AlexNet卷积神经网络-笔记
AlexNet卷积神经网络-笔记
AlexNet卷积神经网络2012年提出
测试结果为:
通过运行结果可以发现,
在眼疾筛查数据集iChallenge-PM上使用AlexNet,loss能有效下降,
经过5个epoch的训练,在验证集上的准确率可以达到94%左右。
实测准确率为:0.92到0.9350
[validation] accuracy/loss: 0.9275/0.1661
[validation] accuracy/loss: 0.9350/0.2233
S E:\project\python> & D:/ProgramData/Anaconda3/python.exe e:/project/python/PM/AlexNet_PM.py
W0803 14:19:51.270619 6520 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.2, Runtime API Version: 10.2
W0803 14:19:51.290621 6520 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
start training ...
epoch: 0, batch_id: 0, loss is: 1.0486
epoch: 0, batch_id: 20, loss is: 0.5316
[validation] accuracy/loss: 0.9275/0.2720
epoch: 1, batch_id: 0, loss is: 0.2918
epoch: 1, batch_id: 20, loss is: 0.2479
[validation] accuracy/loss: 0.9250/0.3421
epoch: 2, batch_id: 0, loss is: 1.7486
epoch: 2, batch_id: 20, loss is: 0.1236
[validation] accuracy/loss: 0.9350/0.2233
epoch: 3, batch_id: 0, loss is: 0.2802
epoch: 3, batch_id: 20, loss is: 0.3339
[validation] accuracy/loss: 0.9275/0.2186
epoch: 4, batch_id: 0, loss is: 0.0429
epoch: 4, batch_id: 20, loss is: 0.1188
[validation] accuracy/loss: 0.9275/0.1661
W0803 14:34:45.152906 17400 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.2, Runtime API Version: 10.2
W0803 14:34:45.173938 17400 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
#AlexNet 子图层结构
[Conv2D(3, 96, kernel_size=[11, 11], stride=[4, 4], padding=5, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0),
Conv2D(96, 256, kernel_size=[5, 5], padding=2, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0),
Conv2D(256, 384, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(384, 384, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(384, 256, kernel_size=[3, 3], padding=1, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0),
Linear(in_features=12544, out_features=4096, dtype=float32),
Dropout(p=0.5, axis=None, mode=upscale_in_train),
Linear(in_features=4096, out_features=4096, dtype=float32),
Dropout(p=0.5, axis=None, mode=upscale_in_train),
Linear(in_features=4096, out_features=2, dtype=float32)]
(10, 3, 224, 224)
[10, 3, 224, 224]
#AlexNet子图层shape[N,Cout,H,W],w参数[Cout,Ci,Kh,Kw],b参数[Cout]
conv2d_5 [10, 96, 56, 56] [96, 3, 11, 11] [96]
max_pool2d_3 [10, 96, 28, 28]
conv2d_6 [10, 256, 28, 28] [256, 96, 5, 5] [256]
max_pool2d_4 [10, 256, 14, 14]
conv2d_7 [10, 384, 14, 14] [384, 256, 3, 3] [384]
conv2d_8 [10, 384, 14, 14] [384, 384, 3, 3] [384]
conv2d_9 [10, 256, 14, 14] [256, 384, 3, 3] [256]
max_pool2d_5 [10, 256, 7, 7]
linear_3 [10, 4096] [12544, 4096] [4096]
dropout_2 [10, 4096]
linear_4 [10, 4096] [4096, 4096] [4096]
dropout_3 [10, 4096]
linear_5 [10, 2] [4096, 2] [2]
PS E:\project\python>
注意:
conv2d_5 [10, 96, 56, 56] [96, 3, 11, 11] [96]
中H=56,W=56的计算方法如下:
H=((Hold+2P-K)/S)+1=((224+2*5-11)/4)+1=56.75=>56
同理W=56
测试源代码如下所示:
#AlexNet在眼疾筛查数据集iChallenge-PM上具体实现的代码如下所示:
# -*- coding:utf-8 -*-# 导入需要的包
import paddle
import numpy as np
from paddle.nn import Conv2D, MaxPool2D, Linear, Dropout
## 组网
import paddle.nn.functional as F# 定义 AlexNet 网络结构 2012年
class AlexNet(paddle.nn.Layer):def __init__(self, num_classes=1):super(AlexNet, self).__init__()# AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征# 与LeNet不同的是激活函数换成了‘relu’self.conv1 = Conv2D(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=5)self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)self.conv2 = Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)self.conv3 = Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)self.conv4 = Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)self.conv5 = Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)self.max_pool5 = MaxPool2D(kernel_size=2, stride=2)self.fc1 = Linear(in_features=12544, out_features=4096)self.drop_ratio1 = 0.5self.drop1 = Dropout(self.drop_ratio1)self.fc2 = Linear(in_features=4096, out_features=4096)self.drop_ratio2 = 0.5self.drop2 = Dropout(self.drop_ratio2)self.fc3 = Linear(in_features=4096, out_features=num_classes)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.max_pool1(x)x = self.conv2(x)x = F.relu(x)x = self.max_pool2(x)x = self.conv3(x)x = F.relu(x)x = self.conv4(x)x = F.relu(x)x = self.conv5(x)x = F.relu(x)x = self.max_pool5(x)x = paddle.reshape(x, [x.shape[0], -1])x = self.fc1(x)x = F.relu(x)# 在全连接之后使用dropout抑制过拟合x = self.drop1(x)x = self.fc2(x)x = F.relu(x)# 在全连接之后使用dropout抑制过拟合x = self.drop2(x)x = self.fc3(x)return x
#数据处理
#==============================================================================================
import cv2
import random
import numpy as np
import os# 对读入的图像数据进行预处理
def transform_img(img):# 将图片尺寸缩放道 224x224img = cv2.resize(img, (224, 224))# 读入的图像数据格式是[H, W, C]# 使用转置操作将其变成[C, H, W]img = np.transpose(img, (2,0,1))img = img.astype('float32')# 将数据范围调整到[-1.0, 1.0]之间img = img / 255.img = img * 2.0 - 1.0return img# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):# 将datadir目录下的文件列出来,每条文件都要读入filenames = os.listdir(datadir)def reader():if mode == 'train':# 训练时随机打乱数据顺序random.shuffle(filenames)batch_imgs = []batch_labels = []for name in filenames:filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)if name[0] == 'H' or name[0] == 'N':# H开头的文件名表示高度近似,N开头的文件名表示正常视力# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0label = 0elif name[0] == 'P':# P开头的是病理性近视,属于正样本,标签为1label = 1else:raise('Not excepted file name')# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader# 定义验证集数据读取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):# 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签# 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容# csvfile文件所包含的内容格式如下,每一行代表一个样本,# 其中第一列是图片id,第二列是文件名,第三列是图片标签,# 第四列和第五列是Fovea的坐标,与分类任务无关# ID,imgName,Label,Fovea_X,Fovea_Y# 1,V0001.jpg,0,1157.74,1019.87# 2,V0002.jpg,1,1285.82,1080.47# 打开包含验证集标签的csvfile,并读入其中的内容filelists = open(csvfile).readlines()def reader():batch_imgs = []batch_labels = []for line in filelists[1:]:line = line.strip().split(',')name = line[1]label = int(line[2])# 根据图片文件名加载图片,并对图像数据作预处理filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader# -*- coding: utf-8 -*-
# 识别眼疾图片
import os
import random
import paddle
import numpy as npDATADIR = './PM/palm/PALM-Training400/PALM-Training400'
DATADIR2 = './PM/palm/PALM-Validation400'
CSVFILE = './PM/labels.csv'
# 设置迭代轮数
EPOCH_NUM = 5# 定义训练过程
def train_pm(model, optimizer):# 开启0号GPU训练use_gpu = Truepaddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')print('start training ... ')model.train()# 定义数据读取器,训练数据读取器和验证数据读取器train_loader = data_loader(DATADIR, batch_size=10, mode='train')valid_loader = valid_data_loader(DATADIR2, CSVFILE)for epoch in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):x_data, y_data = dataimg = paddle.to_tensor(x_data)label = paddle.to_tensor(y_data)#print('image.shape=',img.shape)# 运行模型前向计算,得到预测值logits = model(img)loss = F.binary_cross_entropy_with_logits(logits, label)avg_loss = paddle.mean(loss)if batch_id % 20 == 0:print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy())))# 反向传播,更新权重,清除梯度avg_loss.backward()optimizer.step()optimizer.clear_grad()model.eval()accuracies = []losses = []for batch_id, data in enumerate(valid_loader()):x_data, y_data = dataimg = paddle.to_tensor(x_data)label = paddle.to_tensor(y_data)# 运行模型前向计算,得到预测值logits = model(img)# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别# 计算sigmoid后的预测概率,进行loss计算pred = F.sigmoid(logits)loss = F.binary_cross_entropy_with_logits(logits, label)# 计算预测概率小于0.5的类别pred2 = pred * (-1.0) + 1.0# 得到两个类别的预测概率,并沿第一个维度级联pred = paddle.concat([pred2, pred], axis=1)acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))accuracies.append(acc.numpy())losses.append(loss.numpy())print("[validation] accuracy/loss: {:.4f}/{:.4f}".format(np.mean(accuracies), np.mean(losses)))model.train()paddle.save(model.state_dict(), 'palm.pdparams')paddle.save(optimizer.state_dict(), 'palm.pdopt')
# 定义评估过程
def evaluation(model, params_file_path):# 开启0号GPU预估use_gpu = Truepaddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')print('start evaluation .......')#加载模型参数model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)model.eval()eval_loader = data_loader(DATADIR, batch_size=10, mode='eval')acc_set = []avg_loss_set = []for batch_id, data in enumerate(eval_loader()):x_data, y_data = dataimg = paddle.to_tensor(x_data)label = paddle.to_tensor(y_data)y_data = y_data.astype(np.int64)label_64 = paddle.to_tensor(y_data)# 计算预测和精度prediction, acc = model(img, label_64)# 计算损失函数值loss = F.binary_cross_entropy_with_logits(prediction, label)avg_loss = paddle.mean(loss)acc_set.append(float(acc.numpy()))avg_loss_set.append(float(avg_loss.numpy()))# 求平均精度acc_val_mean = np.array(acc_set).mean()avg_loss_val_mean = np.array(avg_loss_set).mean()print('loss={:.4f}, acc={:.4f}'.format(avg_loss_val_mean, acc_val_mean))
#==============================================================================================# 创建模型
model = AlexNet()
# 启动训练过程
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())train_pm(model, optimizer=opt)# 输入数据形状是 [N, 3, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[10,3,224,224])
x = x.astype('float32')
# 创建LeNet类的实例,指定模型名称和分类的类别数目
model = AlexNet(2)
# 通过调用LeNet从基类继承的sublayers()函数,
# 查看LeNet中所包含的子层
print(model.sublayers())
print(x.shape)
x = paddle.to_tensor(x)
print(x.shape)
for item in model.sublayers():# item是LeNet类中的一个子层# 查看经过子层之后的输出数据形状try:x = item(x)except:x = paddle.reshape(x, [x.shape[0], -1])x = item(x)if len(item.parameters())==2:# 查看卷积和全连接层的数据和参数的形状,# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数bprint(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)else:# 池化层没有参数print(item.full_name(), x.shape) 相关文章:
AlexNet卷积神经网络-笔记
AlexNet卷积神经网络-笔记 AlexNet卷积神经网络2012年提出 测试结果为: 通过运行结果可以发现, 在眼疾筛查数据集iChallenge-PM上使用AlexNet,loss能有效下降, 经过5个epoch的训练,在验证集上的准确率可以达到94%左右…...
)
剑指 Offer 53 - I. !!在排序数组中查找数字 I (考查二分法)
剑指 Offer 53 - I. 在排序数组中查找数字 I 统计一个数字在排序数组中出现的次数。 示例 1: 输入: nums [5,7,7,8,8,10], target 8 输出: 2 示例 2: 输入: nums [5,7,7,8,8,10], target 6 输出: 0 提示: 0 < nums.length < 105 -109 < nums[i] &l…...

RANSAC算法在Python中的实现与应用探索:线性拟合与平面拟合示例
第一部分:RANSAC算法与其应用 在我们的日常生活和多个领域中,如机器学习,计算机视觉,模式识别等,处理数据是一个非常重要的任务。尤其是当我们需要从嘈杂的数据中获取信息或拟合模型时。有时候,数据可能包含异常值或噪声,这可能会对我们的结果产生重大影响。为了解决这…...

PHP接口自动化测试框架实现
我们来看一个简单的PHP实现的超简单的接口。 ...//报名验证 private function apply_verify() {$raid $this->input->get_post(raid);$mid $this->input->get_post(mid);if (!$raid || !$mid) {$this->ret_json(10021, 参数错误);}$this->load->model(…...

VLAN原理+配置
目录 一, 以太网二层交换机 二,三层架构: 三,VLAN配置思路 1.创建vlan 2.接口划入vlan 3.trunk干道 4.vlan间路由器 5.DHCP池塘配置 四,华为VLAN部分的接口模式讲解: 五,华为VLAN部分的…...
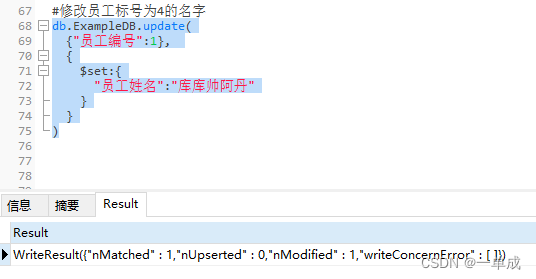
MongoDB文档-基础使用-在客户端(dos窗口)/可视化工具中使用MongoDB基础语句
阿丹: 本文章将描述以及研究mongodb在客户端的基础应用以及在spring-boot中整合使用mongodb来完成基本的数据增删改查。 先放官方的文章 MongoDB CRUD操作 - MongoDB-CN-Manual 本文章分为: 在客户端(dos窗口)/可视化工具中使用…...
“RISC-V成长日记” blog发布,第一个运行在RISC-V服务器上的blog?
尽管推特、公众号、微博、抖音等社交平台风靡一时,但blog(博客)在全世界依然经久不衰,尤其是在技术领域。对于博主而言,博客是他们独立创作的天地,可以随时更新内容和故事,确保素材的时效性。此…...
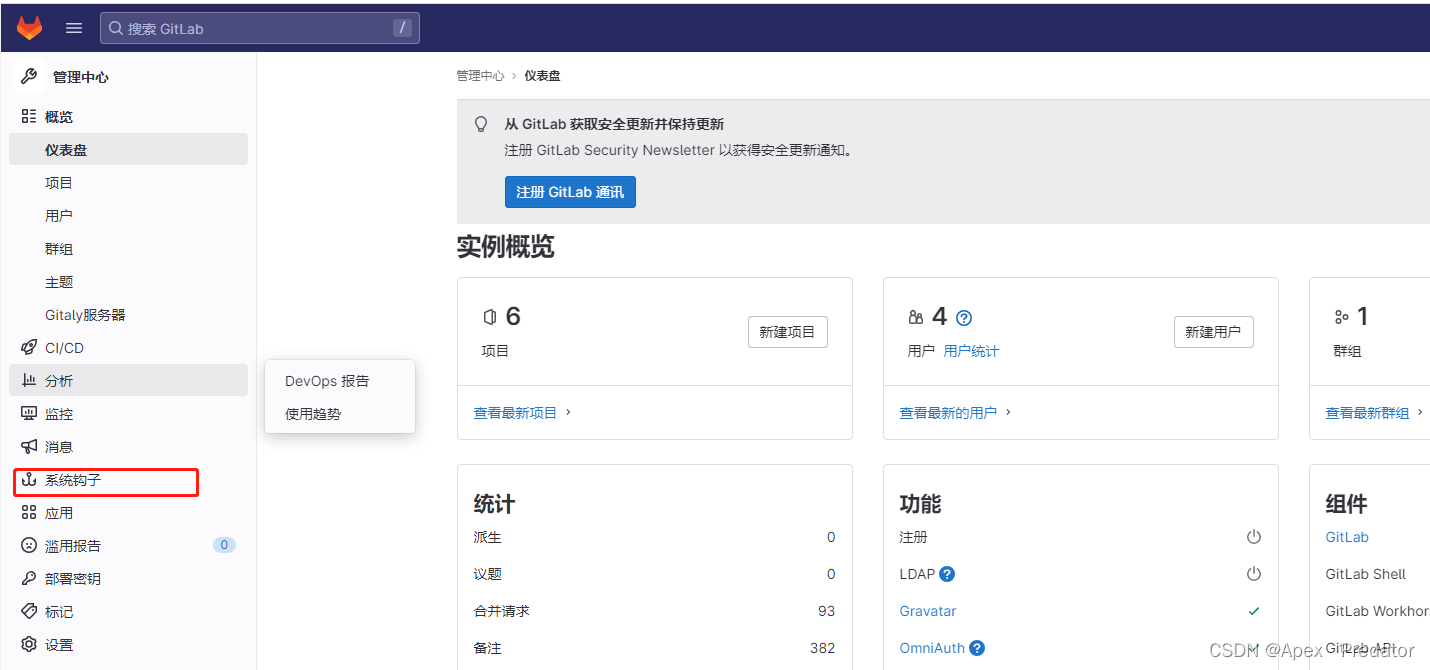
gitlab配置webhook
一.前言 当需要做jenkins的自动化触发构建时,就需要配置gitlab的webhook功能,以下来展示以下如何配置gitlab的webhook,jenkins的配置就不在这里展示了,可以去看我devops文章的完整配置 二.配置 在新版本的gitlab中,…...

编译安装Linux内核实践与踩坑
编译安装Linux内核实践与踩坑 1. 参考方案 先留个坑 1. 参考方案 编译安装linux内核ShawnZhong的仓库make mrproper make oldconfig scripts/config --set-str SYSTEM_TRUSTED_KEYS "" KBUILD_BUILD_TIMESTAMP make CC"ccache gcc" -jnproc LOCALVERSION-…...

郑州https数字证书
很多注重隐私的网站都注重网站信息的安全,比如购物网站就需要对客户的账户信息以及支付信息进行安全保护,否则信息泄露,客户与网站都有损失,网站也会因此流失大量客户。而网站使用https证书为客户端与服务器之间传输的信息加了一个…...
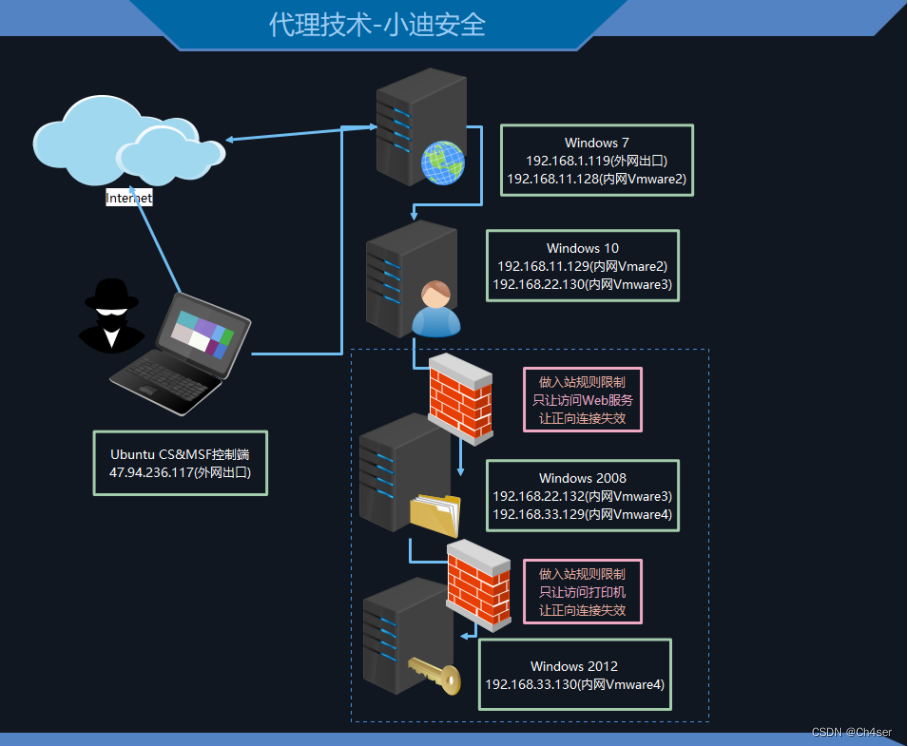
第125天:内网安全-隧道技术SMBICMP正反向连接防火墙出入规则上线
知识点 #知识点: 1、入站规则不出网上线方案 2、出站规则不出网上线方案 3、规则-隧道技术-SMB&ICMP-隧道技术:解决不出网协议上线的问题(利用出网协议进行封装出网) -代理技术:解决网络通讯不通的问题࿰…...
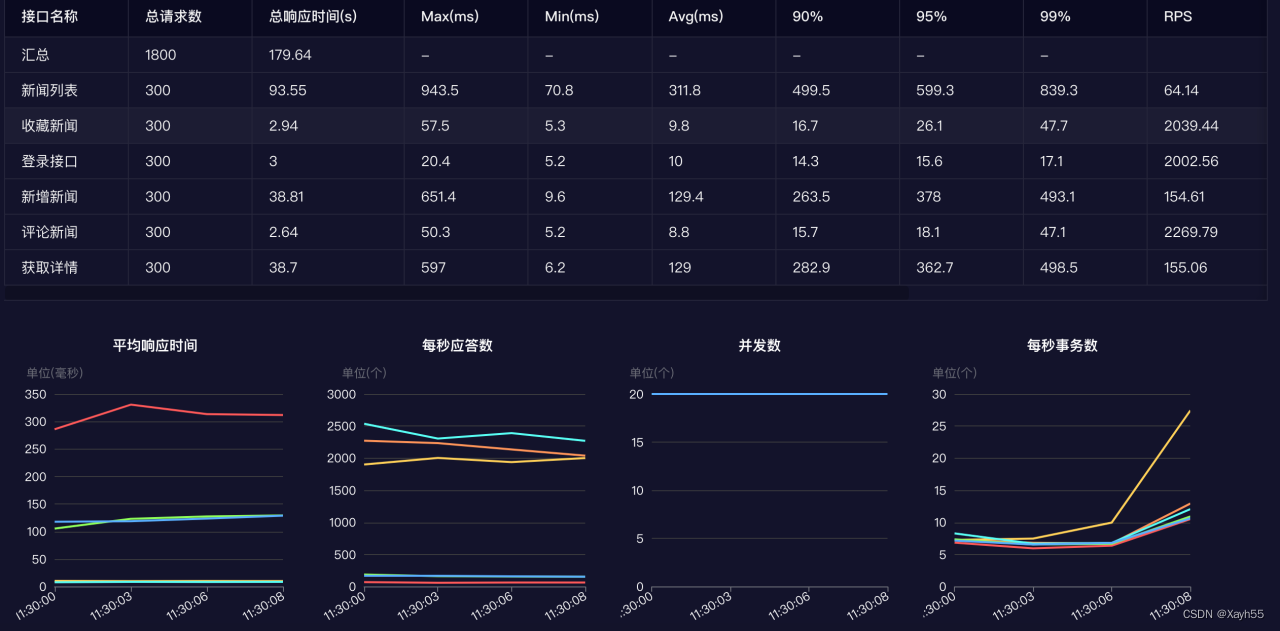
性能测试怎么做?测试工具怎么选择?
在当前软件测试行业,熟练掌握性能测试已经是测试工程师们面试的敲门砖了,当然还有很多测试朋友们每天的工作更多的是点点点,性能方面可能也只是做过简单的并发测试,对于编写脚本,搭建环境方面也比较陌生。今天这篇文章…...
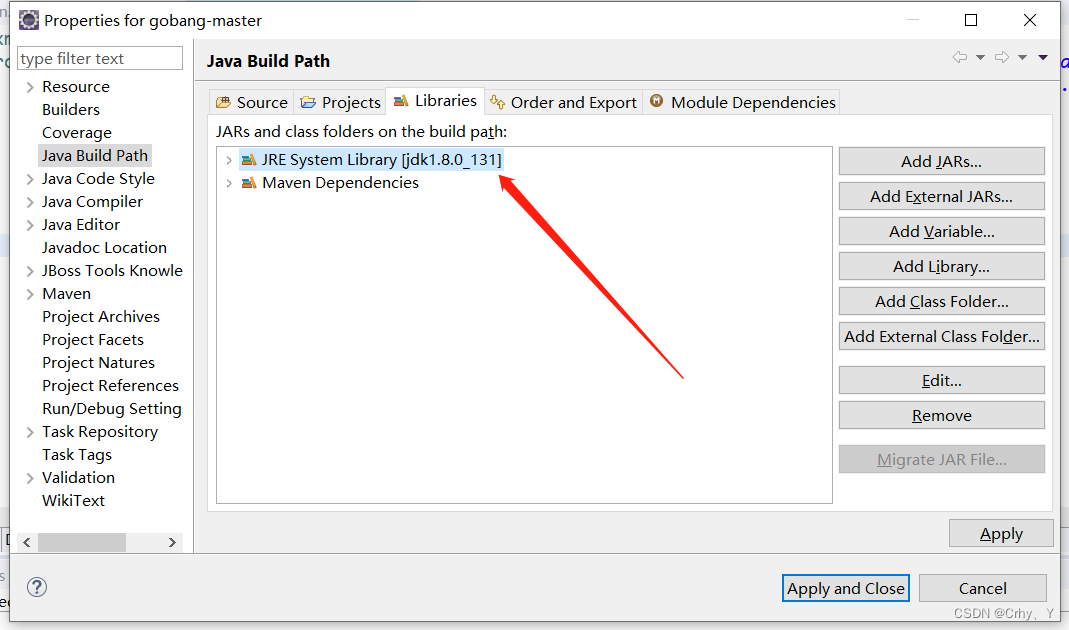
【Eclise配置Jdk环境】Jre环境常见配置错误问题
1、问题描述:执行Run As → Maven install 报出以下错误。 [INFO] Scanning for projects... [INFO] [INFO] -------------------------< com.example:gobang >------------------------- [INFO] Building gobang 0.0.1-SNAPSHOT [INFO] -------------------…...

UM2080F32——32位SoC芯片
UM2080F32是基于ARM Cortex-M0内核的超低功耗、高性能的、单片集成(G)FSK/OOK无线收发机的32位SoC芯片。工作于200MHz~960MHz范围内,支持灵活可设的数据包格式,支持自动应答和自动重发功能,支持跳频操作,支持FEC功能,同…...
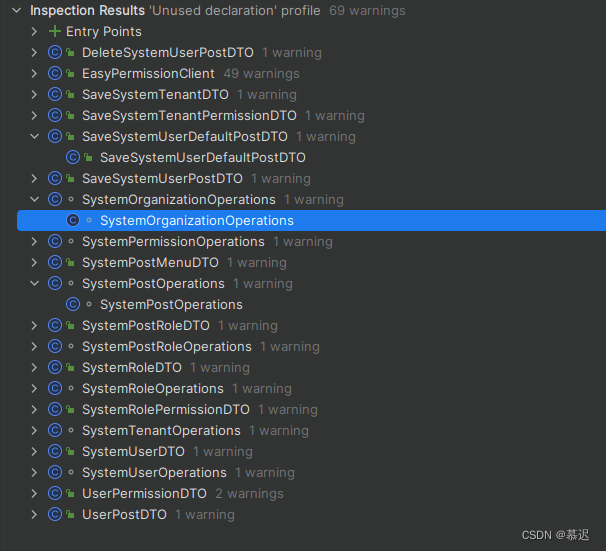
IDEA基础使用
IDEA基础使用 1、IDEA中显示用法和用户截图展示有调用显示无调用显示 对应方法 2、如何找出项目中所有不被调用方法截图展示对应方法 3、常用代码(Code)说明及快捷键:4、未完待续待日后更新。。。总结:欢迎指导,也祝码友们代码越来越棒,技术越…...

[数据集][目标检测]遛狗不牵绳数据集VOC格式-1980张
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):1980 标注数量(xml文件个数):1980 标注类别数:5 标注类别名称:["dog","p…...

基于WebRTC升级的低延时直播
快直播-基于WebRTC升级的低延时直播-腾讯云开发者社区-腾讯云 标准WebRTC支持的音视频编码格式已经无法满足国内直播行业需求。标准WebRTC支持的视频编码格式是VP8/VP9和H.264,音频编码格式是Opus,而国内推流的音视频格式基本上是H.264/H.265AAC的形式。…...
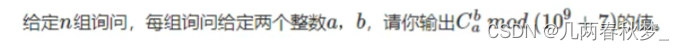
数学知识(二)
一、裴蜀定理 对于任意整数a,b,一定存在非零整数x,y,使得 ax by gcd(a,b) #include<iostream> #include<algorithm>using namespace std;int exgcd(int a,int b,int &x,int &y) {if(!b){x 1,y 0;return a;}int d exgcd(b,a %…...
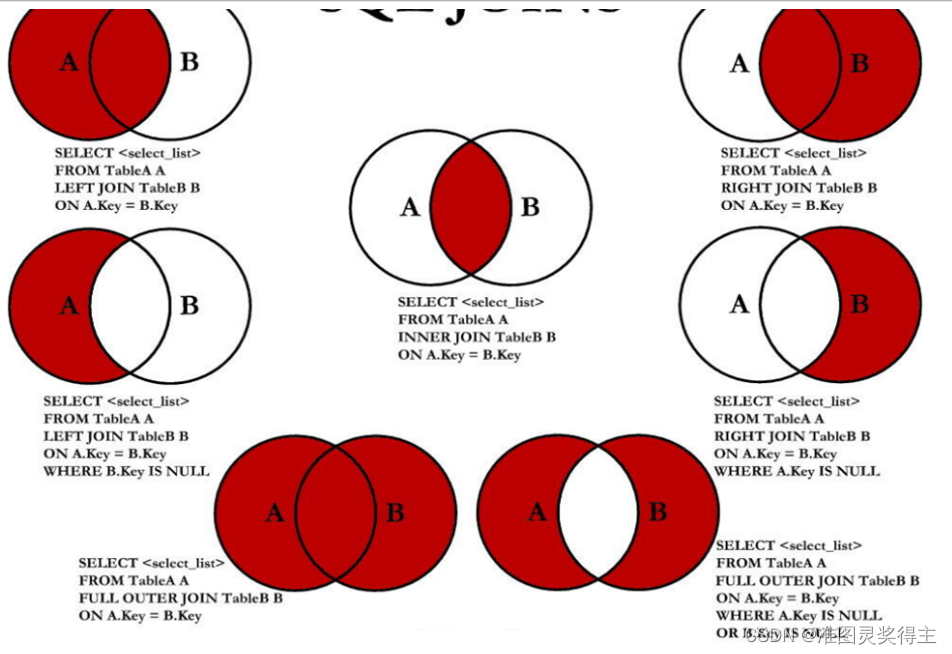
Java实现数据库表中的七种连接【Mysql】
Java实现数据库表中的七种连接【Mysql】 前言版权推荐Java实现数据库表中的七种连接左外连接右外连接其他连接 附录七种连接SQL测试Java测试转换方法类 Cla1类 Cla2类Cla3 最后 前言 2023-8-4 16:51:42 以下内容源自《【Mysql】》 仅供学习交流使用 版权 禁止其他平台发布时…...

452. 用最少数量的箭引爆气球
452. 用最少数量的箭引爆气球452. 用最少数量的箭引爆气球 有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。 一支弓箭可…...
:思想、优劣与应用场景完全解读)
跳表(Skip List):思想、优劣与应用场景完全解读
一、为什么需要跳表?在计算机科学中,我们经常需要一种数据结构,既能快速查找,又能高效插入和删除。数组的二分查找虽然快(O(log n)),但插入删除却需要移动大量元素(O(n))…...
)
保姆级教程:用Nuitka为你的PyQt5应用生成独立exe(含资源文件配置)
从零到一:用Nuitka高效打包PyQt5应用的完整指南 当你完成了一个功能完善的PyQt5应用,下一步自然是想把它分享给他人使用。但直接分发Python源码显然不够友好——用户需要安装Python环境、配置依赖库,还可能遇到版本兼容问题。这时候…...
)
告别手动拖拽!用Python脚本pydcs批量生成DCS World飞行任务(附完整代码)
用Python解放双手:pydcs自动化生成DCS World飞行任务全攻略 当你在DCS World中反复拖拽AI单位、手动设置航点时,是否想过这些机械操作其实可以用几行代码解决?对于追求效率的任务设计师来说,pydcs这个Python库就像给你的任务编辑器…...

农村与中小城市的数字化,藏着被忽略的技术蓝海
被忽视的数字新大陆当一线城市的数字化转型趋于饱和,农村与中小城市正悄然成为技术落地的"价值洼地"。这片蓝海蕴藏着庞大的场景创新空间,却因基础设施薄弱、用户群体特殊、生态体系未成型等痛点被长期忽视。对软件测试从业者而言,…...

D3KeyHelper:5分钟掌握暗黑3专业宏工具,告别手动疲劳
D3KeyHelper:5分钟掌握暗黑3专业宏工具,告别手动疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 如果你还在为暗黑破坏神…...

终极指南:如何用FanControl免费软件完美控制Windows电脑风扇
终极指南:如何用FanControl免费软件完美控制Windows电脑风扇 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trend…...
Transformer+RoPE如何让GVHMR处理超长视频?深入解读Relative Transformer的设计与实现
TransformerRoPE如何让GVHMR处理超长视频?深入解读Relative Transformer的设计与实现 在计算机视觉领域,处理长序列视频数据一直是个棘手的问题。想象一下,当你需要分析一段长达数小时的监控视频或完整电影片段中的人体动作时,传统…...

FastAPI子应用挂载:别再让root_path坑你一夜案
Julia(julialang.org)由Stefan Karpinski、Jeff Bezanson等在2009年创建,目标是融合Python的易用性、C的高性能、R的统计能力、Matlab的科学计算生态。 其核心设计哲学是: 高性能:编译型语言(JIT࿰…...

理想汽车又孵化一家具身公司......
点击下方卡片,关注“自动驾驶之心”公众号戳我-> 领取自动驾驶近30个方向学习路线编辑 | 自动驾驶之心>>自动驾驶前沿信息获取→自动驾驶之心知识星球据雷峰网《新智驾》报道,理想汽车前AI首席科学家陈伟联合理想汽车前产品线总裁张骁创办的公司…...

数据库知识复习03
第三部分 MySQL DQL 数据查询语言1 数据库的 DQL(数据查询语言)DQL(Data Query Language,数据查询语言)是 SQL 中最核心、使用频率最高的语言类型,核心关键字为 SELECT,用于从数据库表中精准检索…...