zookeeper集群和kafka的相关概念就部署
目录
一、Zookeeper概述
1、Zookeeper 定义
2、Zookeeper 工作机制
3、Zookeeper 特点
4、Zookeeper 数据结构
5、Zookeeper 应用场景
(1)统一命名服务
(2)统一配置管理
(3)统一集群管理
(4)服务器动态上下线
(5)软负载均衡
6、Zookeeper选举机制
(1)第一次启动选举机制
(2)非第一次启动选举机制
(3)选举Leader规则
二、Zookeeper集群部署
环境配置
1.安装前准备(所有节点执行)
2.安装 Zookeeper
三 Kafka
3.1Kafka 概述
3.1 .1为什么需要消息队列(MQ)
3.2.2 使用消息队列的好处
3.3.3 消息队列的两种模式
3.2 Kafka 定义
3.3 Kafka 简介
3.4 kafka的特性
3.5 kafka系统架构
四 部署kafka集群
上述zookeeper机器全部安装kafka
环境准备
五 kafka命令行操作
(1)创建topic
(2) 列出所有topic
(3)查看topic信息
(4) 发布消息
(5)消费消息
(6)修改指定topic分区数
(7)删除指定topic
六 kafka架构深入
1、Kafka 工作流程及文件存储机制
2、数据可靠性保证
3、数据一致性问题
4、ack 应答机制
一、Zookeeper概述
1、Zookeeper 定义
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。
2、Zookeeper 工作机制
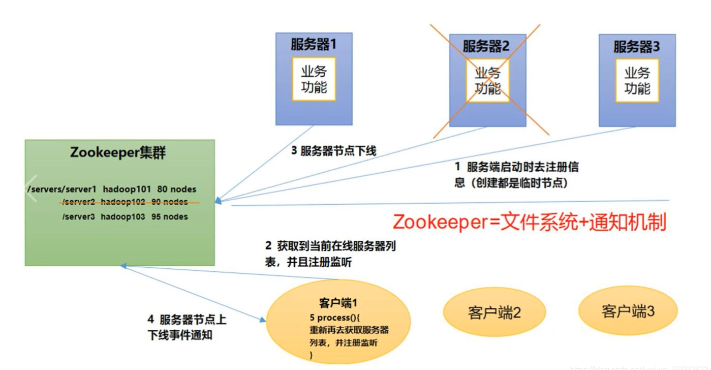
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。也就是说 Zookeeper =文件系统+通知机制。
3、Zookeeper 特点
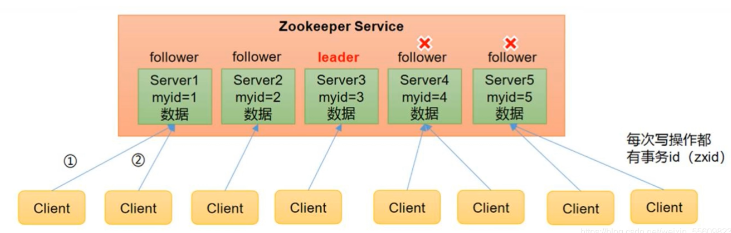
- Zookeeper: 一个领导者(Leader) ,多个跟随者(Follower) 组成的集群。
- Zookeepe集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server, 数据都是一致的。
- 更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,Client能读到最新数据。
4、Zookeeper 数据结构
ZooKeeper数据模型的结构与Linux文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
5、Zookeeper 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
(1)统一命名服务
- 在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如: IP不容易记住,而域名容易记住。
(2)统一配置管理
- 分布式环境下,配置文件同步非常常见。一般要求- - 个集群中,所有节点的配置信息是- - 致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上。
- 配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper.上的一个Znode。各个客户端服务器监听这个znode。一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
(3)统一集群管理
- 分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态做出一些调整
- ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper_上的一个ZNode。监听这个ZNode可获取它的实时状态变化。
(4)服务器动态上下线
- 客户端能实时洞察到服务器上下线的变化。
(5)软负载均衡
- 在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
6、Zookeeper选举机制
(1)第一次启动选举机制
- 服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为
L00KING - 服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的
myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数q票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING 服务器3启动,发起一.次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING服务器4启动,发起一次选举。此时服务器1,2,3已经不是L00KING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING服务器5启动,同4一样当小弟。
(2)非第一次启动选举机制
1、当ZooKeeper 集群中的一台服务器出现以下两种情况之一时, 就会开始进入Leader选举:
- 服务器初始化启动。
- 服务器运行期间无法和Leader保持连接。
2、而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
集群中本来就已经存在一个Leader,对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。
集群中确实不存在Leader,假设ZooKeeper由5台服务器组成,SID分别为1、 2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某时刻,3和5服务器出现故障,因此开始进行Leader选举。
(3)选举Leader规则
- EPOCH大的直接胜出
- EPOCH相同,事务id大的胜出
- 事务id相同,服务器id大的胜出
| 选举参照 | 说明 |
| SID | 服务器ID,用来唯一标识一天ZooKeePer集群中的机器,每台机器不能重复,和myid一致。 |
| ZXID | 事务ID,ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户单“更新请求”的处理逻辑速度有关。 |
| Epoch | 每个Leader任期的代号,没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加 |
二、Zookeeper集群部署
环境配置
准备3台服务器做Zookeeper 集群,每台服务器都进行配置
| 服务器 | IP地址 | 部署操作 |
| zk1 | 192.168.40.105 | Zookeeper集群 |
| zk2 | 192.168.40.126 | zookeeper集群 |
| zk3 | 192.168.40.150 | zookeeper集群 |
1.安装前准备(所有节点执行)
//关闭防火墙和安全机制
systemctl stop firewalld
systemctl disable firewalld
setenforce 0###所有节点执行
//安装 JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
//下载安装包
官方下载地址:https://archive.apache.org/dist/zookeeper/cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
2.安装 Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
//修改配置文件
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.40.105:3188:3288
server.2=192.168.40.126:3188:3288
server.3=192.168.40.150:3188:3288

server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
//拷贝配置好的 Zookeeper 配置文件到其他机器上
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.40.126:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.40.150:/usr/local/zookeeper-3.5.7/conf/
//在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
![]()
//在每个节点的dataDir指定的目录下创建一个 myid 的文件
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid###此处注意:这个步骤是分配zookeeper集群中不同服务器的myid值,每台机器不可重复![]()
//配置 Zookeeper 启动脚本
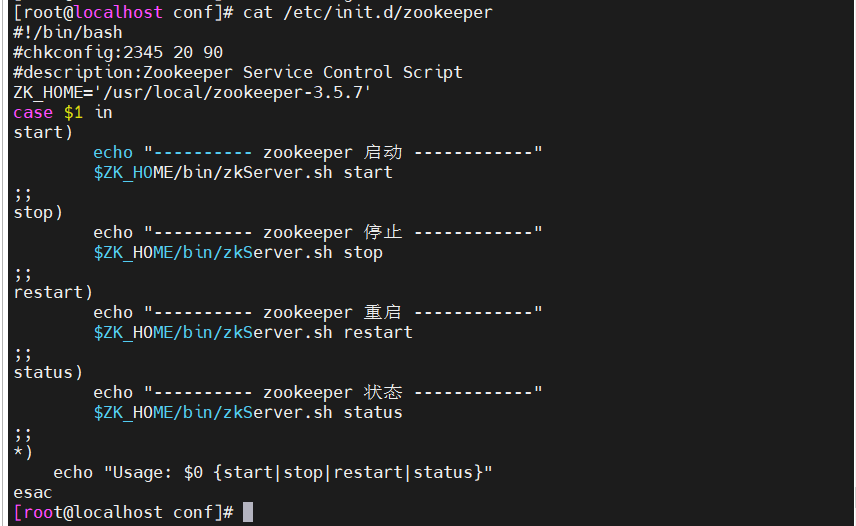
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac
// 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
//每台机器分别启动 Zookeeper
service zookeeper start//每台机器分别查看当前状态
service zookeeper status




这边给大家讲讲为什么明明我第三台机器myid值为3比第二台机器的myid值高却是follower,而第二台的myid值不是最大却当上了leader。这是因为:
●第一次启动选举机制
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(2票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,已经有了半数以上结果,选举完成。所以服务器3就只能当小弟了
三 Kafka
3.1Kafka 概述
3.1 .1为什么需要消息队列(MQ)
- 主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
- 我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
- 当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
3.2.2 使用消息队列的好处
- 解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 缓冲:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
- 灵活性 & 峰值处理能力:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
- 异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3.3.3 消息队列的两种模式
- 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除):消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
- 发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息):消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
3.2 Kafka 定义
- Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域。
3.3 Kafka 简介
- Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写,
- Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
3.4 kafka的特性
- 高吞吐量、低延迟:Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
- 可扩展性:kafka 集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
- 高并发:支持数千个客户端同时读写
3.5 kafka系统架构
(1)Broker
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(2)Topic
可以理解为一个队列,生产者和消费者面向的都是一个 topic。
类似于数据库的表名或者 ES 的 index
物理上不同 topic 的消息分开存储
(3)Partition
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。
Partation 数据路由规则:
1.指定了 patition,则直接使用;
2.未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
3.patition 和 key 都未指定,使用轮询选出一个 patition。
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。
每个 partition 中的数据使用多个 segment 文件存储。
如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition 数目设为 1。
●broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
●如果某 topic 有 N 个 partition,集群有 (N+M) 个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition, 剩下的 M 个 broker 不存储该 topic 的 partition 数据。
●如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
(4)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
(5)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
(6)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
(7)Producer
生产者即数据的发布者,该角色将消息发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
(8)Consumer
消费者可以从 broker 中读取数据。消费者可以消费多个 topic 中的数据。
(9)Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响。
(10)offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终还是会被删除的,默认生命周期为 1 周(7*24小时)。
(11)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
四 部署kafka集群
上述zookeeper机器全部安装kafka
环境准备
关闭防火墙及安全机制
systemctl stop firewalld
setenforce 0
安装kafka
cd /opt
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka![]()

//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.10.17:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 ●123行,配置连接Zookeeper集群地址



//修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin

//配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac 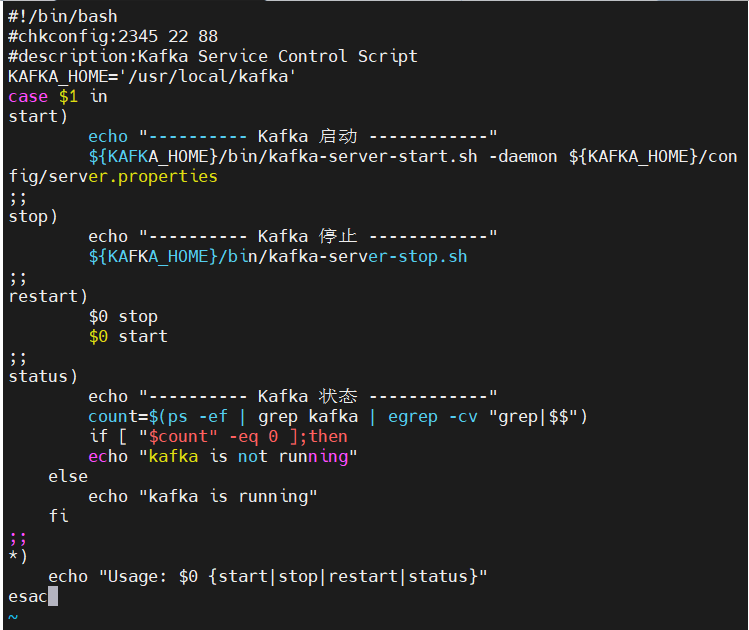
//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka
//分别启动 Kafka
service kafka start 不给权限kafka无法启动
五 kafka命令行操作
(1)创建topic
使用kafka-topics.sh
--create:执行创建,topic端口为2181
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称

(2) 列出所有topic
--list:列出当前所有topic


(3)查看topic信息
--describe:查看topic的信息
--topic:指定topic名,不指定显示所有

(4) 发布消息
使用 kafka-console-producer.sh--broker-list:指定代理节点,发布端口为909 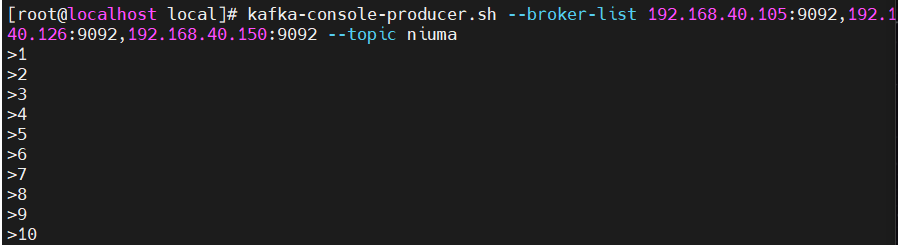
(5)消费消息
使用 kafka-console-consumer.sh
--bootstrap-server:指定消费服务器地址,消费端口也是9092
--from-beginning:会把主题中以往所有的数据都读取出来
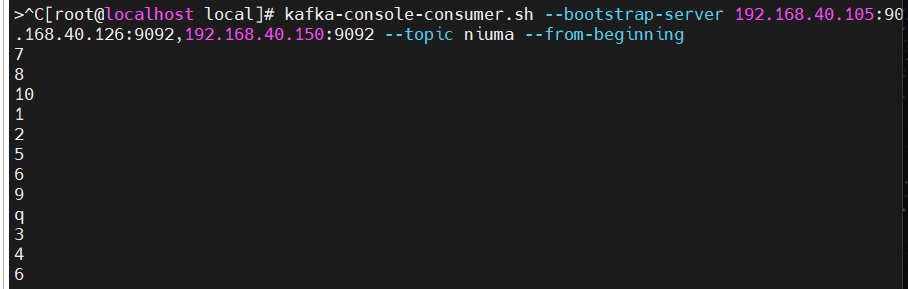
但是如果实时发布和读取(即发布一条消费一条),那么顺序就能保证;还有前文提到,严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partitions 数目设为 1。
(6)修改指定topic分区数
使用kafka-topics.sh--alter:执行修改 
注意:像上一点提到的,修改 partitions 为1,不能使用此方法,只能删除此topic然后重建,是因为修改已存在topic时,partitions 的数目只允许增。例:
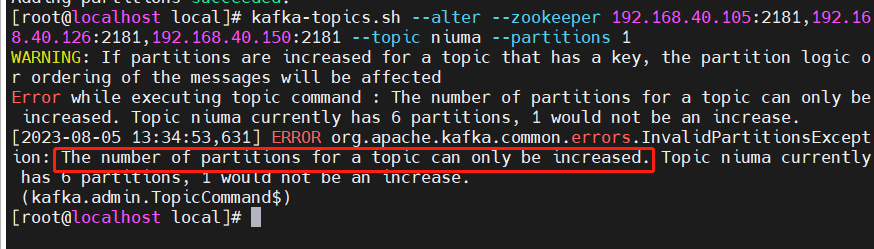
(7)删除指定topic
--delete:执行删除

六 kafka架构深入
1、Kafka 工作流程及文件存储机制
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该 log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment 对应两个文件:“.index” 文件和 “.log” 文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,test 这个 topic 有三个分区, 则其对应的文件夹为 test-0、test-1、test-2。
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。
“.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
2、数据可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后, 都需要向 producer 发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
3、数据一致性问题
LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,所有副本中最小的 LEO。
(1)follower 故障
follower 发生故障后会被临时踢出 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合),待该 follower 恢复后,follower 会读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了。
(2)leader 故障
leader 发生故障之后,会从 ISR 中选出一个新的 leader, 之后,为保证多个副本之间的数据一致性,其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据。
注:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
4、ack 应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡选择。
当 producer 向 leader 发送数据时,可以通过 request.required.acks 参数来设置数据可靠性的级别:
●0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。当broker故障时有可能丢失数据。
●1(默认配置):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果在follower同步成功之前leader故障,那么将会丢失数据。
●-1(或者是all):producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是如果在 follower 同步完成后,broker 发送ack 之前,leader 发生故障,那么会造成数据重复。
三种机制性能依次递减,数据可靠性依次递增。
注:在 0.11 版本以前的Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。在 0.11 及以后版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据, Server 端都只会持久化一条。
相关文章:
zookeeper集群和kafka的相关概念就部署
目录 一、Zookeeper概述 1、Zookeeper 定义 2、Zookeeper 工作机制 3、Zookeeper 特点 4、Zookeeper 数据结构 5、Zookeeper 应用场景 (1)统一命名服务 (2)统一配置管理 (3)统一集群管理 (4&a…...
第4集丨Vue 江湖 —— 计算属性
目录 一、基本使用1.1 在computed中定义1.1.1 案例1.1.2 控制台调用getter1.1.3 控制台中的data和computed 1.2 缓存效果1.3 完整写法1.3.1 案例1.3.2 效果图 1.4 简写形式 二、案例的其他实现2.1 methods实现2.2 插值语法实现 三、体会计算属性的好处3.1 复杂任务时3.2 使用计…...

Docker 容器化学习
文章目录 前言Docker架构 1、 docker安装2、启动docker服务3、设置docker随机器一起启动4、docker体验5、docker常规命令5.1、容器操作docker [run|start|stop|restart|kill|rm|pause|unpause]docker [ps|inspect|exec|logs|export|import] 5.2、镜像操作docker images|rmi|tag…...
springboot第34集:ES 搜索,nginx
#用search after解决深分页性能问题 #第一页 GET /bank/_search {"size": 10,"sort": [{"account_number": {"order": "asc"}}] }#第二页 GET /bank/_search {"size": 10,"sort": [{"account_numb…...
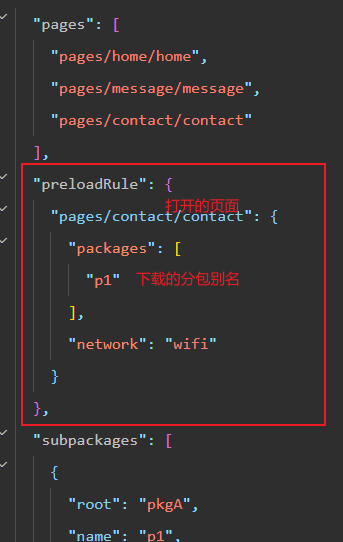
微信小程序中的分包使用介绍
一、分包的好处 可以优化小程序首次启动的下载时间 在多团队共同开发时可以更好的解耦协作 主包:放置默认启动页面/TabBar 页面,公共资源/JS 脚本 分包:根据开发者的配置进行划分 限制:所有分包大小不超过 20M,单…...
【云原生】K8S二进制搭建二:部署CNI网络组件
目录 一、K8S提供三大接口1.1容器运行时接口CRI1.2云原生网络接口CNI1.3云原生存储接口CSI 二、Flannel网络插件2.1K8S中Pod网络通信2.2Overlay Network2.3VXLAN2.4Flannel 三、Flannel udp 模式的工作原理3.1ETCD 之 Flannel 提供说明 四、vxlan 模式4.1Flannel vxlan 模式的工…...

【iOS】—— 离屏渲染
文章目录 离屏渲染UIView和CALayer关系GPU屏幕渲染有两种方式:产生离屏渲染的原因:既然离屏渲染这么耗性能,为什么有这套机制呢?什么情况会离屏渲染?既然离屏渲染这么不好,为什么我们还要强制开启呢?如何避免离屏渲染?…...

基于人工智能的中医图像分类系统设计与实现
华佗AI 《支持中医,永远传承古老文化》 本存储库包含一个针对中药的人工智能图像分类系统。该项目的目标是通过输入图像准确识别和分类各种中草药和成分。 个人授权许可证 版权所有 2023至2050特此授予任何获得华佗AI应用程序(以下简称“软件”)副本的人免费许可,可根据以…...
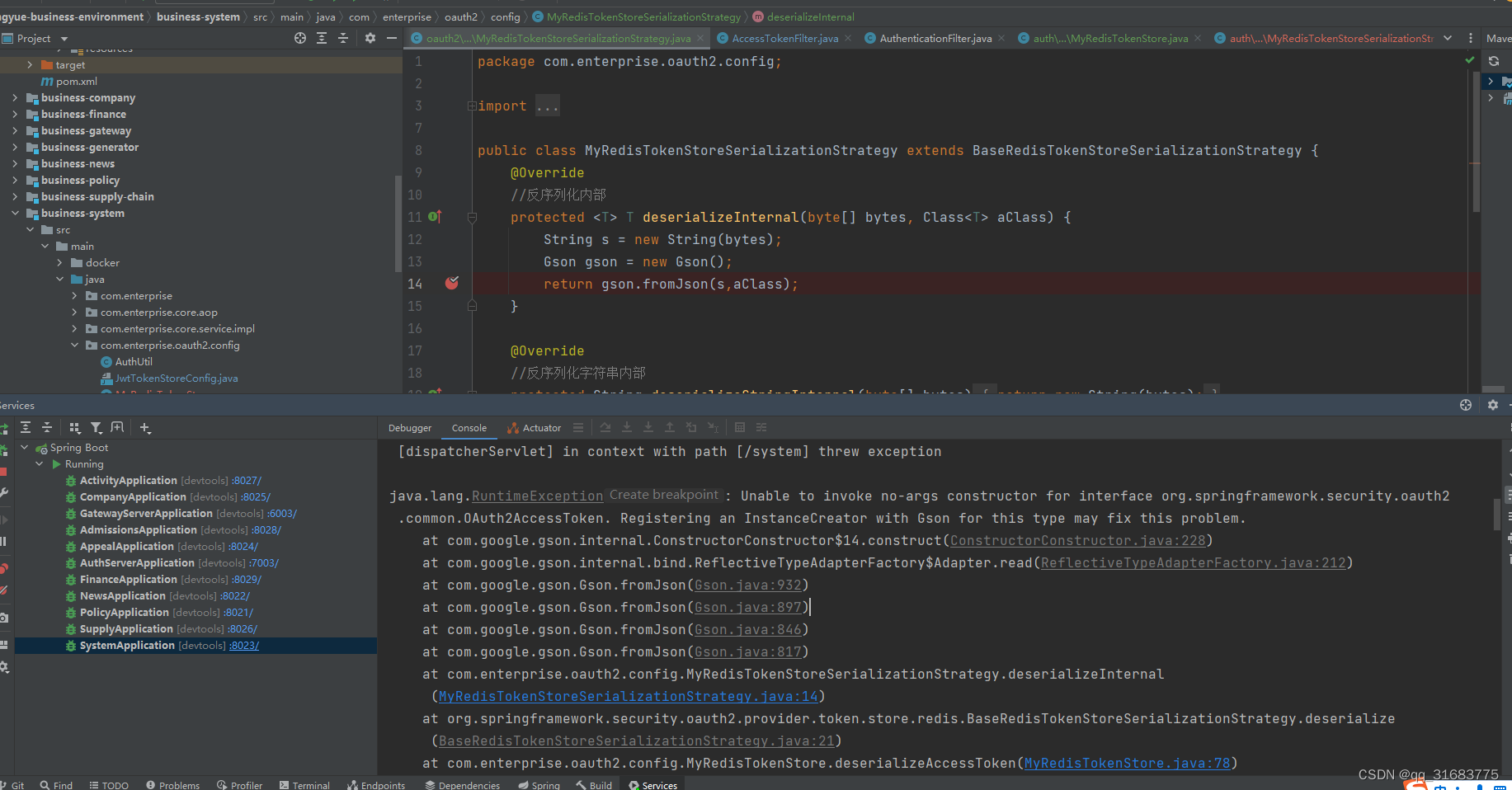
spring security + oauth2 使用RedisTokenStore 以json格式存储
1.项目架构 2.自己对 TokenStore 的 redis实现 package com.enterprise.auth.config;import org.springframework.data.redis.connection.RedisConnection; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis…...

css position: sticky;实现上下粘性布局,中间区域滚动
sticky主要解决的问题 1、使用absolute和fixed中间区域需要定义高度2、使用absolute和fixed底部需要写padding-bottom 避免列表被遮挡住一部分(底部是浮窗的时候,需要动态的现实隐藏) <!DOCTYPE html> <html lang"en"&…...

解密HTTP代理爬虫中的IP代理选择与管理策略
在当今数据驱动的世界中,HTTP代理爬虫作为一项重要的数据采集工具,其成功与否往往取决于IP代理的选择与管理策略。作为一家专业的HTTP代理产品供应商,我们深知IP代理在数据采集中的重要性。在本文中,我们将分享一些关于HTTP代理爬…...
pytorch入门
详细安装教程和环境配置可以看:Python深度学习:安装Anaconda、PyTorch(GPU版)库与PyCharm_哔哩哔哩_bilibili 跟学课程:B站我是土堆 pytorch中两个实用函数: dir():打开 help():说明书…...

Redis | 主从模式
Redis | 主从模式 1. 简介 Redis主从模式(Replication)是Redis提供的一种数据备份和高可用性解决方案。通过主从复制,可以将一个Redis服务器的数据复制到其他多个从服务器,从而实现数据的备份和读写分离,提高系统的性…...

C# Blazor 学习笔记(8):row/col布局开发
文章目录 前言相关文章代码row和col组件B_rowB_col结构 使用 前言 可能是我用的element ui和 uView这种第三方组件用的太多了。我上来就希望能使用这些组件。但是目前Blazor目前的生态其实并不完善,所以很多组件要我们自己写。 我们对组件的要求是 我们在组件化一共…...

金融供应链智能合约 -- 智能合约实例
前提 Ownable:监管者合约,有一个函数能转让监管者。 SupplyChainFin:供应链金融合约,银行、公司信息上链,公司和银行之间的转账。 发票:记录者交易双方和交易金额等的一种记录数据。如:我在超市买了一瓶水,超市给我开了一张发票。 Ownable // SPDX-…...

论文《Contrastive Meta Learning with Behavior Multiplicity for Recommendation》阅读
论文《Contrastive Meta Learning with Behavior Multiplicity for Recommendation》阅读 论文概况论文主要贡献Background & Motivation方法论单行为图神经网络(Behavior-aware GNN)多行为对比学习元对比编码模型训练 实验部分论文总结 论文概况 今…...

K8S 部署 RocketMQ
文章目录 添加模板部署本地访问 集群使用 kubesphere 作为工具 添加模板 添加 helm 模板 helm repo add rocketmq-repo https://helm-charts.itboon.top/rocketmq helm repo update rocketmq-repo编写 value.yaml 文件 配置主从节点的个数,例子为单节点 broker:…...

[Docker]入门之docker-compose
一,Docker-compose简介 1,Docker-compose简介 Docker-Compose项目是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。 Docker-Compose将所管理的容器分为三层,分别是工程(project),…...

SAP ABAP中使用函数ALSM_EXCEL_TO_INTERNAL_TABLE读取EXCEL中不同的SHEET数据
SAP提供了标准的读取EXCEL的函数(ALSM_EXCEL_TO_INTERNAL_TABLE),但是此标准函数无法满足对同一EXCEL 进行不同SHEET的数据读取,一下方法就是教你如何通过修改程序来实现ALSM_EXCEL_TO_INTERNAL_TABLE读取多个SHEET; …...

Rust 编程小技巧摘选(6)
目录 Rust 编程小技巧(6) 1. 打印字符串 2. 重复打印字串 3. 自定义函数 4. 遍历动态数组 5. 遍历二维数组 6. 同时遍历索引和值 7. 迭代器方法的区别 8. for_each() 用法 9. 分离奇数和偶数 10. 判断素数(质数) Rust 编程小技巧(6) 1. 打印…...

压接 vs 焊接:高速连接器组装工艺的选型指南与实战对比
摘要/前言在通信设备、工业控制及数据中心硬件设计中,连接器的组装工艺选择直接影响产品的可靠性、可维护性与生产良率。压接(Press-Fit)与焊接(Soldering)是当前通孔连接器最主要的两种电气互连方式。压接依靠过盈配合…...

如何快速掌握ComfyUI智能图像分割:面向新手的完整指南
如何快速掌握ComfyUI智能图像分割:面向新手的完整指南 【免费下载链接】comfyui_segment_anything Based on GroundingDino and SAM, use semantic strings to segment any element in an image. The comfyui version of sd-webui-segment-anything. 项目地址: ht…...

前端开发从入门到精通:Vue3+TypeScript实战教程
一、为什么软件测试从业者要学Vue3TypeScript在软件测试领域,尤其是自动化测试和性能测试方向,懂前端开发技术早已不是加分项,而是必备技能。作为测试从业者,掌握Vue3TypeScript能为你的职业发展带来多重优势:…...

一文读懂现代城市照明:从亮化到数字化的行业升级指南
当前照明行业早已脱离单纯"亮起来"的初级阶段,正在向场景化、数字化、低碳化方向快速迭代,很多客户在选择照明服务商时往往对行业标准、技术趋势了解不足,导致项目效果与预期存在差距。行业升级的核心方向:从单一照明到…...

RAG vs LoRA:AI产品选型困境终结者!产品经理必看的技术选型指南
本文深入剖析了AI产品开发中RAG与LoRA技术的选型困境,指出两者并非竞争关系,而是基于不同场景的产品判断失误。文章从概念解析入手,通过生动类比区分了RAG(知识库增强)与LoRA(模型微调)的核心差…...

C语言变量与运算符详解:从内存管理到高效编程实践
1. 从零到一:为什么C语言是程序员的“内功心法”?如果你刚看完系列的第一篇,对C语言有了一个模糊的印象,觉得它古老、复杂,甚至有点“过时”,那太正常了。我刚开始接触编程时,也这么想。为什么放…...

ABB机器人通过Socket实现ModbusTCP通信:Float浮点数解析与PLC数据交换实战
1. ABB机器人与PLC通信的基础原理 在工业自动化领域,设备间的数据交换是核心需求之一。ABB机器人作为客户端与PLC(可编程逻辑控制器)进行通信时,最常用的方式就是ModbusTCP协议。但这里有个关键点需要注意:ABB机器人的…...
)
第六届计算机、遥感与航空航天国际学术会议(CRSA 2026)
第六届计算机、遥感与航空航天国际学术会议(CRSA 2026)将于2026年6月26-28日在中国辽宁-沈阳举行。计算机、遥感与航空航天国际学术会议为来自世界各地的研究学者、工程师、学会会员以及相关领域的专家们提供一个关于“计算机科学”、“遥感技术与应用”…...

TikTok 短视频生成工具哪家好?TikTok 爆款视频复刻,有什么工具推荐
在 TikTok 流量竞争愈发激烈的 2026 年,想要快速起号、稳定爆单,离不开优质短视频量产和爆款视频复刻。不用从零原创创作,借助成熟 AI 工具复刻平台热门爆款,已经成为跨境卖家和内容创作者的主流玩法。 不少人都在纠结两大问题&a…...

仓储AGV“大脑“江湖:这家公司拿下37%市场,却仍亏损1.7亿,还马上冲港股
导语大家好,这里是智能仓储物流技术研习社:专注分享智能制造和智能仓储物流等内容。专业书籍:《智能物流系统构成与技术实践》|《智能仓储项目英语手册》|《智能仓储项目必坑手册》|《智能仓储项目甲方必读》|《12大行业智能仓储实战指南》做…...