Python3 处理PDF之PyMuPDF 入门
PyMuPDF 简介
PyMuPDF是一个用于处理PDF文件的Python库,它提供了丰富的功能来操作、分析和转换PDF文档。这个库的设计目标是提供一个简单易用的API,使得开发者能够轻松地在Python程序中实现PDF文件的各种操作。
PyMuPDF的主要特点如下:
- 跨平台兼容性:PyMuPDF支持多种操作系统,如Windows、macOS和Linux,可以在这些平台上运行Python程序。
- 强大的PDF处理能力:PyMuPDF提供了丰富的功能来操作PDF文件,如读取、写入、分割、合并、旋转、裁剪等。此外,它还支持加密和解密PDF文档,以及提取文本、图像和元数据等信息。
- 易于使用:PyMuPDF的API设计简洁明了,易于学习和使用。开发者可以通过简单的函数调用来实现各种PDF操作,而无需深入了解底层细节。
PyMuPDF 安装及其依赖第三方框架
pip 安装 PyMuPDF 模块
pip install pymupdf验证pymupdf 模块是否安装成功
import fitz
import PIL# 打印pymupdf模块:基本信息
from fitz import TextPageprint(fitz.__doc__)PyMuPDF 1.22.5: Python bindings for the MuPDF 1.22.2 library.
Version date: 2023-06-21 00:00:01.
Built for Python 3.10 on win32 (64-bit).PyMuPDF 依赖第三方框架
当使用Pixmap.pil_save()和 Pixmap.pil_tobytes() 需要 Pillow模块
当使用Document.subset_fonts()时需要 FontTools模块
PyMuPDF 核心类
在PyMuPDF 核心类演示涉及类
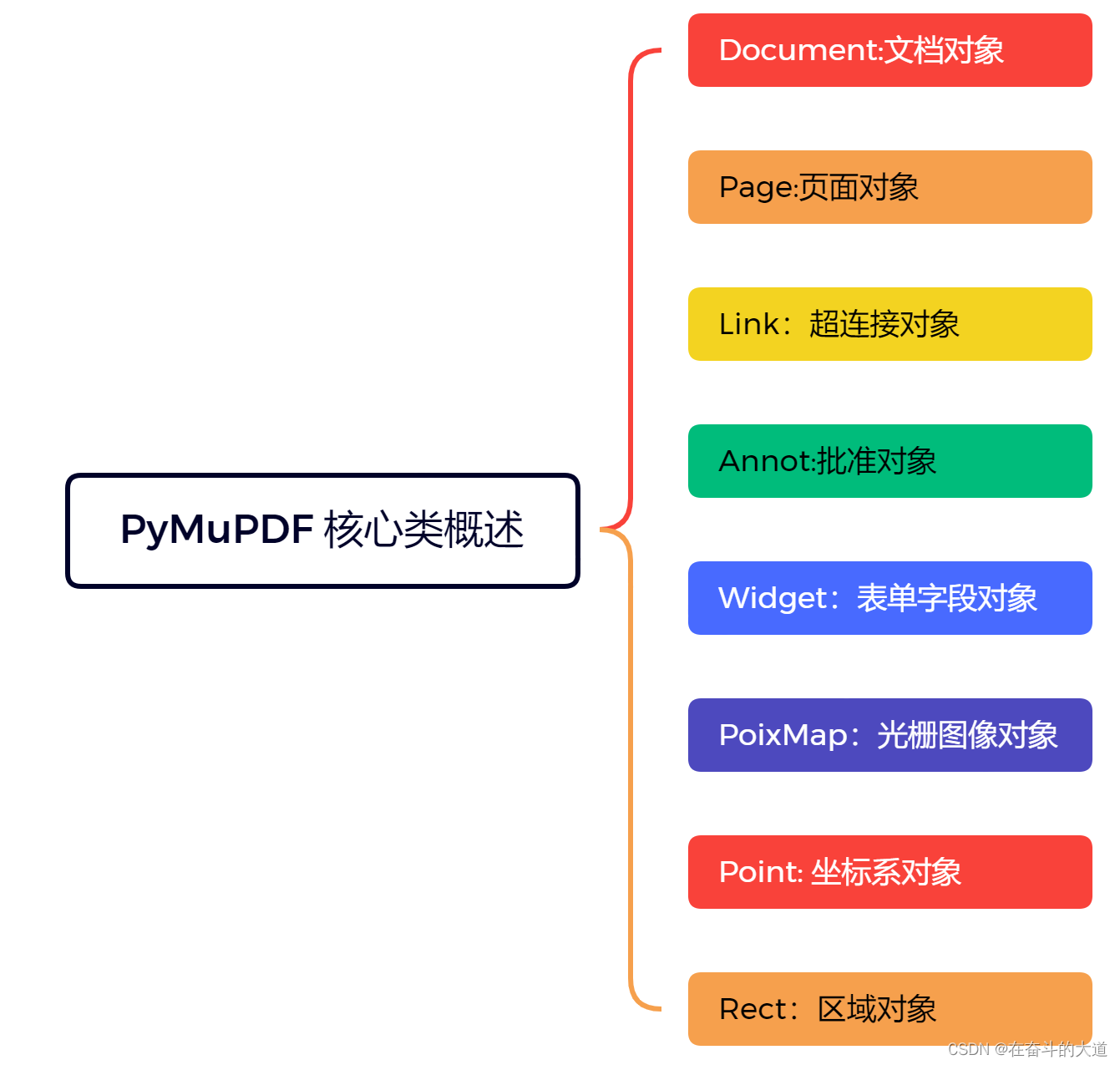
其他未使用到的其他类:Archive(档案)、Colorspace(色彩空间对象)、DisplayList(显示列表对象)、DocumentWriter(文档编辑对象)、Identity(身份对象)、 IRect(长方形对象)、linkDest(连接目的对象)、Matrix(矩阵对象)、Outline(大纲)、Quad(四边形对象)、Shape(形状对象)、 Story(章节对象)、TextPage(文本页面对象)、TextWriter(文本写入对象)、Tools(工具类)、Xml(xml 文档对象)
PyMuPDF 核心类演示
加载PDF文件
# 加载pdf 文件
doc = fitz.open("E:\doc\opencv 4.1中文官方文档v1.1版.pdf")获取Document 属性和方法
# 获取Document 文档对象的属性和方法
# 1、获取pdf 页数
pageCount = doc.page_count
print("pdf 页数", pageCount)# 2、获取pdf 元数据
metaData = doc.metadata
print("pdf 元数据:", metaData)# 3、获取pdf 目录信息
toc = doc.get_toc()
print("pdf 目录:", toc)Page 属性和方法
通过Page 对象实现以下功能:
• 您可以将页面呈现为光栅或矢量(SVG)图像,可以选择缩放、旋转、移动或剪切页面。
• 您可以提取多种格式的页面文本和图像,并搜索文本字符串。
Page 加载方法
page = doc.load_page(pno) # loads page number 'pno' of the document (0-based)
page = doc[pno] # the short form
Documnet 迭代器加载Page 方法
for page in doc:# do something with 'page'# ... or read backwards
for page in reversed(doc):# do something with 'page'# ... or even use 'slicing'
for page in doc.pages(start, stop, step):# do something with 'page'
# 获取Page 页面对象的属性和方法
page = doc.load_page(1) # 默认加载第一页
print("page 对象:", page)检查页面的链接、批注或表单字段
# 1、获取Page 页面的链接、批注或表单字段
links = page.get_links()
for link in links:# 涉及Link 对象print("链接:", link)annots = page.annots()
for annot in annots:# 涉及Annot 对象print("批注:", annot)widgets = page.widgets()
for widget in widgets:# 涉及表单字段print("表单字段:", widget)页面展示/页面图像保存到文件中
# 2、Page 页面-光栅图像
pix = page.get_pixmap()
print("打印页面图像对象:", pix)
# 保存光栅图像图像,需要依赖第三方框架:Pillow
pix.pil_save("page-%i.png" % page.number)Page.get_pixmap()提供了许多用于控制图像的变体:分辨率、颜色空间(例如,生成灰度图像或具有减色方案的图像)、透明度、旋转、镜像、移位、剪切等。
Pixmap包含以下引用的许多方法和属性。其中包括整数宽度、高度(每个像素)和跨距(一个水平图像行的字节数)。属性示例表示表示图像数据的矩形字节区域(Python字节对象)。
温馨提示:page.get_svg_image()创建页面的矢量图像。
提取文本和图像
# 3、Page 获取文本\图像\其他信息
# 温馨提示:涉及TextPage 常量类型定义
text = page.get_text("text")
print("指定页面文本内容:", text)对opt使用以下字符串之一以获取不同的格式:
"text":(默认)带换行符的纯文本。无格式、无文字位置详细信息、无图像-"blocks":生成文本块(段落)的列表-"words":生成单词列表(不包含空格的字符串)-"html":创建页面的完整视觉版本,包括任何图像。这可以通过internet浏览器显示-"dict"/"json":与HTML相同的信息级别,但作为Python字典或resp.JSON字符串。-"rawdict"/"rawjson":"dict"/"json"的超级集合。它还提供诸如XML之类的字符详细信息。-"xhtml":文本信息级别与文本版本相同,但包含图像。-"xml":不包含图像,但包含每个文本字符的完整位置和字体信息。使用XML模块进行解释。
搜索文本
# 4、Page 文本检索
search = page.search_for("图像的基本操作")
print("打印检索文本的位置:", search)提供一个矩形列表,每个矩形都包含一个字符串“mupdf”(不区分大小写)。
PDF操作
PDF是唯一可以使用PyMuPDF修改的文档类型。其他文件类型是只读的。但是,您可以将任何文档(包括图像)转换为PDF,然后将所有PyMuPDF功能应用于转换果,Document.convert_to_pdf()。
Document.save()始终将PDF以其当前(可能已修改)状态存储在磁盘上。
通常,您可以选择是保存到新文件,还是仅将修改附加到现有文件(“增量保存”),这通常要快得多。
# Document 操作PDF页面
# 1、PDF 页面删除
# doc.delete_page(1)
# 1、PDF 页面拷贝和移动
doc.copy_page(1) # 第一页移动最后一页,温馨提示:移动的页面还在元PDF 文件中。
# 1、 PDF 插入页面, 返回插入页面对象
new_page = doc.new_page(pno=-1, width=595, height=842)
# 插入页面, 设置文本
text = "你的文本"
point = fitz.Point(50, 50) # 这是一个下x,y 二维坐标系,在这个区域内插入你的文本
new_page.insert_text(point, text, fontsize=20)
# 2、Document 保存
doc.save("opencv pdf文件调整.pdf")
# 3、Documemt 销毁
doc.close()PDF 删除方法
Document.delete_page()
Document.delete_pages()PDF移动拷贝方法
Document.copy_page()
Document.fullcopy_page()
Document.move_page()PDF插入Page 方法
Document.insert_page()
Document.new_page()PyMuPDF 核心功能模块封装
PDF 分割
每一页单独保存为一个pdf
def split_per_page(input, output):if not os.path.exists(output):os.makedirs(output)doc = fitz.open(input)for page in range(doc.page_count):dst_doc = fitz.open()dst_doc.insert_pdf(doc,from_page=page,to_page=page)dst_doc.save(os.path.join(output,f'{page}.pdf'))dst_doc.close()doc.close()# 把每一个页面保存为一个pdf,并保存在test文件夹中
split_per_page("test.pdf","test")
范围内的页面保存为pdf
def split_range_page(input, output, range):if not os.path.exists(output):os.makedirs(output)doc = fitz.open(input)start = range[0] - 1end = range[1] - 1dst_doc = fitz.open()dst_doc.insert_pdf(doc, from_page=start, to_page=end)dst_doc.save(os.path.join(output,'range_page.pdf'))dst_doc.close()doc.close()# 把1-10也保存为pdf,保存在test文件夹中
split_range_page('test.pdf','test', [1,10])
任意的页面保存为pdf
def split_selected_page(input, output, pages):if not os.path.exists(output):os.makedirs(output)doc = fitz.open(input)result = map(lambda x: x - 1, pages)doc.select(list(result))doc.save(os.path.join(output,'selected_pages.pdf'))doc.close()# 把第一、三、八页面保存为pdf,并保存在test文件夹中
split_selected_page('test.pdf','test',[1,3, 8])
PDF 合并
import fitzdoc_a = fitz.open("a.pdf") # open the 1st document
doc_b = fitz.open("b.pdf") # open the 2nd documentdoc_a.insert_pdf(doc_b) # merge the docs
doc_a.save("a+b.pdf") # save the merged document with a new filename# 把b.pdf合并到a.pdf,保存为a+b.pdf
PDF 中的图片提取
import fitzdoc = fitz.open("test.pdf") # open a documentfor page_index in range(len(doc)): # iterate over pdf pagespage = doc[page_index] # get the pageimage_list = page.get_images()# print the number of images found on the pageif image_list:print(f"Found {len(image_list)} images on page {page_index}")else:print("No images found on page", page_index)for image_index, img in enumerate(image_list, start=1): # enumerate the image listxref = img[0] # get the XREF of the imagepix = fitz.Pixmap(doc, xref) # create a Pixmapif pix.n - pix.alpha > 3: # CMYK: convert to RGB firstpix = fitz.Pixmap(fitz.csRGB, pix)pix.save("page_%s-image_%s.png" % (page_index, image_index)) # save the image as pngpix = None
PDF 保存为图片
def covert2pic(zoom):doc = fitz.open("test.pdf")total = doc.page_countfor pg in range(total):page = doc[pg]zoom = int(zoom) #值越大,分辨率越高,文件越清晰rotate = int(0)trans = fitz.Matrix(zoom / 100.0, zoom / 100.0).prerotate(rotate)pm = page.get_pixmap(matrix=trans, alpha=False)lurl='.pdf/%s.jpg' % str(pg+1)pm.save(lurl)doc.close()covert2pic(200)
PDF 添加水印
def add_watermark(input, watermark):doc = fitz.open(input)for page in doc:page.insert_image(page.bound(),filename=watermark, overlay=False)doc.save(os.path.join("test","watermark.pdf"))doc.close()add_watermark("test.pdf","watermark.png")PDF 加密
PDF加密有两种形式
- 用户加密,需要输入密码才能打开pdf
- 拥有者加密,可以防止打印、复制、添加注释、添加删除页面等功能
def encrypt_pdf():perm = int(fitz.PDF_PERM_ACCESSIBILITY # always use this| fitz.PDF_PERM_PRINT # permit printing| fitz.PDF_PERM_COPY # permit copying| fitz.PDF_PERM_ANNOTATE # permit annotations) # 可以打印,复制,添加注释owner_pass = "owner" # owner passworduser_pass = "user" # user passwordencrypt_meth = fitz.PDF_ENCRYPT_AES_256 # strongest algorithmdoc = fitz.open("test.pdf") # empty pdfdoc.save("encrypt.pdf",encryption=encrypt_meth,owner_pw=owner_pass,permissions=perm,user_pw=user_pass) # 同时使用# 这两个加密方式可以,单独使用,也可以同时使用# 单独使用用户加密
doc.save("encrypt.pdf",encryption=encrypt_meth,owner_pw=owner_pass)
PyMuPDF 在PyQT5 运用
功能要求:在PyQT-5 展示pdf 文件.
效果展示:

PyQT-5 UI效果展示和源文件
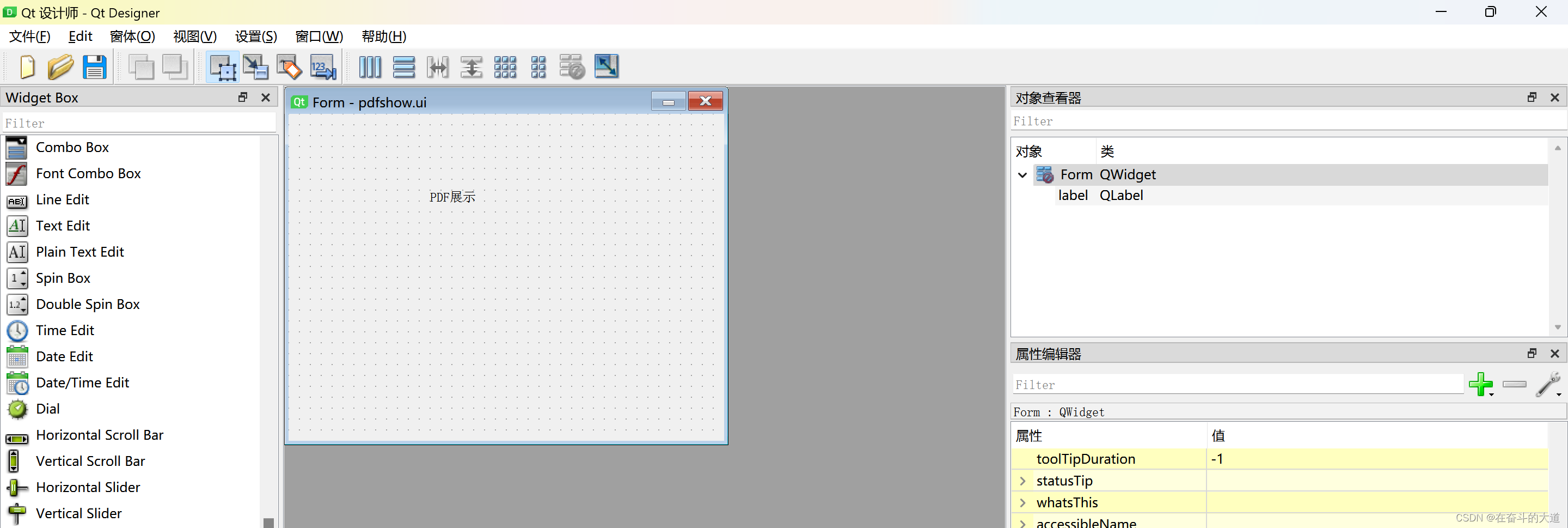
pdfshow.ui
<?xml version="1.0" encoding="UTF-8"?>
<ui version="4.0"><class>Form</class><widget class="QWidget" name="Form"><property name="geometry"><rect><x>0</x><y>0</y><width>400</width><height>300</height></rect></property><property name="windowTitle"><string>Form</string></property><widget class="QLabel" name="label"><property name="geometry"><rect><x>130</x><y>70</y><width>54</width><height>12</height></rect></property><property name="text"><string>PDF展示</string></property></widget></widget><resources/><connections/>
</ui>
pdfshow.py 源码
# -*- coding: utf-8 -*-# Form implementation generated from reading ui file 'pdfshow.ui'
#
# Created by: PyQt5 UI code generator 5.15.9
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
import sysfrom PyQt5 import QtCore, QtWidgets
from PyQt5.QtGui import QImage, QPixmap, QTransform
from PyQt5.QtWidgets import QWidget, QApplication
# 添加PDF 文件操作依赖
import fitzclass Ui_Form(QWidget):def __init__(self):super().__init__()self.label = Noneself.setupUi()self.image()def setupUi(self):self.setObjectName("Form")self.resize(400, 300)self.label = QtWidgets.QLabel(self)self.label.setGeometry(QtCore.QRect(130, 70, 54, 12))self.label.setObjectName("label")self.retranslateUi()QtCore.QMetaObject.connectSlotsByName(self)def retranslateUi(self):_translate = QtCore.QCoreApplication.translateself.setWindowTitle(_translate("Form", "Form"))self.label.setText(_translate("Form", "PDF展示"))def image(self):file = "E:\doc\opencv 4.1中文官方文档v1.1版.pdf"# 打开文件doc = fitz.open(file)# 读取一页 0代表第1页page_one = doc.load_page(1)# 将第一页转换为Pixmappage_pixmap = page_one.get_pixmap()# 将Pixmap转换为QImageimage_format = QImage.Format_RGBA8888 if page_pixmap.alpha else QImage.Format_RGB888page_image = QImage(page_pixmap.samples, page_pixmap.width,page_pixmap.height, page_pixmap.stride, image_format)width = page_image.width()height = page_image.height()# QImage 转为QPixmappix = QPixmap.fromImage(page_image)trans = QTransform()trans.rotate(90) # 这里设置旋转角度new = pix.transformed(trans)# 设置标签宽和高self.label.setFixedSize(400, 350)# 设置图片大小自适应标签self.label.setScaledContents(True)# 给标签设置图像self.label.setPixmap(new)if __name__ == '__main__':app = QApplication(sys.argv)w = Ui_Form()w.show()sys.exit(app.exec_())
解决思路
- 使用PyMuPDF模块打开文件。
- 读取第一页pdf文件第一页。
- 从第一页获取图像,是Pixmap类。
- 使用PyQt5的QImage将上面的Pixmap转换为QImage。
- 将QImage转换为QPixmap。
- 将QPixmap设置给Label。
相关文章:
Python3 处理PDF之PyMuPDF 入门
PyMuPDF 简介 PyMuPDF是一个用于处理PDF文件的Python库,它提供了丰富的功能来操作、分析和转换PDF文档。这个库的设计目标是提供一个简单易用的API,使得开发者能够轻松地在Python程序中实现PDF文件的各种操作。 PyMuPDF的主要特点如下: 跨平台兼容性&a…...

使用隧道HTTP时如何解决网站验证码的问题?
使用代理时,有时候会遇到网站验证码的问题。验证码是为了防止机器人访问或恶意行为而设置的一种验证机制。当使用代理时,由于请求的源IP地址被更改,可能会触发网站的验证码机制。以下是解决网站验证码问题的几种方法: 1. 使用高匿…...

Java超级玛丽小游戏制作过程讲解 第三天 创建并完成常量类02
public class StaticValue {//背景public static BufferedImage bgnull;public static BufferedImage bg2null;//马里奥向左跳跃public static BufferedImage jump_Lnull;//马里奥向右跳跃public static BufferedImage jump_Rnull;//马里奥向左站立public static BufferedImage…...

ARM微架构
一、流水线 二、指令流水线 指令流水线 指令流水线 指令流水线 ARM指令流水线 ARM7采用3级流水线 ARM9采用5级流水线 Cortex-A9采用8级流水线 注1:虽然流水线级数越来越多,但都是在三级流水线的基础上进行了细分 PC的作用(取指) …...
Stable Diffusion AI绘画学习指南【本地环境搭建win+mac】
一、硬件配配置要求 系统:windows 10 / Mac os 硬盘:C 盘预留 15GB 以上,其他盘 50GB 以上,Stable Ddiffusion的很多大模型都是以 GB 起步。 显卡:4GB 以上,建议 8GB, 效率高,能玩大尺寸的图 CPU&…...
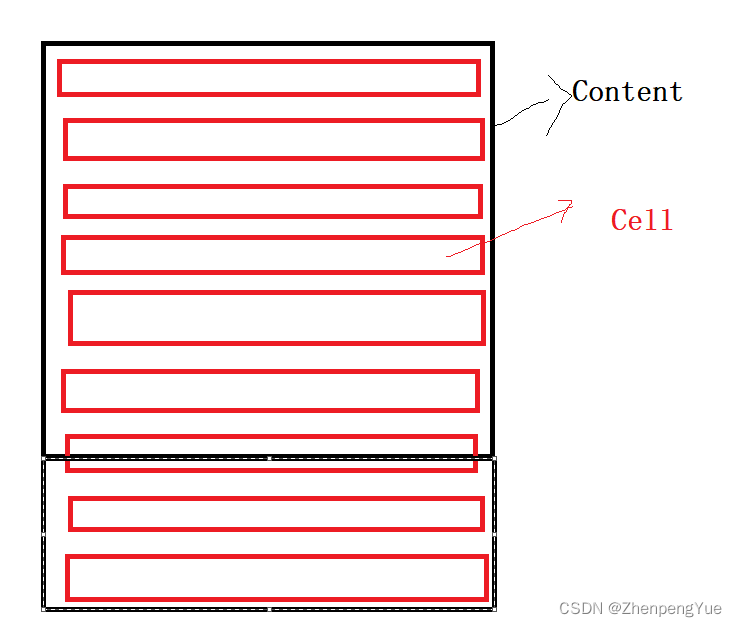
Unity 3D ScrollRect和ScrollView回弹问题的解决
你是否是这样? Content高度 < 全部Cell加在一起的总高 他就认为你的全部Cell加起来就跟Content一样大,所以才出现了这种完全回弹 我该怎么办? 很简单,改变Content的长度跟所有Cell的和一样大 void RefreshSize(){float allD…...
python编写小程序有界面,python编写小程序的运行
大家好,小编为大家解答python编写小程序怎么看代码的的问题。很多人还不知道python编写小程序的运行,现在让我们一起来看看吧! Python第一个简单的小游戏 temp input("请猜一猜姐姐的幸运数字是: ") guess int(temp) …...
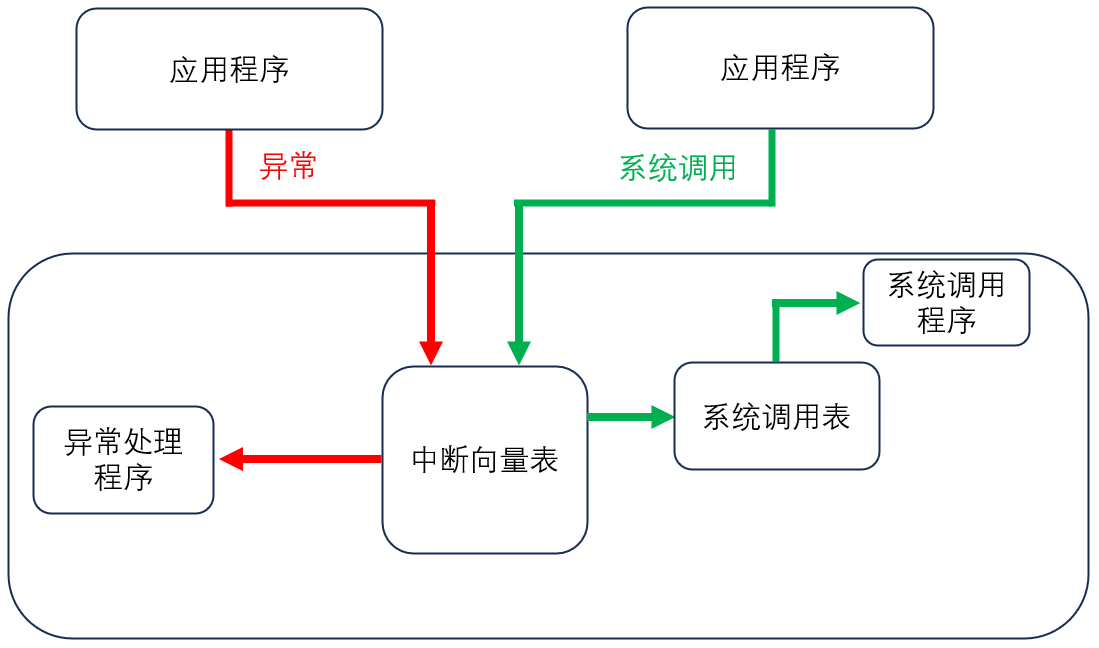
【中断机制】什么是中断?使用中断的原因、注意事项
目录 一、为什么需要中断 二、什么是中断 1、中断的概念 2、中断的分类 3、中断的处理流程 三、中断处理程序要少用延时的原因 一、为什么需要中断 以网卡为例,CPU 如果要从网卡获取数据,不可能时时盯着网卡啥时候会有数据。当网卡收到数据时&…...

C++20 协程(coroutine)入门
文章目录 C20 协程(coroutine)入门什么是协程无栈协程和有栈协程有栈协程的例子例 1例 2 对称协程与非对称协程无栈协程的模型无栈协程的调度器朴素的单线程调度器让协程学会等待Python 中的异步函数可等待对象M:N 调度器——C# 中的异步函数 小结 C20 中…...

2023.8.6
2022河南萌新联赛第(三)场:河南大学\区间操作.cpp //题意:定义一个f[x]函数表示一个数分解质因数后各个质因子的幂次和,给定一个长度为n的数组, //有m个操作,第一种操作是输出[l, r]范围内的a…...

kubernetes网络之网络策略-----Network Policies - Default
默认情况下,如果名称空间中没有配置 NetworkPolicy,则该名称空间中,所有Pod的所有入方向流量和所有出方向流量都是被允许的。 那么如果我们想改变名称空间中默认的网络策略,又该怎么做呢? 默认拒绝所有的入方向流量 …...
奥威BI系统|秒分析,更适合分析大数据
根据以往的经验,当数据量多到一定程度就容易导致系统卡顿、崩溃。这种现象给企业级数据分析造成了极大的困扰。随着业务发展扩大和分析需求精细化,企业需要一套能秒分析大数据的系统。而奥威BI系统就是这样一款可以秒分析大数据的商业智能系统。 奥威BI…...
安全作业-Race竞争型漏洞、原型链污染
1.race漏洞一直卡在虚拟机安装上(待研究) 2.原型链污染 一、第一题js代码 const express require(express) var hbs require(hbs); var bodyParser require(body-parser); const md5 require(md5); var morganBody require(morgan-body); const app express(); var use…...

对微服务网关的一些总结
对微服务网关的一些总结 一. 什么是网关 网关是位于NGINX(或没有)与真实微服务间的转发服务。 用户通过HTTP接口,连接到NGINX,然后NGINX反向到M个网关。 网关根据[服务注册与发现],进行转发请求到具体的微服务上。 由于网关可编码&#…...
该选择WPF 还是 Winform?
WPF和WinForms都是.NET平台下的桌面应用程序开发框架,它们各有特点,适用于不同的场景和需求。下面是对WPF和WinForms的一些比较和优劣势:WPF(Windows Presentation Foundation):WPF具有强大的图形渲染能力&…...

概念解析 | ChatGPT技术概览
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:ChatGPT技术概览 参考资料:Deng J, Lin Y. The benefits and challenges of ChatGPT: An overview[J]. Frontiers in Computing and Intelligent Systems, 2022, 2(2): 81-83. …...

用Rust实现23种设计模式之 代理模式
关注我,学习Rust不迷路!! 代理模式是一种结构型设计模式,它允许通过代理对象来控制对真实对象的访问。以下是代理模式的优点和使用场景: 优点: 控制访问:代理模式可以控制对真实对象的访问&a…...

【nlp pytorch】基于标注信息从句子中提取命名实体内容
基于标注信息从句子中提取实体内容 1 需求2 代码实现3 代码封装1 需求 给定一个句子和已经通过模型训练标注好的信息,从而提取出句子中的实体内容,如下 输入: (1)句子信息 每个糖尿病患者,无论是病情轻重,不论是注射胰岛素,还是口服降糖药,都必须合理地控制饮食。(2)…...

图为科技加入深圳市智能交通行业协会 ,打 …
图为科技加入深圳市智能交通行业协会,打造智能交通新生态! 交通是国民经济发展的“大动脉”,交通拥堵、事故频发等问题不仅影响了人们的出行体验,也对经济的发展产生了负面影响。安全、高效、便捷的出行,一直是人们的…...

大模型排行榜及相关基础技术
大模型排行榜 测试集CEval中文多个学科测试集排名MMLU大规模多任务语言理解英文排名,介绍斯坦福排行榜 强人工智能AGI相关基础技术 标题简介分类稳定扩散模型The Illustrated Stable Diffusion图示化讲解Jay讲解Stable Diffusion计算机技术资料Transformer图示化讲解…...

深入理解 ASP.NET Core 中的 IActionResult
一、从一个问题开始 你写了一个 Web API,有时候要返回数据,有时候要返回 404,有时候要返回 400——这三种情况的返回值类型完全不同,一个 C# 方法怎么能同时返回多种东西? 这就是 IActionResult 存在的根本原因。它的本…...

技术解密:如何从零构建开源贴片机的完整指南
技术解密:如何从零构建开源贴片机的完整指南 【免费下载链接】lumenpnp The LumenPnP is an open source pick and place machine. 项目地址: https://gitcode.com/gh_mirrors/lu/lumenpnp 在电子制造领域,贴片机一直是小型创客和硬件开发者难以企…...

Diablo Edit2完全指南:暗黑破坏神2存档修改器终极使用教程
Diablo Edit2完全指南:暗黑破坏神2存档修改器终极使用教程 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经在暗黑破坏神2中花费数小时刷装备却一无所获?或者想要…...

在数据预处理流水线中集成 Taotoken 进行文本摘要与分类
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据预处理流水线中集成 Taotoken 进行文本摘要与分类 对于数据工程师和算法工程师而言,构建一个稳定、高效且成本可…...
)
别再只用ROC了!用R语言ggplot2为你的Logistic回归模型画个校准曲线(附完整代码)
超越ROC:用R语言打造兼具诊断力与美学的Logistic回归校准曲线 当我们在医学统计或信用评分领域构建预测模型时,常常陷入一个认知陷阱——过度依赖ROC曲线和AUC值作为模型评估的唯一标准。这种单一视角可能掩盖了预测模型中更本质的问题:当模型…...

【实用程序】基于 Java 的简易HTTP 反向代理
本站内的程序及源代码下载地址。 第一章 概述 本项目是一个基于 Java 的简易 HTTP 反向代理实现。反向代理(Reverse Proxy)的核心职责是代表客户端向目标服务器发起请求,并将目标服务器的响应透明地返回给客户端。客户端感知不到后端真实服务的存在,所有交互都通过代理层…...

VMware 17 开机自启实战:从配置到故障排查的完整指南
1. VMware 17开机自启基础配置 很多运维工程师在生产环境中都会遇到这样的需求:让VMware虚拟机像系统服务一样随宿主机自动启动。这个功能对于无人值守的服务器、工控机等场景特别重要。下面我就以VMware Workstation 17为例,手把手教你配置全过程。 首…...

Ecco架构:突破LLM推理内存墙的熵编码优化方案
1. Ecco架构:突破LLM推理的内存墙在A100 GPU上运行LLaMA-70B模型时,仅权重参数就占用140GB显存,而HBM带宽仅有2TB/s——这就是典型的"内存墙"问题。传统解决方案如量化会损失精度,而单纯增加硬件成本又面临边际效益递减…...
)
告别ActiveX!用WebSocket+JavaScript在Chrome/Firefox里直接调用扫描仪(附完整代码)
现代浏览器无插件扫描方案:WebSocket与JavaScript的完美结合 曾几何时,企业办公系统中扫描文档需要依赖特定的浏览器和插件。如今,随着技术演进,我们终于可以摆脱ActiveX和NPAPI的束缚,在Chrome、Firefox等现代浏览器中…...

别再死记硬背物联网四层架构了!用LoRa和ESP32手把手搭个智能花盆,实战理解每一层
从智能花盆实战理解物联网四层架构:LoRaESP32全流程拆解 每次翻开物联网教材,总能看到那个经典的四层架构图:感知层、网络层、平台层、应用层。但真正动手做项目时,却发现理论和实践之间隔着一道鸿沟。今天我们就用最接地气的方式…...