android 如何分析应用的内存(十三)——perfetto
android 如何分析应用的内存(十三)
本篇文章是native内存的最后一篇文章——perfetto
perfetto简介
从2018年始,android开发者峰会正式推出perfetto工具。从此perfetto成为安卓最重要的工具之一。在2018年以前,android使用systrace工具,进行同样的工作。
perfetto结构
perfetto分成三部分:
第一部分: 录制。这部分将录制不同的数据来源,如:内存,cpu调度,网络等等。然后将其存储在一个共享内存中。
第二部分: 处理。这部分将共享内存中的数据,使用trace_processor库处理成易于理解和分析的格式。同时暴露一个SQL的查询接口。使用者可以使用SQL查询语句,进行查询
第三部分: 可视化。这部分使用第二部分trace_processor处理之后的格式进行UI显示。如:Perfetto UI 再如:Android Studio和Android GPU:Inspector
注意1:perfetto的数据来源,丰富多样,除了常见的系统提供的以外,还可以通过perfetto提供的SDK,自定义数据来源
注意2:trace_processor是库的名字,也是一个可执行文件的名字,这个可执行文件以shell的方式进行交互
perfetto的使用
perfetto工程。中包含各种各样的脚本用于帮助使用perfetto。在介绍各种脚本之前,我们先看看,怎么手动启动perfetto。
perfetto命令行选项
perfetto是Android的一个内置命令。它有两种运行模式:
- 轻量模式:所有配置选项都作为命令行参数提供,但可用的数据源仅限于ftrace和atrace。这种模式类似于systrace。
- 常规模式:使用配置,它可以收集所有的数据来源,包括自定义的数据来源。
注意:ftrace是linuix内核提供的跟踪框架。atrace是Android提供的跟踪框架,它基于ftrace开发,并提供了Android特有的功能,如跟踪am,wm等
不管是轻量模式,还是常规模式,他们都有如下的共同的参数:
-d, --background:后台运行
-o, --out OUT_FILE:输出文件
--dropbox TAG:通过DropBoxManager的API上传跟踪的数据
--no-guardrails:启用 --dropbox时,将禁用对过度资源使用的保护措施
--query:查询服务状态,并打印
--query-raw:跟--query一样,但是打印的数据为proto格式
-h, --help:打印帮助信息
轻量模式
下面给出一个轻量模式的例子
adb shell perfetto --out /sdcard/wm.txt wm
该命令表示跟踪wm,同时将结果输出到out指定的文件中。当然ftrace事件也支持跟踪。
轻量模式支持的参数有:
-t, --time TIME[s|m|h]:运行的时间
-b, --buffer SIZE[mb|gb]:指定buffer的大小
-s, --size SIZE[mb|gb]:指定最大文件大小,单位为兆字节(MB)或千兆字节(GB)。默认情况下perfetto仅使用内存中的环形缓冲区。
常规模式
下面给出一个常规模式的例子。
adb shell perfetto --txt --config /sdcard/record.txt
告诉perfetto使用record.txt文件中的配置,进行录制。
其中--txt表示,使用的是protocol buffer格式,简写为pbtxt
常规模式支持的选项有
-c, --config CONFIG_FILE:配置文件
--txt:表示使用pbtxt格式的配置
其中record.txt内容如下,各行解释,见其后
duration_ms: 10000buffers: {size_kb: 8960fill_policy: DISCARD
}
buffers: {size_kb: 1280fill_policy: DISCARD
}
data_sources: {config {name: "linux.ftrace"ftrace_config {ftrace_events: "sched/sched_switch"ftrace_events: "power/suspend_resume"ftrace_events: "sched/sched_process_exit"ftrace_events: "sched/sched_process_free"ftrace_events: "task/task_newtask"ftrace_events: "task/task_rename"ftrace_events: "ftrace/print"atrace_categories: "gfx"atrace_categories: "view"atrace_categories: "webview"atrace_categories: "camera"atrace_categories: "dalvik"atrace_categories: "power"}}
}
data_sources: {config {name: "linux.process_stats"target_buffer: 1process_stats_config {scan_all_processes_on_start: true}}
}
其中各个字段的解释如下,因为本文章主要是内存分析。所以不会解释所有的配置项,仅仅解释上文出现的配置。
duration_ms:perfetto运行的时间,单位毫秒
buffers:定义buffer的大小和buffer满了之后的行为size_kb:即为定义的大小fill_policy:即buffer满了之后的行为,默认是一个环形缓冲buffer,此处定义为:直接丢弃buffers可以定义多个buffer。通常情况下定义一个buffer是没有问题的。但是当写入数据的速率不同时,可能需要定义多个buffer.如果定义了多个buffer,就将data_sources的target_buffer指定为对应的buffer即可。如上列第二个data_sourcesdata_sources:定义数据源config:配置指定的数据源。name:数据源名字:如linux.ftracetarget_buffer:将录制的数据,写入哪一个bufferftrace_config:详细指定linux.ftrace的来源。如上面的ftrace事件和atrace的categoriesprocess_stats_config:详细指定linux.process_stats的状态来源。如上面的scan_all_processes_on_start,表示在启动的时候,所有进程都会被扫描,并dump
perfetto手动配置内存分析
正如前面介绍的一样,我们修改data_sources配置来录制内存。在前面的章节中,使用了test_malloc应用进行内存分析。同样本文也将使用这个应用,进行perfetto的实验。
下面从一个简单的例子开始:
- 运行命令
键入下面的命令,如下:
adb shell perfetto \-c - --txt \-o /data/misc/perfetto-traces/trace \
<<EOFbuffers: {size_kb: 63488fill_policy: DISCARD
}
buffers: {size_kb: 2048fill_policy: DISCARD
}
data_sources: {config {name: "android.packages_list"target_buffer: 1}
}
data_sources: {config {name: "android.heapprofd"target_buffer: 0heapprofd_config {sampling_interval_bytes: 4096process_cmdline: "com.example.test_malloc"shmem_size_bytes: 8388608block_client: true}}
}
duration_ms: 10000EOF
我们先介绍上文出现的配置项,同样的不会介绍所有的配置项,而是介绍上文出现的配置项。
因为,perfetto提供了一个heap_profile的python脚本帮助我们完成这项工作。后文将会
详细介绍这个脚本的参数使用。
1. 首先定义了两个buffer。一个大小2048kb,一个大小63488kb。
2. 数据源1:来自于android.packages_list,将其数据写入buffer 1中
3. 数据源2:来自于android.heapprofd。将其写入buffer 0中
4. 其中android.pacages_list数据源,用于获取包的详细信息。
5. android.heapprofd数据源,用于获取android堆的详细信息。这是我们分析native内存的主要数据来源。
6. heapprofd_config:分别配置了,采样间隔(又称为采样率)为4096字节。
7. heapprofd配置应用为:com.example.test_malloc
8. heapprofd配置自己的共享内存的大小为:8388608(heapprofd的内存见后文)
9. heapprofd配置:当buffer满的时候,要等待buffer腾出空间。即block_client为true
注意:上面关于heapprofd的配置,在后文会做详细介绍。
键入命令完成之后,按下enter键,即开始录制,
- 查看
在手机上,触发内存泄漏,然后10s后,会生成一个/data/misc/perfetto-traces/trace文件,将其拖入Perfetto UI中,如下图

- UI界面说明和分析
从上面截图可以看到,每一个进程下面有一个heapp rofile.同一行中有一个棱形图标,这个菱形图标,表示:从开始分析到这个棱形图标结束,这段时间内的所有heap的一个snapshot.
点击这个棱形图标,将会出现,下面的调用栈。
其中:
- Unreleased malloc size:表示还未释放的内存大小有多少
- Total malloc size:总共分配的内存是多少,包括已经释放了的
- Unreleased malloc count:未调用free的分配的次数
- Total malloc count:总共分配的次数
为了定位内存泄漏,最简单的方法是:查看Unreleased malloc count。即还有多少次分配未调用free
过程如下:

可以看到,总共有9次未被释放
然后一层一层往下找,即可找到,我们测试程序中的例子,如下

从中我们可以看到,在Java_com_example_test_1malloc_MainActivity_stringFromJNI函数中
有4次未释放。
切换到Unreleased malloc size标签下,能看看到,总计为:16kB

然后查看代码如下:
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_test_1malloc_MainActivity_stringFromJNI(JNIEnv* env,jobject /* this */) {std::string hello = "Hello from C++";//未释放的地方volatile int * p = new int[1024];*p = 123456;return env->NewStringUTF(hello.c_str());
}
上面的代码中,指针p未进行释放操作。
注意:因为heapprofd只会记录开始运行到结束,这段时间的内存分配,因此在heapprofd开始之前的,应用的内存分配不会被记录下来。
perfetto脚本配置内存分析
上面介绍了,手动配置prefetto进行内存的抓取。接下来,我们将使用perfetto工程中的脚本工具:heap_profile。
- 下载heap_profile工具
curl -LO https://raw.githubusercontent.com/google/perfetto/master/tools/heap_profile
chmod +x heap_profile
- 使用headp_profile录制内存使用情况
## 录制com.example.test_malloc的内存情况
./heap_profile -n com.example.test_malloc
会出现如下的结果:
Profiling active. Press Ctrl+C to terminate.
You may disconnect your device.
如果出现Profiling active,这表示正在运行中。
此时在手机中,进行相应的操作,触发内存泄漏。
然后按下ctrl+c结束录制。
则会输出如下的结果
^CWaiting for profiler shutdown...
Wrote profiles to /var/folders/fs/mg80v00d5yj67pmqp_qh57_c0000gn/T/629a10 (symlink /var/folders/fs/mg80v00d5yj67pmqp_qh57_c0000gn/T/heap_profile-latest)
The raw-trace file can be viewed using https://ui.perfetto.dev.
The heap_dump.* files can be viewed using pprof/ (Googlers only) or https://www.speedscope.app/.
The two above are equivalent. The raw-trace contains the union of all the heap dumps
注意:heap_profile只能录制,在它运行期间的内存情况,不能录制heap_profile运行之前的情况
- 查看结果
打开Perfetto UI。然后将上面路径中的raw-trace拖入刚才打开的网页。
结果查看同上面手动配置perfetto是一模一样的。
手动配置和脚本配置的比较
手动配置可以同时配置多个数据源,因此它比脚本配置,更适合同时录制多个数据源。
这属于perfetto的高级用法,不过有前面关于perfetto的简单介绍,这种所谓的高级也不过是参数的不同而已。
heapprofd守护进程
前面在进行内存分析的时候,指定的数据源为heapprofd.接下来看看heapprofd是什么东西。
一句话概括如下:heapprofd是android设备中运行的一个守护进程,它将android中的进程heap数据,解析成可以被Perfetto UI解释的格式。
注意:heapprofd需要Android10或者更高版本
内存分析工程的组成部分
我们将heapprofd,heap_profile脚本以及其他的工具和库统称为内存分析工程,这里简写为heap profile
heap profile主要分成三个部分:
第一部分:hprofd.so。应用在需要进行内存分析时,会自动加载这个库。并使用这个库将heap中的数据,导出到一个共享内存中。例如在上面配置的shmem_size_bytes: 8388608,即为这部分共享内存的大小
第二部分:heapprofd 一个运行在android 设备内部的守护进程。它负责处理这个共享内存中的数据,并解析这些数据成合适的格式
第三部分:将录制结果使用图形表示出来。如Android Studio在Android profiler中显示出来,
再比如,https://ui.perfetto.dev/将结果显示在网页中。
heapprofd为什么性能好
如果heapprofd跟踪所有的内存,那么将会陷入malloc debug一样的窘境——变得异常缓慢。
而实际上,heaprofd对内存进行采样分析,在采样上,同样有限制:不会对每个字节都采样,而是使用了统计学上的概率分布。
这里使用了统计学上一个比较著名的函数:P(x)=1-e^(-λ)。其中λ=分配的内存大小/采样率(sampling rate)。 这个函数是对指数分布的一个积分。P(x)则表示:分配x字节大小的内存,至少被采样一次的概率。采样率默认为4096字节。P(x)函数图形如下

至于为什么要采用这个函数,则不是本篇文章的讨论范围,推荐阅读马同学关于:泊松分布和指数分布的文章,如下:
指数分布
泊松分布
从上图可见,部分较小的内存分配,可能不会被采样到,这样就省去了很多开销。需要注意的是:如果有多个内存较小的分配,那么它被采样的概率等同于一次分配同等大小的概率
有时候,为了增加某个分配被采样的概率,则需要调整采样率。比如上文手动配置中:sampling_interval_bytes: 4096。
至于heap_profile脚本如何调整,见下文
heap_profile 参数讲解
heap_profile脚本参数如下,想来大家应该能看懂这里面的所有配置项了
-n,--name 名字:需要进行分析的进程的名字,可以是多个进程,各个进程用逗号分开-p, --pid PIDS:需要进行分析的进程的PID,可以是多个进程,各个pid用逗号分开-i, --interval:采样率的大小,单位字节,默认4096字节-o, --output DIRECTORY:输出的目录文件--all-heaps:收集所有的堆--block-client:当buffer满的时候,等待heapprofd腾出buffer里面的空间--block-client-timeout:等待heapprofd腾出buffer空间的最长时间-c, --continuous-dump:连续dump的间隔时间,单位毫秒,0表示禁止连续dump-d, --duration:heap_profile的运行时间,如果没有设置,则一直运行,直到用户输入ctrl+c--disable-fork-teardown:在fork时不要终止客户端。这对使用vfork的程序可能会有用。仅适用于Android 11及以上版本。--disable-selinux:运行期间,disable selinux--dump-at-max:记录最大的内存使用量,而不是在heap_profile运行时刻的最大内存使用量。这对于分析LMK(Low memory killer)有一定帮助--heaps HEAPS:需要收集的堆列表,逗号分开。android 12以上。常见的堆列表有:malloc,art--idle-allocations:跟踪自上次dump以后,每个调用栈有多少字节未被使用--no-android-tree-symbolization:不要进行符号解析--no-block-client:当buffer满时,提前停止性能分析--no-running:不要分析已经运行的程序。需要android 11以上--no-start:不要启动heapprofd--no-startup:不要收集,在性能分析阶段中启动的进程--no-versions:不要获取apk的版本信息--print-config:要打印log--shmem-size:客户端和 heapprofd 之间的缓冲区大小。默认为 8MiB。必须是 4096 的二次幂且至少为 8192。--simpleperf:获取 heapprofd 的 simpleperf 性能分析。仅用于 heapprofd 开发。--traceconv-binary:traceconv工具的路径。仅用于调试使用连续模式
默认情况下heap profile将所有的dump都存储在一个snapshot中。在UI界面上就是只有一个菱形图标。
另外一个可行的方式是:告诉heap profile周期性的将dump数据存储在不同的snapshot中,这样将会在UI界面上看到多个菱形图标。配置如下:
continuous_dump_config {dump_interval_ms: 5000
}
或者通过heap_profile的-c选项。

其中,每一个棱形,都表示从开始时间,到菱形结束时间的所有dump
只采样java的堆
如果我们只想采样java的堆,该如何操作呢?可以通过heap_profile的选项参数--heaps com.android.art
或者在配置文件中,使用:heaps: “com.android.art”
注意:java堆采样,只有在Android 12 及以上才能使用
注意:java堆采样和java堆转储不能混淆
如下图:

从图中可以看到,java堆采样只有两个tab,分别为:
- 总分配大小:在这个调用栈中,有多少个字节被分配了。这些字节可能已经被释放了
- 总的分配次数:在这个调用栈中,有多少次分配。
java堆采样,对于分析大对象分配导致的内存抖动是有巨大帮助的。同时也有助于分析art的分配类型(new,array,class,largeobject)
手动触发snapshot
如果我们想要手动触发堆的snapshot,可以使用如下的方法:
db shell killall -USR1 heapprofd
调用栈的符号化
有时候,调用栈没有名字,此时可以进行离线的符号化,或者调用栈有名字,但是还想知道出问题的点在第几行。这时,就可以进行符号化的操作了。
注意:在进行符号化之前,需要将llvm-symblozier放入PATH路径中,android的llvm-symbolizer在何处找到见:android 如何分析应用的内存(十一)——ASan下面命令将ndk中的必要工具加入PATH中
export PATH=/Users/biaowan/Library/Android/sdk/ndk/25.2.9519653/toolchains/llvm/prebuilt/darwin-x86_64/bin/:$PATH
具体操作如下。
- 配置PERFETTO_BINARY_PATH环境变量
## 配置为当前目录
export PERFETTO_BINARY_PATH=$(pwd)
- 进行数据抓取,详细见上文
./heap_profile -n com.example.test_malloc
- 对raw-trace 进行转换
## 准备对应的so库,放在PERFETTO_BINARY_PATH目录中
## 具体的路径查找见下文
cp -a cp -a ./app/build/intermediates/cxx/Debug/2j414f1k/obj/arm64-v8a/libtest_malloc.so $PERFETTO_BINARY_PATH## 使用traceconv工具,同heap_profile脚本一样,在同一工程的同一目录下
## 下载命令curl -LO https://raw.githubusercontent.com/google/perfetto/master/tools/traceconv
## traceconv将使用llvm-symbolizer工具,对raw-trace文件进行符号化,并存储在symbols文件中
./traceconv symbolize raw-trace > symbols
- 将符号信息写入trace文件中
cat raw-trace symbols > symbolized-trace
- 查看符号化之后的调用栈
如果使用perfetto ui直接查看调用栈,可能不会显示对应的行号,此时需要使用SQL语句。
所有的符号化都存储在stack_profile_symbol表格中。因此可以使用下面的语句,将该表格中的所有行输出。
SELECT * FROM stack_profile_symbol;

从上图可以看到,对应的行号。
符号化的路径查找
可是从上面的操作过程中,似乎漏掉了一个非常重要的信息。那就是traceconv如何知道对应的so库在什么位置。
在上面的例子中,只是简单的将so库移动到PERFETTO_BINARY_PATH目录下。
事实上,traceconv将会依据下面的路径进行查找。以/system/lib/base.apk!foo.so为例,它的build id为abcd1234
- $PERFETTO_BINARY_PATH/system/lib/base.apk!foo.so
- $PERFETTO_BINARY_PATH/system/lib/foo.so
- $PERFETTO_BINARY_PATH/base.apk!foo.so
- $PERFETTO_BINARY_PATH/foo.so
- $PERFETTO_BINARY_PATH/.build-id/ab/cd1234.debug
注意第五点:.build-id后面的路径规则为:使用前两字字母为子目录如(abcd1234的ab)。然后使用后面的所有字母如(abcd1234的cd1234)再加上.debug,即cd1234.debug作为目录。
符号化常见问题
问题1:
[855.670] subprocess_posix.cc:47 Failed to exec llvm-symbolizer (errno: 2, No such file or directory)
表示没有配置llvm-symbolizer在PATH路径中.将其加入路径中,即可解决
问题2:
[855.680] local_symbolizer.cc:344 Could not find /data/app/~~gx5t-n8HJXchIN64wh1QNg==/com.example.test_malloc-iRcQ3mTPeH-1Q84dFo81GQ==/lib/arm64/libtest_malloc.so (Build ID: 1807c1edf56cb4a2c27e21e533ea0445a857b100).
- 表示没有找到libtest_malloc.so。此时按照上面介绍的符号化路径的5个规则,挨个检查是否存在对应的so库。
- 如果存在so库,但是依然出现这个问题,则需要比较build id是否相同。读取 build id通过如下的命令
llvm-readelf -n ./app/build/intermediates/cxx/Debug/2j414f1k/obj/arm64-v8a/libtest_malloc.so
- 如果build id不同,则说明没有放置正确版本的so库。如果build id相同,则将so库放在根目录下再试
调用栈的反混淆
在java代码中经常出现混淆之后的代码,对于debug来说非常不舒服。可以使用下面的步骤进行反混淆
- 使用PERFETTO_PROGUARD_MAP环境变量,提供混淆映射如下:
PERFETTO_PROGUARD_MAP=com.example.pkg1=foo.txt:com.example.pkg2=bar.txt
- 使用工具traceconv,进行反混淆
##将raw-trace进行反混淆,输出到deobfuscation_map中
traceconv deobfuscate raw-trace > deobfuscation_map
- 将反混淆结果加入raw-trace中
cat raw-trace deobfuscation_map > deobfuscated_trace
最后使用perfetto ui打开deobfuscated_trace即可。
因为跟符号化的过程和步骤极度相似,所以没有做实验。
故障处理
Buffer overrun
如果分配内存的速度太快,而heap_profd无法跟上,则出现一个buffer overrun,这会导致heapprofd提前结束
如果overrrun被一个短暂的内存尖刺触发,则增加共享内存的大小可以解决这个问题。(传递–shmem-size参数)
或者,传递–interval=16000或更高的值来增加采样间隔(牺牲准确度,详见上文:heapprofd为什么性能好)
性能分析结果为空
在user版本中,只有进行了如下配置的,才能进行性能分析,否则会出现分析结果为空的情况
- profilable
<manifest ...><application><profileable android:shell="true"/>...</application>
</manifest>
- debugable
<manifest ...><applicationandroid:debuggable="true">...</application>
</manifest>
自此,android的内存的native部分已经全部介绍完毕,现在针对前面介绍的所有方法做一个小结
内存方法的总结
- 第零个工具xdd:只能查看任意内存
- 第一个工具gdb:它可以查看:寄存器,和任意位置的内存,分析coredump,能查看栈情况,不能查看堆情况
- 第二个工具lldb:它可以查看:寄存器,和任意位置的内存,分析coredump,能查看栈情况,不能查看堆情况
- 第三个工具自定义malloc:只能查看堆情况,且查看的范围较小,几乎只有自己编译的代码
- 第四个工具malloc hook:能查看所有的堆分配情况
- 第五个工具malloc统计和libmemunreachable:可以查看所有堆分配情况
- 第六个工具malloc debug和libc回调:能查看所有堆分配情况
- 第七个工具ASan/HWASan:只能查看linux的堆分配情况,无法查找android的分配情况,列在此处只是为了知识的完整性
- 第八个工具perfetto:只能查看堆内存分配情况
其中gdb,lldb,ASan/HWAsan也可以作为调试工具出现。
下一个大主题,就是android应用的java部分了,这部分应该怎么进行内存的分析,该怎么分析,敬请期待
相关文章:
android 如何分析应用的内存(十三)——perfetto
android 如何分析应用的内存(十三) 本篇文章是native内存的最后一篇文章——perfetto perfetto简介 从2018年始,android开发者峰会正式推出perfetto工具。从此perfetto成为安卓最重要的工具之一。在2018年以前,android使用syst…...
Chapter20 音乐
目录 音乐 琴键 哆来咪 振动与调式 利萨如曲线 和声与音调与和弦 音乐 在音乐理论中,一个八音度(octave)是一个频率范围相差二倍的区间。在大多数西洋乐器中,一个八音度被分为12个频率比相等的半音程(semitone&a…...

详解Nodejs中的模块化
Nodejs是一个基于Chrome V8引擎的JavaScript运行时环境,它允许开发者使用JavaScript在服务器端运行代码。在Nodejs中,模块化是一种组织和重用代码的重要方式。模块化允许我们将代码拆分成小块,使得代码结构更清晰、易于维护,并促进…...

debug思路 - maven构建报错
问题:maven面板中,进行compile、deploy操作时报错。 debug步骤: 1、鼠标右键选择“修改运行配置”。在运行命令中添加参数-X,用于产生执行调试输出。例如:compile -f -X pom.xml。 2、再次进行compile、deploy操作&…...
DSP学习笔记
间接寻址(通过放在辅助寄存器里面,可以对地址包括很多操作,1,-1,/-平移量,辅助寄存器内容的修改是在ARAU0和ARAU1中完成的。分为单操作数和双操作数,有很多模式在ARAU。单操作数间接寻址&#x…...

Java中的Apache Commons Math是什么?
Java中的Apache Commons Math是一个开源的数学库,它提供了许多常用的数学函数和算法,例如线性代数、微积分、统计、插值、拟合等。这个库对于需要处理大量数据的开发者来说非常有用,因为它可以大大简化代码并提高效率。 让我们从新手的角度来…...
规划路线(微信小程序、H5)
//地图getLocationDian(e1, e2) {console.log(e1, e2);let self this;self.xx1 [];self.xx2 [];self.points [];// self.markers[]console.log(self.markers, >marks);// self.$jsonp(url, data).then(re > {// var coors re.result.routes[0].polyline;// for (v…...

【CSS】视频文字特效
效果展示 index.html <!DOCTYPE html> <html><head><title> Document </title><link type"text/css" rel"styleSheet" href"index.css" /></head><body><div class"container"&g…...
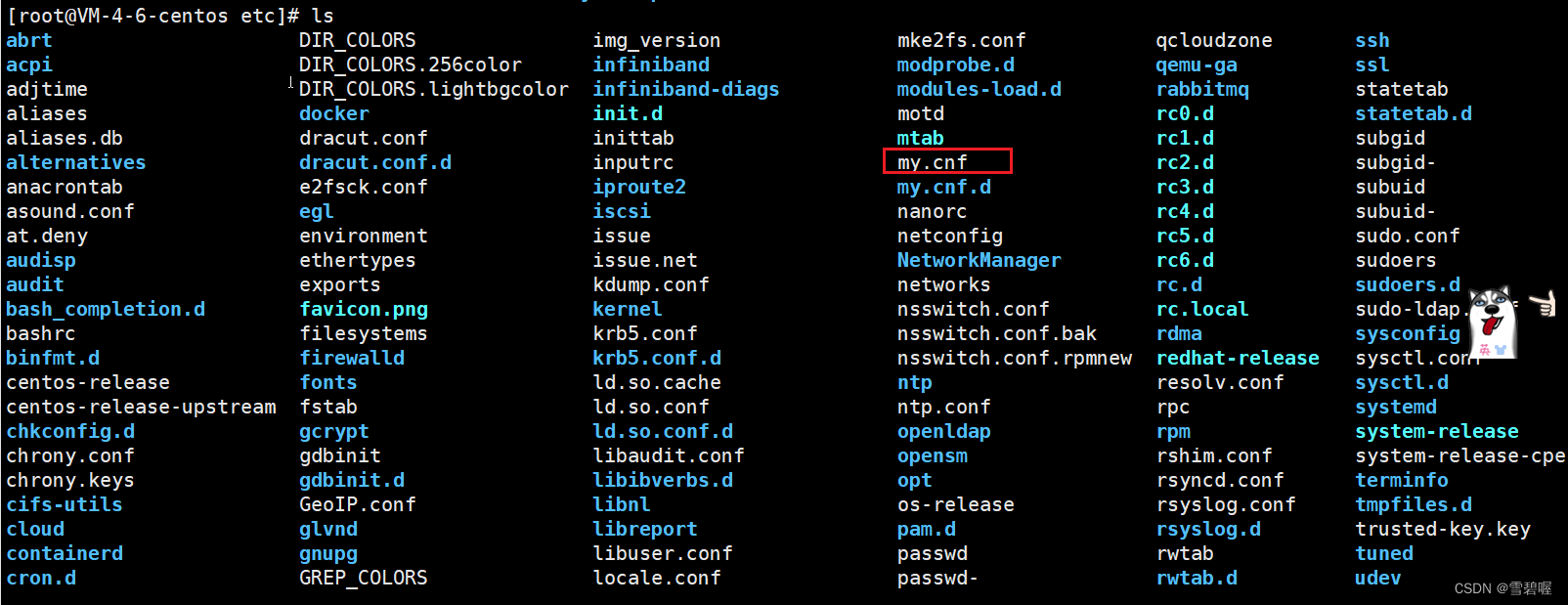
linux-MySQL的数据目录
总结: window中的my.ini linux 中 /etc/my.cnfwindow中的D:\soft\mysql-5.7.35-winx64\data linux 中 /var/lib/mysql 1.查找与mysql有关的目录 find / -name mysql [rootVM-4-6-centos etc]# find / -name mysql /opt/mysql /etc/selinux/targeted/tmp/modul…...

AI绘图实战(十二):让AI设计LOGO/图标/标识 | Stable Diffusion成为设计师生产力工具
S:AI能取代设计师么? I :至少在设计行业,目前AI扮演的主要角色还是超级工具,要顶替?除非甲方对设计效果无所畏惧~~ 预先学习: 安装及其问题解决参考:《Windows安装Stable Diffusion …...

机器视觉系统设计:基础知识
机器视觉系统的设计 机器视觉系统集成是将各种不同的组件和子系统组合在一起并使它们充当单个统一系统的过程。 视觉系统集成包括光源,镜头,相机,相机接口和图像处理软件等等。您可能想知道如何设计和实现一个完整,成功的机器视…...
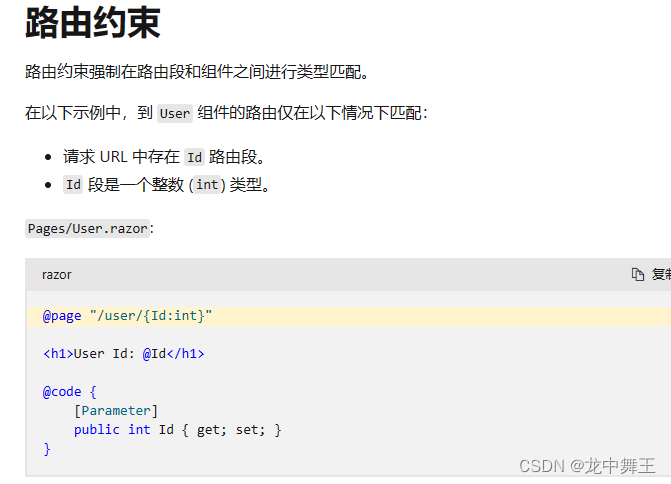
C# Blazor 学习笔记(11):路由跳转和信息传值
文章目录 前言路由跳转测试用例路由传参/路由约束想法更新:2023年8月4日 前言 Blazor对路由跳转进行了封装。 ASP.NET Core Blazor 路由和导航 NavigationManager 类 本文的主要内容就是全局的跳转 路由跳转 路由跳转就要用到NavigationManager 类。 其实最常用…...

Centos 7 安装 Python 时 zlib not available 错误解决
Centos 7 安装 Python 时 zlib not available 错误解决 报错信息, zipimport.ZipImportError: cant decompress data; zlib not available解决方法, sudo yum install -y zlib zlib-devel完结!...

python sqllite基本操作
以下是一些基本的SQLite3操作: 连接到数据库:使用sqlite3.connect()函数连接到数据库,返回一个Connection对象,我们就是通过这个对象与数据库进行交互。例如: import sqlite3 conn sqlite3.connect(example.db)创建…...

记录--基于css3写出的流光登录(注释超详细!)
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 完整效果 对基本的表单样式进行设置 这里设置了基本的表单样式,外层用了div进行包裹,重点是运用了两个i元素在后期通过css样式勾画出一条线没在聚焦文本框的时候线会过度成一个…...

【测试设计】性能测试工具选择:wrk?jmeter?locust?还是LR?
目录 前言 wrk 优点 缺点 jmeter 优点 缺点 locust 优点 缺点 总结 资料获取方法 前言 当你想做性能测试的时候,你会选择什么样的测试工具呢?是会选择wrk?jmeter?locust?还是loadrunner呢? 今…...

为什么升级JDK 11后堆外内存使用增长了?
文章首发地址 JDK 11堆外使用增长的原因 JDK 11堆外使用增长的原因可能有以下几个: G1垃圾回收器的默认设置更改: JDK 11中的G1垃圾回收器默认开启了堆外内存分配,以减少Full GC时的STW时间。因此,如果应用程序使用了G1垃圾回收…...
)
Vue自定义防重复点击指令(v-repeatClick)
!!!Vue防抖节流方法:VUE使用节流和防抖_vue防抖节流_停留的章小鱼的博客-CSDN博客 新建js文件directive.js: // directive.js // 防重复点击(指令实现) //使用: 在需要的按钮中加 v-repeatClick 指令即可 <el-but…...

高频高速板行业现状及市场前景
覆铜板全称为覆铜箔层压板,是由增强材料浸以树脂胶液 , 覆以铜箔 , 经热压而成的一种板状材料。覆铜板是制作印制电路板的核心材料,担负着印制电路板导电、绝缘、支撑三大功能。高频高速电路板有介电常数小且稳定、介质损耗小、传输损耗小等特点。 高频…...

【练手】自定义注解+AOP
在SpringBoot中实现自定义注解:( 声明注解的作用级别以及保留域 ) Target({ElementType.METHOD,ElementType.PARAMETER}) //注解的作用级别 Retention(RetentionPolicy.RUNTIME) //注解的保留域 public interface Log {int value() default 99; }在…...

windows环境oracle 11.2.0.1版本数据库启动报错ORA-01589问题的处理
1.问题分析 问题描述:windows环境oracle 11.2.0.1版本数据库异常关闭,之后无法启动,无备份、未打开归档。 故障分析: 1.直观查看数据库的数据文件、REDO文件均在,查看数据文件的最后修改时间,除SYSAUX02.DB…...

告别系统臃肿:3步打造轻量高效的Windows 11系统
告别系统臃肿:3步打造轻量高效的Windows 11系统 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and customiz…...

AI Agent设计实战:基于千问3.5-9B构建自主任务执行智能体
AI Agent设计实战:基于千问3.5-9B构建自主任务执行智能体 1. 智能体时代的业务自动化新范式 想象一下这样的场景:市场部门需要每周生成一份行业趋势分析报告。传统流程需要人工收集数据、整理信息、分析趋势、撰写报告,整个过程耗时费力。而…...

浏览器中的开发革命:Core72在线IDE版本控制实战指南
浏览器中的开发革命:Core72在线IDE版本控制实战指南 【免费下载链接】core Online IDE powered by Visual Studio Code ⚡️ 项目地址: https://gitcode.com/gh_mirrors/core72/core 当你在咖啡馆突然收到紧急修复需求,却发现没带开发笔记本时&am…...

接口测试——pytest框架续集劫
智能体时代的代码范式转移与 C# 的战略转型 传统的 C# 开发模式,即所谓的“工程导向型”开发,要求开发者创建一个复杂的项目结构,包括项目文件(.csproj)、解决方案文件(.sln)、属性设置以及依赖…...

PL/SQL:xml数据
在PL/SQL中,使用Oracle数据库提供的XML解析功能来处理XML数据。Oracle数据库提供了多种方式来处理XML数据,包括使用内置的XML数据类型、XMLTable函数、XML序列和XPath查询等。 1. 使用XMLTypeXMLType是Oracle提供的一个内置类型,用于存储和操…...

3个核心突破:科研工作者的文献获取难题终极解决方案
3个核心突破:科研工作者的文献获取难题终极解决方案 【免费下载链接】zotero-scipdf Download PDF from Sci-Hub automatically For Zotero7 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-scipdf 作为科研工作者,你是否经常遇到这些困扰&…...

澳大利亚太阳能气象与光伏数据集:15年运营数据的深度解析与应用
1. 澳大利亚太阳能数据宝藏:15年实战记录的价值解读 第一次接触澳大利亚DKASC和Yulara Solar System数据集时,我就像发现了一个装满金矿的宝箱。这套横跨15年的太阳能气象与光伏运营数据,记录着北领地沙漠地区39个太阳能电站每分钟的"呼…...

CLAP-htsat-fused部署指南:Docker资源限制与OOM Killer规避策略
CLAP-htsat-fused部署指南:Docker资源限制与OOM Killer规避策略 1. 项目概述 CLAP-htsat-fused是一个基于LAION CLAP模型的零样本音频分类Web服务。这个工具能够对任意音频文件进行语义分类,无需预先训练特定类别的模型。无论是狗叫声、猫叫声、鸟叫声…...

蛋白质组学新手必看:从基因组到蛋白质组的科研进阶指南
蛋白质组学新手必看:从基因组到蛋白质组的科研进阶指南 刚踏入生命科学领域的研究生们,常常会面临一个关键转折点——如何从熟悉的基因组学领域跨越到更具挑战性的蛋白质组学研究。记得我第一次接触蛋白质组学时,面对质谱数据和复杂的蛋白质互…...