外部排序算法总结
一.内排总结
在之前博客里,博主已经介绍了各种内部排序算法的原理和C语言代码实现,不懂的朋友可以在同系列专栏里选择查看,今天介绍常见排序算法的最后一点,也就是外部排序。在此之前,我们先对外部排序的各种算法做一下简单的总结。
| 算法种类 | 时间复杂度(最好) | 时间复杂度(最坏) | 时间复杂度(平均) | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 折半插入排序 | O(n) | O(n2 ) | O(n2 ) | O(1) | 是 |
| 直接插入排序 | O(n) | O(n2 ) | O(n2 ) | O(1) | 是 |
| 希尔排序 | ---- | ---- | ---- | O(1) | 否 |
| 冒泡排序 | O(n) | O(n2 ) | O(n2 ) | O(1) | 是 |
| 快速排序 | O(nlog2 n) | O(n2 ) | O(nlog2 n) | O(log2 n) | 否 |
| 简单选择排序 | O(n2 ) | O(n2 ) | O(n2 ) | O(1) | 否 |
| 堆排序 | O(nlog2 n) | O(nlog2 n) | O(nlog2 n) | O(1) | 否 |
| 2路归并排序 | O(nlog2 n) | O(nlog2 n) | O(nlog2 n) | O(n) | 是 |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O® | 是 |
针对每种排序算法的效率差别,我已经总结在上面的表格里了,同时我后面还写了一份针对408范围内的所有数据结果和算法的效率分析专项总结,大家可以期待一首。
二.外部排序
1.外排概念
前面介绍过的排序方法都是在内存中进行的(称为内部排序)。而在许多应用中,经常需要对大文件进行排序,因为文件中的记录很多,无法将整个文件复制进内存中进行排序。因此,需要将待排序的记录存储在外存上,排序时再把数据一部分一部分地调入内存进行排序,在排序过程中需要多次进行内存和外存之间的交换。这种排序方法就称为外部排序。
2.排序方法
文件通常是按块存储在磁盘上的,操作系统也是按块对磁盘上的信息进行读写的。因为磁盘读/写的机械动作所需的时间远远超过内存运算的时间(相比而言可以忽略不计),因此在外部排序过程中的时间代价主要考虑访问磁盘的次数,即I/O次数。
外部排序通常采用归并排序法。它包括两个阶段:①根据内存缓冲区大小,将外存上的文件分成若干长度为l的子文件,依次读入内存并利用内部排序方法对它们进行排序,并将排序后得到的有序子文件重新写回外存,称这些有序子文件为归并段或顺串;②对这些归并段进行逐趟归并,使归并段(有序子文件)逐渐由小到大,直至得到整个有序文件为止。
3.举例说明
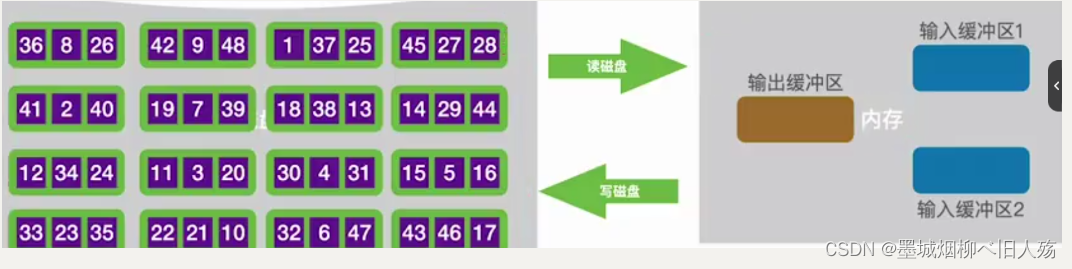
用上面这个例子来说明,我们假设左边是外存中的待排序序列,右边是我们的内存。(这里我们只是举例,实际上用到外部排序时,外存数据量非常庞大,这里只是演示。)这里涉及一部分操作系统的知识点,但都是计算机专业,应该都学过,内存的数据修改完之后是要写回外存的,所以我们这里有两个输入缓冲区和一个输出缓冲区,输入缓冲区用来读入磁盘数据,输出缓冲区用于把数据写回磁盘。
由于我们的外部排序是基于归并排序算法的,归并排序算法要求初始序列有序,所以这里我们在开始外部排序之前(或者说正式排序之前也就是叫预排序),我们需要构造初始有序序列。我们首先从磁盘读取两个块数据进入内存,然后在内存中对这两个块的数据进行某一种内部排序。
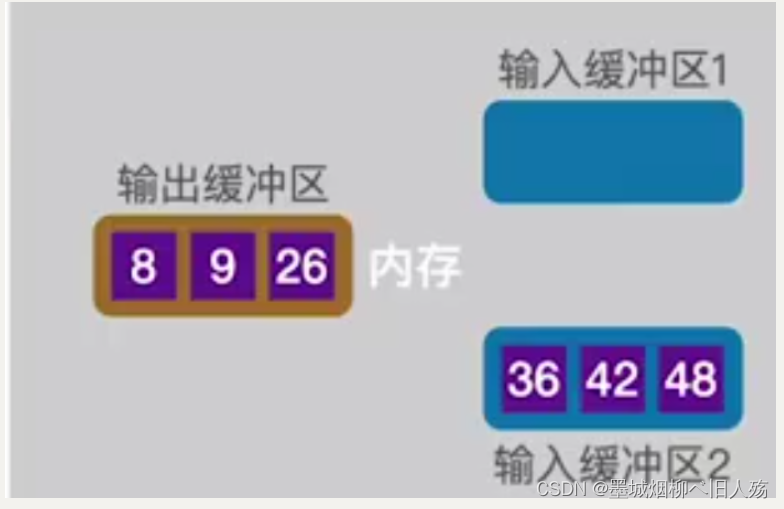
针对本例的前两个数据块,当排序结果写满一个输出缓冲区时,我们把输出缓冲区的数据写回外存。以此类推,预排序就是把外存的数据每两个块读入内存后排序,排序后写回结果。这里的几个块一读是基于内存中输入缓冲区的个数有关,它的选取和外部以及内部空间的大小有关。
预排序后的结果应该是这样的:
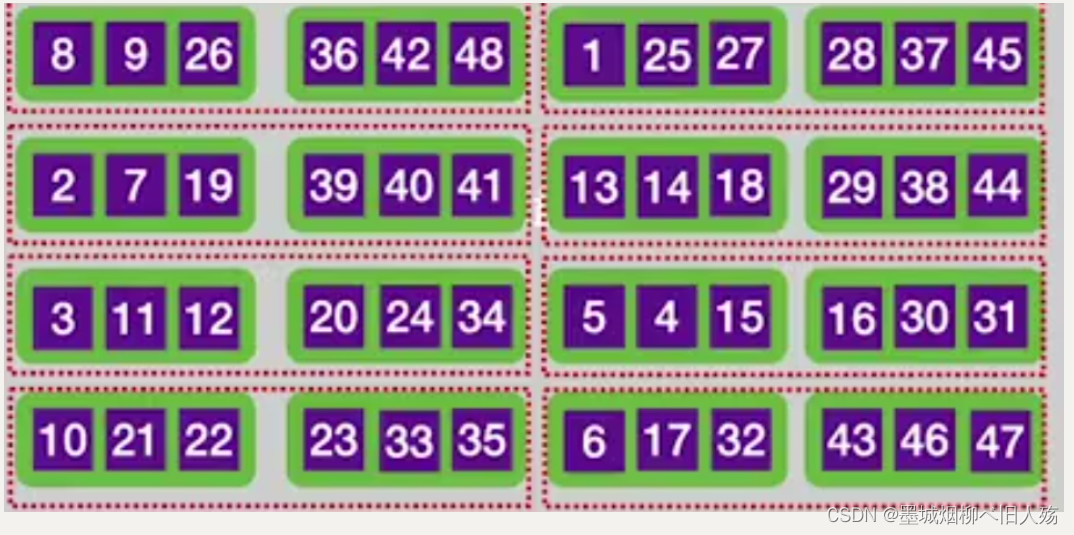
接下来我们的外存中就存在初始有序序列了,所以可以开始进行正常的归并排序了。这里注意,预排序是两个数据块一读,所以两个数据块就形成了一个初始子序列哦,这里只有8个初始子序列哦。接下来把子序列1和子序列2的第一块分别读入输入缓冲区,开始内部排序,还是一样,输出缓冲区已满我们就写回外存。这里还有一点注意哦,当某个时刻比如输入缓冲区1的数据完了,我们不是把输入缓冲区2的数据直接填到输出缓冲区,而是把原来子序列后面的数据块读入内存哦(假设我们这里使用的内部排序算法也是归并排序),这样两个子序列是不是又合并成了一个大的子序列。然后两个大的子序列又可以合并成一个更大的序列,直到最后只有一个序列表示我们外部排序完成。
4.效率分析
我们应该知道,这里影响时间效率的最大因素其实是I/O口的读取次数,内部排序的时间相较于I/O口的读取的读取时间是很少的。所以如果我们想要提高外部排序的时间效率,那么就得想办法减少I/O口的读取次数。
一般地, 对r个初始归并段,做k路平衡归并,归并树可用严格k叉树(即只有度为k与度为0的结点的k叉树)来表示。第一趟可将r个初始归并段归并为 ⌈ r / k ⌉ \lceil{r/k}\rceil ⌈r/k⌉ 个归并段,以后每趟归并将m个归并段归并成 ⌈ m / k ⌉ \lceil{m/k}\rceil ⌈m/k⌉个归并段,直至最后形成一个大的归并段为止。树的高度-1 =「logr1=归并趟数S。可见,只要增大归并路数k,或减少初始归并段
个数r,都能减少归并趟数s,进而减少读写磁盘的次数,达到提高外部排序速度的目的。
三.败者树
上节讨论过,增加归并路数k能减少归并趟数s,进而减少I/O次数。然而,增加归并路数k时,内部归并的时间将增加。做内部归并时,在k个元素中选择关键字最小的记录需要比较k-1次。每趟归并n个元素需要做(n-1)(k-1)次比较,s趟归并总共需要的比较次数随k增长而增长。因此内部归并时间亦随k的增长而增长。这将抵消由于增大k而减少外存访问次数所得到的效益。因此,不能使用普通的内部归并排序算法。为了使内部归并不受k的增大的影响,引入了败者树。 败者树是树形选择排序的一种变体,可视为一棵完全二叉树。k个叶结点分别存放k个归并段在归并过程中当前参加比较的记录,内部结点用来记忆左右子树中的“失败者”,而让胜者往上继续进行比较,一直到根结点。若比较两个数,大的为失败者、小的为胜利者,则根结点指向的数为最小数。
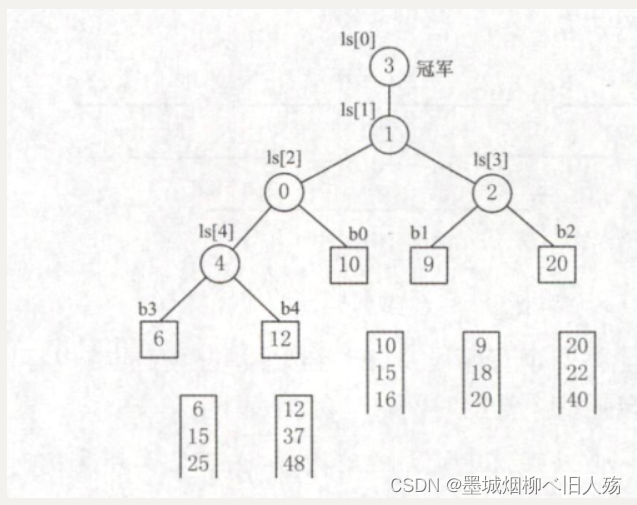
这是实现一个5路归并的败者树的例子。
可见,使用败者树后,内部归并的比较次数与k无关了。因此,只要内存空间允许,增大归并路数k将有效地减少归并树的高度,从而减少I/O次数,提高外部排序的速度。值得说明的是,归并路数k并不是越大越好。归并路数k增大时,相应地需要增加输入缓冲区的个数。若可供使用的内存空间不变,势必要减少每个输入缓冲区的容量,使得内存、外存交换数据的次数增大。当k值过大时,虽然归并趟数会减少,但读写外存的次数仍会增加。
四.置换-选择排序(生成初始序列)
减少初始归并段个数r也可以减少归并趟数S。若总的记录个数为n,每个归并段的长度为l,则归并段的个数r=「nll 1。采用内部排序方法得到的各个初始归并段长度都相同(除最后一段外),它依赖于内部排序时可用内存工作区的大小。因此,必须探索新的方法,用来产生更长的初始归并段,这就是本节要介绍的置换-选择算法。
设初始待排文件为FI,初始归并段输出文件为FO,内存工作区为WA, FO和WA的初始状态为空,WA可容纳w个记录。置换选择算法的步骤如下:
- 1)从FI输入w个记录到工作区WA。
- 2)从WA中选出其中关键字取最小值的记录,记为MINIMAX记录。
- 3)将MINIMAX记录输出到FO中去。
- 4)若FI不空,则从FI输入下一个记录到WA中。
- 5)从WA中所有关键字比MINIMAX记录的关键字大的记录中选出最小关键字记录,作为新的MINIMAX记录。
- 6)重复
3) ~5),直至在WA中选不出新的MINIMAX记录为止,由此得到一个初始归并段,输出一个归并段的结束标志到FO中去。 - 7)重复
2)~6),直至WA为空。由此得到全部初始归并段。
五.最佳归并树
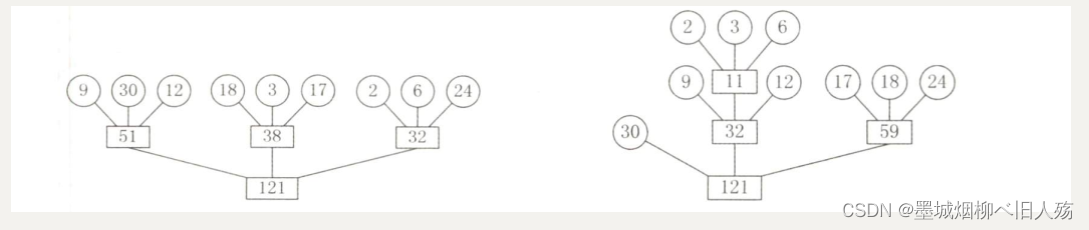
文件经过置换-选择排序后,得到的是长度不等的初始归并段。下 面讨论如何组织长度不等的初始归并段的归并顺序,使得I/O次数最少?假设由置换选择得到9个初始归并段,其长度(记录数)依次为9, 30, 12, 18,3, 17,2,6,24。现做3路平衡归并,其归并树如图8.16所示。在图左中,各叶结点表示一个初始归并段,上面的权值表示该归并段的长度,叶结点到根,的路径长度表示其参加归并的趟数,各非叶结点代表归并成的新归并段,根结点表示最终生成的归并段。树的带权路径长度WPL为归并过程中的总读记录数,故I/O次数= 2xWPL = 484。
显然,归并方案不同,所得归并树亦不同,树的带权路径长度(I/O次数)亦不同。为了优化归并树的WPL,可以将哈夫曼树的思想推广到m叉树的情形,在归并树中,让记录数少的初始归并段最先归并,记录数多的初始归并段最晚归并,就可以建立总的I/O次数最少的最佳归并树。上述9个初始归并段可构造成一棵如图右所示的归并树,按此树进行归并,仅需对外存进行446次读/写,这棵归并树便称为最佳归并树。
六.总结
好了,到这里408范围内的数据结构和算法部分我们已经学完了,接下来转战计算机网络和操作系统部分。
相关文章:
外部排序算法总结
一.内排总结 在之前博客里,博主已经介绍了各种内部排序算法的原理和C语言代码实现,不懂的朋友可以在同系列专栏里选择查看,今天介绍常见排序算法的最后一点,也就是外部排序。在此之前,我们先对外部排序的各种算法做一…...
Redis安装以及配置隧道连接(centOs)
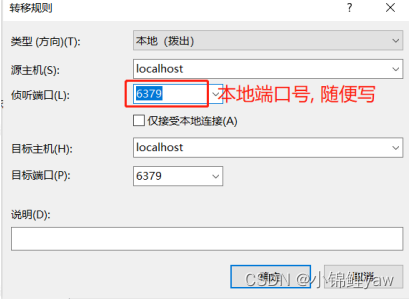
目录 1.centOs安装Redis 2. Redis 启动和停⽌ 3. 操作Redis 2.Xshell配置隧道 1.centOs安装Redis #使⽤yum安装Redis yum -y install redis 2. Redis 启动和停⽌ #查看是否启动 ps -ef|grep redis#启动redis: redis-server /etc/redis.conf &#停⽌Redis redis-cli sh…...

mysql二进制方式升级8.0.34
一、概述 mysql8.0.33 存在如下高危漏洞,需要通过升级版本修复漏洞 Oracle MySQL Cluster 安全漏洞(CVE-2023-0361) mysql/8.0.33 Apache Skywalking <8.3 SQL注入漏洞 二、查看mysql版本及安装包信息 [rootlocalhost mysql]# mysql -V mysql Ver 8.0.33 fo…...

Kotlin单例代码实例
目录 一、饿汉式的实现二、懒汉式的实现三、安全 懒汉式的实现四、双重校验DCL 的实现 一、饿汉式的实现 Kotlin版本 object SingletonDemoKt/*** 背后的逻辑代码:public final class SingletonDemoKt {public static final SingletonDemoKt INSTANCE;private Si…...

(7.28-8.3)【大数据新闻速递】《数字孪生工业软件白皮书》、《中国绿色算力发展研究报告》发布;华为ChatGPT要来了
【数字孪生工业软件白皮书(2023)】 近日,第七届数字孪生与智能制造服务学术会议成功举行,2023《数字孪生工业软件白皮书》在会上正式发布。《白皮书》在《Digital Twin》国际期刊专家顾问委员会指导下,由国家重点研发计…...

TikTok海外抖音云控抢金币宝箱
TikTok海外抖音云控抢金币宝箱 中芯密科云控系统是一个稳定、操作简单的自动化管理工具,专为大型机房设计,可以监控、控制和管理机房内的设备。该系统具有负载均衡、操作简单、高容错等特点,能够提高机房设备的稳定性和可用性。 该系统具有以…...

H3C交换机如何通过MAC和IP查寻对应ARP信息
环境: H3C S6520-26Q-SI version 7.1.070, Release 6326 问题描述: H3C交换机如何通过MAC 查寻对应IP信息 解决方案: 一、已知设备MAC地址为ac11-b134-d066 通过MAC 查寻对应IP信息 命令 dis arp | in X-X-X [H3C]dis arp | in ac11…...

python进阶
目录 Json数据格式 前言 JSON格式 python数据和Json数据的相互转化 多线程 进程和线程 串行和并行 多线程编程 创建线程参数 具体案例 网络编程 套接字 socket服务端编程步骤 socket客户端编程步骤 python操作mysql数据库 查询并接收数据 数据插入 Json数据格…...

spring boot 配置文件和属性注入
文章目录 配置文件位置和路径自定义配置文件 属性注入添加yaml文件的支持 配置文件 位置和路径 当我们创建一个 Spring Boot 工程时,默认 resources 目录下就有一个 application.properties 文件,可以在 application.properties 文件中进行项目配置&am…...
springboot+vue私人健身和教练预约管理系统 nt5mp
随着世界经济信息化、全球网络化的到来,信息线上管理的飞速发展,为私人健身和教练预约管理的改革起到关键作用。若想达到安全、快捷的目的,就需要拥有信息化的组织和管理模式,建立一套合理、畅通、高效的私人健身和教练预约管理系…...

Kotlin基础(十一):反射和注解
前言 本文主要讲解kotlin反射和注解。 Kotlin文章列表 Kotlin文章列表: 点击此处跳转查看 目录 1.1 kotlin反射 1.1.1 kotlin反射概念和常见使用场景 在Kotlin中,反射是一种能够在运行时动态地获取、检查和操作类、属性、方法等结构的能力。Kotlin为反射提供了一…...

DALLE2论文解读及实现(一)
DALLE2: Hierarchical Text-Conditional Image Generation with CLIP Latents paper: https://cdn.openai.com/papers/dall-e-2.pdf github: https://github.com/lucidrains/DALLE2-pytorch DALLE2概览: - CLIP模型: 用于生成text embedding zt 和image …...
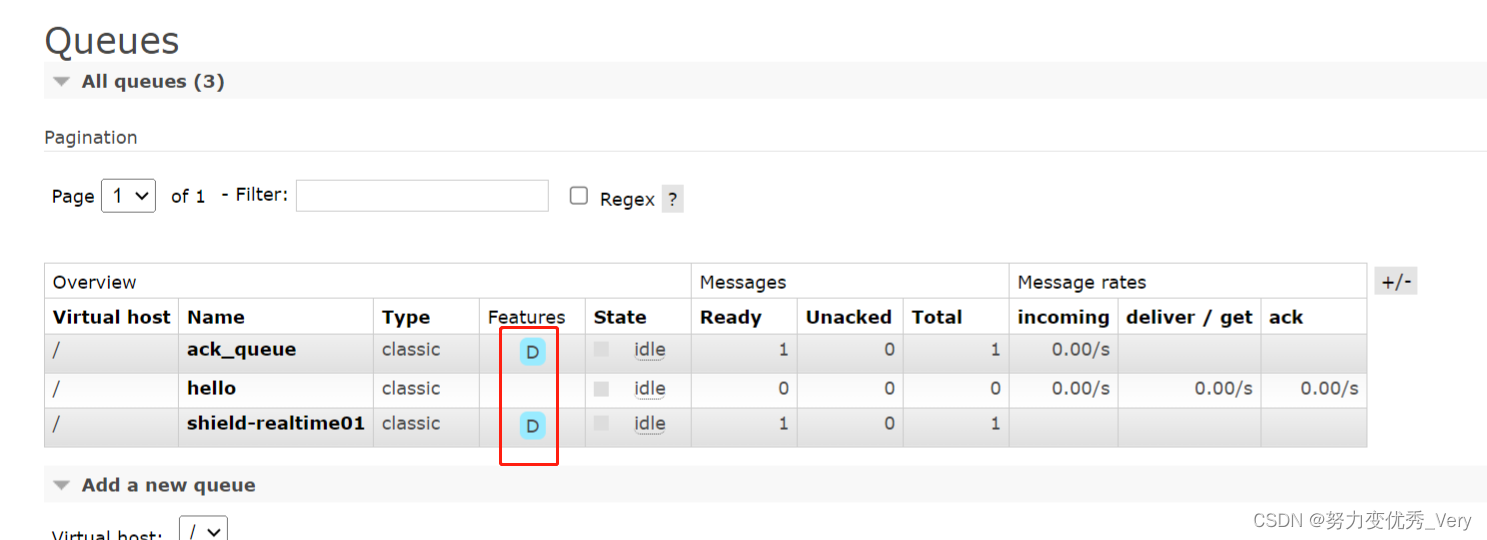
RabbitMQ-API
这里写目录标题 Hello word 模式添加依赖生产者消费者获取信道工具类 Work Queues模式消费者代码 C1开启多线程运行启动 消费者代码 C2生产者代码 消息应答自动应答消息应答的方法Multiple 的解释消息自动重新入队消息手动应答代码消费者API 队列持久化消息持久化不公平分发消息…...
外边距实现居中的写法
1、代码实例 2、默认是贴到左侧对齐的,但我们想要把他贴到中间对齐 3、居中的写法 4、这样就可以保证盒子居中了 5、以上写法仅适于行内元素和行内块元素的写法,有没有什么方法适用于行内块元素:可以添加text-align:center进行添加࿰…...
)
剑指 Offer 20. 表示数值的字符串 (正则 逐步分解)
文章目录 题目描述题目分析法一:完整代码: 法二:完整代码: 题目描述 请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者…...

【深度学习】Transformer,Self-Attention,Multi-Head Attention
必读文章: https://blog.csdn.net/qq_37541097/article/details/117691873 论文名:Attention Is All You Need 文章目录 1、Self-Attention 自注意力机制2、Multi-Head Attention 1、Self-Attention 自注意力机制 Query(Q)表示当…...
CADintosh X for mac CAD绘图软件2D CAD 程序 兼容 M1
CADintosh X for Mac是一个功能强大的2D CAD绘图程序,专为Mac用户设计。它由Lemke Software开发,提供了一套丰富的工具和功能,使用户能够轻松创建高质量的技术图纸,平面图和设计。 CADintosh X for Mac具有直观的用户界面&#x…...

【读书笔记】《厌女》- [日]上野千鹤子 - 2010年出版
不停的阅读,然后形成自己的知识体系。 2023.08. 读 《厌女》- [日]上野千鹤子 - 2010年出版 - 豆瓣读书 文章目录 2023年中文版作者序2015年中文版作者序第一章 喜欢女人的男人的厌女症 2023年中文版作者序 ‘厌女症’的现象本来如‘房间里的大象’,因为…...

Android 从其他xml文件中获取View组件数据
问题 Android Studio 我想在 trace.java 从setting.java绑定的页面activity_setting.xml中 的editview中获取数据 解决方案 仅适用于 在同一应用的不同组件之间共享数据 在 SettingActivity.java 中,当用户准备离开当前活动时,可以将 EditText 中的数…...
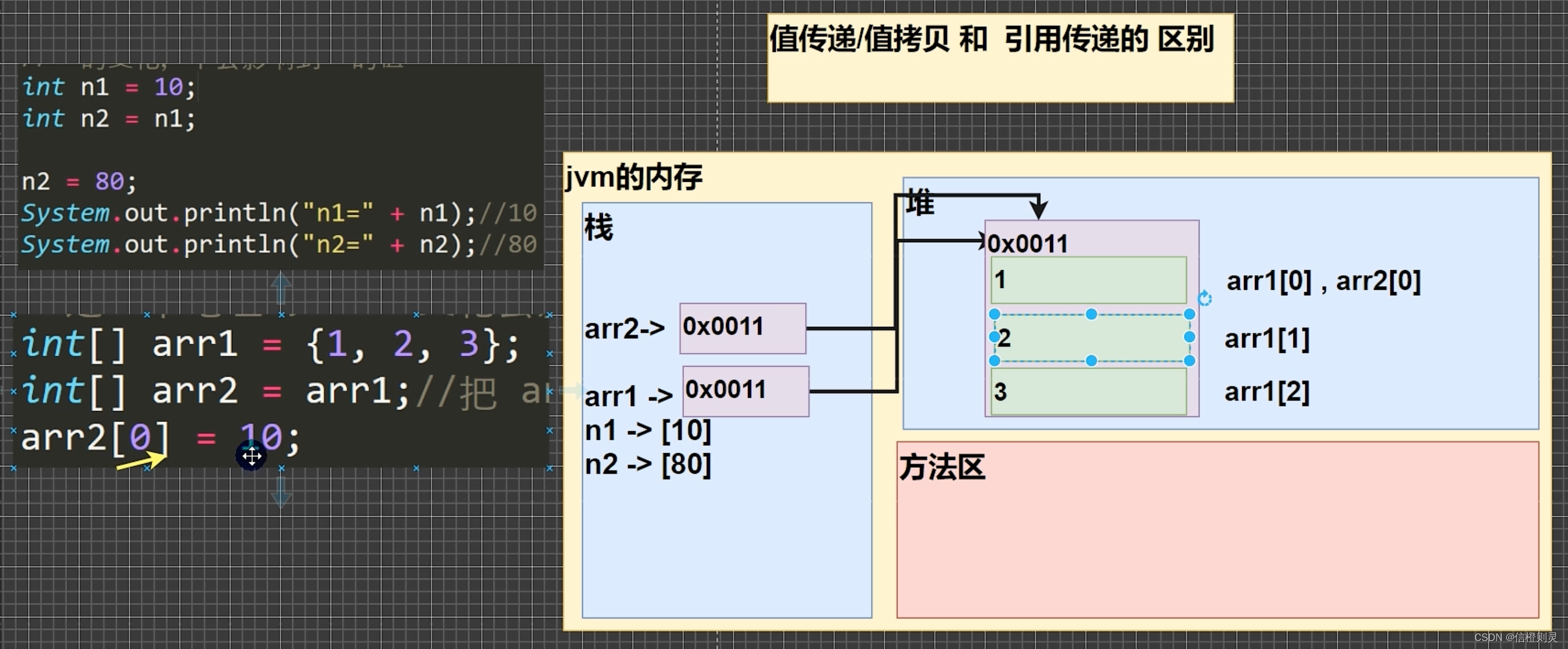
java 数组的使用
数组 基本介绍 数组可以存放多个同一类型的数据,数组也是一种数据类型,是引用类型。 即:数组就是一组数据。 数组的使用 1、数组的定义 方法一 -> 单独声明 数据类型[] 数组名 new 数据类型[大小] 说明:int[] a new int…...

N_m3u8DL-RE:跨平台流媒体下载终极指南
N_m3u8DL-RE:跨平台流媒体下载终极指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 在当今数字时…...

【免费下载】 树莓派4B原理图资源下载
树莓派4B原理图资源下载 【下载地址】树莓派4B原理图资源下载分享 树莓派4B原理图资源下载本仓库提供了一个方便的途径,供大家下载树莓派4B的原理图资源文件 项目地址: https://gitcode.com/open-source-toolkit/ae590 本仓库提供了一个方便的途径࿰…...

Windows热键冲突终结者:Hotkey Detective深度解析与实战指南
Windows热键冲突终结者:Hotkey Detective深度解析与实战指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 想…...
)
别再全局搜组件了!React Developer Tools 这 3 招定位文件(含 VSCode 自动跳转配置)
高效定位React组件的3种专业工作流 在接手一个大型React项目时,最令人头疼的莫过于在数百个文件中寻找特定组件的定义和使用位置。传统的全局搜索方法不仅效率低下,还容易因命名冲突导致误判。本文将分享三种经过实战验证的高效定位方法,特别…...

使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回 在开发或调试过程中,有时你可能需要绕过高级 SDK…...

so-vits-svc3.0 从零到一:Windows环境下的避坑指南与实战训练
1. 环境准备:从零搭建AI语音克隆的基石 第一次接触so-vits-svc3.0时,我花了整整三天时间在环境配置上反复折腾。现在回想起来,那些踩过的坑完全可以避免。Windows环境下最让人头疼的就是CUDA和PyTorch的版本匹配问题,我见过太多新…...

Arm SVE2向量存储指令ST3Q/ST4Q详解与应用优化
1. SVE2向量存储指令概述在Armv9架构中,SVE2(Scalable Vector Extension 2)作为第二代可扩展向量指令集,引入了多项增强的向量处理能力。其中ST3Q和ST4Q指令是专门为高效存储三路和四路128位宽向量数据而设计的谓词化存储操作。这…...

SaaS ERP和传统ERP,到底差在哪?
这几年,ERP这个词越来越火。但有意思的是,很多企业老板、管理层,甚至已经在用ERP的人,其实都没真正分清:“SaaS ERP”和“传统ERP”,到底差在哪。很多人会觉得:“不都是ERP吗?不就是…...

Codex 怎么详细科学地先出计划
本文聚焦一个非常关键的使用能力:让 Codex 在执行之前先出计划。很多人一上来就让 Codex 改代码、修 bug、做联动,结果不是方向偏了,就是改动过大、验证困难。先出计划的价值,不是多一个步骤,而是让复杂任务先被看清楚…...
的经典实战与优化技巧)
从八皇后到N皇后:深度优先搜索(DFS)的经典实战与优化技巧
从八皇后到N皇后:深度优先搜索(DFS)的经典实战与优化技巧 在国际象棋的64格棋盘上放置8个互不攻击的皇后,这个看似简单的谜题背后隐藏着组合数学的深邃奥秘。当我们将问题扩展到NN棋盘上的N皇后问题时,它便成为了检验算法效率的绝佳试金石。本…...