【计算机视觉 | 目标检测 | 图像分割】arxiv 计算机视觉关于目标检测和图像分割的学术速递(8 月 2 日论文合集)
文章目录
- 一、检测相关(8篇)
- 1.1 Explainable Cost-Sensitive Deep Neural Networks for Brain Tumor Detection from Brain MRI Images considering Data Imbalance
- 1.2 MonoNext: A 3D Monocular Object Detection with ConvNext
- 1.3 Detecting Cloud Presence in Satellite Images Using the RGB-based CLIP Vision-Language Model
- 1.4 Patch-wise Auto-Encoder for Visual Anomaly Detection
- 1.5 GradOrth: A Simple yet Efficient Out-of-Distribution Detection with Orthogonal Projection of Gradients
- 1.6 Diffusion Model for Camouflaged Object Detection
- 1.7 Detecting the Anomalies in LiDAR Pointcloud
- 1.8 T-Fusion Net: A Novel Deep Neural Network Augmented with Multiple Localizations based Spatial Attention Mechanisms for Covid-19 Detection
- 二、分割|语义相关(5篇)
- 2.1 LISA: Reasoning Segmentation via Large Language Model
- 2.2 Scene Separation & Data Selection: Temporal Segmentation Algorithm for Real-Time Video Stream Analysis
- 2.3 Multispectral Image Segmentation in Agriculture: A Comprehensive Study on Fusion Approaches
- 2.4 Boundary Difference Over Union Loss For Medical Image Segmentation
- 2.5 C-DARL: Contrastive diffusion adversarial representation learning for label-free blood vessel segmentation
一、检测相关(8篇)
1.1 Explainable Cost-Sensitive Deep Neural Networks for Brain Tumor Detection from Brain MRI Images considering Data Imbalance
考虑数据不平衡的可解释代价敏感深度神经网络在脑MRI图像中的脑肿瘤检测
https://arxiv.org/abs/2308.00608
本文介绍了一项关于使用卷积神经网络(CNN),ResNet 50,InceptionV 3,EfficientNetB 0和NASNetMobile模型来有效检测脑肿瘤的研究,以减少手动审查报告所需的时间,并创建一个自动化的脑肿瘤分类系统。提出了一个自动化管道,其中包括五个模型:CNN、ResNet 50、InceptionV 3、EfficientNetB 0和NASNetMobile。所提出的架构的性能进行评估的平衡数据集,并发现产生的精确度为99.33%的微调InceptionV 3模型。此外,可解释的人工智能方法被纳入可视化模型的潜在行为,以了解其黑箱行为。为了进一步优化训练过程,已经提出了一种成本敏感的神经网络方法,以便与不平衡的数据集一起工作,该数据集的准确性比我们的实验中使用的传统模型高出近4%。成本敏感的InceptionV 3(CS-InceptionV 3)和CNN(CS-CNN)在不平衡数据集上分别显示出92.31%的准确率和1.00的召回值。所提出的模型在提高肿瘤检测准确性方面表现出巨大的潜力,必须进一步开发应用于实际解决方案。我们提供了数据集,并在https://github.com/shahariar-shibli/Explainable-Cost-Sensitive-Deep-Neural-Networks-for-Brain-Tumor-Detection-from-Brain-MRI-Images上公开了我们的实现
1.2 MonoNext: A 3D Monocular Object Detection with ConvNext
MonoNext:一种基于ConvNext的三维单目目标检测
https://arxiv.org/abs/2308.00596
自动驾驶感知任务在很大程度上依赖于相机作为对象检测、语义分割、实例分割和对象跟踪的主要传感器。然而,由相机捕获的RGB图像缺乏深度信息,这在3D检测任务中构成了重大挑战。为了补充这些缺失的数据,诸如LIDAR和RADAR之类的映射传感器被用于精确的3D对象检测。尽管它们的显着的准确性,多传感器模型是昂贵的,需要高的计算需求。相比之下,单目3D对象检测模型正变得越来越受欢迎,为3D检测提供了更快、更便宜且更易于实现的解决方案。本文介绍了一种不同的多任务学习方法,称为MonoNext,它利用空间网格来映射场景中的对象。MonoNext采用基于ConvNext网络的直接方法,并且仅需要3D边界框注释数据。在我们使用KITTI数据集的实验中,MonoNext实现了与最先进方法相当的高精度和竞争性能。此外,通过添加更多的训练数据,MonoNext超越了自己,实现了更高的准确率。
1.3 Detecting Cloud Presence in Satellite Images Using the RGB-based CLIP Vision-Language Model
利用基于RGB的CLIP视觉语言模型检测卫星图像中的云存在
https://arxiv.org/abs/2308.00541
这项工作探讨了预先训练的CLIP视觉语言模型的能力,以识别卫星图像受云影响。几种方法使用的模型来执行云的存在检测的建议和评估,包括一个纯zero-shot操作与文本提示和几个微调的方法。此外,跨不同的数据集和传感器类型(哨兵-2和陆地卫星-8)的方法的可移植性进行了测试。CLIP可以实现非平凡的性能云存在检测任务与明显的能力,以概括跨感测模态和感测频带。还发现,低成本的微调阶段导致真阴性率的大幅增加。结果表明,CLIP模型学习的表示可以是有用的卫星图像处理任务涉及云。
1.4 Patch-wise Auto-Encoder for Visual Anomaly Detection
用于视觉异常检测的逐块自动编码器
https://arxiv.org/abs/2308.00429
没有异常先验的异常检测是具有挑战性的。在无监督异常检测领域,传统的自动编码器(AE)往往基于以下假设而失败:仅在正常图像上训练,模型将无法正确地重建异常图像。相反,我们提出了一个新的补丁式自动编码器(Patch AE)框架,其目的是增强,而不是削弱它的重建能力的AE异常。图像的每个块通过学习的特征表示的对应的空间分布的特征向量来重建,即,分块重建,保证了声发射的异常敏感性。我们的方法是简单和有效的。该模型在Mvtec AD基准测试上取得了最先进的性能,证明了该模型的有效性。在实际工业应用场景中显示出巨大的潜力。
1.5 GradOrth: A Simple yet Efficient Out-of-Distribution Detection with Orthogonal Projection of Gradients
GradOrth:一种简单而高效的梯度正交投影非分布检测方法
https://arxiv.org/abs/2308.00310
检测分发外(OOD)数据对于确保机器学习模型在现实世界应用中的安全部署至关重要。然而,现有的OOD检测方法主要依赖于特征图或全梯度空间信息来导出OOD分数,忽略了预训练网络的最重要参数在分布(ID)数据上的作用。在这项研究中,我们提出了一种新的方法,称为GradOrth,以促进OOD检测的基础上一个有趣的观察,识别OOD数据的重要功能在于在分布(ID)数据的低秩子空间。特别是,我们确定OOD数据通过计算的子空间上的梯度投影的范数被认为是重要的分布数据。较大的正交投影值(即小投影值)指示样本为OOD,因为它捕获ID数据的弱相关性。这种简单而有效的方法表现出出色的性能,与目前最先进的方法相比,在95%真阳性率(FPR95)高达8%时,平均假阳性率显著降低。
1.6 Diffusion Model for Camouflaged Object Detection
伪装目标检测的扩散模型
https://arxiv.org/abs/2308.00303
伪装目标检测是一项具有挑战性的任务,旨在识别与其背景高度相似的目标。由于强大的噪声到图像去噪能力的去噪扩散模型,在本文中,我们提出了一个基于扩散的框架伪装对象检测,称为diffCOD,一个新的框架,认为伪装对象分割任务作为一个去噪扩散过程中的噪声掩模的对象掩模。具体地,对象掩模从地面真实掩模扩散到随机分布,并且所设计的模型学习反转该噪声过程。为了加强去噪学习,将输入图像先验编码并集成到去噪扩散模型中以指导扩散过程。此外,我们设计了一个注入注意力模块(IAM)交互条件语义特征提取的图像与扩散噪声嵌入通过交叉注意力机制,以加强去噪学习。在四个广泛使用的COD基准数据集上进行的大量实验表明,与现有的11种最先进的方法相比,该方法具有良好的性能,特别是在伪装对象的详细纹理分割方面。我们的代码将在以下网址公开发布:https://github.com/ZNan-Chen/diffCOD。
1.7 Detecting the Anomalies in LiDAR Pointcloud
激光雷达点云中的异常检测
https://arxiv.org/abs/2308.00187
LiDAR传感器在现代自动驾驶系统的感知堆栈中发挥着重要作用。恶劣的天气条件,如雨,雾和灰尘,以及一些(偶尔)LiDAR硬件故障可能会导致LiDAR产生点云与异常模式,如分散的噪声点和不寻常的强度值。在本文中,我们提出了一种新的方法来检测激光雷达是否产生异常点云,通过分析点云的特征。具体来说,我们开发了一个基于LiDAR点的空间和强度分布的点云质量度量来表征点云的噪声水平,它依赖于纯数学分析,不需要任何标记或训练,因为基于学习的方法。因此,该方法是可扩展的,并且可以通过监测LiDAR数据中的异常来在线地快速部署以提高自主安全性,或者离线地快速部署以在大量数据上执行LiDAR行为的深入研究。所提出的方法进行了研究,广泛的真实公共道路数据收集的激光雷达与不同的扫描机制和激光光谱,并被证明能够有效地处理各种已知和未知来源的点云异常。
1.8 T-Fusion Net: A Novel Deep Neural Network Augmented with Multiple Localizations based Spatial Attention Mechanisms for Covid-19 Detection
T-融合网络:一种新颖的基于多局部化的深度神经网络空间注意机制用于新冠肺炎检测
https://arxiv.org/abs/2308.00053
近年来,深度神经网络在图像分类任务中表现更好。然而,数据集的日益复杂性和对改进性能的需求需要探索创新技术。目前的工作提出了一种新的深度神经网络(称为T-Fusion Net),它增强了基于空间注意力的多个定位。这种注意力机制允许网络关注相关图像区域,提高其辨别能力。所述网络的均匀集合进一步用于提高图像分类精度。对于集成,所提出的方法考虑多个实例的个人T-融合网络。该模型采用模糊最大融合合并的输出的各个网络。通过精心选择的参数来优化融合过程,以平衡各个模型的贡献。在Covid-19(SARS-CoV-2 CT扫描)基准数据集上的实验评估证明了所提出的T-Fusion Net及其集成的有效性。与其他最先进的方法相比,所提出的T-Fusion Net和同质集成模型表现出更好的性能,分别达到97.59%和98.4%的准确率。
二、分割|语义相关(5篇)
2.1 LISA: Reasoning Segmentation via Large Language Model
LISA:基于大型语言模型的推理分词
https://arxiv.org/abs/2308.00692
虽然近年来感知系统取得了显着的进步,但它们仍然依赖于明确的人类指令来识别目标对象或类别,然后执行视觉识别任务。这样的系统缺乏主动推理和理解隐式用户意图的能力。在这项工作中,我们提出了一个新的分割任务-推理分割。该任务的目的是输出一个分割掩码给定一个复杂的和隐式的查询文本。此外,我们建立了一个基准,包括超过一千的图像指令对,将复杂的推理和世界知识的评估目的。最后,我们介绍一下LISA:大型语言指令分割助手,它继承了多模态大型语言模型(LLM)的语言生成能力,同时还具有生成分割掩码的能力。我们扩展了原来的词汇表与令牌,并提出了嵌入作为掩模范例解锁的分割能力。值得注意的是,LISA可以处理以下案件:1)复杂推理; 2)世界知识; 3)解释性回答; 4)多话轮谈话。此外,当专门在无推理数据集上训练时,它表现出强大zero-shot能力。此外,微调模型,只有239个推理分割图像指令对的结果,在进一步的性能增强。实验表明,我们的方法不仅解锁新的推理分割能力,但也证明了有效的复杂推理分割和标准的参考分割任务。代码、模型和演示请访问https://github.com/dvlab-research/LISA。
2.2 Scene Separation & Data Selection: Temporal Segmentation Algorithm for Real-Time Video Stream Analysis
场景分离与数据选择:实时视频流分析中的时间分割算法
https://arxiv.org/abs/2308.00210
我们提出了一种实时视频流解释的时间分割算法2SDS(场景分离和数据选择算法)。它补充了基于CNN的模型,以利用视频中的时间信息。2SDS算法通过比较两帧图像的差异来检测视频流中场景之间的变化。它将视频分成片段(场景),并通过将自身与CNN模型相结合,2SDS可以为每个场景选择最佳结果。在本文中,我们将讨论一些基本的方法和概念背后的2SDS,以及提出一些初步的实验结果,关于2SDS。在这些实验中,2SDS已经实现了超过90%的总体准确度。
2.3 Multispectral Image Segmentation in Agriculture: A Comprehensive Study on Fusion Approaches
农业多光谱图像分割:融合方法的综合研究
https://arxiv.org/abs/2308.00159
多光谱图像经常被纳入农业任务,为图像分割,作物监测,田间机器人和产量估计等应用提供有价值的支持。从图像分割的角度来看,多光谱相机可以提供丰富的光谱信息,有助于降噪和特征提取。因此,本文集中在使用融合方法,以提高农业应用的分割过程中。更具体地说,在这项工作中,我们比较不同的融合方法,通过结合RGB和NDVI作为输入作物行检测,这可以是有用的自主机器人在现场操作。输入被单独使用以及在过程的不同时间(早期和晚期融合)组合以执行经典和基于DL的语义分割。在这项研究中,两个农业相关的数据集进行分析,使用基于深度学习(DL)和经典的分割方法。实验表明,经典的分割方法,利用边缘检测和阈值处理等技术,可以有效地与基于DL的算法竞争,特别是在需要精确的前景-背景分离的任务。这表明,传统方法在农业领域的某些专门应用中保持其功效。此外,在融合策略检查,后期融合出现的最强大的方法,在不同的分割场景的适应性和有效性的优势。数据集和代码可在https://github.com/Cybonic/MISAgriculture.git上获得。
2.4 Boundary Difference Over Union Loss For Medical Image Segmentation
基于联合损失的边界差分医学图像分割算法
https://arxiv.org/abs/2308.00220
医学图像分割是临床诊断的关键。然而,目前医学图像分割的损失主要集中在整体分割的结果,与较少的损失,提出了指导边界分割。那些确实存在的损失往往需要与其他损失结合使用,并产生无效的结果。为了解决这个问题,我们已经开发了一个简单而有效的损失,称为边界差联合损失(边界DOU损失),以指导边界区域分割。它是通过计算预测和地面实况的差集与差集和部分交集的并集的比率来获得的。我们的损失仅依赖于区域计算,易于实现和训练稳定,无需任何额外的损失。此外,我们使用的目标大小,自适应地调整应用到边界区域的注意。使用UNet,TransUNet和Swin-UNet在两个数据集(ACDC和Synapse)上的实验结果证明了我们提出的损失函数的有效性。代码可在https://github.com/sunfan-bvb/BoundaryDoULoss获得。
2.5 C-DARL: Contrastive diffusion adversarial representation learning for label-free blood vessel segmentation
C-DARL:用于无标记血管分割的对比扩散对抗表示学习
https://arxiv.org/abs/2308.00193
医学成像中的血管分割是基于图像的医学和介入医学中广泛的临床场景中的血管疾病诊断和介入规划的基本步骤之一。不幸的是,由于细微的分支和复杂的结构,血管掩模的手动注释是具有挑战性的并且是资源密集的。为了克服这个问题,本文提出了一种自监督血管分割方法,称为对比扩散对抗表示学习(C-DARL)模型。我们的模型是由一个扩散模块和一个生成模块,学习多域血管数据的分布,通过生成合成血管图像从扩散潜伏。此外,我们通过基于掩码的对比损失来进行对比学习,以便模型可以学习更真实的血管表示。为了验证功效,使用各种血管数据集(包括冠状动脉血管造影片、腹部数字减影血管造影片和视网膜成像)来训练C-DARL。实验结果证实,我们的模型实现了基线方法的噪声鲁棒性的性能改善,表明C-DARL血管分割的有效性。
相关文章:
)
【计算机视觉 | 目标检测 | 图像分割】arxiv 计算机视觉关于目标检测和图像分割的学术速递(8 月 2 日论文合集)
文章目录 一、检测相关(8篇)1.1 Explainable Cost-Sensitive Deep Neural Networks for Brain Tumor Detection from Brain MRI Images considering Data Imbalance1.2 MonoNext: A 3D Monocular Object Detection with ConvNext1.3 Detecting Cloud Presence in Satellite Ima…...

JDK中「SPI」原理分析
基于【JDK1.8】 一、SPI简介 1、概念 SPI即service-provider-interface的简写; JDK内置的服务提供加载机制,可以为服务接口加载实现类,解耦是其核心思想,也是很多框架和组件的常用手段; 2、入门案例 2.1 定义接口 …...
)
DSL:数字用户线路(Digital Subscriber Line)
一、基础释义 DSL(数字用户线路,Digital Subscriber Line)是一种用于传输数字数据的通信技术,允许数据在传统的电话线路(铜线)上进行高速传输。DSL技术通过将高频信号叠加在低频的语音信号上,使…...
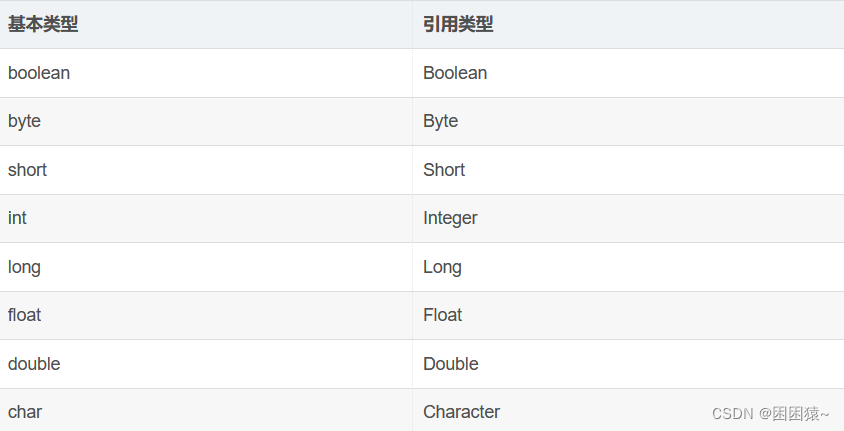
Java集合ArrayList详解
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。 ArrayList 继承了 AbstractList ,并实现了 List 接口。 Java 数组 与 ArrayList 在Java中,我们需要先声明数组的大…...
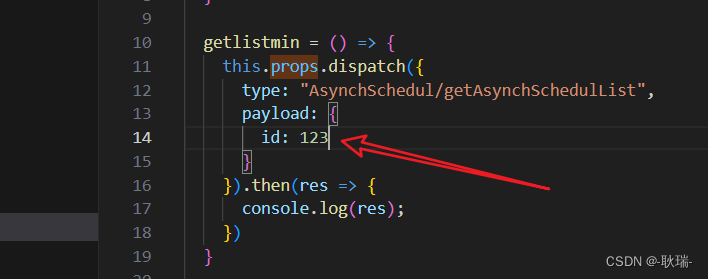
React Dva项目 Model中编写与调用异步函数
上文 React Dva项目中模仿网络请求数据方法 中,我们用项目方法模拟了后端请求的数据 那么 今天我们就在models中尝试去使用一下这种异步获取数据的方法 之前 我们在文章 React Dva项目创建Model,并演示数据管理与函数调用 中已经接触过Model了 也可以理解为 它就是 …...
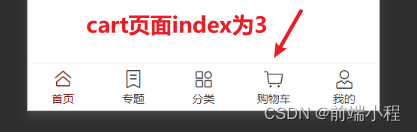
小程序自定义tabBar+Vant weapp
1.构建npm,安装Vant weapp: 1)根目录下 ,初始化生成依赖文件package.json npm init -y 2)安装vant # 通过 npm 安装 npm i vant/weapp -S --production 3)修改 package.json 文件 开发者工具创建的项…...
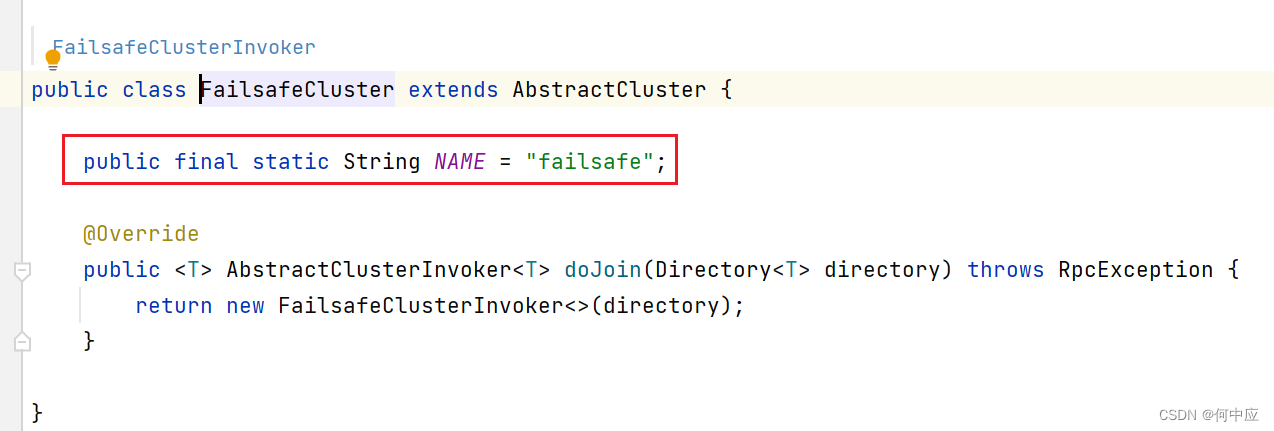
Dubbo+Zookeeper使用
说明:Apache Dubbo 是一款 RPC 服务开发框架,用于解决微服务架构下的服务治理与通信问题,官方提供了 Java、Golang 等多语言 SDK 实现。 本文介绍Dubbo的简单使用及一些Dubbo功能特性,注册中心使用的是ZooKeeper,可在…...

短视频平台视频怎么去掉水印?
短视频怎么去水印,困扰很多人,例如,有些logo水印,动态水印等等,分享操作经验: 抖音作为中国最受欢迎的社交娱乐应用程序之一,已成为许多人日常生活中不可或缺的一部分。在使用抖音过程中&#x…...
Stable Diffusion - Style Editor 和 Easy Prompt Selector 提示词插件配置
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/132122450 Style Editor 插件: cd extensions git clone https://ghproxy.com/https://github.com/chrisgoringe/Styles-Editor报错&…...

Stable Diffusion - SDXL 模型测试 (DreamShaper 和 GuoFeng v4) 与全身图像参数配置
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/132085757 图像来源于 GuoFeng v4 XL 模型,艺术风格是赛博朋克、漫画、奇幻。 全身图像是指拍摄对象的整个身体都在画面中的照片&…...
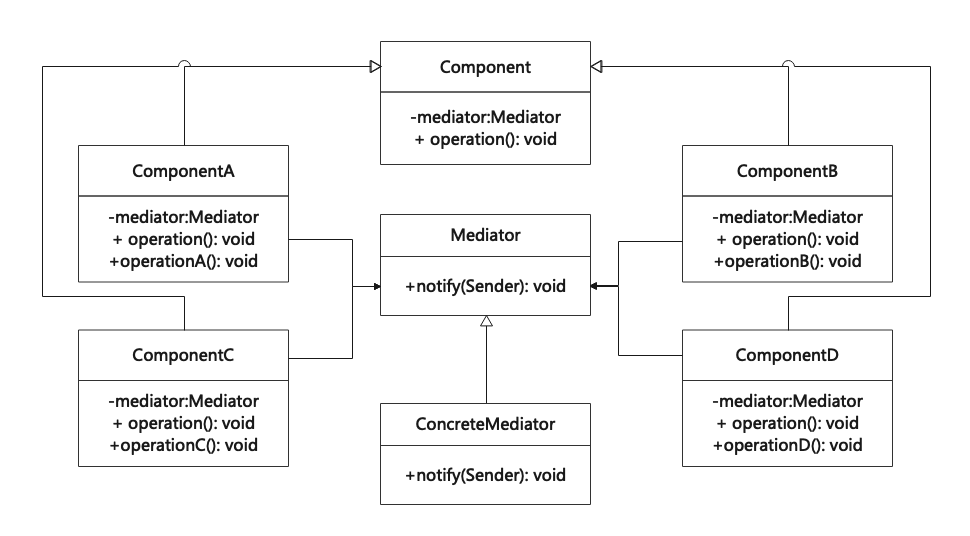
中介者模式(Mediator)
中介者模式是一种行为设计模式,可以减少对象之间混乱无序的依赖关系。该模式会限制对象之间的直接交互,迫使它们通过一个封装了对象间交互行为的中介者对象来进行合作,从而使对象间耦合松散,并可独立地改变它们之间的交互。中介者…...
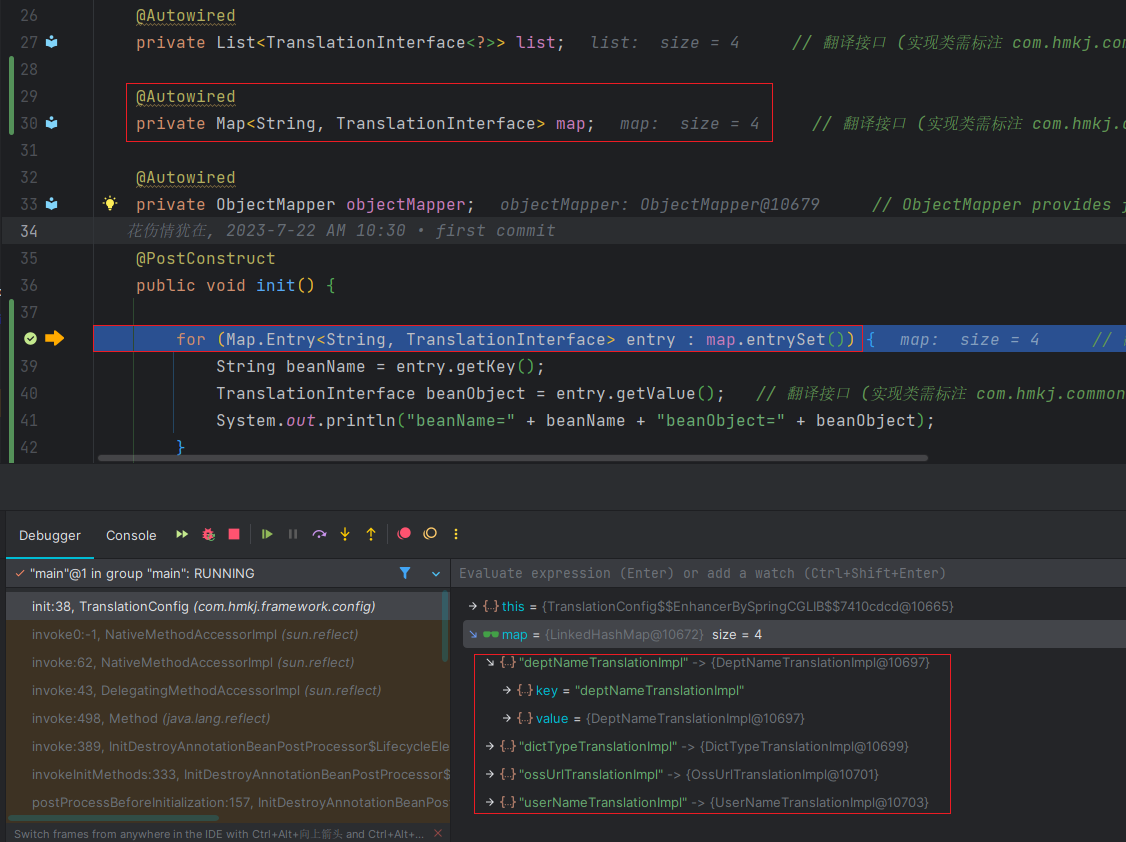
SpringBoot使用@Autowired将实现类注入到List或者Map集合中
前言 最近看到RuoYi-Vue-Plus翻译功能 Translation的翻译模块配置类TranslationConfig,其中有一个注入TranslationInterface翻译接口实现类的写法让我感到很新颖,但这种写法在Spring 3.0版本以后就已经支持注入List和Map,平时都没有注意到这…...

【linux目录的权限和粘滞位】
目录: 目录的权限粘滞位总结 目录的权限 可执行权限: 如果目录没有可执行权限, 则无法cd到目录中. 可读权限: 如果目录没有可读权限, 则无法用ls等命令查看目录中的文件内容. 可写权限: 如果目录没有可写权限, 则无法在目录中创建文件, 也无法在目录中删除文件. 粘…...
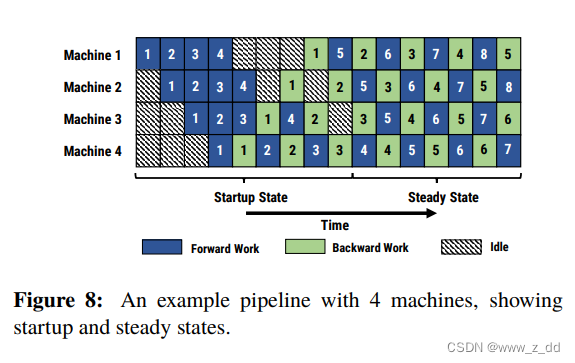
TP DP PP 并行训练方法介绍
这里写目录标题 张量并行TP流水线并行 PPnaive模型并行GPipePipeDream 数据并行DPFSDP 张量并行TP 挖坑 流水线并行 PP 经典的流水线并行范式有Google推出的Gpipe,和微软推出的PipeDream。两者的推出时间都在2019年左右,大体设计框架一致。主要差别为…...

P005 – Python操作符、操作数和表达式
在Python中,操作符用于对值或变量进行操作。操作数是操作符作用的值或变量。表达式是由操作符、操作数和其他表达式组合而成的,可以求得一个值。 在本文中,我们将探讨Python中的不同类型的操作符,学习如何与操作数一起使用它们来…...

SQL92 SQL99 语法 Oracle 、SQL Server 、MySQL 多表连接、Natural 、USING
SQL92 VS SQL 99 语法 92语法 内连接 from table1, table2 where table1.col table2.col 外连接 放在 从表 左连接: from table1, table2 where table1.col table2.col() 右连接: from table1, table2 where table…...
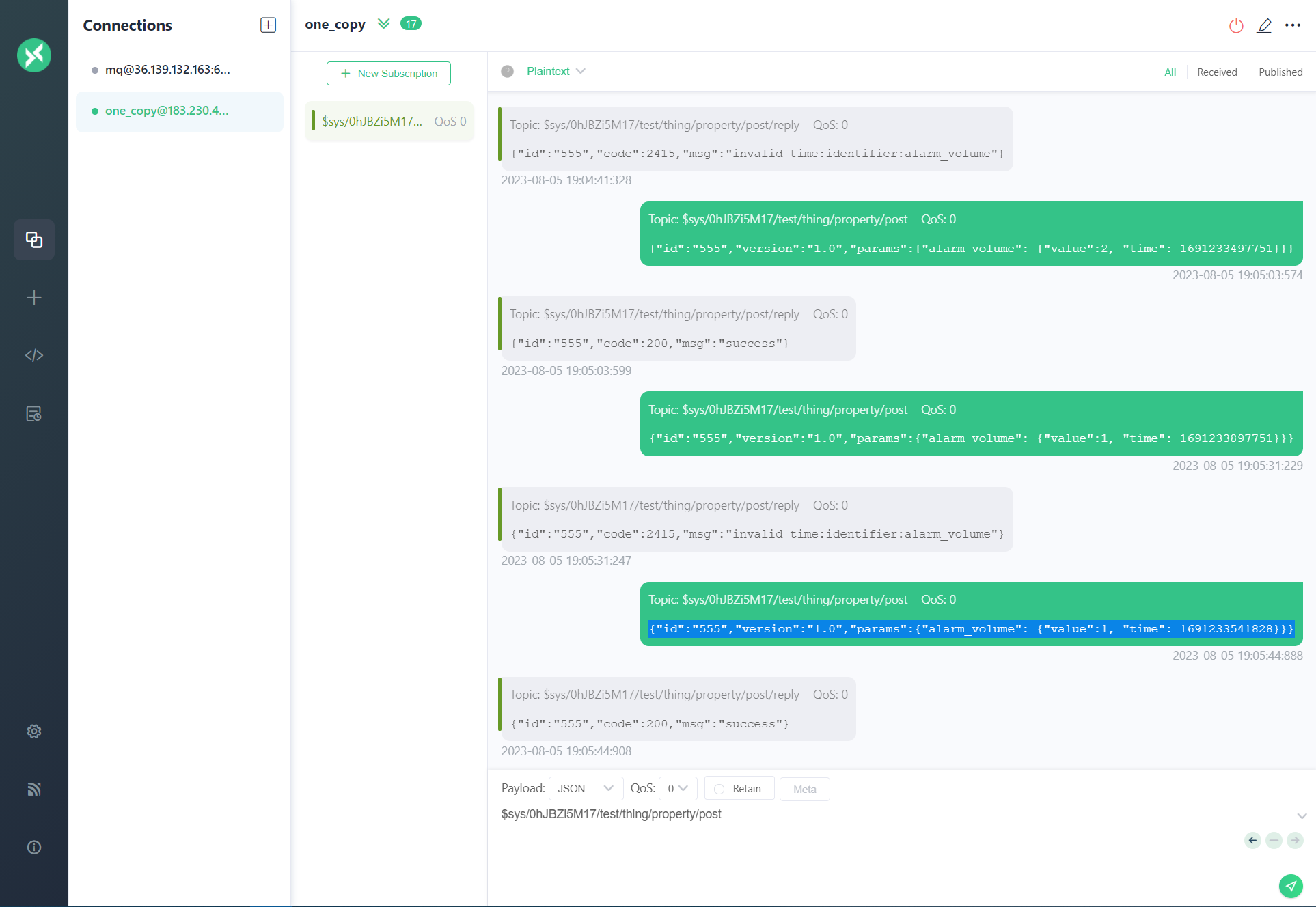
物联网平台使用笔记
阿里云的IOT平台限制了50个设备。排除 移动云的限制较少,这里试用下。 创建完产品,接入设备后。使用MQTT客户端测试 其中client id 为设备id, username 为产品id, password 可以使用设备调试那里生成的。或使用官方token.exe 生成…...
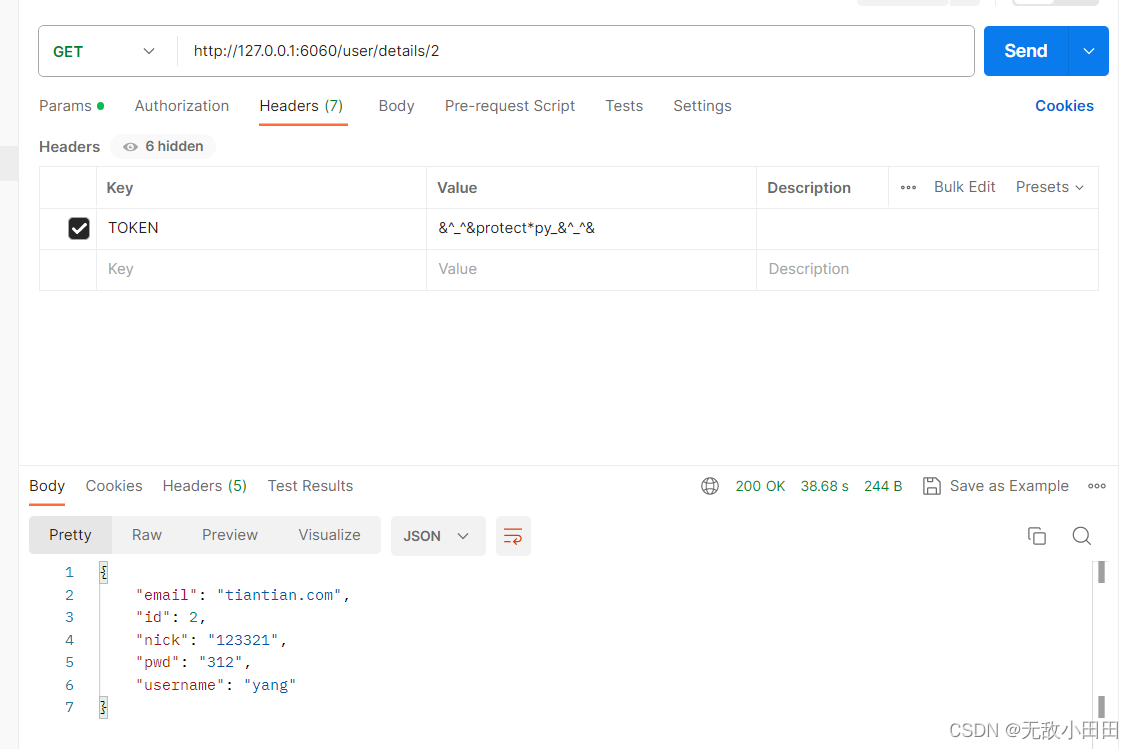
Python-flask项目入门
一、flask对于简单搭建一个基于python语言-的web项目非常简单 二、项目目录 示例代码 git路径 三、代码介绍 1、安装pip依赖 通过pip插入数据驱动依赖pip install flask-sqlalchemy 和 pip install pymysql 2.配置数据源 config.py DIALECT mysql DRIVER pymysql USERN…...

基于数据库 Sqlite3 的 root 管理系统
1.服务器 1.1服务器函数入口 #include "server.h"int main(int argc, char const *argv[]) {char buf[128] {0};char buf_ID[256] {0};// 接收报错信息判断sqlite3 *db;// 创建员工信息的表格,存在则打开db Sqlite_Create();if (db NULL){printf("sqlite_…...
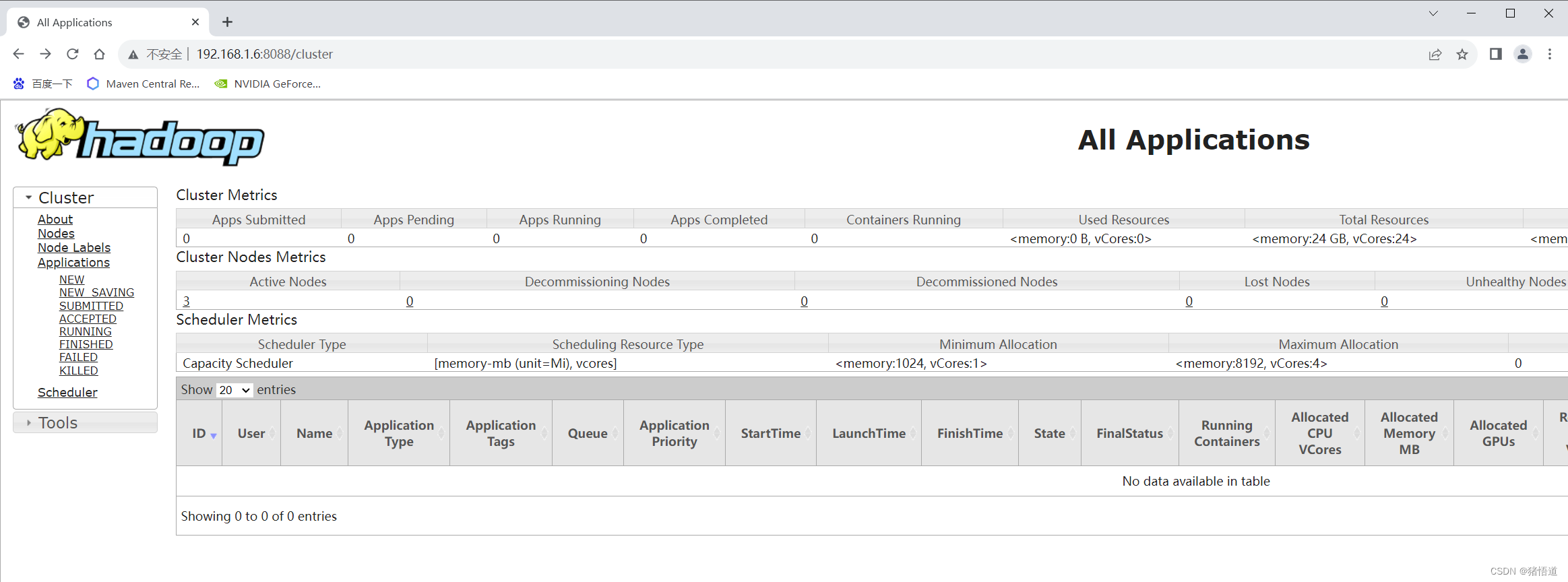
Hadoop 之 Hive 4.0.0-alpha-2 搭建(八)
Hadoop 之 Hive 搭建与使用 一.Hive 简介二.Hive 搭建1.下载2.安装1.解压并配置 HIVE2.修改 hive-site.xml3.修改 hadoop 的 core-site.xml4.启动 三.Hive 测试1.基础测试2.建库建表3.Java 连接测试1.Pom依赖2.Yarm 配置文件3.启动类4.配置类5.测试类 一.Hive 简介 Hive 是基于…...
)
C语言编程实战:用ASCII码表玩转字符大小写转换(附完整代码)
C语言编程实战:用ASCII码表玩转字符大小写转换(附完整代码) 在编程的世界里,字符处理是最基础却又最容易被忽视的技能之一。很多C语言初学者在学习过程中,往往对字符和字符串的操作感到困惑——为什么a和A是不同的&…...

别再只会真彩色了!用ENVI玩转波段组合:揭秘植被红、水体蓝背后的遥感密码
遥感图像解译的艺术:ENVI波段组合背后的科学密码 当一张卫星遥感图像首次展现在眼前时,未经训练的眼睛往往只能看到一片模糊的色块。然而,对于掌握波段组合奥秘的解译专家来说,这些色彩背后隐藏着丰富的地表信息——健康的植被、水…...

CREO新手避坑指南:从拉伸到抽壳,这10个建模细节90%的人都踩过
CREO新手避坑指南:从拉伸到抽壳,这10个建模细节90%的人都踩过 刚接触CREO三维建模时,许多初学者会被软件强大的功能所吸引,却往往在基础操作上反复踩坑。本文将从实际案例出发,剖析那些看似简单却暗藏玄机的建模细节&a…...

nuScenes数据集“平替”指南:Mini版够用吗?完整版、Test版到底怎么选?
nuScenes数据集选型实战指南:从Mini版到完整版的决策逻辑 第一次接触nuScenes数据集时,面对动辄几百GB的庞然大物和仅有3.9GB的mini版本,相信不少研究者都会陷入选择困难。这就像站在自助餐厅里,既想品尝所有美味,又担…...

UnityPackage Extractor终极指南:快速免费提取Unity资源包
UnityPackage Extractor终极指南:快速免费提取Unity资源包 【免费下载链接】unitypackage_extractor Extract a .unitypackage, with or without Python 项目地址: https://gitcode.com/gh_mirrors/un/unitypackage_extractor UnityPackage Extractor是一款简…...

独角数卡支付系统:如何构建高可用的自动售货支付解决方案
独角数卡支付系统:如何构建高可用的自动售货支付解决方案 【免费下载链接】dujiaoka 🦄独角数卡(自动售货系统)-开源站长自动化售货解决方案、高效、稳定、快速!🚀🚀🎉🎉 项目地址: https://g…...

数科OFD阅读历史清理全攻略:统信UOS/麒麟KYLINOS下图形界面与命令行两种方法实测
数科OFD阅读历史清理全攻略:统信UOS/麒麟KYLINOS下图形界面与命令行两种方法实测 在国产化办公环境中,数科OFD作为主流的版式文档阅读工具,其使用痕迹管理常被忽视却至关重要。无论是个人用户希望保护阅读隐私,还是企业IT管理员需…...

别再死记硬背!用Python可视化理解第一类曲面积分中的dσ与dxdy关系
用Python可视化破解曲面积分:从dσ到dxdy的几何直觉 第一次看到曲面积分公式里的dσ √(1 fx fy) dxdy时,我盯着那堆平方根和偏导数符号发呆了十分钟。直到某天用Matplotlib让这个公式"动起来",才突然明白那些教科书上的推导到底…...

全志T113-i嵌入式Linux系统一键升级方案设计与实现
1. 项目概述:为什么我们需要“一键升级”?拿到一块全志T113-i的开发板,或者用它做产品的朋友,肯定都经历过手动更新固件的“痛苦”。传统的升级方式,比如用PhoenixSuit、LiveSuit这类PC端工具,需要连接USB线…...

科研学术篇---论文搜索方法
高效搜集和研读论文,是构建扎实知识体系的基石。要想做到“高效”与“高质”并重,需要把整个过程当作一个闭环系统来优化——从目标锁定、来源筛选、检索策略,到快速粗筛、深度内化、持续追踪,每一步都有对应的工具和心法。下面逐…...