TP DP PP 并行训练方法介绍
张量并行TP
挖坑
流水线并行 PP
经典的流水线并行范式有Google推出的Gpipe,和微软推出的PipeDream。两者的推出时间都在2019年左右,大体设计框架一致。主要差别为:在梯度更新上,Gpipe是同步的,PipeDream是异步的。异步方法更进一步降低了GPU的空转时间比。虽然PipeDream设计更精妙些,但是Gpipe因为其“够用”和浅显易懂,更受大众欢迎(torch的pp接口就基于Gpipe)。因此本文以Gpipe作为流水线并行的范例进行介绍。https://zhuanlan.zhihu.com/p/613196255
gpipe论文 https://arxiv.org/pdf/1811.06965.pdf
naive模型并行
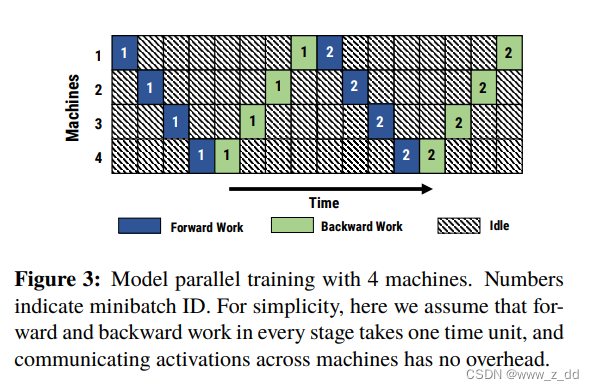
图片来自https://arxiv.org/pdf/1806.03377.pdf
如果一个模型一个gpu放不下,就某些层放在一个卡,上图表示一共四个卡,F0表示第0个batch,灰色的第一个卡计算完第0个batch交给黄色的卡。黄卡上放的模型的层的输入是灰色的卡上放的模型的输出。一次只有一个gpu工作。
GPipe
把mini batch分成micro batch,这样多个gpu可以同时计算。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vWgbtoCx-1691048478616)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/8aa74ef6-308b-48d9-b961-ac72a6031873/Untitled.png)]](https://img-blog.csdnimg.cn/d69d2ead79f340ee8b0864c33cd8381f.png)
具体的算法:
用户定义好L层的网络、前向、损失函数等以后,GPipe 就会将网络划分为 K 个单元,并将第 k 个单元放置在第 k 个加速器上。通信原语自动插入到分区边界,以允许相邻分区之间的数据传输。分区算法最小化所有单元估计成本的方差,以便通过同步所有分区的计算时间来最大化管道的效率。
前向过程:GPipe先把大小为N的minibatch分成M个相等的micro batch,通过 K 个加速器进行流水线处理。在向后传递过程中,每个micro batch通过 K 个加速器进行流水线处理。在向后传递过程中,通过 K 个加速器进行流水线处理。在向后传递过程中,每个micro batch计算梯度都是基于跟前向同一个模型,没有误差哦。每个mini batch的最后,M个micro的梯度都计算完了
在前向计算期间,每个加速器仅存储分区边界处的输出激活。在向后传递期间,第 k 个加速器重新计算复合前向函数 Fk。
在micro-batch的划分下,我们在计算Batch Normalization时会有影响。Gpipe的方法是,在训练时计算和运用的是micro-batch里的均值和方差,但同时持续追踪全部mini-batch的移动平均和方差,以便在测试阶段进行使用。Layer Normalization则不受影响。
总结:
如果模型太大一张卡放不下,按照层来切开,第一层放在第一张卡,第二层放在第二张卡,这样第二层要等第一层的计算结果作为输入,等待的时候卡就空闲了很浪费。
gpipe的做法是batch再切开切成micro batch,这样虽然第一个microbatch的时候要等待,但是多张卡可以同时工作了。
GPipe 还用recomputation这个简单有效的技巧来降低内存,进一步允许训练更大的模型
如何按照层自动划分:根据计算量分配到每张卡
gpipe的micro batch上是需要累计梯度的
重计算,多计算一次前向换空间,但是不是梯度来了从头前向一次,中间有几个激活其实存下来了,叫做checkpoint,然后从checkpoing的激活值的位置前向就行。(因为每张卡上不止一个micro batch,所以激活的数量也是好几份,这个量就比较大)
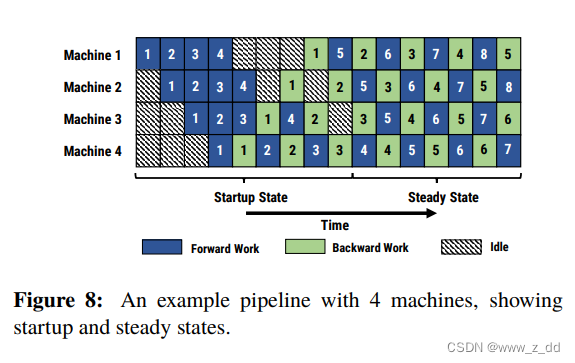
Gpipe流水线其存在两个问题:硬件利用率低,内存占用大。于是在另一篇流水并行的论文里,微软 PipeDream 针对这些问题提出了改进方法,就是1F1B (One Forward pass followed by One Backward pass)策略。
PipeDream
微软在论文 PipeDream: Fast and Efficient Pipeline Parallel DNN Training
PipeDream 模型的基本单位是层,PipeDream将DNN的这些层划分为多个阶段。每个阶段(stage)由模型中的一组连续层组成
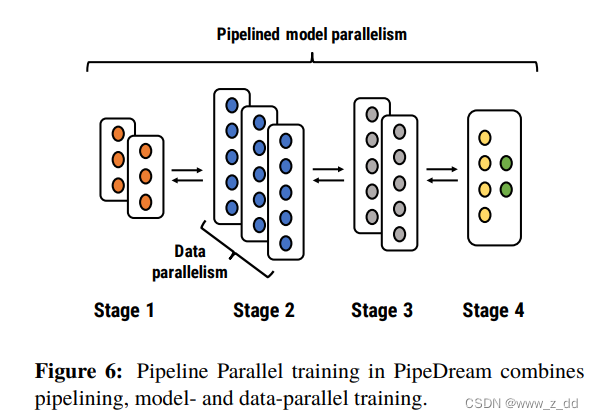
1F1B
由于前向计算的 activation 需要等到对应的后向计算完成后才能释放(无论有没有使用 Checkpointing 技术),因此在流水并行下,如果想尽可能节省缓存 activation 的份数,就要尽量缩短每份 activation 保存的时间,也就是让每份 activation 都尽可能早的释放,所以要让每个 micro-batch 的数据尽可能早的完成后向计算,因此需要把后向计算的优先级提高
参考:
[源码解析] 深度学习流水线并行Gpipe https://www.cnblogs.com/rossiXYZ/
数据并行DP
FSDP
fair scale的fsdp
https://engineering.fb.com/2021/07/15/open-source/fsdp/
Fully Sharded Data Parallel (FSDP) 是一种DP算法,offload一部分计算到cpu。但是模型的参数在多个gpu之间是share的?每个microbatch的计算还是local to每个gpu的
在标准 DDP 训练中,每个工作人员处理一个单独的批次,并使用allreduce对各gpu的梯度进行求和。虽然 DDP 已经变得非常流行,但它占用的 GPU 内存超出了其需要,因为模型权重和优化器状态会在所有 DDP 工作线程之间复制。
FSDP是pytorch1.11的新特性。其新特性目的主要是训练大模型。我们都知道pytorch DDP用起来简单方便,但是要求整个模型能加载一个GPU上,这使得大模型的训练需要使用额外复杂的设置进行模型拆分。pytorch的FSDP从DeepSpeed ZeRO以及FairScale的FSDP中获取灵感,打破模型分片的障碍(包括模型参数,梯度,优化器状态),同时仍然保持了数据并行的简单性。
相关文章:
TP DP PP 并行训练方法介绍
这里写目录标题 张量并行TP流水线并行 PPnaive模型并行GPipePipeDream 数据并行DPFSDP 张量并行TP 挖坑 流水线并行 PP 经典的流水线并行范式有Google推出的Gpipe,和微软推出的PipeDream。两者的推出时间都在2019年左右,大体设计框架一致。主要差别为…...

P005 – Python操作符、操作数和表达式
在Python中,操作符用于对值或变量进行操作。操作数是操作符作用的值或变量。表达式是由操作符、操作数和其他表达式组合而成的,可以求得一个值。 在本文中,我们将探讨Python中的不同类型的操作符,学习如何与操作数一起使用它们来…...

SQL92 SQL99 语法 Oracle 、SQL Server 、MySQL 多表连接、Natural 、USING
SQL92 VS SQL 99 语法 92语法 内连接 from table1, table2 where table1.col table2.col 外连接 放在 从表 左连接: from table1, table2 where table1.col table2.col() 右连接: from table1, table2 where table…...
物联网平台使用笔记
阿里云的IOT平台限制了50个设备。排除 移动云的限制较少,这里试用下。 创建完产品,接入设备后。使用MQTT客户端测试 其中client id 为设备id, username 为产品id, password 可以使用设备调试那里生成的。或使用官方token.exe 生成…...
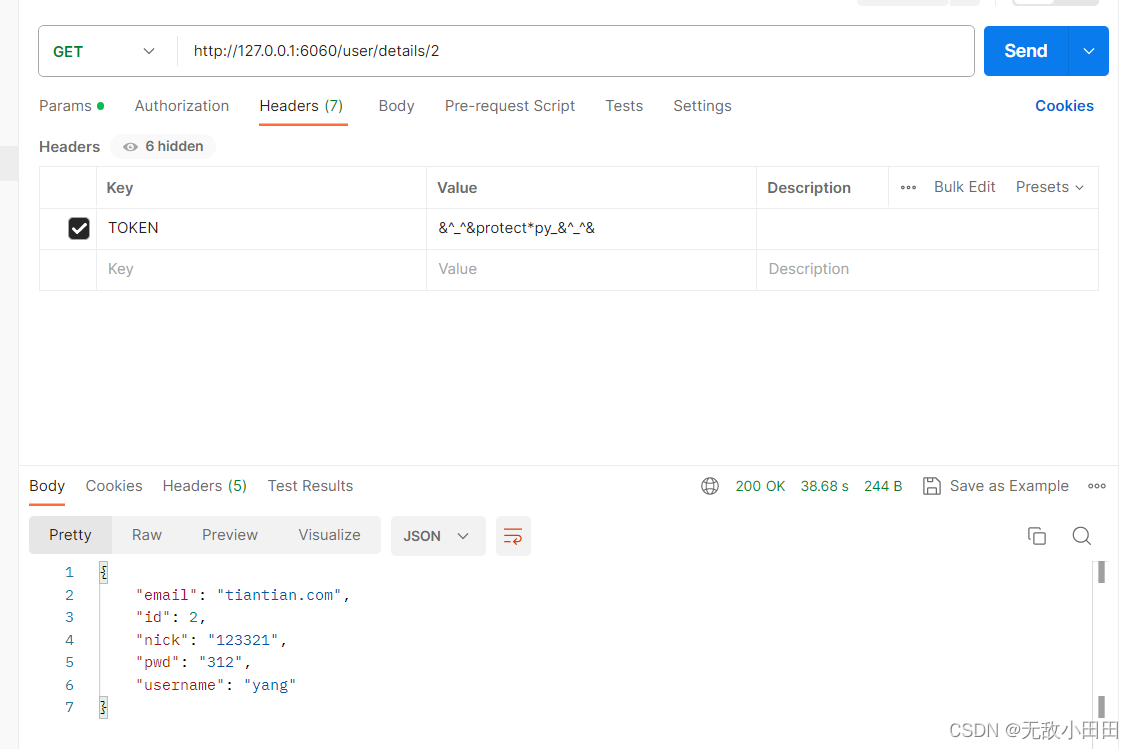
Python-flask项目入门
一、flask对于简单搭建一个基于python语言-的web项目非常简单 二、项目目录 示例代码 git路径 三、代码介绍 1、安装pip依赖 通过pip插入数据驱动依赖pip install flask-sqlalchemy 和 pip install pymysql 2.配置数据源 config.py DIALECT mysql DRIVER pymysql USERN…...

基于数据库 Sqlite3 的 root 管理系统
1.服务器 1.1服务器函数入口 #include "server.h"int main(int argc, char const *argv[]) {char buf[128] {0};char buf_ID[256] {0};// 接收报错信息判断sqlite3 *db;// 创建员工信息的表格,存在则打开db Sqlite_Create();if (db NULL){printf("sqlite_…...
Hadoop 之 Hive 4.0.0-alpha-2 搭建(八)
Hadoop 之 Hive 搭建与使用 一.Hive 简介二.Hive 搭建1.下载2.安装1.解压并配置 HIVE2.修改 hive-site.xml3.修改 hadoop 的 core-site.xml4.启动 三.Hive 测试1.基础测试2.建库建表3.Java 连接测试1.Pom依赖2.Yarm 配置文件3.启动类4.配置类5.测试类 一.Hive 简介 Hive 是基于…...
vue3常用API之学习笔记
目录 一、setup函数 vue2与vue3变量区别 二、生命周期 三、reactive方法 四、ref方法 1、简介 2、使用 3、ref与reactive 4、获取标签元素或组件 五、toRef 1、简介 2、ref与toRef的区别 六、toRefs 七、shallowReactive 浅reactive 1、简介 2、shallowreactiv…...
—— 字符串操作)
Python 程序设计入门(005)—— 字符串操作
Python 程序设计入门(005)—— 字符串操作 目录 Python 程序设计入门(005)—— 字符串操作一、字符串切片与连接1、切片的索引方式2、切片操作的基本表达式3、 切片操作举例4、字符串连接 二、字符串替换:replace() 方…...
怎样将项目jar包放到服务器上
目录 1、在配置文件中配置账号密码 2.在父级的pom里面,加上这个标签 3. deploy部署 4. 注:这两个id得匹配上(原因:有的人会只有上传到测试包的权限,id对应,拥有账号密码的才能有权限) 5.子项…...
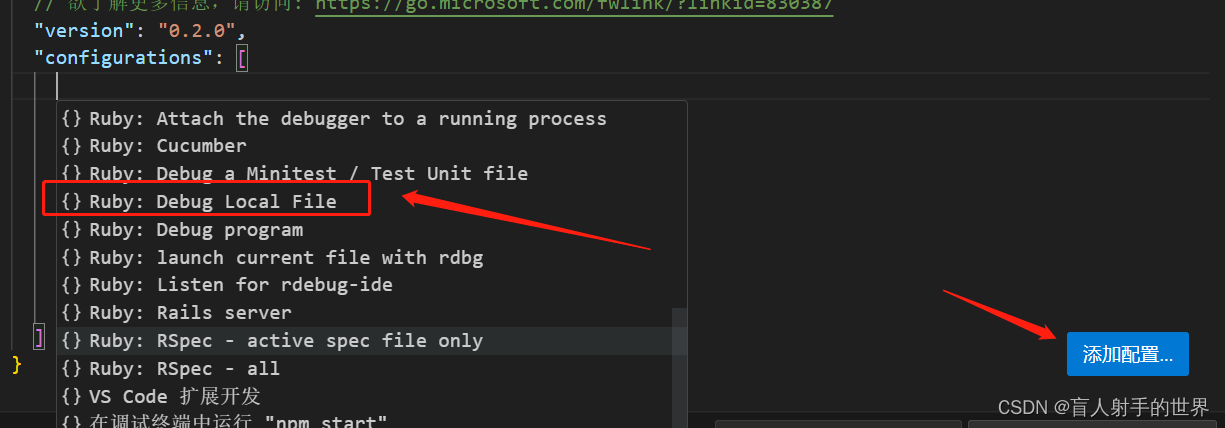
ruby调试
如果下载 ruby-debug-ide gem install ruby-debug-ide vscode 下载 ruby扩展 1, ruby 2,修改launch.json...
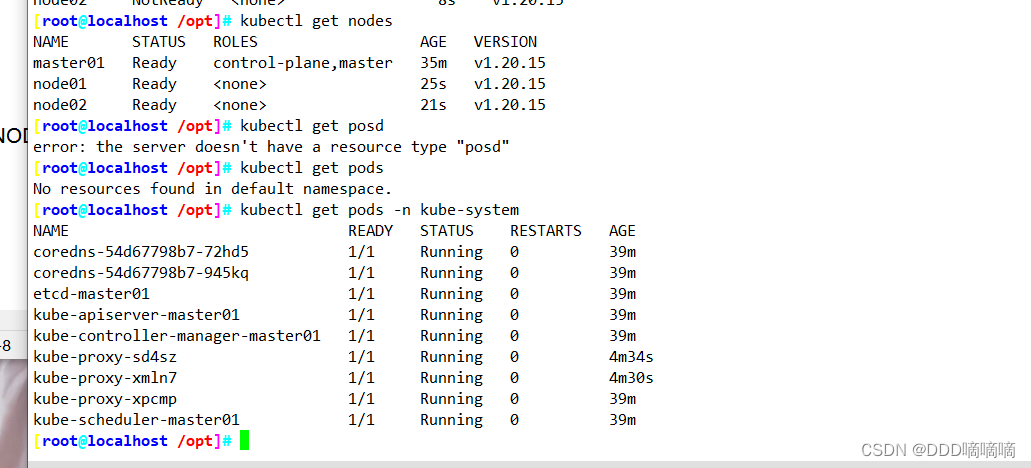
【云原生】使用kubeadm搭建K8S
目录 一、Kubeadm搭建K8S1.1环境准备1.2所有节点安装docker1.3所有节点安装kubeadm,kubelet和kubectl1.4部署K8S集群1.5所有节点部署网络插件flannel 二、部署 Dashboard 一、Kubeadm搭建K8S 1.1环境准备 服务器IP配置master(2C/4G,cpu核心…...
HCIE-Datacom真题和机构资料
通过认证验证的能力 具备坚实的企业网络跨场景融合解决方案理论知识,能够使用华为数通产品及解决方案进行企业园区网络、广域互联网络及广域承载网络的规划、建设、维护及优化,能够胜任企业网络全场景专家岗位(包括客户经理、项目经理、售前…...

轮足机器人硬件总结
简介 本文主要根据“轮腿机器人Hyun”总结的硬件部分。 轮腿机器人Hyun开源地址:https://github.com/HuGuoXuang/Hyun 1 电源部分 1.1 78M05 78M05是一款三端稳压器芯片,它可以将输入电压稳定输出为5V直流电压. 1.2 AMS1117-3.3 AMS1117-3.3是一种输…...
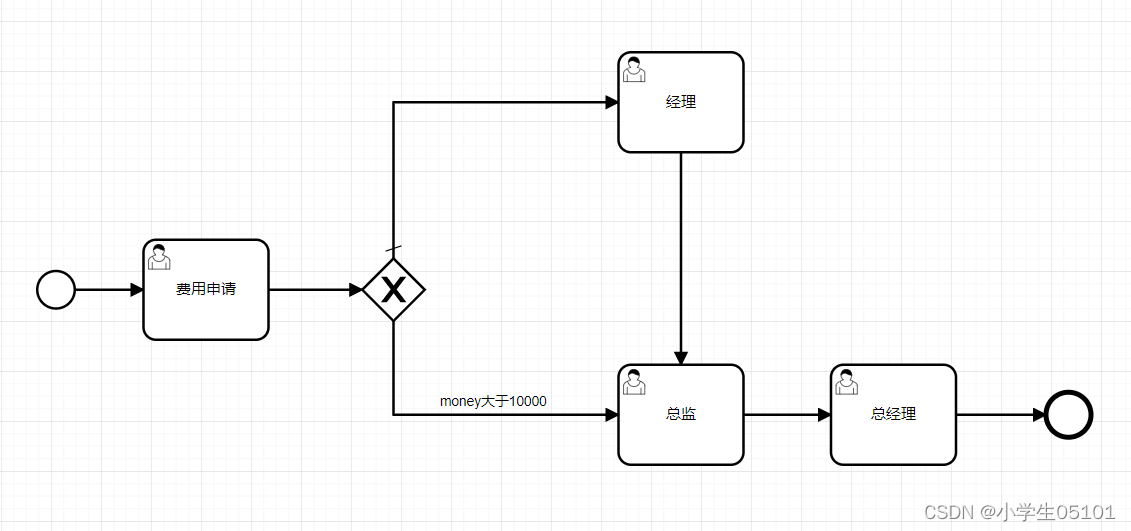
Flowable-网关-排他网关
目录 定义图形标记XML内容示例视频教程 定义 排他网关,也叫异或(XOR)网关,是 BPMN 中使用的最常见的网关之一,用来在流转中实 现发散分支决策。排他网关需要和条件顺序流搭配使用,当流程执行到排他网关&am…...

GET 和 POST 的区别
GET 和 POST 的区别(流利说) 从 http 协议的角度来说,GET 和 POST 它们都只是请求行中的第一个单词,除了语义不同,其实没有本质的区别。 之所以在实际开发中会产生各种区别,主要是因为浏览器的默认行为造成…...
FFmpeg中硬解码后深度学习模型的图像处理dnn_processing(一)
ffmpeg 硬件解码 ffmpeg硬件解码可以使用最新的vulkan来做,基本上来说,不挑操作系统是比较重要的,如果直接使用cuda也是非常好的选择。 AVPixelFormat sourcepf AV_PIX_FMT_NV12;// AV_PIX_FMT_NV12;// AV_PIX_FMT_YUV420P;AVPixelFormat d…...
计及需求响应和电能交互的多主体综合能源系统主从博弈优化调度策略(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
local-path-provisioner的使用(hostPath、local、local-path-provisioner三者对比)
前言 环境:k8s 1.22.17 、centos7.9 有时候,为了使用本地服务器上的磁盘存储资源,我们会使用hostPath这种方式来为k8s提供本地存储,本篇就来对比一下hostPath、local这两种使用本地服务器储存的方案,从而引出第三种lo…...
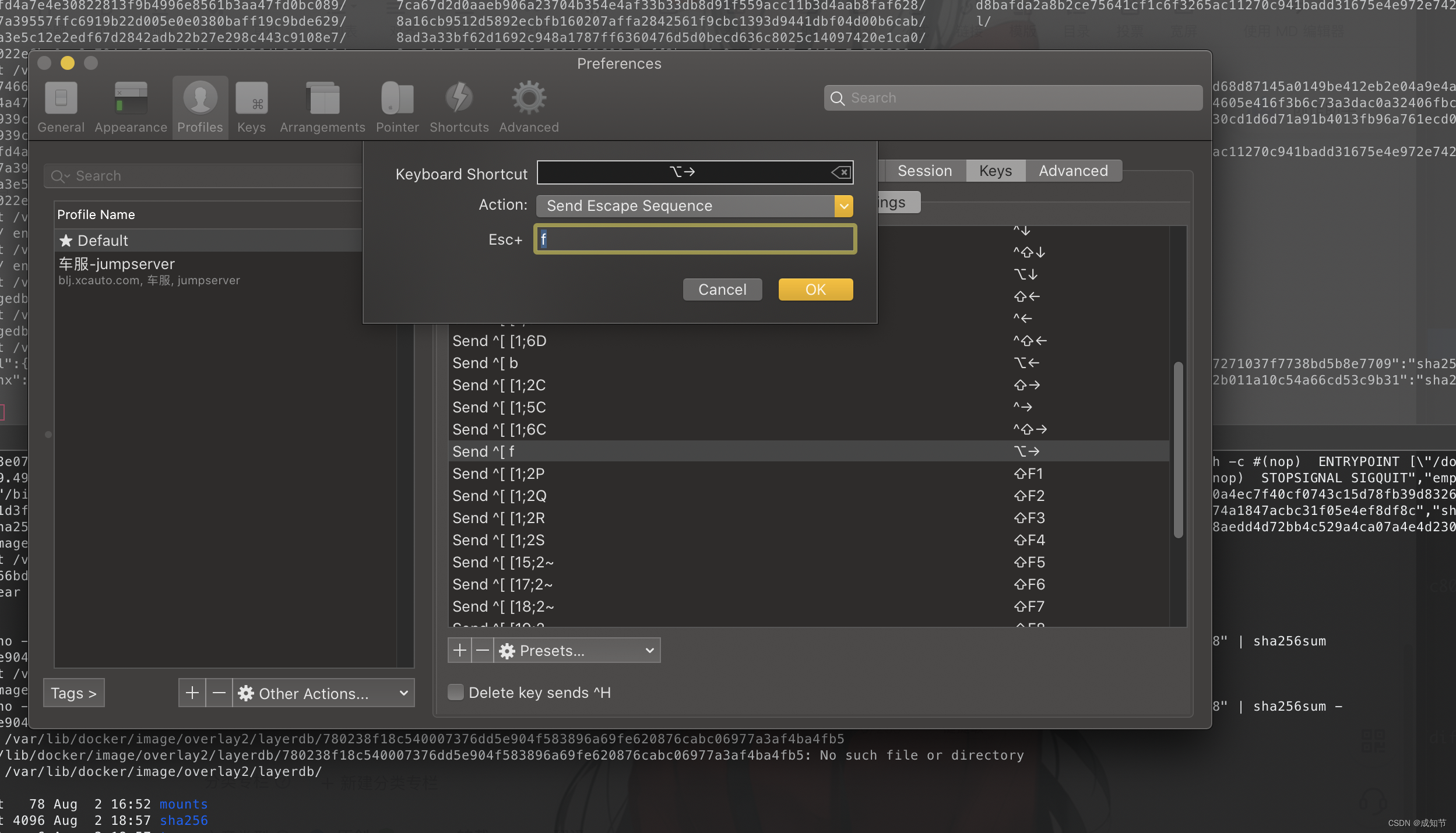
命令行快捷键Mac Iterm2
原文:Jump forwards, backwards and delete a word in iTerm2 on Mac OS iTerm2并不允许你使用 ⌥← 或 ⌥→ 来跳过单词。 你也不能使用 ⌥backspace 来删除整个单词。 下面是在Mac OS上如何配置iTerm2以便能做到这一点的方法。 退格键 首先,你需要将你的左侧 ⌥…...

Redis对象类型与底层数据结构
一、Redis对象类型概述 1.1 Redis数据类型总览 Redis提供了丰富的数据类型,用于不同的业务场景:对象类型说明典型场景String字符串缓存、计数器、分布式锁List双向链表队列、消息队列、最新列表Hash哈希表存储对象、购物车Set无序集合好友关系、抽奖Zset…...

告别HAL库延时:在STM32F103上基于CubeMX和LL库,打造更高效的SysTick延时方案
STM32F103高效延时方案:从HAL库到LL库的SysTick实战优化 在嵌入式开发中,精确的延时控制往往是项目成败的关键因素之一。许多STM32开发者最初接触的是HAL库提供的HAL_Delay()函数,它简单易用,但随着项目复杂度提升,特别…...

DreamTalk与3DMM参数:如何提取和利用面部表情风格特征
DreamTalk与3DMM参数:如何提取和利用面部表情风格特征 【免费下载链接】dreamtalk Official implementations for paper: DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models 项目地址: https://gitcode.com/gh_mirrors/d…...

【从零学Vibe Coding】第一章:Vibe Coding 到底是什么?
第一章:Vibe Coding 到底是什么? 先说结论 Vibe Coding 不是"不写代码",而是"先用自然语言描述意图,再让 AI 生成代码,人类负责判断、修正和推进结果"。 这个词在 2025 年突然出圈,不…...

GNSS模块教程:大夏龙雀 DX-GP21,从硬件接线到 NMEA 数据解析
在物联网、无人机、精准农业等场景中,高精度定位是核心需求。深圳大夏龙雀科技的 DX-GP21 作为一款多模多频 GNSS 模块,支持北斗、GPS、Galileo 等多系统联合定位,定位精度<1.0m,兼具低功耗、小尺寸特性,性…...

RT-Thread Studio开发RA2L1:从环境搭建到GPIO输入输出实战
1. 项目概述与核心价值最近在捣鼓瑞萨电子的RA2L1 MCU开发板,想基于RT-Thread Studio这个国产IDE快速上手。我发现很多朋友拿到一块新板子,第一步“点亮LED”或者“读取按键”这个看似简单的操作,往往就卡在了环境搭建上。网上的资料要么过于…...

灌封胶的热仿真困局:建模方法选择,如何不踩坑?
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 211、985硕士,从业16年 从事结构设计、热设计、售前、产品设计、项目管理等工作,涉足消费电子、新能源、医疗设备、制药信息化、核工业等…...

半波整流电路:从原理到实践,掌握AC-DC转换基础
1. 项目概述:从交流到直流的第一步在电子电路的世界里,我们常常需要将交流电(AC)转换为直流电(DC),这个过程我们称之为“整流”。而半波整流电路,可以说是所有整流电路中最基础、最经…...
)
外部系统调用SAP数据?用ABAP RFC函数搭个“桥梁”其实很简单(含Function Group创建避坑)
跨系统数据整合:ABAP RFC函数的设计哲学与实战指南 当企业数字化转型进入深水区,业务系统间的数据孤岛问题日益凸显。某零售企业的供应链总监最近就面临这样的挑战:"我们的电商平台需要实时获取SAP中的库存数据,但每次手工导…...

c# 简单记录一下我学习的过程 2026.5.20
这一节有几个内容, 分别为方法返回值,方法值传递 ref out in 参数 以及params 参数列表。 接下来我会记录我对他们的理解。1.方法返回值 return有了return 你就可以把方法里面的值拿出来继续用 2.方法值传递分为两种 一个是值传递 一…...