kagNet:对常识推理的知识感知图网络 8.4+8.5
这里写目录标题
- 摘要
- 介绍
- 概述
- 问题陈述
- 推理流程
- 模式图基础
- 概念识别
- 模式图构造
- 概念网
- 通过寻找路径来匹配子图
- 基于KG嵌入的路径修剪
- 知识感知图网络
- 图卷积网络(GCN)
- 关系路径编码
- 分层注意机制
- 实验
- 数据集和使用步骤
- 比较方法
- KAGNET是实施细节
- 性能比较和分析
- Interpretibility案例研究
- 相关工作
- 总结

摘要
常识推理旨在使机器具备人类对日常生活中的普通情况做出假设的能力。
在本文中,我们提出了一个用于回答常识性问题的文本推理框架,该框架有效地利用 外部的、结构化的常识知识图谱来进行可解释的推理。
外部知识图谱是指与原始知识图谱不同的知识库,它们可能来自于不同的领域、不同的语言或者不同的数据源。常见的外部知识图谱包括维基百科、Freebase、YAGO等。这些外部知识图谱可以通过API、SPARQL查询等方式访问和获取,从中提取相关信息用于知识库的构建和扩展。
该框架首先将语义空间中的问题-答案对转换为基于知识库的符号空间,得到一个基于知识库的表示,即一个schema graph(模式图),即 外部知识图谱的相关子图 。它用一个名为 KAGNET 的新型感知知识图谱网络模块来表示图谱,并最终用 图表示法 来给答案打分。
外部知识图谱的相关子图通常指的是从外部知识图谱中提取的、与原始知识图谱相关的一部分子图。
KAGNET是一种基于知识图谱的自然语言推理模型。KAGNET的全称是Knowledge-Aware Global Neighborhood Interaction Network,它结合了知识图谱中的全局信息和局部信息,通过邻域交互的方式进行自然语言推理。
KAGNET的模型结构包括三个主要部分:
1.实体和关系的嵌入表示:通过对知识图谱中的实体和关系进行嵌入表示,可以将知识图谱中的符号信息转化为连续向量空间中的表示,从而方便深度学习模型的处理。
2.邻域交互模块:该模块通过邻域交互的方式,将知识图谱中的全局信息和局部信息结合起来,得到更加丰富的表示,以便进行自然语言推理。
3.推理和预测模块:该模块通过对邻域交互后的表示进行处理,得到自然语言推理的结果,通常是一个二分类问题,即判断给定的两个句子是否具有逻辑关系。
KAGNET的主要优点是结合了知识图谱的全局信息和局部信息,能够有效地处理自然语言推理的问题。同时,KAGNET还可以通过迁移学习的方式进行跨领域的模型迁移,具有较强的通用性和可扩展性。
使用图表示法,我们可以将问题和答案都表示为图中的节点和边,从而可以在图上进行计算和推理,得到问题和答案之间的相似度或匹配程度,进而对答案进行打分。这种方法通常需要使用图神经网络等深度学习模型,以便对图进行表示和计算。
我们的模型基于图卷积网络和LSTMs,具有 基于层次路径的注意力机制 。中间注意力得分使其透明且可解释,从而产生值得信赖的参考。使用ConceptNet作为基于BERT的模型的唯一外部资源,我们在CommonsensegA(一个用于Commonsense推理的大型数据集)上实现了最先进的性能。
注意力机制(Attention Mechanism)是一种机器学习算法,它模拟了人类注意力的行为,用于选择输入数据中最相关的部分并在模型中进行加权处理。
注意力机制的基本思想是对输入数据的不同部分赋予不同的权重,以便在模型中对其进行加权处理。这些权重可以通过计算每个输入部分与模型中某个特定部分之间的相似度来得到。然后,根据这些相似度的权重来计算每个输入部分的重要性,并将其加权求和,得到模型的最终输出结果。
基于路径层次的注意力机制(Path-based Hierarchical Attention Mechanism)是一种在知识图谱中应用注意力机制的方法。该方法通过将知识图谱中的实体和关系表示为一组路径,然后通过注意力机制对这些路径进行加权处理,以便提高知识图谱的表示能力和推理效果。
介绍
推理是将事实和信念结合起来做出新决定的过程,以及操纵知识以得出差异的能力。常识推理利用了基本知识(反映我们对世界和人类行为的自然理解的基本知识),这是所有人类都有的。
赋予机器各种形式的常识推理能力被视为人工通用智能的瓶颈。最近有一些新兴的大规模数据集,用于测试 不同关注点 的机器常识。
“不同的关注点”,在机器常识中指的是机器学习模型具有对多个方面的关注能力,而不仅仅关注某一个方面。例如,在自然语言处理中,机器学习模型需要同时关注词汇、语法、语境等多个方面,才能够更好地理解文本的含义和语义。而在计算机视觉中,机器学习模型需要同时关注图像的颜色、纹理、形状、物体等多个方面,才能够更好地识别图像中的内容和信息。
一个典型的数据集——CommonsenseQA,给出一个问题比如:哪里的成年人使用胶水棒?答案从{classroom(×),office(√),desk drawer(×)},一个常识性的推理器应该把正确的选择与其他干扰选项分开。错误的选择通常与问题上下文高度相关。但在现实世界中,这种可能性很小,这使得任务更加困难。本文旨在解决我们如何教机器做出这种常识性推断的研究问题,特别是在问答环境中。
研究表明,简单地微调大型预训练语言模型如GPT和BERT可以是一种非常强大的基准方法。然而,上述基准的表现与人类表现之间仍然存在很大差距。神经模型的再处理也缺乏透明度和可解释性。对于他们如何设法回答常识性的问题,没有明确的方法,因此他们的推论令人怀疑。
仅仅依靠在语料库上预先训练大型语言模型并不能为可解释的常识推理提供定义明确或可用的结构。我们认为,提出能够利用常识知识库的推理器会更好。知识感知模型可以明确地将外部知识作为关系归纳偏差,以增强其推理能力,并提高模型行为的透明度,从而获得更可解释的结果。此外,以知识为中心的方法可以通过常识性的知识获取技术来扩展。
我们提出了一种用于学习回答常识性问题的知识感知推理框架,该框架包括两个主要步骤:
- 模式图基础
- 推理图建模
对于每对问答候选者,我们从外部知识图中重新检索一个图,以获取相关知识来确定给定答案选择的可行性。受Gestalt心理学家提出的图式理论的启发,这些图表现为“图式图”。基于语境的模式图 通常更复杂、更嘈杂,而不是图中所示的理想情况。
Grounded schema graph“基于语境的模式图”,也可以简称为“GSG”。
它是一种将自然语言和视觉信息结合起来表示知识的图形结构,其中节点表示实体或概念,边表示它们之间的关系。与传统的本体论等知识表示方法不同,GSG中的实体和关系是从自然语言文本和视觉信息中提取出来的,因此不需要手动定义或构建本体。GSG的优点是可以更好地理解自然语言文本和视觉信息之间的关系,从而提高自然语言处理和计算机视觉任务的性能。
因此,我们提出了一个 知识感知图网络模块(Knowledge-aware graph network(KGN) module) 来进一步有效地建模模式图。我们的模型KAGNET是图卷积网络和LSTM的组合,具有基于层次路径的注意力机制。(它形成了一个基于路径的关系图表示的GCN-LSTM-HP架构。实验表明,我们的框架通过中等注意力分数实现了一种新的艺术性能从而获得可读结果。
Knowledge-aware graph network(KGN) module知识感知图网络模块
是一种深度学习模型中的组件,它将知识图谱(例如维基百科或Freebase)中的知识与图神经网络(GNN)相结合,用于解决自然语言处理(NLP)任务。该模块使用知识图谱中的实体和关系来构建一个图形结构,然后使用GNN对该结构进行表示学习。KGN模块的目的是通过整合知识图谱中的信息来提高NLP任务的性能。
在KGN模块中,知识图谱中的实体被视为节点,实体之间的关系被视为边。这些节点和边被输入到GNN中进行表示学习,以便更好地理解文本中提到的实体和它们之间的关系。KGN模块的输出可以被用于各种NLP任务,例如实体识别、关系提取、问答系统等。
概述
首先形式化常识问答问题(在认知环境中),然后介绍了框架总体工作流程
问题陈述
给定一个常识性要求的自然语言问题 q q q和一组 N N N个候选答案{ a i a_i ai},任务是从这组答案中选择一个答案。从 知识意识的角度 来看,我们还假设问题 q q q和候选{ a i a_i ai}可以作为从大型外部知识图谱 G G G中提取的模式图,这有助于测量候选答案的可能性。知识图谱G=(V , E)可以被定义为一个固定的概念V的集合,不同类型边E描述为概念之间的语义关系。因此我们的目标是有效地联系和构建模式图以完善推理过程。
知识意识角度
指从人工智能和计算机科学领域的知识表示和知识处理角度来探讨人类知识和认知的角度。它强调了知识在人类认知和智能中的重要性,并试图通过将人类知识和认知模型与计算机科学中的知识表示和处理技术相结合,来更好地理解人类知识和认知的本质。
从知识意识角度来看,人类知识可以被视为一种结构化的、层次化的组织形式,其中知识被组织成概念、实体和关系的形式。计算机科学中的知识表示和处理技术(如本体论、知识图谱、语义网络等)可以用来表示和处理这种结构化的知识。从而,通过将这些技术应用于人类知识和认知研究中,可以更好地理解人类知识和认知的本质,并开发出更先进和智能的人工智能系统。
推理流程
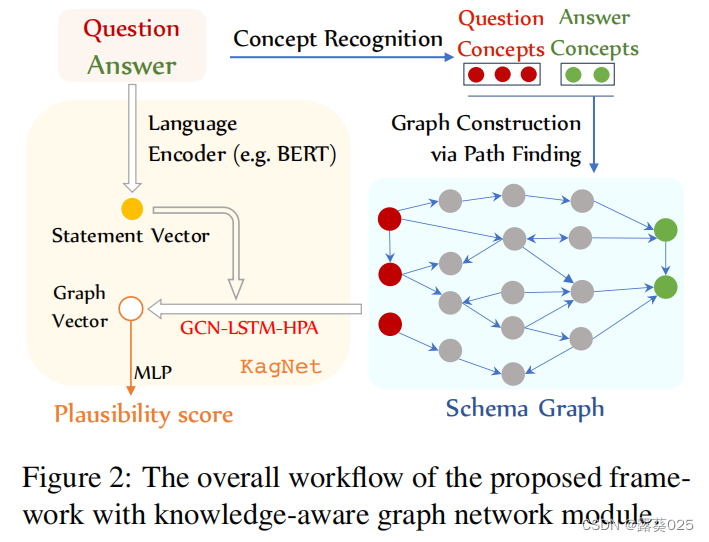
如图,框架接受了一个问题(q)答案(a)对,首先从知识图谱的概念集V中分别识别出其中提到的概念。然后通过在所提到的概念对之间寻找路径来用算法构建模式图 g g g。
利用我们提出的知识感知图网络模块对基础模式图进行了进一步编码。我们首先使用模型不可知的语言编码器,它可以是可训练的或固定的特征提取器,来表示QA对作为语句向量。语句向量是GCN-ISTM-HPA架构的额外输入,用于 基于路径的注意图 建模以获得图向量。将图向量最终输入到一个简单的多层感知器中,将QA对转换为0到1的标量,表示推理的合理性。该框架的最终选择对同一问题具有最大可信度得分的候选答案。
在基于路径的注意图模型中,文本数据被表示为一个图形结构,其中每个单词被看作是一个节点,而它们之间的依赖关系则表示为边。这个图形结构可以被看作是一张无向图,其中每个节点与它的相邻节点之间的路径表示了它们之间的语义关系。模型通过基于路径的注意力机制,来关注这些路径上的信息,并将它们聚合起来,用于下游任务的处理。
模式图基础
基础阶段有三个方面:
- 识别文本中提到的概念
- 通过检索已知边图中的路径构建模式图
- 修剪噪声路径
概念识别
我们将问题和答案中的记号与知识图谱G中提到的概念集(分别为Cq和Ca)进行匹配(由于本文的通用性,我们选择使用ConceptNet)。
概念识别的一个简单方法是将句子中的 n-grams 与V中概念的表面记号精确匹配。例如,在“坐得太近看点式会引起什么样的疼痛”的问题中,精确地匹配结果Cq可以为{sitting,close,watch_TV, watch,TV,sort,pain,等}。我们意识到,这些检索到的概念并不总是完美的(例如,“sort”不是一个语义相关的概念,“close”是一个多义概念)。如何从嘈杂的知识资源中有效地检索上下文相关的知识本身仍然是一个开放的研究问题,因此大多数工作到此为止。我们增强了这种使用一些规则的直接方法,如将匹配与词库化和词库过滤相关联,并通过 修剪路径(pruning path) 进一步处理噪声,并通过保持机制降低其重要性。
n-grams是一种文本分析方法,用于将文本拆分为连续的n个单词或字符的序列。在n-grams中,n表示序列中的元素个数。例如,如果n为2,则称为bigrams;如果n为3,则称为trigrams。
例如,考虑以下句子:“I love to code”。对于n为2的情况,可以生成以下bigrams:
“I love”
“love to”
“to code”
“Pruning path”(修剪路径)是指在神经网络中进行修剪操作时所涉及的路径或过程。神经网络修剪是一种减少模型参数数量的技术,旨在提高模型的效率和推理速度,同时减少存储需求。
修剪路径通常包括以下步骤:
1.训练初始的神经网络模型,通常是使用常规的训练方法和数据集。
2.基于某种准则或策略,确定哪些神经元、连接或层应该被修剪。
3.定义修剪路径,即确定要修剪的神经元、连接或层的位置。
4.在模型中执行修剪操作,将被选中的部分神经元、连接或层删除或禁用。
5.对修剪后的模型进行微调或重新训练,以恢复修剪导致的性能损失。
模式图构造
概念网
在深入研究模式图的构造之前,我们想简单介绍一下我们的目标知识图谱概念网。概念网可以被视为一大组形式为(h,r,t)的三元组,其中h和t表示在概念集合V中头部和尾部的概念,r是预定于关系集R中的某一关系类型。我们将原来42个关系类型删除并合并为17个类型,以增加知识图谱的密度,用于基础和建模。
通过寻找路径来匹配子图
我们定义了一个模式图作为整体知识图谱 G G G的子图 g g g,它表示用 Minimal additional concepts and edges(最小附加概念和边缘) 推理给定问答对的相关知识。人们可能想找到一个覆盖所有问题和概念的最小跨度的子图,这实际上是图中的NP-complete的“施泰纳树问题”。由于概念网的不完整性和有限的规模,我们发现以这种方式检索一组全面但有用的知识事实是不切实际的。因此,我们提出了一种简单而有效的图形构建算法,通过对上述概念的路径查找(Cq U Ca)。
“Minimal additional concepts and edges”(最小附加概念和边缘)
是指在概念网络或知识图谱中,为了满足特定任务或目标而添加的最小数量的概念和关系边。
在概念网络或知识图谱的构建中,通常会根据特定的目标或任务收集和整理常识知识。然而,有时候为了完善图谱的覆盖范围或支持特定的推理或应用,需要添加一些额外的概念和边。
“Minimal additional concepts and edges” 的概念是指在这种情况下,只添加最小的、最必要的概念和边,以避免引入过多的复杂性和冗余。
具体来说,对于每个问题概念ci ∈ Cq和答案概念cj ∈ Ca,我们可以有效地找到它们之间比k个概念更短的路径。然后我们在Cq或Ca中的概念对之间添加边(如果有的话)。
基于KG嵌入的路径修剪
为了从潜在噪声模式图中修剪不相关的路径,我们首先利用知识图谱嵌入(KGE)技术(比如TransE)来预训练概念嵌入V和关系类型嵌入R,它们也被用作KAGNET的初始化。为了测量路径的质量,我们将它分解成一组三元组,其置信度可以通过KGE方法的评分函数直接测量(即三元组分类的置信度)。因此,我们用路径中的每个三元组的分数的乘积为路径打分,然后根据经验设置修剪阈值。
知识感知图网络
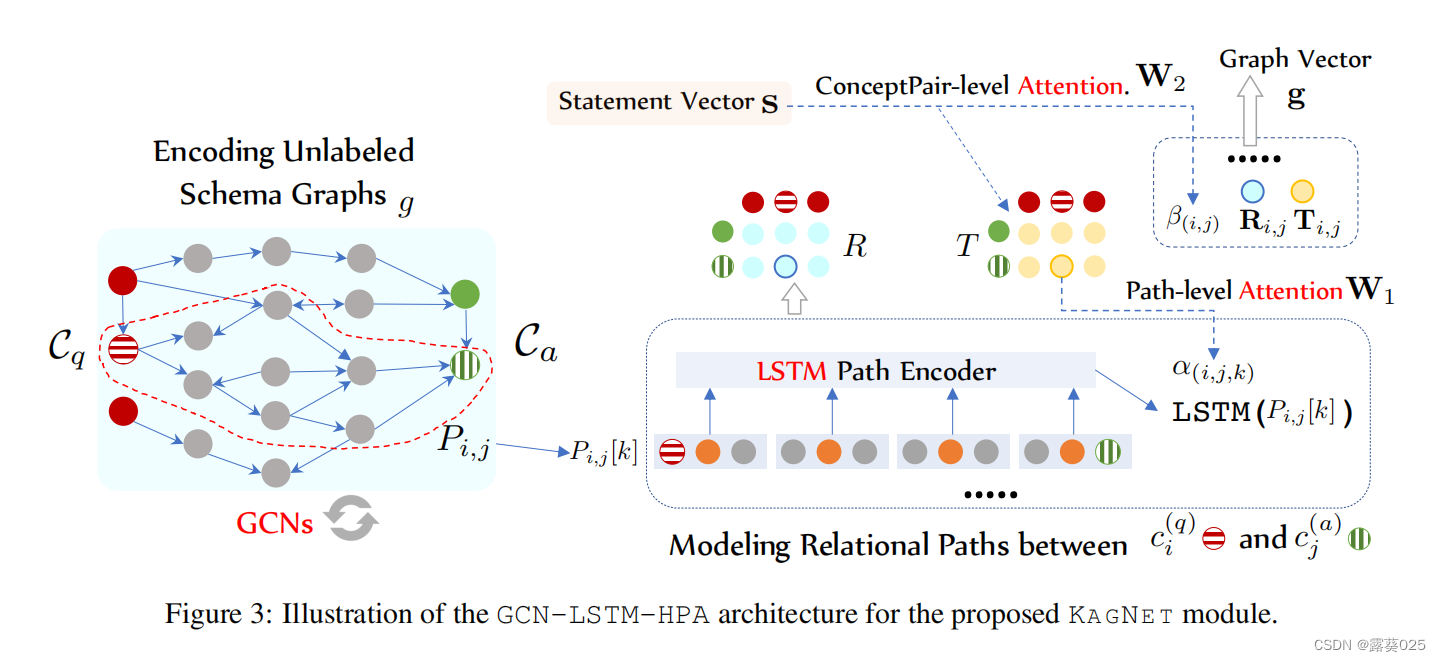
我们推理框架的核心组件是知识感知网络模块KAGNET。KAGNET首先用图卷积网络编码模式图的普通结构,以在模式图中的特定上下文中适应预训练的嵌入概念。然后利用LSTMs来编码Cq和Ca之间的路径。最后应用一种基于层次路径的注意力机制来完成GCN-LSTM-HPA架构,该架构针对问题和答案概念之间的路径关系模式图进行建模。
图卷积网络(GCN)
图卷积网络通过池化其相邻节点的特征来更新节点向量,从而对结构化数据进行编码。我们将GCNs用于模式图是为了:
- 在上下文中细化概念向量
- 捕获模式图的结构模式进行泛化
尽管我们已经通过重新训练获得了概念向量,但概念的表示仍然需要进一步适应其特定的模式图上下文。想想诸如“close”之类的多义概念,它可以是像“关门”这样的动词概念,也可以是意思为“相距很短”的宾语概念。使用GCN来更新与它们邻居的概念向量有助于消除歧义和上下文化的概念嵌入。此外,这种模式图结构模式为推理提供了潜在有价值的信息。例如,问题和答案概念之间的更短、更紧密的联系可能意味着在特定环境下更高的可能性。
就像许多工作展示的那样,关系GCNs常常通过过度参数化模型,无法有效利用多跳关系信息。我们在模式图的纯文本版本(无标签,非定向)上使用GCN,忽略边缘上的关系类型。具体而言,模式图 g g g中的概念向量ci∈ V g V_g Vg首先通过其预训练嵌入 。然后在第 l + 1 l+1 l+1层通过它们邻居节点( N i N_i Ni)的池化特征来更新它们,且它们在第 l l l层的一个非线性激活函数为 σ σ σ:
。然后在第 l + 1 l+1 l+1层通过它们邻居节点( N i N_i Ni)的池化特征来更新它们,且它们在第 l l l层的一个非线性激活函数为 σ σ σ:
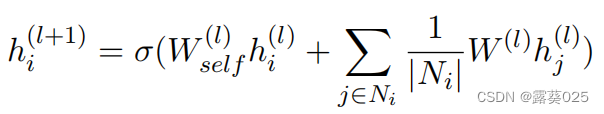
关系路径编码
为了在模式图中捕获关系信息,我们在GCN的输出之上提出了一种基于LSTM的路径编码器。
回想一下,我们的图表示有一个特殊的目的:“测量给定问题的候选答案的合理性”。因此,我们提出用关于问题概念Cq和答案概念Ca之间的路径来表示图。
在第i个问题概念ci(q)∈Cq和第j个答案概念cj(a)∈Ca之间将第k个路径表示为 P i , j [ k ] P_i,_j[k] Pi,j[k],它是一个三元组序列:
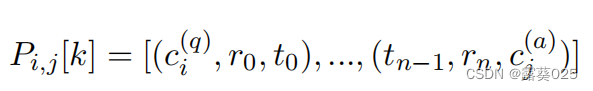
注意,关系用可训练的关系向量表示(用预先训练的关系嵌入初始化),概念向量是GCN的输出( h l h^l hl)。因此每个三元组都可以由三个对应的矢量串联表示。使用LSTM网络来编码将这些路径编码为三元组向量序列,采用第一个和最后一个隐藏状态的 串联:
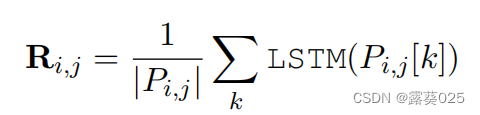
Ri,j可以视作在问题概念ci(q)和答案概念cj(a)之间的潜在的关系,我们在模式图中聚合它们之间所有路径的表示。
指的是将两个向量按照一定的顺序连接起来形成一个更长的向量的操作。
例如,假设有两个向量 A = [1, 2, 3] 和 B = [4, 5, 6]。通过连接操作,我们可以得到一个新的向量 C,表示为 C = [1, 2, 3, 4, 5, 6]。在这个例子中,向量 C 是将向量 A 和向量 B 按照顺序连接起来形成的。
现在,我们可以通过使用平均池化(Mean pooling)聚合矩阵R中聚合所有向量来最终确定模式图 g g g的向量表示:
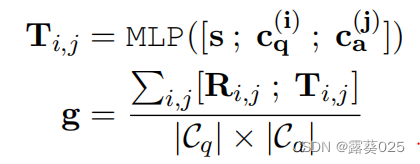
,其中[ ; ]意思是两个向量的串联。上式中的语句向量s是从某个语言编码器获得的,该编码器可以是像LSTM这样的可训练序列编码器,也可以是从像GPT/BERT这样的预训练通用语言编码器中提取的特征。为了用通用语言编码器对问题和答案进行编码,我们只需创建一个句子,将问题和答案与特定标记(“question+[sep]+answer”)组合在一起,然后通过先前的工作,使用“[cls]”的向量作为建议。
在进行平均池化之前,我们将Ri,j与一个额外的向量Ti,j连接起来。
Ti,j它源于关系网络,该网络还将来自上下文的潜在的关系信息编码为状态图s。简单地说,我们想将问题/答案概念对的关系表示从模式图侧(符号空间)和语言侧(语义空间)结合起来。最后,问题q的候选答案a的真实性得分可以通过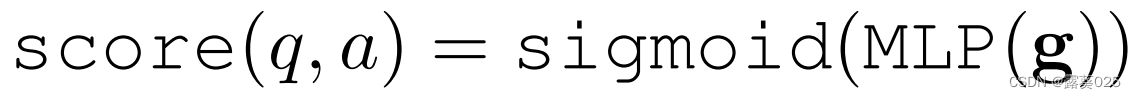
计算。
分层注意机制
反对上述GCN-ISTM-mean体系结构的一个自然论点是,路径向量上的均值池并不总是有意义的,因为有些路径对推理来说比其他路径更重要。此外,通常并不是所有成对的问题和答案概念同样有助于推理。因此,我们提出了一种基于层次路径的注意力机制,以选择性地聚合重要的路径向量,然后聚合更重要的问答概念对。
这一核心思想与一种文档编码器类似,该编码器具有两个级别的注意力机制,分别应用于单词和话语级别。在我们的例子中,我们有路径级和概念对级的注意力来学习对图表示进行上下文建模。我们获得路径级别注意力得分的参数矩阵Wi,以及路径的重要性Pi,j[k]表示为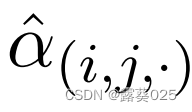 。
。

然后,我们类似地获得了概念对之上的注意力的概念
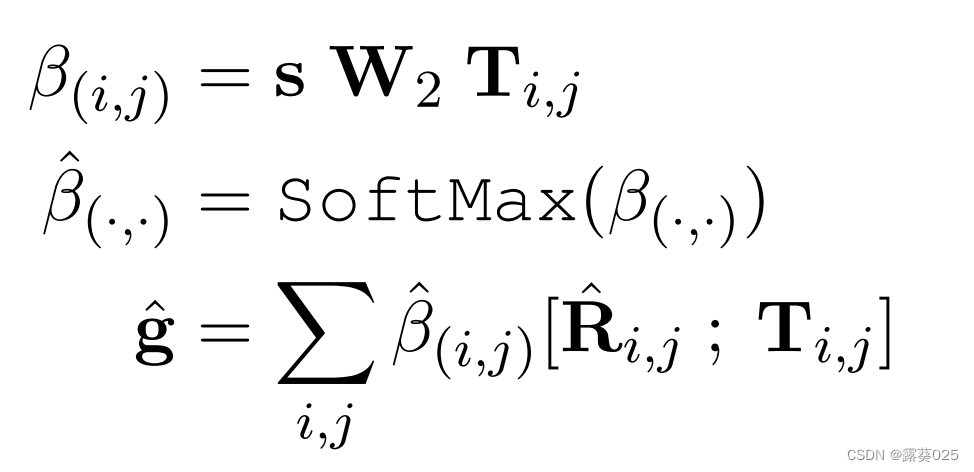 认为整个GCN-ISTM-HPA体系结构如图所示。总之,我们声称KAGNET是一个具有GCN-LSTM-HPA架构的图神经网络模块,它在知识符号空间和语言语义空间的背景下为关系推理建模关系图。
认为整个GCN-ISTM-HPA体系结构如图所示。总之,我们声称KAGNET是一个具有GCN-LSTM-HPA架构的图神经网络模块,它在知识符号空间和语言语义空间的背景下为关系推理建模关系图。
实验
数据集和使用步骤
比较方法
KAGNET是实施细节
性能比较和分析
Interpretibility案例研究
相关工作
总结
相关文章:
kagNet:对常识推理的知识感知图网络 8.4+8.5
这里写目录标题 摘要介绍概述问题陈述推理流程 模式图基础概念识别模式图构造概念网通过寻找路径来匹配子图基于KG嵌入的路径修剪 知识感知图网络图卷积网络(GCN)关系路径编码分层注意机制 实验数据集和使用步骤比较方法KAGNET是实施细节性能比较和分析I…...
Jmeter 压测工具使用手册[详细]
1. jemter 简介 jmeter 是 apache 公司基于 java 开发的一款开源压力测试工具,体积小,功能全,使用方便,是一个比较轻量级的测试工具,使用起来非常简 单。因为 jmeter 是 java 开发的,所以运行的时候必须先…...
matlab智能算法程序包89套最新高清录制!matlab专题系列!
关于我为什么要做代码分享这件事? 助力科研旅程! 面对茫茫多的文献,想复现却不知从何做起,我们通过打包成品代码,将过程完善,让您可以拿到一手的复现过程以及资料,从而在此基础上,照…...

caj文件怎么转换成pdf?了解一下这种方法
caj文件怎么转换成pdf?如果你曾经遇到过需要将CAJ文件转换成PDF格式的情况,那么你一定知道这是一件麻烦的事情。幸运的是,现在有许多软件和工具可以帮助你完成这项任务。下面就给大家介绍一款使用工具。 【迅捷PDF转换器】是一款功能强大的工…...
windows 同时安装 Mysql 5.7 和8.0
下载链接 https://dev.mysql.com/downloads/mysql/ 推荐下载 MSI,可以通过图像化界面配置 8.1 版本 安装5.7 系统安装两个MySQL 怎么访问 都是mysql,所以环境变量 配置,只能一个生效,生效就是谁靠前谁生效 cmd 录入 services.m…...

数字孪生的「三张皮」问题:数据隐私、安全与伦理挑战
引言 随着数字化时代的来临,数据成为了当今社会的宝贵资源。然而,数据的广泛使用也带来了一系列隐私、安全与伦理挑战。数字孪生作为一种虚拟的数字化实体,通过收集和分析大量数据,模拟和预测现实世界中的各种情境,为…...

Hadoop学习:深入解析MapReduce的大数据魔力(上)
Hadoop学习:深入解析MapReduce的大数据魔力(上) 前言1.MapReduce概述1.1MapReduce 定义1.2MapReduce 优缺点优点缺点 1.3MapReduce 核心思想1.4 MapReduce 进程1.5 官方WordCount源码1.6 常用数据序列化类型1.7 MapReduce 编程规范1.8 WordCo…...
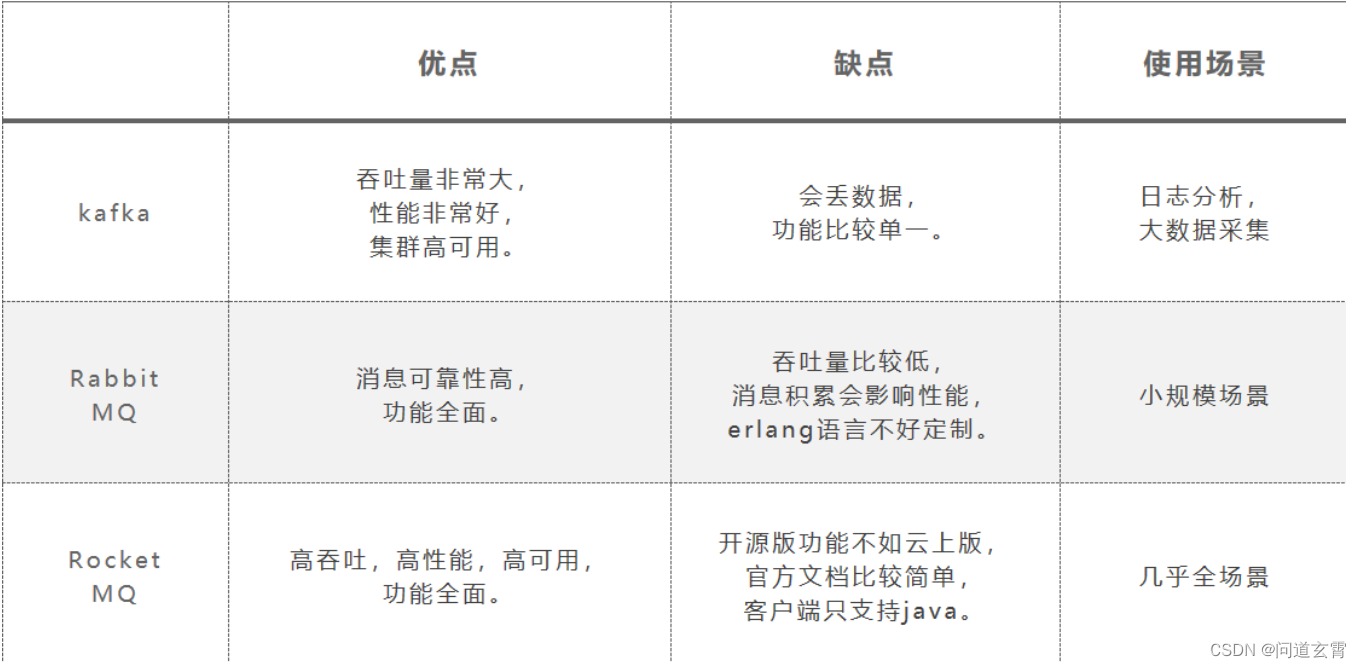
MQ(一)-MQ理论与消息中间件简介
MQ理论 队列,是一种FIFO 先进先出的数据结构。消息:在不同应用程序之间传递的数据。将消息以队列的形式存储起来,并且在不同的应用程序之间进行传递,这就成了MessageQueue。MQ通常三大作用: 异步、解耦、限流 Spring…...

vb与EXCEL的连接
一、 VB读写EXCEL表: VB本身提自动化功能可以读写EXCEL表,其方法如下: 1、在工程中引用Microsoft Excel类型库: 从"工程"菜单中选择"引用"栏;选择Microsoft Excel 9.0 Object Libraryÿ…...
java使用openOffice将excel转换pdf时,将所有列显示在一页
1.接上文,格式转换的基础问题已解决,但还有些细节问题需要单独处理,如excel转换至pdf时,如何将所有列显示在一页的问题,此问题大家都有遇到,解决方案也比较多,我也尝试过重写某类,来…...
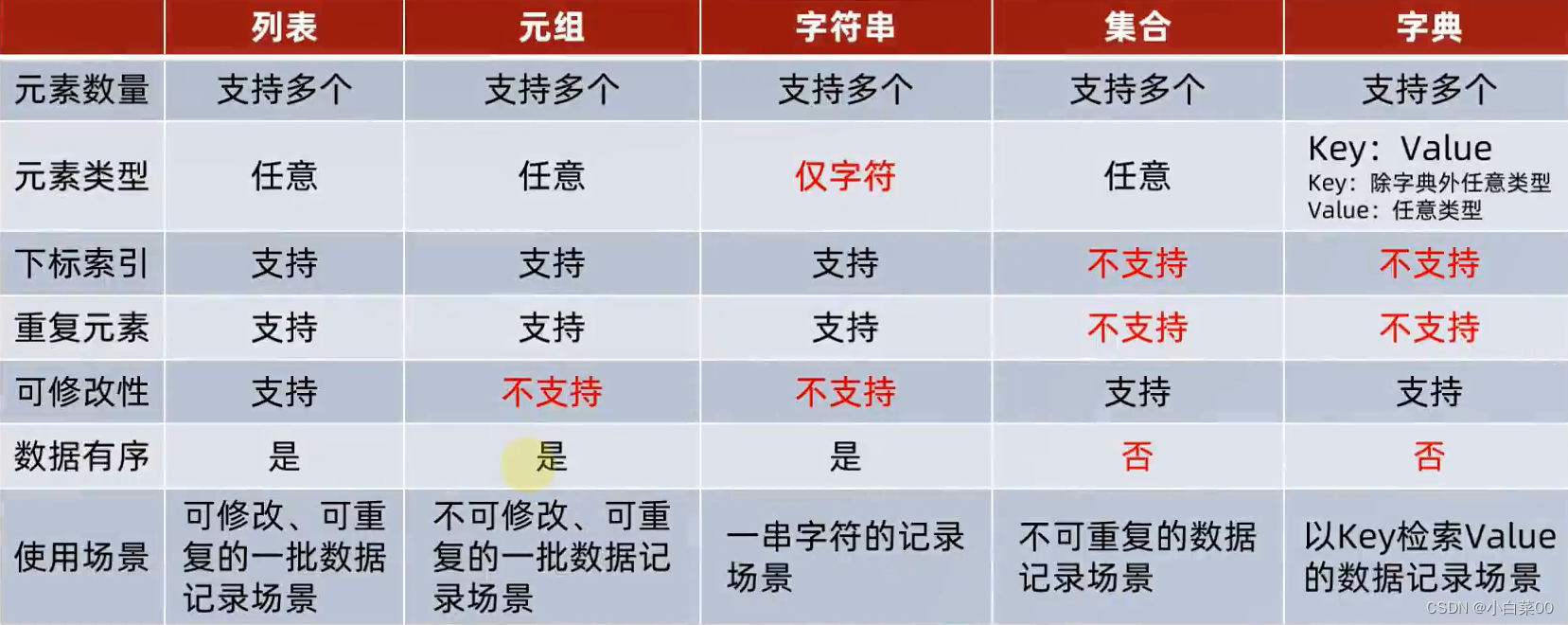
python数据容器
目录 数据容器 反向索引 list列表 语法 案例 列表的特点 列表的下表索引 list的常用操作 list列表的遍历 while循环遍历 for循环遍历 tuple元组 前言 元组定义 元组特点 获取元组元素 元组的相关操作 元组的遍历 while循环遍历 for循环遍历 字符串 前言…...

【TypeScript】中定义与使用 Class 类的解读理解
目录 类的概念类的继承 :类的存取器:类的静态方法与静态属性:类的修饰符:参数属性:抽象类:类的类型: 总结: 类的概念 类是用于创建对象的模板。他们用代码封装数据以处理该数据。JavaScript 中的…...
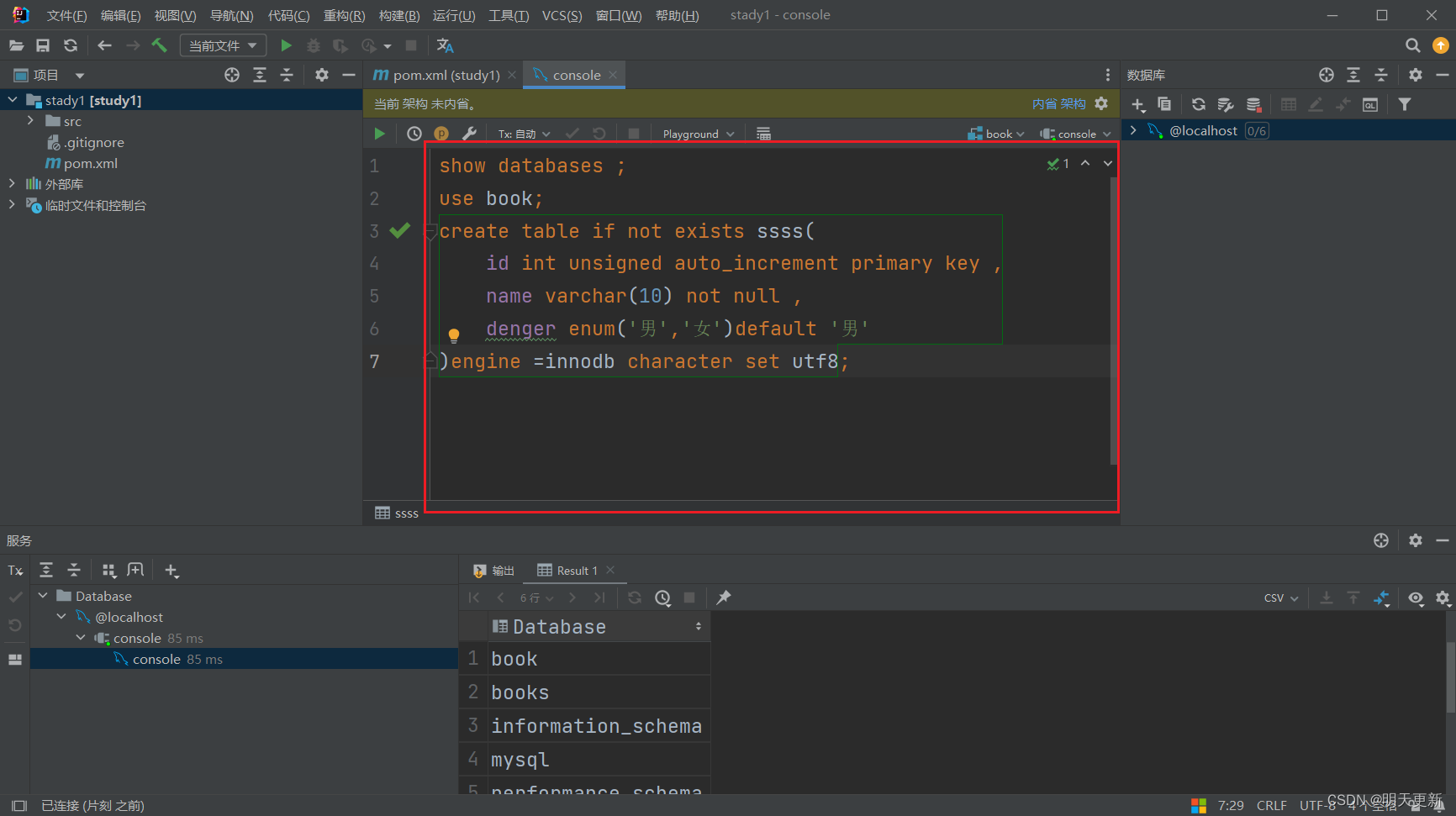
好用的数据库管理软件之idea(idea也有数据库???)
1.建立maven项目(maven项目添加依赖,对于后期连接数据库很方便) 2.连接数据库。。。 这里一定注意端口号,不要搞错了 和上一张图片不一样哦 3.数据库测试代码。。。 然后你就可以在这里边写MySQL代码了,这个工具对于新…...

《操作系统-李治军》测验错题集
章节测试1 启动保护模式以后,指令jmpi 0, 8执行和没有启动保护模式有何区别?() 答:得出跳转地址的方式不同 实模式:cs<<4 ip 保护模式:cs查表 ip 在系统调用的实现中,在i…...

DP-GAN-判别器代码
将输出的rgb作为输入,输入到判别器中。接着执行一个for循环,看一下body_down列表的组成和x经过body_down之后的值。 body_down是由残差块D组成的列表: 残差块的参数为:(3,128),(128,128),(128,256),(256,256),(256,512),(512,5…...
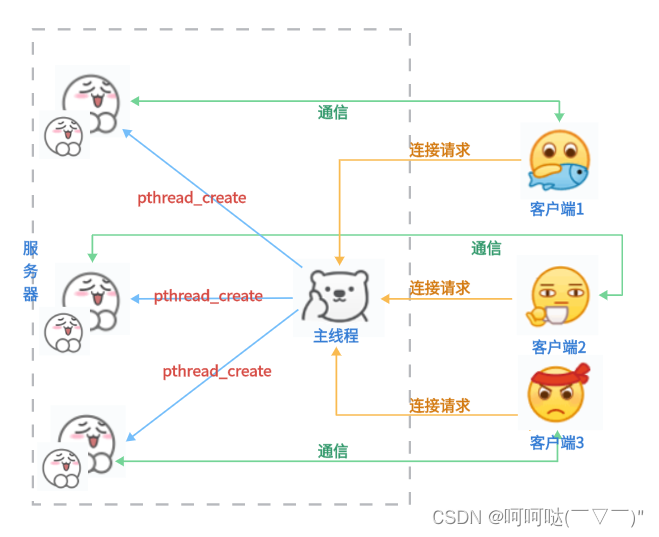
基于多线程实现服务器并发
看大丙老师的B站视频总结的笔记19-基于多线程实现服务器并发分析_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1F64y1U7A2/?p19&spm_id_frompageDriver&vd_sourcea934d7fc6f47698a29dac90a922ba5a3 思路:首先accept是有一个线程的,另外…...

Golang之路---03 面向对象——接口与多态
接口与多态 何为接口 在面向对象的领域里,接口一般这样定义:接口定义一个对象的行为。接口只指定了对象应该做什么,至于如何实现这个行为(即实现细节),则由对象本身去确定。 在 Go 语言中,…...

一条自由游动的鲸鱼
先看效果: 再看代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>鲸鱼</title><style>#canvas-container {width: 100%;height: 100vh;overflow: hidden;}&l…...

将python源代码打包成.exe可执行文件
步骤 1、安装pyinstaller2、打开终端或命令提示符窗口并进入解释器的虚拟环境3、从解释器的虚拟环境进入包含要打包Python文件的目录4、通过以下命令打包5、打包后文件存放位置 1、安装pyinstaller pip install pyinstaller2、打开终端或命令提示符窗口并进入解释器的虚拟环境…...
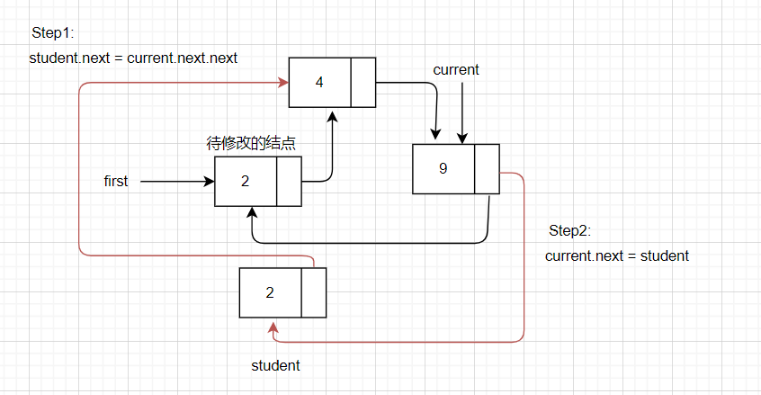
【数据结构篇】手写双向链表、单向链表(超详细)
文章目录 链表1、基本介绍2、单向链表2.1 带头节点的单向链表测试类:链表实现类: 2.2 不带头节点的单向链表2.3 练习测试类:链表实现类: 3、双向链表测试类:双向链表实现类: 4、单向环形链表**测试类**&…...

PentAGI:面向红队实战的开源渗透测试Agent系统
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正进红队实战的渗透测试Agent系统你有没有遇到过这样的场景:在一次内部红队演练中,刚摸到一台边缘业务服务器,想快速判断它是否暴露了Jenkins未授权访问、Confluence远程代码执行…...

抖音批量下载神器:开源工具完整使用指南
抖音批量下载神器:开源工具完整使用指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下…...
:基于127万条真实英文语境的搭配强度阈值模型首次公开)
Perplexity词组搭配查询深度解析(工业级语料验证版):基于127万条真实英文语境的搭配强度阈值模型首次公开
更多请点击: https://codechina.net 第一章:Perplexity词组搭配查询深度解析(工业级语料验证版):基于127万条真实英文语境的搭配强度阈值模型首次公开 Perplexity 不仅是语言模型评估的核心指标,更可转化为…...

魔百盒CM311-1s刷机后体验:安卓9.0固件到底香不香?附5621DS无线实测
魔百盒CM311-1s刷机实战:安卓9.0系统深度评测与无线性能揭秘 当手中的魔百盒CM311-1s遇上安卓9.0系统,这场硬件与软件的碰撞会擦出怎样的火花?作为一款搭载S905L3B芯片的电视盒子,其原生系统往往受限于运营商定制化限制࿰…...

Hyperf 高并发的庖丁解牛
它的本质是:**Hyperf 的高并发并非来自 PHP 语言本身的计算速度,而是来自对 I/O 等待时间 (I/O Wait Time) 的极致利用。它通过 Swoole/Swow 扩展 将传统的 同步阻塞 (Sync-Blocking) 模式转变为 异步非阻塞 (Async-Non-blocking) 模式,并利用…...

地平线6正式上线!UU远程云电脑工作日也能全高画质飙车
《极限竞速:地平线6》5月18日正式全球发售!该作将舞台设在超燃的日本东京,从东京涩谷的霓虹璀璨,到秋名山的晨雾缭绕与漂移快感;从北海道的茫茫雪原越野,到富士山下的樱花赛道浪漫驰骋,每一处场景都细节拉满…...

SAP MIRO发票校验时,如何用增强LMR1M001自动检查供应商号?
SAP MIRO发票校验中供应商号自动检查的增强实战指南 在SAP系统中,发票校验(MIRO)是财务流程中的关键环节,而供应商号的准确性直接关系到后续的付款和账务处理。想象一下这样的场景:采购部门创建了一个采购订单,但财务人员在录入发…...

从零搭建OpenStack私有云:我是如何用两台旧电脑打造个人开发测试平台的
从零搭建OpenStack私有云:我是如何用两台旧电脑打造个人开发测试平台的 去年整理仓库时发现两台闲置的旧台式机,配置都是i5-6500加16GB内存。看着它们积灰实在可惜,我决定用这两台"老伙计"搭建一个OpenStack私有云环境,…...

手把手教你用SPI配置AD9253寄存器:从芯片手册到FPGA驱动的完整避坑指南
手把手教你用SPI配置AD9253寄存器:从芯片手册到FPGA驱动的完整避坑指南 当第一次拿到AD9253这款四通道14位高速ADC芯片时,许多工程师会被其丰富的功能和复杂的寄存器配置所困扰。本文将从一个实战工程师的角度,带你一步步完成从SPI配置到FPGA…...

蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 [特殊字符]
蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 🚀 【免费下载链接】mogu_blog_v2 蘑菇博客(MoguBlog),一个基于微服务架构的前后端分离博客系统。Web端使用Vue Element , 移动端使用uniapp和ColorUI。后端使用Spring cloud Spr…...