动手学深度学习—深度学习计算(层和块、参数管理、自定义层和读写文件)
目录
- 1. 层和块
- 1.1 自定义块
- 1.2 顺序块
- 1.3 在前向传播函数中执行代码
- 2. 参数管理
- 2.1 参数访问
- 2.1.1 目标参数
- 2.1.2 一次性访问所有参数
- 2.1.3 从嵌套块收集参数
- 2.2 参数初始化
- 2.2.1 内置初始化
- 2.2.2 自定义初始化
- 2.3 参数绑定
- 3. 自定义层
- 3.1 不带参数的层
- 3.2 带参数的层
- 4. 读写文件
- 4.1 加载和保存张量
- 4.2 加载和保存模型参数
- 5. GPU
1. 层和块
块可以描述单个层、由多个层组成的组件或整个模型本身。
# 生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层
# 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层
import torch
from torch import nn
from torch.nn import functional as Fnet = nn.Sequential(nn.Linear(20,256), nn.ReLU(), nn.Linear(256,10))X = torch.rand(2, 20)
net(X)
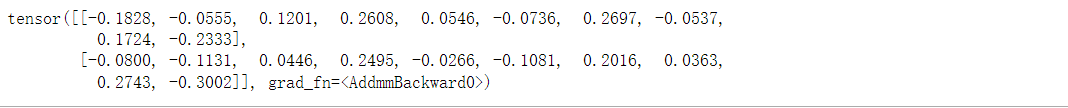
1.1 自定义块
"""自定义块:1、将输入数据作为其前向传播函数的参数。2、通过前向传播函数来生成输出(输出的形状可能与输入的形状不同)。3、计算其输出关于输入的梯度,可通过其反向传播函数进行访问。4、存储和访问前向传播计算所需的参数。5、根据需要初始化模型参数。
"""
"""多层感知机:1、输入是一个20维的输入。2、具有256个隐藏单元的隐藏层和一个10维输出层。
"""
class MLP(nn.Module):# 用模型参数声明层。这里,我们声明两个全连接层def __init__(self):# 调用MLP父类Module的构造函数来执行必要的初始化# 这样,在类实例化中也可以指定其他函数的参数,例如模型参数paramssuper().__init__()self.hidden = nn.Linear(20, 256) # 隐藏层self.out = nn.Linear(256, 10) # 输出层# 定义模型的前向传播,即如何根据输入X返回所需的模型输出def forward(self, X):# 注意,这里我们使用ReLU的函数版本,其在nn.functional模块定义return self.out(F.relu(self.hidden(X)))

1.2 顺序块
"""顺序块(相当于Sequential类):1、一种将块逐个追加到列表中的函数;2、一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
"""
class MySequential(nn.Module):def __init__(self, *args):# __init__函数将每个模块逐个添加到有序字典_modules中super().__init__()for idx, module in enumerate(args):# 这里,module是Module子类的一个实例。我们把它保存在'Module'类的成员# _module的类型是OrderedDict,在模块的参数初始化过程中, 系统知道在_modules字典中查找需要初始化参数的子块。self._modules[str(idx)] = moduledef forward(self, X):# OrderedDict保证了按照成员添加的顺序遍历它们for block in self._modules.values():X = block(X)return X

1.3 在前向传播函数中执行代码
"""实现FixedHiddenMLP模型类:1、实现一个隐藏层, 其权重(self.rand_weight)在实例化时被随机初始化,之后为常量。2、这个权重不是一个模型参数,因此它永远不会被反向传播更新。3、神经网络将这个固定层的输出通过一个全连接层。4、返回输出时做一个循环操作,输出需小于1
"""
class FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()# 不计算梯度的随机权重参数。因此其在训练期间保持不变self.rand_weight = torch.rand((20, 20), requires_grad=False)self.linear = nn.Linear(20 ,20)def forward(self, X):X = self.linear(X)# 使用创建的常量参数以及relu和mm函数X = F.relu(torch.mm(X, self.rand_weight) + 1)# 复用全连接层。这相当于两个全连接层共享参数X = self.linear(X)# 控制流while X.abs().sum() > 1:X /= 2return X.sum()

# 混合搭配各种组合块
class NestMLP(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),nn.Linear(64, 32), nn.ReLU())self.linear = nn.Linear(32, 16)def forward(self, X):return self.linear(self.net(X))chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
chimera(X)

2. 参数管理
- 访问参数,用于调试、诊断和可视化;
- 参数初始化;
- 在不同模型组件间共享参数。
import torch
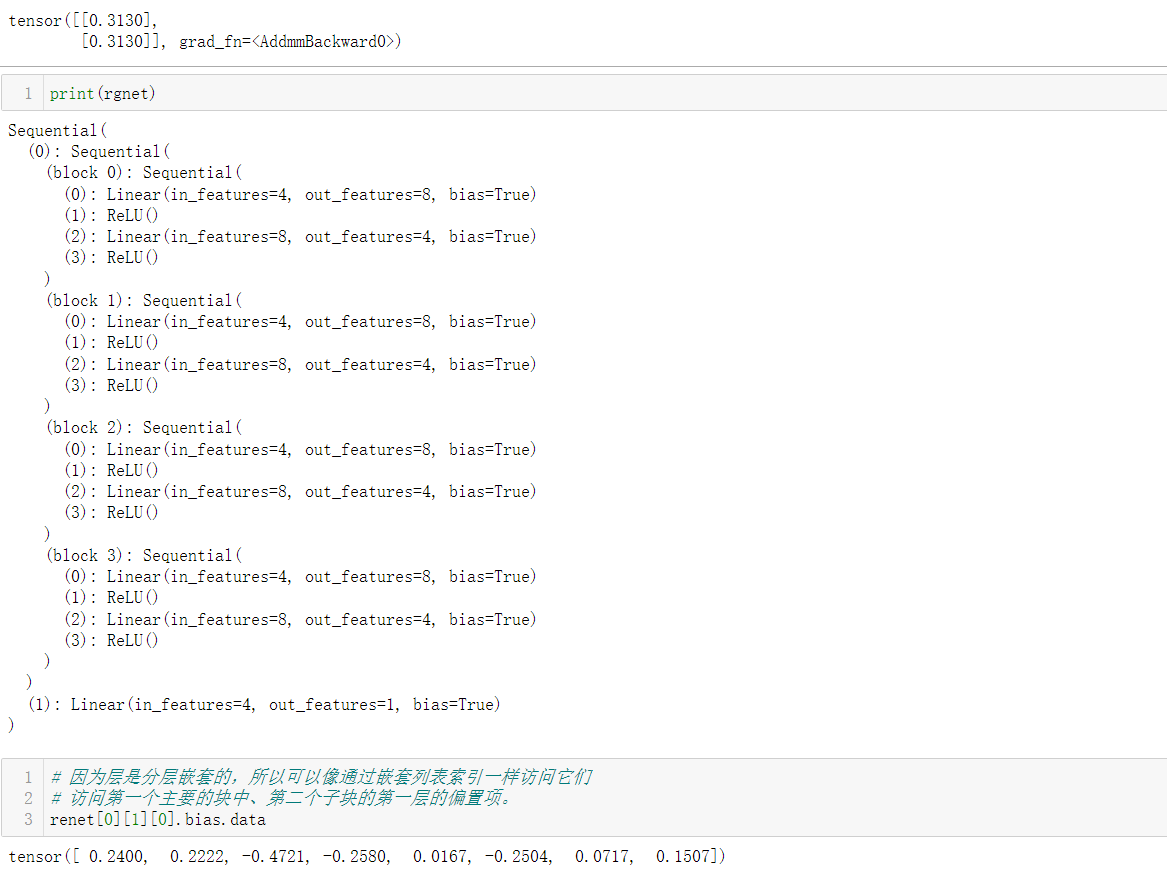
from torch import nnnet = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
net(X)

2.1 参数访问
"""检查第二个全连接层的参数:1、这个全连接层包含两个参数,分别是该层的权重和偏置。2、两者都存储为单精度浮点数(float32)。
"""
print(net[2].state_dict())
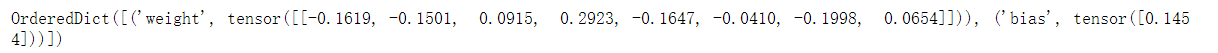
2.1.1 目标参数
# 访问目标参数
print(type(net[2].bias))
print(net[2].bias)
print(net[2].bias.data)

2.1.2 一次性访问所有参数
# 一次性访问所有参数
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])

2.1.3 从嵌套块收集参数
# 从嵌套块收集参数
def block1():return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),nn.Linear(8, 4), nn.ReLU())def block2():net = nn.Sequential()for i in range(4):# 在这里嵌套net.add_module(f'block {i}', block1())return netrgnet = nn.S
2.2 参数初始化
"""参数初始化:1、内置初始化2、自定义初始化
"""
# 将所有权重参数初始化为标准差为0.01的高斯随机变量, 且将偏置参数设置为0
def init_normal(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, mean=0, std=0.01)nn.init.zeros_(m.bias)# model.apply(fn)会递归地将函数fn应用到父模块的每个子模块submodule,也包括model这个父模块自身
net.apply(init_normal)
net[0].weight.data[0], net[0].bias.data[0]
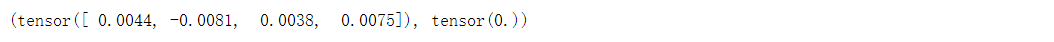
2.2.1 内置初始化
# 将所有参数初始化为给定的常数,比如初始化为1
def init_constant(m):if type(m) == nn.Linear:nn.init.constant_(m.weight, 1)nn.init.zeros_(m.bias)net.apply(init_constant)
net[0].weight.data[0], net[0].bias.data[0]

# 使用Xavier初始化方法初始化第一个神经网络层, 然后将第三个神经网络层初始化为常量值42。
def init_xavier(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)
def init_42(m):if type(m) == nn.Linear:nn.init.constant_(m.weight, 42)net[0].apply(init_xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)

2.2.2 自定义初始化
# 自定义初始化
def my_init(m):if type(m) == nn.Linear:print("Init", *[(name, param.shape)for name, param in m.named_parameters()][0])nn.init.uniform_(m.weight, -10, 10)m.weight.data *= m.weight.data.abs() >= 5net.apply(my_init)
net[0].weight[:2]
# net[0].weight[0:]
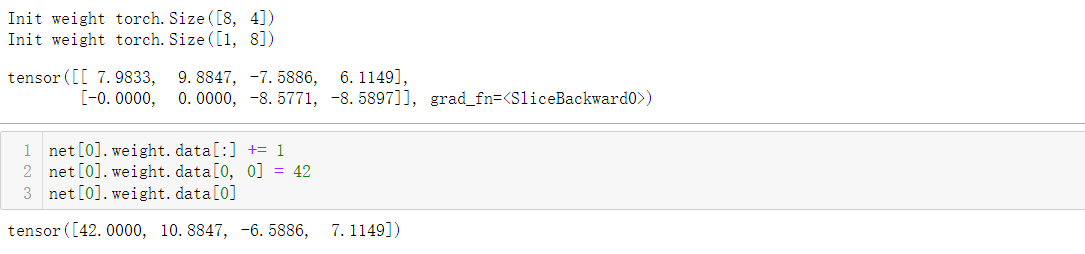
2.3 参数绑定
# 在多个层间共享参数: 我们可以定义一个稠密层,然后使用它的参数来设置另一个层的参数。
# 我们需要给共享层一个名称,以便可以引用它的参数
"""参数绑定:1、第三个和第五个神经网络层的参数是绑定的。 它们不仅值相等,而且由相同的张量表示。2、如果我们改变其中一个参数,另一个参数也会改变。3、由于模型参数包含梯度,因此在反向传播期间第二个隐藏层 (即第三个神经网络层)和第三个隐藏层(即第五个神经网络层)的梯度会加在一起。
"""
shared = nn.Linear(8, 8)
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(),shared, nn.ReLU(),shared, nn.ReLU(),nn.Linear(8 ,1))
net(X)
# 检查参数是否相同
print(net[2].weight.data[0] == net[4].weight.data[0])
net[2].weight.data[0, 0] = 100
# 确保它们实际上是同一个对象,而不是只有相同的值
print(net[2].weight.data[0] == net[4].weight.data[0])

3. 自定义层
我们可以用创造性的方式组合不同的层,从而设计出适用于各种任务的架构。
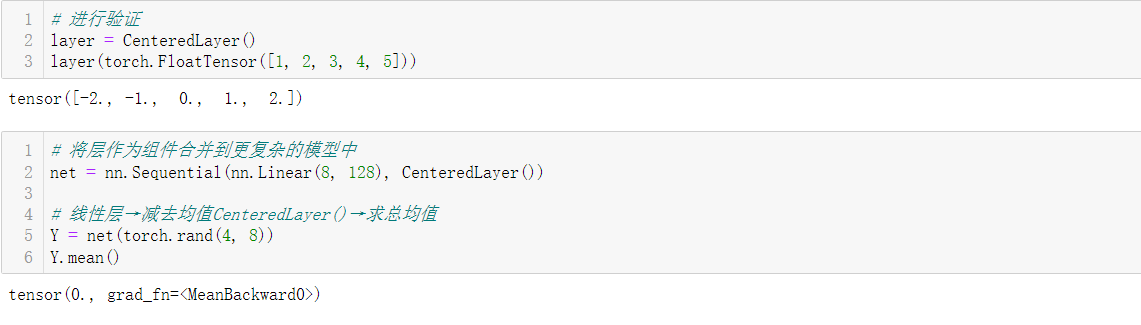
3.1 不带参数的层
"""自定义CenteredLayer类:1、要从其输入中减去均值;2、要构建它,我们只需继承基础层类并实现前向传播功能。
"""
import torch
import torch.nn.functional as F
from torch import nnclass CenteredLayer(nn.Module):def __init__(self):super().__init__()def forward(self, X):return X - X.mean()
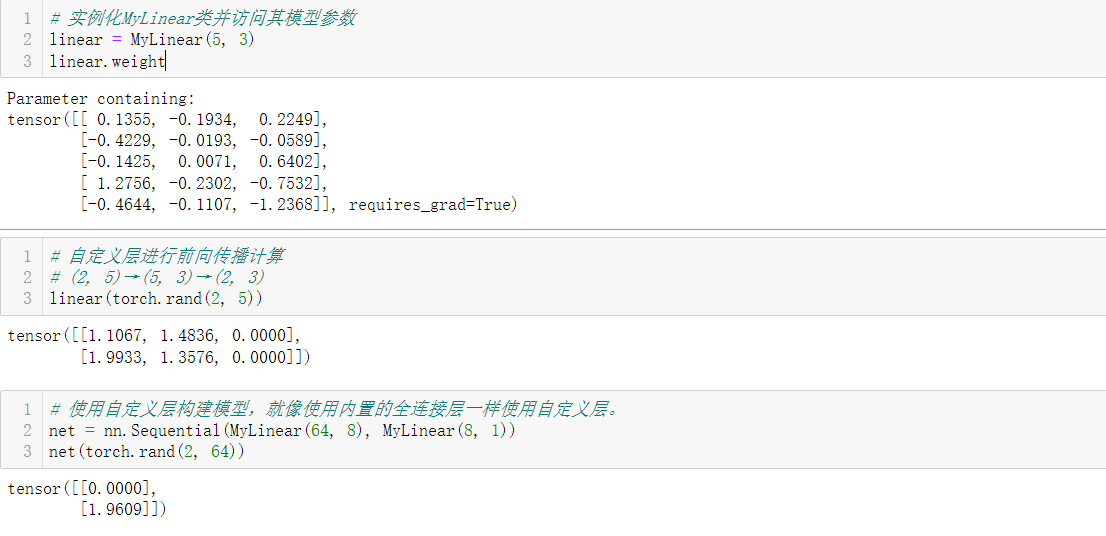
3.2 带参数的层
"""自定义带参数的全连接层:1、该层需要两个参数,一个用于表示权重,另一个用于表示偏置项;2、使用修正线性单元作为激活函;3、in_units和units,分别表示输入数和输出数。
"""
class MyLinear(nn.Module):def __init__(self, in_units, units):super().__init__()self.weight = nn.Parameter(torch.randn(in_units, units))self.bias = nn.Parameter(torch.randn(units,))def forward(self, X):linear = torch.matmul(X, self.weight.data) + self.bias.datareturn F.relu(linear)
4. 读写文件
有时我们希望保存训练的模型, 以备将来在各种环境中使用(比如在部署中进行预测)。
4.1 加载和保存张量
import torch
from torch import nn
from torch.nn import functional as Fx = torch.arange(4)
torch.save(x, 'x-file')

# 存储一个张量列表,然后把它们读回内存。
y = torch.zeros(4)
torch.save([x, y], 'x-files')
x2, y2 = torch.load('x-files')
(x2, y2)

# 写入或读取从字符串映射到张量的字典
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
mydict2

4.2 加载和保存模型参数
"""加载和保存模型参数:1、深度学习框架提供了内置函数来保存和加载整个网络;2、保存模型的参数而不是保存整个模型。
"""
class MLP(nn.Module):def __init__(self):super().__init__()self.hidden = nn.Linear(20, 256)self.output = nn.Linear(256, 10)def forward(self, x):return self.output(F.relu(self.hidden(x)))net = MLP()
X = torch.randn(size=(2, 20))
Y = net(X)

# 为了恢复模型,我们实例化了原始多层感知机模型的一个备份
clone = MLP()
clone.load_state_dict(torch.load('mlp.params'))
clone.eval()

5. GPU
GPU能够帮助我们更好地进行计算,使用nvidia-smi命令来查看显卡信息。
!nvidia-smi
# 定义了两个方便的函数, 这两个函数允许我们在不存在所需所有GPU的情况下运行代码
def try_gpu(i=0): #@save"""如果存在,则返回gpu(i),否则返回cpu()"""if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')def try_all_gpus(): #@save"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""devices = [torch.device(f'cuda{i}')for i in range(torch.cuda.device_count())]return devices if devices else [torch.device('cpu')]try_gpu(), try_gpu(10), try_all_gpus()
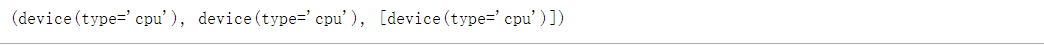
相关文章:
动手学深度学习—深度学习计算(层和块、参数管理、自定义层和读写文件)
目录 1. 层和块1.1 自定义块1.2 顺序块1.3 在前向传播函数中执行代码 2. 参数管理2.1 参数访问2.1.1 目标参数2.1.2 一次性访问所有参数2.1.3 从嵌套块收集参数 2.2 参数初始化2.2.1 内置初始化2.2.2 自定义初始化 2.3 参数绑定 3. 自定义层3.1 不带参数的层3.2 带参数的层 4. …...
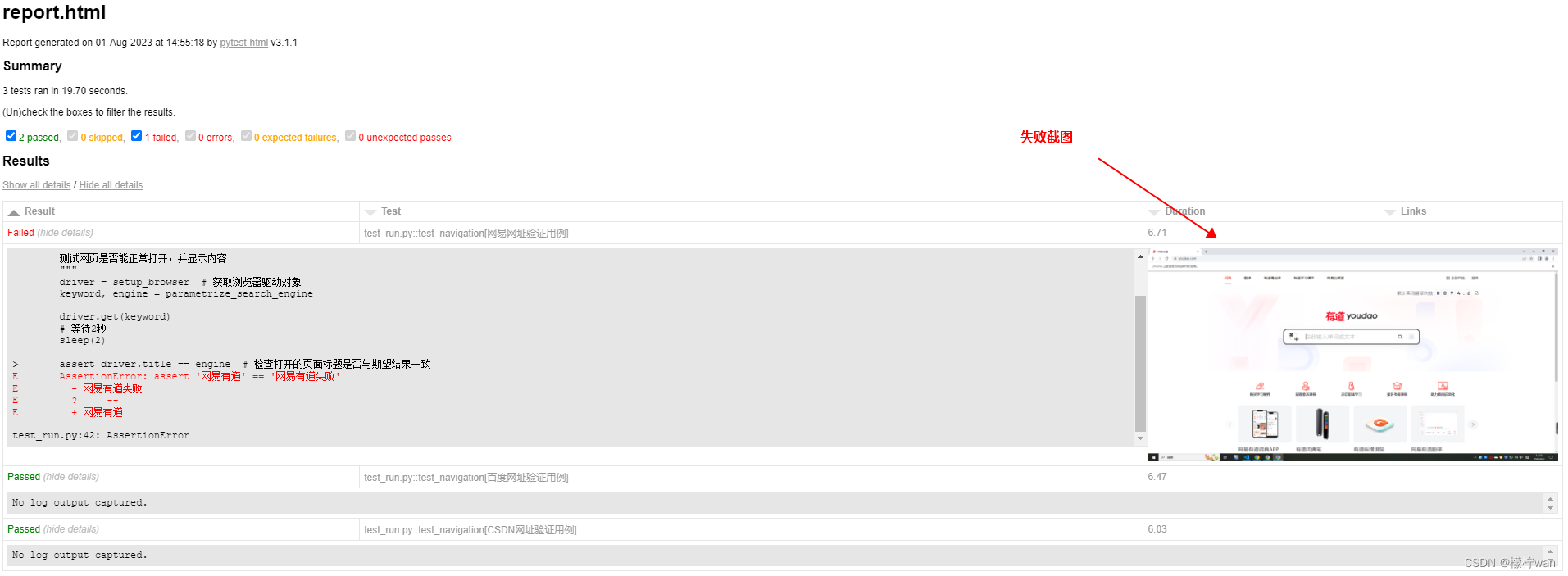
Pytest学习教程_测试报告生成pytest-html(三)
前言 pytest-html 是一个用于生成漂亮的 HTML 测试报告的 pytest 插件。它可以方便地将 pytest 运行的测试结果转换为易于阅读和理解的 HTML 报告,提供了丰富的测试结果展示功能和交互性。 一、安装 # 版本查看命令 pytest版本: pytest --version pyte…...
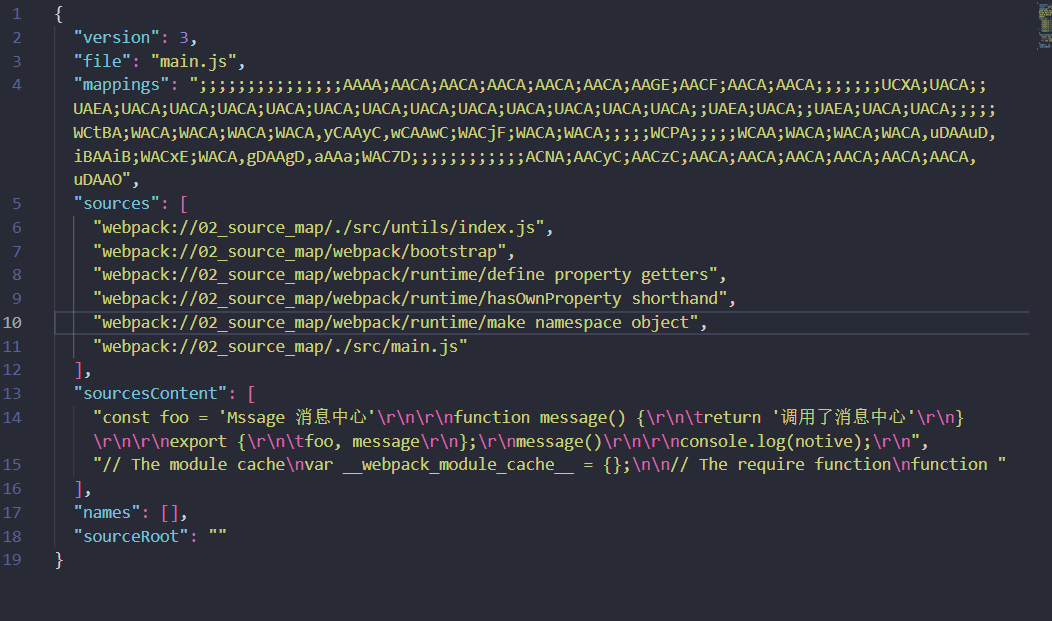
模块化原理:source-map
1. webpack打包基本配置 1.安装webpack与webpack-cli npm i webpack webpack-cli 2.配置 "build":"webpack" 3. 新建webpack.config.js const path require(path); module.exports {// mode: "development",// 默认production(什么…...

【C++】开源:ncurses终端TUI文本界面库
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍ncurses终端文本界面库。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

C语言的_Bool类型
C99 新增了 _Bool 类型,用于表示布尔值,即逻辑值 true 和 false。 _Bool 类型也是一种整数类型。 原则上 _Bool 类型只占用一位存储空间。 C语言将非 0 的数当为 true,0 当为 false。 代码示例: #include<stdio.h> int…...

【python爬虫】获取某一个网址下面抓取所有的a 超链接下面的内容
import requests as rq from bs4 import BeautifulSoup as bs import re# rooturl是传的是我需要查询和抓取的一个网址,可以是html js 等 def gethtml(rooturl, encoding"utf-8"):#默认解码方式utf-8response rq.get(rooturl)response.encoding encodin…...

AutoDL从0到1搭建stable-diffusion-webui
前言 AI绘画当前非常的火爆,随着Stable diffusion,Midjourney的出现将AI绘画推到顶端,各大行业均受其影响,离我们最近的AI绘画当属Stable diffusion,可本地化部署,只需电脑配备显卡即可完成AI绘画工作&…...

手动调整broker扩容后的旧topic分区
在broker扩容了两台机器之后,想让旧topic:quickstart76-events的分区也能铺满broker 1、创建一个topics-to-move.json json文件 $ vim topics-to-move.json json {"topics": [{"topic":"quickstart76-events"}],"v…...
)
【LeetCode-简单】剑指 Offer 25. 合并两个排序的链表(详解)
题目 入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。 示例1: 输入:1->2->4, 1->3->4 输出:1->1->2->3->4->4 本题与主站 21 题相同:力扣 题目地址&#x…...
Java版工程行业管理系统源码-专业的工程管理软件-em提供一站式服务
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目…...

【Spring】简化事件的使用,Spring提供了2种使用方式
Spring中事件可以配置顺序,利用线程池还可以做异步线程通知。怎么样使用事件?Spring简化事件的使用,Spring提供了2种使用方式:面向接口和面向EventListener注解。 1,面相接口的方式 案例 发布事件 需要先继承ApplicationEventP…...

探究Spring事务:了解失效场景及应对策略
在现代软件开发中,数据的一致性和完整性是至关重要的。为了保证这些特性,Spring框架提供了强大的事务管理机制,让开发者能够更加自信地处理数据库操作。然而,事务并非银弹,存在一些失效的情景,本文将带您深…...

Maven Manifold 条件编译
Maven 配置 通过 Maven 的不同 profile 实现不同环境传递不同符号。另外 lombok 可以 manifold 一同使用,见下方配置。 <properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.targ…...

4.数组与基本数学函数
一、数组 1.概念 数组是存放相同类型对象的容器,数组中存放的对象没有名字,而是要通过其所在的位置访问。数组中的每一个元素都相当于一个普通的变量,可以和普通变量一样进行赋值操作。 数组可以帮助我们批量地处理相同数据类型的相关数据…...

python与深度学习(十六):CNN和宝可梦模型二
目录 1. 说明2. 宝可梦模型的CNN模型测试2.1 导入相关库2.2 加载模型2.3 设置保存图片的路径2.4 加载图片2.5 数据处理和归一化2.6 对图片进行预测2.7 显示图片 3. 完整代码和显示结果4. 多张图片进行测试的完整代码以及结果 1. 说明 本篇文章是对上篇文章宝可梦模型训练的模型…...

PTA 1030 Travel Plan
个人学习记录,代码难免不尽人意。 A traveler’s map gives the distances between cities along the highways, together with the cost of each highway. Now you are supposed to write a program to help a traveler to decide the shortest path between his/h…...
MFC、Qt、WPF?该用哪个?
MFC、Qt和WPF都是流行的框架和工具,用于开发图形用户界面(GUI)应用程序。选择哪个框架取决于你的具体需求和偏好。MFC(Microsoft Foundation Class)是微软提供的框架,使用C编写,主要用于Windows…...

使用logback记录日志
1. Pom引用依赖 <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.11</version> </dependency> 2. logback.xml <?xml version"1.0" encoding"U…...
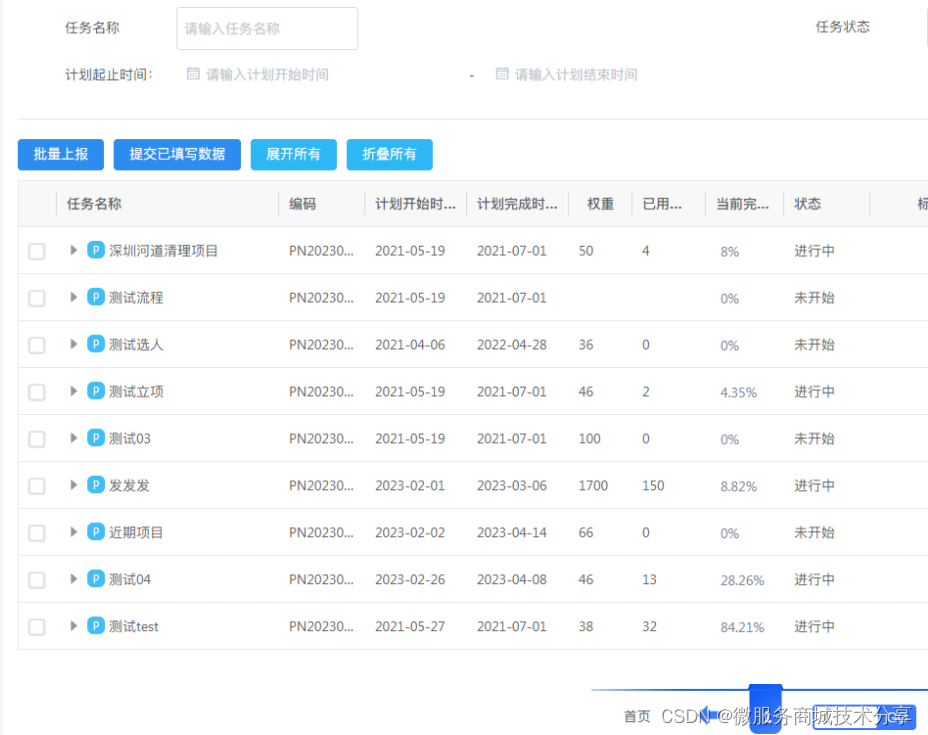
企业工程项目管理系统源码(三控:进度组织、质量安全、预算资金成本、二平台:招采、设计管理) em
工程项目管理软件(工程项目管理系统)对建设工程项目管理组织建设、项目策划决策、规划设计、施工建设到竣工交付、总结评估、运维运营,全过程、全方位的对项目进行综合管理 工程项目各模块及其功能点清单 一、系统管理 1、数据字典&#…...
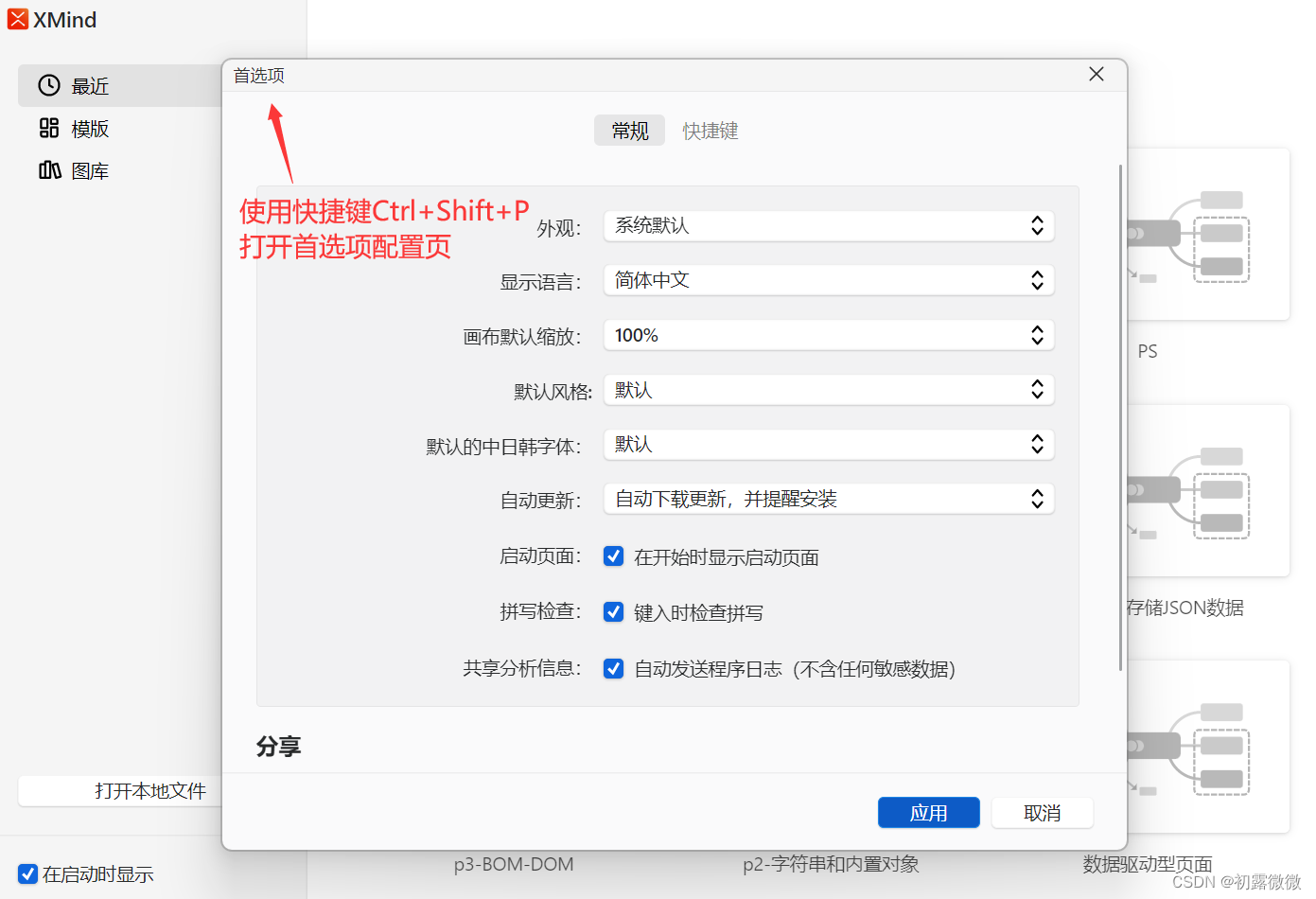
【安装】XMind2022XMind2020安装教程(资源)
Xmind是一个制作思维导图很便利的软件。 1.资源链接 Xmind2022: 链接:https://pan.baidu.com/s/1j4DFedxxX2YJ3HBy1-MpHw?pwdxmin 提取码:xmin Xmind2020: 链接:https://pan.baidu.com/s/1wNqMApuy0yoBF2CvpBDpDA?pwdxmin 提取码&#x…...

Windows 11 24H2 LTSC 微软商店恢复指南:3步解锁完整应用生态
Windows 11 24H2 LTSC 微软商店恢复指南:3步解锁完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 24H2 LTSC版本以…...

带式输送机传动滚筒的设计
目 录 摘要 ………………………………………………………………………………(Ⅰ) Abstract……………………………………………………………………………(Ⅱ) 第一章 绪论………………………………………………………………………(01) 1.1概述……………………………………………...

Node.js 最佳实践终极指南:102个技巧助你构建高性能应用
Node.js 最佳实践终极指南:102个技巧助你构建高性能应用 【免费下载链接】nodebestpractices :white_check_mark: The Node.js best practices list (July 2024) 项目地址: https://gitcode.com/GitHub_Trending/no/nodebestpractices 前言:在Nod…...

Qt桌面应用开发:构建跨平台MogFace-large模型测试工具
Qt桌面应用开发:构建跨平台MogFace-large模型测试工具 最近在做人脸检测相关的项目,经常需要在不同环境下测试MogFace-large模型的效果。每次都要写脚本、调参数、看结果,过程挺繁琐的。我就想,能不能做个简单好用的桌面工具&…...

植物大战僵尸修改器:3分钟解锁无限游戏乐趣的终极指南
植物大战僵尸修改器:3分钟解锁无限游戏乐趣的终极指南 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 还在为阳光不够用而烦恼?无尽模式卡在第10波就过不去?想保…...

3分钟零门槛安装:Axure RP中文语言包全面解析
3分钟零门槛安装:Axure RP中文语言包全面解析 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的英文界…...

Qwen3.5-2B保姆级部署教程:Ubuntu/CentOS系统supervisorctl重启详解
Qwen3.5-2B保姆级部署教程:Ubuntu/CentOS系统supervisorctl重启详解 1. 模型简介 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。该模型主打低功耗、低门槛部署,特别适配端…...
)
iperf3高级玩法:用这些参数组合,精准定位你的网络瓶颈(含TCP/UDP对比测试)
iperf3高级玩法:用参数组合精准定位网络瓶颈 当视频会议频繁卡顿、文件传输速度异常缓慢时,大多数人的第一反应是"网络带宽不够"。但真实情况往往复杂得多——可能是TCP拥塞控制策略不适应高延迟链路,或是UDP流被路由器限速&#x…...

Windows下OpenClaw避坑指南:Qwen3.5-9B镜像对接全记录
Windows下OpenClaw避坑指南:Qwen3.5-9B镜像对接全记录 1. 为什么选择WindowsOpenClaw组合 作为一个长期在Windows环境下工作的开发者,我一直在寻找能够提升本地自动化效率的工具。OpenClaw的出现让我眼前一亮——它不像那些需要复杂配置的企业级系统&a…...

如何用AntiMicroX解决PC游戏手柄支持难题:5分钟从入门到精通
如何用AntiMicroX解决PC游戏手柄支持难题:5分钟从入门到精通 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gitcode.com…...