机器学习06 数据准备-(利用 scikit-learn基于Pima Indian数据集作 数据特征选定)
什么是数据特征选定?
数据特征选定(Feature Selection)是指从原始数据中选择最相关、最有用的特征,用于构建机器学习模型。特征选定是机器学习流程中非常重要的一步,它直接影响模型的性能和泛化能力。通过选择最重要的特征,可以减少模型的复杂性,降低过拟合的风险,并提高模型的训练和预测效率。
特征选定的过程可以采用以下一些常见的方法:
-
相关性分析:通过计算特征与目标变量之间的相关性,选择与目标变量高度相关的特征。可以使用相关系数、互信息等指标进行相关性分析。
-
特征重要性评估:对于一些机器学习模型(如决策树、随机森林、梯度提升树等),可以通过模型训练过程中特征的重要性评估来选择重要的特征。
-
方差选择:选择方差大于某个阈值的特征,过滤掉方差较小的特征,认为方差较小的特征对目标变量的影响较小。
-
正则化方法:使用正则化方法(如L1正则化、L2正则化)进行特征选择,通过加入正则化项来惩罚特征的权重,从而使得部分特征的权重变为零,实现特征选择。
-
基于模型的特征选择:使用某些机器学习模型(如递归特征消除、稳定性选择等)来评估特征的重要性,并选择最重要的特征。
-
基于特征工程的选择:通过领域知识和数据理解来选择最相关的特征,例如选择与问题背景相关的特征、选择对目标变量具有影响的特征等。
特征选定需要结合具体的数据和任务来进行,没有一种通用的方法适用于所有情况。选择合适的特征是一个迭代的过程,通常需要尝试不同的方法和参数来找到最佳的特征子集。重要的是要保持合理的特征维度,确保所选特征能够充分表达数据的信息,并且对于给定的机器学习任务是有效的。
在做数据挖掘和数据分析时,数据是所有问题的基础,并且会影响整个项目的进程。相较于使用一些复杂的算法,灵活地处理数据经常会取到意想不到的效果。
而处理数据不可避免地会使用到特征工程。那么特征工程是什么呢?有这么一句话在业界广为流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
因此,特征过程的本质就是一项工程活动,目的是最大限度地从原始数据中提取合适的特征,以供算法和模型使用。特征处理是特征工程的核心部分,scikit-learn 提供了较为完整的特征处理方法,包括数据预处理、特征选择、降维等。
通过 scikit-learn来自动选择用于建立机器学习模型的数据特征的方法。接下来将会介绍以下四个数据特征选择的方法:
· 单变量特征选定。
· 递归特征消除。
· 主要成分分析。
· 特征的重要性。
特征选定
特征选定是一个流程,能够选择有助于提高预测结果准确度的特征数据,或者有助于发现我们感兴趣的输出结果的特征数据。如果数据中包含无关的特征属性,会降低算法的准确度,对预测新数据造成干扰,尤其是线性相关算法(如线性回归算法和逻辑回归算法)。
因此,在开始建立模型之前,执行特征选定有助于:
- 降低数据的拟合度:较少的冗余数据,会使算法得出结论的机会更大。
- 提高算法精度:较少的误导数据,能够提高算法的准确度。
- 减少训练时间:越少的数据,训练模型所需要的时间越少。
可以在 scikit-learn 的特征选定文档中查看更多的信息(http://scikitlearn.org/stable/modules/feature_selection.html)。下面我们会继续使用PimaIndians的数据集来进行演示。
代码如下:
import pandas as pd
from numpy import set_printoptions
from sklearn.feature_selection import chi2, SelectKBest#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)
#将数据转成数组
array = data.values
#分割数据
X = array[:, 0:8]
Y=array[:,8]#选择K个最好的特征,返回选择特征后的数据
test = SelectKBest(score_func=chi2, k=4)
#fit()方法,计算X中各个特征的相关性
fit = test.fit(X, Y)
#设置数据打印格式
set_printoptions(precision=3)print(fit.scores_)
#得分越高,特征越重要
features = fit.transform(X)
#显示特征
print(features)执行结束后,我们得到了卡方检验对每一个数据特征的评分,以及得
分最高的四个数据特征。执行结果如下:
[ 111.52 1411.887 17.605 53.108 2175.565 127.669 5.393 181.304]
[[148. 0. 33.6 50. ][ 85. 0. 26.6 31. ][183. 0. 23.3 32. ]...[121. 112. 26.2 30. ][126. 0. 30.1 47. ][ 93. 0. 30.4 23. ]]从这组数据中我们可以分析出得分最高 的分别是血糖,胰岛素含量,身体质量指数(BMI),年龄
通过设置SelectKBest的score_func参数,SelectKBest不仅可以执行卡方检验来选择数据特征,还可以通过相关系数、互信息法等统计方法来选定数据特征
递归特征消除
递归特征消除(RFE)使用一个基模型来进行多轮训练,每轮训练后消除若干权值系数的特征,再基于新的特征集进行下一轮训练。通过每一个基模型的精度,找到对最终的预测结果影响最大的数据特征。
在 scikitlearn 文档中有更多的关于递归特征消除(RFE)的描述。下面的例子是以逻辑回归算法为基模型,通过递归特征消除来选定对预测结果影响最大的三个数据特征。
代码如下:
import pandas as pd
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#打印标签名称
print(data.columns)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]
#特征选择
model = LogisticRegression()
#递归特征消除法,返回特征选择后的数据
rfe = RFE(model)
#拟合数据
fit = rfe.fit(X, Y)print("特征个数:", fit.n_features_)
print("被选特征:", fit.support_)print("特征排名:", fit.ranking_)运行结果:
特征个数: 4
被选特征: [ True True False False False True True False]
特征排名: [1 1 3 4 5 1 1 2]
主要成分分析
主要成分分析(PCA)是使用线性代数来转换压缩数据,通常被称作数据降维。
常见的降维方法除了主要成分分析(PCA),还有线性判别分析(LDA),它本身也是一个分类模型。PCA 和 LDA 有很多的相似之处,其本质是将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而 LDA 是为了让映射后的样本有最好的分类性能。
所以说,PCA 是一种无监督的降维方法,而LDA是一种有监督的降维方法。在聚类算法中,通常会利用PCA对数据进行降维处理,以利于对数据的简化分析和可视化。
详细内容请参考 scikit-learn的API文档。代码如下:
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#打印标签名称
print(data.columns)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]pca = PCA(n_components=4)fit = pca.fit(X)print("方差:", fit.explained_variance_ratio_)print(fit.components_)方差: [0.88854663 0.06159078 0.02579012 0.01308614]
[[-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03][-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01][-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01][-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01]]没感觉,看不懂这个结果数据是怎么去进行分析的,先知道有这么个东西,后面再来补充
特征重要性
袋装决策树算法(Bagged Decision Tress)、随机森林算法和极端随机 树算法都可以用来计算数据特征的重要性。
这三个算法都是集成算法中的袋装算法,在后面的集成算法章节会有详细的介绍。下面给出一个使用ExtraTreesClassifier类进行特征的重要性计算的例子。
代码如下:
import pandas as pdfrom sklearn.ensemble import ExtraTreesClassifier#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#打印标签名称
print(data.columns[0:8])#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]model = ExtraTreesClassifier()fit = model.fit(X, Y)print(fit.feature_importances_)
运行结果:
Index(['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin','BMI', 'DiabetesPedigreeFunction', 'Age'],dtype='object')
[0.10886677 0.22739778 0.10066603 0.07878746 0.07515111 0.146191220.11598885 0.14695078]
执行后,我们可以看见算法给出了每一个数据特征的得分,从得分中我们可以分析 得分高的也是跟前面特征 血糖,BMI,年龄等
相关文章:
)
机器学习06 数据准备-(利用 scikit-learn基于Pima Indian数据集作 数据特征选定)
什么是数据特征选定? 数据特征选定(Feature Selection)是指从原始数据中选择最相关、最有用的特征,用于构建机器学习模型。特征选定是机器学习流程中非常重要的一步,它直接影响模型的性能和泛化能力。通过选择最重要的特征&#…...
机器学习-特征选择:如何使用Lassco回归精确选择最佳特征?
一、引言 特征选择在机器学习领域中扮演着至关重要的角色,它能够从原始数据中选择最具信息量的特征,提高模型性能、减少过拟合,并加快模型训练和预测的速度。在大规模数据集和高维数据中,特征选择尤为重要,因为不必要的…...
SpringBoot之Actuator基本使用
SpringBoot之Actuator基本使用 引入分类常用接口含义healthbeansconditionsheapdumpmappingsthreaddumploggersmetrics 引入 <!-- actuator start--> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter…...
)
排序算法(一)
1.冒泡排序-Bubble Sort 1.算法原理 依次比较相邻的两个元素,若按照从小到大的顺序,则将相邻元素中较大的一个放在后面;然后对每一对相邻元素都做这种比较,序列的最后一个元素就是最大的数; 2.算法复杂度 时间复杂度…...

Centos虚拟机忘记密码-修改密码
1.重启系统 2.在这个选择界面,按e建 3.找到如下位置,插入init/bin/sh 4.填写完成后按Ctrlx引导启动 5.输入mount -o remount, rw / (注意空格) 6.重置密码 出现以下为重置成功 7.执行touch /.autorelabel 8.退出exec /sbin/init 9.输入你的新密…...

Shell 分析服务器日志常用命令
1、查看有多少个IP访问: 日志文件的第一列是IP地址 awk {print $1} log_file|sort|uniq|wc -l2、查看某一个页面被访问的次数: grep "/index.php" log_file | wc -l3、查看每一个IP访问了多少个页面: awk {S[$1]} END {for (a i…...

mysql8配置binlog日志skip-log-bin,开启、关闭binlog,清理binlog日志文件
1.概要说明 binlog 就是binary log,二进制日志文件,这个文件记录了MySQL所有的DML操作。通过binlog日志我们可以做数据恢复,增量备份,主主复制和主从复制等等。对于开发者可能对binlog并不怎么关注,但是对于运维或者架…...

机器学习:训练集与测试集分割train_test_split
1 引言 在使用机器学习训练模型算法的过程中,为提高模型的泛化能力、防止过拟合等目的,需要将整体数据划分为训练集和测试集两部分,训练集用于模型训练,测试集用于模型的验证。此时,使用train_test_split函数可便捷高…...
简单介绍淘宝API功能接口作用)
淘宝API开发(一)简单介绍淘宝API功能接口作用
前一阵子按照上级指示,根据淘宝API开发符合自已应用的系统,比如批量上传,批量修改名称,价格等功能什么的,在此就将我的开发历程写一写,为自己前段时间的工作做个总结。 淘宝开发平台(淘宝网 - 淘ÿ…...

Redis相关面试题
Redis的使用场景 根据自己简历上的业务进行回答 缓存 穿透、击穿、雪崩、双写一致、持久化、数据过期、淘汰策略 分布式锁 setnx redisson 缓存穿透:查询一个不存在的数据,数据库查不到数据也不会直接写入缓存,就会导致每次请求都查询数据库…...

数据库简介
1、数据库安装: rpm (redhat package manager) 也是个包管理工具: rpm -ivh 安装 rpm -e 表示卸载,卸载的时候有可能出现依赖的问题,可以用 --nodeps 忽略依赖卸载。 rpm -qa 搜索系统中安装的rpm的应用。 如果使用离线包,安装顺序不要乱。 m…...

腾讯云国际轻量应用服务器怎么使用呢?
腾讯云国际轻量应用服务器怎么使用呢?下面一起来了解一下: 1. 熟悉轻量应用服务器基础知识 ①什么是轻量应用服务器 TencentCloud Lighthouse? ②轻量应用服务器与云服务器 CVM 的区别是什么? ③为什么选择轻量应用服务器…...

arm环境cloudstack在vpc下创建虚拟机失败
一、环境说明 操作系统:openEuler 22.03CPU:Kunpeng-920,arm v8cloudstack:4.18libvirtd:6.2.0 二、问题描述 在UI上创建VPC后,平台会同时创建一个virtual router,此时virtual router有两个网…...
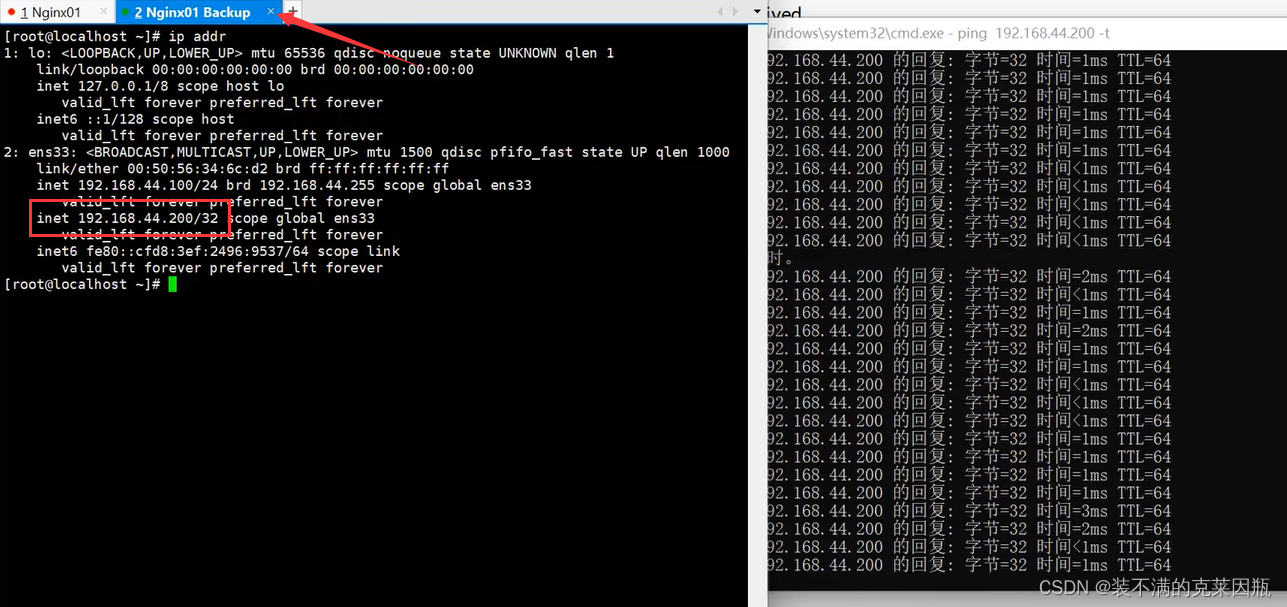
Linux上安装Keepalived,多台Nginx配置Keepalived(保姆级教程)
目录 一、yum安装 第一步:下载 第二步:编辑Keepalived配置文件(第一台) 第三步:编辑Keepalived配置文件(第二台) 第四步:我们在本机利用cmd ping一下 一、yum安装 第一步&…...

centos7 ‘xxx‘ is not in the sudoers file...
如题 执行命令输入密码后时报错: [sudo] password for admin (我的账户)原因,当前用户还没有加入到root的配置文件中。 解决 vim打开配置文件,如下: #切换到root用户 su #编辑配置文件 vim /etc/sudoe…...

Zebec Payroll :计划推出 WageLink On-Demand Pay,进军薪酬发放领域
“Zebec Protocol 生态旨以 Web3 的方式建立全新的公平秩序,基于其流支付体系构建的薪酬支付板块,就是解决问题的一把利刃”...

【2023】字节跳动 10 日心动计划——第三关
目录 1. 最长有效括号2. 有序数组的平方 1. 最长有效括号 🔗 原题链接:32. 最长有效括号 类似于有效的括号,考虑用栈来解决。 具体来讲,我们始终保持栈底元素为当前已经遍历过的元素中「最后一个没有被匹配的右括号的下标」&…...
【无网络】win10更新后无法联网,有线无线都无法连接,且打开网络与Internet闪退
win10更新后无法联网,有线无线都无法连接,且打开网络与Internet闪退 法1 重新配置网络法2 更新驱动法3 修改注册表编辑器法4 重装系统 自从昨晚点了更新与重启后,今天电脑就再也不听话了,变着花样地连不上网。 检查路由器…...

HTML <script> 标签
实例 在 HTML 页面中插入一段 JavaScript: <script type="text/javascript"> document.write("Hello World!") </script>(在本页底部可以找到更多实例) 定义和用法 <script> 标签用于定义客户端脚本,比如 JavaScript。 script …...

FPGA----UltraScale+系列的PS侧与PL侧通过AXI-HP交互(全网唯一最详)附带AXI4协议校验IP使用方法
1、之前写过一篇关于ZYNQ系列通用的PS侧与PL侧通过AXI-HP通道的文档,下面是链接。 FPGA----ZCU106基于axi-hp通道的pl与ps数据交互(全网唯一最详)_zcu106调试_发光的沙子的博客-CSDN博客大家好,今天给大家带来的内容是࿰…...

CANN-MoE模型推理加速实战
MoE 模型推理加速实战:从入门到生产 MoE(Mixture of Experts)模型是当前大模型的主流架构,但它有个问题:8 个专家只激活 2 个,怎么让昇腾跑得更快?本文手把手教你。 一、前情提要:1 …...

FPGA资源吃紧?看Artix7-35T如何“精打细算”实现MIPI视频解码与HDMI输出
Artix7-35T极限优化:在资源受限FPGA上实现MIPI-HDMI全流程处理 当医疗内窥镜或工业检测设备需要嵌入式图像处理时,工程师们常常面临一个残酷的现实:既要实现复杂的MIPI视频处理流水线,又不得不使用Artix7-35T这类入门级FPGA。这颗…...

手语数字人技术详解:3D 动画生成、动作自然度优化与实时渲染工程实践
一、前言:手语数字人是 AI 手语翻译的 “最后一公里”在国家信息无障碍政策推动下,AI 手语翻译已从技术实验走向大规模落地。但手语不是文字替换,而是身体动作、手部姿态、面部表情、口型同步的综合表达。传统手语生成普遍存在三大问题&#…...

Perplexity计算原理与业务落地脱节?——资深算法架构师亲授7步校准法,避免模型上线翻车
更多请点击: https://codechina.net 第一章:Perplexity的本质定义与数学直觉 Perplexity(困惑度)是衡量概率模型对未知序列预测能力的核心指标,其本质是交叉熵的指数形式,直观反映了模型在面对真实数据时的…...

用Python实战脑电分析:手把手教你计算PLV、MVL、MI跨频耦合指标
Python脑电分析实战:PLV、MVL、MI跨频耦合指标全流程解析 神经振荡的跨频耦合(Cross-Frequency Coupling, CFC)分析正在成为探索大脑信息处理机制的重要工具。想象一下,当你面对一组EEG数据时,如何从复杂的波形中提取出…...

小白程序员必看:收藏这份AI大模型学习指南,抢占高薪新赛道!
文章指出,随着AI技术的飞速发展,传统后端开发面临挑战,而懂AI的复合型人才成为稀缺资源。学校教育与企业需求存在错位,导致大学生毕业时所学与企业所需不符。AI智能应用开发、大模型开发等方向成为高薪热门领域,懂AI的…...

GEE实战:Landsat 8 TOA和SR数据去云处理,保姆级代码对比与避坑指南
GEE实战:Landsat 8 TOA与SR数据去云处理深度解析 当你在Google Earth Engine(GEE)平台上处理Landsat 8数据时,是否曾为选择TOA(大气层顶反射率)还是SR(地表反射率)而犹豫不决&#x…...
)
别再手动画路牙了!用SpeedRoad插件5分钟搞定3DMax城市道路建模(含十字路口避坑指南)
3DMax城市道路建模革命:SpeedRoad插件高效工作流全解析 从手动建模到智能生成的效率跃迁 在建筑可视化、游戏场景搭建和城市规划项目中,道路建模往往是耗时又枯燥的环节。传统手动建模方式需要逐个创建路面、路牙、人行道和交通标线,不仅效率…...

别再死记硬背了!一张图搞懂BST、AVL、红黑树的区别与选型
可视化解析:三大树结构的核心差异与工程实践指南 每次面对技术面试中"为什么Java的TreeMap用红黑树而不用AVL树"这类问题时,你是否会感到一阵心虚?作为曾在多个分布式系统中亲手实现过树结构的工程师,我深刻理解这种困…...

Spring Cloud Sleuth 响应式编程支持:WebFlux 与 Reactor 追踪实践
Spring Cloud Sleuth 响应式编程支持:WebFlux 与 Reactor 追踪实践 【免费下载链接】spring-cloud-sleuth Distributed tracing for spring cloud 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-sleuth Spring Cloud Sleuth 是 Spring Cloud 生…...