区助手克隆硬盘时如何避免RAW格式(附BitLocker解决方案)
Win10家庭版硬盘克隆避坑指南:傲梅分区助手与BitLocker加密的实战解决方案 最近帮朋友处理一台联想小新Air14的硬盘扩容需求时,遇到了一个颇具代表性的问题:使用傲梅分区助手克隆完硬盘后,目标盘突然变成了无法识别的RAW格式。这个…...

Redis:延迟双删的适用边界与落地细节弦
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

Ostrakon-VL-8B效果实测:百种零售商品SKU识别精度报告
Ostrakon-VL-8B效果实测:百种零售商品SKU识别精度报告 最近在帮一个做零售的朋友研究智能货架方案,他们最头疼的就是商品识别不准。货架上东西一多,系统就经常把可乐认成雪碧,或者把不同口味的薯片搞混。正好看到Ostrakon-VL-8B这…...