flink+kafka+doris+springboot集成例子
目录
一、例子说明
1.1、概述
1.1、所需环境
1.2、执行流程
二、部署环境
2.1、中间件部署
2.1.1部署kakfa
2.1.1.1 上传解压kafka安装包
2.1.1.2 修改zookeeper.properties
2.1.1.3 修改server.properties
2.1.1.3 启动kafka
2.1.2、部署flink
2.1.2.1 上传解压flink安装包
2.1.2.1 修改flink配置
2.1.2.3 flink单节点启动与停止命令
2.1.3、部署doris
2.1.3.1 下载安装包并上传服务器
2.1.3.2 配置doris fe(前端)
2.1.3.3 启动doris fe(前端)
2.1.3.4 配置doris be(后端)
2.1.3.5 doris启动 be(后端)
2.1.3.5 doris启动成功验证
2.1.3.6 doris的be在fe上注册
2.1.3.6 通过doris的fe的Web UI页面创建数据库表
2.1.4、部署spring-boot的syslog-kafka-es-avro
2.1.4.1、syslog-kafka-es-avro基于netty已UDP方式监听syslog
2.1.4.2、syslog-kafka-es-avro已avro格式保存数据到kafka
2.1.5、部署spring-boot的flink-do-doris
2.1.5.1、flink-do-doris主类
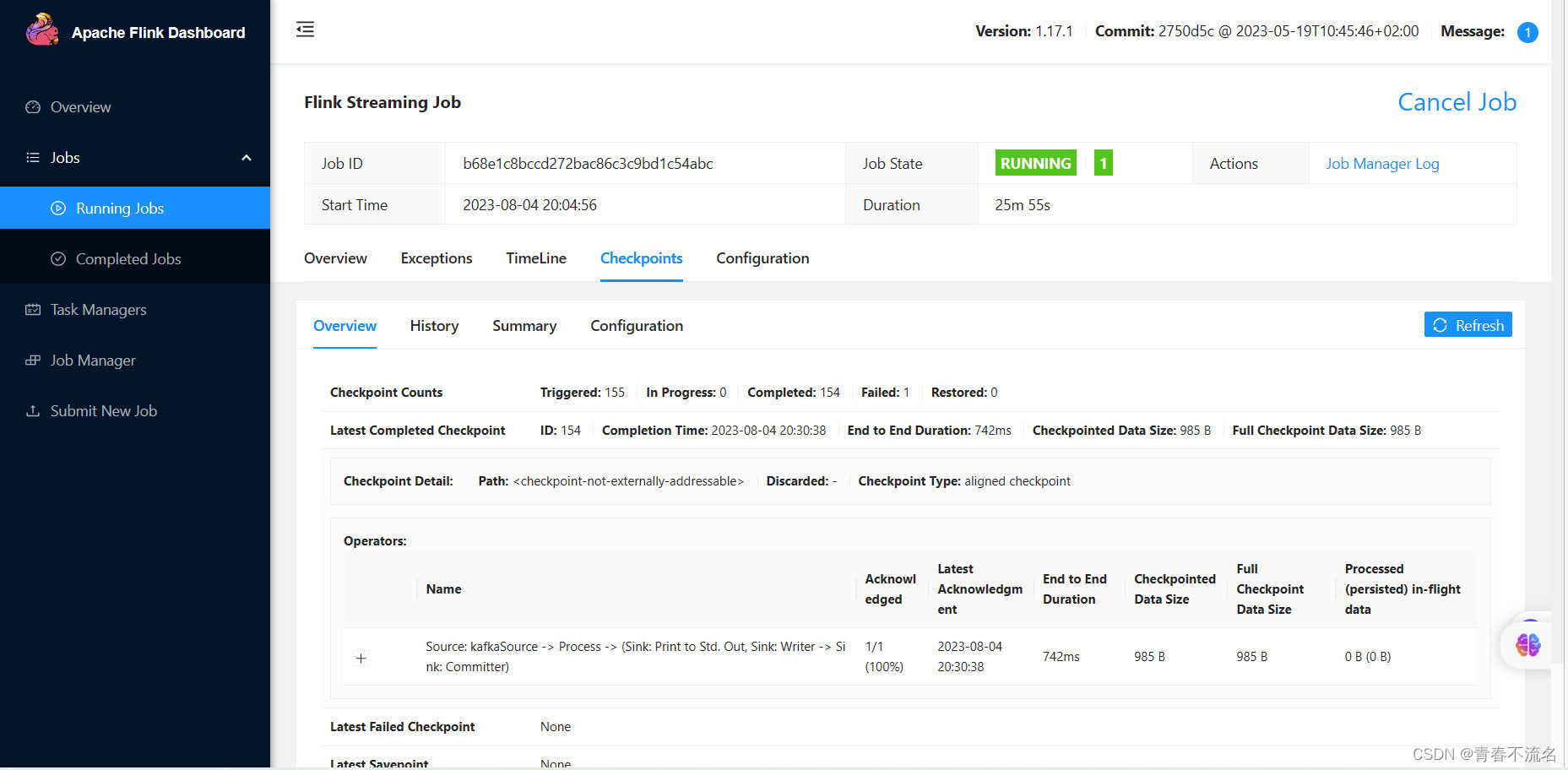
三、效果验证
3.1、发送syslog日志,syslog-kafka-es-avro监听处理,存储到kafka
3.2 、查看flink消费kafka
3.3、 在doris上查看入库详情
一、例子说明
1.1、概述
这是个例子,将输入写入kafka,flink消费kafka,并实时写入doris。
1.1、所需环境
| 软件 | 版本 | 备注 | |
| kafka_2.12-3.5.0 | kafka_2.12-3.5.0 | 使用自带的zookeeper | |
| flink-1.17.1 | flink-1.17.1 | ||
| jdk | 1.8.0_202 | ||
| doris | 1.2.6 ( Stable ) | ||
spring-boot | 2.1.17.RELEASE | syslog-kafka-es-avro | |
| spring-boot | 2.4.5 | flink-do-doris | |
flink-doris-connector-1.17 | 1.4.0 | ||
| elasticsearch | 7.6.2 | ||
| 基础目录 | /home | ||
| 服务器 | 10.10.10.99 | centos 7.x |
1.2、执行流程
①、工具发送数据
②、spring-boot基于netty开启某端口监听,接收发送的消息内容,进行数据清洗、标准化
③、kafka product组件接收上一步产生的数据,已avro格式保存到kafka某topic上。
④、flink实时消费kafka某topic,以流的方式进行处理,输出源设置为doris
⑤、终端数据可在doris的fe页面上实时查询。
二、部署环境
2.1、中间件部署
2.1.1部署kakfa
2.1.1.1 上传解压kafka安装包
将安装包kafka_2.12-3.5.0.tar.gz上传到/home目录
tar -zxvf kafka_2.12-3.5.0.tar.gz
mv kafka_2.12-3.5.0 kafka
2.1.1.2 修改zookeeper.properties
路径:/home/kafka/config/zookeeper.properties
dataDir=/home/kafka/zookeeper
clientPort=2181
maxClientCnxns=0
admin.enableServer=false
# admin.serverPort=8080
2.1.1.3 修改server.properties
路径:/home/kafka/config/server.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.#
# This configuration file is intended for use in ZK-based mode, where Apache ZooKeeper is required.
# See kafka.server.KafkaConfig for additional details and defaults
############################## Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0############################# Socket Server Settings #############################
# The address the socket server listens on. If not configured, the host name will be equal to the value of
# java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://10.10.10.99:9092# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=/home/kafka/kafka-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
log.flush.interval.ms=1000############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
#log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings ############################## The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
2.1.1.3 启动kafka
①、先启动kafka自带的zookeeper
nohup /home/kafka/bin/zookeeper-server-start.sh /home/kafka/config/zookeeper.properties 2>&1 &
验证启动情况ps -ef | grep zookeeper
②启动kafka
/home/kafka/bin/kafka-server-start.sh -daemon /home/kafka/config/server.properties
验证启动情况
etstat -ntulp | grep 9092
或者ps -ef | grep kafka
2.1.2、部署flink
2.1.2.1 上传解压flink安装包
下载地址https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
下载完成后将flink-1.17.1-bin-scala_2.12.tgz上传到/home目录下,解压并重命名为flink
2.1.2.1 修改flink配置
配置文件路径/home/flink/conf/flink-conf.yaml
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
#==============================================================================
# Common
#==============================================================================# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn
# automatically configure the host name based on the hostname of the node where the
# JobManager runs.jobmanager.rpc.address: localhost
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The host interface the JobManager will bind to. By default, this is localhost, and will prevent
# the JobManager from communicating outside the machine/container it is running on.
# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.
# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.
#
# To enable this, set the bind-host address to one that has access to an outside facing network
# interface, such as 0.0.0.0.jobmanager.bind-host: 0.0.0.0
# The total process memory size for the JobManager.
#
# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.jobmanager.memory.process.size: 1600m
# The host interface the TaskManager will bind to. By default, this is localhost, and will prevent
# the TaskManager from communicating outside the machine/container it is running on.
# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.
# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.
#
# To enable this, set the bind-host address to one that has access to an outside facing network
# interface, such as 0.0.0.0.taskmanager.bind-host: 0.0.0.0
# The address of the host on which the TaskManager runs and can be reached by the JobManager and
# other TaskManagers. If not specified, the TaskManager will try different strategies to identify
# the address.
#
# Note this address needs to be reachable by the JobManager and forward traffic to one of
# the interfaces the TaskManager is bound to (see 'taskmanager.bind-host').
#
# Note also that unless all TaskManagers are running on the same machine, this address needs to be
# configured separately for each TaskManager.taskmanager.host: localhost
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.taskmanager.memory.process.size: 1728m
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
#
# taskmanager.memory.flink.size: 1280m# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# The default file system scheme and authority.
#
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme#==============================================================================
# High Availability
#==============================================================================# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
#
# high-availability.type: zookeeper# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
# high-availability.storageDir: hdfs:///flink/ha/# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
# high-availability.zookeeper.quorum: localhost:2181
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
# high-availability.zookeeper.client.acl: open#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled. Checkpointing is enabled when execution.checkpointing.interval > 0.
#
# Execution checkpointing related parameters. Please refer to CheckpointConfig and ExecutionCheckpointingOptions for more details.
#
# execution.checkpointing.interval: 3min
# execution.checkpointing.externalized-checkpoint-retention: [DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION]
# execution.checkpointing.max-concurrent-checkpoints: 1
# execution.checkpointing.min-pause: 0
# execution.checkpointing.mode: [EXACTLY_ONCE, AT_LEAST_ONCE]
# execution.checkpointing.timeout: 10min
# execution.checkpointing.tolerable-failed-checkpoints: 0
# execution.checkpointing.unaligned: false
#
# Supported backends are 'hashmap', 'rocksdb', or the
# <class-name-of-factory>.
#
# state.backend.type: hashmap# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints# Default target directory for savepoints, optional.
#
# state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false# The failover strategy, i.e., how the job computation recovers from task failures.
# Only restart tasks that may have been affected by the task failure, which typically includes
# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.jobmanager.execution.failover-strategy: region
#==============================================================================
# Rest & web frontend
#==============================================================================# The port to which the REST client connects to. If rest.bind-port has
# not been specified, then the server will bind to this port as well.
#
rest.port: 8081# The address to which the REST client will connect to
#
rest.address: 10.10.10.99# Port range for the REST and web server to bind to.
#
#rest.bind-port: 8080-8090# The address that the REST & web server binds to
# By default, this is localhost, which prevents the REST & web server from
# being able to communicate outside of the machine/container it is running on.
#
# To enable this, set the bind address to one that has access to outside-facing
# network interface, such as 0.0.0.0.
#
rest.bind-address: 0.0.0.0# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.web.submit.enable: true
# Flag to specify whether job cancellation is enabled from the web-based
# runtime monitor. Uncomment to disable.web.cancel.enable: true
#==============================================================================
# Advanced
#==============================================================================# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
# io.tmp.dirs: /tmp# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager.memory.network.fraction: 0.1
# taskmanager.memory.network.min: 64mb
# taskmanager.memory.network.max: 1gb#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client#==============================================================================
# HistoryServer
#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
#jobmanager.archive.fs.dir: hdfs:///completed-jobs/# The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0# The port under which the web-based HistoryServer listens.
#historyserver.web.port: 8082# Comma separated list of directories to monitor for completed jobs.
#historyserver.archive.fs.dir: hdfs:///completed-jobs/# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
# jobmanager debug端口
env.java.opts.jobmanager: "-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5006"
# taskmanager debug端口
env.java.opts.taskmanager: "-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005"
2.1.2.3 flink单节点启动与停止命令
/home/flink/bin/stop-cluster.sh && /home/flink/bin/start-cluster.sh
2.1.3、部署doris
2.1.3.1 下载安装包并上传服务器
官方参考文档地址
快速开始 - Apache Doris
下载地址 Download - Apache Doris
将安装包上传到/home下,解压并重命名为doris
配置
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
2.1.3.2 配置doris fe(前端)
配置文件/home/doris/fe/conf/fe.conf
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.#####################################################################
## The uppercase properties are read and exported by bin/start_fe.sh.
## To see all Frontend configurations,
## see fe/src/org/apache/doris/common/Config.java
###################################################################### the output dir of stderr and stdout
LOG_DIR = ${DORIS_HOME}/logDATE = `date +%Y%m%d-%H%M%S`
JAVA_OPTS="-Xmx8192m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$DORIS_HOME/log/fe.gc.log.$DATE"# For jdk 9+, this JAVA_OPTS will be used as default JVM options
JAVA_OPTS_FOR_JDK_9="-Xmx8192m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xlog:gc*:$DORIS_HOME/log/fe.gc.log.$DATE:time"##
## the lowercase properties are read by main program.
### INFO, WARN, ERROR, FATAL
sys_log_level = INFO# store metadata, must be created before start FE.
# Default value is ${DORIS_HOME}/doris-meta
meta_dir = ${DORIS_HOME}/doris-meta# Default dirs to put jdbc drivers,default value is ${DORIS_HOME}/jdbc_drivers
jdbc_drivers_dir = ${DORIS_HOME}/jdbc_drivershttp_port = 8030
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = true# Choose one if there are more than one ip except loopback address.
# Note that there should at most one ip match this list.
# If no ip match this rule, will choose one randomly.
# use CIDR format, e.g. 10.10.10.0/24
# Default value is empty.
priority_networks = 10.10.10.0/24# Advanced configurations
log_roll_size_mb = 1024
sys_log_dir = ${DORIS_HOME}/log
sys_log_roll_num = 10
sys_log_verbose_modules = org.apache.doris
audit_log_dir = ${DORIS_HOME}/log
audit_log_modules = slow_query, query
audit_log_roll_num = 10
meta_delay_toleration_second = 10
qe_max_connection = 1024
max_conn_per_user = 100
qe_query_timeout_second = 300
qe_slow_log_ms = 5000
2.1.3.3 启动doris fe(前端)
/home/doris/fe/bin/start_fe.sh --daemon
2.1.3.4 配置doris be(后端)
配置文件路径/home/doris/be/conf/be.conf
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.PPROF_TMPDIR="$DORIS_HOME/log/"
# if JAVA_OPTS is set, it will override the jvm opts for BE jvm.
#JAVA_OPTS="-Xmx8192m -DlogPath=$DORIS_HOME/log/udf-jdbc.log -Djava.compiler=NONE -XX::-CriticalJNINatives"# since 1.2, the JAVA_HOME need to be set to run BE process.
# JAVA_HOME=/path/to/jdk/# INFO, WARNING, ERROR, FATAL
sys_log_level = INFO# ports for admin, web, heartbeat service
be_port = 9060
webserver_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060# Choose one if there are more than one ip except loopback address.
# Note that there should at most one ip match this list.
# If no ip match this rule, will choose one randomly.
# use CIDR format, e.g. 10.10.10.0/24
# Default value is empty.
priority_networks = 10.10.10.0/24# data root path, separate by ';'
# you can specify the storage medium of each root path, HDD or SSD
# you can add capacity limit at the end of each root path, separate by ','
# eg:
# storage_root_path = /home/disk1/doris.HDD,50;/home/disk2/doris.SSD,1;/home/disk2/doris
# /home/disk1/doris.HDD, capacity limit is 50GB, HDD;
# /home/disk2/doris.SSD, capacity limit is 1GB, SSD;
# /home/disk2/doris, capacity limit is disk capacity, HDD(default)
#
# you also can specify the properties by setting '<property>:<value>', separate by ','
# property 'medium' has a higher priority than the extension of path
#
# Default value is ${DORIS_HOME}/storage, you should create it by hand.
storage_root_path = ${DORIS_HOME}/storage# Default dirs to put jdbc drivers,default value is ${DORIS_HOME}/jdbc_drivers
jdbc_drivers_dir = ${DORIS_HOME}/jdbc_drivers# Advanced configurations
# sys_log_dir = ${DORIS_HOME}/log
# sys_log_roll_mode = SIZE-MB-1024
# sys_log_roll_num = 10
# sys_log_verbose_modules = *
# log_buffer_level = -1
# palo_cgroups
2.1.3.5 doris启动 be(后端)
/home/doris/be/bin/start_be.sh --daemon
2.1.3.5 doris启动成功验证
curl http://10.10.10.99:8030/api/bootstrap
curl http://10.10.10.99:8040/api/health执行这两条命令,会输出success信息
2.1.3.6 doris的be在fe上注册
roris兼容mysql协议
因此使用mysql-client执行命令
mysql -h 10.10.10.99 -P 9030 -uroot
ALTER SYSTEM ADD BACKEND "10.10.10.99:9050";最后在重启下be和fe
2.1.3.6 通过doris的fe的Web UI页面创建数据库表
浏览器访问地址
http://10.10.10.99:8030/login
默认用户名是root,默认密码为空
创建测试数据库表
create database example_db;
CREATE TABLE IF NOT EXISTS example_db.demo
(
`destroy_date` DATETIME NOT NULL COMMENT "destroy_date",
`latitude` DECIMAL NOT NULL COMMENT "精度",
`longitude` DECIMAL NOT NULL COMMENT "纬度",
`city` VARCHAR(256) COMMENT "city"
)
DUPLICATE KEY(`destroy_date`, `latitude`, `longitude`)
DISTRIBUTED BY HASH(`city`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);CREATE TABLE IF NOT EXISTS example_db.log
(
`APP` VARCHAR(256) COMMENT "应用",
`VERSION` VARCHAR(256) COMMENT "VERSION",
`APP_PRO` VARCHAR(256) COMMENT "APP_PRO",
`APP_TYPE` VARCHAR(256) COMMENT "APP_TYPE",
`APP_IP` VARCHAR(256) COMMENT "APP_IP",
`MSG` VARCHAR(256) COMMENT "MSG",
`CONTEXT` VARCHAR(256) COMMENT "CONTEXT",
`TAG` VARCHAR(256) COMMENT "TAG",
`TIME` VARCHAR(256) COMMENT "TIME",
`VENDOR` VARCHAR(256) COMMENT "VENDOR",
`VIDEO` VARCHAR(256) COMMENT "VIDEO",
`RESULT` VARCHAR(256) COMMENT "RESULT",
`LEVEL` VARCHAR(256) COMMENT "LEVEL",
`LOG` VARCHAR(256) NOT NULL COMMENT "LOG",
`NAME` VARCHAR(256) COMMENT "NAME",
`MAC` VARCHAR(256) NOT NULL COMMENT "MAC",
`NOTE` VARCHAR(256) NOT NULL COMMENT "NOTE",
`SERVER` VARCHAR(256) NOT NULL COMMENT "SERVER",
`UUID` VARCHAR(256) NOT NULL COMMENT "UUID",
`CREATE_TIME` DATETIME NOT NULL COMMENT "CREATE_TIME"
)
DUPLICATE KEY(`APP`, `VERSION`, `APP_PRO`)
DISTRIBUTED BY HASH(`UUID`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
2.1.4、部署spring-boot的syslog-kafka-es-avro
配置kafka地址
UDP 端口
直接启动
2.1.4.1、syslog-kafka-es-avro基于netty已UDP方式监听syslog
//表示服务器连接监听线程组,专门接受 accept 新的客户端client 连接
EventLoopGroup group = new NioEventLoopGroup();
try {//1、创建netty bootstrap 启动类Bootstrap serverBootstrap = new Bootstrap();//2、设置boostrap 的eventLoopGroup线程组serverBootstrap = serverBootstrap.group(group);//3、设置NIO UDP连接通道serverBootstrap = serverBootstrap.channel(NioDatagramChannel.class);//4、设置通道参数 SO_BROADCAST广播形式serverBootstrap = serverBootstrap.option(ChannelOption.SO_BROADCAST, true);serverBootstrap = serverBootstrap.option(ChannelOption.SO_RCVBUF, 1024*1024*1000);//5、设置处理类 装配流水线serverBootstrap = serverBootstrap.handler(syslogUdpHandler);//6、绑定server,通过调用sync()方法异步阻塞,直到绑定成功ChannelFuture channelFuture = serverBootstrap.bind(port).sync();log.info("started and listened on " + channelFuture.channel().localAddress());//7、监听通道关闭事件,应用程序会一直等待,直到channel关闭channelFuture.channel().closeFuture().sync();
} catch (Exception e) {log.error("初始化异常",e);
} finally {log.warn("netty udp close!");//8 关闭EventLoopGroup,group.shutdownGracefully();
}
2.1.4.2、syslog-kafka-es-avro已avro格式保存数据到kafka
if (event == null || event.size() == 0) {if (log.isDebugEnabled()) {log.debug("解析数据为空,不执行kafka数据推送 !");}return;
}
if (switchKafkaConfiguration != null && switchKafkaConfiguration.isAvroTest()) {log.info("发送kafka前,先将数据转换成二进制,通过接口发送测试");String filePath= "D:\\conf\\kafka\\demo.avro";try {AvroProcess avroProcess = AvroProcess.builder(filePath);byte[] bytes = avroProcess.serialize(event);String url = "http://127.0.0.1:8080/bin/receive";HttpBinaryUtil.remoteInvoke(bytes,url);} catch (IOException e) {throw new RuntimeException(e);}
}
else{if (log.isDebugEnabled()) {log.debug("数据发送到kafka");}sendProcess.innerHandle(event);
}
2.1.5、部署spring-boot的flink-do-doris
压缩成flink-do-doris-jar-with-dependencies.jar
通过10.10.10.99:8081 web ui页面提交jar文件
2.1.5.1、flink-do-doris主类
import cn.hutool.core.lang.UUID;
import cn.hutool.json.JSONUtil;
import org.apache.commons.collections.MapUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.doris.flink.cfg.DorisExecutionOptions;
import org.apache.doris.flink.cfg.DorisOptions;
import org.apache.doris.flink.cfg.DorisReadOptions;
import org.apache.doris.flink.sink.DorisSink;
import org.apache.doris.flink.sink.writer.RowDataSerializer;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.flink.table.data.TimestampData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.util.Collector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.LocalDate;
import java.util.Map;
import java.util.Properties;/*** @author demo*/
public class FlinkToDorisApp {private static final Logger log = LoggerFactory.getLogger(FlinkToDorisApp.class);private static final String KAFKA_BOOTSTRAP_SERVERS = "10.10.10.99:9092";private static final String TOPIC = "demo";private static final String GROUP_ID = "syslog-process-kafka-flink-doris";private static final String KAFKA_DATASOURCE_NAME = "kafkaSource";private static final String DORIS_FE_HOST = "10.10.10.99:8030";//private static final String DORIS_DB_NAME = "example_db.demo";private static final String DORIS_DB_NAME = "example_db.log";/*** doris安装后默认的用户名是root*/private static final String DORIS_USERNAME = "root";/*** doris安装后默认的是密码是空值*/private static final String DORIS_PASSWORD = "";private static final String schema = "";private static final String[] fields = {};public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(10000);env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(1);CheckpointConfig checkpointConfig = env.getCheckpointConfig();checkpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);KafkaSource<String> kafkaSource = KafkaUtils.getKafkaSource(KAFKA_BOOTSTRAP_SERVERS, TOPIC, GROUP_ID, schema);DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), KAFKA_DATASOURCE_NAME);SingleOutputStreamOperator<RowData> jsonDS = kafkaDS.process(new ProcessFunction<String, RowData>() {@Overridepublic void processElement(String json, Context context, Collector<RowData> collector) {try {if (StringUtils.isNotBlank(json)) {Map event = JSONUtil.toBean(json, Map.class);GenericRowData eventData = mapping(event);if (eventData != null) {collector.collect(eventData);}}} catch (Exception e) {throw new RuntimeException(e);}}});DataStream<RowData> dataStream = jsonDS.forward();dataStream.print();DorisSink.Builder<RowData> builder = DorisSink.builder();DorisOptions.Builder dorisBuilder = DorisOptions.builder();dorisBuilder.setFenodes(DORIS_FE_HOST).setTableIdentifier(DORIS_DB_NAME).setUsername(DORIS_USERNAME).setPassword(DORIS_PASSWORD);Properties properties = new Properties();properties.setProperty("format", "json");properties.setProperty("read_json_by_line", "true");DorisExecutionOptions.Builder executionBuilder = DorisExecutionOptions.builder();executionBuilder.setLabelPrefix("label-doris" + UUID.fastUUID()).setStreamLoadProp(properties);DataType[] types = {DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.TIMESTAMP()};builder.setDorisReadOptions(DorisReadOptions.builder().build()).setDorisExecutionOptions(executionBuilder.build()).setSerializer(RowDataSerializer.builder().setFieldNames(fields).setType("json").setFieldType(types).build()).setDorisOptions(dorisBuilder.build());boolean test = false;if (test) {DataStream<RowData> source = env.fromElements("").map((MapFunction<String, RowData>) value -> {GenericRowData genericRowData = new GenericRowData(4);genericRowData.setField(0, StringData.fromString("beijing"));genericRowData.setField(1, 116.405419);genericRowData.setField(2, 39.916927);genericRowData.setField(3, new Long(LocalDate.now().toEpochDay()).intValue());return genericRowData;});source.sinkTo(builder.build());}dataStream.sinkTo(builder.build());log.info("doris安装后默认的用户名是root,doris安装后默认的密码是空值");env.execute();}private static final int TWO_PER_SECOND = 2;private static GenericRowData mapping(Map event) {GenericRowData genericRowData = new GenericRowData(fields.length);for (int i = 0; i < fields.length - TWO_PER_SECOND; i++) {genericRowData.setField(i, StringData.fromString(MapUtils.getString(event, fields[i], "")));}genericRowData.setField(23, StringData.fromString(UUID.randomUUID().toString()));genericRowData.setField(24, TimestampData.fromEpochMillis(System.currentTimeMillis()));return genericRowData;}
}
三、效果验证
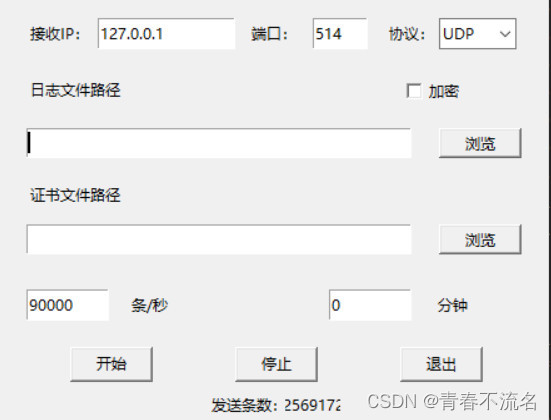
3.1、发送syslog日志,syslog-kafka-es-avro监听处理,存储到kafka
3.2 、查看flink消费kafka

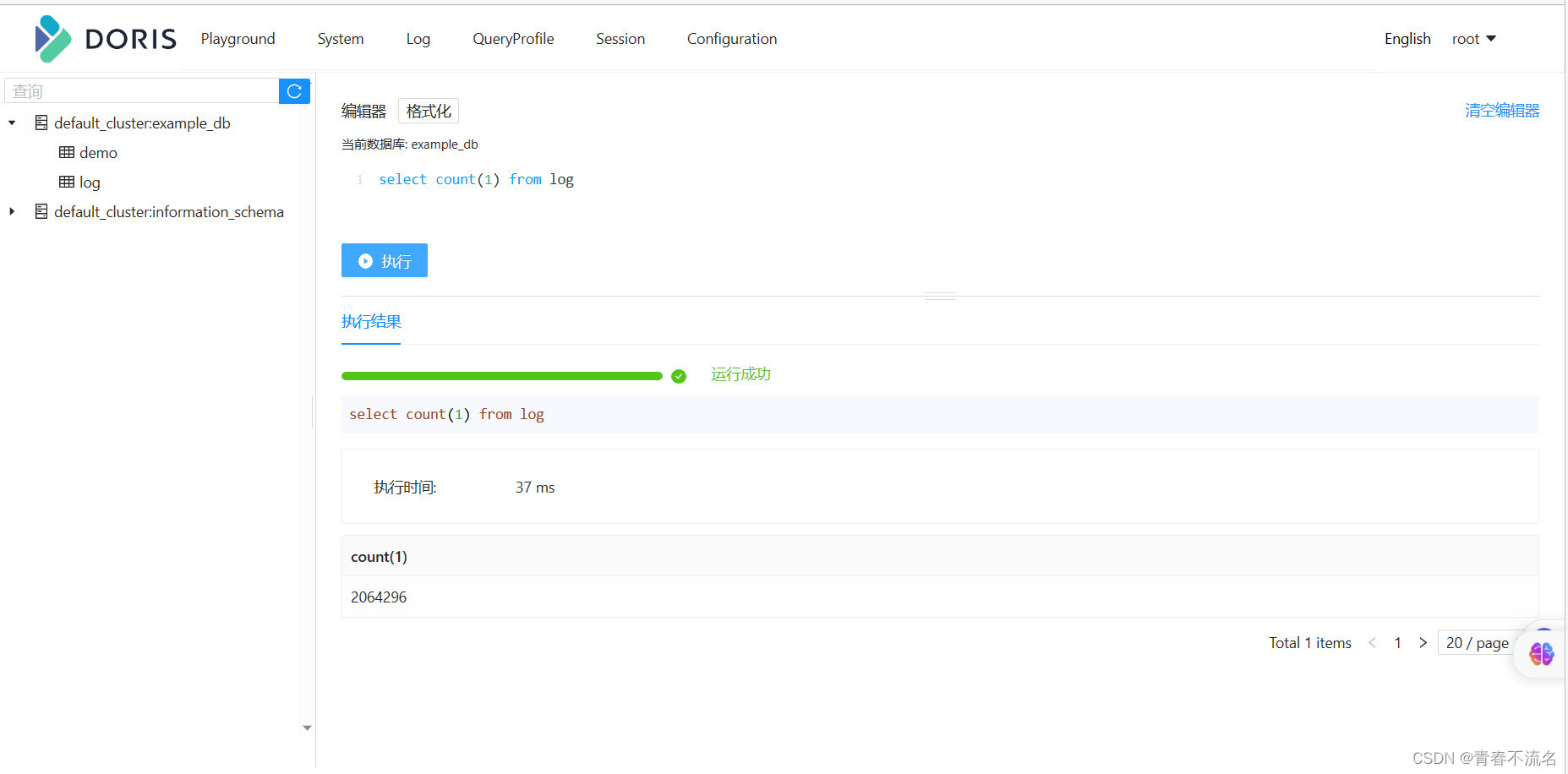
3.3、 在doris上查看入库详情
相关文章:
flink+kafka+doris+springboot集成例子
目录 一、例子说明 1.1、概述 1.1、所需环境 1.2、执行流程 二、部署环境 2.1、中间件部署 2.1.1部署kakfa 2.1.1.1 上传解压kafka安装包 2.1.1.2 修改zookeeper.properties 2.1.1.3 修改server.properties 2.1.1.3 启动kafka 2.1.2、部署flink 2.1.2.1 上传解压f…...
)
ARM裸机-14(S5PV210的时钟系统)
1、时钟系统 1.1、什么是时钟 时钟是同步工作系统的同步节拍 1.2、SoC为什么需要时钟 Soc内部有很多器件,例如CPU、串口、DRAM控制制器、GPIO等内部外设,这些东西要彼此协同工作,需要一个同步的时钟系统来指挥。这个就是我们SoC的时钟系统。…...

Milvus Cloud凭借AI原生,可视化优势荣登全球向量数据库性能排行榜VectorDBBench.com 榜首
在当今的大数据时代,随着人工智能技术的快速发展,向量数据库作为处理大规模数据的关键工具,其性能和效率越来越受到关注。最近,全球向量数据库性能排行榜 VectorDBBench.com 公布了一份最新的评估报告,引人瞩目的是,成立不到一年的新兴公司 Milvus Cloud 凭借其 AI 原生和…...
测试岗?从功能测试进阶自动化测试开发,测试之路不迷茫...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 测试新人在想什么…...
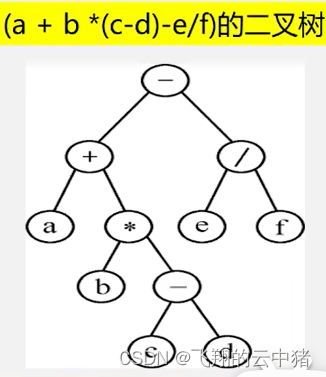
算法与数据结构(五)--树【1】树与二叉树是什么
一.树的定义 树是一个具有层次结构的集合,是由一个有限集和集合上定义的一种层次结构关系构成的。不同于线性表,树并不是线性的,而是有分支的。 树(Tree)是n(n>0)个结点的有限集。 若n0&…...
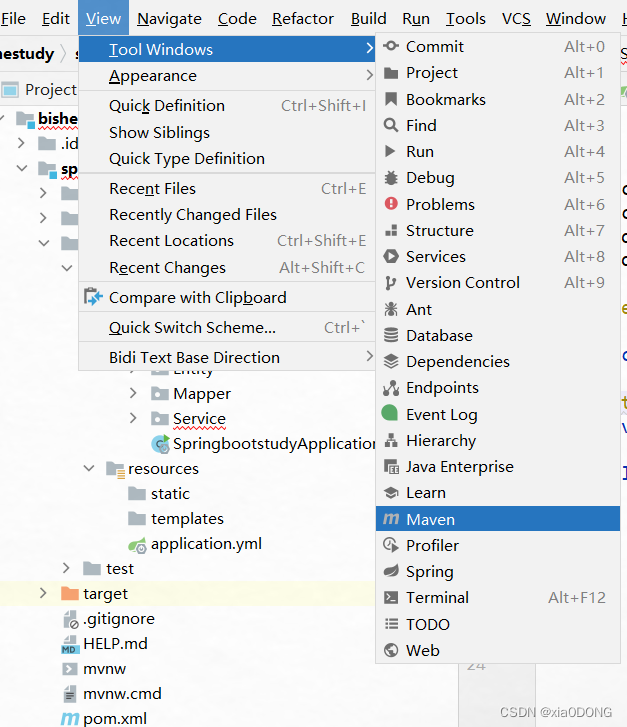
打开的idea项目maven不生效
方法一:CtrlshiftA(或者help---->find action), 输入maven, 点击add maven projects,选择本项目中的pom.xml配置文件,等待加载........ 方法二:view->tools windows->mave…...
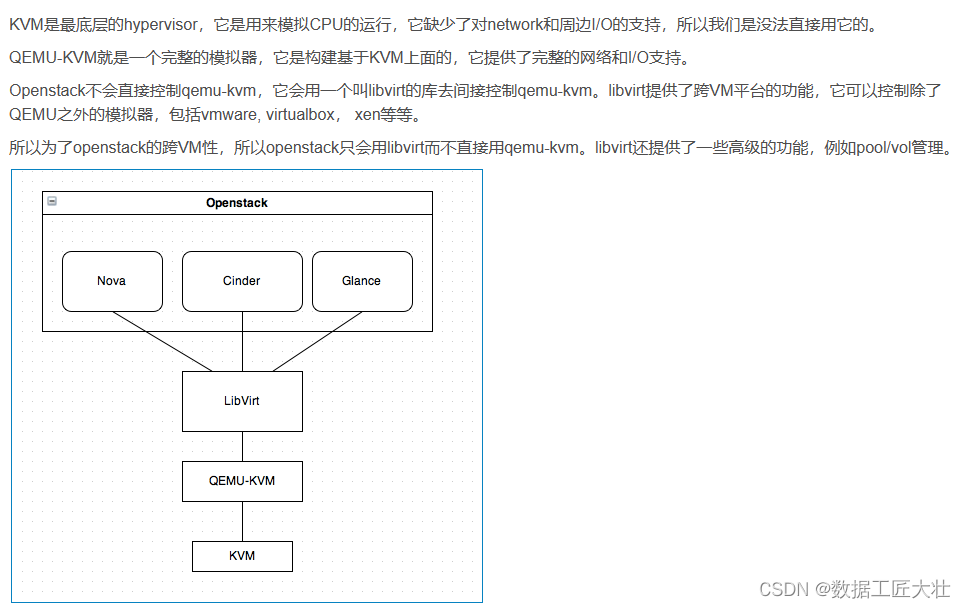
kvm+qemu+libvirt管理虚机
virt-manager 图形化创建虚拟机 #virt-manager纳管远程kvm虚拟机 # 可以指定kvm虚机的ssh端口和virt-manager所在主机的私钥 virt-manager -c qemussh://root10.197.115.17:5555/system?keyfileid_rsa --no-fork # 如果你生成的ssh-key 的名称是 test-key,在/home/ssh-key/ 目…...

电气防火限流式保护器在汽车充电桩使用上的作用
【摘要】 随着电动汽车行业的不断发展,电动汽车充电设施的使用会变得越来越频繁和广泛。根据中汽协数据显示,2022年上半年,我国新能源汽车产销分别完成266.1万辆和260万辆,同比均增长1.2倍,市场渗透率达21.6%。因此,电动汽车的安全…...

VBA技术资料MF38:VBA_在Excel中隐藏公式
【分享成果,随喜正能量】佛祖也无能为力的四件事:第一,因果不可改,自因自果,别人是代替不了的;第二,智慧不可赐,任何人要开智慧,离不开自身的磨练;第三&#…...

Gson:解析JSON为复杂对象:TypeToken
需求 通过Gson,将JSON字符串,解析为复杂类型。 比如,解析成如下类型: Map<String, List<Bean>> 依赖(Gson) <dependency><groupId>com.google.code.gson</groupId><art…...

伪彩色处理及算法
伪色彩(false color)是指将真实世界的中无法被肉眼观察到的色彩通过计算机或其他技术转换为可见光,从而使人们能够看到这些原本无法看到的色彩。这种技术被广泛应用于军事、医学、科研等领域。 在医学领域,伪色彩技术被用于医学影像诊断。例如,通过将不同灰度的图像映射到…...
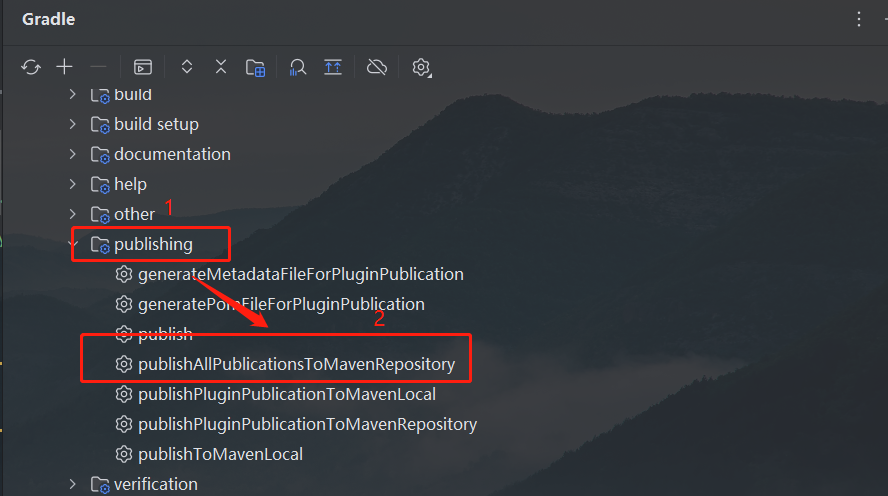
Gradle-02:问题Plugin with id ‘maven‘ not found
1. 背景 在一次使用 Gradle 构建自己项目,完事,需要上传到本地 Maven 仓库,因为事先并不清楚 apply plugin: maven 插件已经被 Gradle 移除,找了一圈,才找到解决方案。 2. 原因 apply plugin: maven def localRepo f…...
jupyter lab环境配置
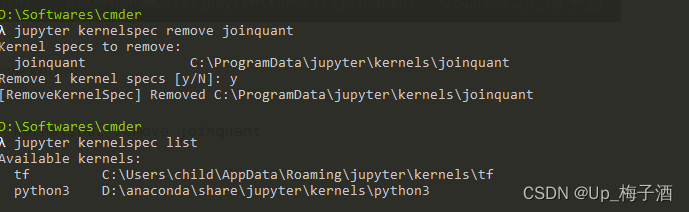
1.jupyterlab 使用虚拟环境 conda install ipykernelpython -m ipykernel install --user --name tf --display-name "tf" #例:环境名称tf2. jupyter lab kernel管理 show kernel list jupyter kernelspec listremove kernel jupyter kernelspec re…...

Unity Sort Group(排序组)
** Unity 中的Sort Group组组件允许让Sprite Renderer(精灵渲染器)重新决定渲染顺序. ** 作为组件存在 组件内容: Unity 使用Sort Group 组件的Sort layer 和Order in layer的值来确定排序组在渲染队列内相对与场景内其他排序组和游戏对象的优先级。 属性功能So…...
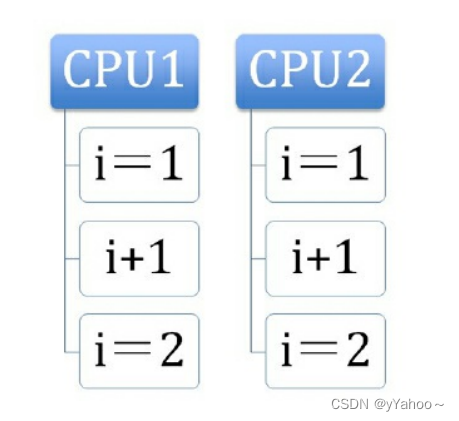
基于总线加锁和缓存锁(CPU实现原子操作的两种方式)
总线锁 总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。 CPU和内存之间的通信被锁!! 如果多个处理器同时对共享变量进行读写…...

MybatisPlus存在 sql 注入漏洞(CVE-2023-25330)解决办法
首先我们了解下这个漏洞是什么? MyBatis-Plus TenantPlugin 是 MyBatis-Plus 的一个为多租户场景而设计的插件,可以在 SQL 中自动添加租户 ID 来实现数据隔离功能。 MyBatis-Plus TenantPlugin 3.5.3.1及之前版本由于 TenantHandler#getTenantId 方法在…...

【java】使用maven完成一个servlet项目
一、创建项目 创建一个maven项目 maven是一个管理java项目的工具,根据maven的pom.xml可以引入各种依赖,插件。 步骤 打开idea,点击新建项目 点击创建项目,项目创建就完成了 进入时会自动打开pom.xml文件。 pom是项目的配置文件…...

前端Vue入门-day07-Vuex入门
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 自定义创建项目 vuex概述 构建 vuex [多组件数据共享] 环境 创建一个空仓库 state 状态 1. 提供数据&…...
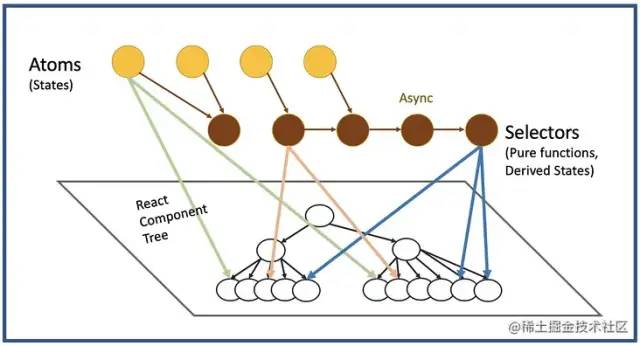
2023再谈前端状态管理
目录 什么是状态管理? 状态 常见模式 要解决的问题 心智模型 React Context Context 的问题 优点 缺点 React 外部状态管理库 概览 Class 时代 Redux 单向数据流 三大原则 如何处理异步 如何处理数据间联动 优点 缺点 Dva icestore Mobx 设…...

ffmpeg SDL播放器--播放udp组播流
c调用ffmpeg api及SDL库播放播放udp组播流。 代码及工程见https://download.csdn.net/download/daqinzl/88168574 参考文档:https://blog.csdn.net/a53818742/article/details/109312740 开发工具:visual studio 2019 记得推送udp流,可采…...

解析日本工程塑料厂家代理新日铁住金产品的核心价值与
在众多日本工程塑料供应商中,新日铁住金凭借其在特种工程塑料领域的技术积累和稳定品质,成为众多制造企业的优选合作伙伴。对于寻求高性价比、稳定供应的塑胶制品厂、精密注塑厂及汽车零部件厂商而言,选择专业代理商是平衡品质与成本的关键。…...

STAR-CCM+物理场实战:用‘伴随求解器’优化无人机气动,附完整仿真流程文件
STAR-CCM物理场实战:用‘伴随求解器’优化无人机气动,附完整仿真流程文件 无人机气动外形优化一直是工程仿真领域的难点与热点。传统方法依赖人工试错与经验调整,效率低下且难以找到全局最优解。本文将深入解析如何利用STAR-CCM的伴随求解器技…...

MySQL新手必看:Navicat导入SQL文件报错1046?三步搞定数据库选择问题
MySQL图形化工具避坑指南:彻底解决1046报错与数据库选择问题 刚接触MySQL的开发者,十有八九会在第一次导入SQL文件时遇到那个令人困惑的弹窗——"Error Code: 1046. No database selected"。这个看似简单的提示背后,其实隐藏着MySQ…...

Redis——string类型相关指令
添加键值对SET [key] [value] [EX seconds|PX milliseconds] [NX|XX] //添加一个键值对SETNX [key] [value] //setNX的组合命令,不支持EX/PX选项SETEX [key] [value] //setEX的组合命令,不支持NX/XX选项PSETEX [key] [value] //setPX的组合命令ÿ…...

读研读博,教你3招搞定文献调研
今天就和大家分享几个我踩坑后总结的高效科研技巧,以及一款能帮你省出大半时间的实用工具——MedPeer的Deep Search。相信每个做科研的人都有过类似的经历:为了找一篇相关文献,翻遍了知网、Web of Science,结果翻了几十页还是找不…...
)
告别FPN信息瓶颈:手把手图解Gold-YOLO的‘聚合-分发’机制(附代码逐行解读)
告别FPN信息瓶颈:手把手图解Gold-YOLO的‘聚合-分发’机制(附代码逐行解读) 在目标检测领域,YOLO系列模型凭借其出色的实时性能一直占据主导地位。然而,随着应用场景的复杂化,传统特征金字塔网络ÿ…...

从伯德图到阶跃响应:手把手教你用Matlab分析控制系统该不该校正
从伯德图到阶跃响应:手把手教你用Matlab分析控制系统该不该校正 控制系统就像一台精密的仪器,而伯德图、根轨迹和阶跃响应则是它的"体检报告"。当你拿到一个系统模型时,如何像医生解读化验单一样,准确判断它是否需要&qu…...

极为罕见!35米宽小行星近距离掠过地球
【环球时报特约记者 陈山】据美国全国广播公司(NBC)网站19日报道,一颗直径约50到115英尺(1英尺约合0.3米)的小行星于18日近距离飞掠地球,成为近年来非常罕见的一幕。小行星从地球附近掠过的概念图。欧洲航天…...

Faster-Whisper-GUI:高效本地语音识别与字幕生成终极指南
Faster-Whisper-GUI:高效本地语音识别与字幕生成终极指南 【免费下载链接】faster-whisper-GUI faster_whisper GUI with PySide6 项目地址: https://gitcode.com/gh_mirrors/fa/faster-whisper-GUI 在人工智能语音技术快速发展的今天,本地化语音…...

OmenSuperHub终极指南:3步解锁暗影精灵完整性能潜力
OmenSuperHub终极指南:3步解锁暗影精灵完整性能潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 想要彻底掌控惠普暗影精灵笔记本的性能吗&…...