详解EMBER数据集中对PE文件提取ByteEntropyHistogram特征
1. 引入
在我们对PE文件提取特征时,经常会在PE特征工程的项目中,看到如下这段代码
class ByteEntropyHistogram(FeatureType):''' 2d byte/entropy histogram based loosely on (Saxe and Berlin, 2015).This roughly approximates the joint probability of byte value and local entropy.See Section 2.1.1 in https://arxiv.org/pdf/1508.03096.pdf for more info.'''name = 'byteentropy'dim = 256def __init__(self, step=1024, window=2048):super(FeatureType, self).__init__()self.window = windowself.step = stepdef _entropy_bin_counts(self, block):# coarse histogram, 16 bytes per binc = np.bincount(block >> 4, minlength=16) # 16-bin histogramp = c.astype(np.float32) / self.windowwh = np.where(c)[0]H = np.sum(-p[wh] * np.log2(p[wh])) * 2 # * x2 b.c. we reduced information by half: 256 bins (8 bits) to 16 bins (4 bits)Hbin = int(H * 2) # up to 16 bins (max entropy is 8 bits)if Hbin == 16: # handle entropy = 8.0 bitsHbin = 15return Hbin, cdef raw_features(self, bytez, lief_binary):output = np.zeros((16, 16), dtype=np.int)a = np.frombuffer(bytez, dtype=np.uint8)if a.shape[0] < self.window:Hbin, c = self._entropy_bin_counts(a)output[Hbin, :] += celse:# strided trick from here: http://www.rigtorp.se/2011/01/01/rolling-statistics-numpy.htmlshape = a.shape[:-1] + (a.shape[-1] - self.window + 1, self.window)strides = a.strides + (a.strides[-1],)blocks = np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides)[::self.step, :]# from the blocks, compute histogramfor block in blocks:Hbin, c = self._entropy_bin_counts(block)output[Hbin, :] += creturn output.flatten().tolist()def process_raw_features(self, raw_obj):counts = np.array(raw_obj, dtype=np.float32)sum = counts.sum()normalized = counts / sumreturn normalized
这段代码是来自知名的项目EMBER(参考1),EMBER对PE文件提取了很多特征,EMBER也是一个数据集和benchmark。
在github中搜索ByteEntropyHistogram(FeatureType)这个关键字符串,或者google上搜索,都能搜到很多项目、博客,包括深度学习和传统机器学习方向,有些博客中也写了这是在计算熵值Entropy。所以,可以看到很多地方对直接引用这段代码来对PE文件(或者任意二进制文件)来做特征工程,笔者实测其效果也确实不错。
但是这段代码理解起来是不太容易的,它的计算过程是怎么样的?它真的只是在计算熵值吗?它代码中block >> 4是在做什么?
下面就一步一步来理解这段做特征工程的代码。
2. 动态运行调试
先让代码跑起来看看,这是工程上调试常用的方法。让代码运行起来,就能知道运行流程是怎样,各个函数的输入输出是怎样,也就能获取到代码不同位置处的中间结果,就能一步一步把问题分析清楚。
要让ByteEntropyHistogram这个class的代码运行起来,就要稍做修改,比如删除它的父类,去掉一些函数中没用到的参数,删除初始化函数中和父类初始化相关的部分。
import numpy as npclass ByteEntropyHistogram():name = 'byteentropy'dim = 256def __init__(self, step=1024, window=2048):self.window = windowself.step = stepdef _entropy_bin_counts(self, block):# coarse histogram, 16 bytes per binc = np.bincount(block >> 4, minlength=16) # 16-bin histogramp = c.astype(np.float32) / self.windowwh = np.where(c)[0]H = np.sum(-p[wh] * np.log2(p[wh])) * 2 # * x2 b.c. we reduced information by half: 256 bins (8 bits) to 16 bins (4 bits)Hbin = int(H * 2) # up to 16 bins (max entropy is 8 bits)if Hbin == 16: # handle entropy = 8.0 bitsHbin = 15return Hbin, cdef raw_features(self, bytez):output = np.zeros((16, 16), dtype=np.int32)a = np.frombuffer(bytez, dtype=np.uint8)if a.shape[0] < self.window:Hbin, c = self._entropy_bin_counts(a)output[Hbin, :] += celse:# strided trick from here: http://www.rigtorp.se/2011/01/01/rolling-statistics-numpy.htmlshape = a.shape[:-1] + (a.shape[-1] - self.window + 1, self.window)strides = a.strides + (a.strides[-1],)blocks = np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides)[::self.step, :]# from the blocks, compute histogramfor block in blocks:Hbin, c = self._entropy_bin_counts(block)output[Hbin, :] += creturn output.flatten().tolist()def process_raw_features(self, raw_obj):counts = np.array(raw_obj, dtype=np.float32)sum = counts.sum()normalized = counts / sumreturn normalizedwith open('cfdbbd60c7dd63db797fb27e1c427077ce1915b8894ef7165d8715304756a7e2', 'rb') as fr:bytez = fr.read()# get binary file bytes arraybe = ByteEntropyHistogram()raw_obj = be.raw_features(bytez)# get raw feature fea_vec = be.process_raw_features(raw_obj)# get final feature vectorprint('out',fea_vec.shape)# (256,) float 1d-vector
最终读入一个二进制文件,依次调用ByteEntropyHistogram提供的函数,就能得到特征向量。
这个运行的过程是:
raw_features()中,使用滑动窗口,来对每一个窗口中的二进制数据(byte数组,就是代码中的block变量),调用_entropy_bin_counts(block),计算Hbin和c的值- 计算得到的c值,被根据Hbin指定的位置,累加到一个16*16的二维矩阵中(
output[Hbin, :] += c) - 这个二维矩阵最终被拉平(reshape)为一个以为向量(
return output.flatten().tolist()),就是代码中的raw_obj的值 - 最终raw_obj被
process_raw_features()函数,做了简单的 normalization,就是每个数据值除以总和(normalized = counts / sum)
这个过程中的关键点,是两个函数:_entropy_bin_counts(block)和raw_features(),下面对这两个函数进行更细节的分析
3._entropy_bin_counts(block)的计算过程
- 函数输入值
这个函数是对一个窗口中的数据进行计算,所以输入的block表示byte数组;byte数组可以理解为一个list结构,其中的每个数据值都是0~255之间的一个整数。比如:
block中就存储了读入的byte数组,举例如下
bytez = b'MZ\x90\x00\x03\x00\x00\x00\x04'
这个例子中,MZ是PE文件的标识,0x是十六进制数据。这个bytez数组可以转换为如下等效的int数组:
bytez = [77,90,144,0,3,0,0,0,4]
byte数组中有9个数据,字母’M’的ASCII码值为十进制整数77,'Z’的ASCII码值为90。上面两个bytez数组的值是一样的。
程序种最终会将bytez转换为np.array格式作为block,即block = np.frombuffer(bytez, dtype=np.uint8),这个过程举例如下:
import numpy as np
bytez = b'MZ\x90\x00\x03\x00\x00\x00\x04'
block = np.frombuffer(bytez, dtype=np.uint8)
print(block)# array([ 77, 90, 144, 0, 3, 0, 0, 0, 4], dtype=np.uint8)
- block >> 4
函数中接收到block数组后,会先对block做一个这个操作block >> 4。这是右移操作,会对block数组中每个数据都右移4位。因为block中的数据是8位int数据,所以右移4位相当于去掉低4位,保留高4位数据。也就是每个数据除以16(2的4次方)后的整数。这个过程举例如下:
block = np.array([ 77, 90, 144, 0, 3, 0, 0, 0, 4], dtype=np.uint8)
y = block >> 4
print(y) # array([4, 5, 9, 0, 0, 0, 0, 0, 0], dtype=uint8)
输入函数的block中的数据是8位int数据,所以每个数据值的范围在[0,255],经过block >> 4的操作后,每个数据取值为[0,15]。这相当于模糊了数据的取值范围,优点是降低了最终特征向量的维度,缺点是降低/模糊了数据精度。
- bincount
bincount是numpy中用于统计array中每个数据出现次数的函数,我们这里的用法是 c = np.bincount(block >> 4, minlength=16),这里的minlength说明输出的数据维度至少为16。具体到我们的数据,经过block >> 4的操作后,每个数据取值为[0,15],设置minlength为16,则最会输出一个维度为16的一维数组,其中表示0~15中每个数据出现的次数。
这个c变量是函数返回值中比较重要的一个参数,它就是对每个窗口中数据做直方图统计的结果。
- 熵值计算
函数中接下来的这一部分,主要是在计算信息熵的值
p = c.astype(np.float32) / self.window #计算每个数据出现的概率,window默认值为2048
wh = np.where(c)[0]#输出满足条件 (即非0) 元素的坐标
# 下面是计算信息熵H,并放大2倍
H = np.sum(-p[wh] * np.log2(p[wh])) * 2
# 再对信息熵值放大2倍,最终相当于Hbin是信息熵值的4倍后的整数
Hbin = int(H * 2) # up to 16 bins (max entropy is 8 bits)
if Hbin == 16: # handle entropy = 8.0 bitsHbin = 15# 该操作让Hbin返回值在[0,15]范围内
这里在对c变量计算信息熵,并将信息熵乘以4后,取整数,而且改变其边界值(如果Hbin == 16则将其值改变为15,Hbin = 15)。
c变量中的值,是[0,15]每个值的出现次数,所以一共有16个概率值(p),当概率相等时信息熵结果数值最大(参考2中的定理)。所以信息熵H最大值为log2(16)=4。代码中将这个值扩大4被后得到Hbin,则Hbin的取值范围就是[0,1,2,…,16]。代码中最后将边界值改为15,所以最终返回的Hbin的取值范围就是[0,1,2,…,15]。
至此,该函数的两个返回值
c:block中数据除以4取整后每个数值的出现次数,是1*16的一维数组,表示直方图向量Hbin: 是[0,15]中的一个整数,表示对c计算信息熵并处理后的整数值
4. raw_features()
这个函数是对整个二进制文件提取特征的总函数,理解它的关键在于如下几行核心逻辑:
output = np.zeros((16, 16), dtype=np.int32)# 16*16的二维数组
# 用滑动窗口把整个二进制文件切割为多个block的字节数组存储到blocks中
for block in blocks:# 对每个block的byte数组计算 Hbin(信息熵)和c(直方图向量)Hbin, c = self._entropy_bin_counts(block)# 在信息熵Hbin相同的维度上,对c累加output[Hbin, :] += c
return output.flatten().tolist()# 最终将16*16的二维数组转换为1*256的一维数组 作为返回值
- 滑动窗口及step设置
class的init函数中,有设置step=1024, window=2048。这说明滑动窗口的大小是2048(字节),每次移动(滑动)的距离数是1024字节
- 如果文件byte数组size小于窗口宽度
如果二进制文件的size比较小,有可能小于2048字节,则直接将这个二进制文件的字节数组拿去计算Hbin(信息熵)和c(直方图向量)
- 滑动窗口过程
该函数的else部分,首先 用滑动窗口把整个二进制文件切割为多个block的字节数组存储到blocks中。
- 结果累加
并对每个窗口block的byte数组计算 Hbin(信息熵)和c(直方图向量),在信息熵Hbin相同的维度上,对c累加。最终将1616的二维数组转换为1256的一维数组 作为返回值。
总结
EMBER对PE文件提取了广泛被使用的 ByteEntropyHistogram 特征,这是直接对二进制文件提取特征的一个案例。这个特征的本质上是利用滑动窗口的过程,对各个窗口中二进制数据做模糊后,求取其直方图的信息熵,在不同信息熵值的维度下,对各个窗口中数据直方图向量值累加的结果。
最终,对这个class做个整体的注释:
class ByteEntropyHistogram():name = 'byteentropy'# 该特征名字dim = 256# 该特征最终返回数据的维度,即如下output变量被flatten为一维数组(数据类型为np.int32)def __init__(self, step=1024, window=2048):self.window = window# 滑动窗口的窗口大小,单位是字节,默认是2048字节self.step = step# 滑动窗口的移动宽度,单位是字节,默认是1024字节# 对输入的block数据处理后,计算信息熵及直方图# block为1维的numpy数组,类型是dtype=np.uint8,说明数据值大小为[0,255](即字节数据)def _entropy_bin_counts(self, block):# block >> 4会让block数组中每个数据值都除以16,最终每个数据值变为[0,15]c = np.bincount(block >> 4, minlength=16) # 统计并返回0~15这16个整数的出现次数:直方图向量# 计算 直方图向量c的信息熵值,并将信息熵值放大4倍后标记为Hbinp = c.astype(np.float32) / self.window#计算每个数据出现的概率,window默认值为2048wh = np.where(c)[0]#输出满足条件 (即非0) 元素的坐标# 下面是计算信息熵H,并放大2倍H = np.sum(-p[wh] * np.log2(p[wh])) * 2 # * x2 b.c. we reduced information by half: 256 bins (8 bits) to 16 bins (4 bits)# 再对信息熵值放大2倍,最终相当于Hbin是信息熵值的4倍后的整数Hbin = int(H * 2) # up to 16 bins (max entropy is 8 bits)if Hbin == 16: # handle entropy = 8.0 bitsHbin = 15# 该操作让Hbin返回值在[0,15]范围内return Hbin, c# Hbin为处理后得到的信息熵值,是整数,取值范围[0,15];c是直方图向量def raw_features(self, bytez):# 结果放到16x16的整数二维数组中output = np.zeros((16, 16), dtype=np.int32)# 将读入的字节数组bytez,转换为np.array的一维向量,每个数据值大小为[0,255]a = np.frombuffer(bytez, dtype=np.uint8)# 如果二进制文件字节数小于window,则直接计算Hbin和c后放到output矩阵中if a.shape[0] < self.window:Hbin, c = self._entropy_bin_counts(a)output[Hbin, :] += celse:# 如果二进制文件字节数(size)大于window大小,则滑动窗口# 用滑动窗口把整个二进制文件切割为多个block的字节数组存储到blocks中# strided trick from here: http://www.rigtorp.se/2011/01/01/rolling-statistics-numpy.htmlshape = a.shape[:-1] + (a.shape[-1] - self.window + 1, self.window)strides = a.strides + (a.strides[-1],)blocks = np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides)[::self.step, :]# from the blocks, compute histogramfor block in blocks:# 对每个block的byte数组计算 Hbin(信息熵)和c(直方图向量)Hbin, c = self._entropy_bin_counts(block)# 在信息熵Hbin相同的维度上,对c累加output[Hbin, :] += creturn output.flatten().tolist()# 最终将16*16的二维数组转换为1*256的一维数组 作为返回值# 做简单的 normalization: X = X/SUM(X)def process_raw_features(self, raw_obj):# 输入的raw_obj是一维向量int32类型(即raw_features()函数返回值)counts = np.array(raw_obj, dtype=np.float32)sum = counts.sum()# 对一维数组中的值求和normalized = counts / sum# 每个数据值求除以总和,即做简单的normalizationreturn normalized
参考
- https://github.com/elastic/ember/blob/master/ember/features.py#L71
- https://blog.csdn.net/feixi7358/article/details/83861858
相关文章:

详解EMBER数据集中对PE文件提取ByteEntropyHistogram特征
1. 引入 在我们对PE文件提取特征时,经常会在PE特征工程的项目中,看到如下这段代码 class ByteEntropyHistogram(FeatureType): 2d byte/entropy histogram based loosely on (Saxe and Berlin, 2015).This roughly approximates the joint probability…...
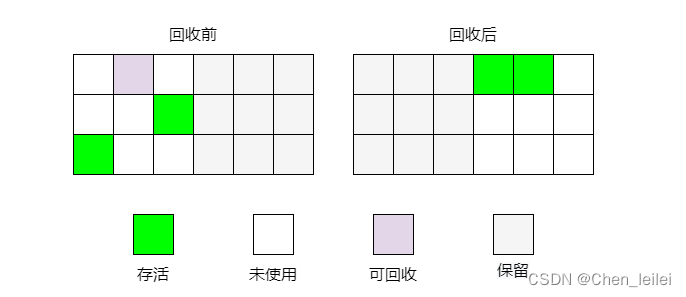
垃圾回收机制和常用的算法
一.什么是垃圾回收? 垃圾回收主要针对堆和方法区(非堆),程序计数器,虚拟机栈,本地方法栈这三个区域属于线程私有,随着线程的销毁,自然就会雄安会了,因此不需要堆着三个区域进行垃圾…...
【PostgreSQL】系列之 一 schema详解(二)
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_Linux,Java基础学习,大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的…...
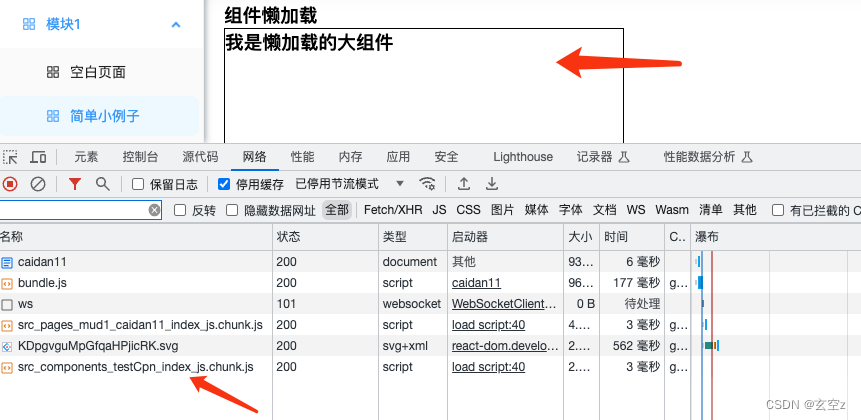
性能优化-react路由懒加载和组件懒加载
背景 随着项目越来越大,打包后的包体积也越来越大,严重影响了首屏加载速度,需要对路由和组件做懒加载处理 主要用到了react中的lazy和Suspense。 废话不多说,直接上干货 路由懒加载 核心代码 import React, { lazy, Suspens…...

静态网页加速器:优化性能和交付速度的 Node.js 最佳实践
如何使用 Node.js 发布静态网页 在本文中,我们将介绍如何使用 Node.js 来发布静态网页。我们将创建一个简单的 Node.js 服务器,将 HTML 文件作为响应发送给客户端。这是一个简单而灵活的方法,适用于本地开发和轻量级应用。 1、创建静态网页…...

Spring 非自定义Bean注解
Spring 非自定义Bean注解 1.概述 在xml中配置的Bean都是自己定义的, 例如:UserDaolmpl,UserServicelmpl。但是,在实际开发中有些功能类并不是我们自己定义的, 而是使用的第三方jar包中的,那么,…...
微信小程序:点击按钮实现数据加载(带模糊查询)
效果图 代码 wxml: <!-- 搜索框--> <form action"" bindsubmit"search_all_productiond"><view class"search_position"><view class"search"><view class"search_left">工单号:</view…...

2023-2029年中国烘焙工坊市场经营管理风险与未来竞争优势分析报告
2023-2029年中国烘焙工坊市场经营管理风险与未来竞争优势分析报告 ################################### 《报告编号》: BG460671 《出版时间》: 2023年8月 《出版机构》: 中智正业研究院 免费售后 服务一年,具体内容及订购流程欢迎咨询客服人员 内容简介&…...

用Rust实现23种设计模式之适配器
关注我,学习Rust不迷路 在 Rust 中,可以使用结构体和 trait 来实现适配器模式。适配器模式是一种结构型设计模式,它允许将一个类的接口转换为客户端所期望的另一个接口。下面是一个使用 Rust 实现适配器模式的示例,带有详细的注释…...
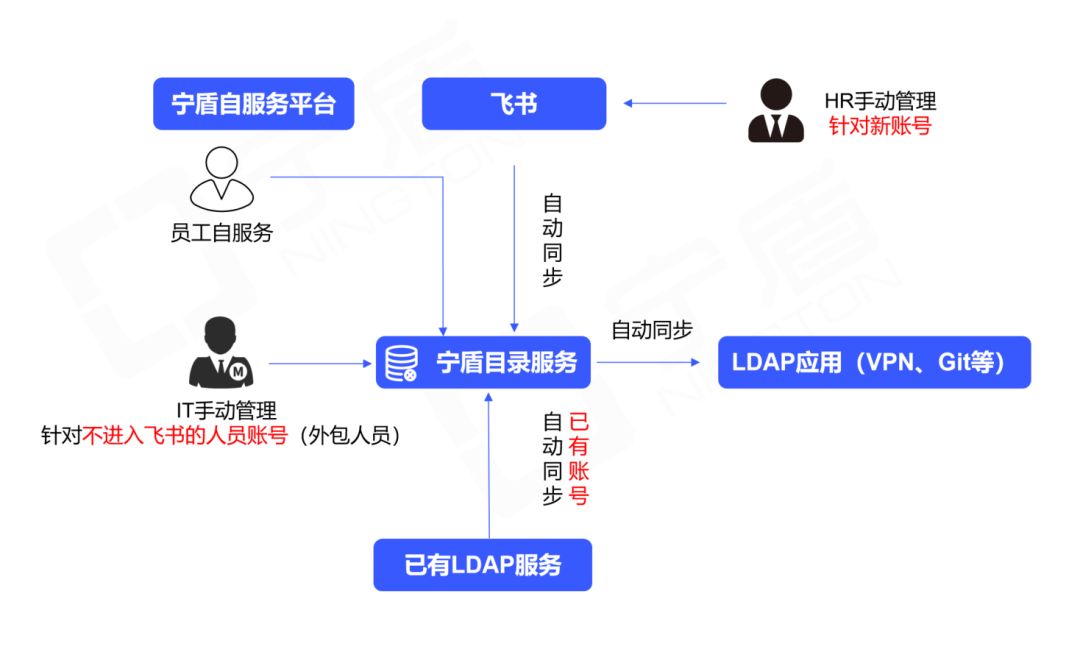
替换开源LDAP,西井科技用宁盾目录统一身份,为业务敏捷提供支撑
客户介绍 上海西井科技股份有限公司成立于2015年,是一家深耕于大物流领域的人工智能公司,旗下无人驾驶卡车品牌Q-Truck开创了全球全时无人驾驶新能源商用车的先河,迄今为止已为全球16个国家和地区,120余家客户打造智能化升级体验…...
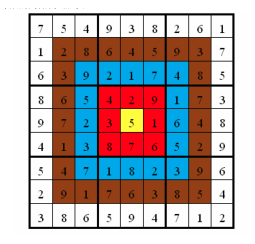
靶形数独
题目描述 小城和小华都是热爱数学的好学生,最近,他们不约而同地迷上了数独游戏,好胜的他们想用数独来一比高低。但普通的数独对他们来说都过于简单了,于是他们向 Z 博士请教,Z 博士拿出了他最近发明的“靶形数独”&am…...

C语言阶段性测试题
【前言】:本部分是C语言初阶学完阶段性测试题,最后一道编程题有一定的难度,需要多去揣摩,代码敲多了,自然就感觉不难了,加油,铁汁们!!! 一、选择题 1.下面程…...

java工厂设计模式
Java中的工厂设计模式是一种创建型设计模式,它提供了一种将对象的创建逻辑抽象出来的方法,使得客户端代码不需要直接实例化具体的类,而是通过一个共同的接口来创建对象。这样可以降低代码之间的耦合性,提高代码的可维护性和可扩展…...
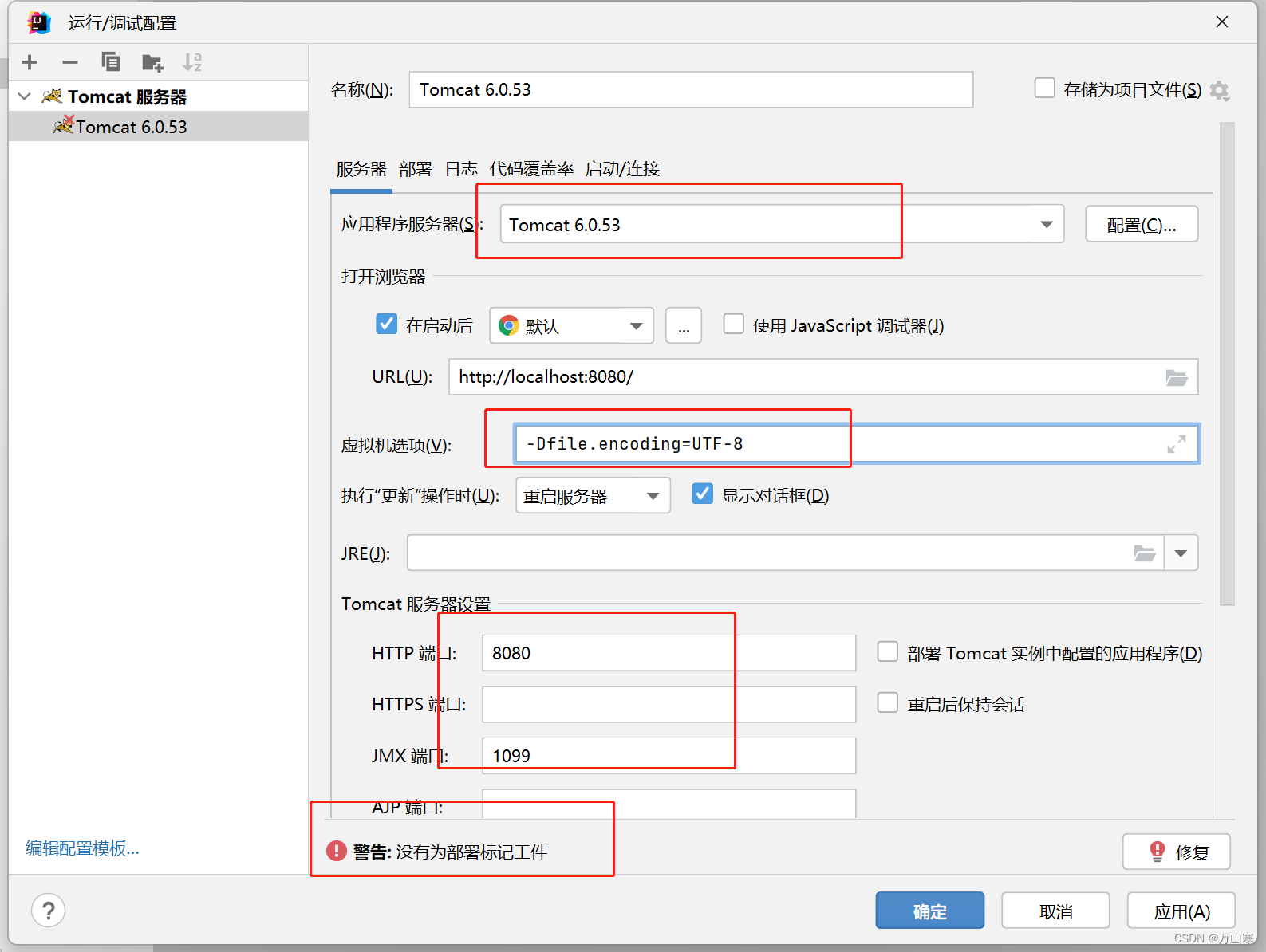
idea运行web老项目
idea打开老项目 首先你要用idea打开老项目,这里看我之前发的文章就可以啦 运行web项目 1. 编辑配置 2. 添加tomcat项目 3. 设置tomcat参数 选择本地tomcat,注意有的tomcat版本,不然运行不了设置-Dfile.encodingUTF-8 启动,这样…...

JS进阶-Day3
🥔:永远做自己的聚光灯 JS进阶-Day1——点击此处(作用域、函数、解构赋值等) JS进阶-Day2——点击此处(深入对象之构造函数、实例成员、静态成员等;内置构造函数之引用类型、包装类型等) 更多JS…...

springboot后端用WebSocket每秒向前端传递数据,python接收数据
1 springboot 1.1 加依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency> 1.2 WebSocketConfig 后端设置前端请求的网址,注册请求的信息 import org.…...

记录uniapp 滚动后溢出显示空白的办法
写了一个横向滚动,超出可视区域图片空白,上下滚动页面可视区域图片显示,不可见区域滚动出来变成空白 错误css如下 width: 678rpx;height: 264rpx;background: #ffffff;border-radius: 16rpx;margin: 64rpx 18rpx 10rpx 18rpx;overflow-y: hid…...

设计原则学习之里氏替换原则
以下内容均来自抖音号【it楠老师教java】的设计模式课程。 1、原理概述 子类对象(objectofsubtype/derivedclass)能够替换程序(program)中父类对象(objectofbase/parentclass)出现的任何地方,…...

排序进行曲-v4.0
文章目录 小程一言快速排序步骤详细解释具体步骤 举例总结 复杂度分析时间复杂度分析:空间复杂度分析:注意 应用场景总结 实际举例结果总结 代码实现结果解释 小程一言 这篇文章是在排序进行曲3.0之后的续讲, 这篇文章主要是对快速排序进行细…...
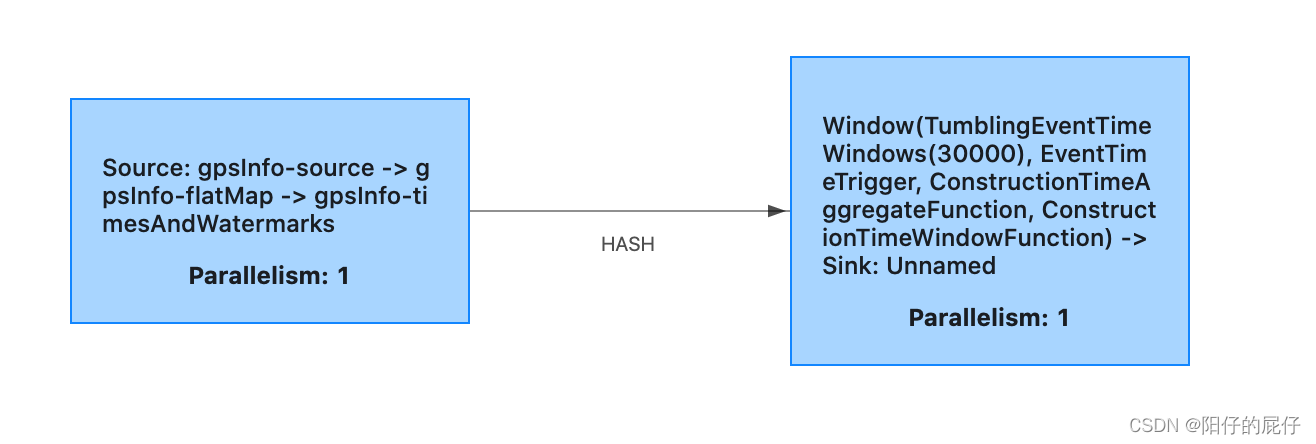
Flink 系列四 Flink 运行时架构
目录 前言 介绍 1、程序结构 1.1、Source 1.2、Transformation 1.3、Sink 1.4、数据流 2、Flink运行时组件 2.1、Dispatcher 2.2、JobManager 2.3、TaskManager 2.4、ResourceManager 3、任务提交流程 3.1、standalone 模式 3.2、yarn 模式 4、任务调度原理 4…...

Google 迎来「DeepSeek 时刻」:TurboQuant算法实现bit无损、×加速、×压缩、零预处理范
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...

推荐一家专业做标签打印软件
1. 上海敖维科技(本地自研代理双强) • 定位:中大型企业/工厂级标签管理,上海本土17年行业经验 • 核心产品: ◦ 自研:码尚智汇链/云标签平台(B/S架构,模板云端下发、打印监控、追溯…...

运维基础入门到精通,收藏这篇就够了
运维基础入门到精通,收藏这篇就够了 运维基础 一、运维概述 1、运维岗位的收入情况   2、运维的职位定义 什么是运维? 在技术人员之间,一致对运维有一个开玩笑的认知:运维就是修电脑的、装网线的、背锅的…...

OpenClaw定时任务管理:千问3.5-27B实现凌晨自动备份
OpenClaw定时任务管理:千问3.5-27B实现凌晨自动备份 1. 为什么需要AI驱动的定时任务? 上个月我经历了一次惨痛的数据丢失——连续三天熬夜写的代码,因为笔记本突然蓝屏而全部消失。虽然最终通过碎片文件恢复了部分内容,但这件事…...

Perseus开源补丁:3步轻松解锁《碧蓝航线》全皮肤完整指南
Perseus开源补丁:3步轻松解锁《碧蓝航线》全皮肤完整指南 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 还在为《碧蓝航线》中那些精美的皮肤无法解锁而烦恼吗?Perseus开源补丁为…...

OpenProject API集成深度解析:构建企业级工作流自动化引擎
OpenProject API集成深度解析:构建企业级工作流自动化引擎 【免费下载链接】openproject OpenProject is the leading open source project management software. 项目地址: https://gitcode.com/GitHub_Trending/op/openproject 在当今的软件开发与项目管理…...

下沉市场蓝海!广东墙体广告成品牌增长“第二曲线”
当城市市场竞争进入白热化,越来越多品牌将目光投向广阔的下沉市场,而广东墙体广告凭借独特的地域优势和灵活的投放策略,成为品牌抢占下沉市场、实现增长突围的“第二曲线”,持续占据行业热搜榜单。作为经济大省,广东不…...

YOLO12实战体验:上传图片秒出结果,80类物体识别全解析
YOLO12实战体验:上传图片秒出结果,80类物体识别全解析 1. 初识YOLO12:新一代实时目标检测利器 YOLO12作为Ultralytics在2025年推出的最新目标检测模型,继承了YOLO系列"快、准、狠"的特点。相比前代YOLOv11,…...

解密900万图像:Open Images数据集在计算机视觉领域的革命性应用
解密900万图像:Open Images数据集在计算机视觉领域的革命性应用 【免费下载链接】dataset The Open Images dataset 项目地址: https://gitcode.com/gh_mirrors/dat/dataset 当计算机视觉研究者面临数据稀缺困境时,Open Images数据集如同一座数字…...

OPUS编解码器在audio DSP上的移植和应用贩
前言 在使用 kubectl get $KIND -o yaml 查看 k8s 资源时,输出结果中包含大量由集群自动生成的元数据(如 managedFields、resourceVersion、uid 等)。这些信息在实际复用 yaml 清单时需要手动清理,增加了额外的工作量。 使用 kube…...