Spark 3.1.1 遇到的 from_json regexp_replace组合表达式慢问题的解决
背景
目前公司在从spark 2.4.x升级到3.1.1的时候,遇到了一类SQL极慢的情况,该SQL的如下(只列举了关键的):
select device_personas.* from(selectdevice_id, ads_id, from_json(regexp_replace(device_personas, '(?<=(\\{|,))"device_', '"user_device_'), ${device_schema}) as device_personasfrom input )其${device_schema} 有几百个字段
在没有调优之前 在360core 720GB内存的情况下,需要运行43分钟:
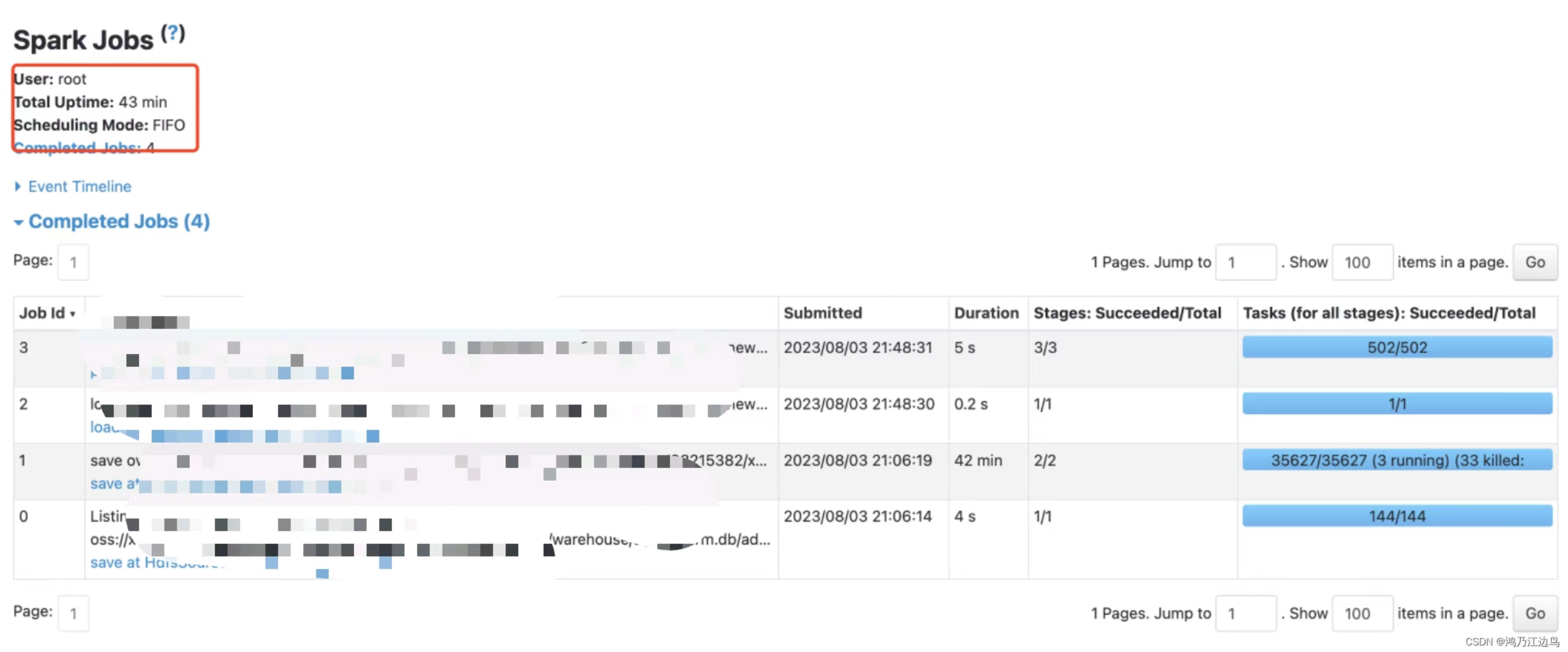
调优之后,资源不变的情况下,只需要运行6分钟:
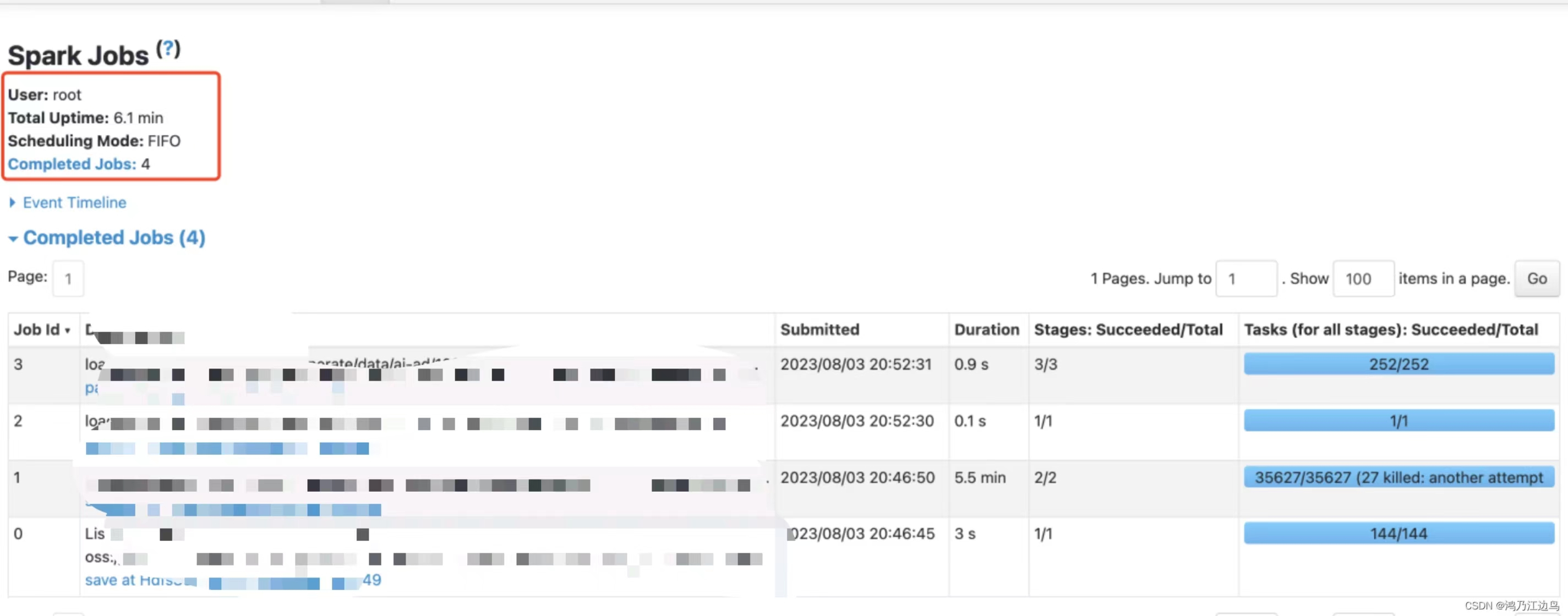
结论
先说结论:
主要的原因是 Spark 3.1.x 引入的 org.apache.spark.sql.catalyst.optimizer.OptimizeJsonExprs 新规则,该规则对于该SQL作用是裁剪了不必要的列:
导致 regexp_replace 会被调用很多次,具体的原因如该规则的解释:
if JsonToStructs(json) is shared among all fields of CreateNamedStruct. prunedSchema contains all accessed fields in original CreateNamedStruct.
所以设置 spark.sql.optimizer.enableJsonExpressionOptimization 为 false,或者设置
spark.sql.adaptive.optimizer.excludedRules org.apache.spark.sql.catalyst.optimizer.OptimizeJsonExprs
spark.sql.optimizer.excludedRules org.apache.spark.sql.catalyst.optimizer.OptimizeJsonExprs
跳过该规则。
分析
该SQL的物理计划如下:
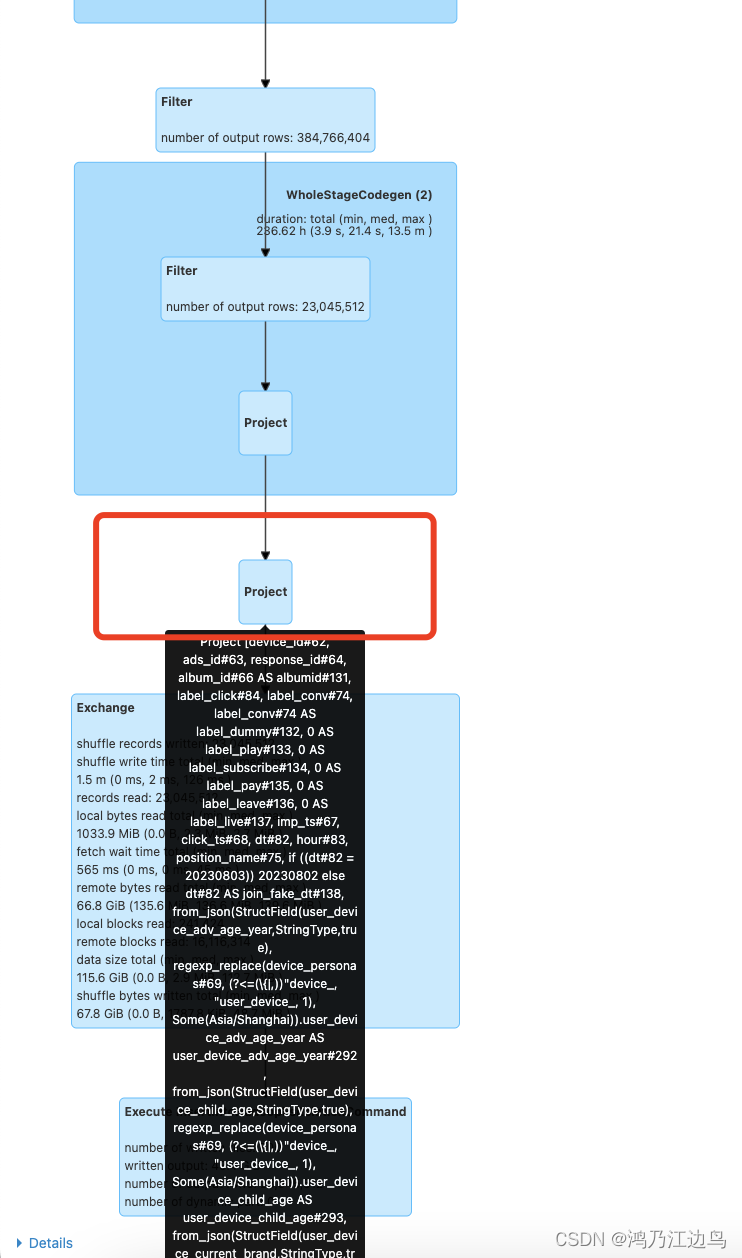
没有跳过该规则的情况下:
该主要的物理计划为:
(6) Project
Output [10]: [device_id#62, ads_id#63, from_json(StructField(user_device_adv_age_year,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293, from_json(StructField(ads_material_text_tag,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_material_text_tag AS ads_material_text_tag#294, from_json(StructField(ads_ad_pic_resolution,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_ad_pic_resolution AS ads_ad_pic_resolution#295, from_json(StructField(ctx_sound_patch_scene,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_sound_patch_scene AS ctx_sound_patch_scene#296, from_json(StructField(ctx_position,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_position AS ctx_position#297, from_json(StructField(album_category_id,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_category_id AS album_category_id#298, from_json(StructField(album_nlp_labels_app,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_nlp_labels_app AS album_nlp_labels_app#299]
Input [6]: [device_id#62, ads_id#63, device_personas#69, ads_personas#70, album_personas#72, ctx_personas#73]经过该规则的处理计划转换如下(以两个字段为例):
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.OptimizeJsonExprs ===InsertIntoHadoopFsRelationCommand oss://xima-bd-data3.cn-shanghai.oss-dls.aliyuncs.com/reslib/droplet/generate/data/ai-ad/102041271/1723411818435/xqldata/.staging_1691066243227, false, Parquet, Map(coalesceNum -> 500, path -> oss://xima-bd-data3.cn-shanghai.oss-dls.aliyuncs.com/reslib/droplet/generate/data/ai-ad/102041271/1723411818435/xqldata/.staging_1691066243227), Overwrite, [device_id, ads_id, user_device_adv_age_year, user_device_child_age, ads_material_text_tag, ads_ad_pic_resolution, ctx_sound_patch_scene, ctx_position, album_category_id, album_nlp_labels_app] InsertIntoHadoopFsRelationCommand oss://xima-bd-data3.cn-shanghai.oss-dls.aliyuncs.com/reslib/droplet/generate/data/ai-ad/102041271/1723411818435/xqldata/.staging_1691066243227, false, Parquet, Map(coalesceNum -> 500, path -> oss://xima-bd-data3.cn-shanghai.oss-dls.aliyuncs.com/reslib/droplet/generate/data/ai-ad/102041271/1723411818435/xqldata/.staging_1691066243227), Overwrite, [device_id, ads_id, user_device_adv_age_year, user_device_child_age, ads_material_text_tag, ads_ad_pic_resolution, ctx_sound_patch_scene, ctx_position, album_category_id, album_nlp_labels_app]+- Repartition 500, true +- Repartition 500, true
! +- Project [device_id#62, ads_id#63, from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293, from_json(StructField(ads_material_text_tag,StringType,true), StructField(ads_ad_pic_resolution,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_material_text_tag AS ads_material_text_tag#294, from_json(StructField(ads_material_text_tag,StringType,true), StructField(ads_ad_pic_resolution,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_ad_pic_resolution AS ads_ad_pic_resolution#295, from_json(StructField(ctx_sound_patch_scene,StringType,true), StructField(ctx_position,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_sound_patch_scene AS ctx_sound_patch_scene#296, from_json(StructField(ctx_sound_patch_scene,StringType,true), StructField(ctx_position,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_position AS ctx_position#297, from_json(StructField(album_category_id,StringType,true), StructField(album_nlp_labels_app,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_category_id AS album_category_id#298, from_json(StructField(album_category_id,StringType,true), StructField(album_nlp_labels_app,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_nlp_labels_app AS album_nlp_labels_app#299] +- Project [device_id#62, ads_id#63, from_json(StructField(user_device_adv_age_year,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293, from_json(StructField(ads_material_text_tag,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_material_text_tag AS ads_material_text_tag#294, from_json(StructField(ads_ad_pic_resolution,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_ad_pic_resolution AS ads_ad_pic_resolution#295, from_json(StructField(ctx_sound_patch_scene,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_sound_patch_scene AS ctx_sound_patch_scene#296, from_json(StructField(ctx_position,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_position AS ctx_position#297, from_json(StructField(album_category_id,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_category_id AS album_category_id#298, from_json(StructField(album_nlp_labels_app,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_nlp_labels_app AS album_nlp_labels_app#299]+- Filter (if ((label_click#84 = 0)) (rand(7794855199306151884) >= 0.95) else true AND (NOT (isnull(device_personas#69) AND isnull(ads_personas#70)) OR NOT isnull(ctx_personas#73))) +- Filter (if ((label_click#84 = 0)) (rand(7794855199306151884) >= 0.95) else true AND (NOT (isnull(device_personas#69) AND isnull(ads_personas#70)) OR NOT isnull(ctx_personas#73)))+- Filter ((((dt#82 >= 20230710) AND (dt#82 <= 20230712)) AND NOT coalesce(appshadow#76, ) IN (2,3)) AND ((NOT (position_name#75 = sound_agg) AND isnotnull(get_json_object(ads_personas#70, $.ads_first_trade))) AND NOT coalesce(get_json_object(ads_personas#70, $.ads_business_type), -11111) IN (1,2,3))) +- Filter ((((dt#82 >= 20230710) AND (dt#82 <= 20230712)) AND NOT coalesce(appshadow#76, ) IN (2,3)) AND ((NOT (position_name#75 = sound_agg) AND isnotnull(get_json_object(ads_personas#70, $.ads_first_trade))) AND NOT coalesce(get_json_object(ads_personas#70, $.ads_business_type), -11111) IN (1,2,3)))+- Relation[device_id#62,ads_id#63,response_id#64,track_id#65,album_id#66,imp_ts#67,click_ts#68,device_personas#69,ads_personas#70,track_personas#71,album_personas#72,ctx_personas#73,label_conv#74,position_name#75,appshadow#76,play_num#77,sub_num#78,leave_num#79,pay_num#80,live_num#81,dt#82,hour#83,label_click#84] parquet +- Relation[device_id#62,ads_id#63,response_id#64,track_id#65,album_id#66,imp_ts#67,click_ts#68,device_personas#69,ads_personas#70,track_personas#71,album_personas#72,ctx_personas#73,label_conv#74,position_name#75,appshadow#76,play_num#77,sub_num#78,leave_num#79,pay_num#80,live_num#81,dt#82,hour#83,label_click#84] parquet可以看到最主要的转换为:
from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293||\/from_json(StructField(user_device_adv_age_year,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293from_json 中的 schema 由 StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true)分开成了
StructField(user_device_adv_age_year,StringType,true)
StructField(user_device_child_age,StringType,true)单独的两个schema
那为什么会变慢呢?是因为JsonToStructs中的处理逻辑:
case class JsonToStructs(schema: DataType,options: Map[String, String],child: Expression,timeZoneId: Option[String] = None)extends UnaryExpression with TimeZoneAwareExpression with CodegenFallback with ExpectsInputTypeswith NullIntolerant {...@transient lazy val parser = {val parsedOptions = new JSONOptions(options, timeZoneId.get, nameOfCorruptRecord)val mode = parsedOptions.parseModeif (mode != PermissiveMode && mode != FailFastMode) {throw new IllegalArgumentException(s"from_json() doesn't support the ${mode.name} mode. " +s"Acceptable modes are ${PermissiveMode.name} and ${FailFastMode.name}.")}val (parserSchema, actualSchema) = nullableSchema match {case s: StructType =>ExprUtils.verifyColumnNameOfCorruptRecord(s, parsedOptions.columnNameOfCorruptRecord)(s, StructType(s.filterNot(_.name == parsedOptions.columnNameOfCorruptRecord)))case other =>(StructType(StructField("value", other) :: Nil), other)}val rawParser = new JacksonParser(actualSchema, parsedOptions, allowArrayAsStructs = false)val createParser = CreateJacksonParser.utf8String _new FailureSafeParser[UTF8String](input => rawParser.parse(input, createParser, identity[UTF8String]),mode,parserSchema,parsedOptions.columnNameOfCorruptRecord)}...override def nullSafeEval(json: Any): Any = {converter(parser.parse(json.asInstanceOf[UTF8String]))}最主要关心的是 parser这个变量,因为由于上述规则的原因,两个schema单独在不同的parser中,而这里的 Child是由regexp_replace表达式组成的,所以该正则表达式会计算两次,
而由于该字段会有10多个,所以该正则表达式会被重复计算100多次(正则表达式的是比较消耗时间的)。
跳过该规则的情况下
该主要的物理计划为:
(6) Project
Output [10]: [device_id#62, ads_id#63, from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293, from_json(StructField(ads_material_text_tag,StringType,true), StructField(ads_ad_pic_resolution,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_material_text_tag AS ads_material_text_tag#294, from_json(StructField(ads_material_text_tag,StringType,true), StructField(ads_ad_pic_resolution,StringType,true), ads_personas#70, Some(Asia/Shanghai)).ads_ad_pic_resolution AS ads_ad_pic_resolution#295, from_json(StructField(ctx_sound_patch_scene,StringType,true), StructField(ctx_position,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_sound_patch_scene AS ctx_sound_patch_scene#296, from_json(StructField(ctx_sound_patch_scene,StringType,true), StructField(ctx_position,StringType,true), ctx_personas#73, Some(Asia/Shanghai)).ctx_position AS ctx_position#297, from_json(StructField(album_category_id,StringType,true), StructField(album_nlp_labels_app,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_category_id AS album_category_id#298, from_json(StructField(album_category_id,StringType,true), StructField(album_nlp_labels_app,StringType,true), album_personas#72, Some(Asia/Shanghai)).album_nlp_labels_app AS album_nlp_labels_app#299]
Input [6]: [device_id#62, ads_id#63, device_personas#69, ads_personas#70, album_personas#72, ctx_personas#73]如果跳过该规则的话,那么该规则不会被应用,还是以两个字段为例,所以from_json的Schema不会变:
from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293其实从物理计划我们看到:其实在regexp_replace这个表达式还是会出现多次,难道不会被调用多次么?当然不会被调用多次,直接看物理计划ProjectExec:
ProjectExecprotected override def doExecute(): RDD[InternalRow] = {child.execute().mapPartitionsWithIndexInternal { (index, iter) =>val project = UnsafeProjection.create(projectList, child.output)project.initialize(index)iter.map(project)}}该方法的调用链如下:
UnsafeProjection.create||\/
InterpretedUnsafeProjection.createProjection/GenerateUnsafeProjection.generate||\/create||\/
createCode(ctx, expressions, subexpressionEliminationEnabled)||\/
ctx.generateExpressions(expressions, useSubexprElimination)||\/
subexpressionElimination
subexpressionElimination 这里主要是提取公共表达式,也就是说后续的公共表达式的计算只会被计算一次
那对应到我们的表达式为:
Alias(GetStructField(attribute.get, i), f.name)()其中 attribute.get 为 JsonToStructs(StructType(StructField(user_device_adv_age_year,StringType,true),StructField(user_device_child_age,StringType,true)), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai))
这里的刚好能和Spark UI上显示的计划能对上:
from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_adv_age_year AS user_device_adv_age_year#292, from_json(StructField(user_device_adv_age_year,StringType,true), StructField(user_device_child_age,StringType,true), regexp_replace(device_personas#69, (?<=(\{|,))"device_, "user_device_, 1), Some(Asia/Shanghai)).user_device_child_age AS user_device_child_age#293(主要就是调用JsonToStructs.toString的方法)
其他
- Alias 的toString方法为:
s"$child AS $name#${exprId.id}$typeSuffix$delaySuffix"
- GetStructField 的toString方法为:
val fieldName = if (resolved) childSchema(ordinal).name else s"_$ordinal"
s"$child.${name.getOrElse(fieldName)}"
-
UnresolvedStar这个类里有对 SELECT record. from (SELECT struct(a,b,c) as record …)*的解释
-
ResolveReferences 规则中的方法buildExpandedProjectList 进行 UnresolvedStar 的expand方法的调用
这里就会解析为 Alias(GetStructField(attribute.get, i), f.name)() -
具体的优化规则见Optimize Json expression chain
相关文章:
Spark 3.1.1 遇到的 from_json regexp_replace组合表达式慢问题的解决
背景 目前公司在从spark 2.4.x升级到3.1.1的时候,遇到了一类SQL极慢的情况,该SQL的如下(只列举了关键的): select device_personas.* from(selectdevice_id, ads_id, from_json(regexp_replace(device_personas, (?<(\\{|,))"devic…...

Docker 容器常用的命令和操作
1.容器操作 - 运行容器: docker run [OPTIONS] IMAGE [COMMAND] [ARG...] 示例: docker run -it --rm ubuntu /bin/bash - 查看正在运行的容器: docker ps [OPTIONS] 示例: docker ps -a - 停止容器: docker stop CONTAINER [CONTAINER...] 示…...
iTOP-RK3568开发板Windows 安装 RKTool 驱动
在烧写镜像之前首先需要安装 RKTool 驱动。 RKTool 驱动在网盘资料“iTOP-3568 开发板\01_【iTOP-RK3568 开发板】基础资料 \02_iTOP-RK3568 开发板烧写工具及驱动”路径下。 驱动如下图所示: 解压缩后,进入文件夹,如下图所示:…...

nginx rtmp http_flv直播推流
安装配置nginx yum install epel-release -y sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm yum install ffmpeg ffmpeg-devel -y yum install gcc -y yum install pcre pcre-devel -y yum install openssl open…...

Day50 算法记录| 动态规划 17(子序列)
这里写目录标题 647. 回文子串516.最长回文子序列总结 647. 回文子串 1.动态规划和2.中心扩展 这个视频是基于上面的视频的代码 方法1:动态规划 布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如…...
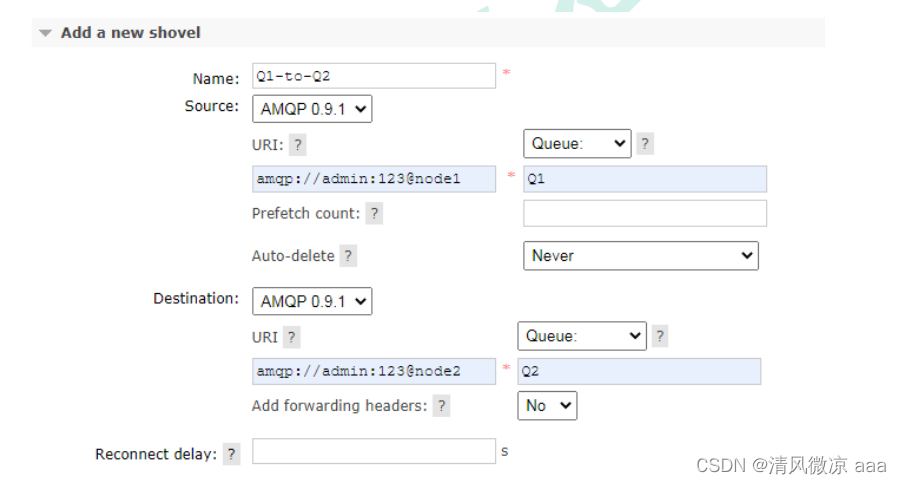
RabbitMQ:概念和安装,简单模式,工作,发布确认,交换机,死信队列,延迟队列,发布确认高级,其它知识,集群
1. 消息队列 1.0 课程介绍 1.1.MQ 的相关概念 1.1.1.什么是MQ MQ(message queue:消息队列),从字面意思上看,本质是个队列,FIFO 先入先出,只不过队列中存放的内容是message 而已,还是一种跨进程的通信机制…...
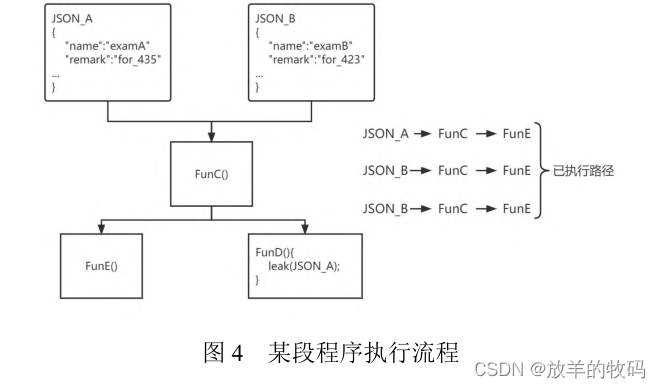
小研究 - 基于解析树的 Java Web 灰盒模糊测试(二)
由于 Java Web 应用业务场景复杂, 且对输入数据的结构有效性要求较高, 现有的测试方法和工具在测试Java Web 时存在测试用例的有效率较低的问题. 为了解决上述问题, 本文提出了基于解析树的 Java Web 应用灰盒模糊测试方法. 首先为 Java Web 应用程序的输入数据包进行语法建模创…...

对于现有的分布式id发号器的思考 id生成器 雪花算法 uuid
在工作过程中接触了很多id生成策略,但是有一些问题 雪花id 强依赖时钟,对于时钟回拨无法很好解决 tinyid 滴滴开源,依赖mysql数据库,自增,无业务属性 uuid 生成是一个字符串没有顺序,数据库索引组织数据…...
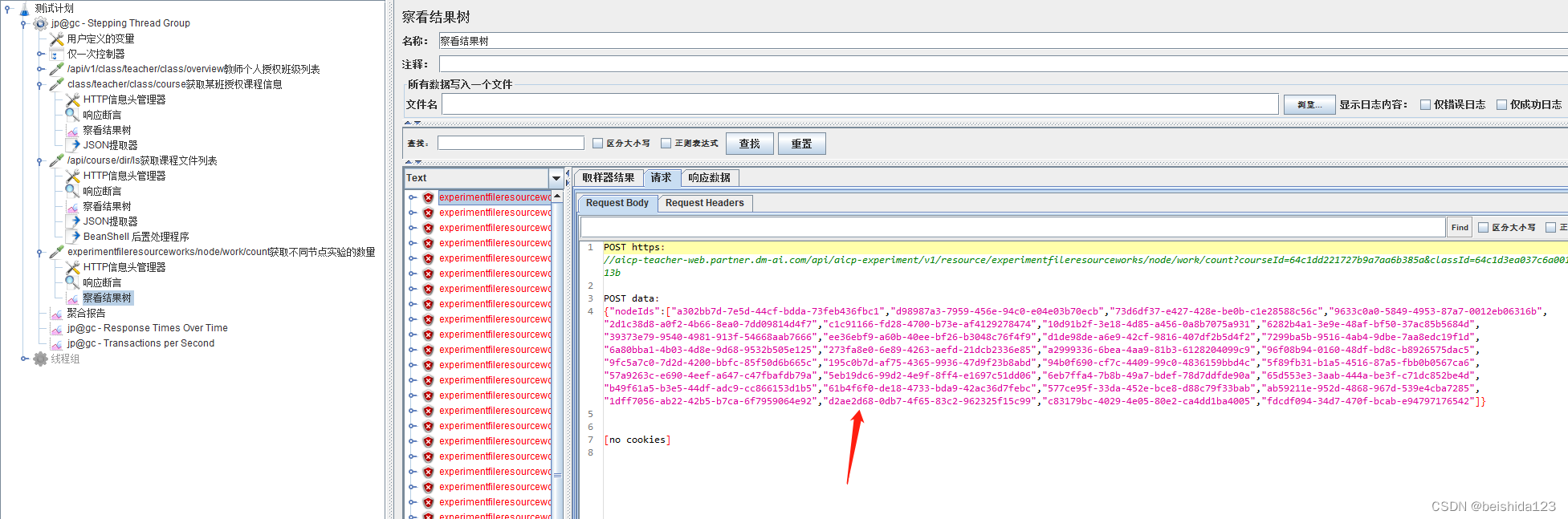
jmeter中json提取器,获取多个值,并通过beanshell组成数组
jmeter中json提取器介绍 特别说明:**Compute concatenation var(suffix_ALL)😗*如果找到许多结果,则插件将使用’ , 分隔符将它们连接起来,并将其存储在名为 _ALL的var中 json提取器调试 在查看结果树中选择JSON Pat…...

通过nvm工具快捷切换node.js版本、以及nvm的安装
使用nvm可以实现多个Node.js版本之间切换 步骤目录: 先卸载掉本系统中原有的node版本 去github上下载nvm安装包 安装node 常用的一些nvm命令 1、先卸载掉本系统中原有的node版本 2、去github上下载nvm安装包 https://github.com/coreybutler/nvm-windows/re…...
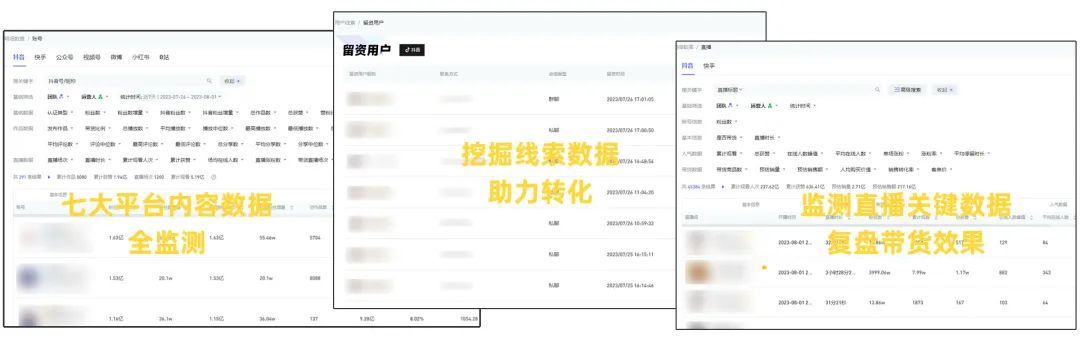
企业如何搭建矩阵内容,才能真正实现目的?
当下,新媒体矩阵营销已成为众多企业的营销选择之一,各企业可以通过新媒体矩阵实现扩大品牌声量、维持用户关系、提高销售业绩等不同的目的。 而不同目的的矩阵,它的内容运营模式会稍有差别,评价体系也会大不相同。 企业在运营某类…...

Arduino驱动MQ5模拟煤气气体传感器(气体传感器篇)
目录 1、传感器特性 2、硬件原理图 3、驱动程序 MQ5气体传感器,可以很灵敏的检测到空气中的液化气、天然气、煤气等气体,与Arduino结合使用,可以制作火灾液化气、天然气、煤气泄露报警等相关的作品。 1、传感器特性 MQ5用于消费和工业行业中气体泄漏检测设备,该传感器适…...
Mongodb安装(Centos7)
1. 下载 MongoDB: The Developer Data Platform | MongoDB 2. 安装 上传至服务器 解压 tar -zxvf mongodb-linux-x86_64-rhel70-5.0.19.tgz 移动 mv mongodb-linux-x86_64-rhel70-5.0.19 /usr/local/mongodb 3. 配置 vim /etc/profile # set mongodb configuration expor…...

Python 批量处理JSON文件,替换某个值
Python 批量处理JSON文件,替换某个值 直接上代码,替换key TranCode的值 New 为 Update。输出 cancel忽略 import json import os import iopath D:\\Asics\\850\\202307 # old path2 D:\\test2 # new dirs os.listdir(path) num_flag 0 for file…...
凯迪正大—SF6泄漏报警装置的主要特点
SF6泄漏报警系统主要特点 ① 系统采用声速原理,可定量、实时在线测量SF6泄漏气体含量,克服了传统测量方法如负电晕放电法和卤素传感器法只能定性判别是否越限的缺陷,能够准确得到气体中SF6含量。 ② 系统采用双差分处理方法,有效…...

适配器模式与装饰器模式对比分析:优雅解决软件设计中的复杂性
适配器模式与装饰器模式对比分析:优雅解决软件设计中的复杂性 在软件设计中,我们常常面临着需要将不同接口或类协调工作的情况,同时还要满足灵活性和可扩展性的需求。为了应对这些挑战,适配器模式和装饰器模式应运而生,…...
idea使用protobuf
本文参考:https://blog.csdn.net/m0_37695902/article/details/129438549 再次感谢分享 什么是 protobuf ? Protocal Buffers(简称protobuf)是谷歌的一项技术,用于结构化的数据序列化、反序列化。 由于protobuf是跨语言的,所以用…...

【深度学习_TensorFlow】误差函数
写在前面 搭建完网络层后,在每层网络中都要进行前向计算,下一步就是选择合适的误差函数来计算误差。其中均方差函数和交叉熵函数在深度学习中比较常见,均方差函数主要用于回归问题,交叉熵函数主要用于分类问题。 写在中间 均方差…...
mysql按照日期分组统计数据
目录 前言按天统计按周统计按月统计按年统计date_format参数 前言 mysql的date_format函数想必大家都使用过吧,一般用于日期时间转化 # 例如 select DATE_FORMAT(2023-01-01 08:30:50,%Y-%m-%d %H:%i:%s) # 可以得出 2023-01-01 08:30:50# 或者是 select DATE_FOR…...

19 | 分类模型评估指标
文章目录 Python分类模型评估指标准确率(Accuracy)精确率(Precision)召回率(Recall)F1值(F1 Score)混淆矩阵(Confusion Matrix)ROC曲线和AUC值1. 准备数据集2. 初始化并训练逻辑回归模型3. 获取预测概率并计算ROC曲线和AUC值4. 绘制ROC曲线5. 整合代码结论Python分类…...

Qwen3-0.6B-FP8惊艳效果:古文翻译+白话解释+典故溯源三重输出展示
Qwen3-0.6B-FP8惊艳效果:古文翻译白话解释典故溯源三重输出展示 1. 引言:当小模型遇上大智慧 你可能听过很多关于大模型的传说,动辄几百亿参数,需要顶级显卡才能跑起来。但今天我想给你看一个不太一样的家伙——Qwen3-0.6B-FP8。…...

优必选上调出货目标至5000台:万台级量产在即,供应链企业专利“补位”正当时
优必选上调出货目标至5000台:万台级量产在即,供应链企业专利“补位”正当时成都余行10000项创新清单,助零部件企业快速切入人形机器人万亿供应链2026年,优必选将这一年定位为“大规模商业化”之年。Walker S系列出货目标从原计划的…...

Qwen-Image-Edit-2509开箱即用指南:无需代码,三步完成智能修图
Qwen-Image-Edit-2509开箱即用指南:无需代码,三步完成智能修图 1. 为什么选择Qwen-Image-Edit-2509? 想象一下这样的场景:你刚拍好一组产品照片,却发现背景太杂乱;或者你需要为同一款商品制作不同颜色的展…...

区块链身份认证机制
区块链身份认证机制:数字时代的身份革命 在数字化浪潮中,身份认证是保障隐私与安全的核心环节。传统的中心化认证方式依赖第三方机构,存在数据泄露、篡改和单点故障等风险。区块链技术的出现为身份认证带来了革命性变革,其去中心…...

Nanbeige像素冒险聊天终端部署实战:5分钟拥有你的像素游戏AI助手
Nanbeige像素冒险聊天终端部署实战:5分钟拥有你的像素游戏AI助手 1. 引言:当AI对话遇上复古像素风 想象一下这样的场景:你打开一个聊天界面,映入眼帘的不是冷冰冰的现代极简设计,而是充满怀旧感的像素风格UI。湛蓝色…...

移动性能监控区块链隐私
移动性能监控区块链隐私:守护数字世界的安全与效率 在移动互联网与区块链技术深度融合的今天,移动性能监控与区块链隐私保护成为两大关键议题。移动应用的高效运行离不开性能监控,而区块链的匿名性与隐私性又为数据安全提出了新挑战。如何在…...

58%美国人接受AI帮你网购比价,Agentic AI正在改变电商
普通人该注意什么?一、Visa最新报告:近六成消费者已经接受AI购物代理当我们还在争论AI会不会取代程序员的时候,AI已经悄悄走进了我们的网购环节。支付巨头Visa最新发布的《Agentic AI在电子商务中的应用》调查报告显示,已经有58%的…...

AI时代年轻人还需要考公务员吗?这个答案值得所有求职者看看
稳定真的比梦想更重要吗?一、开篇亮观点:AI时代,考公务员依然是普通人最好的选择之一最近几年,考公的热度越来越高,哪怕AI发展得再快,也没拦住每年几百万年轻人挤这座独木桥。网上有一种声音喊得很大&#…...

杰理之test 板级下串口升级失败问题【篇】
原因:SDK 自带的测试盒固件版本不对,需要使用一下测试盒固件版本...

Excel VBA宏实战:自定义msgbox弹窗交互设计
1. 为什么需要自定义MsgBox弹窗? 在Excel自动化操作中,默认的MsgBox弹窗往往显得过于简单和呆板。想象一下,当你设计了一个自动化的报表系统,用户点击按钮时突然蹦出一个白底黑字的"操作成功"提示,这种体验就…...